大数据实战之spark安装部署
楔子
我是在2013年底第一次听说Spark,当时我对Scala很感兴趣,而Spark就是使用Scala编写的。一段时间之后,我做了一个有趣的数据科学项目,它试着去预测在泰坦尼克号上幸存。对于进一步了解Spark内容和编程来说,这是一个很好的方式。对于任何有追求的、正在思考如何着手 Spark 的程序员,我都非常推荐这个项目。
今天,Spark已经被很多巨头使用,包括Amazon、eBay以及Yahoo!。很多组织都在拥有成千上万节点的集群上运行Spark。根据Spark FAQ,已知的最大的Spark集群拥有超过8000个节点。Spark确实是一个值得好好考虑和学习的技术。
Apache Spark是什么?一个简单介绍
Spark是一个Apache项目,它被标榜为“快如闪电的集群计算”。它拥有一个繁荣的开源社区,并且是目前最活跃的Apache项目。
Spark提供了一个更快、更通用的数据处理平台。和Hadoop相比,Spark可以让你的程序在内存中运行时速度提升100倍,或者在磁盘上运行时速度提升10倍。去年,在100 TB Daytona GraySort比赛中,Spark战胜了Hadoop,它只使用了十分之一的机器,但运行速度提升了3倍。Spark也已经成为 针对 PB 级别数据排序的最快的开源引擎。
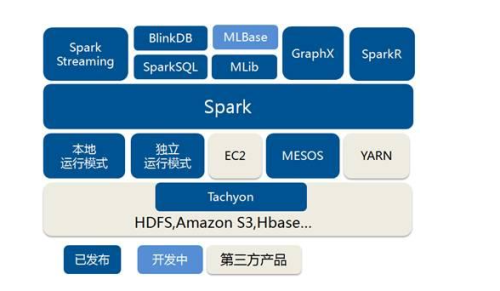
Spark Core
Spark Core是一个基本引擎,用于大规模并行和分布式数据处理。它主要负责:
内存管理和故障恢复
在集群上安排、分布和监控作业
和存储系统进行交互
Spark引入了一个称为弹性分布式数据集(RDD,Resilient Distributed Dataset)的概念,它是一个不可变的、容错的、分布式对象集合,我们可以并行的操作这个集合。RDD可以包含任何类型的对象,它在加载外部数据集或者从驱动应用程序分发集合时创建。
RDD支持两种操作类型:
转换是一种操作(例如映射、过滤、联接、联合等等),它在一个RDD上执行操作,然后创建一个新的RDD来保存结果。
行动是一种操作(例如归并、计数、第一等等),它在一个RDD上执行某种计算,然后将结果返回。
在Spark中,转换是“懒惰”的,也就是说它们不会立刻计算出结果。相反,它们只是“记住”要执行的操作以及要操作的数据集(例如文件)。只有当行为被调用时,转换才会真正的进行计算,并将结果返回给驱动器程序。这种设计让Spark运行得更有效率。例如,如果一个大文件要通过各种方式进行转换操作,并且文件被传递给第一个行为,那么Spark只会处理文件的第一行内容并将结果返回,而不会处理整个文件。
默认情况下,当你在经过转换的RDD上运行一个行为时,这个RDD有可能会被重新计算。然而,你也可以通过使用持久化或者缓存的方法,将一个RDD持久化从年初在内存中,这样,Spark就会在集群上保留这些元素,当你下一次查询它时,查询速度会快很多。
SparkSQL
SparkSQL是Spark的一个组件,它支持我们通过SQL或者Hive查询语言来查询数据。它最初来自于Apache Hive项目,用于运行在Spark上(来代替MapReduce),现在它已经被集成到Spark堆中。除了针对各种各样的数据源提供支持,它还让代码转换与SQL查询编织在一起变得可能,这最终会形成一个非常强大的工具。下面是一个兼容Hive的查询示例:

Spark Streaming
Spark Streaming支持对流数据的实时处理,例如产品环境web服务器的日志文件(例如Apache Flume和HDFS/S3)、诸如Twitter的社交媒体以及像Kafka那样的各种各样的消息队列。在这背后,Spark Streaming会接收输入数据,然后将其分为不同的批次,接下来Spark引擎来处理这些批次,并根据批次中的结果,生成最终的流。
MLlib
MLlib是一个机器学习库,它提供了各种各样的算法,这些算法用来在集群上针对分类、回归、聚类、协同过滤等(可以在 machine learning 上查看Toptal的文章,来获取更过的信息)。其中一些算法也可以应用到流数据上,例如使用普通最小二乘法或者K均值聚类(还有更多)来计算线性回归。Apache Mahout(一个针对Hadoop的机器学习库)已经脱离MapReduce,转而加入Spark MLlib。
