平台篇-58 HBase 平台实践和应用
HBase 是一个基于 Hadoop 的分布式、面向列的 Key-Value 存储系统,可以对需 要实时读写、随机访问大规模数据集的场景提供高可靠、高性能的服务,在大数 据相关领域应用广泛。HBase 可以对数据进行透明的切分,使得存储和计算本身 具有良好的水平扩展性。
在 58 的业务场景中,HBase 扮演重要角色。例如帖子信息等公司基础数据都是 通过 HBase 进行离线存储,并为各个业务线提供随机查询及更深层次的数据分 析。同时 HBase 在 58 还大量用于用户画像、搜索、推荐、时序数据和图数据等 场景的存储和查询分析。
HBase 在 58 的应用架构:
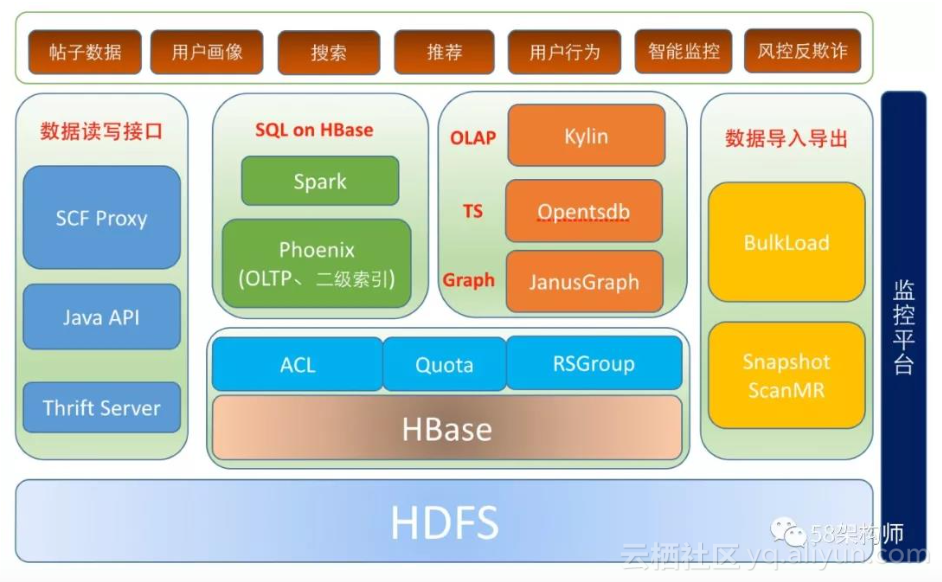
**
HBase 在 58 的应用架构如上图所示,主要内容包括以下几个部分:**
- 多租户支持:包括 SCF 限流、RSGroup、RPC 读写分离、HBase Quota 、ACL;
- 数据读写接口:包括 SCF 代理 API、原生 Java API 以及跨语言访问 Thrift Server;
- HBase 数据导入导出:包括数据批量导入工具 BulkLoad,数据批量导出工具
SnapshotMR; - OLAP:多维分析查询的 Kylin 平台;
- 时序数据库:时序数据存储和查询的时序数据库 Opentsdb;
- 图数据库:图关系数据存储和查询的图数据库 JanusGraph;
- SQL on HBase:支持二级索引和事务的 Phoenix,以及 Spark SQL 等;
- HBase 在 58 的应用业务场景包括:全量帖子数据、用户画像、搜索、推荐、
用户行为、智能监控以及风控反欺诈等的数据存储和分析; - 监控平台:HBase 平台的监控实现。
本文将从多租户支持、数据读写接口、数据导入导出和平台优化四个方面来重点 讲解 58HBase 平台的建设。
说明:下文中所有涉及到 RegionServer 的地方统一使用 RS 来代替。
1. HBase 多租户支持
HBase 在 1.1.0 版本之前没有多租户的概念,同一个集群上所有用户、表都是同 等的,导致各个业务之间干扰比较大,特别是某些重要业务,需要在资源有限的 情况下保证优先正常运行,但是在之前的版本中是无法保证的。从 HBase 1.1.0 开始,HBase 的多租户特性逐渐得到支持,我们的 HBase 版本是 1.0.0-cdh5.4.4, 该版本已经集成了多租户特性。
以下是 58 用户访问 HBase 的流程图:
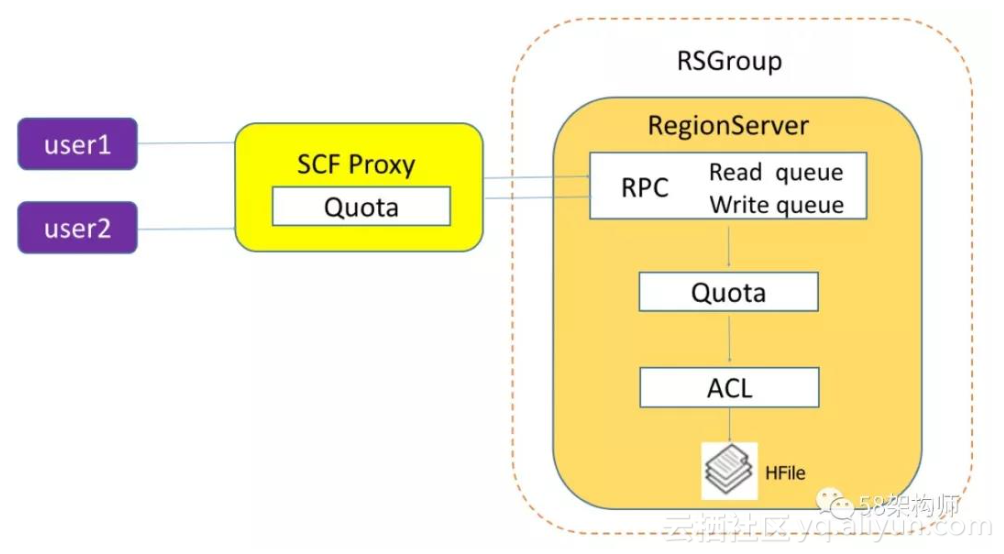
我们从多个层面对 HBase 多租户进行了支持,主要分为以下两个大的方面:
- 资源限制:
a) SCF Quota;
b) HBase Quota。
- 资源隔离:
a) RS RPC 读写分离;
b) HBase ACL 权限隔离;
c) RSGroup 物理隔离。
**1.1 资源限制
(1)SCF Quota**
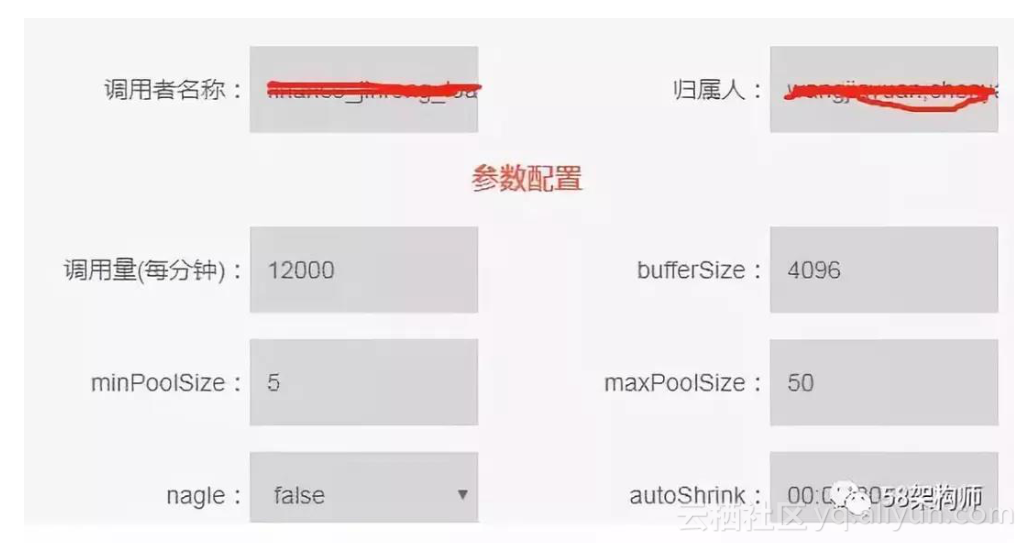
SCF 是公司自研的 RPC 框架,我们基于 SCF 封装了原生 HBase API,用户根据应 用需要申请 HBase SCF 服务调用时,需要根据应用实际情况填写 HBase 的每分 钟调用量(请求次数),在调用量超限时,SCF 管理平台可以实现应用级的限流, 这是全局限流。缺点是只能对调用量进行限制,无法对读写数据量大小限制。
以下是用户申请 HBase SCF 服务调用时需要填写的调用量:
(2)HBase Quota
HBase 的 Quota 功能可以实现对用户级、表级和命名空间级的资源进行限制。这 里的资源包括请求数据量大小、请求次数两个维度,这两个维度基本涵盖了常见 的资源限制。目前 HBase 的 Quota 功能只能限制到 RS 这一级,不是针对整个集 群的。但是因为可以对请求的数据量大小进行限制,一定程度上可以弥补了 SCF Proxy 应用级限流只能对请求次数进行限制的不足。
开启 Quota 的配置如下:

在开启了 HBase 的 Quota 后,Quota 相关的元数据会存储到 HBase 的系统表 hbase:quota 中。
在我们的 HBase 集群中之前遇到过个别用户读写数据量过大导致 RS 节点带宽被 打满,甚至触发 RS 的 FGC,导致服务不稳定,影响到了其他的业务,但是应用级的调用量并没有超过申请 SCF 时设置的值,这个时候我们就可以通过设置 HBase Quota,限制读写表级数据量大小来解决这个问题。
以下是设置 HBase Quota 信息,可以通过命令行进行设置和查看:

1.2 资源隔离
(1)RS RPC 读写分离
默认场景下,HBase 只提供一个 RPC 请求队列,所有请求都会进入该队列进行 优先级排序。这样可能会出现由于读问题阻塞所有 handler 线程导致写数据失败, 或者由于写问题阻塞所有 handler 线程导致读数据失败,这两种问题我们都遇到过,在后续篇幅中会提到,这里不细述。
通过设置参数 hbase.ipc.server.callqueue.handler.factor 来设置多个队列,队列个数等于该参数 * handler 线程数,比如该参数设置为 0.1,总的 handler 线程数为200,则会产生 20 个独立队列。 独立队列产生之后,可以通过参数 hbase.ipc.server.callqueue.read.ratio 来设置读写队列比例,比如设置 0.6,则表示会有 12 个队列用于接收读请求,8 个用于接收写请求;另外,还可以进一步 通过参数 hbase.ipc.server.callqueue.scan.ratio 设置 get 和 scan 的队列比例,比 如设置为 0.2,表示 2 个队列用于 scan 请求,另外 10 个用于 get 请求,进一步还将 get 和 scan 请求分开。
