spark(1.1) mllib 源代码分析
在spark mllib 1.1加入版本stat包,其中包括一些统计数据有关的功能。本文分析中卡方检验和实施的主要原则:
一个、根本
在stat包实现Pierxunka方检验,它包括以下类别
(1)适配度检验(Goodness of Fit test):验证一组观察值的次数分配是否异于理论上的分配。
(2)独立性检验(independence test) :验证从两个变量抽出的配对观察值组是否互相独立(比如:每次都从A国和B国各抽一个人,看他们的反应是否与国籍无关)
计算公式:
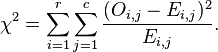
当中O表示观測值,E表示期望值
具体原理能够參考:http://zh.wikipedia.org/wiki/%E7%9A%AE%E7%88%BE%E6%A3%AE%E5%8D%A1%E6%96%B9%E6%AA%A2%E5%AE%9A
二、java api调用example
https://github.com/tovin-xu/mllib_example/blob/master/src/main/java/com/mllib/example/stat/ChiSquaredSuite.java
三、源代码分析
1、外部api
通过Statistics类提供了4个外部接口
// Goodness of Fit test
def chiSqTest(observed: Vector, expected: Vector): ChiSqTestResult = {ChiSqTest.chiSquared(observed, expected)}
//Goodness of Fit test
def chiSqTest(observed: Vector): ChiSqTestResult = ChiSqTest.chiSquared(observed)//independence test
def chiSqTest(observed: Matrix): ChiSqTestResult = ChiSqTest.chiSquaredMatrix(observed)
//independence test
def chiSqTest(data: RDD[LabeledPoint]): Array[ChiSqTestResult] = {ChiSqTest.chiSquaredFeatures(data)
}
2、Goodness of Fit test实现
这个比較简单。关键是依据(observed-expected)2/expected计算卡方值
/** Pearon's goodness of fit test on the input observed and expected counts/relative frequencies.* Uniform distribution is assumed when `expected` is not passed in.*/def chiSquared(observed: Vector,expected: Vector = Vectors.dense(Array[Double]()),methodName: String = PEARSON.name): ChiSqTestResult = {// Validate input argumentsval method = methodFromString(methodName)if (expected.size != 0 && observed.size != expected.size) {throw new IllegalArgumentException("observed and expected must be of the same size.")}val size = observed.sizeif (size > 1000) {logWarning("Chi-squared approximation may not be accurate due to low expected frequencies "+ s" as a result of a large number of categories: $size.")}val obsArr = observed.toArray// 假设expected值没有设置,默认取1.0 / sizeval expArr = if (expected.size == 0) Array.tabulate(size)(_ => 1.0 / size) else expected.toArray/ 假设expected、observed值都必需要大于1if (!obsArr.forall(_ >= 0.0)) {throw new IllegalArgumentException("Negative entries disallowed in the observed vector.")}if (expected.size != 0 && ! expArr.forall(_ >= 0.0)) {throw new IllegalArgumentException("Negative entries disallowed in the expected vector.")}// Determine the scaling factor for expectedval obsSum = obsArr.sumval expSum = if (expected.size == 0.0) 1.0 else expArr.sumval scale = if (math.abs(obsSum - expSum) < 1e-7) 1.0 else obsSum / expSum// compute chi-squared statisticval statistic = obsArr.zip(expArr).foldLeft(0.0) { case (stat, (obs, exp)) =>if (exp == 0.0) {if (obs == 0.0) {throw new IllegalArgumentException("Chi-squared statistic undefined for input vectors due"+ " to 0.0 values in both observed and expected.")} else {return new ChiSqTestResult(0.0, size - 1, Double.PositiveInfinity, PEARSON.name,NullHypothesis.goodnessOfFit.toString)}}// 计算(observed-expected)2/expectedif (scale == 1.0) {stat + method.chiSqFunc(obs, exp)} else {stat + method.chiSqFunc(obs, exp * scale)}}val df = size - 1val pValue = chiSquareComplemented(df, statistic)new ChiSqTestResult(pValue, df, statistic, PEARSON.name, NullHypothesis.goodnessOfFit.toString)}
3、independence test实现
先通过以下的公式计算expected值,矩阵共同拥有 r 行 c 列
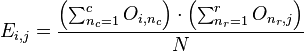
然后依据(observed-expected)2/expected计算卡方值
