Alluxio : 开源分布式内存文件系统
Alluxio : 开源分布式内存文件系统
Alluxio is a memory speed virtual distributed storage system.Alluxio是一个开源的基于内存的分布式存储系统,现在成为开源社区中成长最快的大数据开源项目之一。
公司简介:
由项目的创建者李浩源以及来自UC Berkeley, Google, CMU, Palantir, Stanford, Yahoo等不同公司和学校的项目核心开发者组成。
完成750万 dollars 的A轮融资,由Andreessen Horowitz投资(硅谷最著名的VC之一,主要成员为网景公司创始人之一)。
背景介绍:
2012年诞生于UC Berkeley AMPLab,此前这个实验室孵化了Apache Mesos和Apache Spark等著名开源项目。
2013年4月开源,现在由最初的Tachyon改名为Alluxio,基于Apache License 2.0开源标准,最新版本为Version 1.0 (Feb 23rd, 2016)。

在分布式系统的开源项目中,相比于同级别项目,Alluxio的增长非常迅速
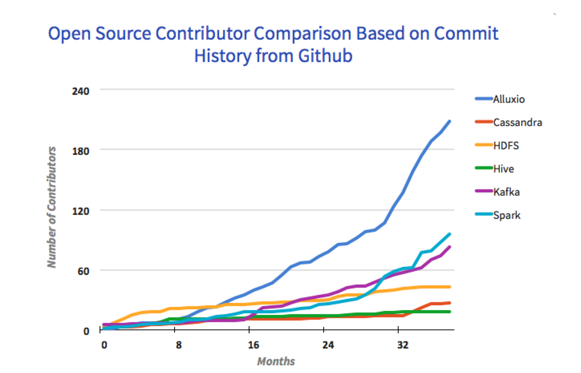
吸引了来自超过50个组织的200+个contributors。

主要特性:
数据存储与计算分离,两部分引擎可以进行独立的扩展。计算引擎(如Hadoop, Spark)可以访问不同数据源(Amazon S3, HDFS)中的数据。
问题:与Redis,Memcached等分布式in-memory key-value缓存的的区别:
答:(1) Alluxio可以同时管理多个底层文件系统,将不同的文件系统统一在同一个名称空间下,让上层客户端可以自由访问统一名称空间内的不同路径,不同存储系统的数据。(2)Alluxio提供文件接口,并存储且维护文件的metadata(比如记录文件分成哪几个block, 每一个block在哪台server上)。并提供fault tolerance的metadata服务。而Redis/Memcached为Nosql的key-value分布式缓存,并不提供文件接口。
