YOLOV3林业病虫害数据集和数据预处理-paddle教程
林业病虫害数据集和数据预处理方法介绍
在本课程中,将使用百度与林业大学合作开发的林业病虫害防治项目中用到昆虫数据集。
读取AI识虫数据集标注信息
AI识虫数据集结构如下:
- 提供了2183张图片,其中训练集1693张,验证集245,测试集245张。
- 包含7种昆虫,分别是Boerner、Leconte、Linnaeus、acuminatus、armandi、coleoptera和linnaeus。
- 包含了图片和标注,请读者先将数据解压,并存放在insects目录下。
!conda list
# packages in environment at C:\ProgramData\Anaconda3\envs\paddle:
#
# Name Version Build Channel
astor 0.8.1 pypi_0 pypi
backcall 0.2.0 pyhd3eb1b0_0 defaults
certifi 2021.5.30 py36haa95532_0 defaults
charset-normalizer 2.0.7 pypi_0 pypi
colorama 0.4.4 pyhd3eb1b0_0 defaults
decorator 5.1.0 pyhd3eb1b0_0 defaults
entrypoints 0.3 py36_0 defaults
gast 0.3.3 pypi_0 pypi
idna 3.3 pypi_0 pypi
ipykernel 5.3.4 py36h5ca1d4c_0 defaults
ipython 7.16.1 py36h5ca1d4c_0 defaults
ipython_genutils 0.2.0 pyhd3eb1b0_1 defaults
jedi 0.17.0 py36_0 defaults
jupyter_client 7.0.1 pyhd3eb1b0_0 defaults
jupyter_core 4.8.1 py36haa95532_0 defaults
nest-asyncio 1.5.1 pyhd3eb1b0_0 defaults
numpy 1.19.3 pypi_0 pypi
paddlepaddle-gpu 2.1.3.post101 pypi_0 pypi
parso 0.8.2 pyhd3eb1b0_0 defaults
pickleshare 0.7.5 pyhd3eb1b0_1003 defaults
pillow 8.4.0 pypi_0 pypi
pip 21.2.2 py36haa95532_0 defaults
prompt-toolkit 3.0.20 pyhd3eb1b0_0 defaults
protobuf 3.19.1 pypi_0 pypi
pygments 2.10.0 pyhd3eb1b0_0 defaults
python 3.6.13 h3758d61_0 defaults
python-dateutil 2.8.2 pyhd3eb1b0_0 defaults
pywin32 228 py36hbaba5e8_1 defaults
pyzmq 22.2.1 py36hd77b12b_1 defaults
requests 2.26.0 pypi_0 pypi
setuptools 58.0.4 py36haa95532_0 defaults
six 1.16.0 pyhd3eb1b0_0 defaults
sqlite 3.36.0 h2bbff1b_0 defaults
tornado 6.1 py36h2bbff1b_0 defaults
traitlets 4.3.3 py36haa95532_0 defaults
urllib3 1.26.7 pypi_0 pypi
vc 14.2 h21ff451_1 defaults
vs2015_runtime 14.27.29016 h5e58377_2 defaults
wcwidth 0.2.5 pyhd3eb1b0_0 defaults
wheel 0.37.0 pyhd3eb1b0_1 defaults
wincertstore 0.2 py36h7fe50ca_0 defaults
将数据解压之后,可以看到insects目录下的结构如下所示。
insects|---train| |---annotations| | |---xmls| | |---100.xml| | |---101.xml| | |---...| || |---images| |---100.jpeg| |---101.jpeg| |---...||---val| |---annotations| | |---xmls| | |---1221.xml| | |---1277.xml| | |---...| || |---images| |---1221.jpeg| |---1277.jpeg| |---...||---test|---images|---1833.jpeg|---1838.jpeg|---...
insects包含train、val和test三个文件夹。train/annotations/xmls目录下存放着图片的标注。每个xml文件是对一张图片的说明,包括图片尺寸、包含的昆虫名称、在图片上出现的位置等信息。
<annotation><folder>刘霏霏</folder><filename>100.jpeg</filename><path>/home/fion/桌面/刘霏霏/100.jpeg</path><source><database>Unknown</database></source><size><width>1336</width><height>1336</height><depth>3</depth></size><segmented>0</segmented><object><name>Boerner</name><pose>Unspecified</pose><truncated>0</truncated><difficult>0</difficult><bndbox><xmin>500</xmin><ymin>893</ymin><xmax>656</xmax><ymax>966</ymax></bndbox></object><object><name>Leconte</name><pose>Unspecified</pose><truncated>0</truncated><difficult>0</difficult><bndbox><xmin>622</xmin><ymin>490</ymin><xmax>756</xmax><ymax>610</ymax></bndbox></object><object><name>armandi</name><pose>Unspecified</pose><truncated>0</truncated><difficult>0</difficult><bndbox><xmin>432</xmin><ymin>663</ymin><xmax>517</xmax><ymax>729</ymax></bndbox></object><object><name>coleoptera</name><pose>Unspecified</pose><truncated>0</truncated><difficult>0</difficult><bndbox><xmin>624</xmin><ymin>685</ymin><xmax>697</xmax><ymax>771</ymax></bndbox></object><object><name>linnaeus</name><pose>Unspecified</pose><truncated>0</truncated><difficult>0</difficult><bndbox><xmin>783</xmin><ymin>700</ymin><xmax>856</xmax><ymax>802</ymax></bndbox></object>
</annotation>
上面列出的xml文件中的主要参数说明如下:
size:图片尺寸。
object:图片中包含的物体,一张图片可能中包含多个物体。
– name:昆虫名称;
– bndbox:物体真实框;
– difficult:识别是否困难。
下面我们将从数据集中读取xml文件,将每张图片的标注信息读取出来。在读取具体的标注文件之前,我们先完成一件事情,就是将昆虫的类别名字(字符串)转化成数字表示的类别。因为神经网络里面计算时需要的输入类型是数值型的,所以需要将字符串表示的类别转化成具体的数字。昆虫类别名称的列表是:[‘Boerner’, ‘Leconte’, ‘Linnaeus’, ‘acuminatus’, ‘armandi’, ‘coleoptera’, ‘linnaeus’],这里我们约定此列表中:'Boerner’对应类别0,'Leconte’对应类别1,…,'linnaeus’对应类别6。使用下面的程序可以得到表示名称字符串和数字类别之间映射关系的字典。
INSECT_NAMES = ['Boerner', 'Leconte', 'Linnaeus', 'acuminatus', 'armandi', 'coleoptera', 'linnaeus']def get_insect_names():"""return a dict, as following,{'Boerner': 0,'Leconte': 1,'Linnaeus': 2, 'acuminatus': 3,'armandi': 4,'coleoptera': 5,'linnaeus': 6}It can map the insect name into an integer label."""insect_category2id = {}for i, item in enumerate(INSECT_NAMES):insect_category2id[item] = ireturn insect_category2id
cname2cid = get_insect_names()
cname2cid
{‘Boerner’: 0,
‘Leconte’: 1,
‘Linnaeus’: 2,
‘acuminatus’: 3,
‘armandi’: 4,
‘coleoptera’: 5,
‘linnaeus’: 6}
调用get_insect_names函数返回一个dict,描述了昆虫名称和数字类别之间的映射关系。下面的程序从annotations/xml目录下面读取所有文件标注信息。
import os
import numpy as np
import xml.etree.ElementTree as ETdef get_annotations(cname2cid, datadir):filenames = os.listdir(os.path.join(datadir, 'annotations', 'xmls'))records = []ct = 0for fname in filenames:fid = fname.split('.')[0]fpath = os.path.join(datadir, 'annotations', 'xmls', fname)img_file = os.path.join(datadir, 'images', fid + '.jpeg')tree = ET.parse(fpath)if tree.find('id') is None:im_id = np.array([ct])else:im_id = np.array([int(tree.find('id').text)])objs = tree.findall('object')im_w = float(tree.find('size').find('width').text)im_h = float(tree.find('size').find('height').text)gt_bbox = np.zeros((len(objs), 4), dtype=np.float32)gt_class = np.zeros((len(objs), ), dtype=np.int32)is_crowd = np.zeros((len(objs), ), dtype=np.int32)difficult = np.zeros((len(objs), ), dtype=np.int32)for i, obj in enumerate(objs):cname = obj.find('name').textgt_class[i] = cname2cid[cname]_difficult = int(obj.find('difficult').text)x1 = float(obj.find('bndbox').find('xmin').text)y1 = float(obj.find('bndbox').find('ymin').text)x2 = float(obj.find('bndbox').find('xmax').text)y2 = float(obj.find('bndbox').find('ymax').text)x1 = max(0, x1)y1 = max(0, y1)x2 = min(im_w - 1, x2)y2 = min(im_h - 1, y2)# 这里使用xywh格式来表示目标物体真实框gt_bbox[i] = [(x1+x2)/2.0 , (y1+y2)/2.0, x2-x1+1., y2-y1+1.]is_crowd[i] = 0difficult[i] = _difficultvoc_rec = {'im_file': img_file,'im_id': im_id,'h': im_h,'w': im_w,'is_crowd': is_crowd,'gt_class': gt_class,'gt_bbox': gt_bbox,'gt_poly': [],'difficult': difficult}if len(objs) != 0:records.append(voc_rec)ct += 1return records
TRAINDIR = './insects/train'
TESTDIR = './insects/test'
VALIDDIR = './insects/val'
cname2cid = get_insect_names()
records = get_annotations(cname2cid, TRAINDIR)
records[0]
{‘im_file’: ‘./insects/train\images\1.jpeg’, ‘im_id’: array([0]), ‘h’: 1344.0, ‘w’: 1344.0, ‘is_crowd’: array([0, 0, 0, 0, 0]), ‘gt_class’: array([1, 0, 6, 4, 5]), ‘gt_bbox’: array([[542.5, 652.5,
140. , 150. ],
[885. , 572. , 127. , 135. ],
[648.5, 811.5, 84. , 62. ],
[798.5, 821. , 86. , 71. ],
[667.5, 521. , 88. , 67. ]], dtype=float32), ‘gt_poly’: [], ‘difficult’: array([0, 0, 0, 0, 0])}
len(records)
1693
通过上面的程序,将所有训练数据集的标注数据全部读取出来了,存放在records列表下面,其中每一个元素是一张图片的标注数据,包含了图片存放地址,图片id,图片高度和宽度,图片中所包含的目标物体的种类和位置。
数据读取和预处理
数据预处理是训练神经网络时非常重要的步骤。合适的预处理方法,可以帮助模型更好的收敛并防止过拟合。首先我们需要从磁盘读入数据,然后需要对这些数据进行预处理,为了保证网络运行的速度,通常还要对数据预处理进行加速。
数据读取
前面已经将图片的所有描述信息保存在records中了,其中每一个元素都包含了一张图片的描述,下面的程序展示了如何根据records里面的描述读取图片及标注。
# 数据读取
import cv2def get_bbox(gt_bbox, gt_class):# 对于一般的检测任务来说,一张图片上往往会有多个目标物体# 设置参数MAX_NUM = 50, 即一张图片最多取50个真实框;如果真实# 框的数目少于50个,则将不足部分的gt_bbox, gt_class和gt_score的各项数值全设置为0MAX_NUM = 50gt_bbox2 = np.zeros((MAX_NUM, 4))gt_class2 = np.zeros((MAX_NUM,))for i in range(len(gt_bbox)):gt_bbox2[i, :] = gt_bbox[i, :]gt_class2[i] = gt_class[i]if i >= MAX_NUM:breakreturn gt_bbox2, gt_class2def get_img_data_from_file(record):"""record is a dict as following,record = {'im_file': img_file,'im_id': im_id,'h': im_h,'w': im_w,'is_crowd': is_crowd,'gt_class': gt_class,'gt_bbox': gt_bbox,'gt_poly': [],'difficult': difficult}"""im_file = record['im_file']h = record['h']w = record['w']is_crowd = record['is_crowd']gt_class = record['gt_class']gt_bbox = record['gt_bbox']difficult = record['difficult']img = cv2.imread(im_file)img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)# check if h and w in record equals that read from imgassert img.shape[0] == int(h), \"image height of {} inconsistent in record({}) and img file({})".format(im_file, h, img.shape[0])assert img.shape[1] == int(w), \"image width of {} inconsistent in record({}) and img file({})".format(im_file, w, img.shape[1])gt_boxes, gt_labels = get_bbox(gt_bbox, gt_class)# gt_bbox 用相对值gt_boxes[:, 0] = gt_boxes[:, 0] / float(w)gt_boxes[:, 1] = gt_boxes[:, 1] / float(h)gt_boxes[:, 2] = gt_boxes[:, 2] / float(w)gt_boxes[:, 3] = gt_boxes[:, 3] / float(h)return img, gt_boxes, gt_labels, (h, w)
