西电计科院微机原理与系统设计课程笔记(车向泉版)
微机原理与系统设计
以下内容是西安电子科技大学计算机科学与技术学院2021年大三上学期车向泉老师的微机原理与系统设计课程的随课笔记。笔记的PDF版本和课程的学在西电上课录像下载链接如下(请勿将录像上传到B站等网站!!):
链接:https://pan.baidu.com/s/12b7Ssu6uygtFn-gfBYoy6g
提取码:2v5w
阅读时请注意:
1.笔记中的删除线标注了上课时老师做了讲解但笔记没有详细记述的内容,有需要可以自己观看录播的相应内容学习
2.9月30日的录播缺失,该节课的内容对应第三章最后的几小节,期末考试不要求
3.第8章只讲了前一部分,该章内容就是第6章、第7章知识的综合运用,所以没有记述。第8章和复习课内容对应录播资源的最后四节,可以自行观看学习
4.虽然笔记的内容比较多,但实际上32位汇编、C语言与汇编语言的混合编程、总线的大部分内容等等都不是期末考试要求的内容。具体哪些内容不要求在每学期末车老师的复习课里都会说
其他各科笔记汇总
开课介绍
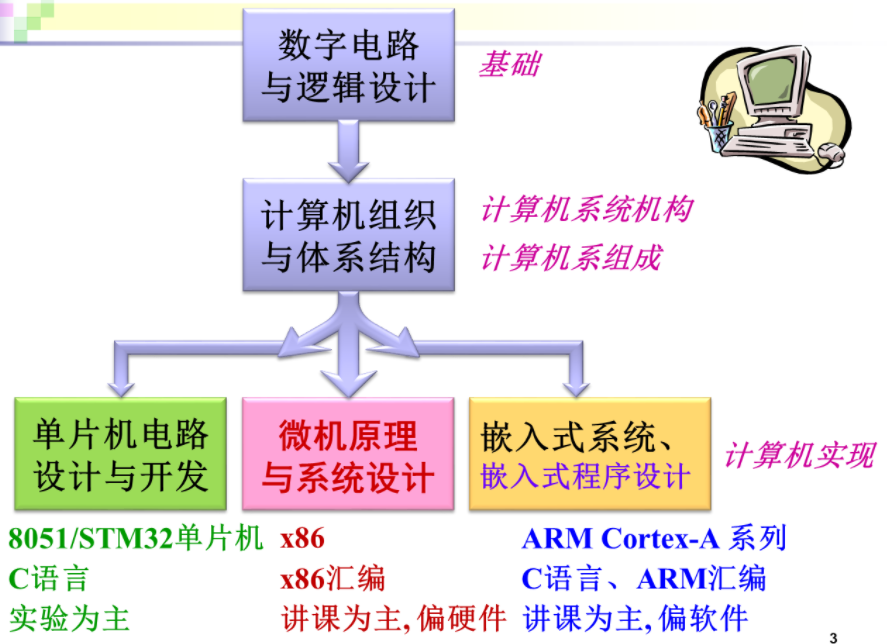
数字电路与逻辑设计:用电路来实现逻辑关系,了解常用的一些模块和芯片
计算机组织与体系结构:这个课以前是计算机组成原理和计算机系统结构两门课。上学期上课时讲过三个概念:计算机系统结构,计算机组成,计算机实现
在设计计算机时,首先要做一个总体的架构,包括指令集,流水线结构等等,这个主体设计就是计算机系统结构要研究的内容
之后要细化为逻辑电路,这就是计算机组成要研究的内容
然后要选择合适的芯片,芯片之间连接构成电路,最后调试。实实在在地做出来,这是计算机实现要解决的问题
单片机电路设计与开发/微机原理与系统设计/嵌入式系统这三门课很像,都对应计算机实现。要构成一个计算机系统,首先要选择一个CPU,然后增加一些外围的东西,如存储器,各种接口芯片。在此基础上还要设计一些软件让它工作,这个整体思路都是一样的。区别在于:
1.研究的CPU不一样
单片机的CPU相对来讲性能比较弱,像8051是8位CPU,纯粹单任务,不支持虚拟存储管理,多任务,也没有流水线和高速缓存
嵌入式系统主要研究ARM的Cortex-A系列,有MMU存储管理单元,支持虚拟存储管理,多任务,也有流水线和高速缓存,可以移植一些操作系统,如Linux
微机原理则研究Intel和AMD的X86处理器
2.编程用语言不一样
3.课程教授方式不同
4.涉及领域不一样
单片机一般用在物联网,如一些家用电器里面,成本低且可靠性高
ARM的Cortex-A系列一般用在智能手机,平板电脑等手持移动设备上,操作系统以Android为主
x86一般用在笔记本电脑,台式机,超级计算机等上,操作系统以Linux和Windows为主
讲了下x86重要性,然后推荐了几本教材和参考资料
绪论
基本概念
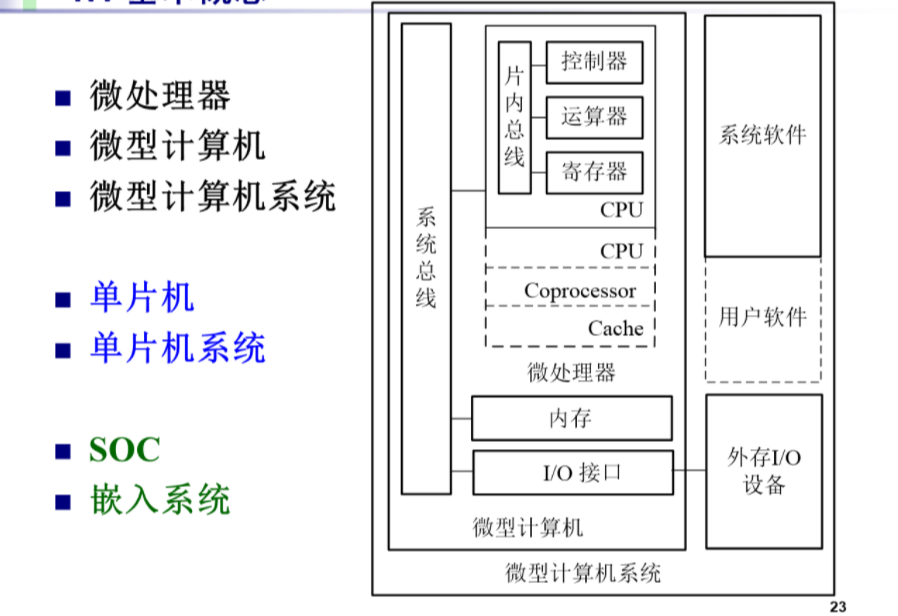
要构成一个CPU,得有控制器,运算器和寄存器,然后通过总线连接起来。在早期这些都是分立元件,随着芯片的集成度提高后,可以把这些构成CPU的东西放在一个芯片里面,这个芯片就叫微处理器。随着集成度越来越高,芯片里还可以集成一定容量的高速缓存,协处理器,甚至很多个CPU的内核
微处理器还要从内存里取指令然后执行指令。人和计算机交互要通过外设,外设要通过接口才能够连接到计算机里面。微处理器,内存还有各种各样的接口放在一起通过系统总线连到一块就叫微型计算机
想要计算机工作还需要相应的软件,硬件和软件加在一块叫微型计算机系统
构成微型计算机的这些东西做到一个芯片里面,好像一个芯片就是一个计算机,这就叫单片机。加上相应的软件就构成单片机系统
从广义上讲,单片机系统就属于嵌入系统。 狭义上讲,嵌入系统指的是性能比较强的专用计算机
SOC (System on Chips) 把一个计算机系统都集成在芯片里面。Intel最新的x86处理器,如i3,i5,i7i3,i5,i7i3,i5,i7就属于SOC,里面不仅集成了多个CPU内核,还集成了图形处理单元,一些高速的总线接口,内存控制器等等,把构成计算机的大多数电路都集成在一个芯片里面
微处理器概述
介绍了Intel的x86处理器的历史,中间比较了几个处理器的参数
8088微处理器是8086微处理器的简化版,它的内核仍然是16位的CPU,但是外部系统总线数据线只有8根线。访问内存和接口时一次只能传输8位数据
微型计算机概述
假设有两台CPU是x86指令集兼容,但是如主板,接口连接的外设等底层硬件不同的计算机,为什么可以实现安装相同的操作系统和软件?
操作系统跟硬件之间隔了一层。 计算机刚一加电,启动之后最先执行的代码是固化在计算机主板的ROM里面(现在用的是flash存储器),那段代码叫BIOS。这个程序要做的是:
1.硬件的自检
如检查一下内存有多大,如何控制内存,有什么外设接口等
2.各种外设接口初始化
接口和外设内也会有一些寄存器,里面的内容决定其工作状态。 加电之后的内容是随机的,所以要BIOS程序写入内容初始化使其正常工作
3.给操作系统提供功能调用
BIOS程序执行完后,它的代码还会驻留在内存里面,然后再从磁盘的引导扇区装代码,引导代码装操作系统。操作系统在装载的过程中是通过BIOS程序提供的编程接口,用调用函数或者软中断的形式来调用BIOS程序的代码来访问硬件的
BIOS程序给操作系统提供的编程接口是标准化的,这样在不同的硬件上就可以装相同的操作系统
x86处理器刚加电启动时处于实模式,实模式相当于是一台快速的8086,只能够运行16位的程序。所以BIOS程序全部或者说最开始执行的那段代码肯定要设计成16位程序,通常可能还要用汇编语言来设计。 但是随着操作系统装载完成,CPU最终要从实模式切换到32位或64位CPU的保护模式,这时操作系统访问硬件就要调用设备驱动程序提供的函数,而设备驱动程序给某一操作系统提供的编程接口也是标准的
不同的硬件设备驱动程序不一样,但它给操作系统提供的编程接口调用方式都是一样的,这样在不同的硬件上就可以装相同的操作系统
中间介绍了微型计算机的历史
Intel 单核/多核处理器
单核处理器8086
8086具有以下特点:
1.最大内存寻址空间可以达到1M(=220)1M(=2^{20})1M(=220)字节
2.内部的通用寄存器都是16位的,因为它是16位的CPU
16位的寄存器怎么表示20位的内存地址?
对内存采用分段管理方式。段寄存器保存段的起始地址的高16位,低4位默认是0;指针寄存器内存16位的段内偏移
3.x86处理器采用独立编址。内存与接口和外设里的存储器各有独立的地址空间,各有不同的指令和读写信号
8086的接口地址空间只有64K字节,不需要分段
8086的内部框图:
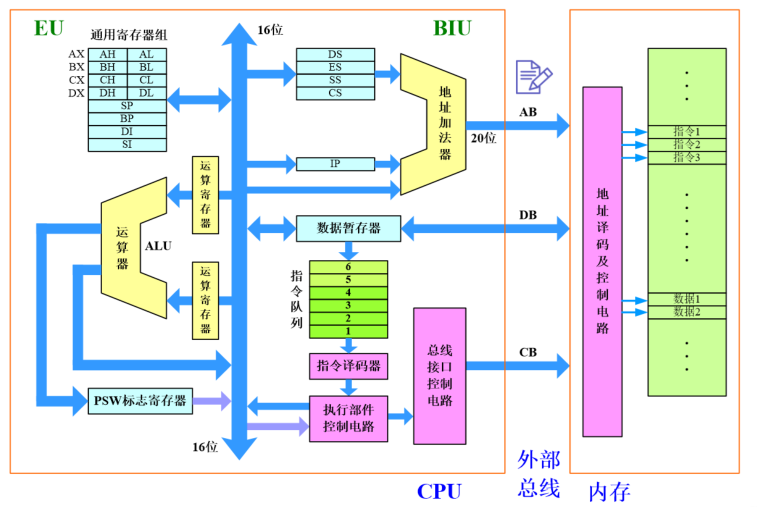
8086内部有14个程序员可见的16位通用寄存器
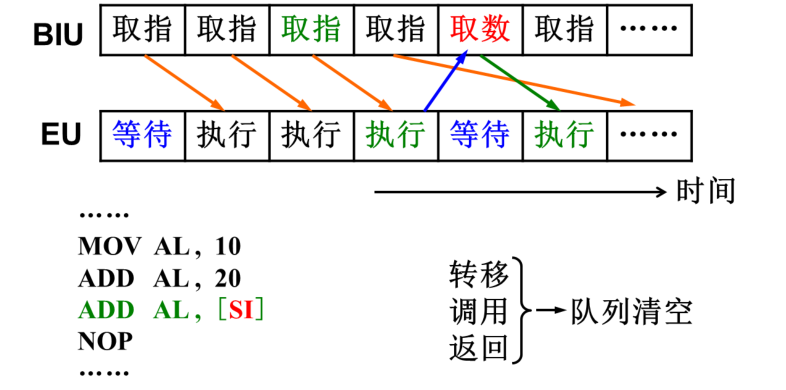
8088的指令队列是4个字节,8086是6个字节
分为BIU和EU。由于有指令队列,二者可并行工作
总线接口单元BIU (Bus Interface Unit) :负责与存储器,I/O接口出传递数据
执行单元EU (Execute Unit) :负责指令的执行
8086的AX∼\sim∼DX4个寄存器可以拆成2个8位的来用,如低8位叫AL,高8位叫AH
汇编语言中 [SI] 表示寄存器间接寻址
8086的寄存器结构:
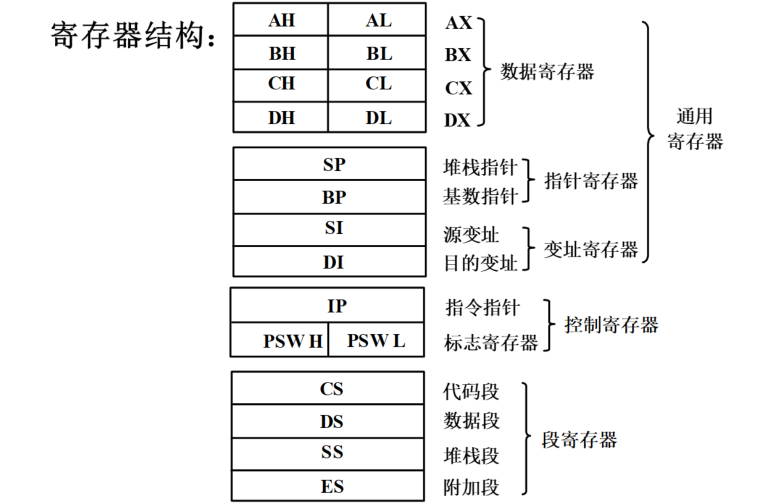
SP,BP,SI,DI,IP是指针寄存器,用来存段内偏移。CS,DS,SS,ES是段寄存器,用来存段起始地址的高16位
例题:
这段程序访问的主存地址是:
MOV DX,0A000H MOV DS,DX MOV SI,9000H MOV AL,[SI]答案:A9000H
解析:
1.数据传送指令不支持立即数到段寄存器之间的直接传送,所以要初始化段寄存器必须要先把立即数传送到某一个通用寄存器
2.16进制的立即数形式如果最高位是英文字母,在它的左侧必须要加一个0,编译程序才会认为这是一个立即数
3.最终DS内容为0A000H,SI内容为9000H。0A0000H + 9000H = 0A9000H
代码段寄存器 (Code Segment):程序执行时内存里会存机器指令,这些机器指令所在的段叫代码段。代码段段的起始地址的高16位就存在CS
数据段寄存器 (Data Segment):指令执行的过程中肯定需要一些数据要从内存中取,或者最终的结果要存到内存中去。存储数据的段叫数据段
堆栈段寄存器 (Stack Segment):执行的指令中会有PUSH压栈和POP出栈指令,主程序调用时要保护当前的断点,断点要保护在堆栈里面,免不了要涉及一些和堆栈有关的操作。堆栈的这些数据所在的段叫堆栈段
附加段寄存器 (Extra Segment):也是用来访问数据的。默认用DS,也可以指定用ES来访问数据。一般用于跨段访问数据
MOV AX,[BX] ;默认段寄存器是DS
MOV AX,ES:[BX] ;加段超越前缀,此时段寄存器是ES
AX∼DXAX\sim DXAX∼DX大多数情况下都可以随便用,但也有特殊用途:
数据寄存器AX (Accumulator):一些特殊的指令,比如说乘法指令,被乘数是隐含寻址,默认在AX。最终结果的一部分也会放在AX,除法指令也有类似的规定。包括后面用来访问接口的IN指令和OUT指令,寄存器必须得用AX
运算结果的低16位默认存在AX,高16位默认存在DX
数据寄存器BX (Base):也可以当指针寄存器来用,用来间接寻址
AX,CX,DX不可以
数据寄存器CX (Count):在一些特殊的指令中用于计数,如汇编语言中用LOOP指令实现循环时CX会记录剩余循环次数
数据寄存器DX (Data):纯粹用来存数据
指令指针寄存器 (Instruction Point):为了取得下一条指令的内存地址,需要用到CS和IP,分别存代码段的起始地址的高16位(低4位默认为0)和16位的段内偏移
堆栈指针寄存器 (Stack Point):SS和SP配合共同确定当前堆栈栈顶的位置
注意x86中栈顶是小地址,栈底是大地址
16位的CPU,堆栈里每一个数据必须是16位的。所以没有 PUSH AL 和 POP AL,只有 PUSH AX 和 POP AX。32位的x86同理
基址指针寄存器 (Base Point):指针寄存器如果用BX,那默认的段寄存器是DS。如果用BP,那默认的段寄存器是SS。故BP一般是用来间接寻址访问堆栈当中的任意一个元素的
源变址寄存器 (Source Point) 和目的变址寄存器 (Destination Point):访问数据,默认的段寄存器是DS,指针寄存器可以用BX,SI,DI,只有这3个寄存器可以用来间接寻址访问数据段
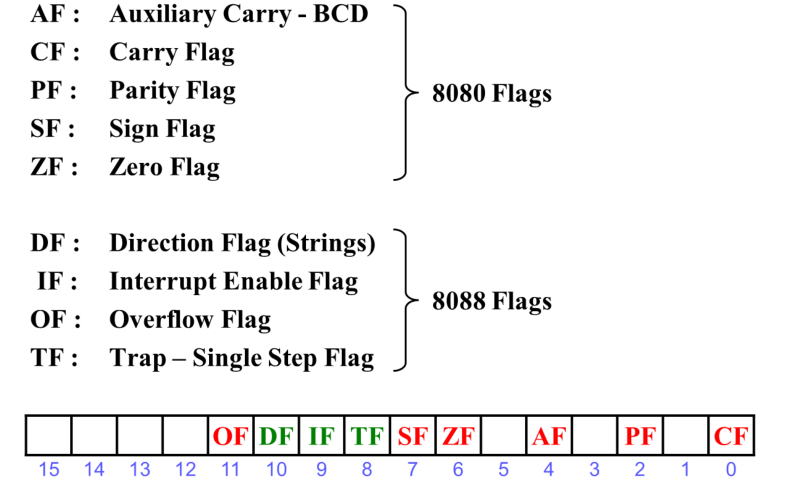
标志寄存器/程序状态字 (PSW/FLAGS) :
辅助进位标志位 (Auxiliary Carry - BCD):加法运算如果运算结果的第3位向第4位有进位,AF置1。BCD数运算有关的指令里可能会用到
第几位从低位,从0开始编号
进位/借位标志位 (Carry Flag):加法运算运算结果的最高位向更高位有进位或减法运算最高位向更高位有借位,CF置1
这里的加减法理解为无符号数相加减
奇偶标志位 (Parity Flag):运算结果中1的结果如果为偶数个,PF置1。可用于加奇偶校验位
符号标志位 (Sign Flag):反映运算结果的最高位,最高位是什么SF就是什么
零标志位 (Zero Flag):运算结果为0,ZF置1
溢出标志位 (Overflow Flag):运算结果溢出时,OF置1
以上标志位都是运算器的硬件根据运算结果自动管理的
中断允许标志位 (Interrupt Enable Flag):关中断指令CLI可将IF置0,之后CPU不会响应任何来自外设或者接口的中断请求。开中断指令STL可将IF置1
方向标志位 (Direction Flag(Strings) ):CLD可将DF清0,串操作指令在重复执行的时候就会从小地址向大地址的方向访问数组。STD可将DF置1,串操作指令访问数组时会从大地址往小地址的方向访问
陷阱标志位 (Trap-Single Step Flag):跟调试有关,单步跟踪的时候可能用到。TF置1后CPU每执行完一条指令后就会在内部产生一个单步中断,最终会跳转到单步中断所对应的中断服务程序,即调试工具代码的一部分
以上标志位有专门的指令进行管理,让CPU工作在不同的状态
8086的主存结构:
先看双体结构:
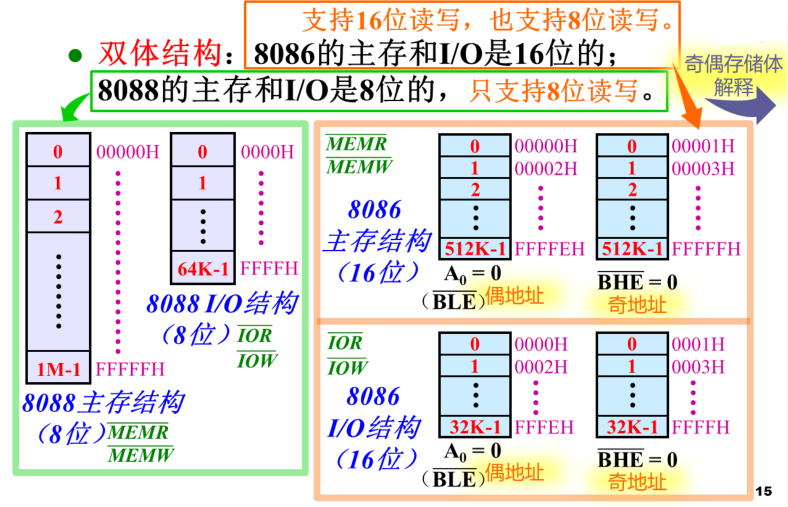
8088的内存相对简单,不分存储体,只有一个8位的存储体就够了,接口也一样,设计较简单
8086把内存分为两个存储体,偶地址存储体和奇地址存储体,有各自的存储体选择信号以实现8位和16位传送读写。偶地址存储体的选择信号如果是低电平有效的话,地址线最低位A0‾\overline{A_0}A0可当作偶地址存储体的选择信号。奇地址存储体的选择信号则有专门的引脚信号BHE‾\overline{BHE}BHE
给这两个存储体的都是字的地址,从A1‾\overline{A_1}A1开始,A0‾\overline{A_0}A0理解成偶地址存储体的选择信号
要读16位数据,会存在一次和分两次的情况:
一次,
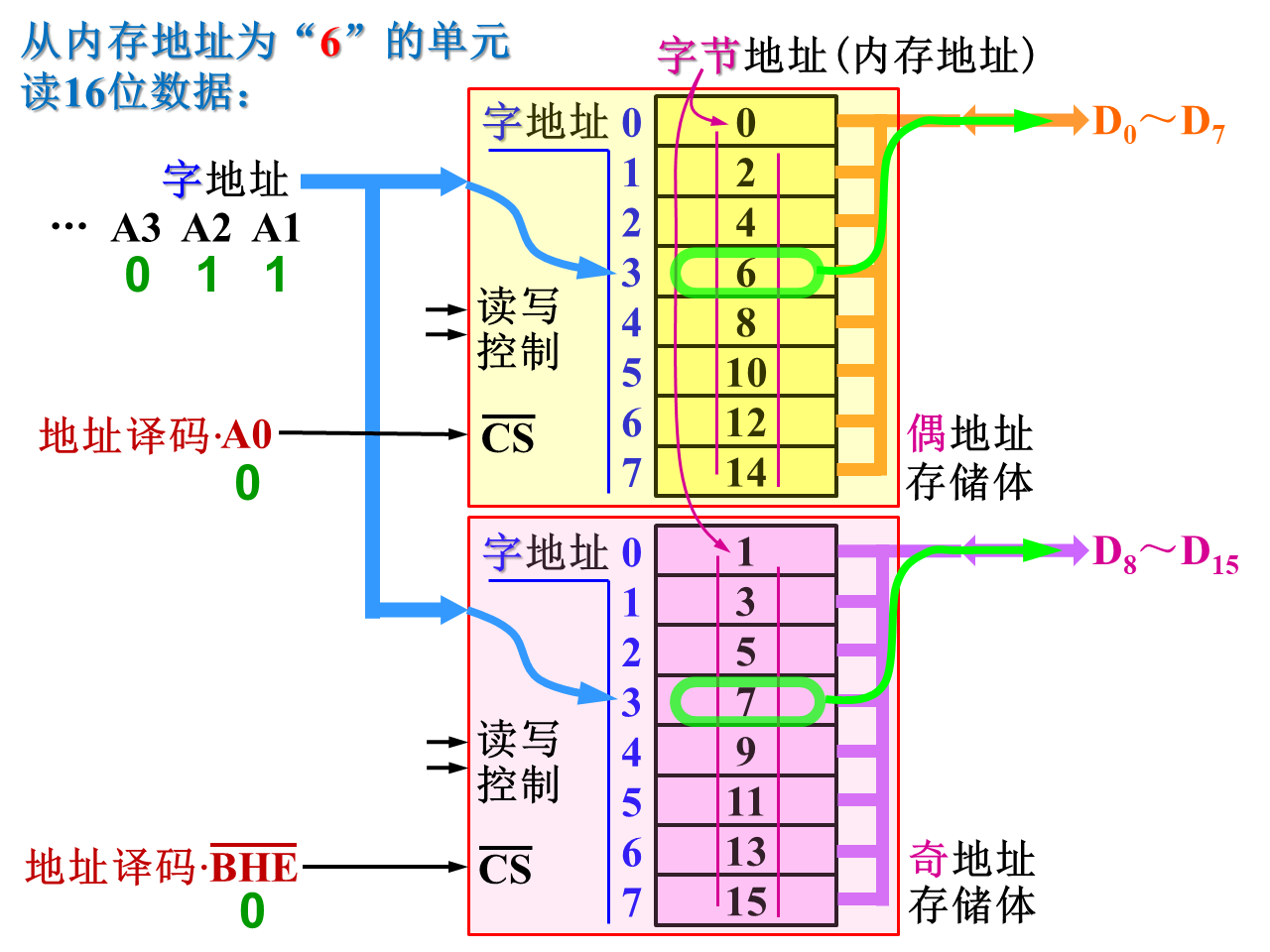
必须分两次,
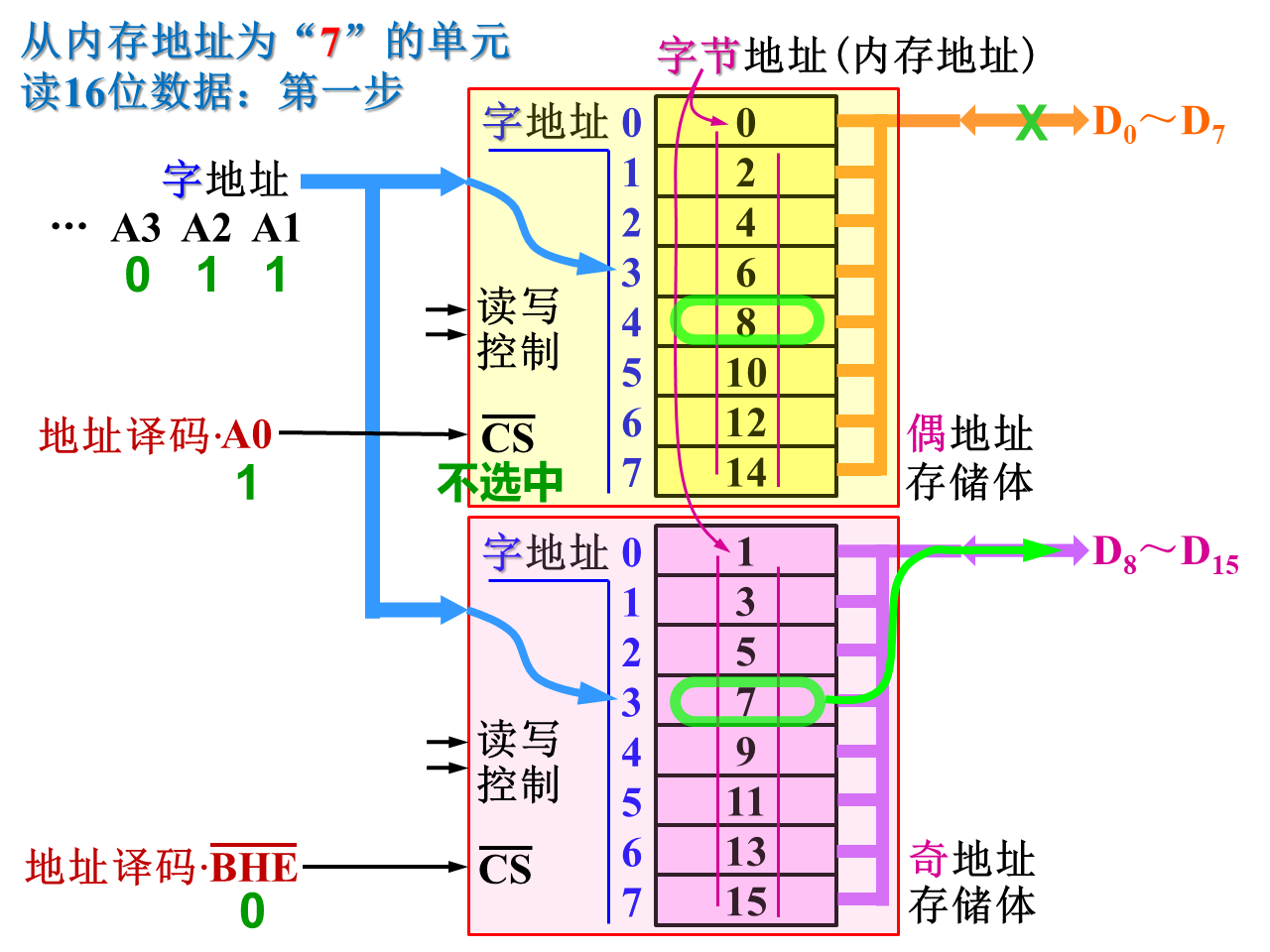
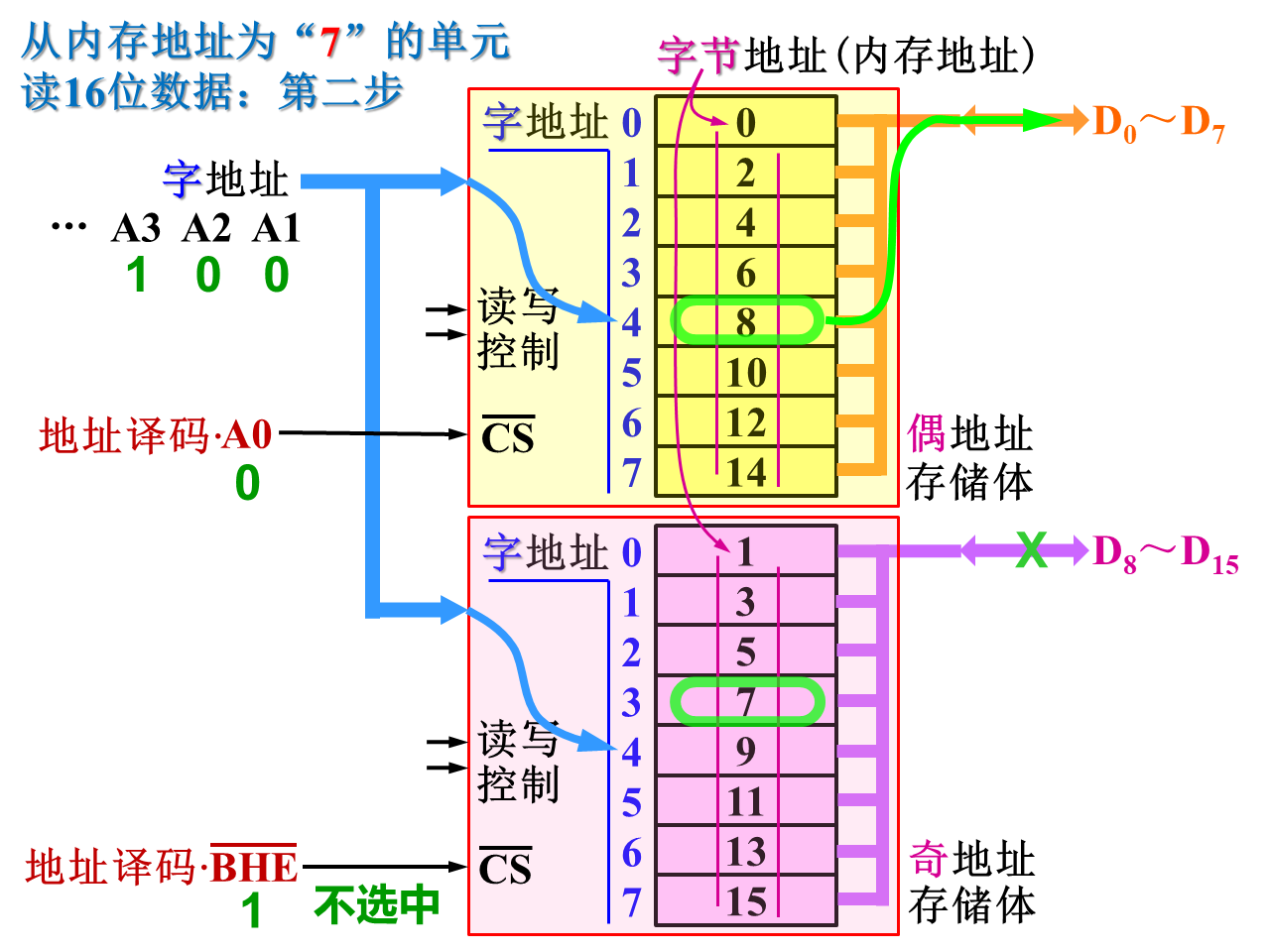
体现了数据对齐的重要性。16位数据在内存中占2个字节,我们就希望在内存里从偶地址开始存放,这样一个总线周期就能完成读写
分段结构方式上面已经多次提到。注意各个分段之间可以重叠
6832H:1280H中6832H是段寄存器的内容,1280H是段内偏移
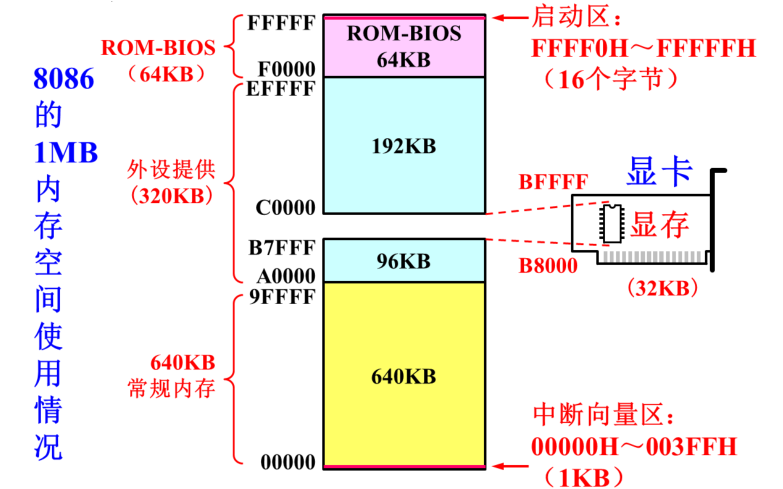
下面再看一些特殊的内存区域:
中断向量区:00000H~003FFH (1KB),每个中断向量占4个字节
显示缓冲区:B0000H~B0F9FH (4000B),B8000H~BFFFFH (32KB)
启动区:FFFF0H~FFFFFH (16B),内为无条件转移指令,使启动时跳转到BIOS程序的起始地址
操作系统装载在常规内存中
显示缓冲区实例不要求
8086芯片引脚:
![]()
1.电源引脚
2.地址、数据线
考虑到不管是访问内存还是访问接口,都是先送地址然后再传数据,Intel 把地址信号和数据信号复用以节省引脚,在设计电路时外面会增加一些辅助芯片来把复用的信号分离出来。即16位的数据和低16位的地址是复用的,高4位地址线和状态信号复用
S6:废用状态,输出一直是低电平
S5:表示当前IF的情况,看该引脚在输出状态时是输出高电平还是低电平可知现在是开中断还是关中断
S3,S4:一共有4种组合,表示现在CPU正在使用哪一个段寄存器
3.时钟、复位
CPU刚一加电之后,里面的内容是随机的,当电源电压稳定之后,在RESET引脚加大于4个时钟周期宽度的正脉冲,就可以把CPU内部的CS置为全1,其他寄存器清0
8086的时钟信号不是方波,高电平持续时间是低电平持续时间的12\frac1221。外部的时钟发生器芯片对一个方波进行三分频
4.中断
NMI:不可屏蔽中断请求输入引脚
INTR:可屏蔽中断请求输入引脚
INTA‾\overline{INTA}INTA:中断应答引脚
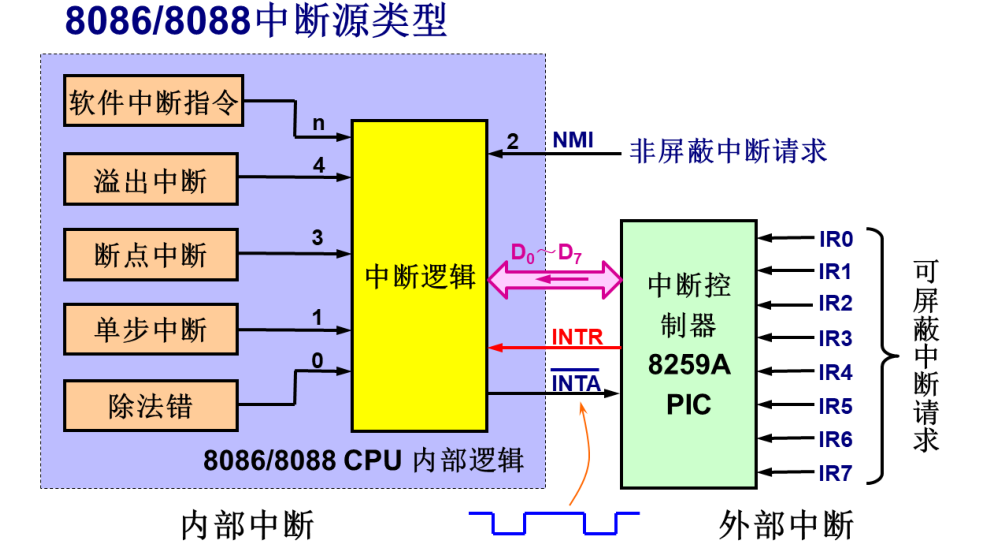
8086/8088 的计算机系统实现中断时需要在外面增加一个可编程中断控制器8259,该芯片可以管理8个中断源,不够用还可以多片级联
x86处理器在管理中断时,每一个中断源都有1个8位二进制编码的编号(中断向量),所以x86处理器最多可以管理256个中断源
有一些中断源的编号是固定的,特别是来自CPU内部的中断源,比如
0号中断对应除法错误(除数为0,结果溢出)
1号中断叫单步中断。调试工具如果把TF置1,那么CPU每执行完一条机器指令之后都会在内部产生一个1号中断,最终进入到单步中断的中断服务程序。那个程序就是调试软件代码的一部分
3号中断叫断点中断,也是调试用的
4号中断叫溢出中断,一些补码加法结果溢出
这些中断究竟是怎么运作的?
比如CPU内部现在产生0号中断,一旦中断产生,CPU马上获取对应中断向量,再根据中断向量查找主存中的中断向量表,读出对应行的前2个字节赋值给IP,后面2个字节赋给CS,这2个寄存器合起来就相当于上学期讲的程序计数器PC,被重新赋值后当然就会跳转到0号中断源对应的中断服务程序执行
注意在赋值前必须要把IP和CS这两个寄存器原来的内容保护在堆栈里,这叫断点保护。响应中断时,需要压入IP,CS,PSW的内容,然后硬件自动把IF置0,再去查中断向量表
中断向量表有256行,行号从0∼\sim∼255,每一行对应某一号中断,占4个字节(前2个字节对应段内偏移,后2个字节是段寄存器的内容),存对应的中断服务程序。表总共1KB,从内存地址0开始存放,在计算机启动的过程中由BIOS程序负责初始化
CPU内部的中断源还有一个,x86处理器的指令集里专门有一条软中断指令INT 21H ,21H是立即数,表示某中断向量。编写16位汇编语言程序时,经常需要调用DOS操作系统的一些功能,DOS操作系统就是利用软中断来给应用程序提供功能调用。上面这条指令在CPU内部一执行就会产生33(=21H)号中断,对应的中断服务程序是DOS操作系统代码的一部分,其目的就是给用户程序提供各种功能调用
以上是CPU内部的中断源,然后再看来自外部的中断请求,涉及到INTR和NMI
为什么这两个一个叫可屏蔽一个叫不可屏蔽?
PSW中有IF,如果通过CLI把IF清0,它实际上就屏蔽来自INTR引脚的中断请求,对其他的没有任何影响,这个引脚的中断请求其实就是来自接口或外设。而NMI不能通过IF屏蔽,通常是非常紧急的中断请求,比如掉电
INTR和NMI还有一个区别,INTR输入高电平有效,NMI输入上升沿有效
INTR通过中断控制器管理来自接口或者外设的好多个中断源,中断控制器通过中断判优决定向CPU发送哪个中断源的中断请求。CPU当前指令执行完,并且处在开中断状态才会去响应中断,通过INTA‾\overline{INTA}INTA发送第一个负脉冲告知中断控制器其正在响应,同时要准备好中断向量。接着发送第二个负脉冲,中断控制器就把中断向量送到低8位的数据总线上传给CPU
5.最小模式/最大模式
24∼\sim∼31号引脚最小模式下是括号里的功能,最大模式下是括号外的功能
工作在最小模式下,所有的控制信号由8086直接产生,不需要再增加其他的外部芯片,电路规模通常较小,并且计算机系统里通常只有8086一个处理器
工作在最大模式下,那些控制信号就不是由这些引脚直接产生的了,需要外面增加一个别的芯片,比如总线控制器8288芯片来产生内存读写,接口读写有关的控制信号。由省出来的一部分引脚可以多一些状态信号和DMA相关的信号,这样整个计算机系统里还可以接更多的主控设备,包括其他的协处理器之类
![]()
BHE‾\overline{BHE}BHE :上面提过
S7:废用状态
TEST‾\overline{TEST}TEST:输入引脚,8086如果正在执行WAIT指令,该指令会判断该引脚的状态,如果是高电平这条指令就一直等待,如果是低电平,这个指令就执行完了。该指令主要用来和数学协处理器8087同步
READY:输入引脚,讲时序时再说
8086在最小模式下的引脚:
![]()
INTA‾\overline{INTA}INTA:上面提过
RD‾,WR‾\overline{RD},\overline{WR}RD,WR:读内存读接口都可以用到,通过M/IO‾M/\overline{IO}M/IO 来区分是访问内存还是接口
ALE:地址锁存。地址信号要么和数据线,要么和状态复用,那怎么知道什么时候输出的是地址呢?
一旦8086正在输出地址,并且地址是稳定的,8086会通过该引脚送来正脉冲。它输出为高电平时,复用的信号正在输出地址
DEN‾\overline{DEN}DEN:输出允许。低电平表示正在传递数据
DT/R‾\overline{R}R:方向控制。高电平表示数据传输的方向是发送(从CPU内到CPU外),低电平表示数据传输的方向是接收
HOLD,HLDA:和DMA有关。DMA控制器如果想直接控制总线实现内存和外设之间的数据传送,就要求8086释放总线的控制权。DMA控制器会首先通过HOLD引脚给8086发高电平,若满足一定条件,8086就通过HLDA告知DMA自己已释放总线控制权
8088和8086的外部引脚的区别在:
1.8088只有低8位地址和数据复用
2.只有一个存储体,不需要BHE‾\overline{BHE}BHE,故34号引脚就是一个基本不用的状态信号
3.28号引脚是IO/M‾IO/\overline{M}IO/M,刚好和8086相反
最后结合时序来讲一下READY引脚,以8088的一个总线周期(总线周期由时钟周期组成)为例:
![]()
上图一个总线周期传了一个数据,花了4个时钟周期的时间。该时序有一个前提条件:内存的速度足够快,让CPU等一个时钟周期(T3周期),内存就能把数据准备好。如果内存比较慢,CPU等一个时钟周期内存还来不及把选中单元的数据取出来放在数据总线上,希望CPU多等几个时钟周期,就要用到READY信号
![]()
T3周期时会判断READY信号的状态,如果为高电平,则T3周期结束之后会直接进入T4周期。如果内存比较慢,则外面要有一个专门的电路,当CPU访问内存时该电路必须要在T3周期之前把READY信号置0来通知CPU多等几个周期,CPU在T3周期开始会采样READY信号,发现是低电平则T3周期结束之后不会进入到T4周期而是插入等待周期TWT_WTW
例题:
8086微处理器主频为5MHZ,在不插入等待周期的情况下,从主存地址80006H读一个8位数据所需要的时间为:
答案:800ns
然后讲了下总线驱动的原理和重要性
8086在最小模式下的系统总线形成:
![]()
8086的引脚数有限,地址信号和其他信号是复用的,外面必须要增加一些电路以保存地址信号,在整个内存或接口读写的过程中地址由外加的电路来提供,这样才能保证在一个总线周期的时间段内地址总是有效的
现在33号引脚接高电平,8086工作在最小模式下
要实现地址和其他信号的分离需要用到锁存器,锁存器有存储功能,可以把在一个总线周期的第一个时钟周期输出的地址保存下来,然后在整个总线周期的时间段内由锁存器来提供地址信号
地址信号一共21根线(20根地址线+BHE‾\overline{BHE}BHE),如果用8位锁存器74LS373,就要3片。锁存器里存的内容希望能一直直接输出,所以输出允许OE‾\overline{OE}OE接地永远有效。锁存器的锁存信号LE由ALE直接提供
在一个总线周期的第一个时钟周期,当输出地址并且地址稳定之后,ALE会输出一个正脉冲
数据线AD0∼AD15AD_{0}\sim AD_{15}AD0∼AD15不存地址的时候就当数据线用,直接引出来就是数据线。如果负载很多,数据线想加驱动器,用74LS245双向驱动器。16位的数据,8位的74LS245要用2片,它有两个控制信号,方向选择DIR接DT/R‾DT/\overline{R}DT/R,输出允许OE‾\overline{OE}OE接DEN‾\overline{DEN}DEN
然后剩下单向的控制信号线,如果想加驱动器用单向的74LS244,输出允许OE1‾,OE2‾\overline{OE_1},\overline{OE_2}OE1,OE2接地令其永远有效。这4个信号经过它驱动之后后面可以带很多的负载
CPU访问内存和接口的时候最好能有各自独立的读写信号,后面还可以加一些电路,借助数电的知识,这个附加电路的功能不难理解
![]()
时钟发生器8284用来产生时钟信号
上图其实不是很严谨。READY信号应该由慢速的内存或者接口电路来产生,复位信号也不是由时钟发生器而是由复位电路来产生,该低电平有效复位信号在8284里反相之后再做为8086的复位信号输入
现在我们就有了地址,数据和控制信号,系统总线就形成了。各自存储器芯片和接口芯片就可以直接连接到这些系统总线上
对8284工作原理的具体功能讲解书上没有
以8088为例,讲了下更具体实际的电路下工作在最小模式下系统总线的形成,不太要求,了解即可
8086在最大模式下的引脚:
![]()
33号引脚接地,8086工作在最大模式下
此时所需要的控制信号,比如内存和接口读写,中断应答信号都没有,所以外面要多加一个总线控制器8288来产生这些信号
S2‾,S1‾,S0‾\overline{S_2},\overline{S_1},\overline{S_0}S2,S1,S0:
8288想从8086知道该产生什么控制信号需要三个状态信号S0,S1,S2,这三根线8种组合分别代表CPU的8种不同状态
![]()
Passive(被动):三根状态线输出111,表示CPU已经释放总线了,它在总线上现在是一个从设备,处于完全被动的状态。现在总线的使用权可能是DMA控制器或者是其他的协处理器
教材的表格里翻译成”无效“
QS0‾,QS1‾\overline{QS0},\overline{QS1}QS0,QS1:四种组合,表示当前指令队列的情况。一般情况下用不到
LOCK‾\overline{LOCK}LOCK:有些时候希望某条指令在执行时不要释放总线,可以在这条指令前加lock前缀。这条指令在执行时该引脚输出低电平,表示现在处于总线封锁状态
RQ‾/GT0‾,RQ‾/GT1‾\overline{RQ}/\overline{GT0},\overline{RQ}/\overline{GT1}RQ/GT0,RQ/GT1:跟最小模式下的HOLD,HLDA功能类似。一个引脚是双向的,既可以当HOLD也可以当HLDA来用。如果DMA控制器想要申请总线的控制权,通过该引脚发一个负脉冲,CPU如果释放总线会通过相同的引脚再往外送一个负脉冲告知DMA控制器
总结一下,最大模式下:
1.可以接更多可以成为总线主控设备的东西,包括DMA控制器,协处理器之类
2.结合8288芯片可以产生更多的控制信号,可以实现更大规模的计算机系统
8086在最大模式下的系统总线形成:
![]()
最大模式下CPU不直接提供ALE,DT/R‾,DEN‾DT/\overline{R},\overline{DEN}DT/R,DEN,这些信号由总线控制器8288产生
注意8288产生的是DEN, 要加反相器
8288芯片产生的控制信号有严格的时序关系,也应有一个时间上的基准,它的时钟信号和CPU用的是同一个。8288本身驱动能力很强,故这些输出的控制信号后面不需要再加驱动,可直接引出作为系统总线的控制信号
以8088为例,讲了下更具体实际的电路下工作在最大模式下系统总线的形成,不太要求,了解即可
Intel 处理器体系结构的发展
基本没讲,就举了个书上没有的宏融合技术的例子
Intel 处理器指令系统及汇编语言
汇编语言基础(一)
为什么要学习汇编语言:
嵌入式系统:在特定硬件下,对程序的大小和运行速度需要高速优化的情况
BIOS程序的设计者,操作系统内核、设备驱动程序的设计者,编译程序、调试工具的设计者、硬件检测/测试/诊断程序的设计者、虚拟机/模拟器的设计者
逆向工程
有助于对计算机硬件、操作系统、应用程序之间交互的整体理解
突破高级语言的局限:高级语言中嵌入汇编
汇编语言格式主要有Intel和AT&T,上课用的Intel格式,编译程序用微软的宏汇编 (MASM)
先以模板程序Hello world为例,大致看下基于8086的16位汇编的整体结构和具体编写方法:
![]()
段名:标识段的名字,唯一的或已存在的,可以随便起
对齐方式:可以是BYTE、WORD、DWORD、PARA(16B对齐,不写默认)、PAGE(256B对齐)
组合方式:可以是PRIVATE(不写默认)、PUBIC、MEMORY,STACK、COMMON、AT地址。定义堆栈段时通常写STACK,告诉编译程序这个段当堆栈来处理