内存与硬盘比较
硬盘内存增长率曲线:
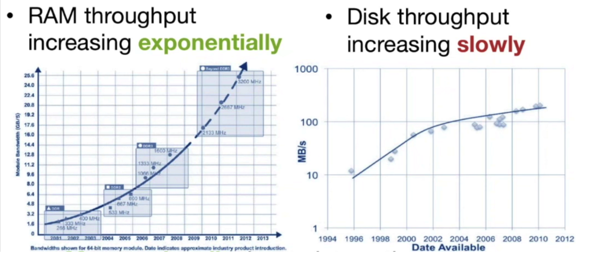
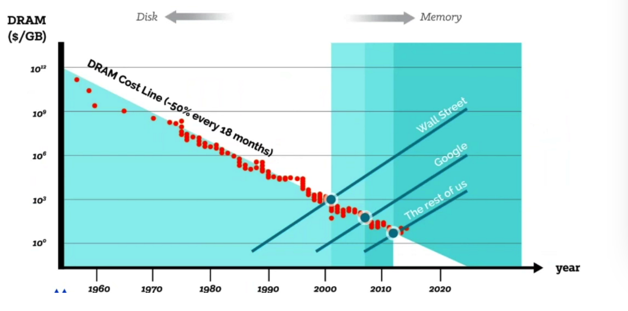
因此,充分利用内存,成为趋势,而Memory locality成为影响相应时间最重要的因素之一。硬盘内存价格曲线:
Alluxio with Spark
Spark是一种基于内存的运算框架。
在JVM的内存中存储一份,以保证较少的网络通信和读写。
记录存储数据的世代(lineage),当数据丢失时,基于世代将job重新运行,得到相应数据。
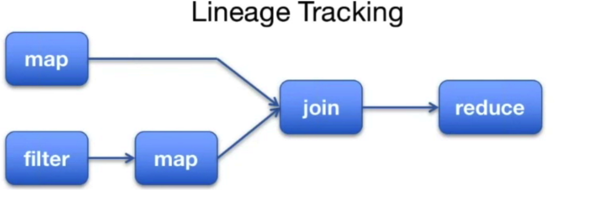
Issue 1:数据分享(Data Sharing)在analytics pipeline中成为瓶颈。
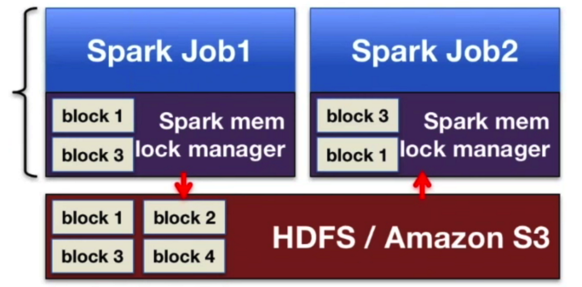
在Spark中,如果job2需要Job1运算的数据,Job1首先需要将数据写入到HDFS的block中,会产生硬盘甚至跨网络的读写,同时在HDFS中默认数据需要写三份,因此造成性能的损失。
Issue 1 的解决方案:内存数据在不同的job和framework中进行分享。
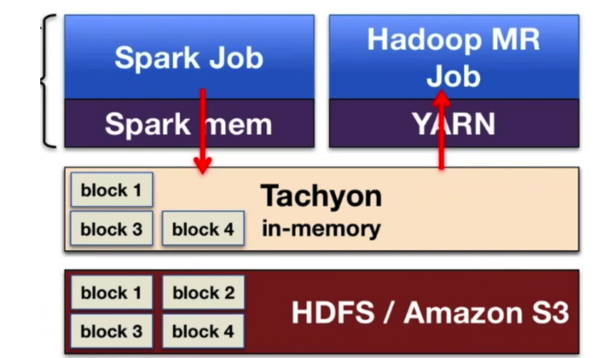
Alluxio在HDFS/ Amazon S3和计算引擎中间提供了中间层,Spark的Job1不需要写到HDFS中,而只需要写到Alluxio的内存中,Job2可以从内存中读取相应数据。
Issue 2: 当计算引擎的进程损坏,Cache 丢失,Spark只能重新启动并计算恢复数据。
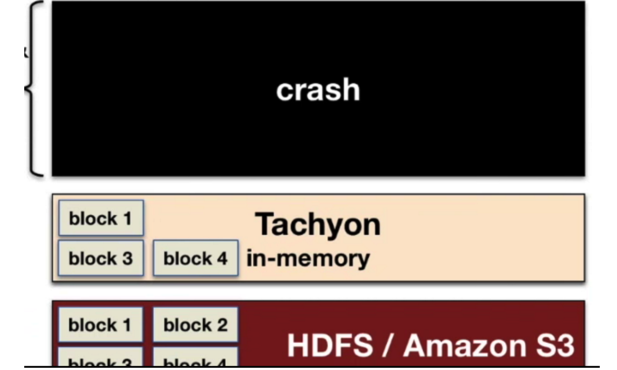
Issue 2 解决方案:
当计算引擎损坏,由于中间由Alluxio存储数据,可以保证内存中的数据安全。
问题1:因为在传统计算引擎中,数据存储在同一个JVM中,而基于Alluxio的中间件将数据存到了不同的JVM中,跨JVM读写会不会影响性能?
