机器学习 结构化数据_聊天机器人:根据结构化数据创建自然语言
机器学习 结构化数据
介绍 (Introduction)
But let us first have a look at the basic translation taking place within a chatbot…
但是,让我们首先看看聊天机器人中进行的基本翻译...
The allure of a chatbot is being able to input unstructured data. We are so use to having to structure our input and data according to what the user interface dictates.
聊天机器人的魅力在于能够输入非结构化数据。 我们习惯于必须根据用户界面的要求来构造输入和数据。
Here chatbots come along, and allow us to enter our data in a conversational manner.
这里出现了聊天机器人,并允许我们以对话的方式输入数据。
And by implication, unstructured.
并暗示,是非结构化的。
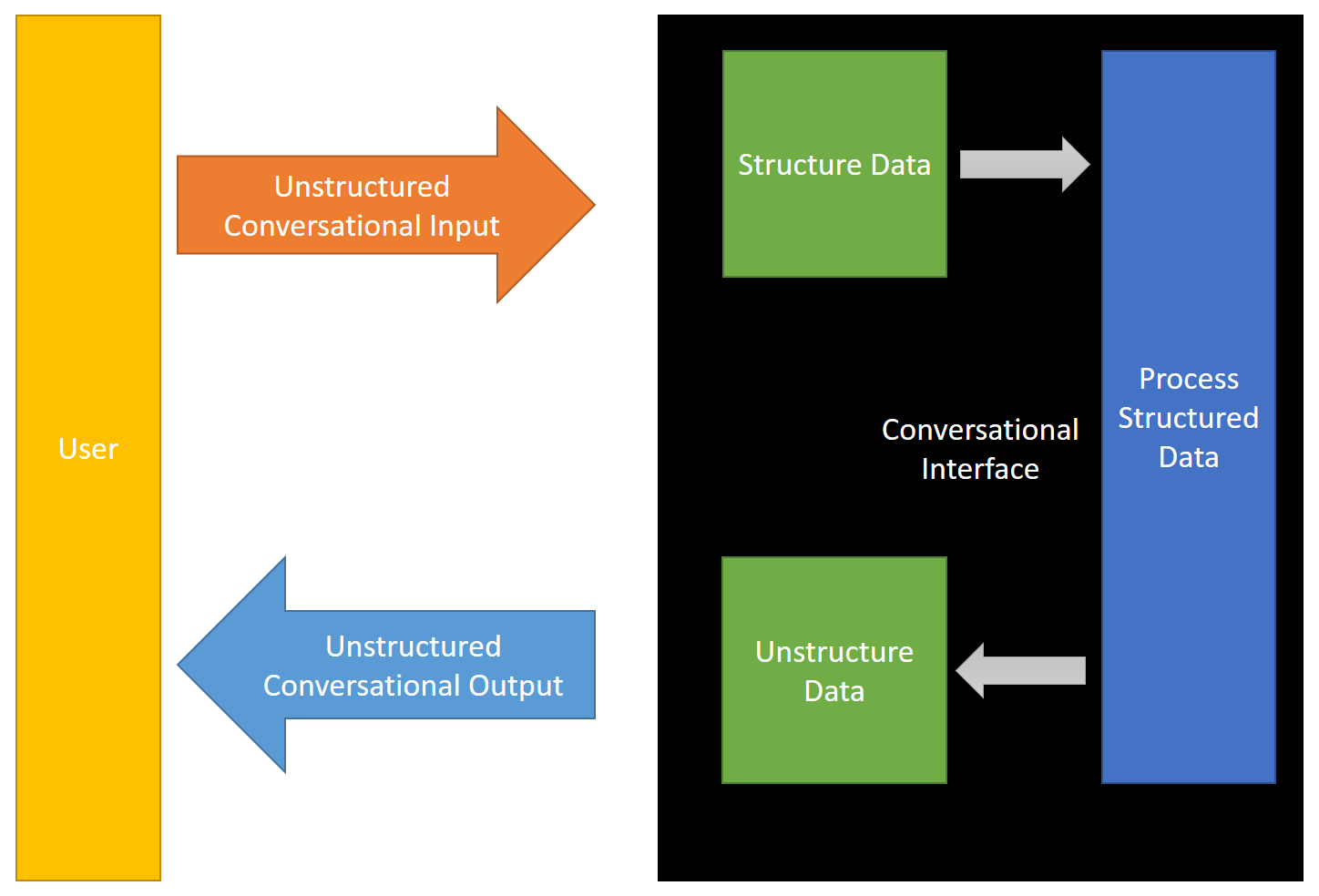
For user input, the chatbot must structure the data. A large part of this structuring can include the following activities:
对于用户输入,聊天机器人必须构造数据。 这种结构的很大一部分可以包括以下活动:
Sentence Boundary Detection (helpful for longer input)
句子边界检测( 有助于较长的输入 )
Language Detection (scenarios where users speak different languages)
语言检测( 用户说不同语言的场景)
- Intent Detection意图检测
- Determining Entities确定实体
and more…
和更多…
Inversely, the data output to the user must be unstructured again into natural language…
相反,必须再次将输出给用户的数据非结构化为自然语言…
与用户交谈 (Speaking To The User)
After the appropriate response to the user have been determined by the chatbot, the data which needs to be presented to the user, is in a structured format.