record = records[0]
img, gt_boxes, gt_labels, scales = get_img_data_from_file(record)
img.shape
(1344, 1344, 3)
gt_boxes.shape
(50, 4)
gt_labels
array([1., 0., 6., 4., 5., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
scales
(1344.0, 1344.0)
get_img_data_from_file()函数可以返回图片数据的数据,它们是图像数据img,真实框坐标gt_boxes,真实框包含的物体类别gt_labels,图像尺寸scales。
数据预处理
在计算机视觉中,通常会对图像做一些随机的变化,产生相似但又不完全相同的样本。主要作用是扩大训练数据集,抑制过拟合,提升模型的泛化能力,常用的方法主要有以下几种:
- 随机改变亮暗、对比度和颜色
- 随机填充
- 随机裁剪
- 随机缩放
- 随机翻转
- 随机打乱真实框排列顺序
下面我们分别使用numpy 实现这些数据增强方法。
随机改变亮暗、对比度和颜色等
import numpy as np
import cv2
from PIL import Image, ImageEnhance
import random# 随机改变亮暗、对比度和颜色等
def random_distort(img):# 随机改变亮度def random_brightness(img, lower=0.5, upper=1.5):e = np.random.uniform(lower, upper)return ImageEnhance.Brightness(img).enhance(e)# 随机改变对比度def random_contrast(img, lower=0.5, upper=1.5):e = np.random.uniform(lower, upper)return ImageEnhance.Contrast(img).enhance(e)# 随机改变颜色def random_color(img, lower=0.5, upper=1.5):e = np.random.uniform(lower, upper)return ImageEnhance.Color(img).enhance(e)ops = [random_brightness, random_contrast, random_color]np.random.shuffle(ops)img = Image.fromarray(img)img = ops[0](img)img = ops[1](img)img = ops[2](img)img = np.asarray(img)return img# 定义可视化函数,用于对比原图和图像增强的效果
import matplotlib.pyplot as plt
def visualize(srcimg, img_enhance):# 图像可视化plt.figure(num=2, figsize=(6,12))plt.subplot(1,2,1)plt.title('Src Image', color='#0000FF')plt.axis('off') # 不显示坐标轴plt.imshow(srcimg) # 显示原图片# 对原图做 随机改变亮暗、对比度和颜色等 数据增强srcimg_gtbox = records[0]['gt_bbox']srcimg_label = records[0]['gt_class']plt.subplot(1,2,2)plt.title('Enhance Image', color='#0000FF')plt.axis('off') # 不显示坐标轴plt.imshow(img_enhance)image_path = records[0]['im_file']
print("read image from file {}".format(image_path))
srcimg = Image.open(image_path)
# 将PIL读取的图像转换成array类型
srcimg = np.array(srcimg)# 对原图做 随机改变亮暗、对比度和颜色等 数据增强
img_enhance = random_distort(srcimg)
visualize(srcimg, img_enhance)
read image from file ./insects/train\images\1.jpeg
![]()
随机填充
# 随机填充
def random_expand(img,gtboxes,max_ratio=4.,fill=None,keep_ratio=True,thresh=0.5):if random.random() > thresh:return img, gtboxesif max_ratio < 1.0:return img, gtboxesh, w, c = img.shaperatio_x = random.uniform(1, max_ratio)if keep_ratio:ratio_y = ratio_xelse:ratio_y = random.uniform(1, max_ratio)oh = int(h * ratio_y)ow = int(w * ratio_x)off_x = random.randint(0, ow - w)off_y = random.randint(0, oh - h)out_img = np.zeros((oh, ow, c))if fill and len(fill) == c:for i in range(c):out_img[:, :, i] = fill[i] * 255.0out_img[off_y:off_y + h, off_x:off_x + w, :] = imggtboxes[:, 0] = ((gtboxes[:, 0] * w) + off_x) / float(ow)gtboxes[:, 1] = ((gtboxes[:, 1] * h) + off_y) / float(oh)gtboxes[:, 2] = gtboxes[:, 2] / ratio_xgtboxes[:, 3] = gtboxes[:, 3] / ratio_yreturn out_img.astype('uint8'), gtboxes# 对原图做 随机改变亮暗、对比度和颜色等 数据增强
srcimg_gtbox = records[0]['gt_bbox']
img_enhance, new_gtbox = random_expand(srcimg, srcimg_gtbox)
visualize(srcimg, img_enhance)
![]()
随机裁剪
随机裁剪之前需要先定义两个函数,multi_box_iou_xywh和box_crop这两个函数将被保存在box_utils.py文件中。
import numpy as npdef multi_box_iou_xywh(box1, box2):"""In this case, box1 or box2 can contain multi boxes.Only two cases can be processed in this method:1, box1 and box2 have the same shape, box1.shape == box2.shape2, either box1 or box2 contains only one box, len(box1) == 1 or len(box2) == 1If the shape of box1 and box2 does not match, and both of them contain multi boxes, it will be wrong."""assert box1.shape[-1] == 4, "Box1 shape[-1] should be 4."assert box2.shape[-1] == 4, "Box2 shape[-1] should be 4."b1_x1, b1_x2 = box1[:, 0] - box1[:, 2] / 2, box1[:, 0] + box1[:, 2] / 2b1_y1, b1_y2 = box1[:, 1] - box1[:, 3] / 2, box1[:, 1] + box1[:, 3] / 2b2_x1, b2_x2 = box2[:, 0] - box2[:, 2] / 2, box2[:, 0] + box2[:, 2] / 2b2_y1, b2_y2 = box2[:, 1] - box2[:, 3] / 2, box2[:, 1] + box2[:, 3] / 2inter_x1 = np.maximum(b1_x1, b2_x1)inter_x2 = np.minimum(b1_x2, b2_x2)inter_y1 = np.maximum(b1_y1, b2_y1)inter_y2 = np.minimum(b1_y2, b2_y2)inter_w = inter_x2 - inter_x1inter_h = inter_y2 - inter_y1inter_w = np.clip(inter_w, a_min=0., a_max=None)inter_h = np.clip(inter_h, a_min=0., a_max=None)inter_area = inter_w * inter_hb1_area = (b1_x2 - b1_x1) * (b1_y2 - b1_y1)b2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1)return inter_area / (b1_area + b2_area - inter_area)def box_crop(boxes, labels, crop, img_shape):x, y, w, h = map(float, crop)im_w, im_h = map(float, img_shape)boxes = boxes.copy()boxes[:, 0], boxes[:, 2] = (boxes[:, 0] - boxes[:, 2] / 2) * im_w, (boxes[:, 0] + boxes[:, 2] / 2) * im_wboxes[:, 1], boxes[:, 3] = (boxes[:, 1] - boxes[:, 3] / 2) * im_h, (boxes[:, 1] + boxes[:, 3] / 2) * im_hcrop_box = np.array([x, y, x + w, y + h])centers = (boxes[:, :2] + boxes[:, 2:]) / 2.0mask = np.logical_and(crop_box[:2] <= centers, centers <= crop_box[2:]).all(axis=1)boxes[:, :2] = np.maximum(boxes[:, :2], crop_box[:2])boxes[:, 2:] = np.minimum(boxes[:, 2:], crop_box[2:])boxes[:, :2] -= crop_box[:2]boxes[:, 2:] -= crop_box[:2]mask = np.logical_and(mask, (boxes[:, :2] < boxes[:, 2:]).all(axis=1))boxes = boxes * np.expand_dims(mask.astype('float32'), axis=1)labels = labels * mask.astype('float32')boxes[:, 0], boxes[:, 2] = (boxes[:, 0] + boxes[:, 2]) / 2 / w, (boxes[:, 2] - boxes[:, 0]) / wboxes[:, 1], boxes[:, 3] = (boxes[:, 1] + boxes[:, 3]) / 2 / h, (boxes[:, 3] - boxes[:, 1]) / hreturn boxes, labels, mask.sum()# 随机裁剪
def random_crop(img,boxes,labels,scales=[0.3, 1.0],max_ratio=2.0,constraints=None,max_trial=50):if len(boxes) == 0:return img, boxesif not constraints:constraints = [(0.1, 1.0), (0.3, 1.0), (0.5, 1.0), (0.7, 1.0),(0.9, 1.0), (0.0, 1.0)]img = Image.fromarray(img)w, h = img.sizecrops = [(0, 0, w, h)]for min_iou, max_iou in constraints:for _ in range(max_trial):scale = random.uniform(scales[0], scales[1])aspect_ratio = random.uniform(max(1 / max_ratio, scale * scale), \min(max_ratio, 1 / scale / scale))crop_h = int(h * scale / np.sqrt(aspect_ratio))crop_w = int(w * scale * np.sqrt(aspect_ratio))crop_x = random.randrange(w - crop_w)crop_y = random.randrange(h - crop_h)crop_box = np.array([[(crop_x + crop_w / 2.0) / w,(crop_y + crop_h / 2.0) / h,crop_w / float(w), crop_h / float(h)]])iou = multi_box_iou_xywh(crop_box, boxes)if min_iou <= iou.min() and max_iou >= iou.max():crops.append((crop_x, crop_y, crop_w, crop_h))breakwhile crops:crop = crops.pop(np.random.randint(0, len(crops)))crop_boxes, crop_labels, box_num = box_crop(boxes, labels, crop, (w, h))if box_num < 1:continueimg = img.crop((crop[0], crop[1], crop[0] + crop[2],crop[1] + crop[3])).resize(img.size, Image.LANCZOS)img = np.asarray(img)return img, crop_boxes, crop_labelsimg = np.asarray(img)return img, boxes, labels# 对原图做 随机改变亮暗、对比度和颜色等 数据增强
srcimg_gtbox = records[0]['gt_bbox']
srcimg_label = records[0]['gt_class']img_enhance, new_labels, mask = random_crop(srcimg, srcimg_gtbox, srcimg_label)
visualize(srcimg, img_enhance)
![]()
随机缩放
# 随机缩放
def random_interp(img, size, interp=None):interp_method = [cv2.INTER_NEAREST,cv2.INTER_LINEAR,cv2.INTER_AREA,cv2.INTER_CUBIC,cv2.INTER_LANCZOS4,]if not interp or interp not in interp_method:interp = interp_method[random.randint(0, len(interp_method) - 1)]h, w, _ = img.shapeim_scale_x = size / float(w)im_scale_y = size / float(h)img = cv2.resize(img, None, None, fx=im_scale_x, fy=im_scale_y, interpolation=interp)return img# 对原图做 随机改变亮暗、对比度和颜色等 数据增强
img_enhance = random_interp(srcimg, 640)
visualize(srcimg, img_enhance)
![]()
随机翻转
# 随机翻转
def random_flip(img, gtboxes, thresh=0.5):if random.random() > thresh:img = img[:, ::-1, :]gtboxes[:, 0] = 1.0 - gtboxes[:, 0]return img, gtboxes# 对原图做 随机改变亮暗、对比度和颜色等 数据增强
img_enhance, box_enhance = random_flip(srcimg, srcimg_gtbox)
visualize(srcimg, img_enhance)
![]()
随机打乱真实框排列顺序
# 随机打乱真实框排列顺序
def shuffle_gtbox(gtbox, gtlabel):gt = np.concatenate([gtbox, gtlabel[:, np.newaxis]], axis=1)idx = np.arange(gt.shape[0])np.random.shuffle(idx)gt = gt[idx, :]return gt[:, :4], gt[:, 4]
图像增广方法汇总