RPC 读写分离设计思想总体来说实现了读写请求队列资源的隔离,达到读写互不干扰的目的,根据 HBase 集群服务的业务类型,我们还可以进一步配置长时 scan 读和短时 get 读之间的队列隔离,实现长时读任务和短时读任务互不干扰。
(2)HBase ACL 权限隔离
HBase 集群多租户需要关注的一个核心问题是数据访问权限的问题,对于一些重 要的公共数据,或者要进行跨部门访问数据,我们只开放给经过权限申请的用户 访问,没有权限的用户是不能访问的,这就涉及到了 HBase 的数据权限隔离了, HBase 是通过 ACL 来实现权限隔离的。
基于 58 的实际应用情况,访问 HBase 的用户都是 Hadoop 计算集群的用户,而 且 Hadoop 用户是按部门分配的,所以 HBase 的用户也是到部门而不是到个人, 这样的好处是维护的用户数少了,便于管理,缺点是有的部门下面不同子部门之 间如果也要进行数据权限隔离就比较麻烦,需要单独申请开通子部门账号。
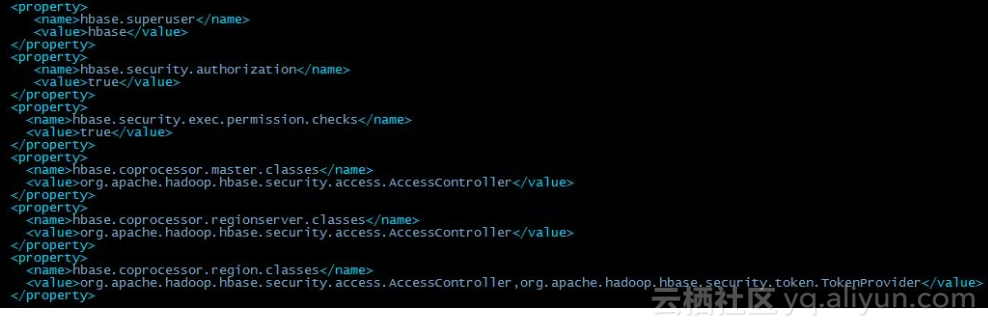
要开启 HBase 的 ACL,只需要在配置文件 hbase-site.xml 中关于 Master、 RegionServer 和 Region 的协处理器都加上 org.apache.hadoop.hbase.security.access.AccessController 类就可以了。
具体 HBase ACL 的配置项如下图所示:
HBase 的访问级别有读取(R)、写入(W)、执行(X)、创建(C)、管理员(A),而权限作 用域包括超级用户、全局、命名空间、表、列族、列。访问级别和作用域的组合 创建了可授予用户的可能访问级别的矩阵。在生产环境中,根据执行特定工作所 需的内容来考虑访问级别和作用域。
在 58 的实际应用中,我们将用户和 HBase 的命名空间一一对应,创建新用户时, 创建同名的命名空间,并赋予该用户对同名命名空间的所有权限(RWCA)。以下 以新用户 zhangsan 为例,创建同名命名空间并授权:

(3)RSGroup 物理隔离
虽然 SCF Quota 和 HBase Quota 功能可以做到对用户的读写进行限制,一定程度上能降低各业务读写数据的相互干扰,但是在我们的实际业务场景中,存在两类特殊业务,一类是消耗资源非常大,但是不希望被限流,另外一类是非常重要, 需要高优先级保证服务的稳定。对于这两种情况下,我们只能对该业务进行物理隔离,物理隔离既能保证重要业务的稳定性,也避免了对其他业务的干扰。我们使用的物理隔离方案是 RSGroup,也即 RegionServer Group。
RSGroup 整体架构:
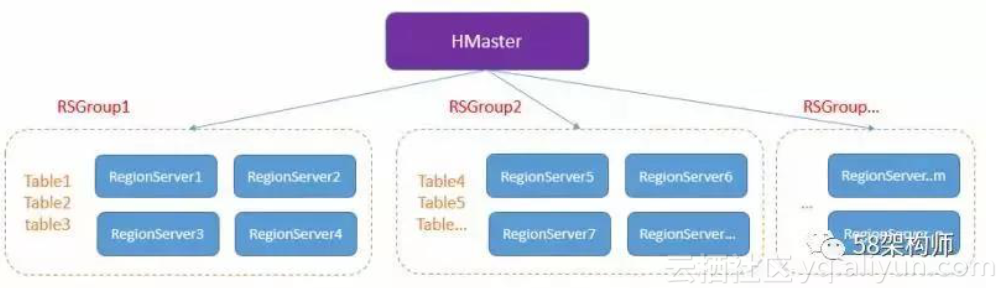
RSGroup 有以下几个特点:
- 不同 RS 和表划分到不同的 RSGroup;
- 同一个 RS 只能属于一个 RSGroup;
- 同一个表也只能属于一个 RSGroup;
- 默认所有 RS 和表都属于“default”这个 RSGroup。
RSGroup 实现细节:
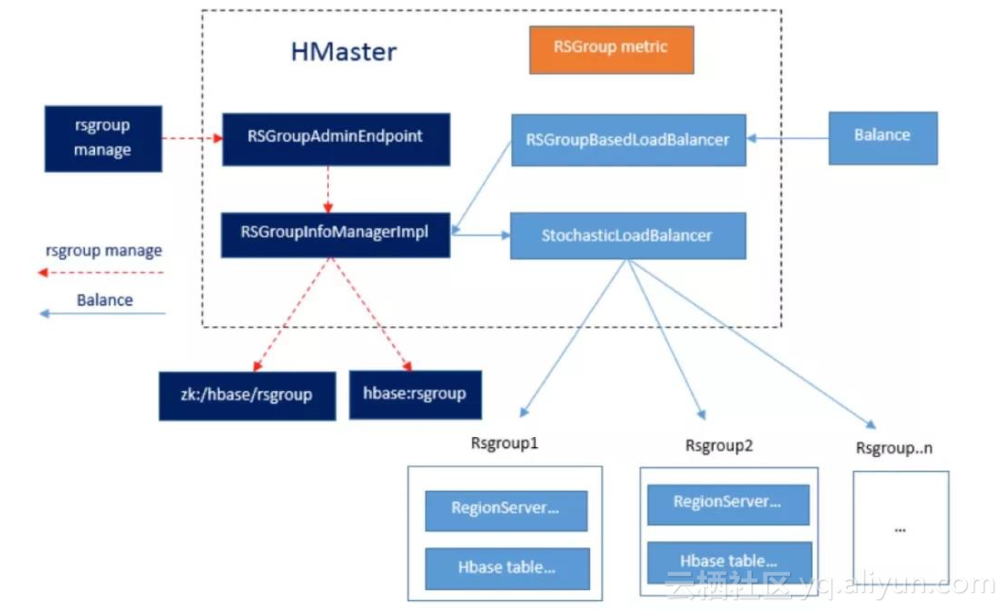
从以上 RSGroup 实现细节中看出,RSGroup 的功能主要包含两部分,RSGroup 元数据管理以及 Balance。
RSGroup 开启的配置项:

- 数据读写接口
目前我们提供了三种 HBase 的数据读写接口以便于用户使用,包括 SCF 代理、 Java 原生 API 和 Thrift Server。以下分别进行说明:
2.1 SCF Proxy
SCF 是 58 架构部自研的 RPC 框架,我们基于 SCF 封装了原生的 Java API,以 SCF RPC 接口的方式暴露给用户使用,其中以这种方式提供给用户的接口多达 30 个。 由于 SCF 支持跨语言访问,很好的解决了使用非 Java 语言用户想要访问 HBase 数据的问题,目前用户使用最多的是通过 Java、Python 和 PHP 这三种语言来访问这些封装的接口。
SCF proxy 接口整体架构:
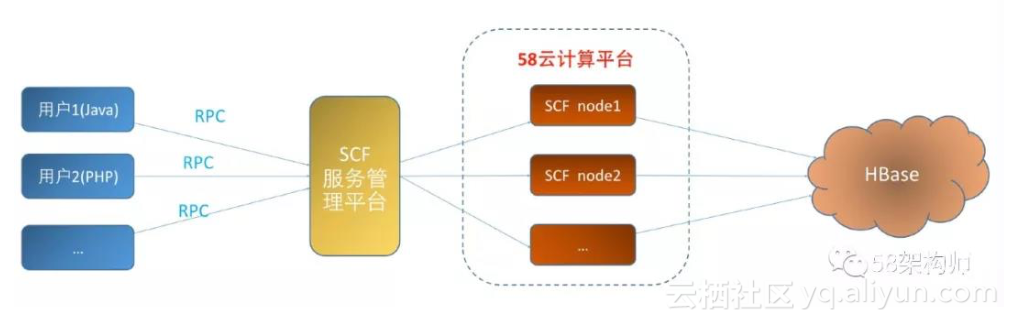
数据读写流程:用户通过 RPC 连接到 SCF 服务管理平台,通过 SCF 服务管理平 台做服务发现,找到 58 云计算平台上部署的服务节点,服务节点最终通过访问 HBase 实现用户数据的读写操作。
使用 SCF Proxy 接口的优势:
- 避免用户直连 HBase 集群,降低 zk 的压力。之前经常遇到因为用户代码存 在 bug,导致 zk 连接数暴涨的情况。
- 针对大量一次性扫描数据的场景,提供单独访问接口,并在接口中设置 scan 的 blockcache 熟悉为 false,避免了对后端读缓存的干扰。
- 通过服务管理平台的服务发现和服务治理能力,结合业务的增长情况以及基 于 58 云计算平台弹性特点,我们很容易对服务节点做自动扩容,而这一切对用户是透明的。
- 通过服务管理平台可以实现对用户的访问做应用级限流,规范用户的读写操作。
- 服务管理平台提供了调用量、查询耗时以及异常情况等丰富的图表,用户可以很方便查看。
以下是我们的 SCF 服务在服务管理平台展示的调用量和查询耗时图表:
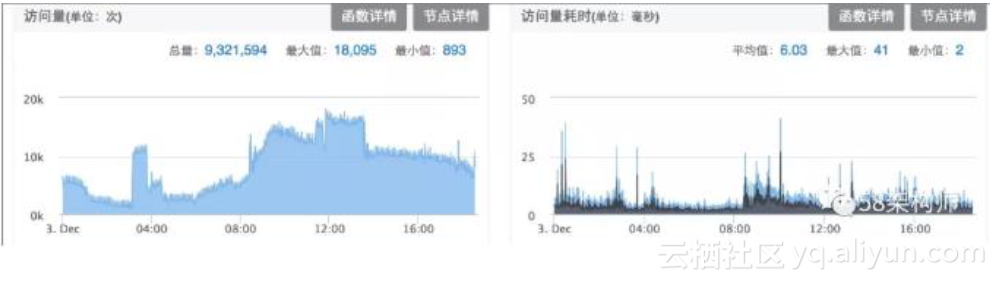
由于 SCF Proxy 接口的诸多优势,我们对于新接的业务都要求通过申请这种方式 来访问 HBase。
2.2 Java API