在聊天机器人确定了对用户的适当响应之后,需要呈现给用户的数据采用结构化格式。
In the case of a weather bot, the data you want to present to the user might look something like this:
如果是气象机器人,您想要提供给用户的数据可能看起来像这样:
{ "id": 803, "main": "Clouds", "description": "broken clouds", "icon": "http://openweathermap.org/img/wn/04d@2x.png", "weather": "Clouds", "temp": 80, "high": 82, "low": 78, "city": "New York"}Under normal circumstances, to present this to a user via a mobile app or website is standard procedure. With a conversational interface, it is a whole different matter.
通常情况下,通过移动应用程序或网站向用户展示此内容是标准过程。 有了对话界面,情况就完全不同了。
We need to convert the data into conversation, hence unstructured it. This brings us to this continuous process of structuring and unstructuring data.
我们需要将数据转换为对话,从而使其变得非结构化。 这使我们进入了结构化和非结构化数据的连续过程。
This process of unstructuring data into conversation is referred to as Natural Language Generation, NLG.
将数据分解为对话的过程称为自然语言生成(NLG)。
Natural language generation
自然语言生成
Natural language generation is the natural language processing task of generating natural language from a machine representation system such as a knowledge base or a logical form. Psycholinguists prefer the term language production when such formal representations are interpreted as models for mental representations.
自然语言生成是从机器表示系统(例如知识库或逻辑形式)生成自然语言的自然语言处理任务。 当这种形式的表述被解释为心理表象的模型时,心理语言学家更喜欢用语言产生一词。
自然语言生成( NLG )基础 (Basics Of Natural Language Generation (NLG))
As with everything, NLG can be performed on various levels of complexity. The most simplistic approach is to have a one-to-one match of return codes and phrases.
就像所有东西一样,NLG可以在各种复杂程度上执行。 最简单的方法是使返回码和短语一对一匹配。
If the API returns 0, then the bot responds with “Thank you, your request have been logged”.
如果API返回0,则漫游器会回复“ 谢谢,您的请求已被记录”。
Else if the API responds with 1, the bot responds with “Sorry, something went wrong, try again later.”
否则,如果API响应为1,则漫游器响应为“抱歉,出了点问题,请稍后再试。”
You could see this as a very basic form of unstructuring data.
您可以将其视为一种非结构化数据的非常基本的形式。
生命的幻觉 (The Illusion of Lifeness)
Of course, you can take this one step further, by creating an illusion of lifeness. Some development environments, like IBM Watson Assistant allows for multiple responses to be defined per conversational node.
