客户端读写hdfs数据
2019独角兽企业重金招聘Python工程师标准>>> 
读:
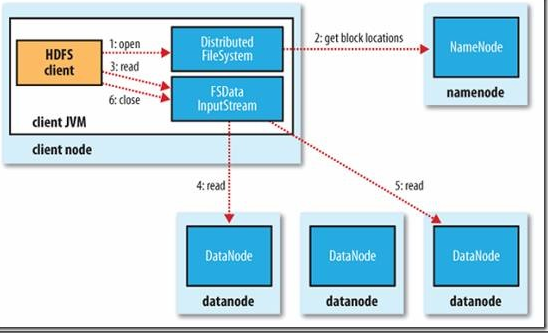
(1)客户端通过调用FIleSystem对象的open()方法来打开希望读取的文件,对于hdfs来说,这个对象是分布式文件系统的一个实例。
(2)DistributedFileSystem通过使用rpc来调用namenode,以确定文件起始块的位置。对于每一个块,namenode返回存有该块副本的datanode的地址。此外,这些datanode根据他们与客户端的距离来排序(机架感应)。如果该客户端本身就是一个datanode(比如,在一个MapReduce任务中),并保存有相应数据块的一个副本时,该节点将从本地datanode中读取数据。
(3)DistributedFileSystem类返回一个FSDataInputStream对象(支持文件定位的输入流)给客户端读取数据。FSDataInput类转而封装DFSInputStream对象,该对象管理着datanode、namenode的I/O。接着,客户端对这个输入流调用read()方法。
(4)存储着文件起始块的datanode地址的DFSInputStream 随即连接距离最近的文件中第一个块所在的datanode。通过对数据流反复调用read()方法,可以将数据从datanode传输到客户端。
(5)到达块的末端时,DFSInputStream 会关闭与该datanode的连接,然后寻找下一个块的最佳datanode。客户端只需要读取连续的流,并且对于客户端都是透明的。客户端从流中读取数据时,块是按照打开DFSInputStream与datanode新建连接的顺序读取的。它根据需要询问namenode来检索下一批所需块的datanode的位置。
(6)一旦客户端读取完成,就对FSDataInputStream调用close()方法,在读取数据的时候,如果DFSInputStream在与datanode通信时遇到错误,它便尝试从这个块的另外一个最邻近的datanode读取数据。它也会记住哪个故障的datanode,以保证以后不会反复读取该节点上后续的块。DFSInputStream也会通过校验和确认从datanode发来的数据是否完整。如果发现一个损坏的块,它就会在DFSInputStream 试图从其他datanode读取一个块的副本,也会将被损坏的块通知给namonode。
这个设计的一个重点是,客户端可以直接连接到datanode检索数据,且namenode告诉客户端每个块中的最佳datanode。由于数据流分散在该集群中所有的datanode,所以这种设计能使HDFS可扩展到大量的并发客户端。同时,namenode仅需要响应快位置的请求(这些信息存储在内存中,因而非常高效),而无需响应数据请求,否则随着客户端数量的增长,namenode很快会成为一个瓶颈。
hadoop写:
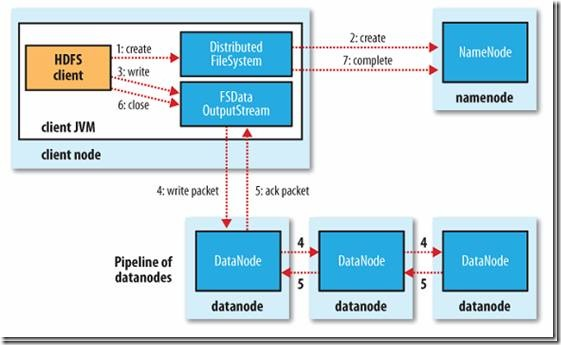
(1)客户端通过对DistributeFileSystem 对象调用create()函数来创建文件。
(2)DistributedFileSystem 对namenode创建一个rpc调用,在文件系统的命名空间中创建一个新文件,但是此时该文件中还没有相应的数据块,namenode执行各个不同的检查以确保这个文件不存在,并且客户端有创建该文件的权限。如果这些检查均通过,namenode就会为创建新文件记录一条记录,否则,文件创建失败并向客户端抛出一个IoException异常。
(3)DistributeFileSystem向客户端返回一个FSDataOutrputStream对象,由此客户端可以开始写入数据。就像读取事件一样,FSDataOutputStream封装一个DFSoutputstream对象,该对象负责处理datanode和namenode之间的通信。在客户端写入数据时,DFSoutputStream将它分成一个个的数据包,并写入内部队列,成为数据队列(data queue)
(4)dataStreamer处理数据队列,它的责任是根据datanode列表来要求namenode分配适合的新块来存储数据备份。这一组datanode构成一个管道(pip管道)---我们假设副本数是3,所以管道中有3个节点。dataStream将数据包流式传输到管道中第一个datanode,该datanode存储数据包之后,并将它发送到管道中第二个datanode中,同样操作,第二个datanode 将数据包存储后给第三个datanode。
(5)DFSOoutputStream也维护着一个内部数据包队列来等待datanode的收到确认回执,称为"确认队列"(ack queue)。当收到管道中所有的datanode确认信息后,该数据包才会从确认队列删除。
如果在数据写入期间,datanode发生故障,则执行以下操作,这对与写入数据的客户端是透明的。首先关闭管道,确认把队列中的任何数据包都添回数据队列的最前端,以确保故障节点下游的datanode不会漏掉任何一个数据包。为存储在另一个正常datanode的当前数据块制定一个新的标识,并将该标识传送给namenode。以便故障datanode在恢复后可以删除存储的部分数据块。从管道中删除故障数据节点并且把余下的数据块写入管道中剩余的两个正常的datanode。namenode注意到块副本量不足时,会在另一个节点上创建一个新的副本。后续的数据块继续正常接受处理。
(6)客户端完成数据的写入后,会对数据流调用close()方法。
(7)该操作将剩余的所有数据包写入datanode管道中,并在联系namenode发送文件写入完成信号之前,等待确认。namenode已经知道文件由哪些块组成(通过DataStreamer询问数据块的分配),所以它在返回成功只需要等待数据块进行最小量的复制。
转载于:https://my.oschina.net/u/4009325/blog/2396167
客户端读写hdfs数据相关推荐
- 客户端读写数据到HDFS的流程
客户端写数据到HDFS中的流程 (1) 客户端发出写数据请求,hadoop fs –put ./localFile.txt /hdfsFile.txt 本地的localFile.txt文件大小是170 ...