GraphX
GraphX是一个库,用来处理图,执行基于图的并行操作。它针对ETL、探索性分析和迭代图计算提供了统一的工具。除了针对图处理的内置操作,GraphX还提供了一个库,用于通用的图算法,例如PageRank。
如何使用Apache Spark:事件探测用例
既然我们已经回答了“Apache Spark是什么?”这个问题,接下来让我们思考一下,使用Spark来解决什么样的问题或者挑战最有效率。
最近,我偶然看到了一篇关于 通过分析Twitter流的方式来探测地震 的文章。它展示了这种技术可以比日本气象厅更快的通知你日本哪里发生了地震。虽然那篇文章使用了不同的技术,但我认为这是一个很好的示例,可以用来说明我们如何通过简单的代码片段,在不需要”胶水代码“的情况下应用Spark。
首先,我们需要处理tweet,将那些和”地震“或”震动“等相关的内容过滤出来。我们可以使用Spark Streaming的方式很容易实现这一目标,如下所示:
|
1 2 |
TwitterUtils.createStream(...) .filter(_.getText.contains("earthquake") || _.getText.contains("shaking")) |
然后,我们需要在tweets上运行一些语义分析,来确定它们是否代表当前发生了地震。例如,像“地震!”或者“现在正在震动”这样的tweets,可能会被认为是正向匹配,而像“参加一个地震会议”或者“昨天的地震真可怕”这样的tweets,则不是。这篇文章的作者使用了一个支持向量机(support vector machine, SVM)来实现这一点。我们在这里使用同样的方式,但也可以试一下 流版本。一个使用了MLlib的代码示例如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
// We would prepare some earthquake tweet data and load it in LIBSVM format. val data = MLUtils.loadLibSVMFile(sc, "sample_earthquate_tweets.txt") // Split data into training (60%) and test (40%). val splits = data.randomSplit(Array(0.6, 0.4), seed = 11L) val training = splits(0).cache() val test = splits(1) // Run training algorithm to build the model val numIterations = 100 val model = SVMWithSGD.train(training, numIterations) // Clear the default threshold. model.clearThreshold() // Compute raw scores on the test set. val scoreAndLabels = test.map { point => val score = model.predict(point.features) (score, point.label) } // Get evaluation metrics. val metrics = new BinaryClassificationMetrics(scoreAndLabels) val auROC = metrics.areaUnderROC() println("Area under ROC = " + auROC) |
如果对于这个模型的预测比例满意,我们可以继续往下走,无论何时发现地震,我们都要做出反应。为了检测一个地震,我们需要在一个指定的时间窗口内(如文章中所述)有一定数量(例如密度)的正向tweets。请注意,对于带有Twitter位置服务信息的tweets来说,我们还能够从中提取地震的位置信息。有了这个只是以后,我们可以使用SparkSQL来查询现有的Hive表(保存那些对接收地震通知感兴趣的用户)来获取用户的邮箱地址,并向他们发送一些个性化的警告邮件,如下所示:
|
1 2 3 4 5 |
// sc is an existing SparkContext. val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc) // sendEmail is a custom function sqlContext.sql("FROM earthquake_warning_users SELECT firstName, lastName, city, email") .collect().foreach(sendEmail) |
1.实战文档如下
Spark下载
为了方便,我直接是进入到了/usr/src文件夹下面进行下载spark-2.1.1
wget https://d3kbcqa49mib13.cloudfront.net/spark-2.2.0-bin-hadoop2.7.tgz
Spark安装之前的准备
文件的解压与改名
tar -zxf spark-2.1.1-bin-hadoop2.7.tgz
rm -rf spark-2.1.1-bin-hadoop2.7.tgz
为了我后面方便配置spark,在这里我把文件夹的名字给改了
mv spark-2.1.1-bin-hadoop2.7 spark-2.1.1
配置环境变量
vi /etc/profile
在最尾巴加入
export SPARK_HOME=/usr/src/spark-2.1.1
export PATH=$PATH:$SPARK_HOME/bin
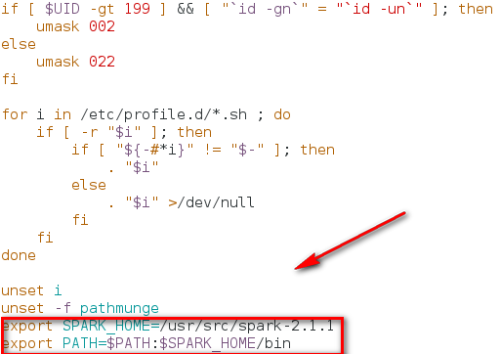
配置Spark环境
打开spark-2.1.1文件夹
cd spark-2.1.1
此处需要配置的文件为两个
spark-env.sh和slaves
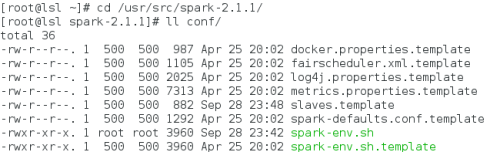
首先我们把缓存的文件spark-env.sh.template改为spark识别的文件spark-env.sh
cp conf/spark-env.sh.template conf /spark-env.sh
修改spark-env.sh文件
vi conf/spark-env.sh
注意!变量按照个人条件情况路径配置
在最尾巴加入
export JAVA_HOME=/usr/java/jdk1.7.0_141
export SCALA_HOME=/usr/scala-2.1.1
export HADOOP_HOME=/usr/local/hadoop-2.7.2
export HADOOP_CONF_DIR=/usr/local/hadoop-2.7.2/etc/hadoop
export SPARK_MASTER_IP=SparkMaster
export SPARK_WORKER_MEMORY=4g
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1
变量说明
JAVA_HOME:Java安装目录
SCALA_HOME:Scala安装目录
HADOOP_HOME:hadoop安装目录
HADOOP_CONF_DIR:hadoop集群的配置文件的目录
SPARK_MASTER_IP:spark集群的Master节点的ip地址
SPARK_WORKER_MEMORY:每个worker节点能够最大分配给exectors的内存大小
SPARK_WORKER_CORES:每个worker节点所占有的CPU核数目
SPARK_WORKER_INSTANCES:每台机器上开启的worker节点的数目
修改slaves文件
vi conf/slaves 或者

在最后面修成为
SparkWorker1
SparkWorker2
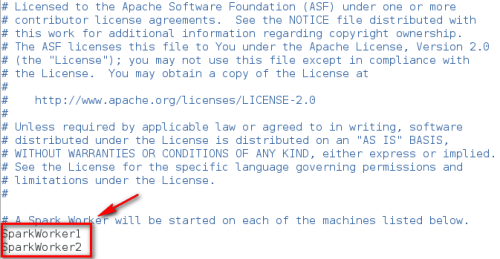
注意!如果是dan台PC可以不用同步rsync
同步SparkWorker1和SparkWorker2的配置
在此我们使用rsync命令