当然,您可以通过创造一种生活错觉来进一步迈出这一步。 某些开发环境(例如IBM Watson Assistant)允许在每个会话节点上定义多个响应。
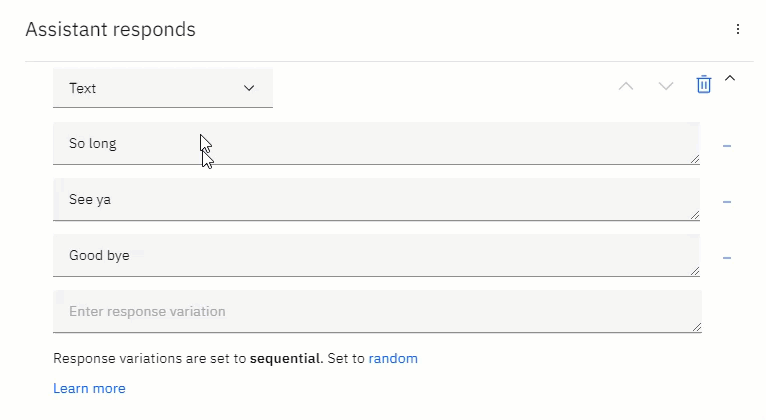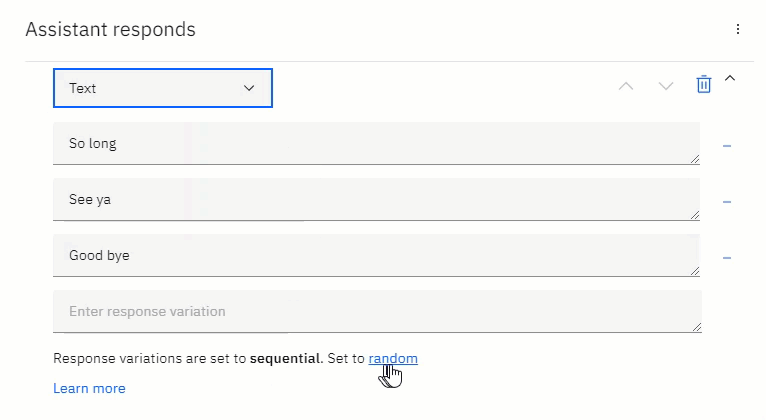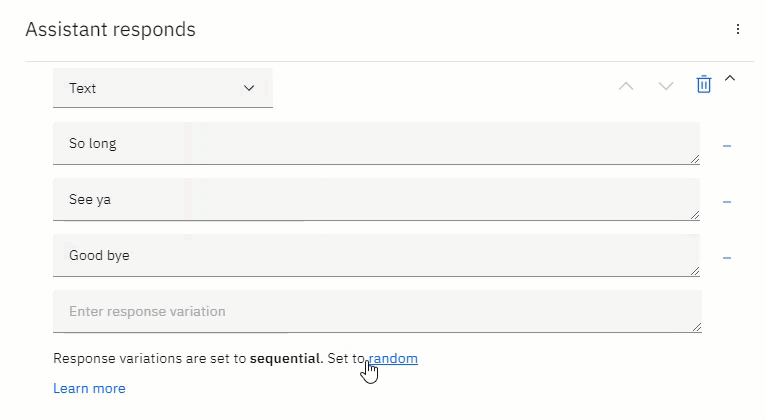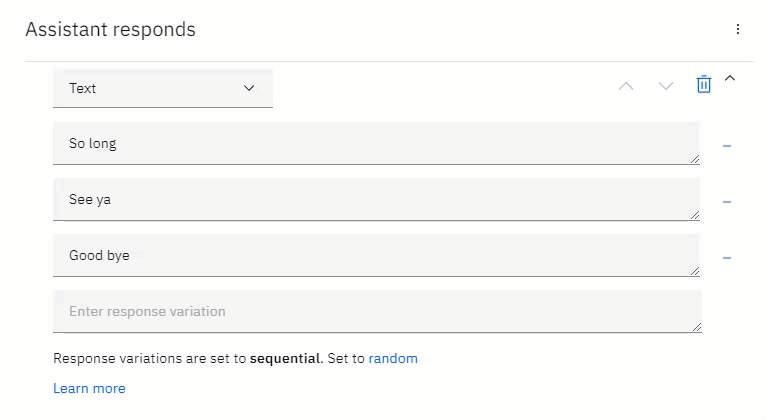
These responses can then be set to random or sequential. In the example shown here, there is a list of goodbye messages. This list of messages can be extensive, and set to be different every time the user says goodbye to the chatbot.
