SQL Server 2014聚集列存储索引
转发请注明引用和原文博客(http://www.cnblogs.com/wenBlog)
简介
之前已经写过两篇介绍列存储索引的文章,但是只有非聚集列存储索引,今天再来简单介绍一下聚集的列存储索引,也就是可更新列存储索引。在SQL Server 2012中首次引入了基于列存储数据格式的存储方式。叫做“列存储索引”。前一篇我已经比较了行存储索引与非聚集的列存储索引(http://www.cnblogs.com/wenBlog/p/5682024.html)。其中对于在小表的指定值或者小范围的查询来讲,尤其针对事务性的负载行存储是很合适的。但是对于分析性负载像数据仓库和BI,在查询中将会对大量数据进行全扫描,例如事实表,这时候列存储索引就是更好地选择。
列存储索引结构
在列存储索引中,数据按照独立列组织到一起形成索引结构。每列都数据都位于被高度压缩的数据集中,叫做数据段。这个数据段只包含该列的值,对于大型表它分到多个数据段中,每个数据段中只含有100万行数据,这就叫做行组、数据段由一个或者多个数据页组成。数据将在内存和硬盘上以数据段的形式传输。
这种索引提高了数据仓库的查询效率。这种通过压缩获得数据格式要比B-Tree结构的压缩率高7倍多。同时由于列存储索引使用了批处理模式执行,数据处理也是批处理的,较少了CPU的使用。列存储索引强化了检索数据的速度,与行存储不同的是不用查询所有列。因为这个原因,更少数据被读取到内存中,再到处理器缓存处理。相关的这些因素都会减少硬盘IO,提高整体查询的性能。
在2014中列存储索引有以下限制:
最多支持1024列在你的索引中;
列存储索引不能被定义为唯一性索引;
不能创建视图;
不能包含稀疏列;
不能使用ALTER INDEX来修改索引,只能drop然后重新创建;
不能使用INCLUDE关键字。
不能排序列;
不能使用FILESTREAM属性。
当然还有一些数据类型不能包含在列存储索引中(binary , varbinary , ntext , text, , image, varchar(max) , nvarchar(max), uniqueidentifier, rowversion , sql_variant,精度大于18 的decimal,CLR 和xml等)
另一方面,对于索引列900字节的限制也不适用与列存储索引。
在SQL Server2012 中,只能创建非聚集列存储索引,并且不能更新。为了更新你必须删除索引,然后进行插入、更新或者删除的操作后在重建索引。
在2014中列存储索引得到了不小的提升,比如消除了只读限制。增加了聚集列存储索引,列存储索引作为了表的存储方式,存储表的数据。
比较聚集和非聚集列存储索引
区别 |
聚集列存储索引 |