- HDFS文件系统基本文件命令、编程读写HDFS
HDFS是一种文件系统,存储着Hadoop应用将要处理的数据,类似于普通的Unix和linux文件系统,不同的是他是实现了google的GFS文件系统的思想,是适用于大规模分布式数据处理相关应用的.可 ...
- hdfs数据节点分发什么协议_分布式文件系统HDFS解析
Hadoop 主要由HDFS和MapReduce 引擎两部分组成.最底部是HDFS,它存储Hadoop 集群中所有存储节点上的文件.HDFS 的上一层是MapReduce 引擎,该引擎由JobTrac ...
- HDFS(数据存储)
HDFS概述 1.HDFS是什么 Hadoop Distributed File System:分步式文件系统 源自于Google的GFS论文,发表于2003年10月,HDFS是GFS克隆版 HDFS ...
- 华为云大数据存储的冗余方式是三副本_大数据入门:HDFS数据副本存放策略
大数据处理当中,数据储存始终是一个重要的环节,从现阶段的市场现状来说,以Hadoop为首的大数据技术框架,仍然占据主流地位,而Hadoop的HDFS,在数据存储方面,仍然得到重用.今天的大数据入门分享 ...
- HDFS数据平衡:节点间平衡与节点内平衡
HDFS数据平衡:节点间平衡与节点内平衡 HDFS容易发生数据不平衡的问题. 这其中包括各个DataNode之间存储的数据量差异,以及一个DataNode内部各磁盘之间存储的数据量差异. HDFS专门 ...
- hdfs 数据迁移_对象存储BOS发布全新工具,加速自建HDFS到云端的访问速度
想让自建Hadoop拥有流畅的云端访问体验?想替老板省点钱?是时候升级你的装备了! 百度智能云对象存储服务BOS新推出BOS HDFS工具,支持HDFS数据在BOS中的海量存储,并能在上层数据运算中使 ...
- 获取并显示服务器数据,客户端获取服务器数据解析
客户端获取服务器数据解析 内容精选 换一换 VR云渲游平台提供了设备的实时监控功能,您可以通过监控大屏,查看指定设备在云上运行时的实时监控数据.当设备处于"运行中"状态时,才可以查 ...
- 【MapReduce】MapReduce读写MySQL数据
MapReduce读写MySQL数据 数据 代码实现 自定义类来接收源数据 自定义类型来存储结果数据 Mapper阶段 Reducer阶段 Driver阶段 上传运行 打包 上传集群运行 使用MapR ...
最新文章
- Delegate成员变量和Event的区别
- 2.7 RMSprop-深度学习第二课《改善深层神经网络》-Stanford吴恩达教授
- 1.0Nvm环境配置
- Ajax基础--创建XMLHttpRequest对象
- 一起谈.NET技术,Microsoft NLayerApp案例理论与实践 - 多层架构与应用系统设计原则...
- 通过build.xml在Eclipse中导入工程
- Linux之ansible 自动化运维工具
- matlab2016 b 安装详细教程正版中文密钥
- 软件工程设计图(总体设计、概要设计、详细设计)
- linux监控网络流量命令,Linux网络流量实时监控ifstat iftop命令详解
- vs2008 在 win7 64位安装问题 office 2003 office 2007兼容问题
- 信号完整性(SI)电源完整性(PI)学习笔记(十七)传输线的串扰(一)
- 多元函数的高阶微分公式 与 Taylor公式
- 哔哩哔哩(B站)暑期实习面经(已OC)
- WAP(wml)开发问答
- QQ(微信)一次性发送多条信息(连续发520遍我爱你)
- 如何避免干井校准操作的常见误区?有效执行温度校准
- javascript+html获取外汇报价并实时更新
- 微博只显示来自android,修改手机发新浪微博显示的来源
- 5月3日云栖精选夜读:乾隆会判阿尔法狗死刑吗 ——浅谈当前人工智能的技术进化...