ElasticSearch架构反向思路
我曾经在多个场合说过,我分析一个系统的设计思路,往往不是一开始就去看看这个系统的设计文档或者源代码,而是去看系统的基本介绍,特别是框架类的功能详细介绍,然后根据介绍可以大概了解这样一个系统用来解决什么问题,有哪些特色,然后基于自己对这些问题的想法,根据自己的经验来同样设计一个系统,看包含哪些内容,使用哪些架构模式和思路,然后带着自己设计的东西再去看另一个系统的设计思路,可能再更加清楚,也会反思自己的设计是否哪些地方存在问题,可以加以改进。
最近正好准备玩ElasticSearch,本来在2013年就想玩这个,但由于工作原因耽误了,现在又翻出来看看有什么好玩的,下面就详细地记录了我对ElasticSearch的反向架构思考。顺便补充一句,目前用来研究的ElasticSearch的版本号是6.3
先来看看一份对ElasticSearch比较典型的介绍:
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎。无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。不过,Elasticsearch不仅仅是Lucene和全文搜索,我们还能这样去描述它:分布式的实时文件存储,每个字段都被索引并可被搜索
分布式的实时分析搜索引擎
可以扩展到上百台服务器,处理PB级结构化或非结构化数据
而且,所有的这些功能被集成到一个服务里面,你的应用可以通过简单的RESTful API、各种语言的客户端甚至命令行与之交互。上手Elasticsearch非常容易。它提供了许多合理的缺省值,并对初学者隐藏了复杂的搜索引擎理论。它开箱即用(安装即可使用),只需很少的学习既可在生产环境中使用。随着你对Elasticsearch的理解加深,你可以根据不同的问题领域定制Elasticsearch的高级特性,这一切都是可配置的,并且配置非常灵活。
幸亏以前使用过Lucene做IDE底层项目模型关系的管理,对Lucene还算比较熟悉,否则还得先去看看Lucene的功能和用法。
从上面的介绍可以看出几个关键内容:
- Lucene在做索引的时候本身就有存储功能,所以存储这个东西是天然就有的,反而不用花时间考虑。
- 性能是一个比较关键的东西,特别是要做实时引擎,怎么保证高性能。
- ElasticSearch是一个分布式的系统,那么必然存在多结点通讯,协作等问题,比如使用ZooKeeper之类的系统进行注册和协同,当然也保不齐他自己玩一套。
- 既然是分布式系统,那么数据存储就不可能完全单机化,也就是存在Sharding的情况,如何Sharding,如何同步,在查找结果的时候,如何聚合。
- 分布式系统,只要涉及到数据更新,必然存在数据不一致问题,怎么解决。
- 由于索引本身原因,一旦出现Sharding,就很难做联合的查询,这个应该不能实现的,至少说不可能很简单得实现。
- 有一个网络层或者说对外服务接口层,用来进行交互,看介绍,支持多种协议,比如Client直接调用,或者是Restful风格。
- 参考服务接口层,还允许很多地方进行配置,那么很显然,应该是使用了类似于插件的技术来支持很多功能。
我的习惯是从使用者角度来倒推系统架构
- 对外服务,称为Interface,这个其实还相对简单,应该提供两个基本功能,即BuildIndex(不一定要区分Create和Update,但Delete肯定要有)和Query(应该基于主Key和Condition两种查询),把这两个基本接口设计好,然后在上面加不同的封装或者通过Netty之类网络架构提供Rest服务,也可能基于Stub类似的机制提供RPC调用。
- 查询功能,是采用SQL还是Query模型的方式,我更倾向于后者,因为关联查询等很多功能是无法提供的,SQL校验会是比较麻烦的事情。
- 不管是BuildIndex还是Query,肯定要找到一台机器或者多台机器进行处理,由于这是一个分布式系统,而且还支持Sharding,那么可以肯定,需要分组,即Group,一个Group中包括若干个Node,用来支持服务。
