机器学习PS参数服务器——分布式计算是个什么鬼?
1. Overview
The parameter server aims for high-performance distributed machine learning applications. In this framework, multiple nodes runs over multiple machines to solve machine learning problems. There are often a single schedule node(进度控制节点), and several worker and servers nodes.
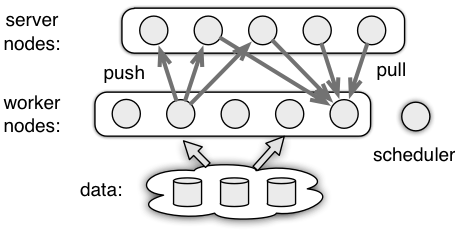
- Worker. A worker node performs the main computations such as reading the data and computing the gradient. It communicates with the server nodes via
pushandpull. For example, it pushes the computed gradient to the servers, or pulls the recent model from them.(通过从PS拉取参数,以及推送参数到PS) - Server. A server node maintains and updates the model weights. Each node maintains only a part of the model.
- Scheduler. The scheduler node monitors the aliveness of other nodes. It can be also used to send control signals to other nodes and collect their progress.(进度控制器)
1.1. Distributed Optimization
Assume(假设) we are going to solve the following
where (yi, xi) are example pairs and w is the weight.
We consider solve the above problem by minibatch stochastic gradient descent (SGD) with batch size b. At time t, this algorithm first randomly picks up b examples, and then updates the weight w by
We give two examples to illusrate(说明) the basic idea of how to implement a distributed optimization algorithm in ps-lite.
1.1.1. Asynchronous SGD 异步随机梯度下降
In the first example, we extend SGD into asynchronous SGD. We let the servers maintain w, where server k gets the k-th segment of w, denoted by wk<\sub>. Once received gradient from a worker, the server k will update the weight it maintained:
t = 0;
while (Received(&grad)) {w_k -= eta(t) * grad;t++;
}
where the function received returns if received gradient from any worker node, and eta returns the learning rate at time t.
While for a worker, each time it dose four things
Read(&X, &Y); // read a minibatch X and Y Pull(&w); // pull the recent weight from the servers ComputeGrad(X, Y, w, &grad); // compute the gradient Push(grad); // push the gradients to the servers
where ps-lite will provide function push and pull which will communicate with servers with the right part of data.
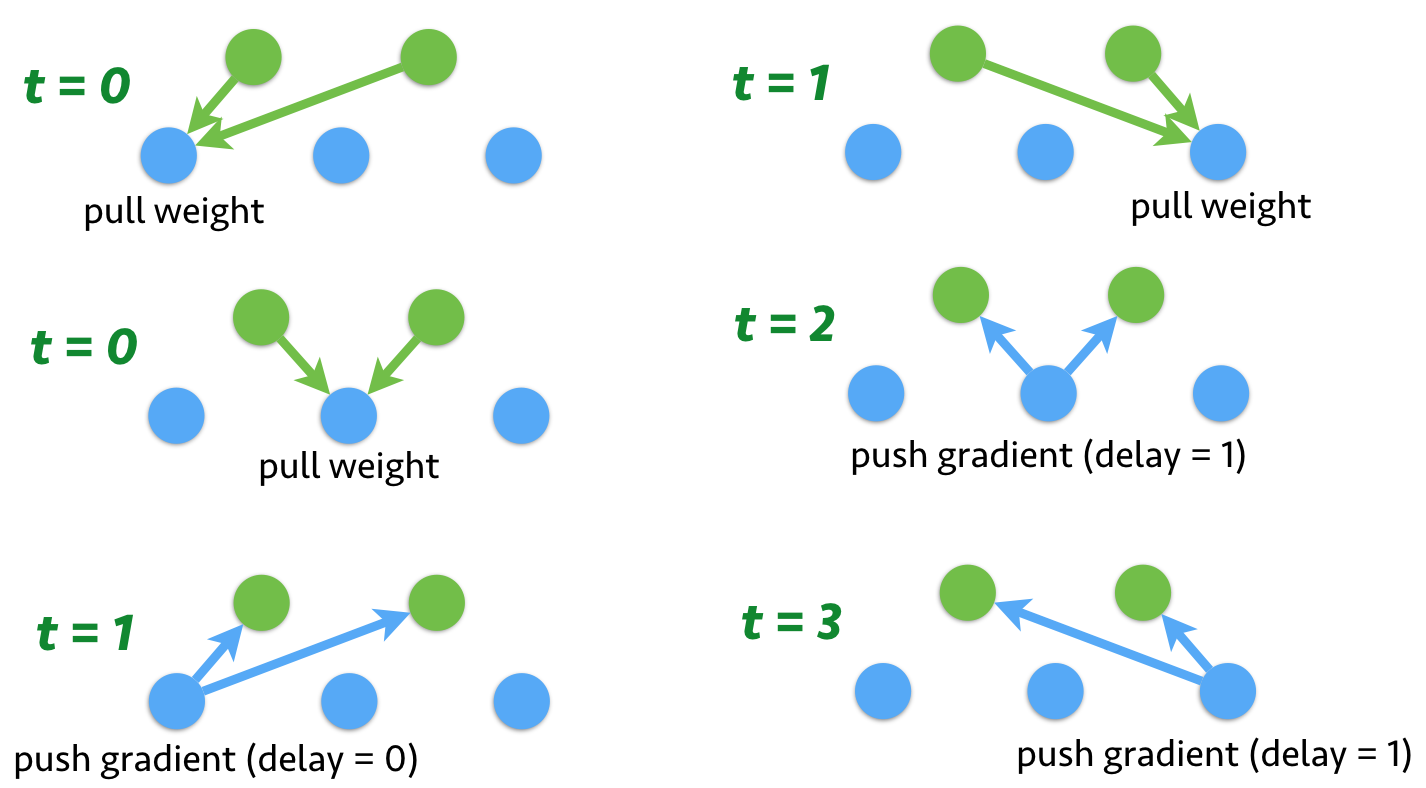
Note that asynchronous SGD is semantically different the single machine version. Since there is no communication between workers, so it is possible that the weight is updated while one worker is calculating the gradients. In other words, each worker may used the delayed(滞后) weights. The following figure shows the communication with 2 server nodes and 3 worker nodes.
1.1.2. Synchronized SGD 同步随机梯度下降
