Python爬虫(二)——豆瓣图书决策树构建
前文参考: https://www.cnblogs.com/LexMoon/p/douban1.html
Matplotlib绘制决策树代码:
1 # coding=utf-8
2 import matplotlib.pyplot as plt
3
4 decisionNode = dict(boxstyle='sawtooth', fc='10')
5 leafNode = dict(boxstyle='round4',fc='0.8')
6 arrow_args = dict(arrowstyle='<-')
7
8
9
10 def plotNode(nodeTxt, centerPt, parentPt, nodeType):
11 createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',\
12 xytext=centerPt,textcoords='axes fraction',\
13 va='center', ha='center',bbox=nodeType,arrowprops\
14 =arrow_args)
15
16
17 def getNumLeafs(myTree):
18 numLeafs = 0
19 firstStr = list(myTree.keys())[0]
20 secondDict = myTree[firstStr]
21 for key in secondDict:
22 if(type(secondDict[key]).__name__ == 'dict'):
23 numLeafs += getNumLeafs(secondDict[key])
24 else:
25 numLeafs += 1
26 return numLeafs
27
28 def getTreeDepth(myTree):
29 maxDepth = 0
30 firstStr = list(myTree.keys())[0]
31 secondDict = myTree[firstStr]
32 for key in secondDict:
33 if(type(secondDict[key]).__name__ == 'dict'):
34 thisDepth = 1+getTreeDepth((secondDict[key]))
35 else:
36 thisDepth = 1
37 if thisDepth > maxDepth: maxDepth = thisDepth
38 return maxDepth
39
40 def retrieveTree(i):
41 #预先设置树的信息
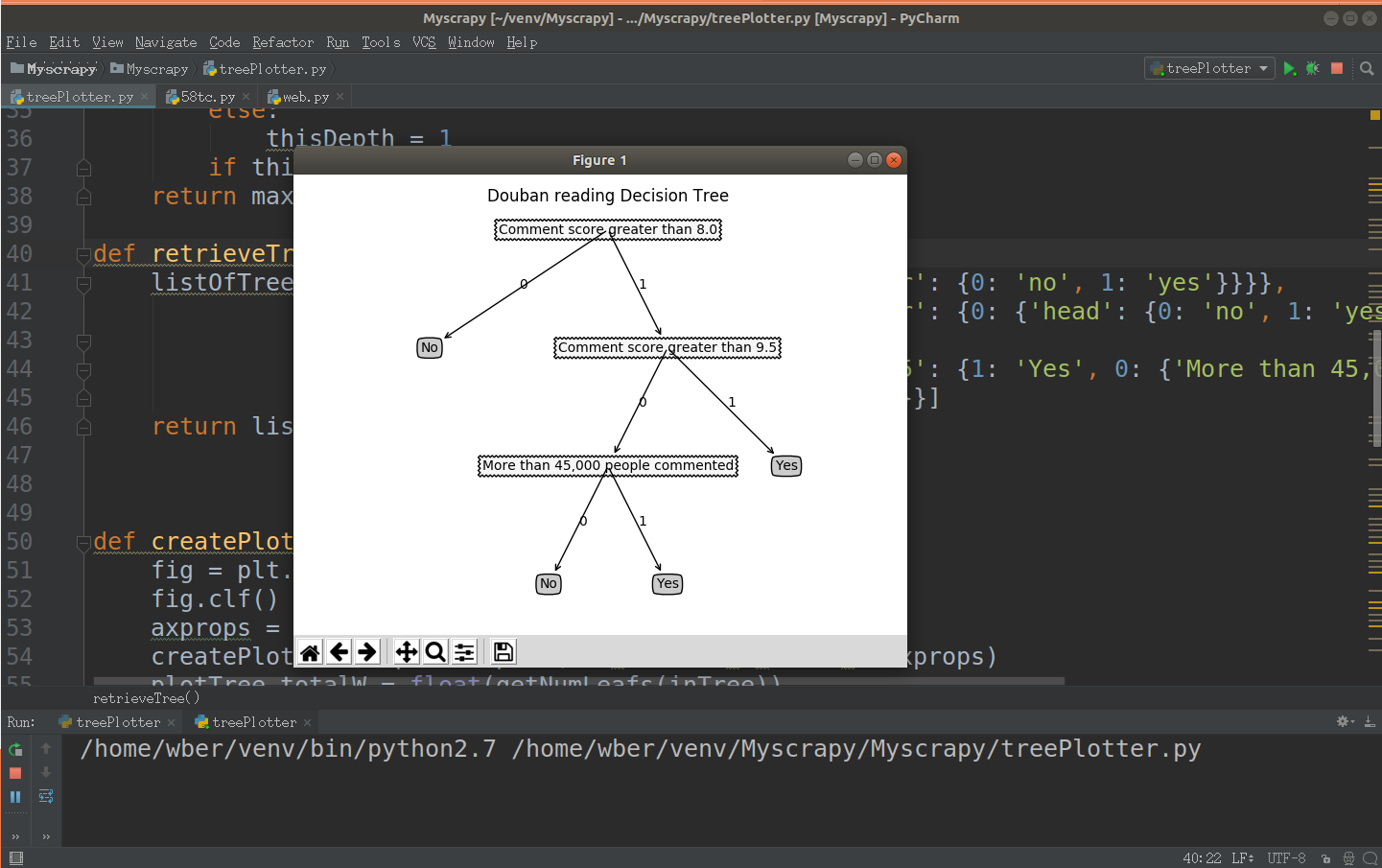
42 listOfTree = [{'no surfacing':{0:'no',1:{'flipper':{0:'no',1:'yes'}}}},
43 {'no surfacing':{0:'no',1:{'flipper':{0:{'head':{0:'no',1:'yes'}},1:'no'}}}},
44 {'Comment score greater than 8.0':{0:{'Comment score greater than 9.5':{0:'Yes',1:{'More than 45,000 people commented': {
45 0: 'Yes',1: 'No'}}}},1:'No'}}]
46 return listOfTree[i]
47
48 def createPlot(inTree):
49 fig = plt.figure(1,facecolor='white')