由于历史原因和个别特殊的新业务还采用 Java 原生的 API 外,其他新业务都通 SCF Proxy 接口来访问。
**
2.3 Thrift Server**
也是由于历史原因,个别用户想使用非 Java 语言来访问 HBase,才启用了 Thrift Server,由于 SCF proxy 接口支持多语言,目前这种跨语言访问的问题都通过 SCF Proxy 来解决了。
3. 数据导入导出 3.1 BulkLoad
3.1 BulkLoad
HBase 相对于其他 KV 存储系统来说比较大的一个优势是提供了强大的批量导入 工具 BulkLoad,通过 BulkLoad,我们很容易将生成好的几百 G,甚至上 T 的 HFile 文件以毫秒级的速度导入 HBase,并能马上进行查询。所以对于历史数据和非实 时写入的数据,我们会建议用户通过 BulkLoad 的方式导入数据。
3.2 SnapshotScanMR
针对全表扫描的应用场景,HBase 提供了两种解决方案,一种是 TableScanMR, 另一种就是 SnapshotScanMR,这两种方案都是采用 MR 来并行化对数据进行扫描,但是底层实现原理确是有很大差别,以下会进行对比分析。
TableScanMR 的实现原理图:
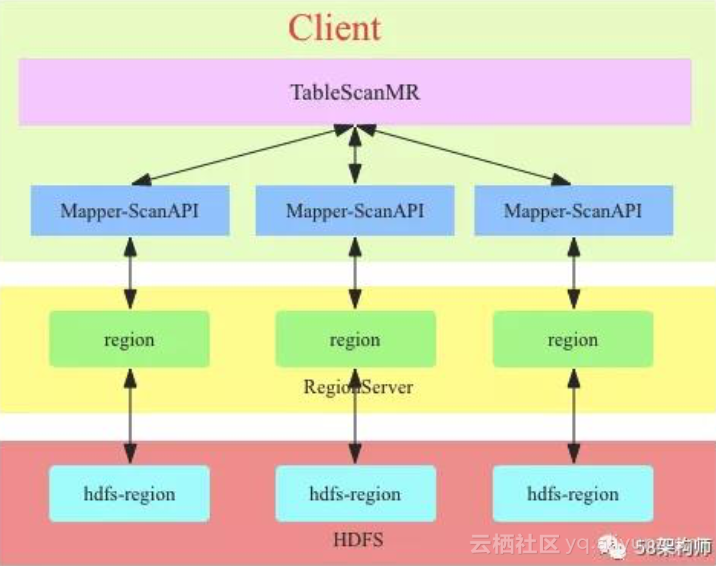
TableScanMR 会将 scan 请求根据 HBase 表的 region 分界进行分解,分解成多个 sub-scan(一个 sub-scan 对应一个 map 任务),每个 sub-scan 内部本质上就是一个 ScanAPI。假如 scan 是全表扫描,那这张表有多少 region,就会将这个 scan 分解成多个 sub-scan,每个 sub-scan 的 startkey 和 stopkey 就是 region 的 startkey 和 stopkey。这种方式只是简单的将 scan 操作并行化了,数据读取链路 和直接 scan 没有本质区别,都需要通过 RS 来读取数据。
SnapshotScanMR 的实现原理图:
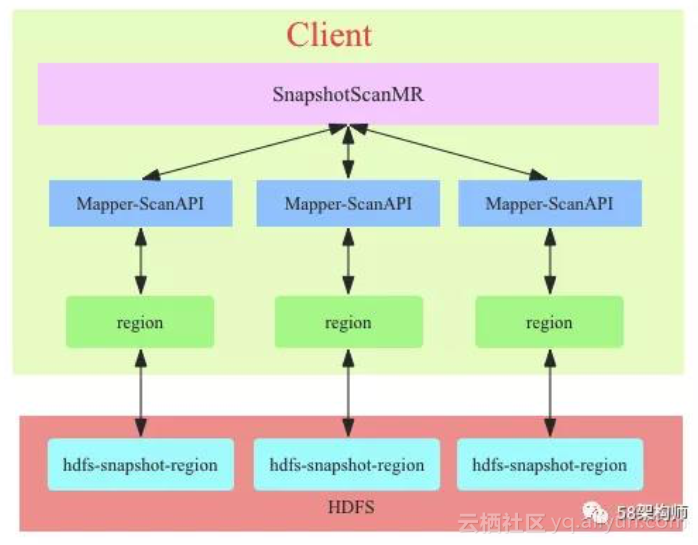
SnapshotScanMR 总体来看和 TableScanMR 工作流程基本一致,不过 SnapshotScanMR 的实现依赖于 HBase 的 snapshot,通过 shapshot 的元数据信息,SnapshotScanMR 可以很容易知道当前全表扫描要访问那些 HFile以及这些 HFile 的 HDFS 路径,所以 SnapshotScanMR 构造的 sub-scan 可以绕过 RS,直接 借用 Region 中的扫描机制直接扫描 HDFS 中数据。
SnapshotScanMR 优势:
- 避免对其他业务的干扰:SnapshotScanMR 绕过了 RS,避免了全表扫描对其 他业务的干扰。