Different to the asynchronous version, now we consider a synchronized version, which is semantically identical(相同) to the single machine algorithm. We use the scheduler to manage the data synchronization
for (t = 0, t < num_iteration; ++t) {for (i = 0; i < num_worker; ++i) {IssueComputeGrad(i, t);}for (i = 0; i < num_server; ++i) {IssueUpdateWeight(i, t);}WaitAllFinished();
}
where IssueComputeGrad and IssueUpdateWeight issue commands to worker and servers, while WaitAllFinished wait until all issued commands are finished.
When worker received a command, it executes the following function,
ExecComputeGrad(i, t) {Read(&X, &Y); // read minibatch with b / num_workers examplesPull(&w); // pull the recent weight from the serversComputeGrad(X, Y, w, &grad); // compute the gradientPush(grad); // push the gradients to the servers
}
which is almost identical to asynchronous SGD but only b/num_workers examples are processed each time.
While for a server node, it has an additional aggregation step comparing to asynchronous SGD
ExecUpdateWeight(i, t) {for (j = 0; j < num_workers; ++j) {Receive(&grad);aggregated_grad += grad;}w_i -= eta(t) * aggregated_grad;
}
1.1.3. Which one to use?
Comparing to a single machine algorithm, the distributed algorithms have two additional costs(两个额外的代价), one is the data communication cost(一个就是通讯代价), namely(也就是) sending data over the network(通过网络发送数据的代价); the other one is synchronization cost due to the imperfect load balance and performance variance cross machines(另一个就是同步代价). These two costs may dominate the performance for large scale applications with hundreds of machines and terabytes of data.(数据量大时尤为明显)
Assume denotations:(符号意义)
| ff | convex function |
| nn | number of examples |
| mm | number of workers |
| bb | minibatch size |
| ττ | maximal delay |
| TcommTcomm | data communication overhead of one minibatch |
| TsyncTsync | synchronization overhead |
The trade-offs are summarized by(总结)
| SGD | slowdown of convergence | additional overhead |
|---|---|---|
| synchronized | b√b | nb(Tcomm+Tsync)nb(Tcomm+Tsync) |
| asynchronous | bτ−−√bτ | nmbTcommnmbTcomm |
What we can see are
- the minibatch size trade-offs the convergence and communication cost (minibatch的大小权衡了收敛和通讯的开销)
- the maximal allowed delay trade-offs the convergence and synchronization cost. In synchronized SGD, we have τ=0 and therefore it suffers a large synchronization cost. While asynchronous SGD uses an infinite τ to eliminate this cost. In practice, an infinite τ is unlikely happens. But we also place a upper bound of τ to guarantee the convergence with some synchronization costs.