非聚集列存储索引 |
| 索引列 | 需要指定列上创建 | 所有列都包含在内 |
| 存储 | 额外增加百分之10的空间作为索引 | 压缩十倍的数据量,如果表之前是页压缩,则可以压缩5倍左右 |
| 更新 | 是 | 否 |
| 排序 | 在创建之前进行排序 | 否 |
列存储索引的结构图:
![]()
如图增量存储部分我们叫做deltastore,用于存储不够最小行组大小的数据。流程就是将行数据提取成列数据,然后进行压缩存储,多余的部分放到deltastore中。
聚集索引插入、删除和更新实现逻辑:
插入新行的时候,值被存储在deltastore中,直到达到最小rowgroup(行组)大小时,然后压缩并移动到列存储数据段中。
删除数据时,行将被删除从deltastore存储中,但是在列存储索引数据段中只是被标记为删除,除非重建后才会被真的删除。
更新的时候,在deltastore存储中行数据被删除,然后在列存储数据段中被标记为删除,新的列别插入到deltastore中。
最后当重建索引的时。SQLServer将会删除所有标记为删除的数据段,数据存储在deltastore中的将与数据段中的数据合并,然后进行压缩。
下面我们来展示下如何从列存储索引中获得性能:
我们首先创建一个事实表在数据库中脚本如下:
1 USE SQLShackDemo 2 3 GO 4 --创建表 5 CREATE TABLE [dbo].[FactFinance]( 6 7 [FinanceKey] [int] NOT NULL, 8 9 [DateKey] [int] NOT NULL, 10 11 [OrganizationKey] [int] NOT NULL, 12 13 [DepartmentGroupKey] [int] NOT NULL, 14 15 [ScenarioKey] [int] NOT NULL, 16 17 [AccountKey] [int] NOT NULL, 18 19 [Amount] [float] NOT NULL, 20 21 [Date] [datetime] NULL 22 23 ) ON [PRIMARY] 24 25 GO 26 27 --创建聚集索引: 28 29 CREATE CLUSTERED INDEX [IX_FactFinance_FinanceKey_DateKey] ON [dbo].[FactFinance] ( [FinanceKey],[DateKey]) 30 GO 31 32 33 --查询表: 34 35 SELECT [FinanceKey] 36 37 ,[DateKey] 38 39 ,[OrganizationKey] 40 41 ,[DepartmentGroupKey] 42 43 FROM [FactFinance]