堆栈段定义了一个100B的空间。db伪指令表示现在要申请以字节为单位的数据块,字节数为100。后面跟dup关键字和一个括号,如果这100B都想初始化为0,括号里就填0,括号里填 ? 编译之后这100B仍然被初始化为0
伪指令编译之后不会产生机器指令,它就是给编译程序一些信息
数据段定义了一个字符串,message就是一个用符号表示的内存地址,本质上就是段内偏移,指向所定义的数据的起始位置,这样在程序中引用字符串就不用直接引用逻辑地址。字符串以字节为单位,还是用db定义。0dh和0ah分别是回车符和换行符,‘$’ 是字符串的结束标识
assume伪指令并不能实现对CS,DS,SS三个段寄存器的赋值。有些代码需要算地址,比如 mov dx,offset message,offset操作符取message地址的16位段内偏移,而编译程序需要知道默认的段寄存器DS对应的是你自己定义的哪个段才能算段内偏移。assume伪指令告诉编译程序编译后面代码时要认为此时CS,DS,SS已分别指向了你自己定义的代码段,数据段,堆栈段
第一条指令必须要给它一个标号,整个程序总的结尾END伪指令跟这个标号,以指明主程序的入口点
接下来初始化数据段寄存器,引用段名把data段起始地址的高16位传送到通用寄存器AX,再传送到DS。这样DS就真正指向了你自己定义的数据段
代码段寄存器和堆栈段寄存器不需要程序初始化,由操作系统负责初始化。操作系统把数据段指向了别的位置,这个寄存器必须要由程序来初始化
data,offset message经过编译之后实际上是立即数7和0,以后再解释
接下来3条指令调用DOS操作系统的功能,负责把定义的字符串显示到屏幕上
DOS操作系统通过 int 21h 软中断指令来给应用程序提供功能调用,执行这条指令之前必须要把功能号放在AH。9号功能就是往屏幕上显示一条字符串,要求段寄存器DS和存段内偏移的DX共同指向要显示的字符串的起始位置。故offset操作符取message地址的16位段内偏移传送到DX寄存器,再执行软中断指令显示字符串
不加offset操作符传送的是内容而不是地址
最后调用DOS操作系统 int 21h 的4C号功能结束当前进程,回收其占用的内存空间
以后编写汇编语言程序时就可以参考这个模板来写
;1) 完整段定义的程序结构STACK SEGMENT PARA STACK 'STACK'DB 500 DUP(0)
STACK ENDS
DATA SEGMENT.......
DATA ENDS
CODE SEGMENTASSUME CS:CODE,DS:DATA,ES:DATA,SS:STACK
START:MOV AX,DATAMOV DS,AX.......MOV AH,4CHINT 21H
CODE ENDSEND START
MASM的高版本还支持简化段定义的写法
;2) 简化段定义的程序结构.MODEL SMALL ;存储模型:小型,16位汇编
.STACK 100H ;定义堆栈段及其大小
.DATA ;定义数据段
....... ;数据声明
.CODE ;定义代码段START: ;起始执行地址标号MOV AX,@DATA ;数据段地址MOV DS,AX ;存入数据段寄存器....... ;具体程序代码MOV AH,4CH INT 21HEND START ;程序结束
然后现场演示运行了下Hello world程序
编译、链接和运行程序
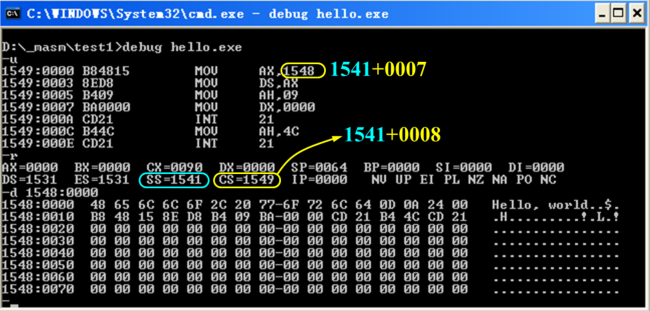
用UltraEdit软件打开Hellp.exe,对其结构进行了简单的分析
![]()
![]()
注意x86处理器数据采用小端存储
用二进制查看软件打开可执行文件Hello.exe。后半部分和源程序内容有对应关系,前半部分是DOS操作系统下可执行文件的文件头,有一些固定的格式,如微软的操作系统下可执行文件的一个标志就是前两个字节固定为"4D 5A"
文件头是编译程序生成的,会记录DOS操作系统在执行该可执行文件之前这些寄存器的初值怎么设置。操作系统从磁盘把这个可执行文件往内存装时,会分析利用文件头的一些信息,分析完之后可能就会丢弃文件头。编译程序用的地址是逻辑地址,它总认为地址是从0开始的,所以他会认为你定义的堆栈段是从地址0开始的,相对应的代码段就从0080开始,段的起始地址高16位是0008,故CS的初值应为0008。程序的入口点就是代码段的第一条指令,段内偏移是0,故IP的初值是0000。堆栈段从逻辑地址0开始,故SS的初值应为0。SP的初值为0064,跟x86处理器对堆栈的管理方式有关系
x86处理器栈顶是小地址,栈底是大地址。16位模式下堆栈里的每个数据必须都是16位,占2个字节2个地址。该程序定义堆栈时申请了100B的堆栈空间,逻辑地址从0开始。x86处理器SP永远指向栈顶上的有用元素,程序刚开始运行堆栈是空的,SP指向逻辑地址100 (64h)
文件头记录了堆栈段和代码段寄存器的初值,但没有记录数据段寄存器的初值。DOS操作系统装载可执行文件之后,DS另作他用,指向用于记录命令行参数的数据结构程序段前缀PSP,故数据段寄存器得由代码段里的指令初始化,令其指向自己所定义的数据段
![]()
将代码段编译之后产生的这些机器码用反汇编工具转化成汇编语言的形式。代码段的前3个字节对应的是MOV AX,7,把立即数7传送到AX。目标寄存器AX16位,故立即数7也用2字节16位来存储,编译的机器码3个字节后2个字节存储立即数7,第1个字节存的是该指令的操作码还有AX寄存器的3位编号。后面的也类似
把反汇编的结果跟源代码比较,可以发现mov ax,data中定义的数据段名称编译后变成立即数7,对应数据段起始地址的高16位。这条语句经过编译程序编译后产生的机器指令是把立即数7传送到AX。类似的还有mov dx,offset message
操作系统不可能把这个程序从内存地址0开始装,操作系统从磁盘把该可执行文件读出来之后会检查足够大的内存空闲区域装入,装完后这些段寄存器应该怎么赋初值呢?
比如说堆栈段寄存器,它首先查文件头,文件头里规定的初值为0,在0的基础上再加上起始的地址的段寄存器的内容,初始化代码段寄存器也类似。数据段寄存器的初值文件头里并没有规定,操作系统在装载这个程序到内存,起始地址确定之后需要修改代码段。文件头中有重定位项,该程序只有1个重定位项,这2个字节相当于指针,指向文件头的另外一个位置,从该位置开始的2个16位字分别代表段内偏移和段起始地址的高16位,它们共同指向代码段中需要重定位的地方
8086的内存管理引入分段机制,第一个目的是为了扩大可寻址的范围,第二个目的是能够实现程序在内存的任意位置浮动,一个程序在内存里任何一个地址开始装,只需要重新初始化段寄存器的内容
然后验证了一下可执行文件的具体格式
接下来再看32位的Hello world汇编程序,没有用到通用寄存器,只是2个函数调用
32位应该是不要求的,但是后面讲课时涉及的比较多,所以这里简单记一下
.386 ;告诉编译程序要产生32位的机器指令
.model flat,stdcall
;定义内存模型,如果这段程序要运行在Windows操作系统下,必须用flat平坦型。平坦的内存模型理解成只分页不分段
;函数调用参数传递的顺序置为stdcall,通过堆栈向函数传递参数;利用Windows给应用程序提供的2个函数(子程序),这2个函数在代码里并没有,用之前需要声明原型,比如函数的名称,函数的参数和参数类型
;DOS操作系统通过软中断给应用程序提供功能调用,Windows通过函数API的形式给应用程序提供功能调用MessageBoxA PROTO, ; 汇编里用PROTO伪指令声明函数原型 hWnd:DWORD, ; 句柄,指向该窗口所属的父窗口,没有父窗口该参数给0lpText:PTR BYTE, ; 指针,指向一个要在窗口内部显示的字符串lpCaption:PTR BYTE ; 指针,指向一个要显示在窗口标题栏上的字符串style:DWORD ; 调用时给0,显示一个最简单的窗口,只有确定按钮ExitProcess PROTO,exitCode:DWORD ; 如果程序正常结束,给参数0.data
szCaption db 'A MessageBox !',0
szText db 'Hello, World !',0
.code
;4个压栈指令传参分别对应style,lpCaption,lpText,hwnd
start: push 0 ; MB_OKpush offset szCaption push offset szTextpush 0 ; NULLcall MessageBoxA ; 显示一个窗口push 0call ExitProcess ; 结束当前进程
end start
然后看了一下该程序编译、链接、运行的过程
Intel微处理器的组成结构
部分32位x86处理器的内部寄存器
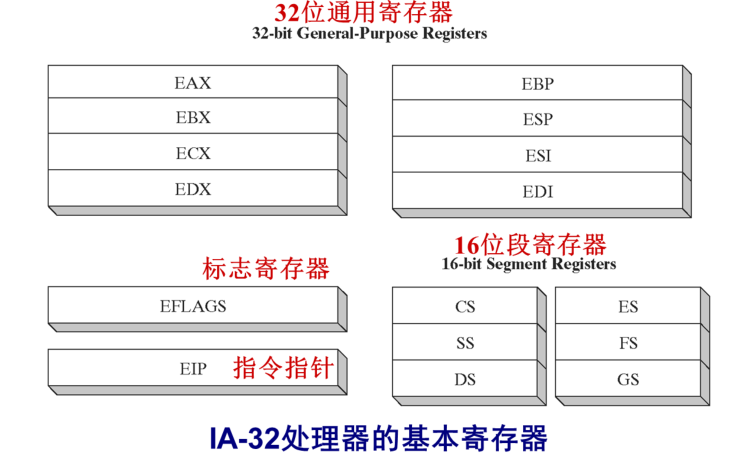
增加的段寄存器FS和GS也是用来访问数据的,访问数据时默认的段寄存器仍是DS。32位汇编里普通应用程序没有权限修改段寄存器的内容,所以也不用太关心
通用寄存器主要用于算术运算和数据传送
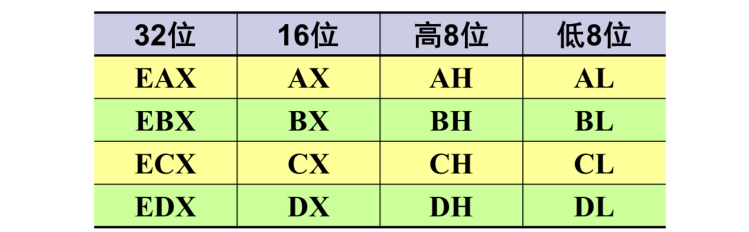
每个寄存器可作32位或16位使用。一些16位的寄存器也可以作为两个单独的8位使用,其余通用寄存器的低16位有独立的名字,但不能进一步细分
EAX, EBX, ECX, EDX : 高16位不能单独使用,低16位可以单独使用,目的是为了和8086兼容
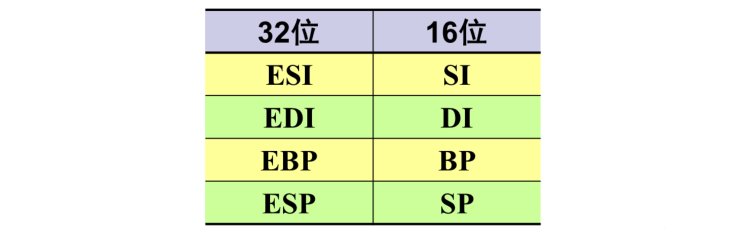
ESI, EDI, EBP, ESP : 下面列出的16位寄存器通常只在编写运行于实地址模式下的程序时才使用,即编写32位汇编,必须得用32位。编写16位汇编,必须得用16位
汇编语言基础(二)
汇编语言的基本元素
1.算术运算符号
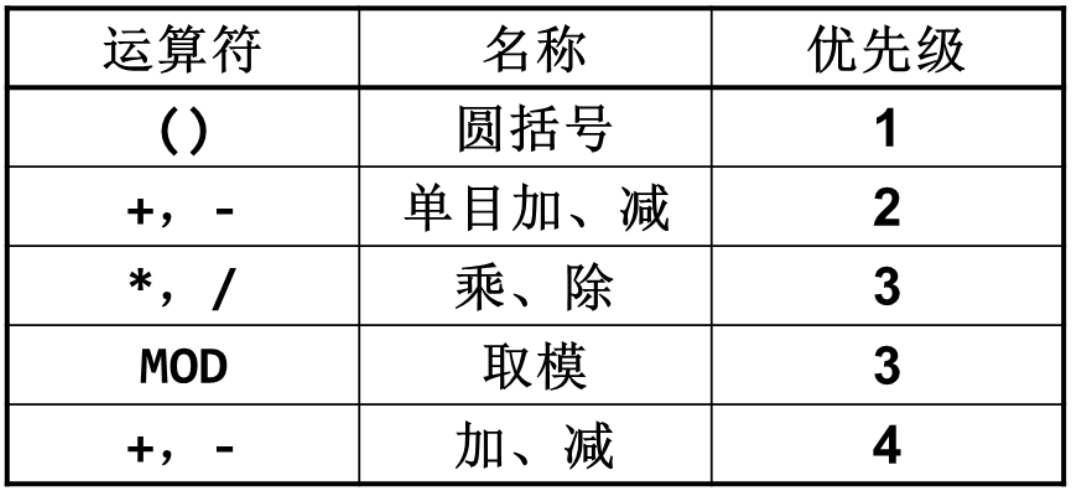
汇编语言里面的表达式最终得到的就是一个立即数。如mov AL 15/5*2,这条语句编译之后并不会产生除法指令和乘法指令,编译程序会计算表达式,产生机器指令把立即数6传送到AL寄存器
2.标识符
程序员选择的名字,用来识别变量、常量、过程或代码标号
这个标识符本质上就是一个用符号表示的内存地址
- 可包含1~247个字符
- 大小写不敏感。(汇编器加“
-cp”参数则大小写敏感) - 第一个字符必须是字母(A~Z和a~z)、下划线(_)、@、? 或 $,后续字符可以是数字
- 不能与保留字相同
- 尽量避免用 “@” 和 “_” 作为第一个字符,因为它们即用于汇编器,也用于高级语言编译器
3.指令
程序被加载至内存开始运行后,由处理器执行的语句
![]()
4.定义数据
![]()