- 怎么分组,正常可能是分两级,一种是基于模型定义的,比如对于某一些数据,象商品,用户这些数据可能分成一类数据对应一个Group来处理,这种处理比较直观,也简单。也就是说每一类模型会对应一个Group,而一个Group可能对着多个模型,特别是数据相对较少的时候。还有一种就是Sharding,通常来说,是对一类数据,根据某一个或者几个字段(Field),进行条件分组,也就说在这种分组情况下,每个Node的数据都是不全的,需要将多个Node合并在一起,才会形成完整的数据集。这两种分组都需要支持的。
- 对于BuildIndex和Query,当系统分成多个Group的时候,肯定要有一个Router的概念,即一个BuildIndex或者Query服务来的时候,得找到相应的Group(应该是Group下的Node),因为Lucene中的Document和Term特性,应该需要设计一个类似于数据库中的Table模型,一个Group负责处理多个Table。在BuildIndex和Query请求里,1. 必须带有Table的准确定义,比如User,Item等。
按照前面的思考,Group是肯定应该存在的,但是每个Group否需要一个MasterNode呢? - 当一个Query请求定义清楚后,会以路由的方式找到一个Group,如果数据量不大的话,一个Group中的Node应该是数据对等的,那么请求落到任何一个Node上都可以得到相应的结果。如果数据量很大,出现Sharding,就分两种情况,一种是Query中的条件,能够符合Sharding的定义条件,那么落到任何一个Node上以后,通过转发的方式,总是可以拿到请求,应该有两种实现方式,一是请求发到某个Node上以后,由Node分析后,将可以导向的Node返回,由请求方再次将指定的Node发送请求,二是任意Node直接向可以导向的Node转发请求,并拿到结果后返回给请求方,第二种对客户端友好,但如果数据量大的话,可能不太合适。还有一种情况就是,如果Query中的条件不能够符合Sharding定义,那么就出现类似于数据库查询的FullScan,由收到的Node将请求转发给相应的Node,构成全量搜索,然后由该Node合并后,返回。如果这样看,最好的方式还是Node统一处理,对请求方更友好一些,也更一致。
- 当BuildIndex的时候,必然是发给一个Node,由其完成Index后,再同步给其它Node,此时同步,是有一个MasterNode还是没有好呢?感觉设计一个MasterNode可能使得逻辑更简单。即大的Group里,MasterNode主要负责协作和BuildIndex同步,而Query则可以尽可能地落到DataNode侧。
- 虽然有了MasterNode,但仍然是可以将BuildIndex请求发给DataNode,由DataNode转发给MasterNode,这样会更加简单和友好。
- 考虑到BuildIndex和Query会有不同步的情况,那么怎么减少这种不一致性呢?如果由MasterNode或者指定的一个DataNode进行BuildIndex的时候,对其它Node的Query都会产生数据不一致性问题。假设由MasterNode给其它DataNode全部上锁,此时查询性能急速下降,这种方法不是非常建议,容易形成堵塞,不过如果数据很少更新,而且对数据一致性有较高要求,也可以支持,那里可能得在这个地方允许用户配置一致性优先还是性能优先了。如果是后者的话,按照我对Lucene的了解,此时每个DataNode最好有一个DiskStore和一个MemoryStore,查询时将两者合并查询,这样在保证高性能的情况下可以减少不一致性。或者更灵活一点,允许在BuildIndex的时候允许指定是否加锁,但这样可能会增加复杂度,需要再思考一下。
- 同样是数据不一致问题,除了上面的内容以外,还需要使用Log,这样MasterNode先记录Log,然后进行Index,同时分发给DataNode,DataNode也是先记录Log,这样一旦出现问题,可以随时在启动时从Log处Redo。
