分类算法:决策树(C4.5)
C4.5是机器学习算法中的另一个分类决策树算法,它是基于ID3算法进行改进后的一种重要算法,相比于ID3算法,改进有如下几个要点:
- 用信息增益率来选择属性。ID3选择属性用的是子树的信息增益,这里可以用很多方法来定义信息,ID3使用的是熵(entropy, 熵是一种不纯度度量准则),也就是熵的变化值,而C4.5用的是信息增益率。
- 在决策树构造过程中进行剪枝,因为某些具有很少元素的结点可能会使构造的决策树过适应(Overfitting),如果不考虑这些结点可能会更好。
- 对非离散数据也能处理。
- 能够对不完整数据进行处理。
首先,说明一下如何计算信息增益率。
熟悉了ID3算法后,已经知道如何计算信息增益,计算公式如下所示(来自Wikipedia):
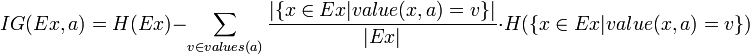
或者,用另一个更加直观容易理解的公式计算:
- 按照类标签对训练数据集D的属性集A进行划分,得到信息熵:
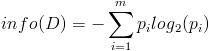
- 按照属性集A中每个属性进行划分,得到一组信息熵:
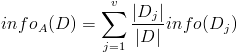
- 计算信息增益
然后计算信息增益,即前者对后者做差,得到属性集合A一组信息增益:

这样,信息增益就计算出来了。
- 计算信息增益率
下面看,计算信息增益率的公式,如下所示(来自Wikipedia):
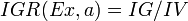
其中,IG表示信息增益,按照前面我们描述的过程来计算。而IV是我们现在需要计算的,它是一个用来考虑分裂信息的度量,分裂信息用来衡量属性分 裂数据的广度和均匀程序,计算公式如下所示(来自Wikipedia):
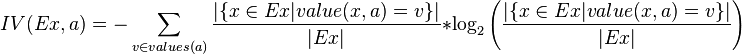 简化一下,看下面这个公式更加直观:
简化一下,看下面这个公式更加直观: 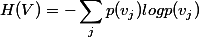
其中,V表示属性集合A中的一个属性的全部取值。
我们以一个很典型被引用过多次的训练数据集D为例,来说明C4.5算法如何计算信息增益并选择决策结点。
上面的训练集有4个属性,即属性集合A={OUTLOOK, TEMPERATURE, HUMIDITY, WINDY};而类标签有2个,即类标签集合C={Yes, No},分别表示适合户外运动和不适合户外运动,其实是一个二分类问题。
我们已经计算过信息增益,这里直接列出来,如下所示:
数据集D包含14个训练样本,其中属于类别“Yes”的有9个,属于类别“No”的有5个,则计算其信息熵:
1
|
Info(D) = -9/14 * log2(9/14) - 5/14 * log2(5/14) = 0.940
|
下面对属性集中每个属性分别计算信息熵,如下所示:
1
|
Info(OUTLOOK) = 5/14 * [- 2/5 * log2(2/5) – 3/5 * log2(3/5)] + 4/14 * [ - 4/4 * log2(4/4) - 0/4 * log2(0/4)] + 5/14 * [ - 3/5 * log2(3/5) – 2/5 * log2(2/5)] = 0.694
|
2
|
Info(TEMPERATURE) = 4/14 * [- 2/4 * log2(2/4) – 2/4 * log2(2/4)] + 6/14 * [ - 4/6 * log2(4/6) - 2/6 * log2(2/6)] + 4/14 * [ - 3/4 * log2(3/4) – 1/4 * log2(1/4)] = 0.911
|
3
|
Info(HUMIDITY) = 7/14 * [- 3/7 * log2(3/7) – 4/7 * log2(4/7)] + 7/14 * [ - 6/7 * log2(6/7) - 1/7 * log2(1/7)] = 0.789
|
4
|
Info(WINDY) = 6/14 * [- 3/6 * log2(3/6) – 3/6 * log2(3/6)] + 8/14 * [ - 6/8 * log2(6/8) - 2/8 * log2(2/8)] = 0.892
|
根据上面的数据,我们可以计算选择第一个根结点所依赖的信息增益值,计算如下所示:
1
|
Gain(OUTLOOK) = Info(D) - Info(OUTLOOK) = 0.940 - 0.694 = 0.246
|
2
|
Gain(TEMPERATURE) = Info(D) - Info(TEMPERATURE) = 0.940 - 0.911 = 0.029
|
3
|
Gain(HUMIDITY) = Info(D) - Info(HUMIDITY) = 0.940 - 0.789 = 0.151
|
4
|
Gain(WINDY) = Info(D) - Info(WINDY) = 0.940 - 0.892 = 0.048
|
接下来,我们计算分裂信息度量H(V):
- OUTLOOK属性
属性OUTLOOK有3个取值,其中Sunny有5个样本、Rainy有5个样本、Overcast有4个样本,则
1
|
H(OUTLOOK) = - 5/14 * log2(5/14) - 5/14 * log2(5/14) - 4/14 * log2(4/14) = 1.577406282852345
|
- TEMPERATURE属性
属性TEMPERATURE有3个取值,其中Hot有4个样本、Mild有6个样本、Cool有4个样本,则
1
|
H(TEMPERATURE) = - 4/14 * log2(4/14) - 6/14 * log2(6/14) - 4/14 * log2(4/14) = 1.5566567074628228
|
- HUMIDITY属性
属性HUMIDITY有2个取值,其中Normal有7个样本、High有7个样本,则
1
|
H(HUMIDITY) = - 7/14 * log2(7/14) - 7/14 * log2(7/14) = 1.0
|
- WINDY属性
属性WINDY有2个取值,其中True有6个样本、False有8个样本,则
1
|
H(WINDY) = - 6/14 * log2(6/14) - 8/14 * log2(8/14) = 0.9852281360342516
|
根据上面计算结果,我们可以计算信息增益率,如下所示:
1
|
IGR(OUTLOOK) = Gain(OUTLOOK) / H(OUTLOOK) = 0.246/1.577406282852345 = 0.15595221261270145
|
2
|
IGR(TEMPERATURE) = Gain(TEMPERATURE) / H(TEMPERATURE) = 0.029 / 1.5566567074628228 = 0.018629669509642094
|
3
|
IGR(HUMIDITY) = Gain(HUMIDITY) / H(HUMIDITY) = 0.151/1.0 = 0.151
|
4
|
IGR(WINDY) = Gain(WINDY) / H(WINDY) = 0.048/0.9852281360342516 = 0.048719680492692784
|
根据计算得到的信息增益率进行选择属性集中的属性作为决策树结点,对该结点进行分裂。
C4.5算法的优点是:产生的分类规则易于理解,准确率较高。
C4.5算法的缺点是:在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。
分类算法:决策树(C4.5)相关推荐
- sklearn分类算法-决策树、随机森林
sklearn分类算法-决策树.随机森林 一.决策树 1.概念 决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-then结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法 比如: ...