# 图像增广方法汇总
def image_augment(img, gtboxes, gtlabels, size, means=None):# 随机改变亮暗、对比度和颜色等img = random_distort(img)# 随机填充img, gtboxes = random_expand(img, gtboxes, fill=means)# 随机裁剪img, gtboxes, gtlabels, = random_crop(img, gtboxes, gtlabels)# 随机缩放img = random_interp(img, size)# 随机翻转img, gtboxes = random_flip(img, gtboxes)# 随机打乱真实框排列顺序gtboxes, gtlabels = shuffle_gtbox(gtboxes, gtlabels)return img.astype('float32'), gtboxes.astype('float32'), gtlabels.astype('int32')img_enhance, img_box, img_label = image_augment(srcimg, srcimg_gtbox, srcimg_label, size=320)
visualize(srcimg, img_enhance)Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
![]()
img, gt_boxes, gt_labels, scales = get_img_data_from_file(record)
size = 512
img, gt_boxes, gt_labels = image_augment(img, gt_boxes, gt_labels, size)
img.shape
(512, 512, 3)
gt_boxes.shape
(50, 4)
gt_labels.shape
(50,)
这里得到的img数据数值需要调整,需要除以255,并且减去均值和方差,再将维度从[H, W, C]调整为[C, H, W]。
img, gt_boxes, gt_labels, scales = get_img_data_from_file(record)
size = 512
img, gt_boxes, gt_labels = image_augment(img, gt_boxes, gt_labels, size)
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
mean = np.array(mean).reshape((1, 1, -1))
std = np.array(std).reshape((1, 1, -1))
img = (img / 255.0 - mean) / std
img = img.astype('float32').transpose((2, 0, 1))
img
array([[[-2.117904 , -2.117904 , -2.117904 , …, -2.117904 ,
-2.117904 , -2.117904 ],
[-2.117904 , -2.117904 , -2.117904 , …, -2.117904 ,
-2.117904 , -2.117904 ],
[-2.117904 , -2.117904 , -2.117904 , …, -2.117904 ,
-2.117904 , -2.117904 ],
…,
[-2.117904 , -2.117904 , -2.117904 , …, -2.117904 ,
-2.117904 , -2.117904 ],
[-2.117904 , -2.117904 , -2.117904 , …, -2.117904 ,
-2.117904 , -2.117904 ],
[-2.117904 , -2.117904 , -2.117904 , …, -2.117904 ,
-2.117904 , -2.117904 ]],
[[-2.0357144, -2.0357144, -2.0357144, …, -2.0357144,
-2.0357144, -2.0357144],
[-2.0357144, -2.0357144, -2.0357144, …, -2.0357144,
-2.0357144, -2.0357144],
[-2.0357144, -2.0357144, -2.0357144, …, -2.0357144,
-2.0357144, -2.0357144],
…,
[-2.0357144, -2.0357144, -2.0357144, …, -2.0357144,
-2.0357144, -2.0357144],
[-2.0357144, -2.0357144, -2.0357144, …, -2.0357144,
-2.0357144, -2.0357144],
[-2.0357144, -2.0357144, -2.0357144, …, -2.0357144,
-2.0357144, -2.0357144]],
[[-1.8044444, -1.8044444, -1.8044444, …, -1.8044444,
-1.8044444, -1.8044444],
[-1.8044444, -1.8044444, -1.8044444, …, -1.8044444,
-1.8044444, -1.8044444],
[-1.8044444, -1.8044444, -1.8044444, …, -1.8044444,
-1.8044444, -1.8044444],
…,
[-1.8044444, -1.8044444, -1.8044444, …, -1.8044444,
-1.8044444, -1.8044444],
[-1.8044444, -1.8044444, -1.8044444, …, -1.8044444,
-1.8044444, -1.8044444],
[-1.8044444, -1.8044444, -1.8044444, …, -1.8044444,
-1.8044444, -1.8044444]]], dtype=float32)
将上面的过程整理成一个get_img_data函数。
def get_img_data(record, size=640):img, gt_boxes, gt_labels, scales = get_img_data_from_file(record)img, gt_boxes, gt_labels = image_augment(img, gt_boxes, gt_labels, size)mean = [0.485, 0.456, 0.406]std = [0.229, 0.224, 0.225]mean = np.array(mean).reshape((1, 1, -1))std = np.array(std).reshape((1, 1, -1))img = (img / 255.0 - mean) / stdimg = img.astype('float32').transpose((2, 0, 1))return img, gt_boxes, gt_labels, scales
TRAINDIR = '/home/aistudio/work/insects/train'
TESTDIR = '/home/aistudio/work/insects/test'
VALIDDIR = '/home/aistudio/work/insects/val'
cname2cid = get_insect_names()
records = get_annotations(cname2cid, TRAINDIR)record = records[0]
img, gt_boxes, gt_labels, scales = get_img_data(record, size=480)
img.shape
(3, 480, 480)
gt_boxes.shape
(50, 4)
gt_labels
array([0, 4, 0, 0, 0, 5, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 1], dtype=int32)
scales
(1220.0, 1220.0)
使用飞桨高层API快速实现数据增强
上述代码中,我们使用numpy实现了多种数据增强方式。同时飞桨也提供了拿来即用的数据增强方法,详细可查阅paddle.vision.transforms模块,transforms模块中提供了数十种数据增强方式,包括亮度增强(adjust_brightness),对比度增强(adjust_contrast),随机裁剪(RandomCrop)等等。更多的关于高层API的使用方法,请登录飞桨官网。
paddle.vision.transforms模块中的数据增强使用方式如下:
#对图像随机裁剪
# 从paddle.vision.transforms模块中import随机剪切的API RandomCrop
from paddle.vision.transforms import RandomCrop# RandomCrop是一个python类,需要事先声明
#RandomCrop还需要传入剪切的形状,这里设置为640
transform = RandomCrop(640)
# 将图像转换为PIL.Image格式
srcimg = Image.fromarray(np.array(srcimg))
# 调用声明好的API实现随机剪切
img_res = transform(srcimg)
# 可视化结果
visualize(srcimg, np.array(img_res))
![]()
同样的方法,可以用飞桨高层API实现亮度增强,如下代码所示:
from paddle.vision.transforms import BrightnessTransform# BrightnessTransform是一个python类,需要事先声明
transform = BrightnessTransform(0.4)
# 将图像转换为PIL.Image格式
srcimg = Image.fromarray(np.array(srcimg))
# 调用声明好的API实现随机剪切
img_res = transform(srcimg)
# 可视化结果
visualize(srcimg, np.array(img_res))
![]()
批量数据读取与加速
上面的程序展示了如何读取一张图片的数据并加速,下面的代码实现了批量数据读取。
# 获取一个批次内样本随机缩放的尺寸
def get_img_size(mode):if (mode == 'train') or (mode == 'valid'):inds = np.array([0,1,2,3,4,5,6,7,8,9])ii = np.random.choice(inds)img_size = 320 + ii * 32else:img_size = 608return img_size# 将 list形式的batch数据 转化成多个array构成的tuple
def make_array(batch_data):img_array = np.array([item[0] for item in batch_data], dtype = 'float32')gt_box_array = np.array([item[1] for item in batch_data], dtype = 'float32')gt_labels_array = np.array([item[2] for item in batch_data], dtype = 'int32')img_scale = np.array([item[3] for item in batch_data], dtype='int32')return img_array, gt_box_array, gt_labels_array, img_scale
由于数据预处理耗时较长,可能会成为网络训练速度的瓶颈,所以需要对预处理部分进行优化。通过使用飞桨提供的paddle.io.DataLoader API中的num_workers参数设置进程数量,实现多进程读取数据,具体实现代码如下。
import paddle# 定义数据读取类,继承Paddle.io.Dataset
class TrainDataset(paddle.io.Dataset):def __init__(self, datadir, mode='train'):self.datadir = datadircname2cid = get_insect_names()self.records = get_annotations(cname2cid, datadir)self.img_size = 640 #get_img_size(mode)def __getitem__(self, idx):record = self.records[idx]# print("print: ", record)img, gt_bbox, gt_labels, im_shape = get_img_data(record, size=self.img_size)return img, gt_bbox, gt_labels, np.array(im_shape)def __len__(self):return len(self.records)# 创建数据读取类
train_dataset = TrainDataset(TRAINDIR, mode='train')# 使用paddle.io.DataLoader创建数据读取器,并设置batchsize,进程数量num_workers等参数
train_loader = paddle.io.DataLoader(train_dataset, batch_size=2, shuffle=True, num_workers=2, drop_last=True)
d = paddle.io.DataLoader(train_dataset, batch_size=2, shuffle=True, num_workers=1, drop_last=True)
img, gt_boxes, gt_labels, im_shape = next(d())
img.shape, gt_boxes.shape, gt_labels.shape, im_shape.shape
([2, 3, 640, 640], [2, 50, 4], [2, 50], [2, 2])
至此,我们完成了如何查看数据集中的数据、提取数据标注信息、从文件读取图像和标注数据、图像增广、批量读取和加速等过程,通过paddle.io.Dataset可以返回img, gt_boxes, gt_labels, im_shape等数据,接下来就可以将它们输入到神经网络,应用到具体算法上了。
在开始具体的算法讲解之前,先补充一下读取测试数据的代码。测试数据没有标注信息,也不需要做图像增广,代码如下所示。
import os
# 将 list形式的batch数据 转化成多个array构成的tuple
def make_test_array(batch_data):img_name_array = np.array([item[0] for item in batch_data])img_data_array = np.array([item[1] for item in batch_data], dtype = 'float32')img_scale_array = np.array([item[2] for item in batch_data], dtype='int32')return img_name_array, img_data_array, img_scale_array# 测试数据读取
def test_data_loader(datadir, batch_size= 10, test_image_size=608, mode='test'):"""加载测试用的图片,测试数据没有groundtruth标签"""image_names = os.listdir(datadir)def reader():batch_data = []img_size = test_image_sizefor image_name in image_names:file_path = os.path.join(datadir, image_name)img = cv2.imread(file_path)img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)H = img.shape[0]W = img.shape[1]img = cv2.resize(img, (img_size, img_size))mean = [0.485, 0.456, 0.406]std = [0.229, 0.224, 0.225]mean = np.array(mean).reshape((1, 1, -1))std = np.array(std).reshape((1, 1, -1))out_img = (img / 255.0 - mean) / stdout_img = out_img.astype('float32').transpose((2, 0, 1))img = out_img #np.transpose(out_img, (2,0,1))im_shape = [H, W]batch_data.append((image_name.split('.')[0], img, im_shape))if len(batch_data) == batch_size:yield make_test_array(batch_data)batch_data = []if len(batch_data) > 0:yield make_test_array(batch_data)return reader
单阶段目标检测模型YOLOv3
R-CNN系列算法需要先产生候选区域,再对候选区域做分类和位置坐标的预测,这类算法被称为两阶段目标检测算法。近几年,很多研究人员相继提出一系列单阶段的检测算法,只需要一个网络即可同时产生候选区域并预测出物体的类别和位置坐标。
与R-CNN系列算法不同,YOLOv3使用单个网络结构,在产生候选区域的同时即可预测出物体类别和位置,不需要分成两阶段来完成检测任务。另外,YOLOv3算法产生的预测框数目比Faster R-CNN少很多。Faster R-CNN中每个真实框可能对应多个标签为正的候选区域,而YOLOv3里面每个真实框只对应一个正的候选区域。这些特性使得YOLOv3算法具有更快的速度,能到达实时响应的水平。
Joseph Redmon等人在2015年提出YOLO(You Only Look Once,YOLO)算法,通常也被称为YOLOv1;2016年,他们对算法进行改进,又提出YOLOv2版本;2018年发展出YOLOv3版本。
YOLOv3模型设计思想
YOLOv3算法的基本思想可以分成两部分:
- 按一定规则在图片上产生一系列的候选区域,然后根据这些候选区域与图片上物体真实框之间的位置关系对候选区域进行标注。跟真实框足够接近的那些候选区域会被标注为正样本,同时将真实框的位置作为正样本的位置目标。偏离真实框较大的那些候选区域则会被标注为负样本,负样本不需要预测位置或者类别。