- 维护和管理功能:动态扩容,Reindex(扩容时肯定要用到),启动时先与多个DataNode同步Log,再根据Log进行Redo,保证数据的一致性。
- 插件化设计没什么难点,不管是类似于OSGi,还是说直接写一个Plugin的接口,然后加一个PluginManager都可以解决问题。但关键是Plugin需要在哪些情况下调用,以便让开发者可以更多的加入自己的定制。我猜可能有以下几个点:网络请求的Before和After处理(比如支持不同的数据模型,不同的安全检查等,记录日志,流量控制等),启动后的After处理(比如对Log进行Check,以便Redo),BuildIndex和Query的Before和After处理(其实就可以通过这个扩展来处理数据同步的问题)。
- 上面说的插件化设计并不难,但是否使用统一的Plugin接口,还是分开,需要考虑一下,毕竟可以提供扩展点的地方太多了。如果是我设计,大概是三大级继承,最顶层的有一个Plugin或者Extension的接口,提供Name,Desription,Dependecy等内容的定义,这个和Equinox都类似,其实不带任何业务支持的,第二层是业务级别的,比如说网络请求的,日志处理的,第三层就是具体实现了。再多就有点复杂了,有一个最顶层接口的好处是,在Eclipse里,查下继承关系,就得到所有实现了,方便分析代码,如果只设计二和三层,哈哈,就有得找了。
基于以上分析,可以列出来几个基本的元素和服务:
- Node+Group+MasterNode+DataNode
- Table+Field+Key+Condition
- BuildIndex+Query
- Log
- Plugin
下面是大致的架构域图:
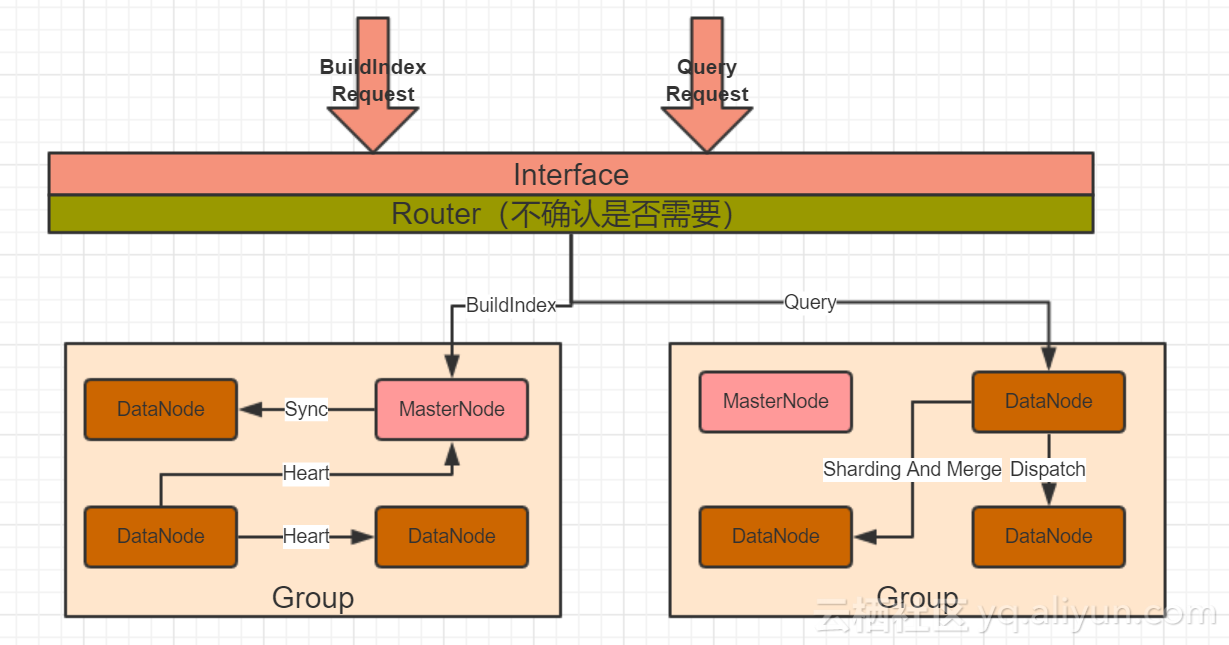
还有几个难点,需要再考虑一下:
- Query可能会有Paging的需要,那么一旦出现Sharding的话,需要将多个DataNode的结果Merge后,进行Sort,再计算Paging后返回。这个对性能的要求比较高,特别是当页面翻到几十页的时候,性能损失非常大,如何处理?还是说技术层面上不做解决,直接让业务方来自行规划。
- 因为ElasticSearch是基于Lucene的,而Lucene并不提供事务操作,比如先行锁再Update,因此一旦出现冲突时,因为网络延时等原因,有可能后面的数据覆盖前面的数据,这种情况怎么考虑,是加一个时间版本号还是忽略这种情况?
- 另外ElasticSearch对数据一致性不可能提供太好的解决方案,因此最好还是将一些非核心业务数据进行查询,比如日志,就不会出现修改,再比如电商中的商品表,修改相对并不频繁,但如果商品表里包含商品数量,那么就挂了,所有必须减少将频繁更新的数据放入搜索。
- 有点记不清楚Lucene的存储机制了,是否支持类似于数据库的Update语句,只更新部分数据。如果不支持,那么ElasticSearch是否需要支持呢?如果是我,应该不会支持,做太多的事情更容易出错。
- 当MasterNode当掉,显然可以通过选举或者别的方法找到一个新的MasterNode,但如果一个MasterNode或者DataNode收到一个BuildIndex请求后,再当掉,最好是通知Client失败,由Client发起重试。由于所有BuildIndex请求都是发给MasterNode来处理的,那么就相对简单了,如果MasterNode失败后重新加入Group,由于此时它不再是Master,就可以丢弃这个日志,保证数据一致性。这块的细节会比较多,记录Log,然后如何Redo,如何Sync,如何抛弃,都需要深入分析。不在这里折腾了。
ElasticSearch架构反向思路相关推荐
- 整理下.net分布式系统架构的思路
最近看到有部分招聘信息,要求应聘者说一下分布式系统架构的思路.今天早晨正好有些时间,我也把我们实际在.net方面网站架构的演化路线整理一下,只是我自己的一些想法,欢迎大家批评指正. 首先说明的是.ne ...