![]()
让我们检查下聚集索引扫描操作符,Estimated I/O Cost(估计IO花销) 的值为0.183866,Estimated CPU Cost(估计CPU花销)为0.0435069,为了比较列索引的值,我们先记住:

现在我们创建列存储索引在非聚集索引:
CREATE NONCLUSTERED COLUMNSTORE INDEX [IX_FactFinance_FinanceKey_DateKey_OrganizationKey_DepartmentGroupKey]ON [FactFinance]([FinanceKey],[DateKey],[OrganizationKey],[DepartmentGroupKey])GO SELECT [FinanceKey] ,[DateKey] ,[OrganizationKey] ,[DepartmentGroupKey] FROM [FactFinance]

这个列存储索引扫描操作符如下所示:
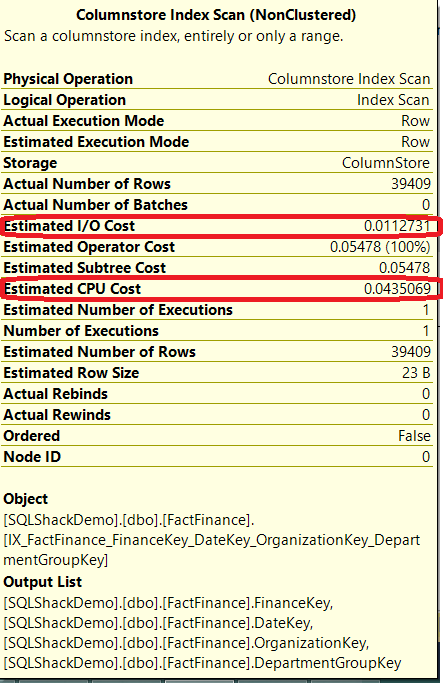
如上所示,Estimated I/O Cost从0.183866下降到0.0112731,这是因为SQL引擎只检索需要的列,节省了IO和内存资源。Estimated CPU的时间没有变化。
IO强化与之前相比是明显的,我们也可以比较两个查询,启用I/O statistics,检查IO的hits 表现如下:
SET STATISTICS IO ON GOSELECT [FinanceKey] ,[DateKey] ,[OrganizationKey] ,[DepartmentGroupKey] FROM [FactFinance] with (index (IX_FactFinance_FinanceKey_DateKey)) GO SELECT [FinanceKey] ,[DateKey] ,[OrganizationKey] ,[DepartmentGroupKey] FROM [FactFinance] with (index(IX_FactFinance_FinanceKey_DateKey_OrganizationKey_DepartmentGroupKey))
正如所示,比较执行计划,使用列存储索引的要比行索引的好四倍,那么期望一下处理大数据时的10倍性能:
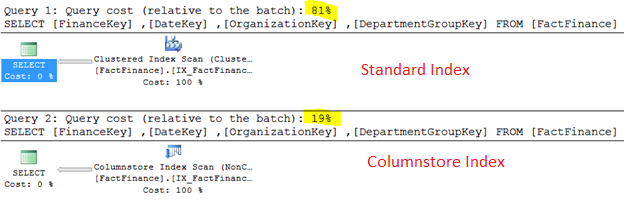
当比较逻辑读时你也能发现相似的结果。明显这个逻辑读也是四倍+关系。

那么我们可以根据下图概括一下传统的行索引与列存储所以的一般性区别:
![]()
列存储索引的创建