- 使用卷积神经网络提取图片特征并对候选区域的位置和类别进行预测。这样每个预测框就可以看成是一个样本,根据真实框相对它的位置和类别进行了标注而获得标签值,通过网络模型预测其位置和类别,将网络预测值和标签值进行比较,就可以建立起损失函数。
YOLOv3算法训练过程的流程图如 图8 所示:
图8:YOLOv3算法训练流程图

- 图8 左边是输入图片,上半部分所示的过程是使用卷积神经网络对图片提取特征,随着网络不断向前传播,特征图的尺寸越来越小,每个像素点会代表更加抽象的特征模式,直到输出特征图,其尺寸减小为原图的 1 32 \frac{1}{32} 321。
- 图8 下半部分描述了生成候选区域的过程,首先将原图划分成多个小方块,每个小方块的大小是 32 × 32 32 \times 32 32×32,然后以每个小方块为中心分别生成一系列锚框,整张图片都会被锚框覆盖到。在每个锚框的基础上产生一个与之对应的预测框,根据锚框和预测框与图片上物体真实框之间的位置关系,对这些预测框进行标注。
- 将上方支路中输出的特征图与下方支路中产生的预测框标签建立关联,创建损失函数,开启端到端的训练过程。
接下来具体介绍流程中各节点的原理和代码实现。
产生候选区域
如何产生候选区域,是检测模型的核心设计方案。目前大多数基于卷积神经网络的模型所采用的方式大体如下:
- 按一定的规则在图片上生成一系列位置固定的锚框,将这些锚框看作是可能的候选区域。
- 对锚框是否包含目标物体进行预测,如果包含目标物体,还需要预测所包含物体的类别,以及预测框相对于锚框位置需要调整的幅度。
生成锚框
将原始图片划分成 m × n m\times n m×n个区域,如下图所示,原始图片高度 H = 640 H=640 H=640, 宽度 W = 480 W=480 W=480,如果我们选择小块区域的尺寸为 32 × 32 32 \times 32 32×32,则 m m m和 n n n分别为:
m = 640 32 = 20 m = \frac{640}{32} = 20 m=32640=20
n = 480 32 = 15 n = \frac{480}{32} = 15 n=32480=15
如 图9 所示,将原始图像分成了20行15列小方块区域。
图9:将图片划分成多个32x32的小方块

YOLOv3算法会在每个区域的中心,生成一系列锚框。为了展示方便,我们先在图中第十行第四列的小方块位置附近画出生成的锚框,如 图10 所示。
注意:
这里为了跟程序中的编号对应,最上面的行号是第0行,最左边的列号是第0列。

图10:在第10行第4列的小方块区域生成3个锚框
图11 展示在每个区域附近都生成3个锚框,很多锚框堆叠在一起可能不太容易看清楚,但过程跟上面类似,只是需要以每个区域的中心点为中心,分别生成3个锚框。
图11:在每个小方块区域生成3个锚框

生成预测框
在前面已经指出,锚框的位置都是固定好的,不可能刚好跟物体边界框重合,需要在锚框的基础上进行位置的微调以生成预测框。预测框相对于锚框会有不同的中心位置和大小,采用什么方式能得到预测框呢?我们先来考虑如何生成其中心位置坐标。
比如上面图中在第10行第4列的小方块区域中心生成的一个锚框,如绿色虚线框所示。以小方格的宽度为单位长度,
此小方块区域左上角的位置坐标是:
c x = 4 c_x = 4 cx=4
c y = 10 c_y = 10 cy=10
此锚框的区域中心坐标是:
c e n t e r _ x = c x + 0.5 = 4.5 center\_x = c_x + 0.5 = 4.5 center_x=cx+0.5=4.5
c e n t e r _ y = c y + 0.5 = 10.5 center\_y = c_y + 0.5 = 10.5 center_y=cy+0.5=10.5
可以通过下面的方式生成预测框的中心坐标:
b x = c x + σ ( t x ) b_x = c_x + \sigma(t_x) bx=cx+σ(tx)
b y = c y + σ ( t y ) b_y = c_y + \sigma(t_y) by=cy+σ(ty)
其中 t x t_x tx和 t y t_y ty为实数, σ ( x ) \sigma(x) σ(x)是我们之前学过的Sigmoid函数,其定义如下:
σ ( x ) = 1 1 + e x p ( − x ) \sigma(x) = \frac{1}{1 + exp(-x)} σ(x)=1+exp(−x)1
由于Sigmoid的函数值在 0 ∼ 1 0 \thicksim 1 0∼1之间,因此由上面公式计算出来的预测框的中心点总是落在第十行第四列的小区域内部。
当 t x = t y = 0 t_x=t_y=0 tx=ty=0时, b x = c x + 0.5 b_x = c_x + 0.5 bx=cx+0.5, b y = c y + 0.5 b_y = c_y + 0.5 by=cy+0.5,预测框中心与锚框中心重合,都是小区域的中心。
锚框的大小是预先设定好的,在模型中可以当作是超参数,下图中画出的锚框尺寸是
p h = 350 p_h = 350 ph=350
p w = 250 p_w = 250 pw=250
通过下面的公式生成预测框的大小:
b h = p h e t h b_h = p_h e^{t_h} bh=pheth
b w = p w e t w b_w = p_w e^{t_w} bw=pwetw
如果 t x = t y = 0 , t h = t w = 0 t_x=t_y=0, t_h=t_w=0 tx=ty=0,th=tw=0,则预测框跟锚框重合。
如果给 t x , t y , t h , t w t_x, t_y, t_h, t_w tx,ty,th,tw随机赋值如下:
t x = 0.2 , t y = 0.3 , t w = 0.1 , t h = − 0.12 t_x = 0.2, t_y = 0.3, t_w = 0.1, t_h = -0.12 tx=0.2,ty=0.3,tw=0.1,th=−0.12
则可以得到预测框的坐标是(154.98, 357.44, 276.29, 310.42),如 图12 中蓝色框所示。
说明:
这里坐标采用 x y w h xywh xywh的格式。

图12:生成预测框
这里我们会问:当 t x , t y , t w , t h t_x, t_y, t_w, t_h tx,ty,tw,th取值为多少的时候,预测框能够跟真实框重合?为了回答问题,只需要将上面预测框坐标中的 b x , b y , b h , b w b_x, b_y, b_h, b_w bx,by,bh,bw设置为真实框的位置,即可求解出 t t t的数值。
令:
σ ( t x ∗ ) + c x = g t x \sigma(t^*_x) + c_x = gt_x σ(tx∗)+cx=gtx
σ ( t y ∗ ) + c y = g t y \sigma(t^*_y) + c_y = gt_y σ(ty∗)+cy=gty
p w e t w ∗ = g t h p_w e^{t^*_w} = gt_h pwetw∗=gth
p h e t h ∗ = g t w p_h e^{t^*_h} = gt_w pheth∗=gtw
可以求解出: ( t x ∗ , t y ∗ , t w ∗ , t h ∗ ) (t^*_x, t^*_y, t^*_w, t^*_h) (tx∗,ty∗,tw∗,th∗)
如果 t t t是网络预测的输出值,将 t ∗ t^* t∗作为目标值,以他们之间的差距作为损失函数,则可以建立起一个回归问题,通过学习网络参数,使得 t t t足够接近 t ∗ t^* t∗,从而能够求解出预测框的位置坐标和大小。
预测框可以看作是在锚框基础上的一个微调,每个锚框会有一个跟它对应的预测框,我们需要确定上面计算式中的 t x , t y , t w , t h t_x, t_y, t_w, t_h tx,ty,tw,th,从而计算出与锚框对应的预测框的位置和形状。
对候选区域进行标注
每个区域可以产生3种不同形状的锚框,每个锚框都是一个可能的候选区域,对这些候选区域我们需要了解如下几件事情:
锚框是否包含物体,这可以看成是一个二分类问题,使用标签objectness来表示。当锚框包含了物体时,objectness=1,表示预测框属于正类;当锚框不包含物体时,设置objectness=0,表示锚框属于负类。
如果锚框包含了物体,那么它对应的预测框的中心位置和大小应该是多少,或者说上面计算式中的 t x , t y , t w , t h t_x, t_y, t_w, t_h tx,ty,tw,th应该是多少,使用location标签。
如果锚框包含了物体,那么具体类别是什么,这里使用变量label来表示其所属类别的标签。
选取任意一个锚框对它进行标注,也就是需要确定其对应的objectness, ( t x , t y , t w , t h ) (t_x, t_y, t_w, t_h) (tx,ty,tw,th)和label,下面将分别讲述如何确定这三个标签的值。
标注锚框是否包含物体
如 图13 所示,这里一共有3个目标,以最左边的人像为例,其真实框是 ( 133.96 , 328.42 , 186.06 , 374.63 ) (133.96, 328.42, 186.06, 374.63) (133.96,328.42,186.06,374.63)。
图13:选出与真实框中心位于同一区域的锚框
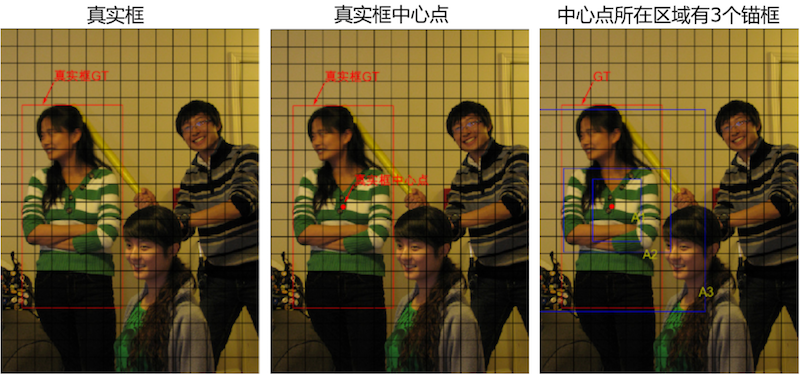
真实框的中心点坐标是:
c e n t e r _ x = 133.96 center\_x = 133.96 center_x=133.96
c e n t e r _ y = 328.42 center\_y = 328.42 center_y=328.42
i = 133.96 / 32 = 4.18625 i = 133.96 / 32 = 4.18625 i=133.96/32=4.18625
j = 328.42 / 32 = 10.263125 j = 328.42 / 32 = 10.263125 j=328.42/32=10.263125
它落在了第10行第4列的小方块内,如图13所示。此小方块区域可以生成3个不同形状的锚框,其在图上的编号和大小分别是 A 1 ( 116 , 90 ) , A 2 ( 156 , 198 ) , A 3 ( 373 , 326 ) A_1(116, 90), A_2(156, 198), A_3(373, 326) A1(116,90),A2(156,198),A3(373,326)。
用这3个不同形状的锚框跟真实框计算IoU,选出IoU最大的锚框。这里为了简化计算,只考虑锚框的形状,不考虑其跟真实框中心之间的偏移,具体计算结果如 图14 所示。
图14:选出与真实框与锚框的IoU
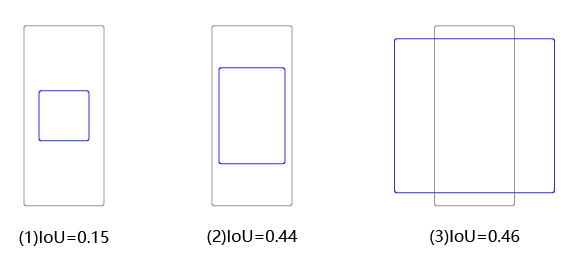
其中跟真实框IoU最大的是锚框 A 3 A_3 A3,形状是 ( 373 , 326 ) (373, 326) (373,326),将它所对应的预测框的objectness标签设置为1,其所包括的物体类别就是真实框里面的物体所属类别。
依次可以找出其他几个真实框对应的IoU最大的锚框,然后将它们的预测框的objectness标签也都设置为1。这里一共有 20 × 15 × 3 = 900 20 \times 15 \times 3 = 900 20×15×3=900个锚框,只有3个预测框会被标注为正。
由于每个真实框只对应一个objectness标签为正的预测框,如果有些预测框跟真实框之间的IoU很大,但并不是最大的那个,那么直接将其objectness标签设置为0当作负样本,可能并不妥当。为了避免这种情况,YOLOv3算法设置了一个IoU阈值iou_threshold,当预测框的objectness不为1,但是其与某个真实框的IoU大于iou_threshold时,就将其objectness标签设置为-1,不参与损失函数的计算。
所有其他的预测框,其objectness标签均设置为0,表示负类。
对于objectness=1的预测框,需要进一步确定其位置和包含物体的具体分类标签,但是对于objectness=0或者-1的预测框,则不用管他们的位置和类别。
标注预测框的位置坐标标签
当锚框objectness=1时,需要确定预测框位置相对于它微调的幅度,也就是锚框的位置标签。
在前面我们已经问过这样一个问题:当 t x , t y , t w , t h t_x, t_y, t_w, t_h tx,ty,tw,th取值为多少的时候,预测框能够跟真实框重合?其做法是将预测框坐标中的 b x , b y , b h , b w b_x, b_y, b_h, b_w bx,by,bh,bw设置为真实框的坐标,即可求解出 t t t的数值。
令:
σ ( t x ∗ ) + c x = g t x \sigma(t^*_x) + c_x = gt_x σ(tx∗)+cx=gtx
σ ( t y ∗ ) + c y = g t y \sigma(t^*_y) + c_y = gt_y σ(ty∗)+cy=gty
p w e t w ∗ = g t w p_w e^{t^*_w} = gt_w pwetw∗=gtw
p h e t h ∗ = g t h p_h e^{t^*_h} = gt_h pheth∗=gth
对于 t x ∗ t_x^* tx∗和 t y ∗ t_y^* ty∗,由于Sigmoid的反函数不好计算,我们直接使用 σ ( t x ∗ ) \sigma(t^*_x) σ(tx∗)和 σ ( t y ∗ ) \sigma(t^*_y) σ(ty∗)作为回归的目标。
d x ∗ = σ ( t x ∗ ) = g t x − c x d_x^* = \sigma(t^*_x) = gt_x - c_x dx∗=σ(tx∗)=gtx−cx
d y ∗ = σ ( t y ∗ ) = g t y − c y d_y^* = \sigma(t^*_y) = gt_y - c_y dy∗=σ(ty∗)=gty−cy
t w ∗ = l o g ( g t w p w ) t^*_w = log(\frac{gt_w}{p_w}) tw∗=log(pwgtw)
t h ∗ = l o g ( g t h p h ) t^*_h = log(\frac{gt_h}{p_h}) th∗=log(phgth)
如果 ( t x , t y , t h , t w ) (t_x, t_y, t_h, t_w) (tx,ty,th,tw)是网络预测的输出值,将 ( d x ∗ , d y ∗ , t w ∗ , t h ∗ ) (d_x^*, d_y^*, t_w^*, t_h^*) (dx∗,dy∗,tw∗,th∗)作为 ( σ ( t x ) , σ ( t y ) , t h , t w ) (\sigma(t_x), \sigma(t_y), t_h, t_w) (σ(tx),σ(ty),th,tw)的目标值,以它们之间的差距作为损失函数,则可以建立起一个回归问题,通过学习网络参数,使得 t t t足够接近 t ∗ t^* t∗,从而能够求解出预测框的位置。
标注锚框包含物体类别的标签
对于objectness=1的锚框,需要确定其具体类别。正如上面所说,objectness标注为1的锚框,会有一个真实框跟它对应,该锚框所属物体类别,即是其所对应的真实框包含的物体类别。这里使用one-hot向量来表示类别标签label。比如一共有10个分类,而真实框里面包含的物体类别是第2类,则label为 ( 0 , 1 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 ) (0,1,0,0,0,0,0,0,0,0) (0,1,0,0,0,0,0,0,0,0)
对上述步骤进行总结,标注的流程如 图15 所示。
图15:标注流程示意图
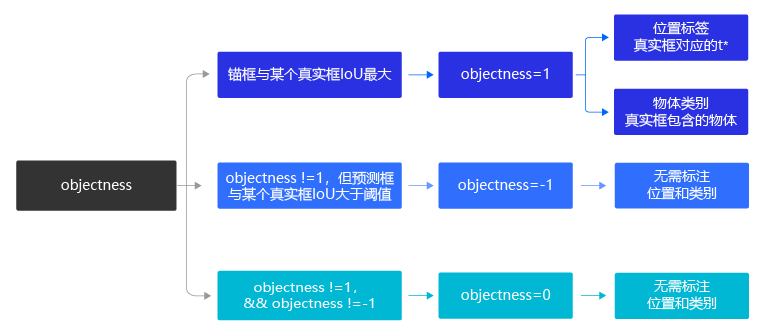
通过这种方式,我们在每个小方块区域都生成了一系列的锚框作为候选区域,并且根据图片上真实物体的位置,标注出了每个候选区域对应的objectness标签、位置需要调整的幅度以及包含的物体所属的类别。位置需要调整的幅度由4个变量描述 ( t x , t y , t w , t h ) (t_x, t_y, t_w, t_h) (tx,ty,tw,th),objectness标签需要用一个变量描述 o b j obj obj,描述所属类别的变量长度等于类别数C。
对于每个锚框,模型需要预测输出 ( t x , t y , t w , t h , P o b j , P 1 , P 2 , . . . , P C ) (t_x, t_y, t_w, t_h, P_{obj}, P_1, P_2,... , P_C) (tx,ty,tw,th,Pobj,P1,P2,...,PC),其中 P o b j P_{obj} Pobj是锚框是否包含物体的概率, P 1 , P 2 , . . . , P C P_1, P_2,... , P_C P1,P2,...,PC则是锚框包含的物体属于每个类别的概率。接下来让我们一起学习如何通过卷积神经网络输出这样的预测值。
标注锚框的具体程序
上面描述了如何对预锚框进行标注,但读者可能仍然对里面的细节不太了解,下面将通过具体的程序完成这一步骤。