答:跨JVM读写会影响性能,在Alluxio中,使用了RamDisk来模拟本地文件系统的方式。
问题2:如果Alluxio crash,怎么保证数据安全?
答:在Alluxio中,数据不是保存在JVM中,而是保存在RamDisk中,RamDisk为独立的进程,因此可以保证数据安全。
问题3:Alluxio是否可以支持随机读写?
答:可以进行随机读,给定一个offset。新创立的文件一旦关闭,就会变成immutable
Issue 3: 内存数据的重复和Java的垃圾回收。Issue 3 解决方案:
由于计算引擎与存储引擎共享同一个进程,而不是放在自己的JVM中,可以减少垃圾回收和数据重复。
Alluxio 架构: Memory-centric storage architecture
核心思想:将世代(lineage)由计算引擎放到了数据层处理。
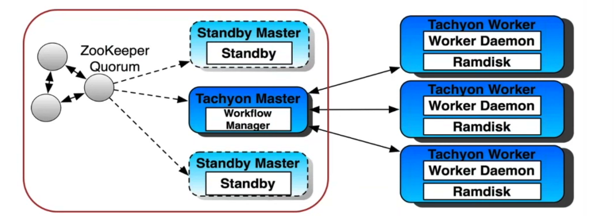
1,存储架构:
master节点负责管理worker节点,数据存储在worker节点中。
对于每一个worker,worker daemon为一个JVM,负责管理Ramdisk,数据存储在Ramdisk中。
如果有高可用性的需求,可以设置standby master和zookeeper来容错,这里会有性能损耗。
2,世代(Lineage) 保证数据的Reliability
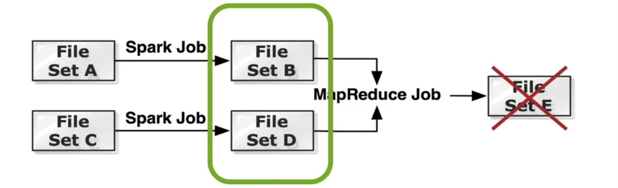
1,当数据E丢失后,通过世代找到相应的之前数据,重新部署一个Job将数据重新计算。
2,将数据在底层文件系统中备份。
问题:HDFS中每个数据块会默认有多个备份, 从而在极端情况下会有更大的读取带宽。 在Alluxio中,由于数据存储在同一份内存中,如何处理多个Job同时读取同一份数据的情况。
答: Alluxio的数据在内存当中,本身可以提供更大的本地读取带宽。另外Alluxio也允许让用户绕过Alluxio直接从底层的持久化文件系统读取数据。
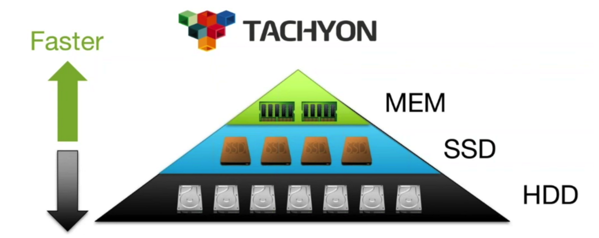
3,分层存储(Tiered Storage):
当数据大小超过内存容量,如何处理?
Alluxio不仅仅管理内存,同样可以管理SSD,HDD等系统资源。保证Alluxio可以正常运行。
One Large Scale deployment:
某公司实现了1000 workder 的Alluxio部署,每个机器几G-几十个G的内存 。
4,可插拔的数据管理(Pluggable Data Management)
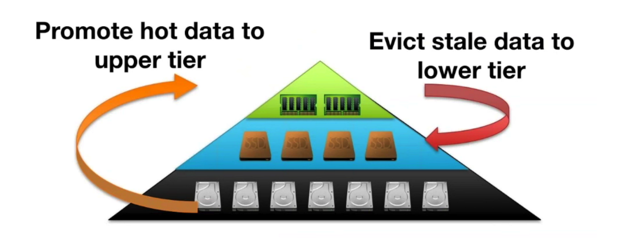
基于每一个worker,暂时没有跨worker。对于计算机系统来说,长期以来人们在不同的场景下反复使用两个经典但行之有效的方案:
1,cache。
2,增加一个中间层(比如增加一层指针,如virtual memory)
Q: Alluxio 有没有全局的分层存储的allocation/eviction管理?