也能够使用SSMS创建索引: Indexes -> New Index ->Non-Clustered Columnstore Index 如下:
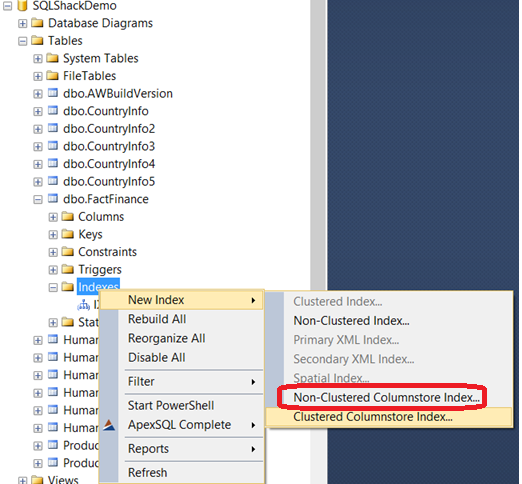
与非聚集索引创建类似,选择列,然后这些列没有排序也不能使用Include选项:
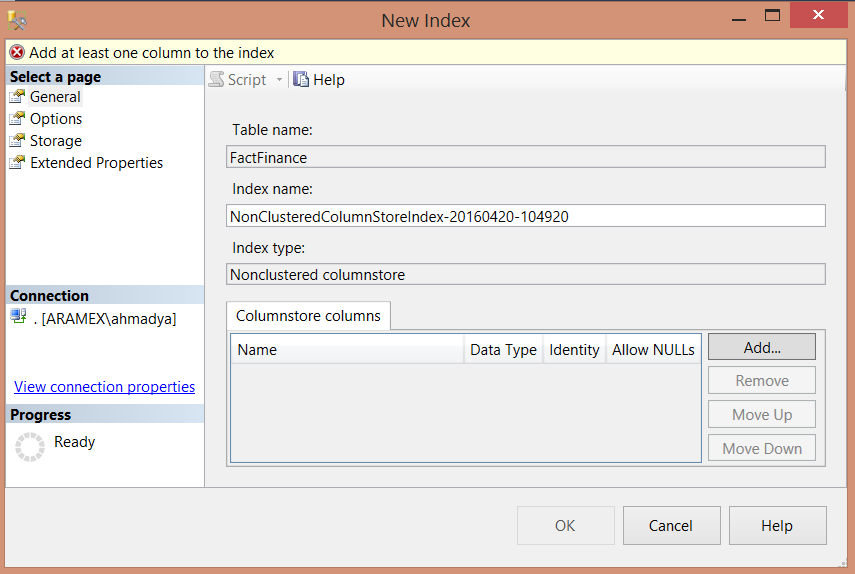
下图中我在SQL Server2014 企业版中,创建聚集索引:
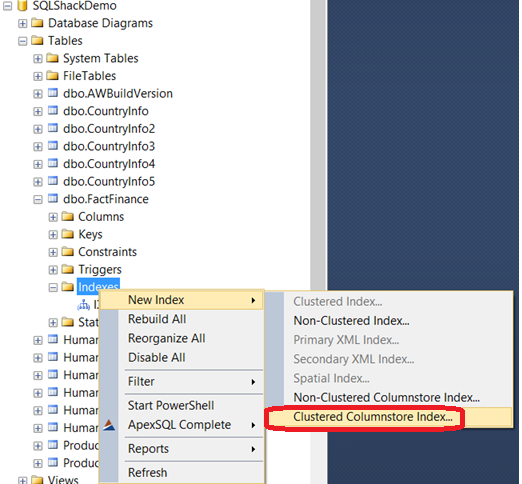
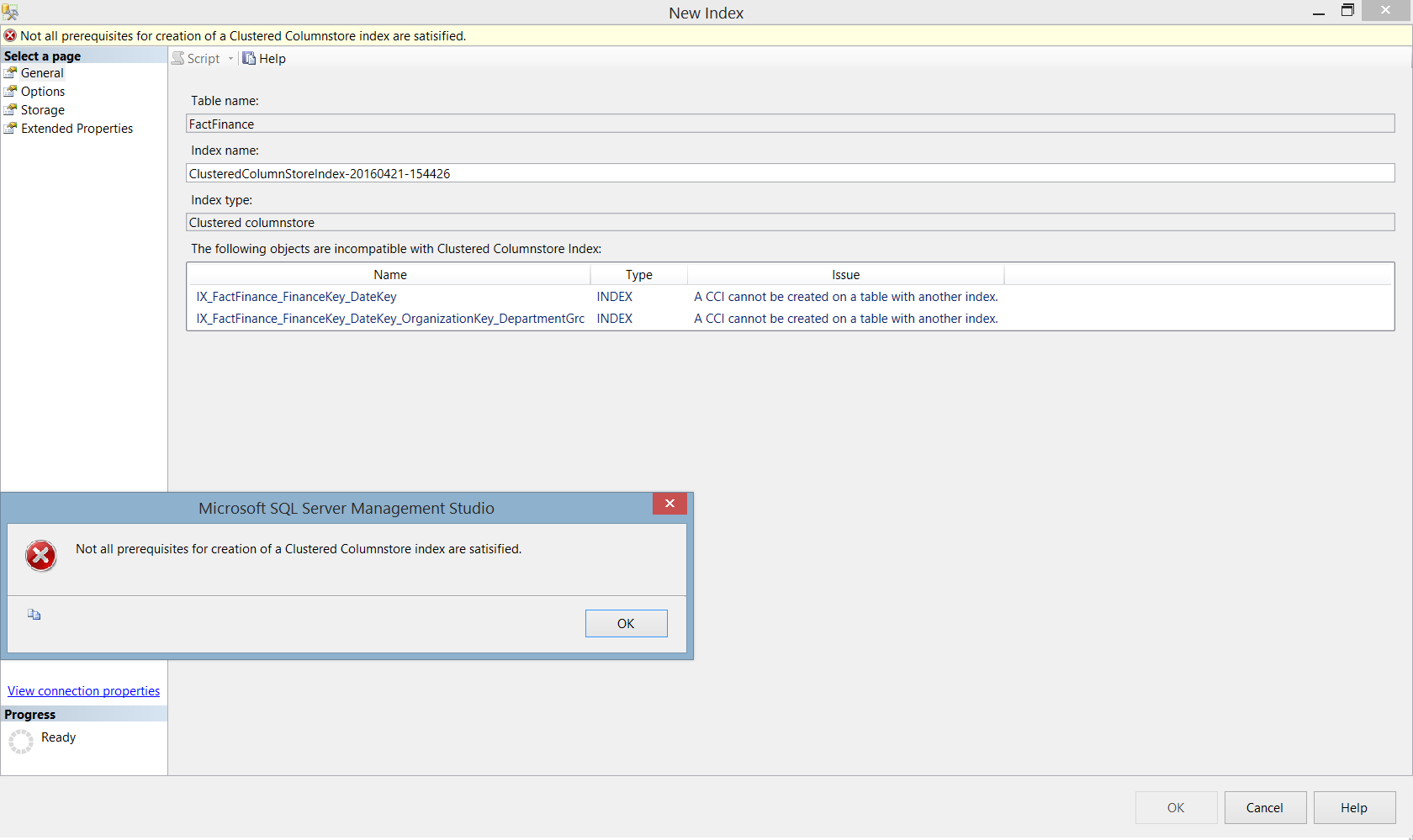
需要注意的是如果在表上已经有其他索引,尝试创建聚集列存储索引就会出现错误,正如我们之前说的,同一个表中不能或者其他索引:
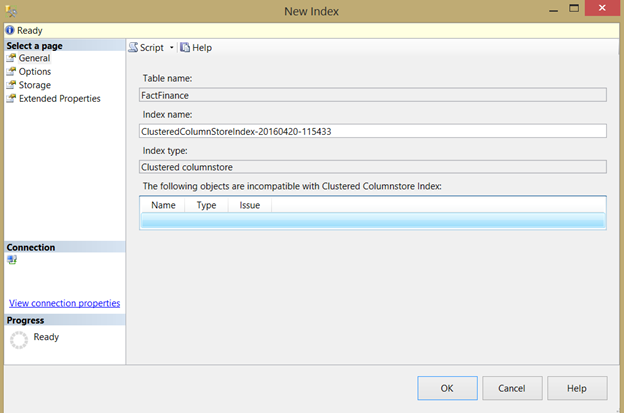
不用选择列,所有数据都包含在内了:
几个好的应用场景:
如果你有大型的事实表并且存在查询问题的,或者SSAS存在其他性能问题的,列存储是一个不错的方案。一下两种情况是经过测试的比较好的应用场景:
- 对于高频率响应的报表/仪表板,尤其分析当性能表现不佳的时候,会有很不错的性能。
- 对于ETL的过程来讲,源数据的列存储索引将会极大提高性能,如果数据足够大甚至可以考虑临时创建列存储索引。然后执行ETL。
总结:
列存储索引是一个使用SQL Server性能优化的方案,通过减少IO消耗,尤其对数据仓库和BI查询都是由明显性能提升。它通过排序数据作为列存储,然后压缩,并使用批处理来处理数据。当然,必须要确保使用列存储索引的使用带来了好处,而不会引起其他性能问题才能使用。比如需要注意使用的硬件环境和数据,如果没有join、过滤、或者聚合导出巨大的数据量没有足够的内存则将被暂时放入硬盘进行switch off,从而引起查询性能下降。尽量在使用之前在测试环境中测试是否适合使用,同时还要关注其他环节是否受影响。
补充,在2016中增加的几个我认为不错新的feature:
基于聚集列存储索引的 B 树索引;
基于内存优化表的列存储索引;
CREATE TABLE 和 ALTER TABLE 中的列存储索引的压缩延迟选项;
单线程查询的批处理执行。
转载于:https://www.cnblogs.com/wenBlog/p/6228346.html
SQL Server 2014聚集列存储索引相关推荐
- SQL Server中的列存储索引
先决条件 (Prerequisite ) 通过理论和实践措施可以更好地解释与SQL Server 2012列存储索引有关的讨论. 因此,对于实际测量部分–我将使用AdventureWorksDW201 ...