50 fig.clf()
51 axprops = dict(xticks = [], yticks=[])
52 createPlot.ax1 = plt.subplot(111,frameon = False,**axprops)
53 plotTree.totalW = float(getNumLeafs(inTree))
54 plotTree.totalD = float(getTreeDepth(inTree))
55 plotTree.xOff = -0.5/plotTree.totalW;plotTree.yOff = 1.0
56 plotTree(inTree,(0.5,1.0), '')
57 plt.title('Douban reading Decision Tree\n')
58 plt.show()
59
60 def plotMidText(cntrPt, parentPt,txtString):
61 xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0]
62 yMid = (parentPt[1] - cntrPt[1])/2.0 + cntrPt[1]
63 createPlot.ax1.text(xMid, yMid, txtString)
64
65 def plotTree(myTree, parentPt, nodeTxt):
66 numLeafs = getNumLeafs(myTree)
67 depth = getTreeDepth(myTree)
68 firstStr = list(myTree.keys())[0]
69 cntrPt = (plotTree.xOff+(1.0+float(numLeafs))/2.0/plotTree.totalW,\
70 plotTree.yOff)
71 plotMidText(cntrPt,parentPt,nodeTxt)
72 plotNode(firstStr,cntrPt,parentPt,decisionNode)
73 secondDict = myTree[firstStr]
74 plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD
75 for key in secondDict:
76 if type(secondDict[key]).__name__ == 'dict':
77 plotTree(secondDict[key],cntrPt,str(key))
78 else:
79 plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
80 plotNode(secondDict[key],(plotTree.xOff,plotTree.yOff),\
81 cntrPt,leafNode)
82 plotMidText((plotTree.xOff,plotTree.yOff),cntrPt,str(key))
83 plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
84
85 if __name__ == '__main__':
86 myTree = retrieveTree(2)
87 createPlot(myTree)运行结果:
Python爬虫(二)——豆瓣图书决策树构建相关推荐
- python爬虫获取豆瓣图书Top250
在上一篇博客<python爬虫获取豆瓣电影TOP250>中,小菌为大家带来了如何将豆瓣电影Top250的数据存入MySQL数据库的方法.这次的分享,小菌决定再带着大家去研究如何爬取豆瓣图片 ...