rsync -av /usr/src/spark-2.1.1/ SparkWorker1:/usr/src/spark-2.1.1/
rsync -av /usr/src/spark-2.1.1/ SparkWorker2:/usr/src/spark-2.1.1/
启动Spark集群
因为我们只需要使用hadoop的HDFS文件系统,所以我们并不用把hadoop全部功能都启动。
启动hadoop的HDFS文件系统
start-dfs.sh
但是在此会遇到一个情况,就是使用start-dfs.sh,启动之后,在SparkMaster已经启动了namenode,但在SparkWorker1和SparkWorker2都没有启动了datanode,这里的原因是:datanode的clusterID和namenode的clusterID不匹配。是因为SparkMaster多次使用了hadoop namenode -format格式化了。
==解决的办法:==
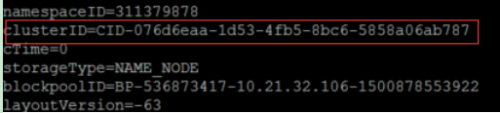
在SparkMaster使用
cat /usr/src/hadoop-2.7.2/hdfs/name/current/VERSION
查看clusterID,并将其复制。
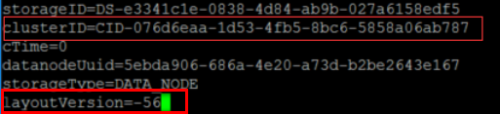
在SparkWorker1和SparkWorker2上使用
vi /usr/src/hadoop-2.7.2/hdfs/name/current/VERSION
将里面的clusterID,更改成为SparkMasterVERSION里面的clusterID
做了以上两步之后,便可重新使用start-dfs.sh开启HDFS文件系统。
启动之后使用jps命令可以查看到SparkMaster已经启动了namenode,SparkWorker1和SparkWorker2都启动了datanode,说明hadoop的HDFS文件系统已经启动了。
启动Spark
因为
hadoop/sbin以及spark/sbin均配置到了系统的环境中,它们同一个文件夹下存在同样的start-all.sh文件。最好是打开spark-2.2.0,在文件夹下面打开该文件。
./sbin/start-all.sh
成功打开Spark集群之后可以进入Spark的WebUI界面,可以通过
SparkMaster_IP:8080 例:192.168.1.186:8080
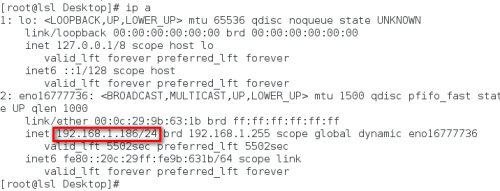
访问,可见有两个正在运行的Worker节点。
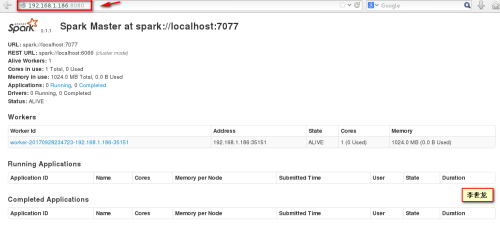
打开Spark-shell
使用
spark-shell and ./bin/spark-shell
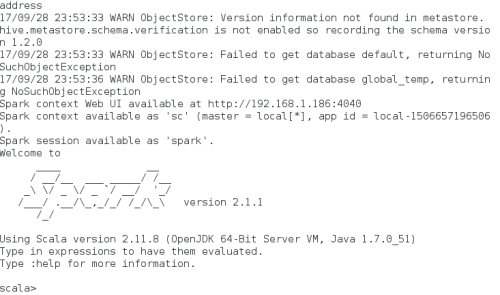
便可打开Spark的shell
同时,因为shell 在运行,我们也可以通过
SparkMaster_IP:4040
访问WebUI查看当前执行的任务。
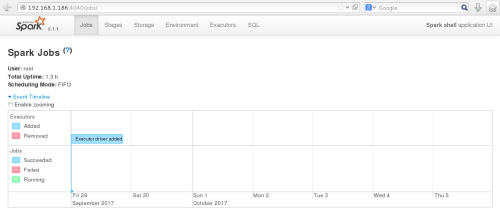
结言
到此我们的Spark集群就搭建完毕了。搭建spark集群原来知识网络是挺庞大的,涉及到Linux基本操作,设计到ssh,设计到hadoop、Scala以及真正的Spark。在此也遇到不少问题,通过翻阅书籍以及查看别人的blog得到了解决。在此感谢分享知识的人。希望自己越努力越幸运!
转载于:https://blog.51cto.com/lwm666/1969682
大数据实战之spark安装部署相关推荐
- 时空大数据实践之GeoWave安装部署实践
2019独角兽企业重金招聘Python工程师标准>>> 时空大数据实践之GeoWave安装部署实践 GeoWave是由国家地理空间情报局(NGA)与RadiantBlue和Booz ...
- 大数据篇:Spark安装及测试PI的值
本文运行的具体环境如下: centos7.3 Hadoop 2.8.4 Java JDK 1.8 Spark 1.6.3 一.安装Hadoop 关于Hadoop的安装,这里就不概述了! 二.安装 Sp ...