# 标注预测框的objectness
def get_objectness_label(img, gt_boxes, gt_labels, iou_threshold = 0.7,anchors = [116, 90, 156, 198, 373, 326],num_classes=7, downsample=32):"""img 是输入的图像数据,形状是[N, C, H, W]gt_boxes,真实框,维度是[N, 50, 4],其中50是真实框数目的上限,当图片中真实框不足50个时,不足部分的坐标全为0真实框坐标格式是xywh,这里使用相对值gt_labels,真实框所属类别,维度是[N, 50]iou_threshold,当预测框与真实框的iou大于iou_threshold时不将其看作是负样本anchors,锚框可选的尺寸anchor_masks,通过与anchors一起确定本层级的特征图应该选用多大尺寸的锚框num_classes,类别数目downsample,特征图相对于输入网络的图片尺寸变化的比例"""img_shape = img.shapebatchsize = img_shape[0]num_anchors = len(anchors) // 2input_h = img_shape[2]input_w = img_shape[3]# 将输入图片划分成num_rows x num_cols个小方块区域,每个小方块的边长是 downsample# 计算一共有多少行小方块num_rows = input_h // downsample# 计算一共有多少列小方块num_cols = input_w // downsamplelabel_objectness = np.zeros([batchsize, num_anchors, num_rows, num_cols])label_classification = np.zeros([batchsize, num_anchors, num_classes, num_rows, num_cols])label_location = np.zeros([batchsize, num_anchors, 4, num_rows, num_cols])scale_location = np.ones([batchsize, num_anchors, num_rows, num_cols])# 对batchsize数目的这一批次的样本进行循环,依次处理每张图片,其中的坐标都为除以总长度后的坐标for n in range(batchsize):# 对图片上的真实框进行循环,依次找出跟真实框形状最匹配的锚框for n_gt in range(len(gt_boxes[n])):gt = gt_boxes[n][n_gt]gt_cls = gt_labels[n][n_gt]gt_center_x = gt[0]gt_center_y = gt[1]gt_width = gt[2]gt_height = gt[3]if (gt_width < 1e-3) or (gt_height < 1e-3):continuei = int(gt_center_y * num_rows) #相当于gt_center_y * input_w // downsamplej = int(gt_center_x * num_cols)ious = []for ka in range(num_anchors):bbox1 = [0., 0., float(gt_width), float(gt_height)]anchor_w = anchors[ka * 2]anchor_h = anchors[ka * 2 + 1]bbox2 = [0., 0., anchor_w/float(input_w), anchor_h/float(input_h)]# 计算iouiou = box_iou_xywh(bbox1, bbox2)ious.append(iou)ious = np.array(ious)inds = np.argsort(ious)k = inds[-1]label_objectness[n, k, i, j] = 1c = gt_clslabel_classification[n, k, c, i, j] = 1.# for those prediction bbox with objectness =1, set label of locationdx_label = gt_center_x * num_cols - jdy_label = gt_center_y * num_rows - idw_label = np.log(gt_width * input_w / anchors[k*2])dh_label = np.log(gt_height * input_h / anchors[k*2 + 1])label_location[n, k, 0, i, j] = dx_labellabel_location[n, k, 1, i, j] = dy_labellabel_location[n, k, 2, i, j] = dw_labellabel_location[n, k, 3, i, j] = dh_label# scale_location用来调节不同尺寸的锚框对损失函数的贡献,作为加权系数和位置损失函数相乘scale_location[n, k, i, j] = 2.0 - gt_width * gt_height# 目前根据每张图片上所有出现过的gt box,都标注出了objectness为正的预测框,剩下的预测框则默认objectness为0# 对于objectness为1的预测框,标出了他们所包含的物体类别,以及位置回归的目标return label_objectness.astype('float32'), label_location.astype('float32'), label_classification.astype('float32'), \scale_location.astype('float32')
# 计算IoU,矩形框的坐标形式为xywh
def box_iou_xywh(box1, box2):x1min, y1min = box1[0] - box1[2]/2.0, box1[1] - box1[3]/2.0x1max, y1max = box1[0] + box1[2]/2.0, box1[1] + box1[3]/2.0s1 = box1[2] * box1[3]x2min, y2min = box2[0] - box2[2]/2.0, box2[1] - box2[3]/2.0x2max, y2max = box2[0] + box2[2]/2.0, box2[1] + box2[3]/2.0s2 = box2[2] * box2[3]xmin = np.maximum(x1min, x2min)ymin = np.maximum(y1min, y2min)xmax = np.minimum(x1max, x2max)ymax = np.minimum(y1max, y2max)inter_h = np.maximum(ymax - ymin, 0.)inter_w = np.maximum(xmax - xmin, 0.)intersection = inter_h * inter_wunion = s1 + s2 - intersectioniou = intersection / unionreturn iou
# 读取数据
import paddle
reader = paddle.io.DataLoader(train_dataset, batch_size=2, shuffle=True, num_workers=1, drop_last=True)
img, gt_boxes, gt_labels, im_shape = next(reader())
img, gt_boxes, gt_labels, im_shape = img.numpy(), gt_boxes.numpy(), gt_labels.numpy(), im_shape.numpy()# 计算出锚框对应的标签
label_objectness, label_location, label_classification, scale_location = get_objectness_label(img,gt_boxes, gt_labels, iou_threshold = 0.7,anchors = [116, 90, 156, 198, 373, 326],num_classes=7, downsample=32)img.shape, gt_boxes.shape, gt_labels.shape, im_shape.shape
((2, 3, 640, 640), (2, 50, 4), (2, 50), (2, 2))
label_objectness.shape, label_location.shape, label_classification.shape, scale_location.shape
((2, 3, 20, 20), (2, 3, 4, 20, 20), (2, 3, 7, 20, 20), (2, 3, 20, 20))
上面的程序实现了对锚框进行标注,对于每个真实框,选出了与它形状最匹配的锚框,将其objectness标注为1,并且将 [ d x ∗ , d y ∗ , t h ∗ , t w ∗ ] [d_x^*, d_y^*, t_h^*, t_w^*] [dx∗,dy∗,th∗,tw∗]作为正样本位置的标签,真实框包含的物体类别作为锚框的类别。而其余的锚框,objectness将被标注为0,无需标注出位置和类别的标签。
- 注意:这里还遗留一个小问题,前面我们说了对于与真实框IoU较大的那些锚框,需要将其objectness标注为-1,不参与损失函数的计算。我们先将这个问题放一放,等到后面建立损失函数的时候再补上。
卷积神经网络提取特征
在上一节图像分类的课程中,我们已经学习过了通过卷积神经网络提取图像特征。通过连续使用多层卷积和池化等操作,能得到语义含义更加丰富的特征图。在检测问题中,也使用卷积神经网络逐层提取图像特征,通过最终的输出特征图来表征物体位置和类别等信息。
YOLOv3算法使用的骨干网络是Darknet53。Darknet53网络的具体结构如 图16 所示,在ImageNet图像分类任务上取得了很好的成绩。在检测任务中,将图中C0后面的平均池化、全连接层和Softmax去掉,保留从输入到C0部分的网络结构,作为检测模型的基础网络结构,也称为骨干网络。YOLOv3模型会在骨干网络的基础上,再添加检测相关的网络模块。
图16:Darknet53网络结构
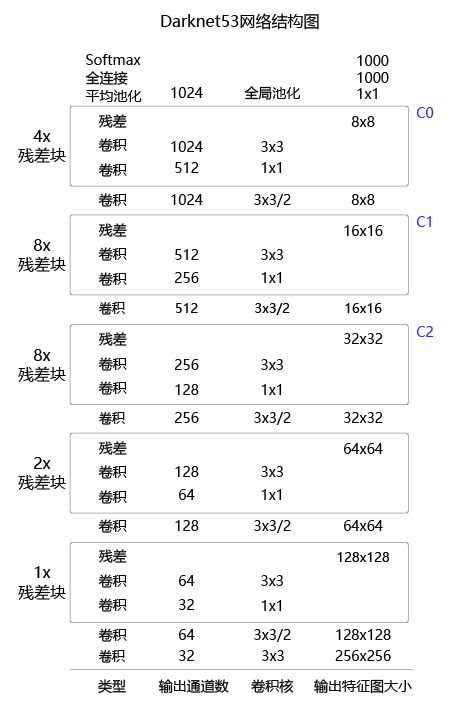
下面的程序是Darknet53骨干网络的实现代码,这里将上图中C0、C1、C2所表示的输出数据取出,并查看它们的形状分别是, C 0 [ 1 , 1024 , 20 , 20 ] C0 [1, 1024, 20, 20] C0[1,1024,20,20], C 1 [ 1 , 512 , 40 , 40 ] C1 [1, 512, 40, 40] C1[1,512,40,40], C 2 [ 1 , 256 , 80 , 80 ] C2 [1, 256, 80, 80] C2[1,256,80,80]。
- 名词解释:特征图的步幅(stride)
在提取特征的过程中通常会使用步幅大于1的卷积或者池化,导致后面的特征图尺寸越来越小,特征图的步幅等于输入图片尺寸除以特征图尺寸。例如:C0的尺寸是 20 × 20 20\times20 20×20,原图尺寸是 640 × 640 640\times640 640×640,则C0的步幅是 640 20 = 32 \frac{640}{20}=32 20640=32。同理,C1的步幅是16,C2的步幅是8。
import paddle
import paddle.nn.functional as F
import numpy as npclass ConvBNLayer(paddle.nn.Layer):def __init__(self, ch_in, ch_out, kernel_size=3, stride=1, groups=1,padding=0, act="leaky"):super(ConvBNLayer, self).__init__()self.conv = paddle.nn.Conv2D(in_channels=ch_in,out_channels=ch_out,kernel_size=kernel_size,stride=stride,padding=padding,groups=groups,weight_attr=paddle.ParamAttr(initializer=paddle.nn.initializer.Normal(0., 0.02)),bias_attr=False)self.batch_norm = paddle.nn.BatchNorm2D(num_features=ch_out,weight_attr=paddle.ParamAttr(initializer=paddle.nn.initializer.Normal(0., 0.02),regularizer=paddle.regularizer.L2Decay(0.)),bias_attr=paddle.ParamAttr(initializer=paddle.nn.initializer.Constant(0.0),regularizer=paddle.regularizer.L2Decay(0.)))self.act = actdef forward(self, inputs):out = self.conv(inputs)out = self.batch_norm(out)if self.act == 'leaky':out = F.leaky_relu(x=out, negative_slope=0.1)return outclass DownSample(paddle.nn.Layer):# 下采样,图片尺寸减半,具体实现方式是使用stirde=2的卷积def __init__(self,ch_in,ch_out,kernel_size=3,stride=2,padding=1):super(DownSample, self).__init__()self.conv_bn_layer = ConvBNLayer(ch_in=ch_in,ch_out=ch_out,kernel_size=kernel_size,stride=stride,padding=padding)self.ch_out = ch_outdef forward(self, inputs):out = self.conv_bn_layer(inputs)return outclass BasicBlock(paddle.nn.Layer):"""基本残差块的定义,输入x经过两层卷积,然后接第二层卷积的输出和输入x相加"""def __init__(self, ch_in, ch_out):super(BasicBlock, self).__init__()self.conv1 = ConvBNLayer(ch_in=ch_in,ch_out=ch_out,kernel_size=1,stride=1,padding=0)self.conv2 = ConvBNLayer(ch_in=ch_out,ch_out=ch_out*2,kernel_size=3,stride=1,padding=1)def forward(self, inputs):conv1 = self.conv1(inputs)conv2 = self.conv2(conv1)out = paddle.add(x=inputs, y=conv2)return outclass LayerWarp(paddle.nn.Layer):"""添加多层残差块,组成Darknet53网络的一个层级"""def __init__(self, ch_in, ch_out, count, is_test=True):super(LayerWarp,self).__init__()self.basicblock0 = BasicBlock(ch_in,ch_out)self.res_out_list = []for i in range(1, count):res_out = self.add_sublayer("basic_block_%d" % (i), # 使用add_sublayer添加子层BasicBlock(ch_out*2,ch_out))self.res_out_list.append(res_out)def forward(self,inputs):y = self.basicblock0(inputs)for basic_block_i in self.res_out_list:y = basic_block_i(y)return y# DarkNet 每组残差块的个数,来自DarkNet的网络结构图
DarkNet_cfg = {53: ([1, 2, 8, 8, 4])}class DarkNet53_conv_body(paddle.nn.Layer):def __init__(self):super(DarkNet53_conv_body, self).__init__()self.stages = DarkNet_cfg[53]self.stages = self.stages[0:5]# 第一层卷积self.conv0 = ConvBNLayer(ch_in=3,ch_out=32,kernel_size=3,stride=1,padding=1)# 下采样,使用stride=2的卷积来实现self.downsample0 = DownSample(ch_in=32,ch_out=32 * 2)# 添加各个层级的实现self.darknet53_conv_block_list = []self.downsample_list = []for i, stage in enumerate(self.stages):conv_block = self.add_sublayer("stage_%d" % (i),LayerWarp(32*(2**(i+1)),32*(2**i),stage))self.darknet53_conv_block_list.append(conv_block)# 两个层级之间使用DownSample将尺寸减半for i in range(len(self.stages) - 1):downsample = self.add_sublayer("stage_%d_downsample" % i,DownSample(ch_in=32*(2**(i+1)),ch_out=32*(2**(i+2))))self.downsample_list.append(downsample)def forward(self,inputs):out = self.conv0(inputs)#print("conv1:",out.numpy())out = self.downsample0(out)#print("dy:",out.numpy())blocks = []for i, conv_block_i in enumerate(self.darknet53_conv_block_list): #依次将各个层级作用在输入上面out = conv_block_i(out)blocks.append(out)if i < len(self.stages) - 1:out = self.downsample_list[i](out)return blocks[-1:-4:-1] # 将C0, C1, C2作为返回值# 查看Darknet53网络输出特征图
import numpy as np
backbone = DarkNet53_conv_body()
x = np.random.randn(1, 3, 640, 640).astype('float32')
x = paddle.to_tensor(x)
C0, C1, C2 = backbone(x)
print(C0.shape, C1.shape, C2.shape)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:648: UserWarning: When training, we now always track global mean and variance.