- 【机器学习】sclearn分类算法-决策树、随机森林
分类算法-决策树.随机森林 1.决策树 1.1 认识决策树 1.2 信息论基础-银行贷款分析 1.3 决策树的生成 1.4 决策树的划分依据之一-信息增益 1.5 sklearn决策树API 1.6 ...
- 分类算法-决策树、随机森林
分类算法-决策树.随机森林 决策树 1. 认识决策树 决策树模型呈树形结构.在分类问题中,表示基于特征对实例进行分类的过程,它可以认为是if-then规则的集合.在决策树的结构中,每一个实例都被一条路 ...
- 数据挖掘十大算法之分类算法(决策树模型)
文章目录 1. 决策树的概念 2. 构建决策树 3. 决策树中的信息论原理 3.1 信息量 3.2 熵 3.3 分类集合信息量 3.4 信息增益 接上篇文章分类介绍及评价指标我们讨论了分类算法中,分类 ...
- 分类算法——决策树(1)
决策树归纳是从类标记的训练元组学习决策树.决策树是一种类似于流程图的结构,其中,每个内部节点(非树叶节点)表示在一个属性上的测试,每个分枝代表一个测试输出,而每个树叶节点(或终节点)存放一个类标号.树 ...
- Chapter 5 分类算法——决策树与随机森林
决策树 认识决策树 决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-then结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法. 信息熵:单位为比特. 信息和消除不确定性是相联系 ...
- 建模基础教学:分类算法 --- 决策树
决策树理解案例 我们在买苹果的时候可以通过苹果的颜色.硬度来判断它的好坏,再决定是否买这个苹果.那么我们也许可以基于之前买苹果的经验做出这样一个分析: 某人不太会挑苹果,所以纯粹是随机写的几条数据,假 ...
- ML算法基础——分类算法-决策树、随机森林
文章目录 1.决策树 1.1 认识决策树 1.2 信息论基础-银行贷款分析 1.2.1 信息论基础-信息熵 1.2.2 决策树的划分依据之一-信息增益 1.3 泰坦尼克号乘客生存分类 1.3.1 sk ...
- 机器学习-分类算法-决策树,随机森林10
决策树: 决策树的思想来源非常朴素,程序设计中的条件分支机构就是if-then结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法. 信息和消除不确定性是相联系的 信息增益:当得知一个特征后, ...
- 决策树分类python代码_分类算法-决策树 Decision Tree
决策树(Decision Tree)是一个非参数的监督式学习方法,决策树又称为判定树,是运用于分类的一种树结构,其中的每个内部节点代表对某一属性的一次测试,每条边代表一个测试结果,叶节点代表某个类或类 ...
最新文章
- 记录一次MySQL两千万数据的大表优化解决过程,提供三种解决方案
- 蓝桥杯java第八届第九题--分巧克力
- HTML提交弹出提交中,javascript – 从弹出窗口在父窗口中提交表单?
- 局域网聊天室 -ChatServer
- Codeforces - tag::data structures 大合集 [占坑 25 / 0x3f3f3f3f]
- 数字化时代在线教育行业营销解决方案
- windows下mongoDB的环境配置
- Office文档在线预览接口服务器
- 阿衰小冲用计算机,《阿衰漫画》小衰学电脑,差点扔进垃圾桶,ESC怎么没有作用?...
- 人工智能大数据,公开的海量数据集下载
- 2017秋季武汉工程大学全日制自考本科招生简章
- 数据同步工具ETL-kettle使用
- C语言 简易计算器 //支持求阶乘
- python opencv手势识别_OpenCV+Python3.5 简易手势识别的实现
- MQTT-Eclipse paho mqtt重连机制
- 电脑PE系统无法进入,完整详细解决方案
- WEB前端打印使用记录
- 解决filebeat 报错 Failed to publish events
- windows10桌面计算机图标删除吗,win10电脑桌面图标删除不了怎么办
- android手机如何获取手机号