- 《Python Spark 2.0 Hadoop机器学习与大数据实战_林大贵(著)》pdf
<Python+Spark 2.0+Hadoop机器学习与大数据实战> 五星好评+强烈推荐的一本书,虽然内容可能没有很深入,但作者非常用心的把每一步操作详细的列出来并给出说明,让我们跟着做 ...
- spark python教程_Python Spark 2.0 Hadoop机器学习与大数据实战 完整pdf_IT教程网
资源名称:Python Spark 2.0 Hadoop机器学习与大数据实战 完整pdf 第1章 Python Spark机器学习与Hadoop大数据 1 第2章 VirtualBox虚拟机软件的安装 ...
- 成都大数据Hadoop与Spark技术培训班
成都大数据Hadoop与Spark技术培训班 中国信息化培训中心特推出了大数据技术架构及应用实战课程培训班,通过专业的大数据Hadoop与Spark技术架构体系与业界真实案例来全面提升大数据工程师.开 ...
- 大数据实时处理-基于Spark的大数据实时处理及应用技术培训
随着互联网.移动互联网和物联网的发展,我们已经切实地迎来了一个大数据 的时代.大 数据是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫 ...
- dataframe记录数_大数据系列之Spark SQL、DataFrame和RDD数据统计与可视化
Spark大数据分析中涉及到RDD.Data Frame和SparkSQL的操作,本文简要介绍三种方式在数据统计中的算子使用. 1.在IPython Notebook运行Python Spark程序 ...
- 大数据实战之Spark-Flume-Kafka-idea-Mysql实时处理数据并存储
大数据实战之Spark-Flume-Kafka-idea-Mysql实时处理数据并存储 数据流的处理 实时数据的模拟 需求分析 设计流程 流程图 Spark与hadoop部分: flume部分: ka ...
- 大数据技术之Spark(一)——Spark概述
大数据技术之Spark(一)--Spark概述 文章目录 前言 一.Spark基础 1.1 Spark是什么 1.2 Spark VS Hadoop 1.3 Spark优势及特点 1.3.1 优秀的数 ...
- 大数据实战之用户画像概念、项目概述及环境搭建
下面跟着我一起来学习大数据获取用户画像: 项目Profile课程安排 : 用户画像概念 1.用户画像概述 1.1.产生背景 早期的用户画像起源于交互设计之父Alan Cooper提出的"Pe ...
最新文章
- html5--5-15 绘制阴影
- 【数据平台】基于pymysql库python连接mysql
- SPI初始化C语言编程,SD卡spi模式读写,初始化和复位都成功了
- 论大型信息系统集成项目的人力资源管理
- .net数据绑定控件中的数据导出到Excel
- OpenDDS通讯中rtps_discovery对等发现的基本配置和说明
- REACT是否真的就比VUE强?(文末附两个框架的学习福利)
- 淘宝电商PRD文档模板讲解
- CJOJ 1659 【中学高级本】倒酒
- FS\OFS\RS\ORS的使用
- itools备份短信到android,【itools备份文件路径】itools备份路径_itools备份短信-系统城...
- STM32之继电器驱动(上下拉电阻)
- 程序员找工作的个人经验教训以及注意事项
- 12306官方抢票服务,铁路候补购票服务扩大到全部旅客列车!
- Lua实现三目运算符
- mac(5) : 使用终端解压rar文件
- 手把手教你如何管理进程
- Java对象的打印_java反射原理制作对象打印工具
- Qt+sqlite 《扫雷》游戏排名功能
- [编程题]java实现游历魔法王国
热门文章
- ASP.NET 常用语句代码
- 【OpenCV】图像变换(五)-仿射变换和透视变换
- 【学堂在线数据挖掘:理论方法笔记】第四天(3.28)
- 【MATLAB】 分形插值
- 从零基础入门Tensorflow2.0 ----九、44.3 keras模型转换成savedmodel
- Flutter之Stepper源码浅析
- android activity 主题,android activity 主题
- java 弹幕游戏_java弹幕小游戏1.0版本
- java dao接口_java web项目中dao和service前面为什么要有接口呢??
- javaweb简单源代码_Java Web轻松学39 - JSP核心原理