“When training, we now always track global mean and variance.”)
[1, 1024, 20, 20] [1, 512, 40, 40] [1, 256, 80, 80]
上面这段示例代码,指定输入数据的形状是 ( 1 , 3 , 640 , 640 ) (1, 3, 640, 640) (1,3,640,640),则3个层级的输出特征图的形状分别是 C 0 ( 1 , 1024 , 20 , 20 ) C0 (1, 1024, 20, 20) C0(1,1024,20,20), C 1 ( 1 , 512 , 40 , 40 ) C1 (1, 512, 40, 40) C1(1,512,40,40)和 C 2 ( 1 , 256 , 80 , 80 ) C2 (1, 256, 80, 80) C2(1,256,80,80)。
根据输出特征图计算预测框位置和类别
YOLOv3中对每个预测框计算逻辑如下:
预测框是否包含物体。也可理解为objectness=1的概率是多少,可以用网络输出一个实数 x x x,可以用 S i g m o i d ( x ) Sigmoid(x) Sigmoid(x)表示objectness为正的概率 P o b j P_{obj} Pobj
预测物体位置和形状。物体位置和形状 t x , t y , t w , t h t_x, t_y, t_w, t_h tx,ty,tw,th可以用网络输出4个实数来表示 t x , t y , t w , t h t_x, t_y, t_w, t_h tx,ty,tw,th
预测物体类别。预测图像中物体的具体类别是什么,或者说其属于每个类别的概率分别是多少。总的类别数为C,需要预测物体属于每个类别的概率 ( P 1 , P 2 , . . . , P C ) (P_1, P_2, ..., P_C) (P1,P2,...,PC),可以用网络输出C个实数 ( x 1 , x 2 , . . . , x C ) (x_1, x_2, ..., x_C) (x1,x2,...,xC),对每个实数分别求Sigmoid函数,让 P i = S i g m o i d ( x i ) P_i = Sigmoid(x_i) Pi=Sigmoid(xi),则可以表示出物体属于每个类别的概率。
对于一个预测框,网络需要输出 ( 5 + C ) (5 + C) (5+C)个实数来表征它是否包含物体、位置和形状尺寸以及属于每个类别的概率。
由于我们在每个小方块区域都生成了K个预测框,则所有预测框一共需要网络输出的预测值数目是:
[ K ( 5 + C ) ] × m × n [K(5 + C)] \times m \times n [K(5+C)]×m×n
还有更重要的一点是网络输出必须要能区分出小方块区域的位置来,不能直接将特征图连接一个输出大小为 [ K ( 5 + C ) ] × m × n [K(5 + C)] \times m \times n [K(5+C)]×m×n的全连接层。
建立输出特征图与预测框之间的关联
现在观察特征图,经过多次卷积核池化之后,其步幅stride=32, 640 × 480 640 \times 480 640×480大小的输入图片变成了 20 × 15 20\times15 20×15的特征图;而小方块区域的数目正好是 20 × 15 20\times15 20×15,也就是说可以让特征图上每个像素点分别跟原图上一个小方块区域对应。这也是为什么我们最开始将小方块区域的尺寸设置为32的原因,这样可以巧妙的将小方块区域跟特征图上的像素点对应起来,解决了空间位置的对应关系。
图17:特征图C0与小方块区域形状对比
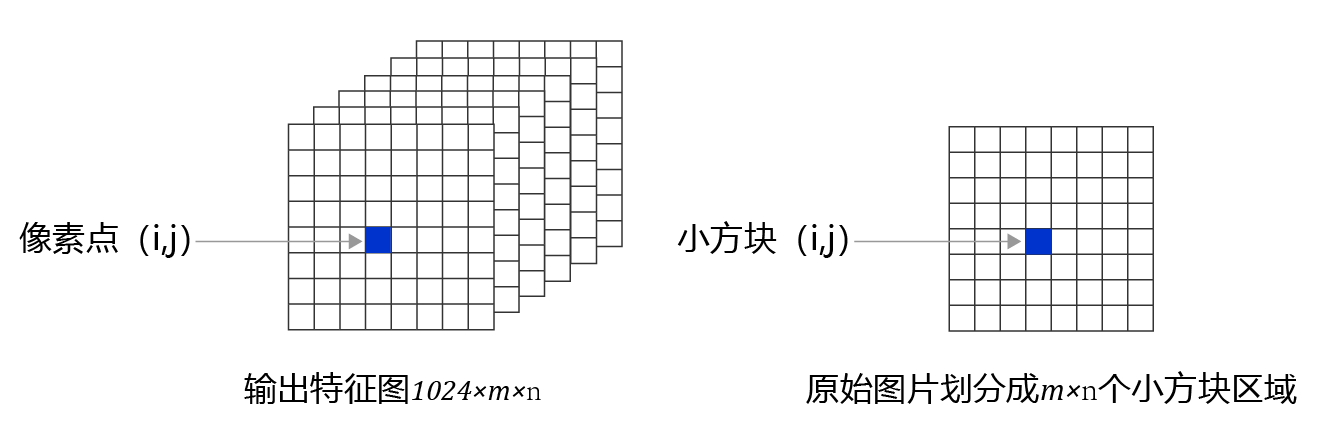
下面需要将像素点 ( i , j ) (i,j) (i,j)与第i行第j列的小方块区域所需要的预测值关联起来,每个小方块区域产生K个预测框,每个预测框需要 ( 5 + C ) (5 + C) (5+C)个实数预测值,则每个像素点相对应的要有 K ( 5 + C ) K(5 + C) K(5+C)个实数。为了解决这一问题,对特征图进行多次卷积,并将最终的输出通道数设置为 K ( 5 + C ) K(5 + C) K(5+C),即可将生成的特征图与每个预测框所需要的预测值巧妙的对应起来。当然,这种对应是为了将骨干网络提取的特征对接输出层来形成Loss。实际中,这几个尺寸可以随着任务数据分布的不同而调整,只要保证特征图输出尺寸(控制卷积核和下采样)和输出层尺寸(控制小方块区域的大小)相同即可。
骨干网络的输出特征图是C0,下面的程序是对C0进行多次卷积以得到跟预测框相关的特征图P0。
class YoloDetectionBlock(paddle.nn.Layer):# define YOLOv3 detection head# 使用多层卷积和BN提取特征def __init__(self,ch_in,ch_out,is_test=True):super(YoloDetectionBlock, self).__init__()assert ch_out % 2 == 0, \"channel {} cannot be divided by 2".format(ch_out)self.conv0 = ConvBNLayer(ch_in=ch_in,ch_out=ch_out,kernel_size=1,stride=1,padding=0)self.conv1 = ConvBNLayer(ch_in=ch_out,ch_out=ch_out*2,kernel_size=3,stride=1,padding=1)self.conv2 = ConvBNLayer(ch_in=ch_out*2,ch_out=ch_out,kernel_size=1,stride=1,padding=0)self.conv3 = ConvBNLayer(ch_in=ch_out,ch_out=ch_out*2,kernel_size=3,stride=1,padding=1)self.route = ConvBNLayer(ch_in=ch_out*2,ch_out=ch_out,kernel_size=1,stride=1,padding=0)self.tip = ConvBNLayer(ch_in=ch_out,ch_out=ch_out*2,kernel_size=3,stride=1,padding=1)def forward(self, inputs):out = self.conv0(inputs)out = self.conv1(out)out = self.conv2(out)out = self.conv3(out)route = self.route(out)tip = self.tip(route)return route, tipNUM_ANCHORS = 3
NUM_CLASSES = 7
num_filters=NUM_ANCHORS * (NUM_CLASSES + 5)backbone = DarkNet53_conv_body()
detection = YoloDetectionBlock(ch_in=1024, ch_out=512)
conv2d_pred = paddle.nn.Conv2D(in_channels=1024, out_channels=num_filters, kernel_size=1)x = np.random.randn(1, 3, 640, 640).astype('float32')
x = paddle.to_tensor(x)
C0, C1, C2 = backbone(x)
route, tip = detection(C0)
P0 = conv2d_pred(tip)print(P0.shape)
[1, 36, 20, 20]
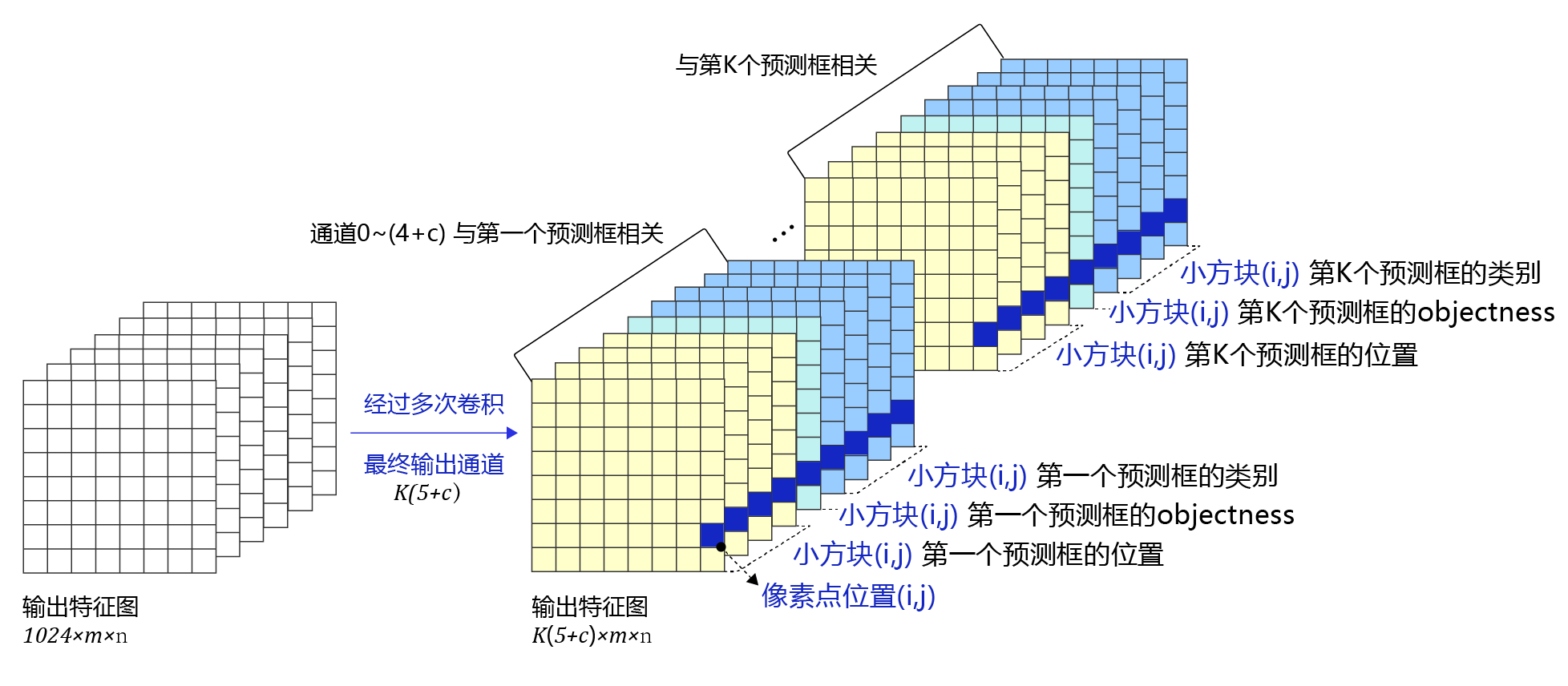
如上面的代码所示,可以由特征图C0生成特征图P0,P0的形状是 [ 1 , 36 , 20 , 20 ] [1, 36, 20, 20] [1,36,20,20]。每个小方块区域生成的锚框或者预测框的数量是3,物体类别数目是7,每个区域需要的预测值个数是 3 × ( 5 + 7 ) = 36 3 \times (5 + 7) = 36 3×(5+7)=36,正好等于P0的输出通道数。
将 P 0 [ t , 0 : 12 , i , j ] P0[t, 0:12, i, j] P0[t,0:12,i,j]与输入的第t张图片上小方块区域 ( i , j ) (i, j) (i,j)第1个预测框所需要的12个预测值对应, P 0 [ t , 12 : 24 , i , j ] P0[t, 12:24, i, j] P0[t,12:24,i,j]与输入的第t张图片上小方块区域 ( i , j ) (i, j) (i,j)第2个预测框所需要的12个预测值对应, P 0 [ t , 24 : 36 , i , j ] P0[t, 24:36, i, j] P0[t,24:36,i,j]与输入的第t张图片上小方块区域 ( i , j ) (i, j) (i,j)第3个预测框所需要的12个预测值对应。
P 0 [ t , 0 : 4 , i , j ] P0[t, 0:4, i, j] P0[t,0:4,i,j]与输入的第t张图片上小方块区域 ( i , j ) (i, j) (i,j)第1个预测框的位置对应, P 0 [ t , 4 , i , j ] P0[t, 4, i, j] P0[t,4,i,j]与输入的第t张图片上小方块区域 ( i , j ) (i, j) (i,j)第1个预测框的objectness对应, P 0 [ t , 5 : 12 , i , j ] P0[t, 5:12, i, j] P0[t,5:12,i,j]与输入的第t张图片上小方块区域 ( i , j ) (i, j) (i,j)第1个预测框的类别对应。
如 图18 所示,通过这种方式可以巧妙的将网络输出特征图,与每个小方块区域生成的预测框对应起来了。
图18:特征图P0与候选区域的关联
计算预测框是否包含物体的概率
根据前面的分析, P 0 [ t , 4 , i , j ] P0[t, 4, i, j] P0[t,4,i,j]与输入的第t张图片上小方块区域 ( i , j ) (i, j) (i,j)第1个预测框的objectness对应, P 0 [ t , 4 + 12 , i , j ] P0[t, 4+12, i, j] P0[t,4+12,i,j]与第2个预测框的objectness对应,…,则可以使用下面的程序将objectness相关的预测取出,并使用paddle.nn.functional.sigmoid计算输出概率。
NUM_ANCHORS = 3
NUM_CLASSES = 7
num_filters=NUM_ANCHORS * (NUM_CLASSES + 5)backbone = DarkNet53_conv_body()
detection = YoloDetectionBlock(ch_in=1024, ch_out=512)
conv2d_pred = paddle.nn.Conv2D(in_channels=1024, out_channels=num_filters, kernel_size=1)x = np.random.randn(1, 3, 640, 640).astype('float32')
x = paddle.to_tensor(x)
C0, C1, C2 = backbone(x)
route, tip = detection(C0)
P0 = conv2d_pred(tip)reshaped_p0 = paddle.reshape(P0, [-1, NUM_ANCHORS, NUM_CLASSES + 5, P0.shape[2], P0.shape[3]])
pred_objectness = reshaped_p0[:, :, 4, :, :]
pred_objectness_probability = F.sigmoid(pred_objectness)
print(pred_objectness.shape, pred_objectness_probability.shape)
[1, 3, 20, 20] [1, 3, 20, 20]
上面的输出程序显示,预测框是否包含物体的概率pred_objectness_probability,其数据形状是[1, 3, 20, 20],与我们上面提到的预测框个数一致,数据大小在0~1之间,表示预测框为正样本的概率。
计算预测框位置坐标
P 0 [ t , 0 : 4 , i , j ] P0[t, 0:4, i, j] P0[t,0:4,i,j]与输入的第 t t t张图片上小方块区域 ( i , j ) (i, j) (i,j)第1个预测框的位置对应, P 0 [ t , 12 : 16 , i , j ] P0[t, 12:16, i, j] P0[t,12:16,i,j]与第2个预测框的位置对应,依此类推,则使用下面的程序可以从 P 0 P0 P0中取出跟预测框位置相关的预测值。
NUM_ANCHORS = 3
NUM_CLASSES = 7
num_filters=NUM_ANCHORS * (NUM_CLASSES + 5)backbone = DarkNet53_conv_body()
detection = YoloDetectionBlock(ch_in=1024, ch_out=512)
conv2d_pred = paddle.nn.Conv2D(in_channels=1024, out_channels=num_filters, kernel_size=1)x = np.random.randn(1, 3, 640, 640).astype('float32')
x = paddle.to_tensor(x)
C0, C1, C2 = backbone(x)
route, tip = detection(C0)
P0 = conv2d_pred(tip)reshaped_p0 = paddle.reshape(P0, [-1, NUM_ANCHORS, NUM_CLASSES + 5, P0.shape[2], P0.shape[3]])
pred_objectness = reshaped_p0[:, :, 4, :, :]
pred_objectness_probability = F.sigmoid(pred_objectness)pred_location = reshaped_p0[:, :, 0:4, :, :]
print(pred_location.shape)[1, 3, 4, 20, 20]