然后可以将这些响应设置为随机或顺序 。 在此处显示的示例中,有一个再见消息列表。 该消息列表可能很广泛,并且每次用户向聊天机器人说再见时,都会设置为不同。
Hence presenting this idea to the user of an unscripted and spontaneous agent.
因此,向无脚本和自发代理的用户提出此想法。
脚本语言生成 (Scripted Language Generation)
Taking matters one step further, is creating a language generation script.
使事情更进一步的一步是创建语言生成脚本。
Microsoft’s Bot Framework Composer has a Bot Response option on the left, where you can define the bot responses.
Microsoft的Bot Framework Composer在左侧有一个Bot Response选项,您可以在其中定义漫游器响应。

In the marked example, a Language Generation script is defined called:
在标记的示例中, 语言生成脚本被定义为:
#DescriberWeatherThe purpose of this example is to take the response from the weather API, and transform it into more natural sounding language. If the API returns “Dust”, we want our chatbot dialog to return: “There’s dust in the air” etc.
本示例的目的是从天气API中获取响应,并将其转换为更自然的发音语言。 如果API返回“ 灰尘 ”,我们希望聊天机器人对话框返回:“ 空气中有灰尘 ”等。
We can create multiple such scripts quick and easy for different API’s, and scenarios.
我们可以针对不同的API和场景快速轻松地创建多个此类脚本。
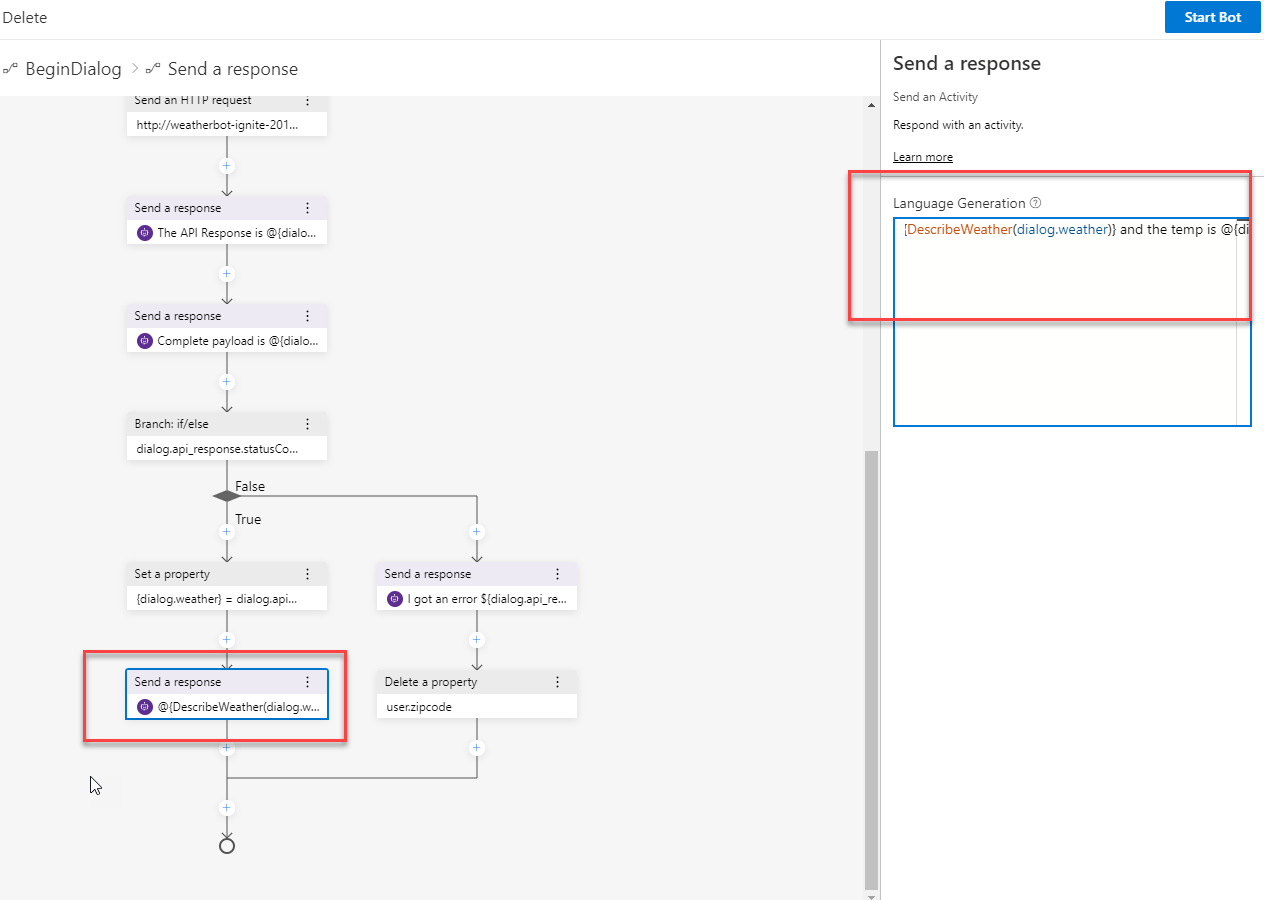
And within the Send a response element, we can reference the language script for user feedback:
在“ 发送响应”元素中,我们可以引用语言脚本以获取用户反馈:
- @{DescribeWeather(dialog.weather)} and the temp is @{dialog.weather.temp}°This affords us a predictable and standardized avenue of crafting responses for the user. Just think of multiple user languages in a chatbots, where the language generator can be used to respond to the user in a particular language.
这为我们提供了用户可预测的标准化响应途径。 只需考虑聊天机器人中的多种用户语言,即可在其中使用语言生成器以特定语言响应用户。
易于扩展 (Ease Of Scaling)
One issue chatbot endeavors often run into, is scaling. Invariably there comes a stage where the environment and framework need to be reconsidered.
聊天机器人经常遇到的一个问题是扩展。 总有一个阶段需要重新考虑环境和框架。
Segmenting chatbot elements as much as possible help to a large degree.