- 极大的提升了扫描效率:SnapshotScanMR 绕过了 RS,减少了一次网络传输, 对应少了一次数据的序列化和反序列化操作;TableScanMR 扫描中 RS 很可 能会成为瓶颈,而 SnapshotScanMR 不需要担心这一点。
基于以上的原因,在全部扫描,以及全部数据导出的应用场景中,我们选择了 SnapshotScanMR,并对原生的 SnapshotScanMR 进行了进一步的封装,作为一个通用工具提供给用户。
4. 平台优化
在使用 HBase 的过程中,我们遇到了很多问题和挑战,但最终都一一克服了,以下是我们遇到一部分典型问题及优化:
4.1 CLOSE_WAIT 偏高优化
问题描述:在一次排查 HBase 问题的时候发现 RS 进程存在大量的 CLOSE_WAIT, 最多的达到了 6000+,这个问题虽然还没有直接导致 RS 挂掉,但是也确实是个 不小的隐患。
从 socket 的角度分析产生 CLOSE_WAIT 的原因:对方主动关闭连接或者网络异 常导致连接中断,这时我方的状态会变成 CLOSE_WAIT, 此时我方要调用 close() 来使得连接正确关闭,否则 CLOSE_WAIT 会一直存在。
对应到咱们这个问题,其实就是用户通过 RS 访问 DataNode(端口 50010)的数 据,DataNode 端已经主动关闭 Socket 了,但是 RS 端没有关闭,所以要解决的 问题就是 RS 关闭 Socket 连接的问题。
解决办法:社区对该问题的讨论见 HBASE-9393。该问题的修复依赖 HDFS-7694, 我们的 Hadoop 版本是 hadoop2.6.0-cdh5.4.4,已经集成了 HDFS-7694 的内容。
HBASE-9393 的核心思想是通过 HDFS API 关闭 HBase 两个地方打开的 Socket;
RS 打开 HFile 读取元数据信息(flush、bulkload、move、balance 时)后关闭 Socket;每次执行完成用户 scan 操作后关闭 Socket。
优化效果:CLOSE_WAIT 数量降为 10 左右
4.2 DN 慢盘导致 RS 阻塞优化
问题描述:由于集群某个磁盘出现坏道(没有完全坏,表现为读写慢,disk.io.util 为 100%),导致 RS 所有 handler 线程因为写 WAL 失败而被阻塞,无法对外提 供服务,严重影响了用户读写数据体验。
最后分析发现,RS 写 WAL 时由于 DN 节点出现磁盘坏道(表现为 disk.io.util 为长时间处于 100%),导致写 WAL 的 pipeline 抛出异常并误将正常 DN 节点标记为 bad 节点,而恢复 pipeline 时使用 bad 节点进行数据块 transfer,导致 pipeline 恢复失败,最终 RS 的所有写请求都阻塞到 WAL 的 sync 线程上,RS 由于没有可用的 handler 线程,也就无法对外提供服务了。