.data
value1 BYTE 10h
value2 BYTE ?
list1 BYTE 10,20,30,40BYTE 50,60,70,80
list2 BYTE 32,41h,00100010b,'a'
greeting BYTE "Good afternoon",0dh,0ah,0
array WORD 5 DUP(?) ;五个未初始化的值
value3 DWORD 12345678h
PTR操作符
Intel处理器采用小端存储方式
.data
myDouble DWORD 12345678h
.code
mov ax,myDouble ;错误
mov ax,WORD PTR myDouble ;ax = 5678h
mov ax,WORD PTR [myDouble+2] ;ax = 1234h
mov bl,BYTE PTR myDouble ;bl = 78h

5.符号常量
不是变量,不占用任何实际的存储空间。常量的定义语句编译之后不会产生任何机器指令,也不会产生任何数据
等号伪指令
COUNT = 500 ;给编译程序传达一个信息,告诉它后面不想直接写500,用COUNT来代替 .data ...... array WORD COUNT DUP(0) ...... .code......mov cx,COUNT ;产生的机器指令把500立即数传送到cx寄存器 L1: ............loop L1......EQU伪指令
TEXTEQU伪指令
;计算数组和字符串的大小
list1 BYTE 10,20,30,40
List1Size = ($-list1) ;数组元素所占的字节数。微软的宏汇编语法中,'$'代表当前语句的地址myString BYTE "This is a long string,"BYTE " Containing any number"BYTE " of characters",0dh,0ah
MyString_len = ($ - myString) ;字符串占的字节数,也就是字符串里字符的个数list2 WORD 1000h,2000h,3000h,4000h ;注意数组元素的类型是WORD,16位占2个字节2个地址
List2Size = ($ - list2)/2
数据传送、寻址和算术运算
数据传送指令
1.MOV指令
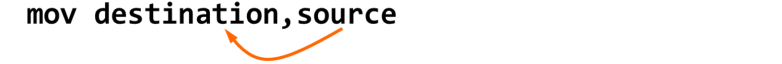
MOV指令需要遵循的规则:
两个操作数的尺寸必须一致
.DATA VAR1 WORD 30 VAR2 WORD 50 .CODE......MOV AL,VAR1 ;×MOV DX,AL ;×两个操作数不能同时为内存操作数,要通过一个通用寄存器作为中介
MOV VAR2 VAR1 ;×目的操作数不能是CS,EIP和IP,想改这几个寄存器的内容另有专门的指令
立即数不能直接送至段寄存器
MOV DS,7 ;× MOV DS,@DATA ;×,编译之后产生的是一个立即数
MOV指令格式:
mov reg,reg
mov mem,reg
mov reg,mem
mov mem,imm
mov reg,imm
reg --> 寄存器,mem --> 内存变量,imm --> 立即数
x86处理器其他的两个操作数指令,其实就是支持类似这几种格式
内存之间的移动通过寄存器暂存
.data
var1 WORD ?
var2 WORD ?
.code
mov ax,var1
mov var2,ax
2.XCHG指令
含义:exchange data,交换两个操作数的内容
格式:
xchg reg,reg
xchg reg,mem
xchg mem,reg
交换两个内存操作数:利用寄存器,MOV与XCHG结合使用
mov ax,val1
xchg ax,val2
mov val1 ax
RISC结构的处理器没有这样的指令,要实现xchg ax,bx这样两个寄存器之间的交换,可以有好几种方法:
;方法一:用另外一个寄存器作为中介
mov cx,ax
mov ax,bx
mov bx,cx;方法二:通过堆栈
push ax
mov ax,bx
pop bx;方法三:用异或指令
xor ax,bx
xor bx,ax
xor ax,bx
直接偏移操作数(直接寻址)
MOV AL 7 ;把立即数7传送到AL寄存器
这条指令源操作数是立即数,立即寻址。目的操作数写的是寄存器的助记符,经过编译之后产生的机器指令里面存的是这个寄存器的编号,寄存器寻址
要访问的数据在内存里面,指令中直接给出内存地址,这样叫直接寻址。我们在写汇编程序时想直接寻址,后面直接给内存地址太不直观,还得数究竟它放的逻辑地址是什么,这本来是可以交给编译程序来做的。所以在定义数据段里那些变量的时候要给变量起名字,用这个名字来表示内存地址,这本质上也属于直接寻址
变量、数组、字符串、子程序的名字在本质上来讲都是一个用符号来表示的内存地址
.data
arrayB BYTE 10h,20h,30h,40h,50h
;arrayB这个符号本质上来讲就是数组的首地址(逻辑地址),或者说数组第0个元素的地址
.code
mov al,arrayB ; AL=10h
;在代码段里直接引用这个符号地址,它指向数组的第0个元素,把第0个元素传送到AL寄存器,属于直接寻址mov al,[arrayB+1] ; AL=20h
;第一个元素。编译程序完成首地址+偏移量的加法,结果就是一个逻辑地址,仍属于直接寻址
;MASM并不要求一定要使用方括号
mov al,[arrayB+2] ; AL=30hmov al,[arrayB+20] ; AL=??
;汇编语言不管是编译程序还是执行时,DOS操作系统都不会做数组的越界检查
;字和双字数组
.data
arrayW WORD 100h,200h,300h
.code
mov ax,arrayW ; AX=100h
mov ax,[arrayW+2] ; AX=200h 字占2个字节2个地址,数组首地址基础上+2指向数组第一个元素.data
arrayD DWORD 10000h,20000h
.code
mov eax,arrayD ; EAX=10000h
mov eax,[arrayD+4] ; EAX=20000h 双字32位占4个字节4个地址
常用的算术运算类指令
1.ADD指令
将同尺寸的源操作数和目的操作数相加,结果在目的操作数中(不改变源操作数)
格式:同MOV指令,add 目的操作数 源操作数
.data
var1 DWORD 10000h
var2 DWORD 20000h
.code
mov eax,var1
add eax,var2 ;30000h
2.SUB指令
将源操作数从目的操作数中减掉,结果在目的操作数中(不改变源操作数)
格式:与MOV、ADD指令相同,sub 目的操作数 源操作数
.data
var1 DWORD 30000h
var2 DWORD 10000h
.code
mov eax,var1
sub eax,var2 ;20000h
影响的标志位:CF、ZF、SF、OF、AF、PF
3.NEG指令
含义:negate, 求负
该指令认为操作数为一个有符号数,是补码。将操作数按位取反、末位加1
格式:
neg reg
meg mem
影响的标志位:CF、ZF、SF、OF、AF、PF
;例子:实现算术表达式 Rval = -Xval + (Yval-Zval).data
Rval SDWORD ?
;微软宏汇编高版本新引入的变量类型SDWORD,有符号的32位整数,理解成32位补码
Xval SDWORD 26
Yval SDWORD 30
Zval SDWORD 40
.code
mov eax,Xval
neg eax ; EAX = -26
mov ebx,Yval
sub ebx,Zval ; EBX = -10
add eax,ebx
mov Rval,eax ; -36
算术运算影响的标志
1.零标志位
mov cx,1
sub cx,1 ; ZF = 1
mov ax,0FFFFh ; 全1理解成补码,真值就是-1
inc ax ; ZF = 1
inc ax ; ZF = 0
2.符号标志位
mov cx,0
sub cx,1 ; SF = 1
add cx,2 ; SF = 0
3.进位标志位
INC和DEC指令不影响进位标志
mov al,0FFh
add al,1 ; CF = 1mov ax,00FFh
add ax,1 ; CF = 0mov ax,0FFFFh
add ax,1 ; CF = 1mov al,1
sub al,2 ; CF = 1。最高位向更高位有进位或借位时置1
4.溢出标志位
OF=Cn⊕Cn−1OF=C_n\oplus C_{n-1}OF=Cn⊕Cn−1。其中CnC_nCn为符号位产生的进位,即标志位CFCFCF;Cn−1C_{n-1}Cn−1为最高有效位向符号位产生的进位
mov al,+127
add al,1 ; OF = 1mov al,-128
sub al,1 ; OF = 1mov al,-128 ; AL = 10000000b
neg al ; AL = 10000000b, OF = 1mov al,+127 ; AL = 01111111b
neg al ; AL = 10000001b, OF = 1。
CPU如何知道一个数字是有符号的还是无符号的?
CPU并不知道——只有程序员才知道。CPU在执行指令之后机械地设置各种状态标志,它并不知道那些对程序员是重要的,程序员自己来选择哪些标志和忽略哪些标志
;例子程序(AddSub3).386
.MODEL flat, stdcall
.STACK 4096
ExitProcess PROTO,dwExitCode:DWORD
;PROTO伪指令左侧跟函数的名字,右侧是函数的参数和参数类型.data
Rval SDWORD ?
Xval SDWORD 26
Yval SDWORD 30
Zval SDWORD 40
.code
main PROC ;"主程序的名称 PROC"开始,"相同的名称 ENDP"作为结尾;主程序的名称可以随便起,本质是一个用符号表示的内存地址,它所定义的就是这个代码段 ;的第一条指令的地址,是程序的入口点mov ax,1000h ; INC and DECinc ax ; 1001hdec ax ; 1000h; Expression: Rval = -Xval + (Yval - Zval)mov eax,Xvalneg eax ; EAX = -26mov ebx,Yval sub ebx,Zval ; EBX = -10add eax,ebxmov Rval,eax ; -36; Zero flag example:mov cx,1sub cx,1 ; ZF = 1mov ax,0FFFFh inc ax ; ZF = 1; Sign flag example:mov cx,0sub cx,1 ; SF = 1mov ax,7FFFh add ax,2 ; SF = 1; Carry flag examplemov al,0FFhadd al,1 ; CF = 1, AL = 00; Overflow flag examplemov al,+127 add al,1 ; OF = 1mov al,-128sub al,1 ; OF = 1INVOKE ExitProcess,0 ;32位的汇编最后都要调用操作系统结束当前进程的函数,该函数调用前要声明原型;引入INVOKE伪指令使带参数的函数在调用的时候可以一行写完,后面跟函数名和参数main ENDP
END main
然后用Visual Studio演示了一下运行该程序
间接寻址
1.间接操作数(寄存器间接寻址)
把指针寄存器外加中括号。它其实就是一个指针,指向内存的某一个位置
;32位汇编:三个双字相加.data
arrayD DWORD 10000h,20000h,30000h
.code
mov esi,OFFSET arrayD
;OFFSET操作符取数组的首地址传送到指针寄存器,引用数组名,数组名本质上是数组的首地址;指针寄存器里存的是32位的段内偏移,默认的段寄存器仍然是数据段寄存器DS,DS里存的是段表的行号,该指令执行时会根据DS的内容查段表对应的行,从该行得到段的起始地址。段的起始地址加指针寄存器的段内偏移,结果就是内存地址,然后访问内存中的数组元素;代码段并没有初始化数据段寄存器,在32位保护模式下只有最高特权级的代码,如操作系统内核才有权限修改段寄存器的内容,普通的应用程序运行在最低特权级3下没有权限修改段寄存器的内容的;16位的汇编段寄存器要由程序自己管理mov eax,[esi]
;寄存器间接寻址,访问数组的第0个元素add esi,4
;数组元素32位占4个字节,指针+4指向数组的第1个元素
add eax,[esi]
add esi,4
add eax,[esi]
;16位汇编:三个字相加.data
arrayW WORD 1000h,2000h,3000h
.code
mov ax,@data
mov ds,ax
;初始化数据段寄存器mov si,OFFSET arrayW
;OFFSET操作符取数组首地址,或者叫16位的段内偏移传送到指针寄存器mov ax,[si]
;默认的段寄存器还是数据段寄存器,把数据段寄存器的内容段起始地址的高16位读出,末尾添4个0构成20位的段起始地址,再加上指针寄存器里的16位段内偏移,结果为20位的内存地址。访问内存刚好对应数组的第0个元素,从这个地址开始连续传送2个字节至AXadd si,2
add ax,[si]
add si,2
add ax,[si]
间接操作数可以是任何用方括号括起来的32位通用寄存器(EAX,EBX,ECX,EDX,ESI,EDI,EBP,ESP)。实地址模式下只能用SI,DI,BX,BP。通常尽量避免使用BP(BP默认的段寄存器是SS,常用来寻址堆栈而不是数据段)
PTR与间接操作数的联合使用
inc [esi]
; error: operand must have size. +1指令只有一个操作数,并且还是一个指针,指向一个内存位置,不知道存的是8位还是16位,32位inc BYTE PTR [esi] ; 认为是8位数据
2.变址操作数(寄存器相对寻址)
.data
arrayB BYTE 10h,20h,30h
.code
mov esi,0 ; 要访问的数组元素编号作为偏移量放在指针寄存器
mov al,[arrayB + esi] ; AL = 10h
mov al,arrayB[esi] ; 同上另一种格式
mov esi,OFFSET arrayB
mov al,[esi] ; AL = 10h
mov al,[esi+1] ; AL = 20h
mov al,[esi+2] ; AL = 30h
实模式下只能使用SI,DI,BX,BP寄存器。(尽量避免使用BP寄存器)
JMP和LOOP指令
1.JMP指令
top:...jmp top ;repeat the endless loop
2.LOOP指令
格式:LOOP 目的地址
LOOP指令的执行:
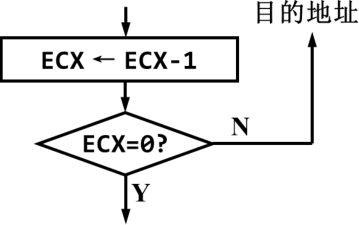
在实地址模式下,用做默认循环计数器的是CX而不是ECX
mov ax,0mov ecx,5
L1: inc ax loop L1 ;循环体的第一条指令必须要给标号。循环体的最后一条指令要用loop,后面跟这个标号;循环结束时,AX=5 ECX=0
循环的嵌套
.data
count DWORD ?
.codemov ecx,100
L1: push ecx ; 将循环计数器的内容,即外层循环的当前次数保存mov ecx,20 ; 重新设置循环计数器的内容
L2: ..loop L2pop ecx ; 恢复循环计数器原来的内容 loop L1
;例子:整数数组求和; This program sums an array of words. (SumArray.asm)
.386
.MODEL flat, stdcall
.STACK 4096
ExitProcess PROTO,dwExitCode:DWORD
.data
intarray WORD 100h,200h,300h,400h
.code
main PROCmov edi,OFFSET intarray ; address of intarraymov ecx,LENGTHOF intarray ; loop countermov ax,0 ; zero the accumulator
L1: add ax,[edi] ; add an integeradd edi,TYPE intarray ; point to next integerloop L1 ; repeat until ECX = 0INVOKE ExitProcess,0
main ENDP
END main
;例子:拷贝字符串; This program copies a string. (Copystr.asm)
.386
.MODEL flat, stdcall
.STACK 4096
ExitProcess PROTO,dwExitCode:DWORD
.data
source BYTE "This is the source string",0
target BYTE SIZEOF source DUP(0)
.code
main PROCmov esi,0 ; index registermov esi,SIZEOF source ; loop counter
L1: mov al,source[esi] ; get a character from sourcetarget[esi],al ; store it in the targetinc esi ; move to next characterloop L1 ; repeat for entire stringINVOKE ExitProcess,0
main ENDP
END main
然后用Visual Studio演示了一下运行该程序
过程
与外部库链接
链接库如何工作?
假设程序要调用名为WriteString的过程在控制台上显示字符串,这个函数在另外一个库里,并没有在源代码文件中,则:
1.程序中要用PROTO伪指令声明要调用的程序
例:Irvine32.inc 中包含如下语句
WriteString PROTO
2.用一条CALL指令执行WriteString过程
call WriteString
3.当程序被编译时,编译器知道操作码但不知道地址码,因为这个函数的代码不在当前文件中,它为CALL指令的目标地址留出空白,该空白将由链接器在链接时填充
4.链接器在链接库中查找WriteString这个名字,从库中提取函数代码,跟编译产生的目标文件链接到一起形成可执行文件,链接到一起之后这个函数的首地址逻辑地址才知道,再由链接器负责把WriteString的首地址填到CALL指令留的空白的位置
链接器的命令行选项
之前32位汇编的例子里结束当前程序要调用操作系统的函数,那个函数在kernel32.lib库文件中
例:
Link32 HelloWin.obj user32.lib kernel32.lib/subsystem:windows

Windows下同一时刻可能有多个程序在运行,免不了要调用各种各样Windows提供的函数,包括结束当前进程的函数,几乎所有程序都要调用,每个程序里都会有很多这种重复的函数可执行代码,实际上是没有必要的,也浪费内存空间
所以实际在Windows系统里,这些库文件里存的所谓的这些函数的代码其实就是函数的链接而不是函数真正的代码,可以理解成库文件里跟那个函数所对应的代码就是个跳转指令,跳转指令执行后才会真正地跳转到那个函数的代码去执行。那个函数的代码包含在kernel32.dll动态链接库文件中,重复的函数代码在动态链接库,在内存里只有一个副本
过程的定义和使用
1.过程的定义
子程序定义一般的结构:用PROC和ENDP伪指令来声明,另外还必须给过程起一个名字(一个有效的标识符),中间写代码,代码的最后一条指令必须得写ret子程序返回指令
写主程序的时候也可以用相同的结构来写,主程序的结束如果是16位的汇编,通常调用DOS操作系统的4C号功能并且给操作系统返回0表示程序正常结束
如果是32位的汇编主程序结束一般结合INVOKE伪指令。INVOKE伪指令是微软宏汇编6.0以上引入的,引入的目的就是为了带参数的函数在调用的时候可以一行写完,后面跟函数名和参数,多个参数用 ‘,’ 隔开
具体到这个例子,这条语句编译之后会产生2条机器指令,首先会产生压栈指令,把参数0压入堆栈,然后再产生call指令调用子程序
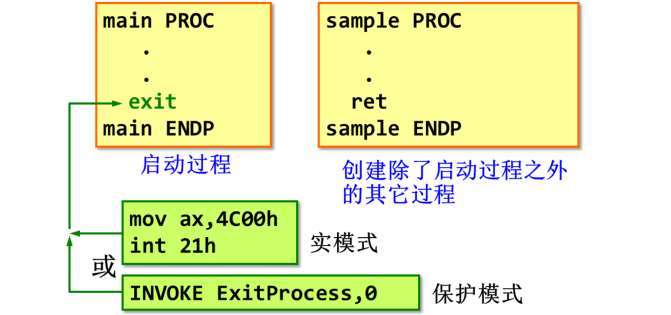
2.例子:三个整数之和
SumOf PROCadd eax,ebxadd eax,ecxret
SumOf ENDP
3.为过程添加文档
;-------------------------------------------------------------------
SumOf PROC
;
;Calculates and returns the sum of three 32-bit integers.
;Receivers: EAX, EBX, ECX, the three integers. May be
; signed or unsigned
;Returns: EAX = sum, and the status flags (Carry,
; Overflow, etc.) are changed.
;-------------------------------------------------------------------add eax,ebxadd eax,ecxret
SumOf ENDP
4.向过程传递寄存器参数
.data
theSum DWORD ?
.code
main PROCmov eax,10000h ; argumentmov ebx,20000h ; argumentmov ecx,30000h ; argumentcall Sumof ; EAX=(EAX+EBX+ECX)mov theSum,eax ; save the sum
例子:对整数数组求和
; ArraySum 过程:;-------------------------------------------------------------------
ArraySum PROC
;
; Calculates the sum of an array of 32-bit integers
; Receives: ESI points to the array, ECX = array size
; Returns: EAX = sum of the array elements
;-------------------------------------------------------------------push esi ; save ESI, ECXpush ecxmov eax,0 ; set the sum to zero
L1:add eax,[esi] ; add each integer to sumadd esi,4 ; point to next integerloop L1 ; repeat for array sizepop ecx ; restore ECX, ESIpop esiret ; sum is in EAX
ArraySum ENDP
; 调用 ArraySum.data
array DWORD 10000h,20000h,30000h,40000h,50000h
theSum DWORD ?
.code
main PROC mov esi,OFFSET array ; ESI points to arraymov ecx,LENGTHOF array ; ECX = array countcall ArraySum ; calculate the summov theSum,eax ; return in EAX......