A: 目前Alluxio的cache策略是基于每一个worker单独的决策,暂时没有实现跨worker的分层存储的协作。
5,Pin Data

对于重要的数据,可以通过Pin来显示的把数据“挂”在内存层
问题:对于Pin的data,怎么保证底层数据修改之后上层数据的更新。
答:给用户提供命令去主动更新数据。
6,透明命名(Transparent Naming)
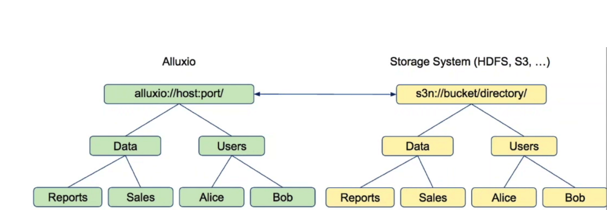
Alluxio可以提供将创建,重命名和删除文件等操作从Alluxio映射到底层存储层(比如上图中的HDFS 或者S3)的对象中,从而实现将底层存储系统中的文件与其Alluxio自身管理的文件系统的完全同步。
7,统一命名空间(Unified Namespace)
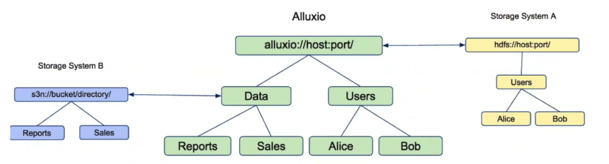
Alluxio可以挂载多个不同的文件系统到一个统一的命名空间当中,如不同的文件系统A和文件系统B可以同时挂载到Alluxio上面的不同目录当中。
在不同的数据文件系统中可以共享数据。
此操作可以on the fly,被管理员进行操作。
Alluxio Case Study:
百度:
性能提升:30x
框架: SparkSQL
存储系统: Baidu’s File System
存储媒介: MEM+HDD
节点数量: 100+
空间管理大小:1PB+
Q: 为什么可以提供30x的性能提升?
A: 百度的一项业务采用计算和存储分离的架构:比如计算集群在一个城市,而数据存储集群在另一个城市。数据存储集群计算资源较少,而计算集群没有足够存储资源。百度将Alluxio部署到了计算集群中。从而将数据存储在了Alluxio中,从而使计算集群可以在本地完成读写。
去哪儿网:
框架:Spark Streaming
存储系统:HDFSS
存储媒介:MEM+HDD
节点数量:200+
Barclays:
框架:SparkSQL
存储系统:None
存储媒介: Memory
某石油公司:
框架: Spark
存储数据:ClusterFS
存储媒介:MEM only
性能提升:在传统文件系统中使用Spark进行数据处理。
某SAAS公司:
框架:Impala
存储系统: S3
存储媒介: MEM+SSD
性能提升:15x
Alluxio新特性:
- Alluxio Key-value (Alpha)
- Native Swift Integration(Openstack下面的文件系统)
- Alibaba Object Storage Service Integration
- Users/Groups in File System
- ACL Permission
- Read/Write Location Preference Policy
- Improved Yarn and Mesos Integration
注:本文系2016年2月29日太阁三人行“一起聊聊Alluxio”的总结分享,感谢Menglei Sun的整理,Dr Bin Fan的校注
转载于:https://www.cnblogs.com/bonelee/p/11041665.html
Alluxio : 开源分布式内存文件系统相关推荐
- 分布式内存文件系统Alluxio
分布式内存文件系统 alluxio 简介 简介 简单架构图 alluxio源码 https://gitee.com/pingfanrenbiji/alluxio.git 官方文档 https://do ...