解决办法:RS 配置 RPC 读写分离:避免由于写阻塞所有 handler 线程,影响到读请求;
pipeline 恢复失败解决:社区已有该问题的讨论,见并 HDFS-9178,不过因为 HDFS 的 pipeline 过程非常复杂,HDFS-9178 能否解决该问题需要进一步验证。
4.3 Compact 占用 Region 读锁优化
问题描述:某次有一个业务执行 BulkLoad 操作批量导入上 T 的数据到 HBase 表时,RS 端报 BulkLoad 操作获取 Region 级写锁出现超时异常:failed to get a lock in 60000 ms,当时该表并没有进行读写操作,最终定位到是该时间段内这个业务 的表正在进行 compact 操作,在我们的 HBase 版本中,执行 compact 时会获取 Region 级的读锁,而且会长时间占用,所有导致 BulkLoad 获取写锁超时了。
解决办法:Compact 时不持有 Region 读锁,社区对该问题的讨论见 HBASE-14575。
4.4 HTablePool 问题优化
问题描述:我们的 SCF 服务最初是基于 HTablePool API 开发的,SCF 服务在运 行一段时间后经常会出现 JVM 堆内存暴增而触发 FGC 的情况,分析发现 HTablePool 已经是标记为已废弃,原因是通过 HTablePool 的获取 Table 对象,会创建单独的线程池,而且线程个数没有限制,导致请求量大时,线程数会暴增。
解决办法:最后我们换成了官方推荐的 API,通过 Connection 获取 Table,这种方式 Connection 内部的线程池可以在在所有表中共享,而且线程数是可配置的。
4.5 其他优化
BlockCache 启用 BuckCache;Compact 限流优化等。
5. 总结
Apache HBase 实战技术总结 – 中国 HBase 技术社区
本文从多租户支持、数据读写接口、数据导入导出和平台优化四个方面讲解了 HBase 相关的平台建设工作。HBase 作为一个开源的平台,有着非常丰富的生态 系统。在 HBase 平台基础之上,我们持续不断地引入了各种新的能力,包括 OLAP、 图数据库、时序数据库和 SQL on HBase 等,这些我们将在 58HBase 平台实践和应用的后续篇章中进一步介绍。
转载
文章作者:何良均/张祥——58 同城 资深研发工程师
平台篇-58 HBase 平台实践和应用相关推荐
- kylin如何支持flink_Kylin 在腾讯的平台化及 Flink 引擎实践
△Meetup 现场视频 Kylin 平台化实践 首先,介绍下我们为什么进行平台化改造? 我们部门为公司内其他业务线提供了各种大数据平台,如 Kylin.HBase.Spark.Flink 等等,提供 ...