尽可能细分聊天机器人元素可以在很大程度上帮助您。
And, segmenting the script/dialog from the dialog flow is prudent, and the Language Generator speaks to this.
而且,谨慎地从对话流中分割脚本/对话框是明智的,并且语言生成器也对此进行了说明。
But why not take it even a step further…
但是,为什么不走得更远呢……
自然语言理解的逆向 (The Inverse of Natural Language Understanding)
NLG is a software process where structured data is transformed into natural conversational language for output to the user. In other words, structured data is presented in an unstructured manner to the user. Think of NLG is the inverse of NLU.
NLG是一种软件过程,其中结构化数据被转换为自然的对话语言,以输出给用户。 换句话说,结构化数据以非结构化的方式呈现给用户。 认为NLG是NLU的逆。
With NLU we are taking the unstructured conversational input from the user (natural language) and structuring it for our software process. With NLG, we are taking structured data from backend and state machines, and turning this into unstructured data. Conversational output in human language.
使用NLU,我们可以从用户(自然语言)获取非结构化的对话输入,并为我们的软件流程构建结构。 借助NLG,我们将从后端和状态机中获取结构化数据,并将其转换为非结构化数据。 用人类语言进行会话输出。
Commercial NLG is emerging and forward looking solution providers are looking at incorporating it into their solution. At this stage you might be struggling to get your mind around the practicalities of this. Below are two practical examples which might help.
商业NLG正在兴起,前瞻性的解决方案提供商正在寻求将其纳入其解决方案中。 在此阶段,您可能正在努力使自己对此有所了解。 下面是两个可能有用的示例。
伪造产品评论生成器 (Fake Product Review Generator)
For this example I took close to 580,000 product reviews and created a TensorFlow model from that.
在此示例中,我接受了将近580,000条产品评论,并由此创建了一个TensorFlow模型。
By providing key words or a phrase, a product review can be generated. This product review can be seen as natural language generation.
通过提供关键词或短语,可以生成产品评论。 该产品评论可以看作是自然语言的生成。
A fictitious review is generated from a corpus of review data, based on a key word.