LEA DX,mess2和MOV DX,OFFSET mess2功能上等价,直接引用变量的名字,取该变量的地址而不是内容到DX寄存器。段内偏移放在DX寄存器,而段寄存器主程序已初始化好了
整个程序总的结尾用END跟这个程序的入口点,入口点应该是主程序的名字,本质上是主程序的第一条指令的地址。由于汇编语言用这种方式指明程序的入口点,所以写的时候也可以把子程序写在前面,主程序写在后面
运行一下这个16位程序。在32位Windows下新建文本文件,后缀名改成.asm,打开把代码粘贴进去。保存完之后再用最原始的方法在命令行方式下先后输入编译命令和链接命令,再输入产生的可执行文件名字运行
![]()
会发现和想象的不太一样,程序好像是个循环程序,循环到后面报错了,程序被操作系统强行关闭。为什么会这样?
![]()
问题出在子程序里面用压栈指令保护现场,但是返回之前没有出栈指令恢复现场,即返回指令之前少写了POP DX
CALL指令执行的时候CPU首先会保护当前的断点,把当前PC的内容压入堆栈,8086的PC对应两个寄存器CS和IP。这个程序CALL指令和RET指令默认都属于静调用和静返回,静调用和静返回只需要保护IP,段寄存器的内容不需要保护,调用返回都是在同一个段里面。所以CALL指令执行时会首先把当前IP的内容压入堆栈,它往堆栈里压的这个地址应该是CALL指令顺序的下一条指令的地址,再跳转到子程序执行。子程序又会把DX原来的内容压入堆栈,子程序返回指令会从堆栈段栈顶弹出数据到PC,对8086就是弹到IP,少写POP指令会导致把一个错的数弹到IP
OFFSET操作符取第一个字符串的首地址传送到DX,第一个字符串是数据段里最开始定义的字符串,在它之前没有任何东西,所以它的段内偏移应为0,DX的内容就是0。所以子程序执行到返回指令时,它会从堆栈里把0弹出赋值给IP。代码段寄存器内容不变,但是段内偏移变为0,就会从主程序的第一条指令开始执行,所以会不停地来回循环,在屏幕上不停地显示那两条字符串
而且每调用一次子程序都在堆栈里留了一个数没有弹出,栈只申请了256B的空间,增长到一定程度就会导致栈溢出,最终堆栈里的数据会覆盖代码段里的的指令,CPU再取指令译码发现是非法指令就产生中断让操作系统强行中止程序
条件处理
布尔和比较指令
1.AND指令
功能:在操作数的对应数据位之间执行布尔(位)”与“操作,并将结果保存在目的操作数中
格式:AND 目的操作数 源操作数
允许的操作数形式:
AND reg,reg
AND reg,mem
AND mem,reg
AND reg,imm
AND mem,imm
两个操作数可以是8、16或32位的,但它们的尺寸必须相同
影响的标志位:
- 总是清除OF和CF
- 根据结果修改SF、ZF、PF
主要用途:
对特定的位清”0“,同时保留其他的位
mov al,00111011b mov al,00001111b
大写字母与小写字母的ASCII码之间的关系:
‘a’:61h,即 01100001
‘A’:41h,即 01000001
;例:将字符转换为大写形式.data array BYTE 50 DUP(?) .codemov ecx,LENGTHOF arraymov esi,OFFSET array L1:and byte ptr [esi],11011111binc esiloop L1
2.OR指令
功能:按位取”或“
格式:与AND指令相同
主要用途:
对特定的位置置”1“,并保留其它位
mov al,00111011b or al,00001111b
例:将0到9之间的整数转换成对应的ASCII码数字
方法:将位4和位5置为1
mov dl,5 ; 二进制值 or dl,30h ; 转换到ASCII码
要调用操作系统的功能在屏幕上显示必须得以ASCII码的形式
也可以用
add dl,30h或add dl,'0'
3.XOR指令
功能:按位取”异或“
格式:与AND及OR指令相同
XOR指令的用途:
对某些位取反,同时不影响其他的位
0跟一个数异或还是那个数,1跟一个数异或就是那个数的取反
判断16位或32位值的奇偶性
mov ax,64C1h ; 0110 0100 1100 0001 xor ah,al ; PE,奇偶标志被设置奇偶标识位只反映运算结果低8位里1的个数是否是偶数个
简单数据加密
将某个操作数与同样的操作数执行两次异或运算后,其值保持不变
(X⊕Y)⊕Y=X(X\oplus Y)\oplus Y=X (X⊕Y)⊕Y=X
4.NOT指令
功能:将操作数所有数据位取反,结果为反码
格式:
NOT reg
NOT mem
例:
mov al,11110000b
not al ; AL = 00001111b
NOT指令不影响任何状态标志
布尔和比较指令
1.TEST指令
功能:两操作数按位“与”,根据结果设置标志位,但不回送结果(不修改目的操作数)
格式:与AND指令相同
用途:测试操作数的某一位是“0”还是“1”
例子:测试多个位
想知道AL中第0位、第3位是否同时为“0”
test al,00001001b ;test bits 0 and 3
判断ZF是否等于1
影响的标志:清除OF、CF;修改SF、ZF、PF
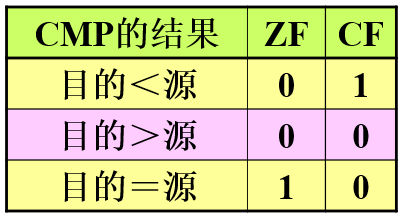
2.CMP指令
格式:与AND指令相同。cmp 目的操作数 源操作数
功能:与减法指令一样执行减法操作,即目的操作数-源操作数,但不回送结果,只影响标志位
影响的标志:根据相减结果修改OF、SF、ZF、CF、AF、PF
无符号操作数的比较:
有符号操作数的比较:
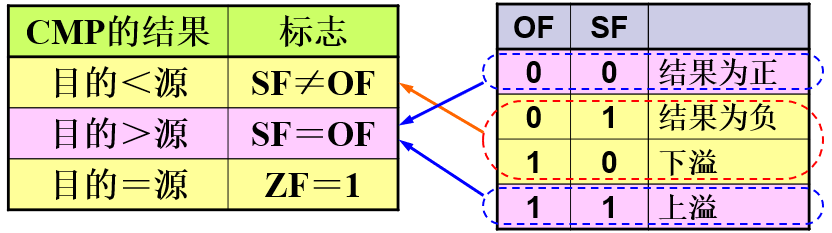
例:
mov ax,5
cmp ax,10 ; CF = 1mov si,105
cmp si,0 ; ZF=0,CF=0mov ax,1000
mov cx,1000
cmp cx,ax ; ZF = 1
条件跳转
1.条件结构
条件分支的实现:
- 使用CMP、TEST、AND之类的指令修改CPU标志
- 使用条件跳转指令测试标志值,以决定是否向新的分支转移
例子:
cmp al,0jz L1 ;jump if ZF=1..
L1:
and dl,10110000bjnz L2 ;jump if ZF=0..
L2:
2.跳转指令的类型
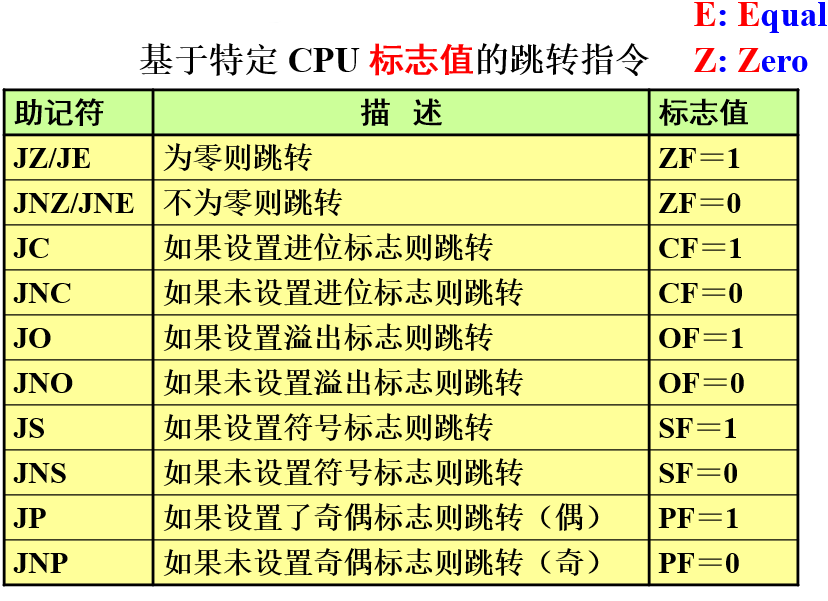
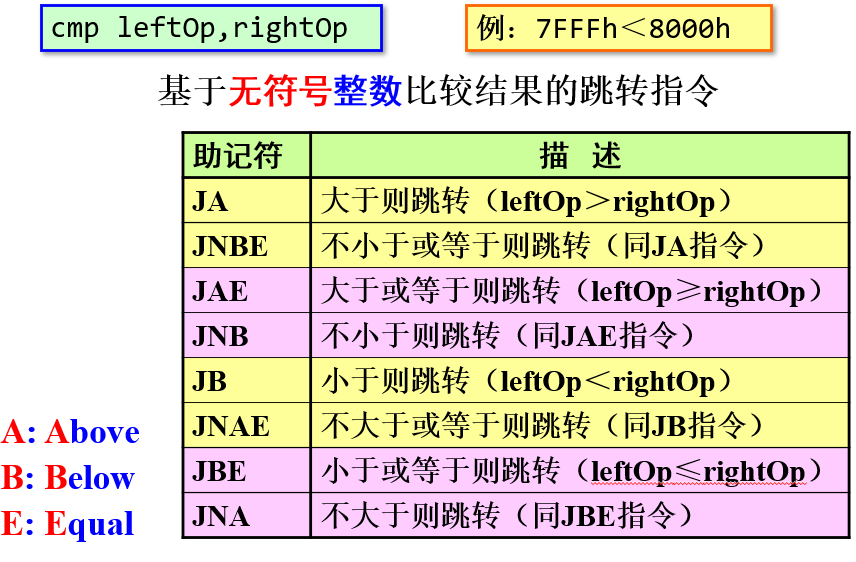
mov al,7Fh ; (7Fh or +127)
cmp al,80h ; (80h or -128)
ja IsAbove ; no: 7F not > 80h
jg IsGreater ; yes: +127 > -128
例:8位内存操作数status中存放着同接口卡相连的外设的状态信息
1.bit5为“1”时外设处于脱机状态,跳转到某标号处
mov al,status
test al.00100000b
jnz EquipOffline
2.bit0、bit1、bit4任何一位为“1”时跳转到某标号处
mov al,status
test al,00010011b
jnz InputDataByte
3.bit2、bit3、bit7全部为“1”时跳转到某标号处
mov al,status
and al,10001100b
cmp al,10001100b
jz ResetMachine
例:比较V1、V2、V3三个无符号变量的值,将最小值送入AX寄存器
.data
V1 WORD 23
V2 WORD 0
V3 WORD -1
.codemov ax,V1 ;assume V1 is smallestcmp ax,V2 ;if ax <= V2 thenjbe L1 ; jump to L1mov ax,V2 ;else move V2 to ax
L1: cmp ax,V3 ;if ax <= V3 thenjbe L2 ; jump to L2mov ax,V3 ;else move V3 to ax
L2: ......
然后推荐了https://godbolt.org,可以直接输入C语言代码,即时查看反汇编结果
整数算数指令
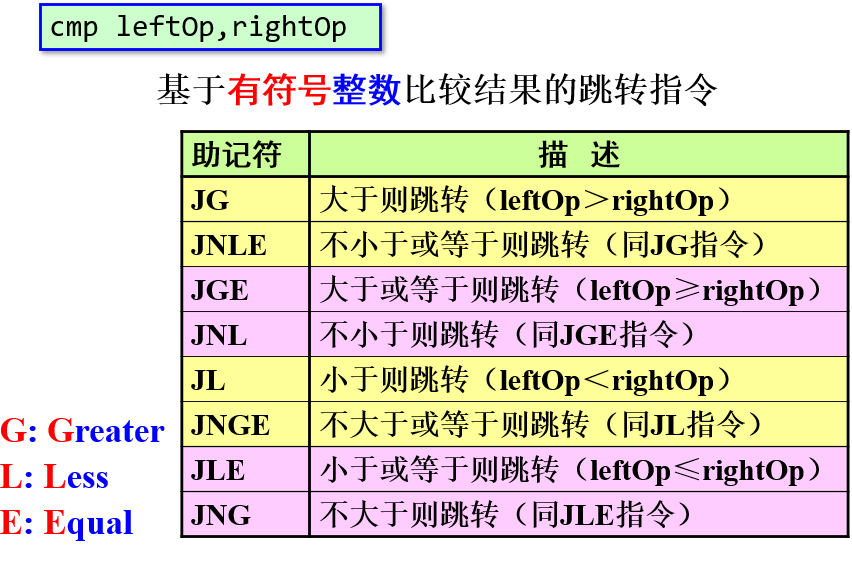
移位 (Shifting) 指令:
记住以下单词:Shift, Left, Right, Arithmetic, Rotate, Carry
SHL 逻辑左移
SHR 逻辑右移
SAL 算术左移
SAR 算术右移
ROL 循环左移
ROR 循环右移
RCL 带进位的循环左移
RCR 带进位的循环右移
上述移位指令影响OF、CF
1.SHL指令:逻辑左移

格式:SHL 目的操作数 移位位数
SHL reg,imm8
SHL mem,imm8
SHL reg,CL
SHL mem,CL
8088/8086要求imm8必须等于1。80286以上,imm8可为任意整数
CL方式可用于任何Intel x86处理器
上述格式也适用于SHR、SAL、SAR、ROR、ROL、RCR、RCL指令
源操作数可以是立即数,如果是8088/8086,立即数只能是1。如果想左移多位,得把移位的次数先放到CL寄存器
例:无符号数与2的整数次幂做快速乘法
mov dl,5
shl dl,1 ;5*2 = 10
mob dl,10
shl dl,2 ;10*4 = 40
2.SAL指令:算术左移,与SHL指令等价
3.SHR指令:逻辑右移,最高位总是填0

格式:与SHL相同
例:无符号数与2的整数次幂做快速除法
mov dl,32
shr dl,1 ;32/2 = 16
mov dl,01000000b ;AL = 64
shr dl,3 ;64/8 = 8
4.SAR指令:算术右移,最高位填充原来的符号位

例1:
mov al,0F0h ; AL = 11110000b (-16)
sar al,1 ; AL = 11111000b (-8); CF = 0
例2:有符号数的除法,-128/8=-16
mov dl,-128 ; DL = 10000000b
sar dl,3 ; DL = 11110000b
5.ROL指令:循环左移

特点:不丢失任何数据位
例1:
mov al,40h ;01000000
rol al,1 ;10000000, CF=0
rol al,1 ;00000001, CF=1
rol al,1 ;00000010, CF=0
例2:将一个字节的低4位与高4位进行交换
mov al,26h
rol al,4 ;AL = 62h
6.ROR指令:循环右移

例:
mov al,01h ;00000001
ror al,1 ;10000000, CF=1
ror al,1 ;01000000, CF=0
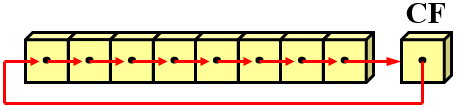
7.RCL和RCR
RCL指令:带进位的循环左移
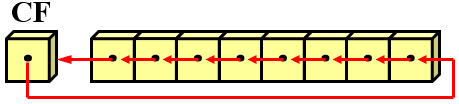
RCR指令:带进位的循环右移
移位和循环移位的应用:
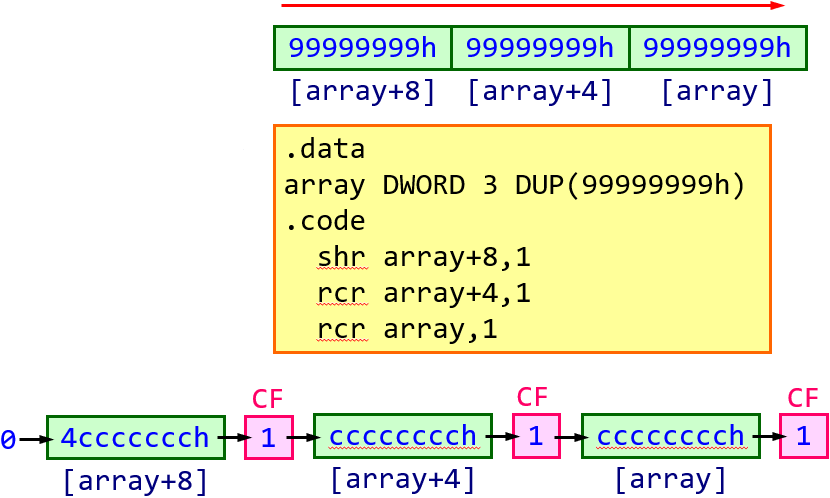
多双字移位
在数据段里定义3个元素的数组,数组元素的类型是32位双字,这3个元素连到一块组成96位的数,小地址对应低位数据,大地址对应高位数据。希望将其整体逻辑右移1位
移位时从高位开始移。逻辑右移最高位永远填0,最低位移走到CF。中间的数再移位就可以把刚才高位移走的数从CF再移到这个数里面去
二进制乘法:利用移位、相加实现
显示二进制位
分离位串
例:MS-DOS的功能57h在DX中返回文件的修改时间,假设为2019年3月10日,则DX中的文件日期戳如下(年份是相对于1980年的):

提取月可以将这个数整体地逻辑右移5位,然后再用AND指令将高12位清0只保留低4位
乘法和除法指令
1.MUL指令
格式(操作数为乘数):操作数可以是寄存器也可以是内存变量,但不能是立即数。只跟一个操作数,另外一个操作数是隐含的或者说默认的
MUL r/m8
MUL r/m16
MUL r/m32
功能:无符号乘法。将8位、16位或32位的操作数与AL、AX或EAX相乘
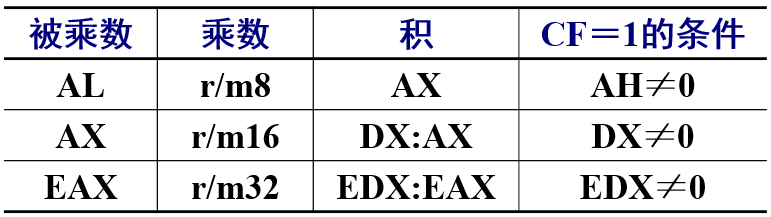
乘数和被乘数位数必须相等。两个8位数相乘运算结果用16位表示,两个16位数相乘结果是32位,高16位在DX,低16位在AX。32位数相乘同理
作为高级语言来讲,32位变量做各种运算后运算结果也会存到一个32位变量里面,但这实际上有溢出的可能,用汇编语言来写可以更完备。两个8位数相乘,运算结果用8位表示不了,CF会置1。16位数和32位数相乘同理
例:
mov al,5h
mov bl,10h
mul bl ; CF = 0
; 积在AX中,50h
.data
val1 WORD 2000h
val2 WORD 0100h
.code
mov ax,val1
mul val2 ; CF = 1
; 积在DX:AX中,00200000h
2.IMUL指令
有符号乘法,格式与MUL指令相同。认为被乘数和乘数都是补码,乘的结果也会用补码来表示
如果积的高半部分不是低半部分的符号扩展,置CF和OF
例:
mov al,48 ; 48D = 30H
mov bl,4
imul bl ; AX = 00C0h, OF = 1mov al,-4
mov bl,4
imul bl ; AX = FFF0h, OF = 0mov ax,48
mov bx,4
imul bx ; DX:AX = 000000C0h, OF = 0
3.DIV指令
无符号除法
格式(操作数为除法):
DIV r/m8
DIV r/m16
DIV r/m32
功能:执行8位、16位、32位无符号整数除法运算

除数是8位,被除数必须是16位,商跟余数也得是8位。除数是16位和32位同理
例:
; 8003h/100h
mov dx,0 ; clear dividend, high
mov ax,8003h ; dividend, low
mov cx,100h ; divisor
div cx ; AX = 0080h, DX = 0003h
.data
dividend QWORD 0000000800300020h
divisor DWORD 00000100h
.code
mov edx,DWORD PTR dividend + 4 ; high doubleword
mov eax,DWORD PTR dividend ; low doubleword
div divisor ; EAX = 08003000h, EDX = 00000020h
除法运算指令可能溢出,乘法两个n位数相乘运算结果用2n位表示肯定不会溢出。如:
mov Ax,1000H
mov BL,10H
DIV BL
结果商为100H,用8位寄存器AL无法表示,除法溢出在CPU内内部产生0号中断
有符号数的除法运算指令为IDIV,下面几个具体的例子会说到
例1:以汇编语言实现下面的C++语句(使用32位无符号整数):
var4 = (var1 + var2) * var3;
mov eax,var1add eax,var2mul var3 ; EAX = EAX * var3jc tooBig ; unsigned overflow?mov var4,eaxjmp next
tooBig: ; display error message
例2:使用32位有符号整数实现下面C++语句:
var4 = (var1 * -5) / (-var2 % var3);
mov eax,var2 ; begin right side
neg eax
;有符号数,需将被除数符号扩展到EDX,然后用IDIV指令
cdq ; sign-extend dividend
idiv var3 ; EDX = remainder
mov ebx,edx ; EBX = right sidemov eax,-5 ; begin left side
imul var1 ; EDX:EAX = left sideidiv ebx ; final division
mov var4,eax ; quotient
cdq 把EAX的最高位符号位扩展到EDX,x86还专门设计了类似的指令
cbw : 把AL寄存器里存的8位补码扩展到16位,存到AX
cwd : 把AX寄存器里存的6位补码扩展到32位。高16位存在DX,低16位存在AX
扩展加法和减法
思考:用C++如何实现两个128位整数相加?
1.ADC:带进位加
目的操作数+源操作数+进位标志→\to→目的操作数
ADC reg,reg
ADC mem,reg
ADC reg,mem
ADC mem,imm
ADC reg,imm
2.SBB:带进位减
目的操作数-源操作数-进位标志→\to→目的操作数
利用上述指令可方便地实现任意大小数字的减加法运算
高级过程
高级语言如C语言的编译器把参数传递给子程序需要借助堆栈,子程序如何把参数从堆栈里取出来?
堆栈框架
内存模式:.MODEL伪指令
例:
.MODEL flat,stdcall
保护模式程序使用平坦内存模式
STDCALL关键字:指定过程按照从右往左的顺序压入参数。例:
INVOKE ADDTwo,5,6
将生成如下汇编语言代码:
push 6
push 5
call AddTwo
堆栈参数的显式访问:
.data
sum DWORD ?
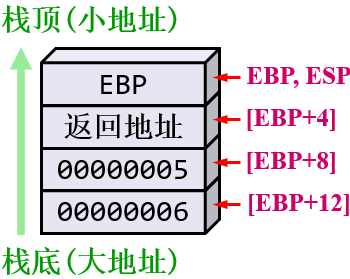
.codepush 6 ; second argumentpush 5 ; first argumentcall AddTwo ; EAX = summov sum,eax ; save the sum......
AddTwo PROCpush ebp mov ebp,esp ; base of stack frame;把ESP的内容赋值给EBP,这样EBP和ESP同时指向当前栈顶的位置。如果后面子程序里还有;PUSH,POP这样对堆栈的操作只会影响ESP的内容,但EBP一旦赋值之后,在整个子程序范围;内就不会再修改mov eax,[ebp + 12] ; second argumentadd eax,[ebp + 8] ; first argumentpop ebpret 8 ; clean up the stack;首先从堆栈中弹出栈顶元素至指令指针寄存器,然后把ESP的内容加上8,相当于把2个参数占;用的堆栈空间也释放了
AddTwo ENDP
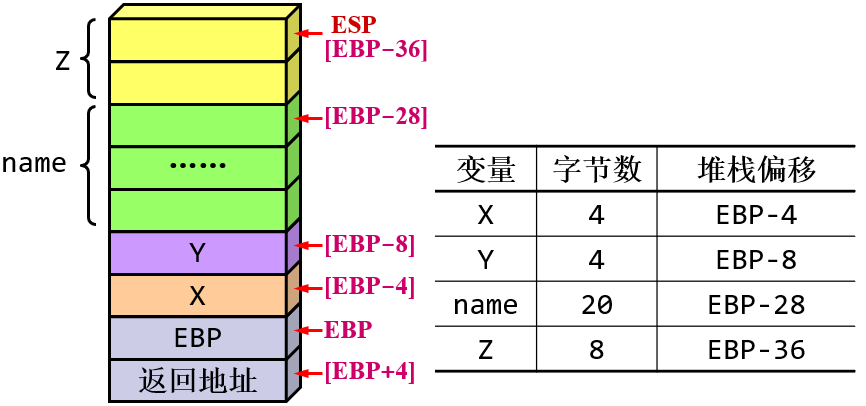
子程序中定义的这些临时变量存储在堆栈中。在操作系统的角度来讲,我们在C语言里写的这个主程序也是子程序,所以主程序里定义的这些变量其实也是临时变量,也存储在堆栈中。这种情况下堆栈应该如何管理?
在主程序之外定义的变量不在堆栈中
创建局部变量:
C++例子
void MySub()
{char X = 'X';int Y = 10;char name[20];name[0] = 'B';double Z = 1.2;
}
访问这些变量都通过EBP相对寻址
为了对齐,尽管第一个变量X是8位数据,但实际上在堆栈里也会占用4个字节
用汇编语言实现
MySub PROCpush ebpmov ebp,espsub esp,36; create variablesmov BYTE PTR [ebp-4],'X' ; Xmov DWORD PTR [ebp-8],10 ; Ymov BYTE PTR [ebp-28],'B' ; name[0]mov DWORD PTR [ebp-32],3ff33333h ; Z(high)mov DWORD PTR [ebp-36],33333333h ; Z(low)…… ……mov esp,ebp ; destroy variablespop ebpret
MySub ENDP
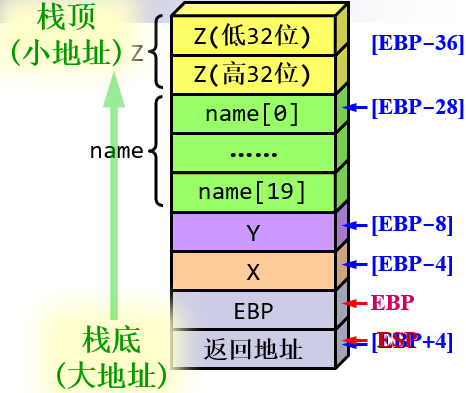
z采用IEEE754标准存储
讲了下缓冲区溢出攻击,并解释了在https://godbolt.org中查看该例子时存在的一些不同
字符串和数组
基本字符串操作指令
5组处理字节、字和双字数组的指令,成为基本字符串指令,但用法并不限于处理字符串数组
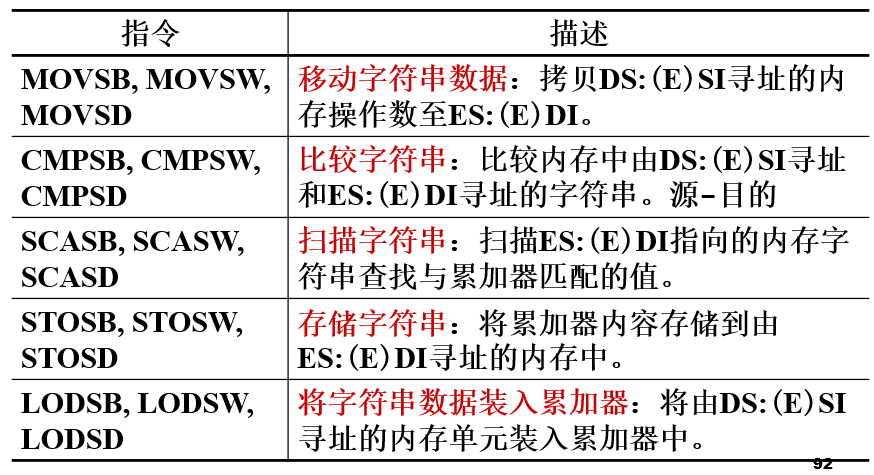
MOV : 数据传送类 S : 串操作指令 B, W, D : 数组元素的类型是字节,字,双字
使用重复前缀
例:
main PROCmov ax,@data ;get addr of data segmov ds,ax ;initialize DSmov es,ax ;initialize ES
cld ; clear direction flag
mov si,OFFSET string1 ; SI points to source
mov di,OFFSET string2 ; DI points to target
mov cx,10 ; set counter to 10
rep movsb ; move 10 bytes
对于串操作指令。段寄存器必须用DS,指针寄存器必须用SI,这两个寄存器指向源数组/源串。ES和DI指向目的数组/目的串
加了重复前缀rep后,这条指令会重复执行好多次,重复次数要放在CX/ECX。指令每执行一次首先会把CX/ECX的内容减1,如果不为0则重复执行这条指令。串操作指令从DS和SI指向的位置读一个字节的数据然后把它写入到ES和DI指向的位置。写完了之后SI和DI的内容加还是减由方向标志位DF决定,DF=0则ESI、EDI自动增加,DF=1则ESI、EDI自动减少。加减多少取决于数组元素类型
数组元素的类型是字节,并且里面存的是ASCII码,那就是字符串
方向标志可以通过CLD和STD指令改变:
CLD ; 清除方向标志
STD ; 设置方向标志
二维数组
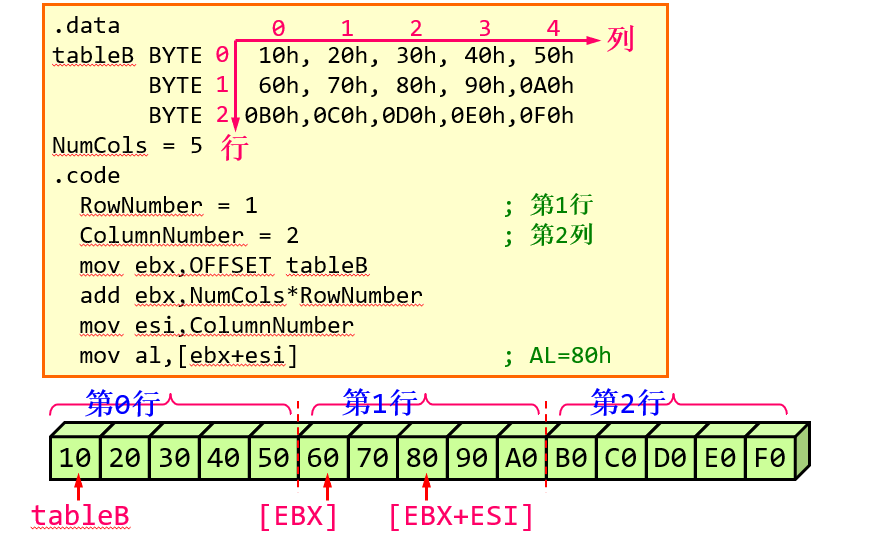
1.基址变址操作数(基址+变址寻址)
基址变址 (base-index) 操作数:将两个寄存器的值相加(称为基址寄存器、变址寄存器)来产生偏移地址
保护模式程序中,可使用任意32位通用寄存器
实地址模式下,基址寄存器访问数据段最好用BX(也可以用BP,但是BP一般是用来访问堆栈的,它的段寄存器默认是SS)。变址寄存器可以用SI和DI
.data
array WORD 1000h,2000h,3000h
.codemov ebx,OFFSET arraymov esi,2 mov ax,[ebx+esi] ; AX = 2000h
表格的例子:
2.相对基址变址操作数(基址+变址+相对寻址)
相对基址变址操作数:有效地址偏移=偏移+基址寄存器+变址寄存器
几种常见的格式:[base + index + displacement], displacement[base + index], displacement[base][index]
偏移 (displacement) : 变量的名字;常量表达式
基址、变址:保护模式为任意32位寄存器,实地址模式为BX、BP和SI、DI
表格的例子:

结构和宏
宏 (Macro)
命名的汇编语句块。调用宏的时候,汇编语句块的一份拷贝被直接插入到程序中
在程序代码里要重复使用几条指令,来来回回多次的写会比较麻烦,就可以用宏来代替这几条指令。在代码里多次引用宏,编译程序编译到宏后会展开,用实际参数代替它的形式参数
宏的定义
macroname MACRO parameter-1,parameter-2...statement-list
ENDM
例1:
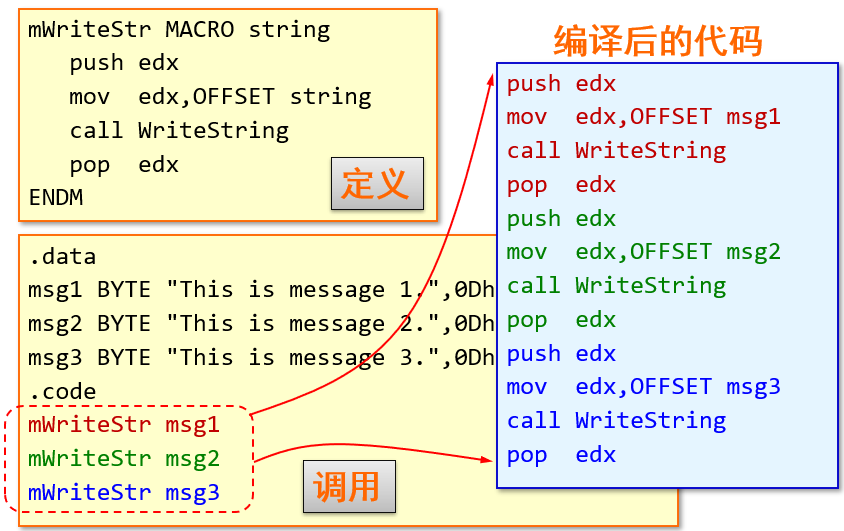
使用I/O端口控制硬件
x86属于独立编址,要访问接口地址空间只能用IN指令和OUT指令。不管是8086还是32位、64位的CPU,接口地址都是16位的,端口地址范围为0∼\sim∼FFFFh
IN和OUT指令
IN指令:从端口输入一个字节、字或双字
OUT指令:向端口输出一个字节、字或双字
指令格式:

端口地址:0∼\sim∼FFh之间的一个常量(立即数),或是包含0∼\sim∼FFFFh之间的值的DX寄存器
累加器:AL、AX或EAX
in al,3Ch ; input byte from port 003Ch
out 3Ch,al ; output byte to port 003Ch
mov dx,2A3Ch ; DX can contain a port number
in ax,dx ; input word from port named in DX
out dx,ax ; output word to the same port
in eax,dx ; input doubleword from port
out dx,eax ; output doubleword to same port
然后讲解了PC声音程序和实时钟RTC两个例子,并现场演示了一下
32位/64位处理器扩展指令——多媒体/流媒体SIMD扩展指令集
多媒体扩展 (MMX) 指令集
SIMD : 单指令多数据 Single Instruction Multiple Data
Pentium Ⅱ : 引入MMX (Multiple Media Extensions) 指令集,实现64位并行处理。引入8个64位MMX寄存器mm0∼\sim∼mm7
Pentium Ⅲ : 引入SSE (Streaming SIMD Extensions) 指令集,实现128位并行浮点运算。引入8个128位MMX寄存器xmm0∼\sim∼xmm7
Pentium 4 : 引入SSE2指令集,实现128位并行定点运算
如果要处理的是32位数据,一个XXM寄存器可以存储4个这样的数据,1条SSE2指令可以同时处理4对操作数得到4个结果,这就是所谓的单指令流多数据流
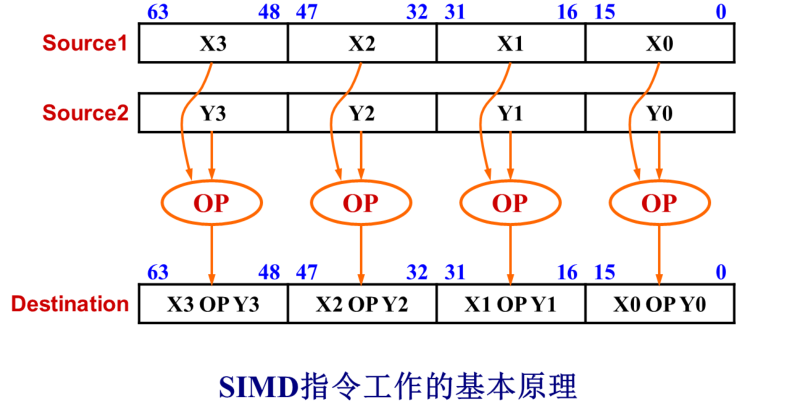
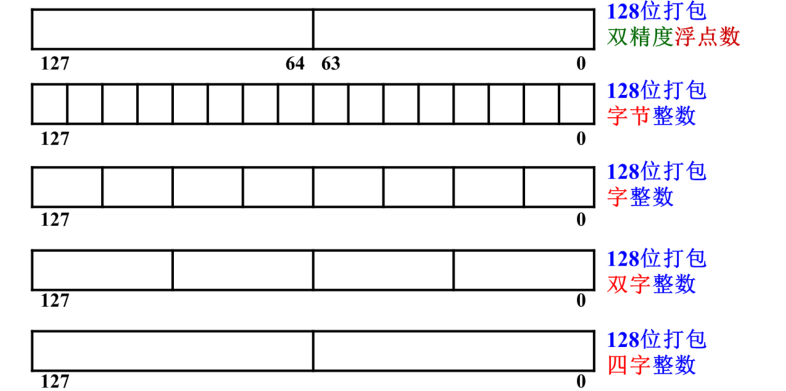
SSE2指令集
SSE2数据类型
一个XXM寄存器可以存放4个单精度浮点数、2个双精度浮点数、16个8位整数、8个16位整数、4个32位整数、2个64位整数。SSE和SSE2指令的操作数就是XXM寄存器,因此可以实现单指令流多数据流,具有高并行度
汇编语言与高级语言的接口
在C语言中嵌入汇编语言代码
1.嵌入方法
//“__asm” 关键字//单句格式
main()
{__asm MOV AH,2;__asm MOV BH,0;__asm MOV DL,20;__asm MOV DH,10;
}//模块格式
main()
{__asm {MOV AH,2;MOV BH,0;MOV DL,20;MOV DH,10; }
}
在Visual C++中使用嵌入汇编的规定:
在用汇编编写的函数中,不必保存EAX、EBX、ECX、EDX、ESI、EDI寄存器,但必须保存函数中使用的其他寄存器(如ESP、EBP、PSW等)
嵌入式汇编语言语句中,可以使用汇编语言格式表示整数常量(如378H),也可以采用C++的格式(如0x378)
嵌入式汇编中的标号和C++的标号相似,作用范围是在定义它的函数中有效
2.程序举例
例3:使用SSE2指令优化程序运行速度
已知矢量A=(a0,a1,...,aN−1)(a_0,a_1,...,a_{N-1})(a0,a1,...,aN−1)和矢量B=(b0,b1,...,bN−1)(b_0,b_1,...,b_{N-1})(b0,b1,...,bN−1),两个矢量的点乘定义为:A⋅B=∑i=0N−1aibiA\cdot B=\sum_{i=0}^{N-1}a_ib_iA⋅B=∑i=0N−1aibi
编写采用SSE2指令实现求两个矢量的点积的程序。设N=8N=8N=8,矢量分量类型为字
采用SSE2指令中的PMADDWD(教材P83,表3.5)完成矢量的分类乘运算和部分和,然后利用移位运算一次求出最终结果
程序源代码:

为了测试代码运行时间,使用了标准C提供的CLOCK函数,该函数的原型和有关数据类型的声明在 time.h 头文件中。程序结尾希望调用操作系统的相关功能让程序暂停,按任意键继续,因此需要包含 Window.h 头文件。用CLOCK函数测量时间,精度只能达到毫秒级,因此定义常量N让被测试代码执行2亿次
主程序中,start, stop变量记录时间,其数据类型在time.h头文件中定义。变量X存储两个向量点积的最终结果。i, j用于循环计数。两个数组每个8个元素,元素的数据类型为16位短整型,用一个128位的XXM寄存器可以存储整个数组。然后显示数组A和数组B的内容
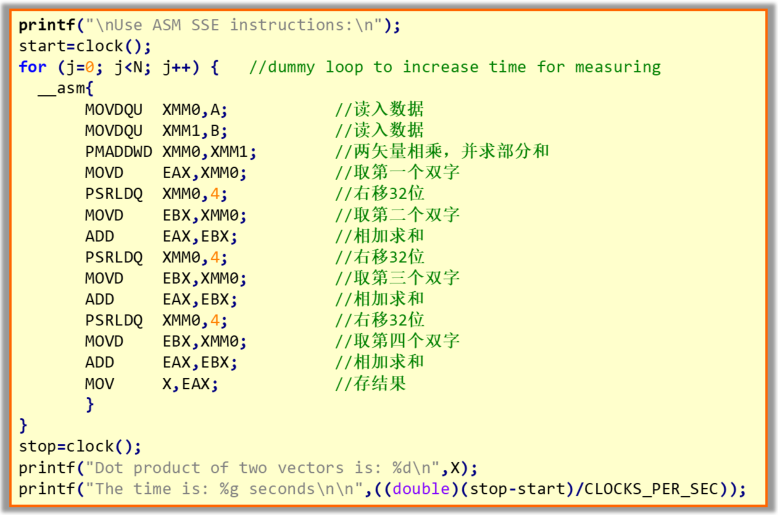
调用CLOCK函数记录开始时间
然后令求向量点积的代码重复执行2亿次。两个下划线跟asm关键字,大括号括起来的部分是汇编语言的代码,这里大部分指令属于SSE2指令集
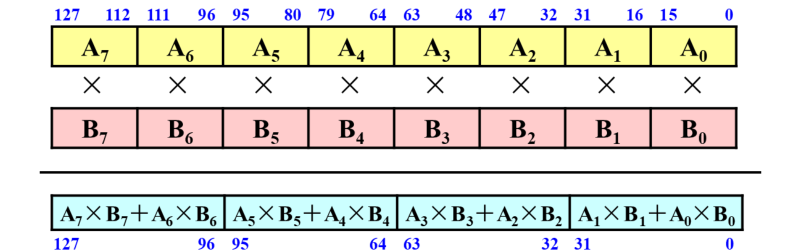
分别取数组A和数组B的所有元素装载至128位的XXM0和XXM1寄存器。PMADDWD乘法 - 累计指令的两个操作数都是两个128位的寄存器,也就是刚刚装载的A和B两个数组。这条指令的功能是两个128位的XXM寄存器中相同位置的16位有符号整数相乘,相邻的两个乘积再求和。8对操作数经过一定的运算后得到4个结果。后面只需把这4个结果再求累加和即为2个向量的点积
将运算结果寄存器的低32位也就是4个结果中的一个传送至EAX,再右移4个字节取第二个结果传送至EBX。普通加法指令执行后EAX的内容为2个结果之和。右移32位,取第三个结果至EBX,再加到EAX中。右移32位,取第4个结果至EBX,再加到EAX中。此时EAX的内容即为两个向量的点积,最终结果存入内存的X单元
调用CLOCK函数记录结束时间
显示点积结果和代码运行2亿次的时间(结束时间-开始时间除以1000,时间单位为秒)
以下部分则是用C语言实现向量的点积。最后屏幕暂停,按任意键继续

测试结果及运行环境
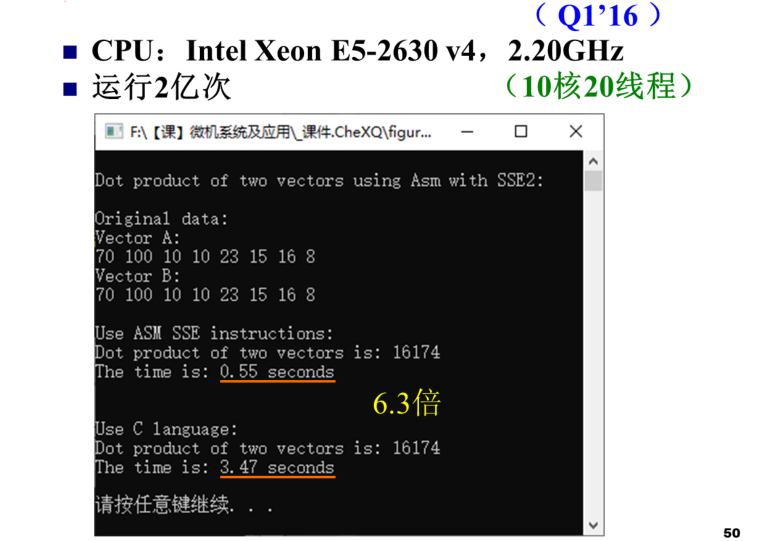
可以发现同样是求两个向量的点积重复2亿次,通过嵌入汇编使用SSE2指令集实现,可以针对特定的硬件,优化程序的性能,其速度是用C语言实现的6.6倍。测试计算机的CPU是2008年第三季度推出的2核2线程的酷睿移动处理器,主频为2.26GHZ
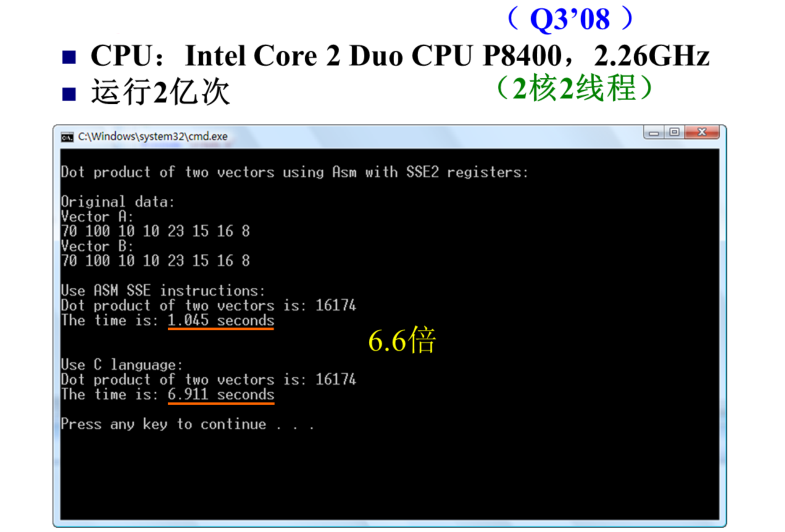
换1台计算机测试,这台计算机的CPU是2007年第一季度推出的4核4线程的酷睿多面处理器,主频为2.4GHZ,发现和前面的测试结果相差不大。同样的程序为什么主频差不多,在4核计算机上的运行速度没有明显的提高?
因为这是一个单线程的程序,线程是操作系统调度的最小单位,一个线程只能在一个内核上运行,其运行速度与CPU的总内核数无关
![]()
再换一台计算机测试,这台计算机是2016年第一季度推出的10核20线程的至强处理器,主频为2.2GHZ,与前2台测试机的主频相差不大,但是程序的运行时间接近前2台计算机运行时间的一半,这是CPU内部指令流水线进一步优化,引入了很多增强性能的新技术的结果。因此看一个CPU的单核性能,除了主频之外,其体系结构方面的改进也非常关键
让C语言从外部调用汇编
两种实现方法:
1.嵌入汇编——在C语言中嵌入汇编语言代码
优点:
- 简单:无需考虑外部链接、命名、参数传递协议等问题
- 高效:不存在过程调用的开销
缺点:不易维护,不方便移植
2.模块连接——让C语言从外部调用汇编
可以采用模块化的程序设计思路,必须用汇编语言实现的部分可以设计成一个函数,存储为后缀名为.asm的单独文件,并将汇编程序文件加入到C语言项目中,在C语言代码中直接调用这个用汇编语言实现的函数
例:
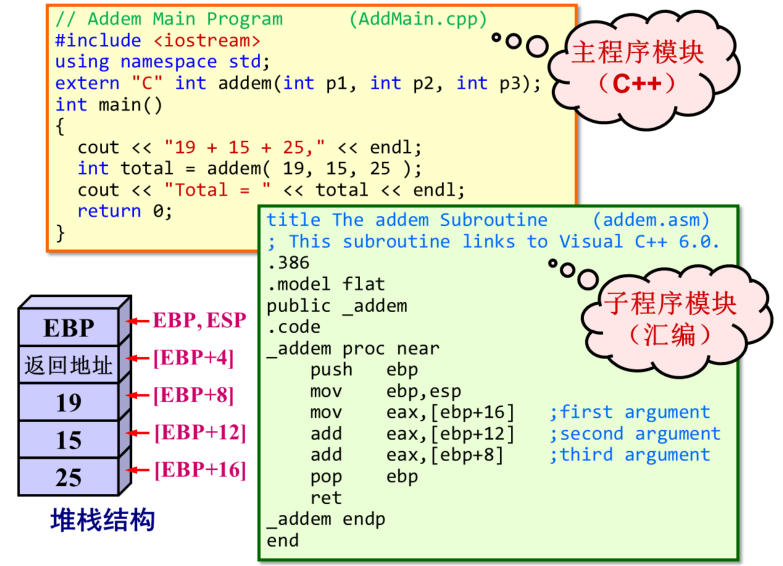
C++语言实现的主程序中需要调用外部的addem函数,这个函数需要三个整型参数,其功能为返回这三个参数之和。这里需要声明一下这是一个外部的,C风格的函数,同时声明了函数的原型
输出字符串到屏幕,提示本程序的功能是求三个数之和。再调用addem函数,传入三个参数,返回的累加和存入变量total。这条指令编译后首先会产生3条压栈指令,按照从右往左的顺序分别把三个参数压入堆栈,然后是一个子程序调用CALL指令调用函数addem,执行时先将当前指令指针寄存器的内容也就是返回地址压入堆栈,然后跳转到用32位汇编实现的addem函数去执行
.386伪指令告诉编译程序产生32位的机器指令。.model伪指令定义内存模型为平坦型。.public跟函数名称说明这个函数可以被外部的其他程序调用
然后是代码段。“函数名称 PROC”开始,“函数名称 ENDP”结束,最后是END伪指令,不跟程序入口点。注意到这里的函数名称比主程序中引用的多了个下划线,因为Visual C++编译器在编译主程序代码时会自动给addem函数名称左侧加一个下划线
将EBP原来的值压入堆栈,将ESP的值赋给EBP,此时EBP和ESP同时指向栈顶的位置。后面的代码如果有压栈出栈指令只会影响ESP的内容,EBP的内容就此固定。通过EBP相对寻址就可以访问到堆栈中由主程序传递来的参数。取第一个参数至EAX,将第二和第三个参数加到EAX。最后恢复EBP原来的值,函数返回
在Visual C的函数调用规范中规定如果函数的返回值是一个32位整数就必须通过EAX返回
最后将函数的返回值,也就是三个参数之和显示到屏幕上
通过程序调试界面的反汇编窗口,从中观察到主程序的int total = addem( 19, 15, 25 )C++语句经过编译后产生6条机器指令,包括3个压栈指令、1个子程序调用指令、1个加法指令和1个数据传送指令。当程序执行到addem函数内部求三个参数之和的代码时,堆栈的内容如下图所示。当执行出栈指令时EBP原来的值从堆栈中弹出,当执行子程序返回指令时返回地址被弹出,在执行加法指令之前,堆栈的栈顶位置如下图所示。这条加法指令将ESP的内容加12,这就相当于回收了三个参数占用的空间,最后把函数的返回值由EAX传送至内存的total变量
![]()
不同的C语言编译器,其底层子程序调用的规范、参数传递的规则可能不同
高级语言编译器在代码优化方面是卓有成效的。有些编译器针对特有的处理器进行了优化,可极大提高被编译程序的执行速度
但是编译器通常采用常规的优化处理手段,对个别的特殊应用和安装的特殊硬件并不了解。而手动编写的汇编语言代码可充分利用计算机系统的某些硬件(比如视频显示卡、声卡等)的特性。在某些场合,汇编语言可以很方便地实现高级语言不提供或较难实现的功能
C语言调用汇编的其他例子
判断有符号整数加法溢出
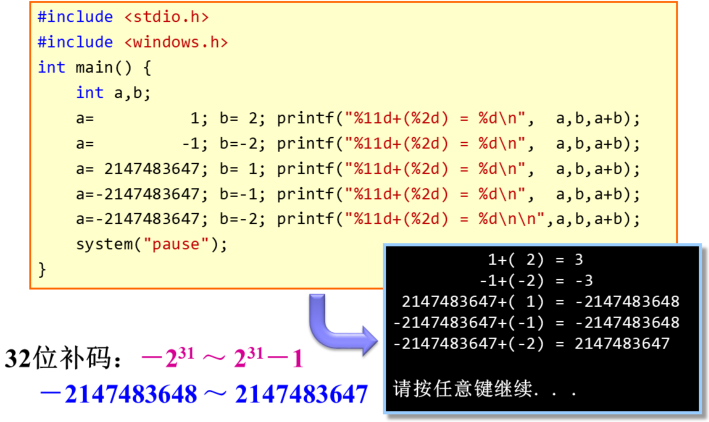
尽管结果显然是错误的,但C语言程序运行时没有任何警告和提示。C编译器不会做任何有关运算结果溢出的检查。可以通过C嵌入汇编设计一个函数,来检查两个整型变量加法结果是否溢出。函数代码如下:

函数接收两个整型变量作为参数。相加后如果OF置位则跳转返回1表示结果溢出。否则顺序执行令EAX清0,也就是函数返回0表示相加结果不溢出
汇编语言实现分支功能,前面分支的末尾必须加跳转指令跳过后面的分支
修改一下原来做加法的C程序,增加对刚才函数的调用。然后运行验证

总线技术
总线概述
总线
连接两个以上数字系统元件的公共的信息通路
这是一般性的概念,实际上还有一种总线叫专用总线,总线上可能只需要连接两个数字系统或两个模块
计算机组件间、计算机间、计算机与设备间连接的信号线和通信的公共通路
总线的分类——按连接的层次
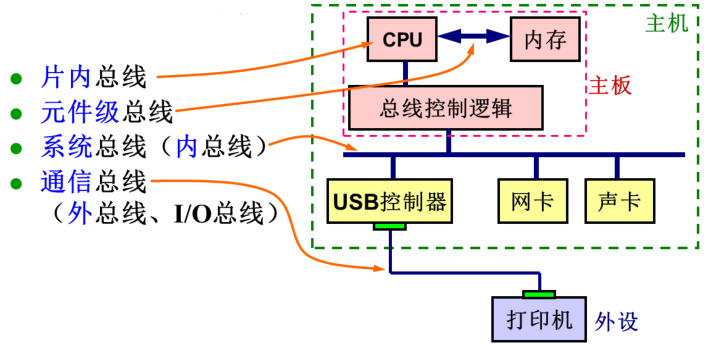
CPU内部有很多种不同的总线结构,比如说单总线、双总线、甚至是三总线结构。这种芯片内部的总线就叫片内总线
一般用来连接电路板上各个芯片之间的非标准的总线叫元件级总线。比如说早期的计算机内存芯片是直接焊接到计算机主板上的,连接内存芯片跟CPU芯片之间的这种总线就可以叫元件级总线
当然最新的计算机内存都是以内存条的形式插到计算机主板上的,内存条跟计算机主板之间的总线就属于系统总线,指的是连接计算机系统内部各个模块之间,或者说用来连接计算机主板跟各种插件板之间的标准的总线。因为系统总线通常在主机箱的内部,所以也叫内总线
通信总线用来连接计算机系统跟外设,这种总线一般在主机箱外部,所以也叫外总线
也有一些特例,比如现在最普及的PCIe总线
现在CPU内部通常会集成很多个CPU的内核,还集成了内存的控制器,包括一些高速的接口控制器。微处理器芯片内部CPU内核和内存控制器还有高速的总线控制器之间的互联通常也会采用PCIe总线。尽管最新的微处理器芯片内部也会有PCIe总线,从制定PCIe总线规范的初衷来讲,PCIe应该属于系统总线
辅存,如硬盘一般也会归到外设里面。现在比较流行的固态硬盘有多种连接方式,有一种叫M.2和U.2接口,底层的通信协议仍然采用PCIe
总线的分类——按数据传输位数
1.并行总线
采用多条数据线对数据各位进行同时传输
仅适宜计算机内部高速部件近距离连接。高频率使发送端原本同步的数据到达接收端时出现时钟偏移,也会加剧空间距离很近的多条数据线间的串扰
典型的并行PCI总线,一般时钟频率就是33MHZ。后来在服务器或者工作站上采用66MHZ,频率再高,以上这些问题要解决起来就非常复杂
通信距离较长则信号线线数比较多,也会增加总线的长度进而增加总线的成本
2.串行总线
采用一条数据线逐位传输各位数据
无需考虑时钟偏移和串扰问题,故可通过提高频率来提高数据传输率
数据二进制位采用差分的形式来传递的话就可以避免线跟线之间,或者说外界对数据线的干扰
常用于长距离通信及计算机网络
在短距离应用中性能也已超过并行总线
系统总线 (PCI, PCIe) 和通信总线 (USB) 一般都会有标准化的组织为它制定相应的规范
标准化总线
由IEEE(美国电气电子工程师协会)或计算机厂商联盟制定。对总线插槽尺寸、引脚分布、信号分布、时序控制、数据传输率、总线通信协议等有明确规定
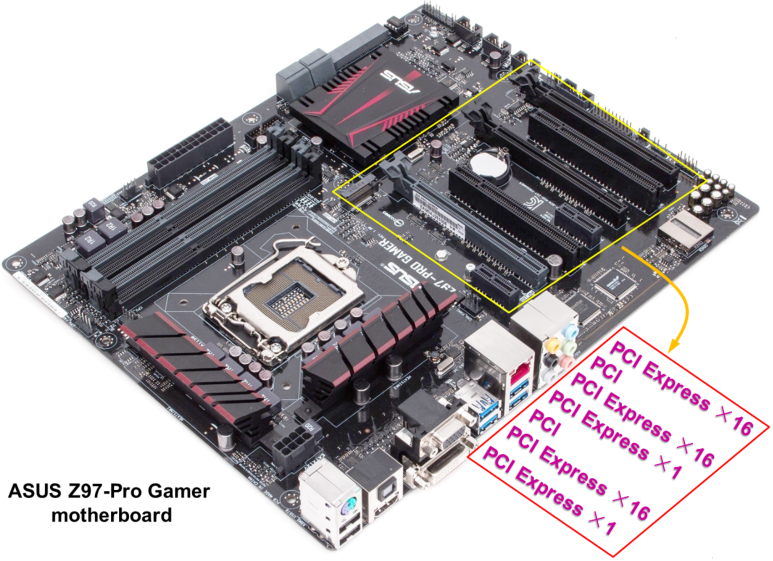
显卡电路板跟计算机主板之间相连一般采用标准的PCIe$\times$16系统总线
总线标准化的优点:
1.简化软硬件设计,简化系统结构 →\to→模块化
2.使系统易于扩展、便于更新
3.便于调试、维修 →\to→各插件板分别调试;一级维修
典型的标准化总线——内总线
ISA总线
1981年,IBM PC/XT (8位ISA总线,基于8088)
内存直接焊接在计算机主板上。要对计算机进行功能扩展,可以基于8位的ISA总线来扩展插件板,把设计的板卡直接插到计算机主板8位的ISA总线插槽上,就相当于对计算机系统的硬件进行了一定的扩展
1984年,IBM PC/AT (16位ISA总线,基于80286)
16位的ISA总线为了跟原来的8位兼容,在原来的8位ISA总线基础上后面增加了一些相应的信号。数据线从原来的8位扩展到了16位,地址线从原来的20位扩展到了24位
即设计的板卡如果基于8位的ISA总线,实际上也可以插,只不过只用到了插槽的前面这一半
1988年,以康柏 (Compaq) 公司为首,EISA (Extended ISA),32位
ISA总线可以简单地理解成就是8088/8086系统总线的延伸,16位的ISA总线也可以理解成是80286系统总线的延伸。常用的读写信号,如地址线、数据线、读写控制信号ISA总线上面应该都能找得到,电源、时钟信号、跟中断有关的信号也有
下图的两部分应该在一条上,底下一截平移到了右边显示
PCI总线
特点:
1.不依赖于处理器
PCI总线在制定规范时则并没有参考任何一款处理器
ISA总线在制定规范的时候针对的就是Intel从8086到80286这一系列的微处理器,基于这样的微处理器的系统总线信号定义到ISA总线上
2.扩充性好
可以通过相应的桥芯片扩展出多条PCI总线,连接更多的外设部件
3.支持自动配置
基于PCI总线的设备或板卡插到总线的扩展插槽上,计算机启动时会自动识别插接到扩展插槽上的设备并且对设备内部的各种资源比如占用的接口地址、内存范围进行自动配置
ISA总线通常不支持。事先要把ISA总线的板卡(上面一般会有一些拨动开关,开关拨到不同状态占用的接口地址范围是不同的)插接到计算机的主板上加电看能不能正常启动。不能则说明ISA总线的板卡占用的资源跟主板资源冲突
4.支持多主控设备
如果某一个PCI总线上的设备成为主控设备之后,实际上它可以主动去访问这个总线上的其他设备,甚至可以直接主动去访问主存。不经过CPU能够实现板卡与板卡之间,设备与设备之间或者说设备与内存之间的直接数据传送
DMA就是基于这种所谓的多主控设备方式来实现的
PCI总线上究竟有哪些总线信号,这些总线信号通过什么方式来实现PCI总线上两个设备之间的可靠数据通信?下面通过时序来说明,这是传统的并行PCI总线上常用的信号
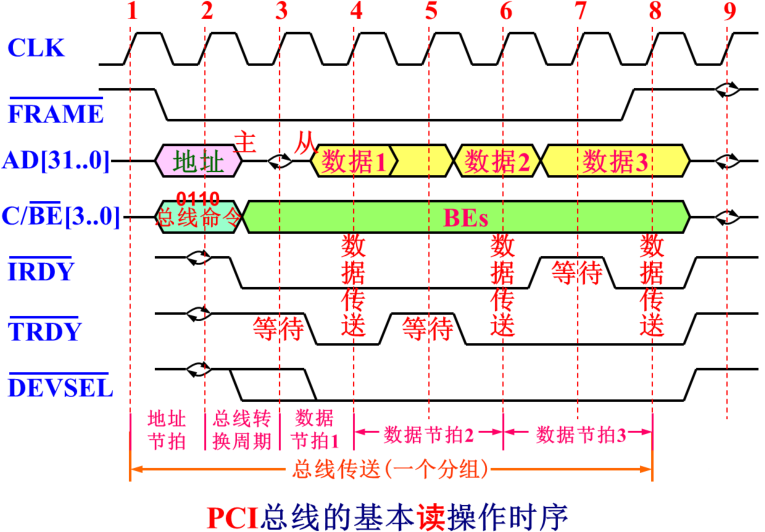
PCI总线属于同步总线,所以总线信号里肯定应该有一个CLK时钟信号
PCI总线上的仲裁方式采用的是集中式的独立请求方式。假设现在PCI总线上的某一个设备取得了总线的使用权,成为了PCI总线上的主设备,想要选择某一个从设备传输数据,要从从设备里的存储器里读一些数据
主设备先把FRAME‾\overline{FRAME}FRAME信号置低电平,告知总线上的其他设备做好准备自己要进行通信,同时会把它要访问的内存地址放在[AD…0] 这32根地址数据复用的信号线上。在C/BE‾[3..0]C/\overline{BE}[3..0]C/BE[3..0]这4根线上放一个命令,0110表示内存读命令。此时挂接在PCI总线上的其他设备要检查一下主设备要访问的内存地址是否落在自己的管辖范围内。被选中的从设备会把设备被选中信号DEVSEL‾\overline{DEVSEL}DEVSEL置为低电平,告知主设备自己在哪并且已经准备就绪
实际上计算机的最大内存寻址空间通常比较大。比如32位系统下内存地址是32位,最大的内存地址空间应该是4GB,但实际上这4GB不可能全部分配给内存条来用。通常在高端的地址要保留一部分给外设来用,相当一部分要保留给PCI设备来用,所以PCI设备内部存储器通常容量也比较大,一般也会把它映射到内存地址空间
中间隔一个时钟周期实现总线传输信号方向的转变以避免总线竞争。经过一个总线转换周期后,后面理论上来讲只要主设备和从设备都处于就绪状态,则每一个时钟周期时钟信号的上升沿就可以传递一个32位的数据。当然传递的过程主设备和从设备内部的地址会自增,所以地址只需要传一次,后面可以连续传输很多的数据,这种方式叫多发数据传送方式
如果主设备或者从设备内部有时可能内部来不及处理需要等待一下呢?IRDY‾\overline{IRDY}IRDY是主设备准备好的信号,TRDY‾\overline{TRDY}TRDY是从设备准备好的信号,这2个信号同时为低电平就可以传输一个数据,如在时钟周期5时钟信号的上升沿,从设备没有准备好,此时就不会传输数据
主设备把FRAME‾\overline{FRAME}FRAME信号置高电平,后面再传输一个数据,整个传输过程就可以结束
通过这个时序可以了解到PCI总线一个时钟周期就可以传输一个32位的数据,通过这点可以算传统的PCI总线理想情况下的多发数据传输率。如33MHZ PCI对应数据传输率为33×106×32÷8=132MB/s33\times10^6\times 32\div8=132MB/s33×106×32÷8=132MB/s
PCI总线的局限:
总线上的所有设备共享带宽,只能分时使用
用并行单端信号,一般通过提高总线位宽和频率的方法增加总线带宽。提高总线位宽会增加芯片引脚,影响芯片生产成本。提高总线频率会产生时钟偏移和串扰问题,还会影响总线负载能力
高端的工作站或者服务器上PCI总线的数据线的位数一般相比个人计算机更大
PCIe总线
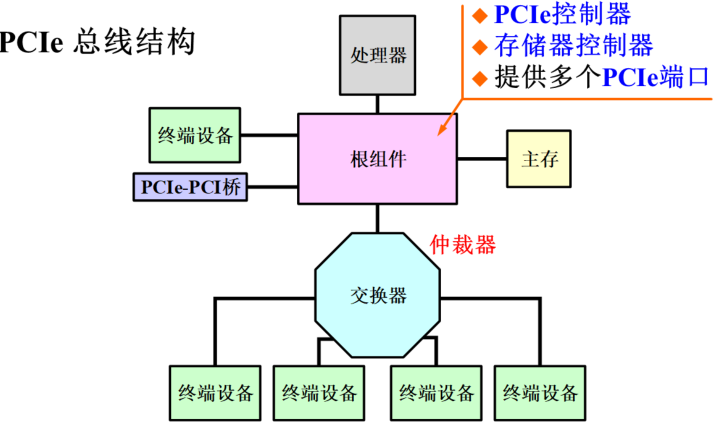
PCIe在计算机里面首先会有一个总的控制器根组件,根组件内部通常会集成一个PCIe总线控制器和存储器控制器,存储器控制器主要用来实现PCIe总线地址空间跟内存地址空间之间的映射,或者说转换。同样根组件内部还提供了多个PCIe端口
如果需要用到传统的并行的PCI总线可以再接一个PCIe-PCI桥。桥可以实现两种不同总线协议之间的转换
如果需要接更多的基于PCIe总线的外设,可以通过一个交换器(和网络上的交换机类似)扩展更多的端口
PCIe总线的特点:
1.串行差分,一次只传输一个二进制位
避免了时钟偏移和串扰问题,总线可达到很高的频率,从而进一步提高总线带宽
每一条PCIe数据通路 (Lane) 由两组串行差分信号(4根信号线,这4根线组成一个通道)构成,可进行全双工数据传输,发送和接收各是一对信号线,发送和接收并行工作
2.直流平衡、内嵌时钟
PCIe1.0和PCIe2.0采用8/10b编码,将每8位数据编码成10位传输,编码开销占总带宽的20%开销
串行传输的信号如果传输的时候连续0和连续1太多,电平长时间没有变化,很难从信号里把时钟提取出来。8/10b编码就是用10个二进制位,从1024种组合里找出256种组合,这256种组合连续0和连续1的个数不会太多,且0的个数和1的个数基本均衡,用它来表示相应的一个字节的信息
PCIe3.0采用128/130b编码提高了带宽利用率,编码开销占总带宽的1.538%开销
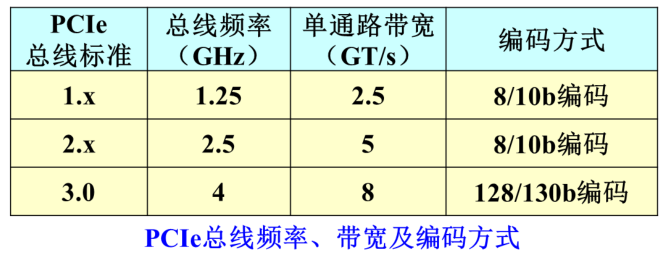
总线频率2.5GHz则每秒钟可以传输2500M个二进制位,10个二进制位用来表示一个字节,所以×1\times1×1单向带宽为250MB/s (1GT/s=1Gbit/s)。如果发送的同时还在接收的话,则总的带宽在此基础上可以再乘2
3.多通道
一条PCIe链路可以由多条数据通路组成,多通道并行工作提高总线带宽
目前PCIe链路可以支持1、2、4、8、12、16和32个数据通路,即×1、×2、×4、×8、×16、×32\times1、\times2、\times4、\times8、\times16、\times32×1、×2、×4、×8、×16、×32 数据带宽