- 唯品会在 Flink 容器化与平台化上的建设实践
简介:唯品会 Flink 的容器化实践应用,Flink SQL 平台化建设,以及在实时数仓和实验平台上的应用案例. 转自dbaplus社群公众号 作者:王康,唯品会数据平台高级开发工程师 GitHub ...
- 唯品会:在 Flink 容器化与平台化上的建设实践
简介: 唯品会 Flink 的容器化实践应用,Flink SQL 平台化建设,以及在实时数仓和实验平台上的应用案例. 转自dbaplus社群公众号 作者:王康,唯品会数据平台高级开发工程师 自 201 ...
- 《美团数据平台及数仓建设实践》(209页).PDF
7份有关数据化建设的资料都整理好了,包括数据仓库.数据中台.数据仓库等等,有需要的私信:"美团"领取 1.美团数据平台及数仓建设实践.PDF下载 美团技术团队的博客质量非常高,里面 ...
- 转转智能代码平台神笔马良的研发与实践
作者|张所勇 编辑|贾亚宁 本文由 InfoQ 整理自转转平台方向前端负责人张所勇在 GMTC 全球大前端技术大会(深圳站)2021 的分享<转转智能代码平台神笔马良的研发与实践>. 转转 ...
- 美团外卖广告平台化的探索与实践
随着美团外卖业务不断发展,外卖广告引擎团队在多个领域进行了工程上的探索和实践,目前已经取得了一些成果.我们计划通过连载的形式分享给大家,本文是<美团外卖广告工程实践>专题连载的第一篇. 本 ...
- 关于《在Windows与.NET平台上的持续交付实践》的问答录
<在Windows与.NET平台上的持续交付实践>(Continuous Delivery with Windows and .Net)(免费下载)是由Matthew Skelton与Ch ...
- 手机端html5 面试,今日头条 张祖俭 - H5动画在移动平台上的性能优化实践
1.H5动画在移动平台上 的性能优化实践 今日头条 张祖俭 2.大纲 Part 1. H5动画 在移动平台上的性能问题 Part 2. 解决思路-从浏览器渲染入手 Part 3. 在H5Animato ...
- 蚂蚁区块链平台BaaS技术解析与实践
摘要: 以"数字金融新原力(The New Force of Digital Finance)"为主题,蚂蚁金服ATEC城市峰会于2019年1月4日在上海如期举办.在ATEC区块链 ...
最新文章
- 工作报告总是写不好?表达不准确?试试这个写作方法
- B1015/A1062 . 德才论 (25)
- Atom飞行手册翻译: 4.2 深入键表(keymap)
- 如何卸载mysql5.6.28_如何完全删除MySQL以进行全新安装
- python转换函数使用_Python基础学习之时间转换函数用法详解
- LINUX下三个内核文件详解(vmlinuz/initrd.img/System.map)
- 个人开发者上架Android应用市场
- miscrosoft visio 2003记
- 90后美女学霸传奇人生:出身清华姚班,成斯坦福AI实验室负责人高徒
- EMQ X开源版使用
- 笔记本win10玩红警黑屏_你的红警还黑屏吗?
- 【NLP基础理论】10 上下文表示(Contextual Representation)
- el-dialog 圆角 白边问题
- 让电脑自动开机、关机以及取消开机密码
- Wise Disk Cleaner 免费的磁盘清理和磁盘碎片整理工具
- 管理IT外包的七大秘诀
- python爬虫英文单词_利用PYTHON 爬虫爬出自己的英语单词库
- Ext.js 自定义桌面注意
- Linux:查看主机显卡
- 传奇GOM引擎单机架设图文教程
热门文章
- php7取系统信息,操作系统-如何获取运行PHP的操作系统?
- java jdbc datetime_Java JDBC 操作二进制数据、日期时间
- mysql数据库木马查杀_Linux系统木马后门查杀方法详解
- oracle主目录自动检测,ORACLE ADDM数据库自动诊断测试
- 长连接测试_如何选择好一根测试电缆组件?
- 20秋PHP作业3,北语20秋《PHP》作业3【标准答案】
- cat卡特鞋有实体店吗_保养课堂 | 小小密封件,竟然是CAT油缸和连杆耐用的秘密...
- FPGA的设计艺术(4)STA实战之不同时序路径的建立保持时间计算
- FPGA之道(65)代码中的约束信息(二)乘法器的相关约束
- 一次综合的、深入浅出的压感的回顾与总结