1.2. Further Reads
Distributed optimization algorithm is an active research topic these years. To name some of them
- Dean, NIPS‘13, Li, OSDI‘14 The parameter server architecture
- Langford, NIPS‘09, Agarwal, NIPS‘11 theoretical convergence of asynchronous SGD
- Li, NIPS‘14 trade-offs with bounded maximal delays τ
- Li, KDD‘14 improves the convergence rate with large minibatch size b
- Sra, AISTATS‘16 asynchronous SGD adaptive to the actually delay rather than the worst maximal delay
- Li, WSDM‘16 practical considerations for asynchronous SGD with the parameter server
- Chen, LearningSys‘16 synchronized SGD for deep learning.
机器学习PS参数服务器——分布式计算是个什么鬼?相关推荐
- [源码解析] 机器学习参数服务器ps-lite (1) ----- PostOffice
[源码解析] 机器学习参数服务器ps-lite (1) ----- PostOffice 文章目录 [源码解析] 机器学习参数服务器ps-lite (1) ----- PostOffice 0x00 ...
- [源码解析] 机器学习参数服务器 Paracel (1)-----总体架构
[源码解析] 机器学习参数服务器 Paracel (1)-----总体架构 文章目录 [源码解析] 机器学习参数服务器 Paracel (1)-----总体架构 0x00 摘要 0x01使用 1.1 ...
- 参数服务器——分布式机器学习的新杀器
转自:微信公众号 数据极客 在大规模数据上跑机器学习任务是过去十多年内系统架构师面临的主要挑战之一,许多模型和抽象先后用于这一任务.从早期的MPI,到后来的Hadoop,乃至于目前使用较多的Spark ...
- python ray定时_使用 Ray 用 15 行 Python 代码实现一个参数服务器
使用 Ray 用 15 行 Python 代码实现一个参数服务器 参数服务器是很多机器学习应用的核心部分.其核心作用是存放机器学习模型的参数(如,神经网络的权重)和提供服务将参数传给客户端(客户端通常 ...
- 【Spark Summit EU 2016】Glint: Spark的异步参数服务器
更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data:此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.a ...
- [源码解析] NVIDIA HugeCTR,GPU版本参数服务器--- (5) 嵌入式hash表
[源码解析] NVIDIA HugeCTR,GPU版本参数服务器- (5) 嵌入式hash表 文章目录 [源码解析] NVIDIA HugeCTR,GPU版本参数服务器--- (5) 嵌入式hash表 ...
- 服务器记录的定位信息,服务器资讯:巧用机器学习定位云服务器故障
原标题:服务器资讯:巧用机器学习定位云服务器故障 背景 对于每一单母机故障我们都需要定位出背后真实的故障原因,以便对相应的部件进行更换以及统计各种部件故障率的情况,因此故障定位和分析消耗的人力也越来越 ...
- ps连接服务器无响应,ps更新服务器未响应
ps更新服务器未响应 内容精选 换一换 更新token信息握手.设置成"POST".该接口仅支持POST方法,不支持PUT.GET和DELTE等方法.https://ip:port ...
- [翻译] NVIDIA HugeCTR,GPU 版本参数服务器 --(10)--- 推理架构
[翻译] NVIDIA HugeCTR,GPU 版本参数服务器 --(10)- 推理架构 文章目录 [翻译] NVIDIA HugeCTR,GPU 版本参数服务器 --(10)--- 推理架构 0x0 ...
最新文章
- aa bb ccc java,TinyTemplate(Velocity Plus版)即将火热推出~~~
- 用MacBook对交换机进行初始化配置
- X509证书 指定了无效的提供程序类型 System.Security.Cryptography.CryptographicException 错误解决方法
- python章节总结_《Python深度学习》第一章总结
- 分布式唯一ID生成器
- VS2012手动关联xaml与CS文件
- Non-resolvable parent POM for com.supermarket:supermarket:0.0.1-SNAPSHOT: Could not transfer artifac
- Python中的枚举类型
- ListViewAdapter
- 南邮数据库系统设计期中测试题库(雨课堂 + 慕课)
- 软件开发打败了80%的程序员
- Spring 与 Hibernate 集成 Transactional设置为只读
- Unity中Camera的Clear flags,Culling Mask,Depth参数
- 搞笑--亚阳影视官方的keyword里写“破解版”
- 外贸企业域名邮箱怎么申请?
- 使用Bugly 作为APP异常上报工具
- 2020 用html jQuery实现广告轮播图自动切换 滚动页面 鼠标悬浮下标且左右切换图片
- Guava base -- Splitter
- Crime and Punishment
- 如何查到营业执照_知道法人姓名,如何查营业执照?