如独立显卡一般会通过PCIe×\times×16的总线连接到主板上,指的就是有16个通道
通道之间不需要同步。比如说这次要传输一大批数据,采用PCIe$\times$16的总线传输。可以把这一大批数据平均分成16等份,每一等份用一个通道来传输,底层会一个个数据包打包之后再传输。具体数据包之间按照什么顺序来组合内部都有编号。接收方接收到这些数据之后按照数据包内部规定跟顺序有关的信息接收方再重新拼装成原始数据
4.端到端(交换结构),实现多模块同时通信
传统并行PCI总线所有设备共享带宽。PCIe总线采用端到端(交换结构)的连接方式,每一条PCIe链路中只连接两个设备
5.软件向下兼容
不管是PCI还是PCIe总线对挂接在这个总线上的设备进行读写和控制,软件的接口是完全一样的
下面这个主板上有很多PCI总线的插槽。为了兼容老的基于并行PCI总线的设备或者说插卡,仍然保留了传统的32位PCI总线
典型的标准化总线——外总线(通信总线)
通常把这种总线也叫做接口,比如说USB接口
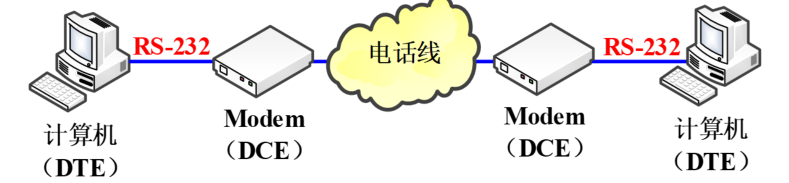
RS-232C串行通信接口
打开设备管理器,在端口这一栏有一个通信端口 (COM1),这就是传统的RS232串行接口。最新的计算机主板可能并没有把这个接口作为一个插座引出,但是这个接口的资源在计算机主板上仍然存在。打开COM1端口的属性还可以设置这个端口在通信时的一些参数
早期国际互联网还没有出现时想实现远程的不同地方的计算机之间的通信要借助电话线,电话线上传输的是模拟信号,调制解调器把计算机能够接收的TTL电平转换为模拟信号,而调制解调器就是通过RS-232C连接到计算机上的
现在如果提到DTE,就理解成计算机。提到DCE就理解成外设

1.信号
传送信息信号:
RS-232C能够实现全双工的通信,所以数据线有2根,一根用来发送一根用来接收
- TxD : 发送数据线 (DTE →\to→ DCE)
- RxD : 接收数据线 (DTE ←\leftarrow← DCE)
联络信号
- RTS : 请求发送,计算机告诉外设要发送数据 (DTE →\to→ DCE)
- CTS : 清除发送,外设告诉计算机可以接收数据 (DTE ←\leftarrow← DCE)
- DTR : DTE就绪,计算机告诉外设已经准备就绪 (DTE →\to→ DCE)
- DSR : DCE就绪,外设告诉计算机已经准备就绪 (DTE ←\leftarrow← DCE)
- DCD : 数据载波检测。调制解调器如果从电话线上接收到有数据来了就会把数据载波检测置成有效告诉计算机 (DTE ←\leftarrow← DCE)
- RI (22) : 振铃提示,跟电话线有关 (DTE ←\leftarrow← DCE)
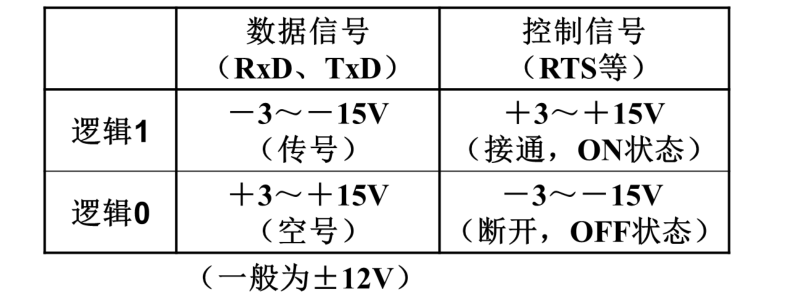
2.电平
3.与TTL电平转换
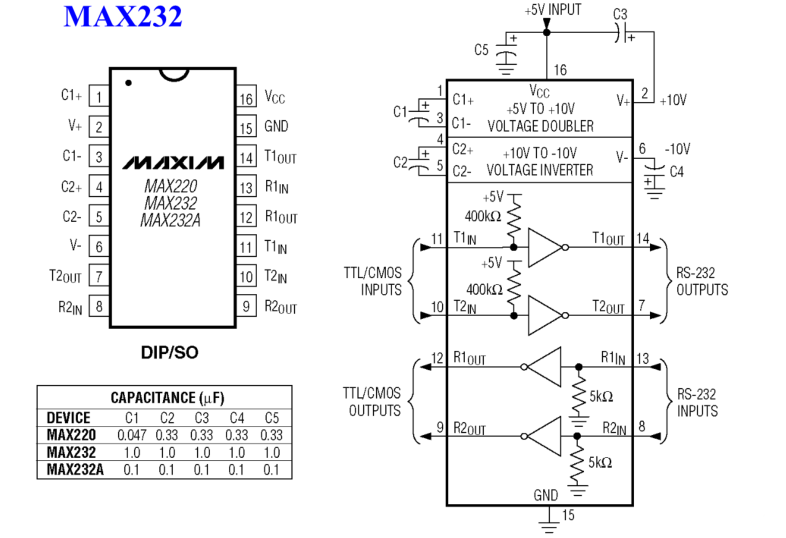
计算机希望接收发送的信号都是TTL电平,比如低电平就是0V,高电平就是5V。所以中间需要电平转换

MAX232芯片只需要一个单5V电源供电,单5V电源内部经过升压之后产生±10V\pm 10V±10V的电压。下图即为该芯片的具体引脚
增压电路需要一些电容,电容很难集成到芯片内部,特别是一些容量大的电容,需要外接。计算机发送出来的TTL电平信号经过它转换成RS-232C串行接口所需要的±10V\pm 10V±10V的电平。从串行接口来的±10V\pm 10V±10V的电平信号通过它转换成计算机能够接受的TTL电平
接下来看一下RS-232串行接口具体的通信格式
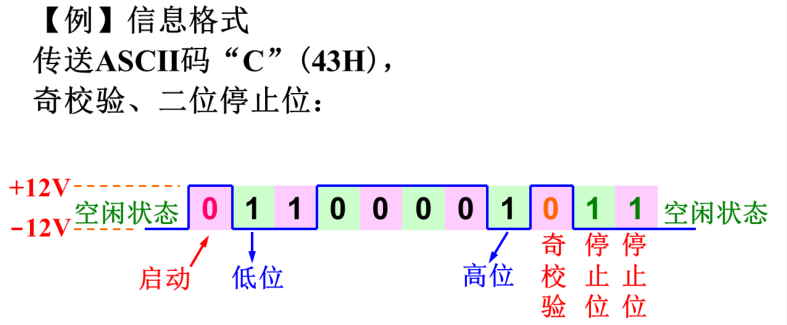
首先总线处于空闲状态,一个启动位,接下来先传低位后传高位,最后是奇偶校验位和2个停止位
RS-232串行接口有的时候叫异步串行通信。因为它没有时钟信号,所以不是同步总线而是异步总线。并且通信之前双方事先要约定通信的波特率,两边设置的参数包括数据的格式必须要一样,然后才可以通信
比如说发送方要发送数据,必须得从启动位开始,接收方检测到启动位就会从这个位置开始计时,因为双方约定了数据传输的波特率,相邻两个数据之间的间隔可以计算得到。从这个启动位开始,接收方每固定一段时间采样一次数据线得到一位的二进制数据
当然发送方和接收方具体的定时不可能毫无误差,但只要保证这一个数据(通常最多只传输一个字节)在传输的过程中哪怕每一次采样时稍微有一点点错位,传输到最后一个数据能够正常接收就可以了。传输下一个数据时又会再来一个启动位重新对齐
应用:
1.使用Modem连接
电缆信号一一对应,共10线。
(保护地、信号地、…)
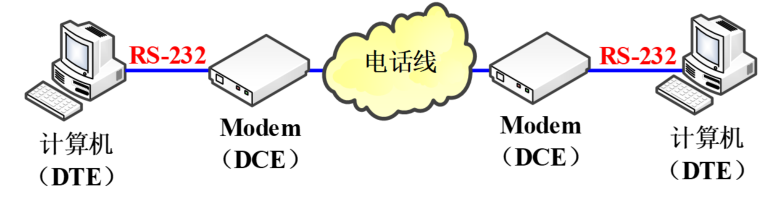
2.直接连接:计算机 (DTE) ↔\leftrightarrow↔ 计算机 (DTE)
RS-232串行接口最大的优点在于实现起来非常方便,成本也低。最简单的实现方式是三线经济方式 (三线制 RS-232)
计算机跟外设之间首先要共地。发送一根数据线,接收一根数据线,两边交叉着直接连

3.软硬件系统调试:控制台、超级终端
RS-232串行接口相对数据传输率较低,现在用的不是很多。最典型的应用主要是硬件调试
比如说现在有一块嵌入式的开发板,这个电路板在设计的时候为了简化问题,可能没有那么多输入输出设备可以连接
为了观察到电路板内部CPU执行程序的过程,或者说发命令来控制它的工作过程,可以通过最简单的三根线实现的RS-232串行接口实现接口来和计算机连接。在计算机上运行超级终端软件,通过计算机的键盘在超级终端软件里面直接输入命令,那个命令就会通过RS-232串行接口传输到电路板内部。电路板内部接收到命令,做一定的运算操作之后会把可能的相应输出信息的ASCII码再通过串行接口传输到计算机上运行的超级终端软件里面。超级终端软件会把相应的接收到的字符串显示到计算机屏幕上
这样其实就相当于把计算机的显示器和键盘给开发板来用

USB总线
特点:
每个USB总线支持127个外设
整个USB系统只用一个端口(接口地址)、一个中断 →\to→ 节省系统资源
支持热插拔、动态加载驱动程序:PnP,自动配置。带电拔出后自动回收资源
传输距离:3~5米,电压:5V
通过信号的名字可以观察到USB总线采用串行差分的方式来传送数据。USB1.0和USB2.0只有一对数据线,只能工作在半双工状态下,不能同时接收和发送
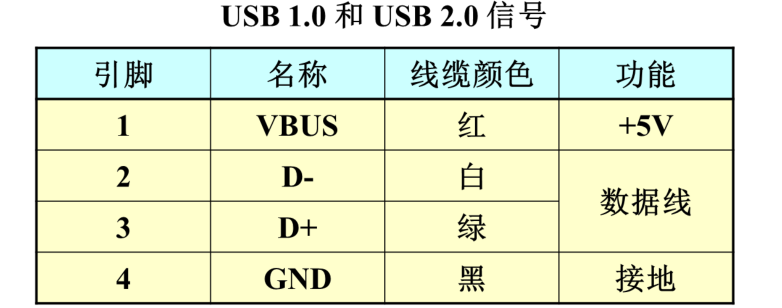
USB各版本向下兼容。USB3.0为了和USB2.0兼容,原来的+5V电源、+5V地、两根差分形式传输的数据线仍然保留,另外又新增了两对数据线。USB3.0如果工作在超速模式下,发送和接收分别各用一对,采用差分的形式来传输信号,支持全双工的方式来进行工作

Low-Speed 低速模式,Full-Speed 全速模式,High-Speed 高速模式,SuperSpeed 超速模式
现在一些低速的外设,比如说USB接口的键盘和鼠标,工作在低速模式下应该也完全够用
USB总线可以通过总线来给外设提供电源,即能够实现给外设直接供电。USB3.1从第2代开始还支持快充模式,可以提供更大功率的输出

再来看一下USB具体物理上的接口,计算机端和外设端有A、B、C类型。C类型接口从使用的角度来讲最大的方便之处在于不分正反,正着插和反着插都可以。通过信号的分布会发现所有的这些总线信号都是根据中心点镜像对称的,不管是正插还是反插对应的都是同一个位置
TX1+和TX1-是一对用来发送的差分信号线,RX1+和RX1-是一对用来接收的信号线
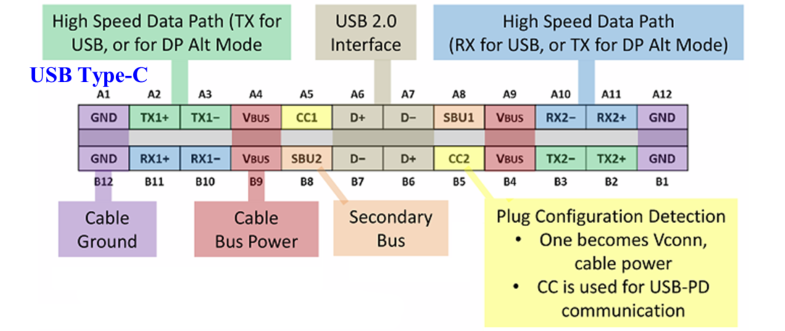
Type-C有两个高速数据通道, (TX1+/TX1-,RX1+/RX1-) 和 (TX2+/TX2-,RX2+/RX2-)
USB3.1仅使用其中一个通道,另一个通道可用于备用模式
USB3.2可以充分使用这两个高速通道,双通道20Gbps。要能够实现最高的数据传输率必须得用C型接口
如果这两个高速通道都用于备用模式,则速度就会下降成USB2.0的High-Speed
ATA总线
ATA总线连接存储设备和计算机。早期采用并行的方式传输数据,PATA即并行ATA接口,其总线电缆是40芯或者80芯的扁平电缆,线比较宽占主机箱空间,也影响散热,也不可能过长。后来出现了串行ATA接口,叫SATA或者SATA总线

ATA总线设计之初就是用来连接硬盘的,所以它在具体通信时的通信格式,包括逻辑块地址用多少个二进制位来表示在它的总线规范里有具体表示。比如最早的ATA总线,它在通信时规定逻辑块地址用22位来表示,这样硬盘的逻辑块最多有222=4M2^{22}=4M222=4M个,一个逻辑块对应一个扇区,而通常情况下一个扇区是512B,这样就能算出理论上能支持的最大磁盘容量
1TB=1024TB,1TB=1024GB
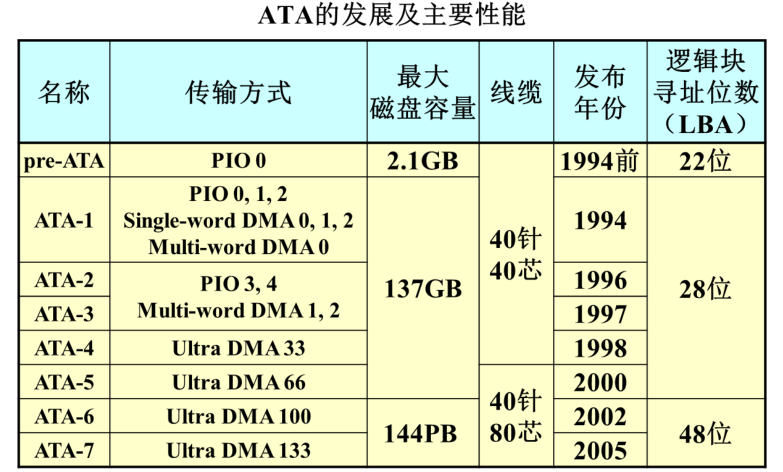
SATA具有速度高、电压低(功耗低)、线缆窄、支持热拔插、传输距离长的特点,现已取代PATA
服务器一般配置好,通常是24小时不断电工作。如果服务器磁盘阵列里的某一个硬盘出问题会希望服务器不要关机,直接带电将其拆下来,这就要求硬盘的接口必须支持热插拔
总线的驱动与控制
总线的竞争与负载
总线竞争:同一总线上,同一时刻,有两个或两个以上的器件输出其状态
1.对TTL门
有两个门同时将状态输出到信号线上,一个输出低电平一个输出高电平,此时总线上会是一种不高不低的非TTL电平,可能会丢失状态。并且这种情况下可能有一个非常大的电流灌进输出低电平的引脚,严重时会烧坏电路
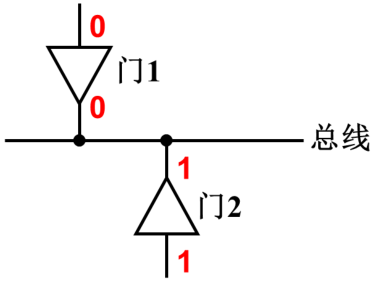
照着具体的门电路内部看一下。如果这两个门的输出引脚接到一起,实际上就相当于两个门同时把状态输出到这一根线上
右边的与非门只画了输出的这部分电路
比如一个输出低电平一个输出高电平,输出低电平的引脚底下的晶体管处于饱和状态,即集电极和发射极之间导通。输出高电平的引脚对应的这个晶体管截止,集电级跟发射极之间断开,上面上拉用的晶体管是导通的。这样如下图所示,从正电源到输出低电平的输出引脚,内部的晶体管一直到地会有一个相对比较大的电流。长时间维持这种状态,电流大功耗大,发热热量达到一定程度有可能会把这两个器件的输出引脚,即它内部对应的晶体管烧坏
这根线上究竟是高还是低呢?
实际上只要有一个引脚输出为低电平,就相当于把这根线通过这个输出引脚内部的下拉晶体管直接接地,所以上这根线上呈现的应该是类似低电平的状态
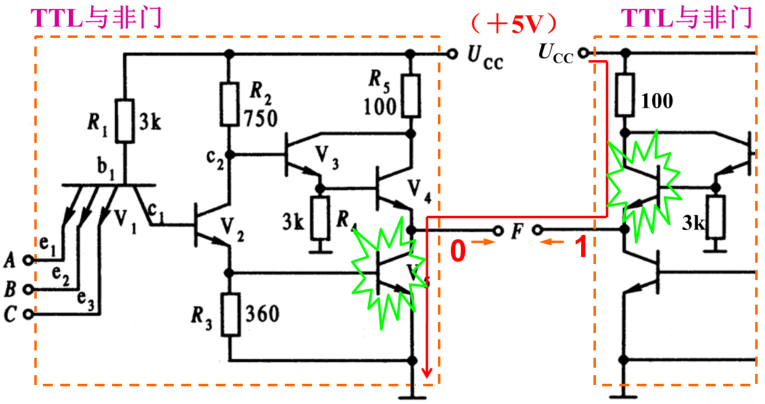
2.特例:集电极开路/漏极开路输出
OC: Open Collector
有一种门电路,它的输出引脚集电极开路/漏极开路,相当于输出引脚上面上拉的部分没有,输出引脚到正电源之间什么都没连,处于开路状态
下图只画了输出引脚有关的晶体管,内部的其他部分省略
这样的输出引脚是可以接到一起的,外面必须加一个阻值相对较大的上拉电阻。如果这几个引脚都想输出高电平,每一个晶体管都处于截止状态,集电极与发射极之间不导通,线上呈现高电平。若某一个输出引脚想要输出低电平,其三极管处于饱和状态,相当于把这根线通过晶体管接地,会产生如下图所示的电流,但因为上拉电阻阻值较大,所以这个电流比较小,不会烧坏器件,但B输出的“1”信息会丢失
在数字电路中三极管当作电子开关来用,要么导通要么断开
只有所有的输出引脚都输出电平时,这根线才会是高电平,任何一个输出引脚只要输出低电平,这根线就呈现低电平状态,这就是线与逻辑
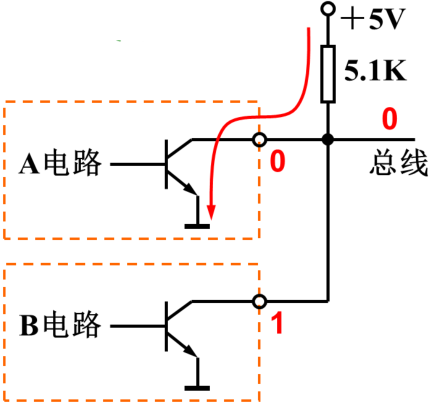
3.用三态电路,严格控制逻辑
这根线接了两个负载也就是两个输出引脚,都具有三态功能,可以控制是否能输出。三态门的输出状态有高电平、低电平、高阻三种。高阻相当于电阻无穷大,相当于输出引脚跟总线之间脱开
总线的负载
1.直流负载
如果驱动门输出高电平时,没有能力提供负载需要吸收的电流,会导致高电平电压高不上去。输出低电平时如果吸收电流的能力不够,会导致低电平电压低不下来。都会造成逻辑上的问题
2.交流负载
对MOS电路,IILI_{IL}IIL、IIHI_{IH}IIH很小 →\to→ 主要考虑电容负载
所有的这些负载输入引脚对地之间都有一个分布电容。接的负载多了后,这些电容是并联关系,一端同时接到线上,另外一端同时接地,总电容越来越大,会产生较大的电容负载,滤掉高频分量
且如果想从低电平变到高电平,电容电压无法突变,充电需要过程,电容越大过程越缓慢,从高电平变到低电平也一样。一些窄的正脉冲可能会被滤掉,产生逻辑问题

所有的负载输入引脚到地到会有一个电容。信号线在电路板上走,信号线本身到地之间也会有电容,这是元件级总线、内总线带来的电容。信号线要从一个电路板引到另外一个电路板上,或者连接到某一个外设上,传输线长了也会用更大的分布电容
故要求输出门的负载电容CPC_PCP满足如下条件:
![]()