虚拟评论是根据关键字从评论数据语料库中生成的。
Imagine of the chatbot has got access to a corpus of response data, and based on key words or values, a response is generated. Unique in a sense.
想象一下,聊天机器人可以访问响应数据集,并根据关键字或值生成响应。 在某种意义上是独特的。
假新闻标题生成器 (Fake News Headline Generator)
In the video below, I got a data set from kaggle.com with about 185,000 records.
在下面的视频中,我从kaggle.com获得了大约185,000条记录的数据集。
Each of these records where a newspaper headline which I used to create a TensforFlow model from.
所有这些记录都来自我用来创建TensforFlow模型的报纸头条。
Based in this model, I could then enter one or two intents, and random “fake” (hence non-existing) headlines were generated.
基于此模型,我可以输入一个或两个意图,并生成随机的“伪造”(因此不存在)标题。
There are a host of parameters which can be used to tweak the output used.
有许多参数可用于调整使用的输出。
结论 (Conclusion)
We have seen growth in the way input data is processed by chatbots. Multiple intents can be detected, with multiple entities. Relations and types of entities can also be identified. The flexibility is astounding in many cases.
我们已经看到聊天机器人处理输入数据的方式有所增长。 可以检测到具有多个实体的多个意图。 实体的关系和类型也可以被识别。 在许多情况下,灵活性令人震惊。
Yet we have not seen the same degree of advancement and flexibility in the chatbot script. Users judge a chatbot by its script and how appropriate and lifelike each response is. The script also informs the user on the current conversation state, and how to proceed; hence its importance.
但是,我们尚未在chatbot脚本中看到相同程度的进步和灵活性。 用户通过其脚本以及每个响应的适当程度和逼真程度来判断聊天机器人。 该脚本还通知用户当前的对话状态以及如何进行。 因此它的重要性。
在这里… (Read More Here…)
翻译自: https://medium.com/@CobusGreyling/chatbots-creating-natural-language-from-structured-data-bbc81ee6c78c
机器学习 结构化数据
http://www.taodudu.cc/news/show-1874095.html
相关文章:
- mc2180 刷机方法_MC控制和时差方法
- 城市ai大脑_激发AI研究的大脑五个功能
- 神经网络算法优化_训练神经网络的各种优化算法
- 算法偏见是什么_人工智能中的偏见有什么作用?
- 查看-增强会话_会话助手平台-Hinglish Voice等!
- 可解释ai_人工智能解释
- 机器学习做自动聊天机器人_聊天机器人业务领袖指南
- 神经网络 代码python_详细使用Python代码和数学构建神经网络— II
- tensorflow架构_TensorFlow半监督对象检测架构
- 最牛ai波士顿动力上台阶_波士顿动力的位置如何使美国成为人工智能的关键参与者...
- 阿里ai人工智能平台_AI标签众包平台
- 标记偏见_人工智能的偏见
- lstm预测单词_从零开始理解单词嵌入| LSTM模型|
- 动态瑜伽 静态瑜伽 初学者_使用计算机视觉对瑜伽姿势进行评分
- 全自动驾驶论文_自动驾驶汽车:我们距离全自动驾驶有多近?
- ocr图像识别引擎_CycleGAN作为OCR图像的去噪引擎
- iphone 相机拍摄比例_在iPhone上拍摄:Apple如何解决Deepfakes和其他媒体操纵问题
- 机器学习梯度下降举例_举例说明:机器学习
- wp-autoblog_AutoBlog简介
- 人脸识别 特征值脸_你的脸值多少钱?