- Python爬虫(5):豆瓣读书练手爬虫
Python爬虫(5):豆瓣读书练手爬虫 我们在之前的文章中基本上掌握了Python爬虫的原理和方法,不知道大家有没有练习呢.今天我就来找一个简单的网页进行爬取,就当是给之前的兵书做一个实践.不然不就 ...
- Python 爬虫分析豆瓣 TOP250 之 信息字典 和 马斯洛的锥子
问题 本文是对<Python 爬虫分析豆瓣 TOP250 告诉你程序员业余该看什么书?> 一文的补充 我们以<追风少年>为例 用chrome的developer tool查看源 ...
- Python爬虫之豆瓣排行榜(正则表达式)
Python爬虫之豆瓣排行榜(正则表达式) 1. 项目目标 使用Chrome浏览器打开网页https://maoyan.com/ ,切换到[榜单],[TOP100榜].本次项目就是要获取豆瓣排名Top ...
- 使用Python爬虫获取豆瓣影评,并用词云显示
使用Python爬虫获取豆瓣影评,并用词云显示 Python语言流行到现在,目前最受开发者喜爱的功能莫过于它的爬虫功能,以至于很多人以为Python的英语发音也是"爬虫",其实它是 ...
- python爬取豆瓣图书(详细步骤讲解)
题目: 老师安排我们爬取豆瓣图书,恰好想学,所以把爬取的过程按照顺序写下来,主要是留个痕迹.在文中我会把爬虫所需的所有代码以图片形式一一讲解,图片里的代码就是全部的爬虫代码!!!如果你懒得自己敲的话, ...
- 实战python网络爬虫豆瓣_三分钟教会你利用Python爬虫实现豆瓣电影采集(实战篇)...
一.项目背景 豆瓣电影提供最新的电影介绍及评论包括上映影片的影讯查询及购票服务.可以记录想看.在看和看过的电影电视剧 .顺便打分.写影评.极大地方便了人们的生活. 今天小编以电视剧(美剧)为例,批量爬 ...
- Python爬虫实战----------豆瓣TOP250
*前段时间学习了一些浅显的爬虫知识,防止遗忘写个博客记录一下,如果能帮到其他人是更好的 本篇介绍一下如何一步一步实现使用python爬取豆瓣电影TOP250,博主是个小白,如果内容有误,请将宝贵的建议 ...
- 三分钟教会你利用Python爬虫实现豆瓣电影采集(实战篇)
一.项目背景 豆瓣电影提供最新的电影介绍及评论包括上映影片的影讯查询及购票服务.可以记录想看.在看和看过的电影电视剧 .顺便打分.写影评.极大地方便了人们的生活. 今天小编以电视剧(美剧)为例,批量爬 ...
最新文章
- java飞机大战爆炸效果_Java飞机大战游戏设计与实现
- 【Web前端培训】预解析(变量提升)
- Visual Studio 2017 15.7预览版发布
- mybatis对mapper.xml的解析(二)
- excel执行INSERT和UPDATE操作语句
- mysql的还原_MySQL 还原
- apche commons项目简介
- 跟新centos的yum源
- 事关SuperSocket发布,寻找YangFan哥哥
- 前端学习(684):循环导读
- 斯坦福CS224n追剧计划【大结局】:NLP和深度学习的未来
- Deepin 系统下安装VMware并激活
- c php curl post,php curl post
- SQL Server字符串处理函数大全
- VS2015自定义编程背景
- RK3566调试外部以太网PHY
- 初识人工智能,机器学习,深度学习的关系(概念)
- 快速健身---马步站桩
- 手把手教你用SetWindowsHookEx做一个键盘记录器
- 信号傅里叶变换后的实数和虚数部分理解