- Java生鲜电商平台-电商中海量搜索ElasticSearch架构设计实战与源码解析
Java生鲜电商平台-电商中海量搜索ElasticSearch架构设计实战与源码解析 生鲜电商搜索引擎的特点 众所周知,标准的搜索引擎主要分成三个大的部分,第一步是爬虫系统,第二步是数据分析,第三步才 ...
- mysql双主架构沈剑_58 沈剑 - 数据库架构师做什么-58同城数据库架构设计思路
1.数据库架构师做什么? 58同城数据库架构设计思路 技术中心-沈剑 shenjian@58.com 2.关亍我-@58沈剑 • 前百度高级工程师 • 58同城技术委员会主席,高级架构师 • 58同城 ...
- 2021年大数据ELK(十一):Elasticsearch架构原理
全网最详细的大数据ELK文章系列,强烈建议收藏加关注! 新文章都已经列出历史文章目录,帮助大家回顾前面的知识重点. 目录 Elasticsearch架构原理 一.Elasticsearch的节点类型 ...
- 秒杀系统架构优化思路
本文曾在"架构师之路"上发布过,近期支援Qcon-AS大会,在微信群里分享了该话题,故对原文进行重新整理与发布. 架构师之路16年精选50篇 一.秒杀业务为什么难做 1)im系统, ...
- 阿里秒杀系统架构优化思路
秒杀业务为什么难做 im系统,例如qq或者微博,每个人都读自己的数据(好友列表.群列表.个人信息) 微博系统,每个人读你关注的人的数据,一个人读多个人的数据 秒杀系统,库存只有一份,所有人会在集中的时 ...
- 基于阿里云数加MaxCompute的企业大数据仓库架构建设思路
摘要: 数加大数据直播系列课程主要以基于阿里云数加MaxCompute的企业大数据仓库架构建设思路为主题分享阿里巴巴的大数据是怎么演变以及怎样利用大数据技术构建企业级大数据平台. 本次分享嘉宾是来自阿 ...
- 哈工大2020软件构造Lab2 Problem3 Playing Chess 架构设计思路
哈工大2020春软件构造实验2 Problem 3 Playing Chess 架构设计思路 问题简述 整体结构 ADT功能设计 功能实现路径 问题简述: 设计一款棋类游戏,同时支持国际象棋(Ches ...
- Elasticsearch架构选型指南——不止是搜索引擎,还有......
最近被咨询到"ETC 卡口数据的存储以及车流量分析.车路线分析业务场景是否适合 Elasticsearch 去做"的问题. 这个问题涉及 Elasticsearch 架构选型的问题 ...
最新文章
- 论文里常出现的可扩展性(Scalability)是什么意思呢?
- canvas-绘制矩形-读书笔记
- windows窗体继承问题
- 推荐搜索炼丹笔记:双塔模型在Airbnb搜索排名中的应用
- keybd_event跟SendMessage,PostMessage模拟键盘消息的区别 z
- python截取后三位元素_python – 如何从BeautifulSoup的表中获取第一个和第三个td?...
- 推荐一个好玩的鼠标和键盘使用情况统计软件,完全免费
- java 数据队列_Java 数据结构 - 队列
- 如何创建一个标准的Windows服务
- instant java,Instant
- 文档中的公式编号怎么不从1开始
- RHEL 7.0安装配置LAMP服务器(Apache+PHP+MariaDB)
- Syslog日志中心服务器收集windows和linux客户端日志
- 【OpenCV】绘图与注释——绘制色差图
- YARN队列优先级分配策略
- 【Mysql】慢SQL优化详解 Mysql案例
- 如何通过二极管设计一个与门电路
- 【conda】conda环境的复制移植的两种方法
- 基恩士XG-XvisionEditor修改程序ID号
- GDKOI2014「壕壕的寒假作业」
热门文章
- 循序渐进!java开发手册阿里巴巴泰山版
- webp环境搭建和使用过程
- 三星java3倍拍照手机_最强安卓拍照手机!三星Note 8将采用双摄+三倍光学变焦
- 华为qy2音乐如何转换为mp3_华为手机还有这种骚操作?开启这个功能,让你体验至尊级待遇...
- python中字典的用法_Python字典操作用法总结
- input file设置默认值_innodb_data_file_path设置--通过错误日志中page大小计算实际值...
- xp mysql字符集与乱码_MySQL乱码的原因和设置UTF8数据格式的方法介绍-mysql教程-学派吧...
- windows启动linux系统,windows 10 启动linux系统
- php vue seo,处理 Vue 单页面 SEO 的另一种思路
- 外服封号_王者荣耀外服玩家被封号十年吐槽无辜,官方复审后,玩家表示轻了...