- Azure Synapse Analytics (Azure SQL DW)性能优化指南(1)——使用有序聚集列存储索引优化性能
目录 (一)前言 (二)有序与无序聚集列存储索引 (三)查询性能 (四)数据加载性能 (五)减少段重叠 (六)在大型表中创建有序 CCI (六)实战案例 A. 检查有序列和序号: B. 若要更改列序号 ...
- SQL Server 2017:列存储就地更新
In this post, I continue the exploration of SQL Server 2017 and we will look at the nonclustered col ...
- SQL Server 2016 列存储索引功能增强
列存储索引(columnstore index)在SQL Server 2012中已经引入,其带来性能提升的同时也有很多限制,比如对带有列存储索引的表进行INSERT, UPDATE和DELET ...
- 数据库索引统计信息不一致_列存储索引增强功能–克隆数据库中的索引统计信息更新
数据库索引统计信息不一致 SQL Server was launched in 1993 on WinNT and it completed its 25-year anniversary recen ...
- SQL Server 2016新特性:列存储索引新特性
SQL Server 2016新特性:列存储索引新特性 行存储表可以有一个可更新的列存储索引,之前非聚集的列存储索引是只读的. 非聚集的列存储索引支持筛选条件. 在内存优化表中可以有一个列存储索引,可 ...
- DBA基础系列SQL Server 2014:2. SQL Server用户数据库初始化配置
前言 开始前先黑微软一把:Microsoft秉承一贯的简单易用作风(Next.Next.Next- )这点是它吸引用户的地方,但是这个优点如果用在数据库上将是一场灾难,如我们上一章讲到的SQL Ser ...
- SQL Server 2014里的性能提升
在这篇文章里我想小结下SQL Server 2014引入各种惊艳性能提升!! 缓存池扩展(Buffer Pool Extensions) 缓存池扩展的想法非常简单:把页文件存储在非常快的存储上,例如S ...
- SQL Server 2014新特性:其他
SQL Server 2014新特性:其他 AlwaysOn 增强功能 SQL Server 2014 包含针对 AlwaysOn 故障转移群集实例和 AlwaysOn 可用性组的以下增强功能: &q ...
最新文章
- canvas三角函数模拟水波效果
- 东南大学校内智能车竞赛
- Vivado Hardware Manager的使用
- FutureTask 实现预加载数据 在线看电子书、浏览器浏览网页等
- javascript要点
- 很多女生都这么干!效果就是可以很快换电脑……
- 阿里开发者招聘节 | 2019阿里巴巴技术面试题分享:20位专家28道题
- make、make是什么??
- matlab使用histogram画直方图划分柱宽度不一致问题
- fckeditor for php 下载,FCKeditor(HTML在线编辑器)
- 性能测试实战脚本—服务器端性能测试的通用脚本
- 前端程序员转行做新媒体运营?什么原因
- html文件在线打开word,html打开word程序 html直接打开word文档
- SDH原理--1.SDH概述
- 【已解决】ansys打开没有主界面,只有output窗口怎么回事?
- 区块链开发中使用最流行的编程语言
- 从前装量产数据看“软硬分离”与“市场博弈”
- 大批程序员可能面临被劝退!
- 基于 Impala 的高性能数仓实践之物化视图服务
- esp8266 SDK相关资料
热门文章
- 面试官三连问:你这个数据量多大?分库分表怎么做?用的哪个组件?
- 老板:kill -9的原理都不知道就敢到线上执行,明天不用来了
- Java中BigDecimal工具类(支持空值运算版)
- 基于 Nginx+lua+Memcache 实现灰度发布
- 40万总奖金!院士指导,顶级云服务免费用!2021全球高性能云计算创新大赛来了...
- 登顶CLUE榜单,腾讯云小微与腾讯AI Lab联合团队提出基于知识的中文预训练模型...
- 再见吧,996!程序员开源考公指南获高赞:三人已成功上岸
- EMNLP2020:Hugging Face获最佳demo
- 华人斩获最佳Demo论文,Bengio获时间检验奖,最佳论文突破NLP传统测试方法 | ACL 2020...
- 哈佛终身教授:年轻人如何做科研?