/** Pearon's independence test on the input contingency matrix.* TODO: optimize for SparseMatrix when it becomes supported.*/def chiSquaredMatrix(counts: Matrix, methodName:String = PEARSON.name): ChiSqTestResult = {val method = methodFromString(methodName)val numRows = counts.numRowsval numCols = counts.numCols// get row and column sumsval colSums = new Array[Double](numCols)val rowSums = new Array[Double](numRows)val colMajorArr = counts.toArrayvar i = 0while (i < colMajorArr.size) {val elem = colMajorArr(i)if (elem < 0.0) {throw new IllegalArgumentException("Contingency table cannot contain negative entries.")}colSums(i / numRows) += elemrowSums(i % numRows) += elemi += 1}val total = colSums.sum// second pass to collect statisticvar statistic = 0.0var j = 0while (j < colMajorArr.size) {val col = j / numRowsval colSum = colSums(col)if (colSum == 0.0) {throw new IllegalArgumentException("Chi-squared statistic undefined for input matrix due to"+ s"0 sum in column [$col].")}val row = j % numRowsval rowSum = rowSums(row)if (rowSum == 0.0) {throw new IllegalArgumentException("Chi-squared statistic undefined for input matrix due to"+ s"0 sum in row [$row].")}val expected = colSum * rowSum / totalstatistic += method.chiSqFunc(colMajorArr(j), expected)j += 1}val df = (numCols - 1) * (numRows - 1)val pValue = chiSquareComplemented(df, statistic)new ChiSqTestResult(pValue, df, statistic, methodName, NullHypothesis.independence.toString)}
版权声明:本文博客原创文章,博客,未经同意,不得转载。
转载于:https://www.cnblogs.com/zfyouxi/p/4731120.html
spark(1.1) mllib 源代码分析相关推荐
- Spark SQL 源代码分析系列
从决定写Spark SQL文章的源代码分析,到现在一个月的时间,一个又一个几乎相同的结束很快,在这里也做了一个综合指数,方便阅读,下面是读取顺序 :) 第一章 Spark SQL源代码分析之核心流程 ...
- Spark SQL Catalyst源代码分析之TreeNode Library
/** Spark SQL源代码分析系列文章*/ 前几篇文章介绍了Spark SQL的Catalyst的核心执行流程.SqlParser,和Analyzer,本来打算直接写Optimizer的,可是发 ...
- Spark SQL Catalyst源代码分析Optimizer
/** Spark SQL源代码分析系列*/ 前几篇文章介绍了Spark SQL的Catalyst的核心运行流程.SqlParser,和Analyzer 以及核心类库TreeNode,本文将具体解说S ...
- Spark SQL之External DataSource外部数据源(二)源代码分析
上周Spark1.2刚公布,周末在家没事,把这个特性给了解一下,顺便分析下源代码,看一看这个特性是怎样设计及实现的. /** Spark SQL源代码分析系列文章*/ (Ps: External Da ...
- 【Spark】实验6 Spark机器学习库MLlib编程实践
Spark机器学习库MLlib编程实践 一.实验目的 通过实验掌握基本的MLLib编程方法: 掌握用MLLib解决一些常见的数据分析问题,包括数据导入.成分分析和分类和预测等. 二.实验平台 新工科智 ...
- Spark中组件Mllib的学习41之保序回归(Isotonic regression)
更多代码请见:https://github.com/xubo245/SparkLearning Spark中组件Mllib的学习之分类篇 1解释 问题描述:给定一个无序数字序列,要求不改变每个元素的位 ...
- Android系统默认Home应用程序(Launcher)的启动过程源代码分析
在前面一篇文章中,我们分析了Android系统在启动时安装应用程序的过程,这些应用程序安装好之后,还需要有一个Home应用程序来负责把它们在桌面上展示出来,在Android系统中,这个默认的Home应 ...
- 《LINUX3.0内核源代码分析》第一章:内存寻址
https://blog.csdn.net/ekenlinbing/article/details/7613334 摘要:本章主要介绍了LINUX3.0内存寻址方面的内容,重点对follow_page ...
- Apache 流框架 Flink,Spark Streaming,Storm对比分析(一)
https://bigdata.163.com/product/article/5 Apache 流框架 Flink,Spark Streaming,Storm对比分析(一) 转载于:https:// ...
最新文章
- make[1]: g++: Command not found
- 【一步教学,一步到位】mysql高可用架构
- Android初步学习BroadCast与Service实现简单的音乐播放器
- Struts文件上传包含修改文件上传参数,多文件上传
- KoalaUI的DateTimePicker的若干问题解答
- C# ---扩展方法
- Oralce中备份,还原数据库
- How to resolve error message CRM_PRODUCT_SALES-E016 during product download
- 蓝桥杯 ADV-146算法提高 计算器
- MATLAB语言初步学习(四)
- 【一天一个C++小知识】009.C++面向对象
- Un*、Id分别突变情况下单闭环直流调速系统仿真
- Maven 详解及常用命令
- 城市应急指挥系统详情分析及建设方案概述
- java毕业设计彩妆销售网站Mybatis+系统+数据库+调试部署
- 【综合】系统架构设计师考试经历分享
- java微信服务通知
- 12星座都是什么性格?(python爬虫+jieba分词+词云)
- Android穿山甲SDK接入,已封装直接使用
- RDIFramework.NET 框架之组织机构权限设置