- 分布式持久内存文件系统Octopus(ATC-17 )分析(二)
清华课题 Octopus 源码分析(二) 前言 论文摘要 设计框架 源码分析 include 头文件 Configuration.hpp common.hpp bitmap.hpp debug.hpp ...
- 分布式持久内存文件系统Octopus(ATC-17 )分析(三)
清华课题 Octopus 源码分析(三) 前言 论文摘要 设计框架 源码分析 include 头文件 src 源文件 fs 模块 net 模块 client 模块 tools 模块 文件依赖关系分析 ...
- 分布式持久内存文件系统Octopus(ATC-17 )分析(一)
清华课题 Octopus 源码分析一 前言 论文摘要 设计框架 源码分析 清华课题 Octopus 源码分析(一) 前言 由于项目工作的需要,我们团队阅读了清华在文件系统方面的一个比较新颖的工作:Oc ...
- 分布式持久内存文件系统Octopus(ATC-17 )分析(五)
清华课题 Octopus 源码分析(五) 前言 论文摘要 设计框架 src目录源码分析 fs 模块 TxManager.cpp filesystem.cpp 清华课题 Octopus 源码分析(五) ...
- 分布式持久内存文件系统Octopus(ATC-17 )分析(四)
清华课题 Octopus 源码分析四 前言 论文摘要 设计框架 src目录源码分析 fs 模块 bitmapcpp lockcpp hashtablecpp storagecpp TxManagerc ...
- Java分布式内存开源实现:Hazelcast
Hazelcast是一个Java的开源分布式内存实现,它具有以下特性: 01 Distributed implementations of java.util.{Queue, Set, List ...
- hazelcast java_Java分布式内存开源实现:Hazelcast
Hazelcast是一个Java的开源分布式内存实现,它具有以下特性: 01 Distributed implementations of java.util.{Queue, Set, List ...
- java中如何合并两个网格,Hazelcast: Java分布式内存网格框架(平台)
转自:http://blog.csdn.net/iihero/article/details/7385641 下边是它的宣传内容: hazelcast是一个开放源码集群和高度可扩展的数据分发平台,这是 ...
最新文章
- 2013年上半年全国高等学校(安徽考区)计算机水平考试试卷,2013年上半年全国高等学校(安徽考区)计算机水平考试试卷(6页)-原创力文档...
- CTFshow 信息收集 web3
- 通过printf设置Linux终端输出的颜色和显示方式
- video和dvd audio区别:
- vue的computed计算属性学习
- 计算仰角_41页最新全站仪测量方法及计算+图文解说,助你轻松掌握测量
- Hibrenate实现根据实体类自动创建表或添加字段
- python虚拟环境windows环境搭建_window10配置python虚拟环境的路径
- Emberjs学习之路(一)
- Spark大数据技术与应用
- 熵值法确定权重算法及Matlab实现
- 为什么excel中取消隐藏行后仍然有隐藏的行
- 【HEC-RAS】02 软件下载及安装
- 雷允上药业百年老店回春
- maximo-API下载连接
- 计算机开机主机不停地重启,求救:电脑一直重启,开机自检后,一会就重启
- 分享一套永久免费的ChatGPT使用方法
- 大写字母逆序2 (100分)
- could only be written to 0 of the 1 minReplication nodes. There are 0 datanode(s) running and 0 node
- H264 nal_aud, TS格式分析;分析一帧数据包(H264)
热门文章
- c++人脸特征保存到本地_尚邦小规模人脸识别布控系统
- oracle text db2,从Oracle 到DB2(一)
- jexcel可以合并单元格么_含金量超高的3个文本、字符合并实用技巧解读!
- ppt格式刷快捷键_高效地制作PPT
- python列表索引 end start_python学习--list列表操作
- 华为正式发布鸿蒙智慧屏,华为正式发布鸿蒙OS操作系统 智慧屏将率先使用
- android编译.a文件,Android 7.1源码编译导入AS完整教程
- 与word2vec_NLP--Word2Vec详解
- 引用http开头的JS失败以及laravel的url()方法的坑
- 大厂首发!java代码对齐快捷键