- 机器学习算法的差异_我们的机器学习算法可放大偏差并永久保留社会差异
- ai人工智能_AI破坏已经开始
- 无监督学习 k-means_无监督学习-第5部分
- 负熵主义者_未来主义者
- ai医疗行业研究_我作为AI医疗保健研究员的第一个月
- 梯度离散_使用策略梯度同时进行连续/离散超参数调整
- 机械工程人工智能_机械工程中的人工智能
- 遗传算法是机器学习算法嘛?_基于遗传算法的机器人控制器方法
- ai人工智能对话了_对话式AI:智能虚拟助手和未来之路。
- mnist 转图像_解决MNIST图像分类问题
机器学习 结构化数据_聊天机器人:根据结构化数据创建自然语言相关推荐
- Java_Hive自定义函数_UDF函数清洗数据_清洗出全国的省份数据
Java_Hive_UDF函数清洗数据_清洗出全国的省份数据 最近用Hadoop搞数据清洗,需要根据原始的地区数据清洗出对应的省份数据,当然我这里主要清洗的是内陆地区的数据,原始数据中不包含港澳台地区 ...
- python自然语言处理与方言聊天机器人_聊天机器人Python实现案例 | 老炮儿聊机器语音...
点击上方蓝色字体,关注:九三智能控 世界上最早的聊天机器人诞生于20世纪80年代,名为"阿尔贝特",用BASIC语言编写而成.目前,聊天机器人从功能和技术的角度,可以分为两类,一类 ...
- java开发机器人聊天_聊天机器人与Web开发的未来
java开发机器人聊天 Since Facebook launched their annual F8 conference for bot developers in 2016 and Micros ...
- 【python】tkinter界面化+百度API—聊天机器人(四)
目录 百度API tkinter界面设计 完整代码 实现结果如下: 百度API 这里聊天机器人的功能也是结合第一篇的语音识别([python]tkinter界面化+百度API-语音识别_张顺财的博客- ...
- 机器人对话常用语模板_聊天机器人的技术原理和未来的发展
近年来,人工智能越来越火,那你们真的知道人工智能吗? 一.人工智能是什么 人工智能(Artificial Intelligence),英文缩写为AI.它是研究.开发用于模拟.延伸和扩展人的智能的理论. ...
- 机器人聊天软件c#_聊天机器人_c#应用
用 .net 研发 msn 聊天机器人 _c# 应用 写在前面: 我不是研发人员,不是高手,就是自己比较爱玩.在技术上,没有什 么喜欢摸索的精神,而是喜欢投机取巧.在这篇文章里,你也不能 &quo ...
- 达观数据超自动化机器人实践分享 | 达观数据产品总监邵万骏
8月13日,由苏州市金融科技协会指导,RPA中国主办,达观数据作为顶级联合主办的「第二届中国RPA+AI开发者大赛」在苏州观园流苏酒店圆满落幕.达观数据产品总监邵万骏作为特邀嘉宾,在会上做主题演讲&l ...
- 提取数据_基于众包的可视化图表数据提取
Crowdsourcing-based Data Extraction from Visualization Charts 作者 Chengliang Chai† Guoliang Li† Ju Fa ...
- osg加载osgb数据_铁路工程三维协同大数据云平台研究与开发
铁路工程三维协同大数据云平台是基于3DGIS空间信息平台.BIM云平台.GIM云平台.在线监测云平台及增强现实云平台的多平台融合技术 现代铁路工程建设更加注重BIM.物联网等新技术,构建全生命周期一体 ...
- 云中数据_免费备份和共享云中数据的最佳网站
云中数据 We've been told many times how important backups are, although we may not realize it until it's ...
最新文章
- 在leopard下用textmate开发rails项目
- 《构建之法》 读书笔记
- django 给单个文件加log_django配置日志模块
- GPS围栏两个多边形相交问题的奇葩解法
- Windows删除EFI系统分区
- 自己工资自己算,策略设计模式(Strategy)
- Linux修改hosts主机映射文件
- CJOJ 1659 【中学高级本】倒酒
- JS的onload事件
- 案例分享|智慧广电的“宽带加速”之路,博睿数据来“私人定制”
- C/C++常用函数使用总结
- 查看U盘占用程序的方法
- 软件失效模式与影响分析SFMEA的8个入手点
- 如何在IPad上优雅地看移动硬盘中的视频
- anaconda创建虚拟环境_win_linux anaconda虚拟环境设定
- win10电脑禁止启动某软件
- 恢复清除回收站的文件怎么操作
- NoSql的主要类型及相关产品
- OpenSea使用教程
- 【React进阶-1】从0搭建一个完整的React项目(入门篇)