驱动门和负载的原始参数都可以通过查芯片手册得到
总线驱动设计
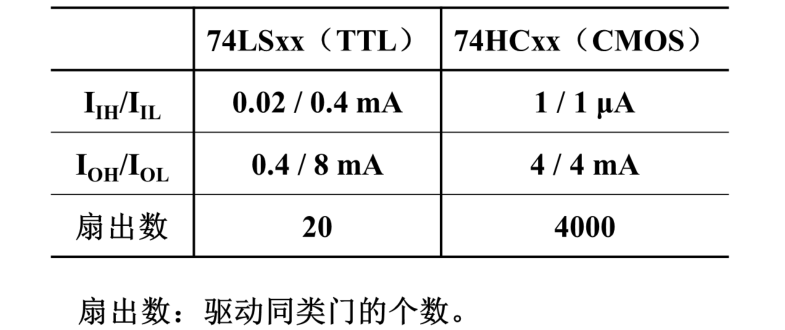
单向总线信号的驱动设计
如果连接到总线上的模块很多,也就是总线的负载很重,就需要加驱动器。对于单向的总线控制信号,比如地址、读写控制信号,情况相对简单。双向数据总线如果要加驱动,稍有不慎就会引起总线竞争
比如要设计一个由两块电路板(主板CPU板,扩展板电路板1)组成的产品。扩展板上需要从CPU板引过来很多信号,包括地址线的最低位A0。地址线实际上需要接很多负载,比如CPU板需要扩展内存,主板上可能会有很多内存芯片,每个内存芯片都有地址线,可能都要跟CPU的地址线相连,A0这根线本身在CPU板上就要接很多负载。现在这根线要引出来到扩展板上,扩展板很多地方也要用到这个信号,又要有很多负载
最好不要直接把这根线引出来而是加一个驱动器。经过驱动器再输出,不管它输出之后后面接了多少个负载,对CPU来讲也只是增加了1个负载而已
把该信号引入后最好也不要直接用而是加缓冲器。下图从驱动器的角度来讲它后面只接了3个负载,每个缓冲器后面又加了5个负载
缓冲器和驱动器功能类似,只是叫法不一样
驱动器和缓冲器也能起到缓冲作用,保护硬件
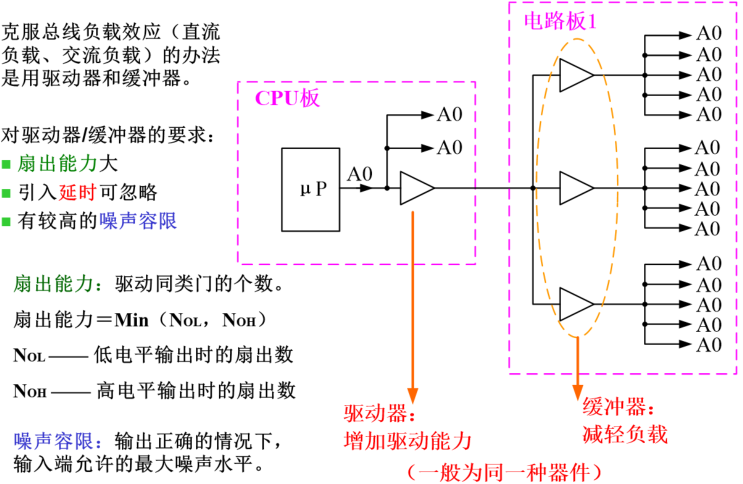
74LS244可以当驱动器或者说缓冲器来用,它主要用来实现单向的总线信号驱动。其内部有8个三态门,4个一组,总共2组,每组三态门的控制端接到一起引出来,低电平有效。把允许信号,即三态门的控制端接地令其永远有效,这样8个输入和8个输出永远一样
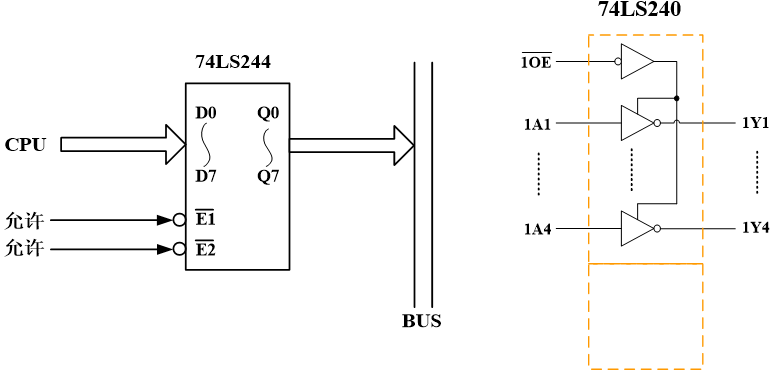
双向总线信号的驱动设计
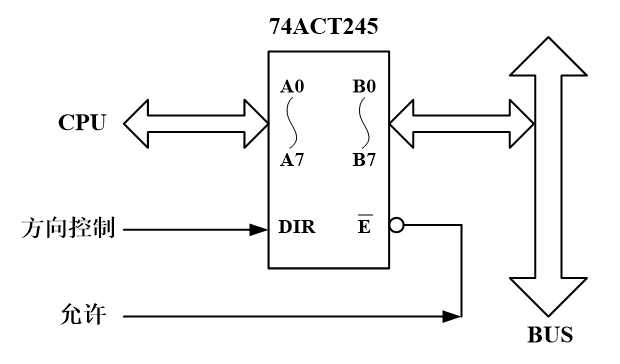
双向数据总线驱动器可以选择74LS245芯片实现,通过控制允许信号和方向控制信号来避免总线竞争。允许信号低电平,A边和B边导通。然后方向控制信号给高电平,信号传递的方向从A到B,给低电平则从B到A
注意74LS245不是一个开关,它是把一边接收的信号原封不动地复制到另一边输出
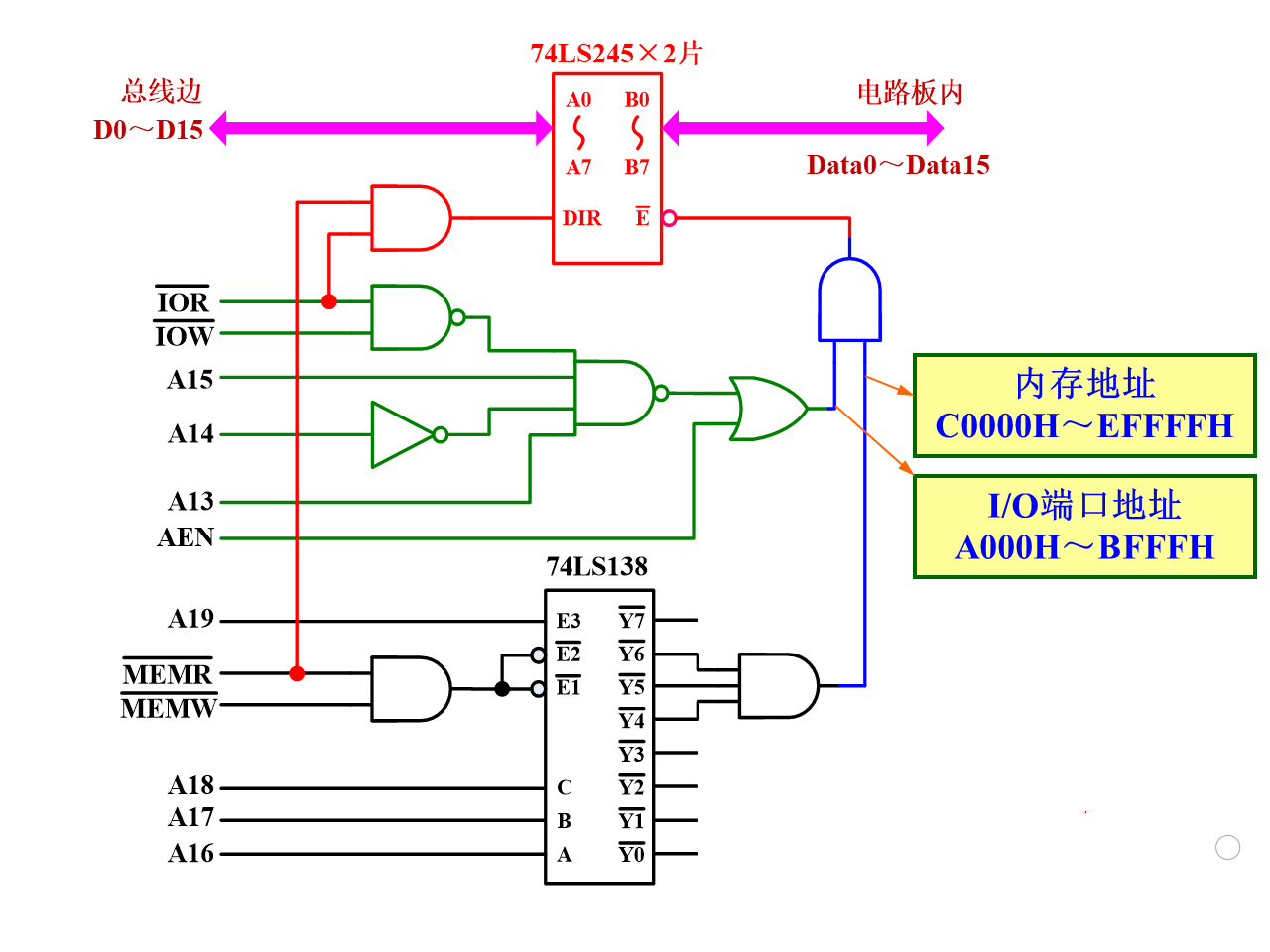
例3:某微型机电路板上有内存C0000H∼\sim∼EFFFFH和接口A000H∼\sim∼BFFFH,试画出该电路板板内双向数据总线驱动与控制电路
1.防止总线竞争原则:只有当CPU读板内内存或读板内接口时,才允许双向数据驱动器指向系统总线的三态门是导通的
2.地址分析(内存地址、接口地址)
设计的插件板板卡内部有很多存储器,插在计算机主板插槽上占用资源,希望占用一部分的内存地址空间和接口地址空间。计算机主板CPU运行某一程序时访问内存或接口,访问的内存或接口地址落在这个范围之内,访问板卡内部的存储器,驱动器74LS245的允许信号就应该给低电平让两边接通,然后根据读板卡还是写板卡控制方向信号。设计双向数据总线驱动时,要设计相应的内存和接口地址译码电路判断计算机主板要访问的内存和接口是否在范围内
C0000H∼\sim∼EFFFFH低4位全0到全F所有的组合都包含在内,故只需分析从C到E的最高位。观察高位地址发现A18、A17、A16是4、5、6这3种组合之一,如果该译码电路用3-8译码器实现,那Y4、Y5、 Y6任何一个是低电平,这三根线肯定就是这三种状态之一。此外A19必须是1。
对A000H∼\sim∼BFFFH的分析过程也类似,高三位地址只要是“101”地址就落在范围内

3.画驱动与控制电路
74LS138是3-8译码器
内存地址译码电路限定了高位地址A19必须是1,A18、A17、A16必须是4、5、6三种组合之一,CPU此时正在访问内存的条件
接口地址译码电路限定了A15、A14、A13分别是高电平、低电平、高电平,CPU此时正在访问接口地址空间,CPU此时正在控制总线不是DMA状态(AEN信号给低电平)的条件
这两部分任何一个条件全部满足74LS245的两边就应该接通
方向控制信号用读信号,内存读和接口读信号任何一个给低电平经过与门输出就是低,方向从B到A。写时读信号肯定无效,两个信号都是高电平,经过与门输出高电平,方向从A到B
存储技术
常用存储器芯片及连接使用
![]()
静态随机读/写存储器 (SRAM) 及接口设计
SRAM的优点是可以直接连接到系统总线上,有独立的地址线,数据线,读信号,写信号和片选,并且读写速度都很快。是易失性存储器,掉电之后内容就没了,刚一加电内容是随机的
用单个SRAM芯片构成8088的内存
![]()
可以认为这些信号都是8088工作在最大模式下的系统总线信号,或者认为这些信号都是8位ISA总线的信号,反正都一样
有的电路高位地址会留几根不连,这样连线较少但会浪费内存地址空间
![]()
用多片SRAM芯片构成8088的内存
存储器的字扩展:
1.地址线并联
2.数据线并联
3.OE― 并 → MEMR―,WE― 并 → MEMW―
4.CS― → 地址译码器(高位地址译码)的不同输出
8088系统总线数据线有8根,要求内存是8位的
如果SRAM芯片只有4根数据线,则不管构成什么内存都要进行位扩展,因为CPU访问内存最小内存就是8位,不可能一次访问4位的数据
![]()
存储器的位扩展:
1.地址线并联
2.数据线:1号芯片D0∼D7,2号芯片D8∼D15
3.OE― 并 → MEMR―,WE― 并 → MEMW―
4.CS―并联 → 地址译码器(高位地址译码)
8086要求内存必须是16位的,下图中SRAM芯片是8位的,要进行位扩展
连接地址线时,SRAM芯片的A0∼A10要连接到系统总线的A1∼A11。因为2个8位存储器位扩展之后构成1个16位存储器,给16位存储器地址要给字地址。x86按字节编址,如果给字的地址要从A1开始。这两个芯片可以同时被选中,同时被选中时CPU就对内存进行16位读写
![]()
若现在想用汇编语言编一个程序访问它里面的某一个单元,如从80002H地址读一个16位数据:
先初始化DS,将段的起始地址高16位传送到DS。再将16位段内偏移送到指针寄存器BX
然后寄存器间接寻址从指向的内存单元读一个数。默认段寄存器为DS,CPU会从DS读出段起始地址的高16位,末尾添4个0,再加上BX里存的16位段内偏移,加的结果就是要访问的内存地址
MOV AX,8000H
MOV DS,AX
MOV BX,2
MOV AX,[BX]
如要读一个8位数据,只需要把目标寄存器改为8位
从偶地址读BHE―为高电平,A0为低电平。从奇地址读BHE―为低电平,A0为高电平
如要读一个16位数据,目的寄存器就应该写16位
从偶地址开始读,BHE―和A0均为低电平,连续读2个字节传送到目的寄存器,2个字节占2个地址,小地址传送到低8位,大地址传送到高8位
从奇地址开始读,必须分两次来读,先让BHE―引脚为低电平,A0为高电平,读8位数据传送到目的寄存器的低8位。再让BHE―为高电平,A0为低电平,读8位数据传送到目的寄存器的高8位
数据在内存中要对齐存放,如果按字节编址,16位数据起始地址是2的整数倍,32位数据起始地址是4的整数倍,64位数据起始地址是8的整数倍
如果不对齐存放,像x86处理器,如8086,16位数据从奇地址开始放照样可以处理,只是速度会变慢,如果对齐一个总线周期就能够完成,如果不对齐得花两个总线周期。时间变长,但是功能照样能实现
这里也体现出CISC结构处理器对软件要求不是很高,硬件能干的活尽量硬件都干了,有一些RISC结构的处理器就要求数据在内存里面必须对齐存放,不对齐指令就无法执行,不同的CPU处理方式不一样
现在计算机内存并不是用SRAM来构成的,包括最早的个人计算机内存也是用DRAM构成的。讲课用SRAM是因为这个简单,因为它从信号上来讲有独立的地址线数据线读写信号和片选,可以直接连接到系统总线,电路包括控制方式最简单
用SRAM构成单片机内存完全够用。如51单片机芯片内部会集成一定容量的内存,就存储一些临时变量用的,如果太小外面可能还要再扩展内存,扩展内存一般不大
如果用DRAM构成内存,进行一次读写地址得分两次来送,先送一个行地址,再送一个列地址,然后才能读写,还有定时刷新。DRAM后来发展出现了SDRAM(同步动态随机访问存储器),再发展出现了双倍速的SDRAM就是DDR的SRAM,现在主流用的比较多的是DDR4
这种双倍速的SDRAM在读写时时序更复杂,对它进行读写首先要发激活命令,同时送行地址。发激活命令相当于把它里面的某一行打开,然后把这一行的所有内容读到行缓冲区中,然后再给它发相应的读写命令,同时给它列地址,对打开的行缓冲区进行读写。在访问其他行之前要把当前这一行关闭,也就是把行缓冲区的内容回写到原来的位置,这要给它发一个预充电命令
SDRAM存储器在控制时涉及到很多比较复杂的命令,没有办法直接连接到系统总线。一般要设计一个比较复杂的电路现在都会有一些现成的芯片,或者说现成的IP核可以直接用。你可以理解成CPU系统总线上必须要通过一个SDRAM控制器间接地才可以访问到SDAM。从这个角度来讲,现在计算机的内存其实和外设很像,CPU通过相应的接口访问,而不是直接访问,实现的电路非常复杂
现在的内存,如DDR的SDAM在进行读写时采用突发的读写方式,一次突发读写传送几个数据,并不是随机访问。CPU内核要取得某一个数据最终从CPU内部的Cache得到,数据如果在内存中对齐存放,最终以块为单位装载到Cache内,它在Cache内也是对齐存放的。CPU内核可以直接访问Cache,Cache就是用SRAM实现的
计算机的存储器现在分层较细,如果只算寄存器组,控制器和运算器之外的那些存储器,最顶层的是用SRAM构成,可以直接访问的Cache,再往下是用DDR的SRAM实现的主存,再往下有一些计算机有如Intel的奥腾存储器的介于主存和固态硬盘之间的层次,再往下是固态硬盘,再往下是机械硬盘
除了用基本的逻辑门和3-8译码器,也可以用ROM作译码器。ROM能根据输入选中对应存储单元并输出该存储单元的内容
现在要用4片6264构成一个存储容量为32KB的8位存储器(字扩展),其地址空间为E0000H~E7FFFH。用一块512×4(即512个存储单元,每个存储单元为4位)的PROM芯片63S241作为ROM译码器
![]()
给单向信号(A0∼A12,MEMR―,MEMW―)和双向数据信号(D0∼D7)加驱动
CPU没有访问内存时MEMR―,MEMW―均为高电平,经过与门之后输出是高。ROM芯片片选和读信号都是高电平,数据线输出是高阻。高阻就是电阻无穷大,相当于4片6264芯片的片选信号悬空哪都没有接,输入引脚是高电平还是低电平是不定的。加上拉电阻能保证这4根线输出高阻时仍然会呈现高电平状态
![]()
也可以用数据比较器作译码器
两路8位输入数据相等,输出低电平。否则输出高电平
![]()
一路输入直接接开关置于固定状态。开关断开时由于上拉电阻呈现高电平,闭合时相当于把这根线通过开关接地,这根线就是低电平
另一路接到系统总线的高位,不用的线也直接接高电平。高位地址和开关拨的状态一样时才会输出低电平选中这个芯片
数据线还是要加双向驱动
![]()
也可以用PLD作译码器。知道有这种办法就可以了
SRAM设计举例1:
现有容量为 8K×8bit 和 4K×8bit 的SRAM芯片。在8086系统中,
1.利用这样的芯片构成地址范围为C2000H~C7FFFH的内存,画出最大模式下包括总线驱动在内的此芯片与系统总线的连接图(译码器件自行选择,尽量选择容量大的芯片)
2.试编写8086汇编语言程序,从地址C2000H开始,依次写入数据,直到地址C7FFFH。要求数据从0开始,每写入一个字节后数据加1,即写入数据依次为:00H、01H、02H、03H、… 、FEH、FFH、00H、01H、…… 。然后逐个单元读出比较,若有错,则在DL中写入01H,退出检测;若每个单元均对,则在DL写入00H
顺便介绍了下检查内存的几种方法和原理
首先确定要用多少片芯片
C8000H-C2000H=6000H,即24K
尽量选择容量大的芯片,首先要用8K×8bit的芯片。但考虑到要构成8086的内存,如果用8位的SRAM必须是偶数片,2片8位的SRAM位扩展之后才能够构成1个16位的存储器。折中一下:
需要8K×8bit芯片2片、4K×8bit芯片2片
8K×8bit芯片地址线:A0∼A12,数据线:D0∼D7
4K×8bit芯片地址线:A0∼A11,数据线:D0∼D7
考虑内存地址译码电路应该有几个输出
作为8086的内存来讲,每2片8位芯片位扩展之后构成1个16位的存储器,各对应地址译码电路的1个输出。所以应该有2个输出
然后根据地址范围分析内存地址译码电路应该怎么设计
C8000H-C2000H 16进制地址的低3位从全0到全F,所有组合都有,可以不用考虑,直接分析高8位地址C2~C7
先看经过位扩展之后构成一个16位存储器的2片8K×8bit的芯片,它的内部地址应该是什么
8K×8bit芯片地址线是A0∼A12,16位存储器要给字的地址。所以连系统总线时从A1开始连,连接系统总线的A1∼A13。下图的表格中每一行低12位地址A0∼A11是任意的,对应4KB,2片8KB的芯片位扩展之后总容量是16KB,对应前4行。前4行对应内存地址译码电路的1个输出,用来选择这2片8KB的芯片
后2行对应另外一个输出,选择的是2片4KB芯片位扩展之后的16位存储器
内存地址译码电路的输入应该是高位地址,A13虽然是SRAM内部地址的高位,也要参与地址译码,这样才能保证不参与地址译码的A0∼A12能包含全0到全1的所有组合
![]()
然后画具体电路
首先画SRAM芯片
先画2片8KB的芯片。第一片8KBSRAM芯片的引脚首先是数据线D0∼D7,这8根线直接连8086系统总线的低8位D0′∼D7′,这样连它就是偶地址存储体。然后地址线A0∼A12连8086的系统总线A1′∼A13′(注意从A1′开始连)。读信号OE―连内存读MEMR′―,写信号WE―连内存写MEMW′―。最后一个是片选CS―,偶地址存储体要被选中应该有一个或门,或门的输出是它的片选,或门的一个输入是偶地址存储体的选择信号A0′,另外一根线接地址译码电路的第一个输出
片选和地址译码电路的输出有关,可以留到最后画
第二片8KBSRAM芯片作为奇地址存储体,或门的输出是它的片选,或门的输入是奇地址存储体的选择信号BHE′―和和第一片相同的地址译码电路输出,数据线D0∼D7连接系统总线数据线高8位D8′∼D15′,地址线,读信号OE―,写信号WE―的连法和第一片一样
因为2个芯片是位扩展的,这2个芯片受地址译码电路同一个输出的控制。所以为了画起来方便下图把这个芯片的片选画在上面2个挨着
再看2片4KB的芯片,画法几乎一样。同样数据线8根线D0∼D7一个作为偶地址存储体连系统总线的低8位D0′∼D7′,一个作为奇地址存储体连系统总线的高8位D8′∼D15′。地址线12根线A0∼A11连系统总线A1′∼A12′。读信号OE―和写信号WE―所有芯片的连法都一样。片选的套路也一样,用或门输出,输入端是A0(偶地址存储体)或BHE′―(奇地址存储体)和地址译码电路的另外一路输出
再画内存地址译码电路
限定高位地址要满足的规律。按照刚才的分析,内存地址译码电路的输入应该从A13′开始一直到A19
上表中A15,A14,A13′这3根线一共就3种组合,用3-8译码器74LS138实现较方便,分别接C,B,A这3根线。2种组合对应Y1―和Y2―,Y1―和Y2―任何一个输出低电平,地址译码电路的第一路输出都应该是低令2片8KB芯片的片选有效,故Y1―和Y2―这2根线经过一个与门之后合成一个信号输出。Y3―是另外一路输出,用来选中2片4KB的芯片
画的时候如果不希望线连的太长,可以给输出信号起名字(如下图的CS8K表示8KB芯片的片选信号),另一边起相同的名字,默认两根连在一起
高4位地址A16∼A19限定上表的条件就可以。高2位地址A19,A18都得是高电平,用一个与门接到高有效的允许G1。A17,A16都得是低电平,用或门接到低有效的允许G2A。此外这是一个内存地址译码电路,只有当CPU访问内存时它输出才有可能是低电平,此时内存读MEMR′―和内存写MEMW′―必然有一个是低电平,经过一个与门接到低有效的允许G2B
不用的Y―可以不画
如果要求画驱动,则还需要再增加一些东西驱动那些接了好几处的信号
驱动单向信号A0∼A13,BHE―,MEMR―,MEMW―用单向驱动器74LS244,允许接地令其永远有效
驱动双向数据总线D0∼D7用双向驱动器74LS245。需要2片,一片A边接系统总线低8位D0∼D7,B边是驱动后的D0′∼D7′,把需要通过低8位数据线传输数据的芯片的片选信号CS1―和CS3―加一个与门接到其输出允许OE―。一片A边接系统总线高8位D8∼D15,B边是驱动后的D8′∼D15′,把需要通过高8位数据线传输数据的芯片的片选信号CS2―和CS4―加一个与门接到其输出允许OE―。方向控制DIR都接内存读MEMR′―
经过驱动的信号可以加一撇
![]()
在这个基础上编写汇编程序
如果按8位字节来写和比较。首先初始化段寄存器DS和指针寄存器DI,循环次数放到CX,每次写入的数据内容放在AL,初值为0。然后循环,每写一个数据DI和AL的内容加1指向下一个字节。再循环比较,循环之前的准备基本和上面一样,初始化指针寄存器SI,循环次数放到SI,比较的数据内容放在AL。比较过程中如果发现不一样就跳转到错误程序,如果一样则AL和SI加1继续循环,如果循环正常退出说明所有单元正确,置一个正确标志后跳到最后
如果按16位字,在刚才的基础上稍微改一点。循环次数减半,每次写入的数据内容放在AX,初始低8位是全0高8位是全1。每次循环写入后DI加2指向下一个字,AX低8位和高8位分别加2。比较时也类似
![]()
只读存储器 (ROM) 及接口设计
非易失性存储器,掉电之后内容不丢失
紫外线可擦除只读存储器EPROM
这里对一些应该不太重要的硬件细节记得比较简略
![]()
若利用全地址译码将EPROM2764接在8088内存首地址为A0000H的内存区,试画连接图
![]()
擦除时用紫外线照石英窗口15∼20min,擦干净时每单元里内容均为FFH,编程写入时把期望变成0的那些位变成0
![]()
例:利用2732(8K×8bit SRAM,A12∼A0)和6264(4K×8bit EPROM,A11∼A0)构成从00000H~02FFFH的ROM存储区和从03000H~06FFFH的RAM存储区。画出与8088系统总线的连接图。(不考虑板内总线驱动)
ROM区:(2FFF+1) / 400 = C,共12KB → 需3片
RAM区:4000 / 400 = 10,共16KB → 需2片
![]()
![]()
如果将SRAM芯片改成8K×4bit,则
![]()
电可擦除只读存储器EEPROM (E2PROM)
![]()
98C64写之前不需要擦除,直接给写的时序就能够把原来的内容覆盖掉写入新的数据
读的时序和SRAM,EPROM都一样,主要看怎么写入
下图是一个写的时序,在整个写的过程中读信号OE―必须无效,首先A12∼A0这13根地址线给地址选中内部的某一单元,整个过程中片选信号CE―有效选中该芯片。然后D7∼D0数据线上给要写的数据,地址数据稳定后在写信号WE―上给负脉冲,该负脉冲的最小宽度是100ns。在负脉冲的上升沿把地址还有数据写入到芯片内部的一个缓存,上升沿结束之后,芯片内部才真正开始把数据写入到指定的单元,这个写的过程是比较慢的,大概需要5∼10ms,忙信号READY/BUSY―会输出低电平,READY/BUSY―再次变成无效时数据才真正写完
![]()
用98C64构成8088的内存
![]()
把芯片内部所有的单元写入55H
![]()
如果想要提高效率,可以设计一个输入接口读READY/BUSY―信号当前的状态,如果为低电平忙则等待,如果为高电平不忙就马上写下一个数据。把READY/BUSY―信号通过一个三态门连接到数据线,CPU要查询这根线时三态门才打开把状态输出到数据线上,以防止总线竞争
控制端控制这个三态门什么时候该打开,什么时候该关闭。如果把这个输入接口映射到内存地址空间就给内存地址译码电路,要映射到接口地址空间就给接口地址译码电路。下图显然是接口地址译码电路
READY/BUSY―是一个漏极开路的引脚,输出应该加上拉电阻。此外下图还加了一个不太重要的滤波电容
这里和下一章有点关系。可以先看后面,回头再看会比较好理解
![]()
这样原来的延时程序就可以改成查询方式。通过IN指令从内存地址7000H读进8位数据到AL,最低位即反映READY/BUSY―信号的状态。再用TEST指令将AL高7位清0(只影响标志位,不回送结果),若结果为0,说明READY/BUSY―信号为低电平,芯片正忙,则跳转继续循环等待。直到芯片真正把数据写入到对应单元,READY/BUSY―变为高电平,结果为1时才不再跳转顺序执行下面的指令
![]()
然后讲了下为什么要把忙信号设计成漏极开路
闪速E2PROM : Flash
对于E2PROM,需要快写必须一次写一页,按字节写速度慢。编程时间长、容量小
Flash : 容量大,编程速度快。成本低、密度大。应用广泛
本章后面的内容都是了解性的,可以自己看对应的录播(10.18后半节)和课件
输入/输出技术
程序查询 I/O 方式
无条件传送方式
有一些最简单的外设不需要查询,可以随时给它发命令,随时读它的状态,这种外设可以采用无条件传送的方式
输入:开关、…
输出:发光二极管、继电器、步进电机、…
输入设备
![]()
下图中外设是开关,10K的上拉电阻经过开关接地,电容起到消抖的作用。要读该外设的状态,不能直接连接到系统总线,要经过三态门以避免总线竞争
CPU要访问该外设时才允许把这根线的状态输入到系统总线的某一根数据线上,否则这根线应该和系统总线没有任何关系
74LS244有8个三态门,我们只需要接到其中某一个的输入,该三态门的输出接到系统总线数据线的最低位D0
三态门的控制端,允许信号OE―接一个或门。或门的一个输入端接接口读信号IOR―,另外两个输入端接译码的输出,译码的输入是低16位地址线
下图连的是8088的总线。但不管是8086还是8088访问接口都只需要用到低16位地址线
这里简化了AEN信号,AEN应为低电平表示CPU在控制总线而不是处在DMA状态
不难得接口地址是FFF7H。有了该接口地址之后可以写一段汇编程序。首先接口地址FFF7H传送到DX,因为通常不管是IN指令还是OUT指令都要求接口地址得在DX,然后执行IN指令,从地址为FFF7H的接口读8位数据到AL,AL的最低位反映的就是开关的状态。接下来用AND指令将高7位清0,如果结果为0说明A开关闭合,跳转到ON标号执行,否则说明开关断开,跳转到OFF标号执行
![]()
输出设备
![]()
下图中反相器加发光二极管加限流电阻是一个外设,总共有8个外设。虽然直接连到系统总线的数据线不会造成总线竞争,但是系统总线是分时使用的公共信号线,故必须要接具有存储能力的锁存器
锁存器74LS273的输出Q0∼Q7接8个外设,输入D0∼D7分别接系统总线数据线的D0∼D7
锁存信号(写信号)CLK接一个或门。或门的一个输入端接接口写信号IOW―,另外两个输入端接接译码的输出,译码的输入是低16位地址线
不难得接口地址是0000H。具体的控制程序先把接口地址送到DX,然后把要往接口写的数据送到AL,再执行OUT指令把数据写入锁存器,其输出在下次改写前都保持不变
![]()
刚才针对的都是8088的8位总线,现在要设计16位总线的8086的接口
下图中有16个外设,用2片74LS273构成一个16位的接口
上面的74LS273作为偶地址存储体,输入D0∼D7连系统总线数据线的低8位D0∼D7,译码时加A0必须为低电平的条件
下面的74LS273作为奇地址存储体,输入D0∼D7连系统总线的高8位D8∼D15,译码时加BHE―必须为低电平的条件
用3-8译码器做接口地址译码,输入为地址A1∼A15和IOW―
不难得偶地址存储体的地址为3804H,奇地址存储体的地址为3805H。程序首先做偶地址8位写。把偶地址存储体的地址放在DX,然后把要写入的数据放在AL。再执行OUT指令,该指令执行时用的是8位的AL,是8位接口写,并且接口地址是偶地址,会把数据写入到上面的74LS273,不会影响到下面的74LS273
然后做奇地址8位写和16位写
![]()
查询方式
![]()
查询方式的基础是必须要有能读取外设当前状态的输入接口,根据外设的不同状态决定应该对外设采取什么样的操作
下图中外设引脚有8根数据线D0∼D7,锁存信号(写信号)STB―,忙信号BUSY。忙信号为高电平则等待,忙信号为低电平则把要写入的下一个数据放在8根数据线上,当数据稳定之后在STB―给一个宽度大于100μs的负脉冲,在负脉冲的上升沿把数据写入到外设。写入的数据内部需要花一定时间处理,一旦写完则BUSY马上变为高电平。当忙信号再次变为低电平,说明上一个数据已经处理完,然后再重复上面的过程
![]()
现在要设计基于该外设的接口
要设计输出接口来给外设提供8位数据和锁存信号,输入接口读外设BUSY信号当前的状态。输出接口用锁存器实现,输入接口用三态门实现
第一个输出接口要提供8位的数据,需要一个74LS273,一边D0∼D7接系统总线数据线D0∼D7,一边Q0∼Q7接外设,CLK接一个或门,或门的一个输入端接IOW―,另外一端接地址译码电路的一个输出
另一个输出接口的74LS273只用到其中的一位,其输入接某一根系统总线数据线,输出接STB―,CLK接一个或门,或门的一个输入端接IOW―,另外一端接地址译码电路的一个输出
输入接口的74LS244只用到其中的一个三态门,其输入接BUSY,输出接某一根系统总线数据线。OE―接一个或门,或门的一个输入端接IOR―,另外一端接地址译码电路的一个输出
再用3-8译码器实现接口地址译码电路,需要的3个输出为Y0―∼Y2―,输入为低16位地址A0∼A15
不难得Y0―∼Y2―对应的接口地址分别为02F8H,02F9H,02FAH
![]()
编程首先把段的起始地址的高16位D200H通过通用寄存器传到DS,然后用寄存器间接寻址就可以访问到内存从这个单元开始的这些数据。指针寄存器可以是BX,SI,DI,这里用BX,将BX初值置为0。循环次数1000放在CX
初始化STB―,STB―写时给负脉冲,不写时应该是高电平。OUT指令把AL的内容01H写入到接口地址02F9H对应的中间的74LS273令Q0=1,将STB―置为高电平为后面写数据做准备
判断BUSY的状态。IN指令读地址为02FA的接口,读取的数据放在AL。再用AND指令将低7位清0只保留最高位。如果结果不为0,说明BUSY为高电平,就跳转回上面再读,一直循环到结果为0,BUSY变为低电平才顺序执行后面的指令
数据输出。利用寄存器间接寻址,DS为默认段寄存器,BX存段内偏移,从内存D2000H取数据放在AL。OUT指令将该数据写入接口地址02F8H对应的上面的74LS273,给外设提供数据
数据已经准备好,将STB―置为低电平,延时100μs后再将STB―置为高电平。在STB―的上升沿将数据写入到外设
写完之后BX内容加1指向内存的下一个单元,然后继续循环。总共循环1000次,每次都先判断BUSY忙则等待,不忙再写下一个数据
![]()
然后引申讲了下输出接口和输入接口占用同一个接口地址等简化软硬件的方法
多外设的查询控制
这种方式不好。因为如果某一个外设坏了永远处于没准备好的状态,CPU就会老是等待,其他外设也永远得不到服务
![]()
这种方式有优先级的概念,会偏向认为先查询的外设更重要
![]()
如果不需要优先级,机会均等。采用这种方式
![]()
中断方式
x86处理器处理中断的过程在第二章讲CPU引脚时已经介绍过,可以查阅当时的笔记。这里介绍来自INTR引脚的中断请求,一般对应的都是外设或接口的中断请求
![]()
假设CPU执行到某条指令,通过INTR引脚来一个中断请求。这种情况下若满足中断响应的条件:标志寄存器中中断允许标志位IF为1处于开中断状态,当前这条指令执行完才会响应中断请求
首先要保护当前的断点,依次将Flags,CS,IP的内容压入堆栈,并将标志寄存器中的中断允许标志位IF和陷阱标志位IF清0关中断,这样再从这个引脚来中断请求CPU就不会响应了
标志寄存器教材叫程序状态字PSW,即下图的Flags。子程序调用则不需要保护Flags的内容
1413:0105表示内存地址,左侧是段寄存器的内容,右侧是段内偏移
然后CPU会通过INTA―连续送出两个负脉冲。8259接收到第一个负脉冲就知道CPU正在响应刚才的中断请求,它会准备好发出中断请求的中断源的8位中断向量码,等第二个负脉冲来时将其放在低8位数据线上让CPU采样得到
CPU会根据中断向量查从内存地址0开始放的中断向量表的对应行,获取对应的中断服务程序的入口地址。中断向量表每一行4个字节,前2个字节存段内偏移赋值给IP,后2个字节存段寄存器的内容赋值给CS,下一条指令就会跳转到从中断服务程序的第一条指令的地址开始取并执行
注意是小端存储,小地址对应低字节,大地址对应高字节
中断服务程序的结构和子程序很像,也要保护现场,将要修改的控制寄存器的内容先压入堆栈,用完之后再恢复现场,然后再中断返回。执行中断返回指令IRET时会从堆栈弹出3个数恢复Flags,CS,IP,返回到刚才被打断的指令的下一条指令继续执行
CPU硬件在响应中断时会自动关中断。如果中断服务程序允许中断嵌套,在保护现场之后加开中断指令STI,恢复现场之前再用关中断指令CLI
![]()
![]()
这里内部中断理解成中断源在CPU内部,跟调试无关的那些中断,如除法错误中断。跟调试有关的那些中断,如单步中断和断点中断通常优先级最低
可编程中断控制器8259
可对8个中断源实现优先级控制
支持多片级联,一个主片可以有8个从片,可扩展至对64个中断源实现优先级控制
可编程设置不同工作方式
根据中断源向x86提供不同中断类型码
可编程就是该芯片内部有一些寄存器,往寄存器里面写入不同的内容就可以具有不同的功能,可以工作在不同的模式下
8259内部结构
![]()
8259的引脚:
中断源中断请求输入IR0∼IR7
双向数据总线D0∼D7
中断请求INTR,中断应答INTA―
读信号RD―,写信号WR― : 要对内部寄存器进行读写,读写时传数据通过8根数据线
片选信号CS― : 支持多片级联,要看访问哪一片
地址A0 : 8259只有一根地址线,只需要占用2个接口地址
上图中还有4个引脚,这几个引脚和级联有关,如果只是单片使用用不上
需要了解3个寄存器:
中断请求寄存器IRR (INTERRUPT REQUEST REG):保存从IR0∼IR7来的中断请求信号,某位=1表示对应的IRi有中断请求
中断屏蔽寄存器IMR (INTERRUPT MASK REG):存放中断屏蔽字,某位=1表示对应的IRi输入被屏蔽
中断服务寄存器ISR (IN - SERVICE REG):保存正在服务的中断源,某位=1表示对应的IRi中断正在被服务
中断优先权判别电路 (PRIORITY RESOLVER): 确定是否向CPU发出中断请求,中断响应时确定ISR的哪位应置位及把相应中断的类型码放到数据总线上
下图中即表示8086/8088 CPU正在执行IR6和IR4两个引脚所对应的中断源的中断服务程序,CPU同时执行两个中断源的中断服务程序,很显然发生了中断嵌套。引脚IR2,IR3,IR5同时发中断请求,作为8259如果是固定优先级,编号小的优先级高。考虑到IR2被屏蔽,且IR3优先级高于IR6和IR4,8259会通过INT向CPU发一个IR3的中断请求
CPU通过一系列过程响应中断,再通过INTA―给8259送连续2个负脉冲。8259接收到第一个负脉冲后,因为CPU马上要执行到IR3对应的中断源的中断服务程序,会将ISR的第3位置1,IRR的第3位清0
CPU在中断服务程序执行完之后通知8259可以将ISR的相应位清0。在中断服务程序的最后恢复现场之前要给8259发一个EOI中断结束命令。要实现EOI功能可能需要3条指令,先将8259的偶地址(8259只有一根地址线,地址线给0是偶地址,给1是奇地址)放到DX,要写入的内容放在AL,再用OUT指令把AL的内容写入到DX所指向的接口
MOV DX,8259偶地址
MOV AL,20H
OUT DX,AL
写的数是20H,是一般EOI命令。允许中断嵌套并且是正常优先级的情况下就会在在中断服务程序的末尾向8259发一个一般EOI命令。8259接收到命令后将ISR中优先级最高的那一位清0,因为有正常优先级概念的情况下,如果允许中断嵌套,最先执行完的中断服务程序肯定是优先级最高的
![]()
![]()
8259工作方式
![]()
![]()
缓冲方式可以设成非缓冲和缓冲。如果设置成工作在缓冲方式,双向数据线需要加一个74LS245驱动器,其OE―信号由8259的SP―/EN―作为输出引脚提供。如果没有工作在缓冲模式下,SP―/EN―作为输入引脚让多片级联时8259可以知道自己是主片还是从片,其接到高电平为主片,接地为从片
书上后面的例子都没有让8259工作在缓冲模式下
中断是否允许嵌套即中断程序是否允许被优先级更高的中断源打断。如果不允许中断嵌套就设置中断结束方式为自动EOI方式。在接收到中断应答的第二个负脉冲时就会将ISR的内容清0,此时可以简单地认为ISR的内容总是0,不会记录CPU正在执行哪一个中断源的中断服务程序,所以也就无法实现带优先级的各种中断嵌套。这样在编写中断服务程序时就不用加STL指令,末尾也不需要向8259发EOI命令
屏蔽方式可以设成一般屏蔽和特殊屏蔽。一般屏蔽就是正常优先级的概念,即如果CPU正在执行某一个中断源的中断服务程序,同级的和优先级更低的中断源是不能打断当前的中断服务程序的,这样在中断服务程序的末尾要向8259发一个一般EOI命令。如果设置成特殊屏蔽方式就没有优先级的概念,只要不是同级的,任何一个其他的中断源都可以打断当前的服务程序,究竟哪一个中断服务程序最先执行完不一定, 这样在中断服务程序的末尾要向8259发一个特殊EOI命令,里面包含清0的那一位的编号,明确告诉8259应该把ISR的哪一位清0
教材上后面的例子都让8259工作在一般屏蔽方式
刚才举的这些例子都默认8259工作在固定优先级,优先级顺序从高到低为IR0∼ IR7,还可以设置成循环优先级
自动循环优先级:
中断源轮流处于最高优先级,即自动中断级循环
初始优先级顺序可由编程改变
某中断请求IRi被处理后,其优先级别自动降为最低,原来比它低一级的优先级上升为最高级
![]()
指定循环优先级:
优先级排列顺序可编程改变
加电后8259A的默认方式,默认优先级顺序从高到低为IR0∼IR7
![]()
最后看8259是否需要多片级联。如果不需要级联单片工作设置成一般嵌套方式。如果是多片级联主片设置成特殊嵌套方式,从片设置成一般嵌套方式
8259级联:
单片8259A可支持8个中断源
采用多片8259A级连,可最多支持64个中断源。n片8259A可支持7n+1 (n≤9) 个中断源
级联时只有一片8259A为从片,其余的均为从片。只有主片有能力向CPU发中断请求。从片的中断请求连到主片的某一个IRi引脚,从片所有引脚发的中断请求都得从该引脚走,从片再向主片发中断请求,主片再向CPU发中断请求
涉及到的8259A引脚包括:CAS0−CAS2,SP―/EN―,IRi,INT
通过SP―/EN―引脚8259得知自己是主片还是从片,其接高电平是主片,接地是从片。ICW3写什么内容和级联状态下怎么连有关系,通过初始化过程向ICW3写入适当的内容,让主片知道IRi引脚接的是从片还是中断源,让从片知道接的是主片的IRi引脚
8259有4个初始化命令字ICW1∼ICW4,还有3个操作命令字OCW1∼OCW3。OCW1其实就是IMR,所以8259内部总共有9个寄存器
连电路时INTA―接主片和从片,所有8259都能接收到CPU从INTA―发来的两个连续负脉冲。主片通过INTA―接收到第一个负脉冲后会对ISR和IRR置位。主片替IRi向CPU发中断请求,就会通过CAS0∼CAS2这3根线送级联地址i给两个从片,两个从片在中断应答的第一个负脉冲会检查这3根线的状态与ICW3内容作比较,一致则对ISR和IRR置位,并在第二个负脉冲来时提供中断向量
![]()
一般嵌套方式与特殊全嵌套方式的区别:
![]()
主片能够区分引脚哪一个接中断源,哪一个接从片。只有接从片的引脚才允许同级的中断源打断当前的中断服务程序
8259编程使用
内部寄存器的寻址方式:
需要CS―,A0,RD―,WR―和D4,D3的配合。内部寄存器的访问方法如下表
![]()
为了能够区分内部究竟访问的是哪一个寄存器,写入数据的某一位在8259内部也是当地址来用的
如8259要能正常工作必须要有初始化的过程,往4个ICW里写入事先设计好的内容。首先要写ICW1,ICW1对应的是8259的偶地址,即A0=0的情况。所以如果想要初始化8259,第一步就要往8259的偶地址里写入D4位为1的一个数据
Icw1的结构如下。D2和D5∼D7这几位没有用到,LTIM表示IR0∼IR7这8根线是高电平还是上升沿有效,SNGL表示是单片工作(级联控制字ICW3不需要写)还是多片级联,IC4表示是否要写ICW4
![]()
一旦ICW1被写就启动了一个初始化的过程,紧接着要马上写后面这几个ICW,往奇地址里面连续写入若干个数:
若现在写ICW1,将其配置成多片级联并且要写ICW4就要写3个数,分别自动写入到ICW2∼ICW4
如果写的内容规定是单片工作且要写ICW4,就要写2个数,分别自动写入到ICW2和ICW4
如果写的内容规定是单片工作且不要写ICW4,就要写1个数,到ICW2
![]()
一旦初始化的过程完成之后,后面这些OCW随时都可以写,按什么顺序写都无所谓,写不写都可以
电路连好后怎么检查8259能否正常工作,或者说它的寄存器能否正常读写?
OCW1是8259内部唯一一个既可以写又可以读的寄存器,它对应奇地址
初始化完之后往8259的奇地址里面写入全0,再读出来比较一下是否为全0。再写入全1,读出来比较一下是否为全1。如果都对就认为8259内部的这些寄存器能够正常写入,数据线和地址线的连法应该也没有问题
ICW1:初始化字
上面已经进行了说明
ICW2:中断向量码
![]()
ICW3:级联控制字
![]()
ICW4:中断结束方式字
![]()
OCW1:中断屏蔽字
![]()
OCW2:中断结束和优先级循环
![]()
OCW3:屏蔽方式和读出控制字
![]()
中断方式实现方法
1.8259连接(硬件)
若要连接到8086的系统总线。8259地址线只有一根,占用2个接口地址,如果想把它映射到偶地址上,或者说作为一个偶地址存储体,其8根数据线要连接到系统总线数据线的低8位。A0是偶地址存储体的选择信号,地址线从A1开始,故这块应该连到A1上,A1作为芯片的内部地址,高位地址从A2开始
如果要映射到偶地址最好让A0也参与译码,限定A0是0。下图中因为A0没有参与译码其实应该占用4个接口地址FF00H∼FF03H,但实际上如FF00H和FF01H这两个地址中只能用FF00H,因为FF01H对8086来讲是奇地址,8086不管是访问内存还是接口,如果访问的是奇地址就会通过高8位的数据线来传递数据。所以如果你用FF01H这个地址读8259的某一个寄存器,IN指令执行时8086只会采样数据线的高8位,虽然8259芯片已经输出了寄存器的内容,但它放在了数据线的低8位,得不到数据
所以我们在连数据线时这8根线连接到系统总线的低8位,8086在访问该8259芯片时就必须要用偶地址,用奇地址访问不到芯片内部的寄存器。FF01H和FF03H这2个接口地址虽然被占用但是不能用,如果不想浪费,就应该加限定A0是0的条件,这样电路就只占用2个接口地址,对于8086来讲这两个都是偶地址,对于8259来讲,FF00H是8偶地址,FF02H是奇地址
如果计算机中有DMA存在,应该有限定AEN―是低电平的条件
![]()
2.编写初始化程序:8259初始化,设置中断向量表
在有了硬件的基础上。计算机刚一加电启动的过程中,通常由BIOS程序负责对8259的ICW写入事先设计好的内容来进行初始化让它工作在期望的模式下
初始化8259:
SET59A:MOV DX,0FF00H ;8259的地址A0=0MOV AL,13H ;写ICW1,边沿触发,单片,需要ICW4OUT DX,ALMOV DX,0FF02H ;8259的地址A0=1MOV AL,48H ;写ICW2,设置中断向量码OUT DX,ALMOV AL,03H ;写ICW4,8086/88模式,自动EOI;非缓冲,一般嵌套OUT DX,ALMOV AL,0E0H ;写OCW1,屏蔽IR5、IR6、IR7;(假定这3个中断输入未用)OUT DX,AL
下例检查硬件电路能否正常工作,可以认为和前面的初始化没有关系
;将00H与FFH分别写入IMR,并将其读出比较
MOV DX,0FF02H
MOV AL,0
OUT DX,AL ;写OCW1,将00H写入IMR
IN AL,DX ;读IMR
OR AL,AL ;判断IMR内容为00H否
JNZ IMRERR
MOV AL,0FFH
OUT DX,AL
IN AL,DX
ADD AL,1
JNZ IMRERR
设置中断码:
中断向量码初始化位48H,中断处理程序入口地址的标号为CLOCK,设置中断向量表
法1 直接写中断向量表
INTITB: MOV AX,0MOV DS,AX ;将内存段设置在最低端MOV SI,0120H ;n=48H, 4×n=120HMOV AX,OFFSET CLOCK ;获取中断处理程序首地址的段内偏移地址MOV [SI],AX ;段内偏移地址写入中断向量表4×n地址处MOV AX,SEG CLOCK ;获取中断处理程序首地址的段地址MOV [SI+2],AX ;段地址写入中断向量表4×n+2地址处
法2 利用DOS功能调用
MOV AH,25H ;功能号
MOV AL,48H ;中断向量码
MOV DX,SEG CLOCK
MOV DS,DX ;段地址→DS
MOV DX,OFFSET CLOCK ;偏移地址→DX
INT 21H
3.编写中断处理程序
中断嵌套的实现:
保护现场 (PUSH reg’s)
开中断 (STI)
中断服务
…
中断服务
关中断 (CLI)
产生EOI命令
恢复现场 (POP reg’s)
中断返回
产生EOI命令:
上例初始化时设置成自动EOI模式,所以中断服务程序的末尾没有必要向8259发EOI命令。如果允许中断嵌套,工作在一般EOI方式,往8259偶地址中写入20H相当于发一个一般EOI命令,8259会把ISR置1位中优先级最高的那一位清0
![]()
中断方式实现示例
![]()
初始化8259:SET59A
初始化中断向量表:INTITB
中断处理程序:CLOCK
![]()
假设在内存中有连续这么几个字节的数据,第一个字节由标号TIMER指向,存1/50秒的信息,下一个字节存秒的信息,再下一个字节存分钟的信息,最后一个字节存小时的信息。并且后三个字节的内容采用压缩的BCD码的形式存,1/50秒直接用二进制的形式存
DAA指令会根据当前标志寄存器里面的一些信息决定要不要加6修正
![]()
![]()
![]()
DMA的过程之前讲过,DMA控制器8237不具体讲
可编程8237芯片有4个通道,可以实现内存到接口,内存到内存之间的数据传送,但是不能实现接口到接口之间的数据传送
到此这章的内容就结束了。后面还讲了下TSR时钟显示程序和比较新的计算机如何实现中断和DMA
常用接口器件
思考:计算机和外设之间如何通过接口传送数据(非DMA)?
最简单的方式是上一章讲的程序查询或者说直接控制
想读输入设备当前的状态,通过三态门实现接口。给三态门接口地址,只有用IN指令读地址为这个的接口时,三态门才打开把外设的状态输出到系统总线数据线,IN指令最后采样数据线把外设的状态读到CPU内部寄存器
用OUT指令输出数据,数据只在OUT指令执行的瞬间呈现在数据线上,所以输出接口需要用锁存器实现存储功能
下图中输入接口只能读不能写,只需要IOR―信号参与地址译码。输出接口只能写不能读,只需要IOW―信号参与地址译码
![]()
这种方式CPU利用率较低,大部分时间都花在不停地循环查询外设。如果想要提高CPU的利用率,外设或者说接口能够引入中断功能,外设不忙需要CPU参与时再给CPU发中断请求
输出接口里有可以暂存数据的缓冲寄存器,可以判断该寄存器内容是否为空,即数据是否已被外设取走。如果为空应该向通过INTR―信号向CPU发中断请求通知CPU缓存已空,能否写入新的数据。CPU经过一定过程响应中断,最终进入中断服务程序,中断服务程序把要传输给外设的下一个数据写入到接口内部的缓冲寄存器,写完直接返回。接口检测到缓冲寄存器写入新数据,将OBF―信号置低通知外设拿走数据,外设采样数据线拿走数据处理完后通过ACK―信号发一个负脉冲通知接口数据已被取走。接口将OBF―信号置高,同时再次向CPU发中断请求重复刚才的过程
输入接口里也有可以暂存数据的寄存器,可以通知外设缓冲寄存器内容为空可以写下一个数据。外设通过数据线提供数据,数据稳定后通过STB―信号发一个负脉冲,在负脉冲的上升沿把数据写入到接口的暂存器中。接口写入新数据后把IBF信号置高表示输入缓冲区满,通过INTR―信号向CPU发中断请求,CPU响应中断进入到中断服务程序,从接口把数据读走。接口将IBF信号置低,重复刚才的过程
ACK―和STB―不是状态信号而是脉冲信号
![]()
设计双向的具有中断功能的输入/输出接口,结合上述两种情况
输入/输出接口内部有2个寄存器,从CPU角度一个只能写不能读一个只能读不能写,可以占用同一个寄存器地址。CPU通过读状态寄存器得知产生中断的原因并做相应处理
![]()
要实现上述接口,可以直接用可编程并行接口8255
8255一共有3种工作方式:
工作在方式0的输入相当于三态门,工作在方式0的输出相当于锁存器
工作在方式1的输出相当于具有中断功能的输出接口,工作在方式1的输入相当于具有中断功能的输入接口
工作在方式2相当于双向的输入/输出接口
8255:可编程并行接口
内部结构及外部引线
8255有A,B,C三个并行接口
每个并行接口都有8根线,A口为PA7∼PA0,B口为PB7∼PB0,C口分成相互独立,可以分别配置的高4位PC7∼PC4和低4位PC3∼PC0
任何一个口都可以工作在方式0,A口还可以工作在方式1和方式2,B口还可以工作在方式1。方式0和方式1可以配置成输入也可以配置成输出
工作在方式1和方式2需要借用C口的信号线
若配置8255的A口工作在方式2。PA7∼PA0这8根线跟外设之间是双向的,此外构成其他的一些握手信号STB―,IBF,ACK―,OBF―和INTR―还需要分别借用C口的信号线PC4∼PC7和PC3。如果B口刚好工作在方式1,还可以借用C口的另外3根线
A口,B口,C口各有1个8位的缓冲寄存器,此外还有1个控制字,加电启动后通过写控制字可以初始化8255,配置具体的哪一个口应该工作在哪种方式下。对这些寄存器进行读写和总线间要有地址线A0∼A1,数据线D0∼D7和读信号RD―,写信号WR―,片选信号CS―
另外还多了1个复位信号RESET,直接接到计算机主板的复位电路引脚。计算机刚一加电后复位电路工作产生负脉冲,将8255内部的控制字自动置成事先设置好的状态即A,B,C口均为输入以避免总线竞争
![]()
8255的方式控制字及状态字
8255的地址线有2根,A,B,C三个口的缓冲寄存器和控制字分别占用地址00,01,10和11
写地址11,最高位用来区分现在是写控制字还是将C口寄存器的某一位清0或置1
C口寄存器具体的某一位跟C口的引脚之间一般有对应关系。如C口寄存器的第3位置1,则PC3输出引脚直接输出高电平
![]()
8255的工作方式
![]()
![]()
![]()
![]()
8255的寻址和连接使用
方式0:
易得A,B,C口寄存器和控制字的具体接口地址分别是380H,381H,382H,383H
![]()
看地址线A0,A1怎么连确定连的是8086还是8088。8259的A0,A1连系统总线的A0,A1连的是8088的系统总线。A0,A1连系统总线的A1,A2连的是8086的系统总线,数据线如果连到系统总线低8位必须要给偶地址,地址译码电路加偶地址存储体选择信号A0必须是低电平的条件
8255初始化及应用举例:方式0 - 打印机接口
![]()
除了数据线,外设还要求有锁存信号STROBE―,要用B口或C口的某一根线提供(负脉冲宽度要求≥1us,无法直接通过较快的总线信号提供)。对外设来讲STOROBE―信号是输入,BUSY信号是输出,而C口较为灵活,高4位和低4位可以分别配置。可以让C口的高4位配置成输出,只能写不能读,再随便选一根线如PC6,C口的低4位配置成输入,只能读不能写,再随便选一根线如PC1,刚好既可以判断BUSY信号的状态,又可以给它送STROBE―信号
8255地址:380H~383H
初始化程序:
![]()
利用8255方式0以程序控制(查询)方式实现打印机接口
![]()
8255初始化及应用举例:方式1 - 打印机接口
单稳触发器将下降沿转换为宽度为1us的负脉冲
同样这种情况下PC6输入引脚和C口寄存器的第6位没有关系,C口寄存器的第6位是中断允许位
![]()
8255地址:380H~383H
初始化程序:
![]()
利用8255方式1程序控制(查询)方式实现打印机接口:
![]()
利用8255方式1以中断方式实现打印机接口:
![]()
8253:可编程定时器
外部引线及功能
频率已知的时钟信号,对时钟信号进行计数就能达到定时的效果,所以所谓的定时器还有另外一个名字:计数器。8253芯片内有3个计数器,要求写入计数初值,开始计数后每来一个时钟信号的下降沿计数值减1
3个计数器都有相应的16位寄存器用于写入计数初值。8根数据线D0∼D7写计数初值时分两次写,先写的对应低8位,后写的对应高8位
要区分读或写的是哪一个寄存器还要有地址线A0∼A1。系统总线可见或者说可以访问的寄存器还有控制字,往控制字写入不同的内容就可以让每一个计数器工作在不同的模式下。4个寄存器用2位地址访问。2根地址线4种组合。00,01,10,11分别对应计数器0,1,2的1计数值寄存器和控制字。地址0,1,2这3个寄存器可写可读,地址3寄存器可写不可读
此外8253和系统总线这边的信号还有读写信号RD―,WR―,片选信号CS―
计数器i有时钟信号输入引脚CLKi,用于通知计数值减到0的输出引脚OUTi,用于暂停计数的门控信号GATEi。GATEi高电平正常计数,低电平暂停计数)
![]()
工作方式
每一个计数器可以工作在6种不同的模式下
![]()
方式0和方式1产生一个负脉冲
![]()
方式0:计数结束产生中断
![]()
写控制字规定某计数器工作在方式0下后OUT引脚马上就变为低电平。写入计数初值n后开始定时计数,计数值减到0后OUT引脚变为高电平。其他方式只要写控制字规定工作方式后OUT引脚马上变为高电平
可将其接到8259的一个中断请求输入引脚,定时向CPU发出中断请求
方式1:可编程单稳
![]()
与方式0不同,方式1写完计数初值后要等到GATE信号来一个上升沿后才开始计数
可将一个上升沿转换成一个宽度可编程的负脉冲
方式2和方式3产生周期信号,方式2产生周期性负脉冲。方式3产生方波
![]()
方式2:频率发生器
![]()
方式3:方波发生器
![]()
方式4和方式5隔一定时间后产生宽度为一个时间周期的负脉冲
![]()
方式4:软件触发旁通
![]()
方式5:硬件触发旁通
![]()
8253的控制字
![]()
开始计数时,第一个时钟下降沿会把计数值从计数值寄存器传送到减1寄存器,此时不会判断计数值是否为0。在下一个时钟周期下降沿才把减1寄存器的内容减1,然后判断是否为0。故计数初值如果写0对应的是最大计数值
减1计数器的每次改变都会同步到计数锁存器,正常工作时这两个寄存器的内容总是一样的。计数值寄存器和计数锁存器占用同一个地址,写这个地址将计数初值写入计数值寄存器,读这个地址读当前计数锁存器的内容。减1计数器则不能读也不能写。读之前要给计数器发锁存命令 ,一旦发锁存命令后减1计数器和计数锁存器切断联系,计数锁存器内容不再变化
从系统总线的角度来讲,每个计数器好像只有1个相应的16位寄存器,但其实有3个
8253的地址3对应控制字,看起来8253内部好像也只有一个控制字,但实际上内部对应每一个计数器都有其专有的控制字
故每一个计数器内部都有4个寄存器:计数值寄存器,减1计数器,计数锁存器和控制字
![]()
8255的寻址及连接
![]()
8253的初始化及应用
![]()
![]()
然后讲了下以前CPU为8088时计算机主板上跟8253有关的部分电路和电源掉电检测的例子
可编程定时/计数器8253的串联使用
单个定时/计数器的限制:
![]()
多个定时/计数器串联使用:
![]()
要求输出为指定宽度的周期性负脉冲,如何设计?
方法1:
![]()
方法2:
![]()
基于总线的I/O接口设计
略
西电计科院微机原理与系统设计课程笔记(车向泉版)相关推荐
- xdoj系统_【战疫情】西电计科院教学在行动(6)——对话全面线上服务的万波老师...
(通讯员 王孟晞 薛科)线上教学是疫情期间的特殊需要,更是我们进行信息化.智能化教学建设的需要.即使没有这次疫情,计科院也在着手进行"人工智能+教育","互联网+教育&q ...
- 西电计算机学院名誉院长,杨孟飞院士受聘为西电计科院名誉院长及讲席教授
西电新闻网讯(通讯员 陈龙)12月21日上午,西安电子科技大学计算机科学与技术学院名誉院长杨孟飞院士"华山学者"讲席教授及战略咨询委员会委员聘任仪式在北校区主楼Ⅱ区319会议室举行 ...
- 西电计科操作系统实验
#西电计科操作系统实验: ##操作系统的实验方敏老师和黄伯虎老师要求并不一样,方敏老师的OS实验比起黄伯虎老师简直轻松的不值一提,因此选课的时候,建议大家选方敏老师,性价比更高! ##本次给大家介绍的 ...
- 22考研上岸西电计科初试395分经验分享
[西电22考研 计科院834]17级毕业生 本科双非通信专业 脱产在家 辞职跨考 一战上岸西安电子科技大学! 视频原地址 备考经验分享视频 接下来我将从以下几个方面简单的介绍一下我自己,希望准备考研的 ...
- 西电计科微机原理期末复习笔记
本人西电19计科,微原期末90+,这是复习期间整理的笔记,基本涵盖了课程全部重点,有需要的学弟学妹可以在复习的时候参考一下.
- 西电计科数据库系统期末复习笔记
本人西电19计科,数据库系统98,这是复习期间整理的笔记,基本涵盖了课程全部重点,有需要的学弟学妹可以在复习的时候参考一下.
- 西电计科计算机视觉期末复习笔记
本人西电19计科,CV期末90+,这是复习期间整理的笔记,基本涵盖了课程全部重点,有需要的学弟学妹可以在复习的时候参考一下.
- 西电计科19级保研情况分享
保研人数: 突出特长指美赛.全国互联网+创新创业大赛.电赛.ACM等获得一定名次的人.
- 西电计科模电期末复习提纲+一些个人笔记
博主当时模电96,这里是我当时复习的时候做的一些笔记,供各位学弟学妹复习时参考~
- 西电计科四年(学院任选)课程推荐
大一上: 工图(2学分),简单好拿分. 大一下: 果断python 3学分 有人会问为什么不推荐Java,原因: 1.Java内容要理解的远比python多得多,python课程内容讲的也不少,但是内 ...
最新文章
- 2020中国大学本科毕业生质量排行榜公布(附前152名)
- 提示找不到include/common.h 提示No package 'minigui' found
- 单机运行环境搭建之 --CentOS-6.4安装MySQL 5.6.10并修改MySQL的root用户密码
- 课时36:类与对象:给大家介绍对象
- html5 video如何添加进度条_教你制作独一无二的进度条视频效果
- UITableView知识梳理须知—(一)
- 机器学习实践五---支持向量机(SVM)
- java 设计char类型_JAVA中的char类型
- 牛客SQL22 统计各个部门的工资记录数
- 下面两种送礼模式会让你的生意兴隆
- 【三层】无法直接启动带有“类库输出类型”的项目
- 从零开始学习ASP.NET MVC1.O (第一章)
- 静默授权获取unionid_Asp.Net Core 中IdentityServer4 授权中心之自定义授权
- [UI] 精美UI界面欣赏[4]
- 英文横版游戏《玛丽师傅》源码H5+安卓+IOS三端源码
- 安装系统时,提示无法安装到这个磁盘,选中的磁盘具有MBR分区表,在EFI系统上,windows只能安装到GPT磁盘的问题
- html邮件的排版问题
- android 百度地图定位图标素材,百度地图定位开发图标大全 百度地图开发可以用到的一些实用标注/图标(baidu map development) - 下载 - 搜珍网...
- MIT-OS实验-lab1
- python socket基于TCP/IP协议实现多人聊天室