网络输出值是 ( t x , t y , t w , t h ) (t_x, t_y, t_w, t_h) (tx,ty,tw,th),还需要将其转化为 ( x 1 , y 1 , x 2 , y 2 ) (x_1, y_1, x_2, y_2) (x1,y1,x2,y2)这种形式的坐标表示。使用飞桨paddle.vision.ops.yolo_box API可以直接计算出结果,但为了给读者更清楚的展示算法的实现过程,我们使用Numpy来实现这一过程。
# 定义Sigmoid函数
def sigmoid(x):return 1./(1.0 + np.exp(-x))# 将网络特征图输出的[tx, ty, th, tw]转化成预测框的坐标[x1, y1, x2, y2]
def get_yolo_box_xxyy(pred, anchors, num_classes, downsample):"""pred是网络输出特征图转化成的numpy.ndarrayanchors 是一个list。表示锚框的大小,例如 anchors = [116, 90, 156, 198, 373, 326],表示有三个锚框,第一个锚框大小[w, h]是[116, 90],第二个锚框大小是[156, 198],第三个锚框大小是[373, 326]"""batchsize = pred.shape[0]num_rows = pred.shape[-2]num_cols = pred.shape[-1]input_h = num_rows * downsampleinput_w = num_cols * downsamplenum_anchors = len(anchors) // 2# pred的形状是[N, C, H, W],其中C = NUM_ANCHORS * (5 + NUM_CLASSES)# 对pred进行reshapepred = pred.reshape([-1, num_anchors, 5+num_classes, num_rows, num_cols])pred_location = pred[:, :, 0:4, :, :]pred_location = np.transpose(pred_location, (0,3,4,1,2))anchors_this = []for ind in range(num_anchors):anchors_this.append([anchors[ind*2], anchors[ind*2+1]])anchors_this = np.array(anchors_this).astype('float32')# 最终输出数据保存在pred_box中,其形状是[N, H, W, NUM_ANCHORS, 4],# 其中最后一个维度4代表位置的4个坐标pred_box = np.zeros(pred_location.shape)for n in range(batchsize):for i in range(num_rows):for j in range(num_cols):for k in range(num_anchors):pred_box[n, i, j, k, 0] = jpred_box[n, i, j, k, 1] = ipred_box[n, i, j, k, 2] = anchors_this[k][0]pred_box[n, i, j, k, 3] = anchors_this[k][1]# 这里使用相对坐标,pred_box的输出元素数值在0.~1.0之间pred_box[:, :, :, :, 0] = (sigmoid(pred_location[:, :, :, :, 0]) + pred_box[:, :, :, :, 0]) / num_colspred_box[:, :, :, :, 1] = (sigmoid(pred_location[:, :, :, :, 1]) + pred_box[:, :, :, :, 1]) / num_rowspred_box[:, :, :, :, 2] = np.exp(pred_location[:, :, :, :, 2]) * pred_box[:, :, :, :, 2] / input_wpred_box[:, :, :, :, 3] = np.exp(pred_location[:, :, :, :, 3]) * pred_box[:, :, :, :, 3] / input_h# 将坐标从xywh转化成xyxypred_box[:, :, :, :, 0] = pred_box[:, :, :, :, 0] - pred_box[:, :, :, :, 2] / 2.pred_box[:, :, :, :, 1] = pred_box[:, :, :, :, 1] - pred_box[:, :, :, :, 3] / 2.pred_box[:, :, :, :, 2] = pred_box[:, :, :, :, 0] + pred_box[:, :, :, :, 2]pred_box[:, :, :, :, 3] = pred_box[:, :, :, :, 1] + pred_box[:, :, :, :, 3]pred_box = np.clip(pred_box, 0., 1.0)return pred_box通过调用上面定义的get_yolo_box_xxyy函数,可以从 P 0 P0 P0计算出预测框坐标来,具体程序如下:
NUM_ANCHORS = 3
NUM_CLASSES = 7
num_filters=NUM_ANCHORS * (NUM_CLASSES + 5)backbone = DarkNet53_conv_body()
detection = YoloDetectionBlock(ch_in=1024, ch_out=512)
conv2d_pred = paddle.nn.Conv2D(in_channels=1024, out_channels=num_filters, kernel_size=1)x = np.random.randn(1, 3, 640, 640).astype('float32')
x = paddle.to_tensor(x)
C0, C1, C2 = backbone(x)
route, tip = detection(C0)
P0 = conv2d_pred(tip)reshaped_p0 = paddle.reshape(P0, [-1, NUM_ANCHORS, NUM_CLASSES + 5, P0.shape[2], P0.shape[3]])
pred_objectness = reshaped_p0[:, :, 4, :, :]
pred_objectness_probability = F.sigmoid(pred_objectness)pred_location = reshaped_p0[:, :, 0:4, :, :]# anchors包含了预先设定好的锚框尺寸
anchors = [116, 90, 156, 198, 373, 326]
# downsample是特征图P0的步幅
pred_boxes = get_yolo_box_xxyy(P0.numpy(), anchors, num_classes=7, downsample=32) # 由输出特征图P0计算预测框位置坐标
print(pred_boxes.shape)
(1, 20, 20, 3, 4)
上面程序计算出来的pred_boxes的形状是 [ N , H , W , n u m _ a n c h o r s , 4 ] [N, H, W, num\_anchors, 4] [N,H,W,num_anchors,4],坐标格式是 [ x 1 , y 1 , x 2 , y 2 ] [x_1, y_1, x_2, y_2] [x1,y1,x2,y2],数值在0~1之间,表示相对坐标。
计算物体属于每个类别概率
P 0 [ t , 5 : 12 , i , j ] P0[t, 5:12, i, j] P0[t,5:12,i,j]与输入的第 t t t张图片上小方块区域 ( i , j ) (i, j) (i,j)第1个预测框包含物体的类别对应, P 0 [ t , 17 : 24 , i , j ] P0[t, 17:24, i, j] P0[t,17:24,i,j]与第2个预测框的类别对应,依此类推,则使用下面的程序可以从 P 0 P0 P0中取出那些跟预测框类别相关的预测值。
NUM_ANCHORS = 3
NUM_CLASSES = 7
num_filters=NUM_ANCHORS * (NUM_CLASSES + 5)backbone = DarkNet53_conv_body()
detection = YoloDetectionBlock(ch_in=1024, ch_out=512)
conv2d_pred = paddle.nn.Conv2D(in_channels=1024, out_channels=num_filters, kernel_size=1)x = np.random.randn(1, 3, 640, 640).astype('float32')
x = paddle.to_tensor(x)
C0, C1, C2 = backbone(x)
route, tip = detection(C0)
P0 = conv2d_pred(tip)reshaped_p0 = paddle.reshape(P0, [-1, NUM_ANCHORS, NUM_CLASSES + 5, P0.shape[2], P0.shape[3]])
# 取出与objectness相关的预测值
pred_objectness = reshaped_p0[:, :, 4, :, :]
pred_objectness_probability = F.sigmoid(pred_objectness)
# 取出与位置相关的预测值
pred_location = reshaped_p0[:, :, 0:4, :, :]
# 取出与类别相关的预测值
pred_classification = reshaped_p0[:, :, 5:5+NUM_CLASSES, :, :]
pred_classification_probability = F.sigmoid(pred_classification)
print(pred_classification.shape)
[1, 3, 7, 20, 20]
上面的程序通过 P 0 P0 P0计算出了预测框包含的物体所属类别的概率,pred_classification_probability的形状是 [ 1 , 3 , 7 , 20 , 20 ] [1, 3, 7, 20, 20] [1,3,7,20,20],数值在0~1之间。
损失函数
上面从概念上将输出特征图上的像素点与预测框关联起来了,那么要对神经网络进行求解,还必须从数学上将网络输出和预测框关联起来,也就是要建立起损失函数跟网络输出之间的关系。下面讨论如何建立起YOLOv3的损失函数。
对于每个预测框,YOLOv3模型会建立三种类型的损失函数:
表征是否包含目标物体的损失函数,通过pred_objectness和label_objectness计算。
loss_obj = paddle.nn.fucntional.binary_cross_entropy_with_logits(pred_objectness, label_objectness)表征物体位置的损失函数,通过pred_location和label_location计算。
pred_location_x = pred_location[:, :, 0, :, :]pred_location_y = pred_location[:, :, 1, :, :]pred_location_w = pred_location[:, :, 2, :, :]pred_location_h = pred_location[:, :, 3, :, :]loss_location_x = paddle.nn.fucntional.binary_cross_entropy_with_logits(pred_location_x, label_location_x)loss_location_y = paddle.nn.fucntional.binary_cross_entropy_with_logits(pred_location_y, label_location_y)loss_location_w = paddle.abs(pred_location_w - label_location_w)loss_location_h = paddle.abs(pred_location_h - label_location_h)loss_location = loss_location_x + loss_location_y + loss_location_w + loss_location_h表征物体类别的损失函数,通过pred_classification和label_classification计算。
loss_obj = paddle.nn.fucntional.binary_cross_entropy_with_logits(pred_classification, label_classification)
我们已经知道怎么计算这些预测值和标签了,但是遗留了一个小问题,就是没有标注出哪些锚框的objectness为-1。为了完成这一步,我们需要计算出所有预测框跟真实框之间的IoU,然后把那些IoU大于阈值的真实框挑选出来。实现代码如下:
# 挑选出跟真实框IoU大于阈值的预测框
def get_iou_above_thresh_inds(pred_box, gt_boxes, iou_threshold):batchsize = pred_box.shape[0]num_rows = pred_box.shape[1]num_cols = pred_box.shape[2]num_anchors = pred_box.shape[3]ret_inds = np.zeros([batchsize, num_rows, num_cols, num_anchors])for i in range(batchsize):pred_box_i = pred_box[i]gt_boxes_i = gt_boxes[i]for k in range(len(gt_boxes_i)): #gt in gt_boxes_i:gt = gt_boxes_i[k]gtx_min = gt[0] - gt[2] / 2.gty_min = gt[1] - gt[3] / 2.gtx_max = gt[0] + gt[2] / 2.gty_max = gt[1] + gt[3] / 2.if (gtx_max - gtx_min < 1e-3) or (gty_max - gty_min < 1e-3):continuex1 = np.maximum(pred_box_i[:, :, :, 0], gtx_min)y1 = np.maximum(pred_box_i[:, :, :, 1], gty_min)x2 = np.minimum(pred_box_i[:, :, :, 2], gtx_max)y2 = np.minimum(pred_box_i[:, :, :, 3], gty_max)intersection = np.maximum(x2 - x1, 0.) * np.maximum(y2 - y1, 0.)s1 = (gty_max - gty_min) * (gtx_max - gtx_min)s2 = (pred_box_i[:, :, :, 2] - pred_box_i[:, :, :, 0]) * (pred_box_i[:, :, :, 3] - pred_box_i[:, :, :, 1])union = s2 + s1 - intersectioniou = intersection / unionabove_inds = np.where(iou > iou_threshold)ret_inds[i][above_inds] = 1ret_inds = np.transpose(ret_inds, (0,3,1,2))return ret_inds.astype('bool')
上面的函数可以得到哪些锚框的objectness需要被标注为-1,通过下面的程序,对label_objectness进行处理,将IoU大于阈值,但又不是正样本的锚框标注为-1。
def label_objectness_ignore(label_objectness, iou_above_thresh_indices):# 注意:这里不能简单的使用 label_objectness[iou_above_thresh_indices] = -1,# 这样可能会造成label_objectness为1的点被设置为-1了# 只有将那些被标注为0,且与真实框IoU超过阈值的预测框才被标注为-1negative_indices = (label_objectness < 0.5)ignore_indices = negative_indices * iou_above_thresh_indiceslabel_objectness[ignore_indices] = -1return label_objectness
下面通过调用这两个函数,实现如何将部分预测框的label_objectness设置为-1。
# 读取数据
reader = paddle.io.DataLoader(train_dataset, batch_size=2, shuffle=True, num_workers=0, drop_last=True)
img, gt_boxes, gt_labels, im_shape = next(reader())
img, gt_boxes, gt_labels, im_shape = img.numpy(), gt_boxes.numpy(), gt_labels.numpy(), im_shape.numpy()
# 计算出锚框对应的标签
label_objectness, label_location, label_classification, scale_location = get_objectness_label(img,gt_boxes, gt_labels, iou_threshold = 0.7,anchors = [116, 90, 156, 198, 373, 326],num_classes=7, downsample=32)NUM_ANCHORS = 3
NUM_CLASSES = 7
num_filters=NUM_ANCHORS * (NUM_CLASSES + 5)backbone = DarkNet53_conv_body()
detection = YoloDetectionBlock(ch_in=1024, ch_out=512)
conv2d_pred = paddle.nn.Conv2D(in_channels=1024, out_channels=num_filters, kernel_size=1)x = paddle.to_tensor(img)
C0, C1, C2 = backbone(x)
route, tip = detection(C0)
P0 = conv2d_pred(tip)# anchors包含了预先设定好的锚框尺寸
anchors = [116, 90, 156, 198, 373, 326]
# downsample是特征图P0的步幅
pred_boxes = get_yolo_box_xxyy(P0.numpy(), anchors, num_classes=7, downsample=32)
iou_above_thresh_indices = get_iou_above_thresh_inds(pred_boxes, gt_boxes, iou_threshold=0.7)
label_objectness = label_objectness_ignore(label_objectness, iou_above_thresh_indices)使用这种方式,就可以将那些没有被标注为正样本,但又与真实框IoU比较大的样本objectness标签设置为-1了,不计算其对任何一种损失函数的贡献。计算总的损失函数的代码如下:
def get_loss(output, label_objectness, label_location, label_classification, scales, num_anchors=3, num_classes=7):# 将output从[N, C, H, W]变形为[N, NUM_ANCHORS, NUM_CLASSES + 5, H, W]reshaped_output = paddle.reshape(output, [-1, num_anchors, num_classes + 5, output.shape[2], output.shape[3]])# 从output中取出跟objectness相关的预测值pred_objectness = reshaped_output[:, :, 4, :, :]loss_objectness = F.binary_cross_entropy_with_logits(pred_objectness, label_objectness, reduction="none")# pos_samples 只有在正样本的地方取值为1.,其它地方取值全为0.pos_objectness = label_objectness > 0pos_samples = paddle.cast(pos_objectness, 'float32')pos_samples.stop_gradient=True# 从output中取出所有跟位置相关的预测值tx = reshaped_output[:, :, 0, :, :]ty = reshaped_output[:, :, 1, :, :]tw = reshaped_output[:, :, 2, :, :]th = reshaped_output[:, :, 3, :, :]# 从label_location中取出各个位置坐标的标签dx_label = label_location[:, :, 0, :, :]dy_label = label_location[:, :, 1, :, :]tw_label = label_location[:, :, 2, :, :]th_label = label_location[:, :, 3, :, :]# 构建损失函数loss_location_x = F.binary_cross_entropy_with_logits(tx, dx_label, reduction="none")loss_location_y = F.binary_cross_entropy_with_logits(ty, dy_label, reduction="none")loss_location_w = paddle.abs(tw - tw_label)loss_location_h = paddle.abs(th - th_label)# 计算总的位置损失函数loss_location = loss_location_x + loss_location_y + loss_location_h + loss_location_w# 乘以scalesloss_location = loss_location * scales# 只计算正样本的位置损失函数loss_location = loss_location * pos_samples# 从output取出所有跟物体类别相关的像素点pred_classification = reshaped_output[:, :, 5:5+num_classes, :, :]# 计算分类相关的损失函数loss_classification = F.binary_cross_entropy_with_logits(pred_classification, label_classification, reduction="none")# 将第2维求和loss_classification = paddle.sum(loss_classification, axis=2)# 只计算objectness为正的样本的分类损失函数loss_classification = loss_classification * pos_samplestotal_loss = loss_objectness + loss_location + loss_classification# 对所有预测框的loss进行求和total_loss = paddle.sum(total_loss, axis=[1,2,3])# 对所有样本求平均total_loss = paddle.mean(total_loss)return total_loss
from paddle.nn import Conv2D# 计算出锚框对应的标签
label_objectness, label_location, label_classification, scale_location = get_objectness_label(img,gt_boxes, gt_labels, iou_threshold = 0.7,anchors = [116, 90, 156, 198, 373, 326],num_classes=7, downsample=32) NUM_ANCHORS = 3
NUM_CLASSES = 7
num_filters=NUM_ANCHORS * (NUM_CLASSES + 5)backbone = DarkNet53_conv_body()
detection = YoloDetectionBlock(ch_in=1024, ch_out=512)
conv2d_pred = Conv2D(in_channels=1024, out_channels=num_filters, kernel_size=1)x = paddle.to_tensor(img)
C0, C1, C2 = backbone(x)
route, tip = detection(C0)
P0 = conv2d_pred(tip)
# anchors包含了预先设定好的锚框尺寸
anchors = [116, 90, 156, 198, 373, 326]
# downsample是特征图P0的步幅
pred_boxes = get_yolo_box_xxyy(P0.numpy(), anchors, num_classes=7, downsample=32)
iou_above_thresh_indices = get_iou_above_thresh_inds(pred_boxes, gt_boxes, iou_threshold=0.7)
label_objectness = label_objectness_ignore(label_objectness, iou_above_thresh_indices)label_objectness = paddle.to_tensor(label_objectness)
label_location = paddle.to_tensor(label_location)
label_classification = paddle.to_tensor(label_classification)
scales = paddle.to_tensor(scale_location)
label_objectness.stop_gradient=True
label_location.stop_gradient=True
label_classification.stop_gradient=True
scales.stop_gradient=Truetotal_loss = get_loss(P0, label_objectness, label_location, label_classification, scales,num_anchors=NUM_ANCHORS, num_classes=NUM_CLASSES)
total_loss_data = total_loss.numpy()
print(total_loss_data)上面的程序计算出了总的损失函数,看到这里,读者已经了解到了YOLOv3算法的大部分内容,包括如何生成锚框、给锚框打上标签、通过卷积神经网络提取特征、将输出特征图跟预测框相关联、建立起损失函数。
多尺度检测
目前我们计算损失函数是在特征图P0的基础上进行的,它的步幅stride=32。特征图的尺寸比较小,像素点数目比较少,每个像素点的感受野很大,具有非常丰富的高层级语义信息,可能比较容易检测到较大的目标。为了能够检测到尺寸较小的那些目标,需要在尺寸较大的特征图上面建立预测输出。如果我们在C2或者C1这种层级的特征图上直接产生预测输出,可能面临新的问题,它们没有经过充分的特征提取,像素点包含的语义信息不够丰富,有可能难以提取到有效的特征模式。在目标检测中,解决这一问题的方式是,将高层级的特征图尺寸放大之后跟低层级的特征图进行融合,得到的新特征图既能包含丰富的语义信息,又具有较多的像素点,能够描述更加精细的结构。
具体的网络实现方式如 图19 所示:
图19:生成多层级的输出特征图P0、P1、P2
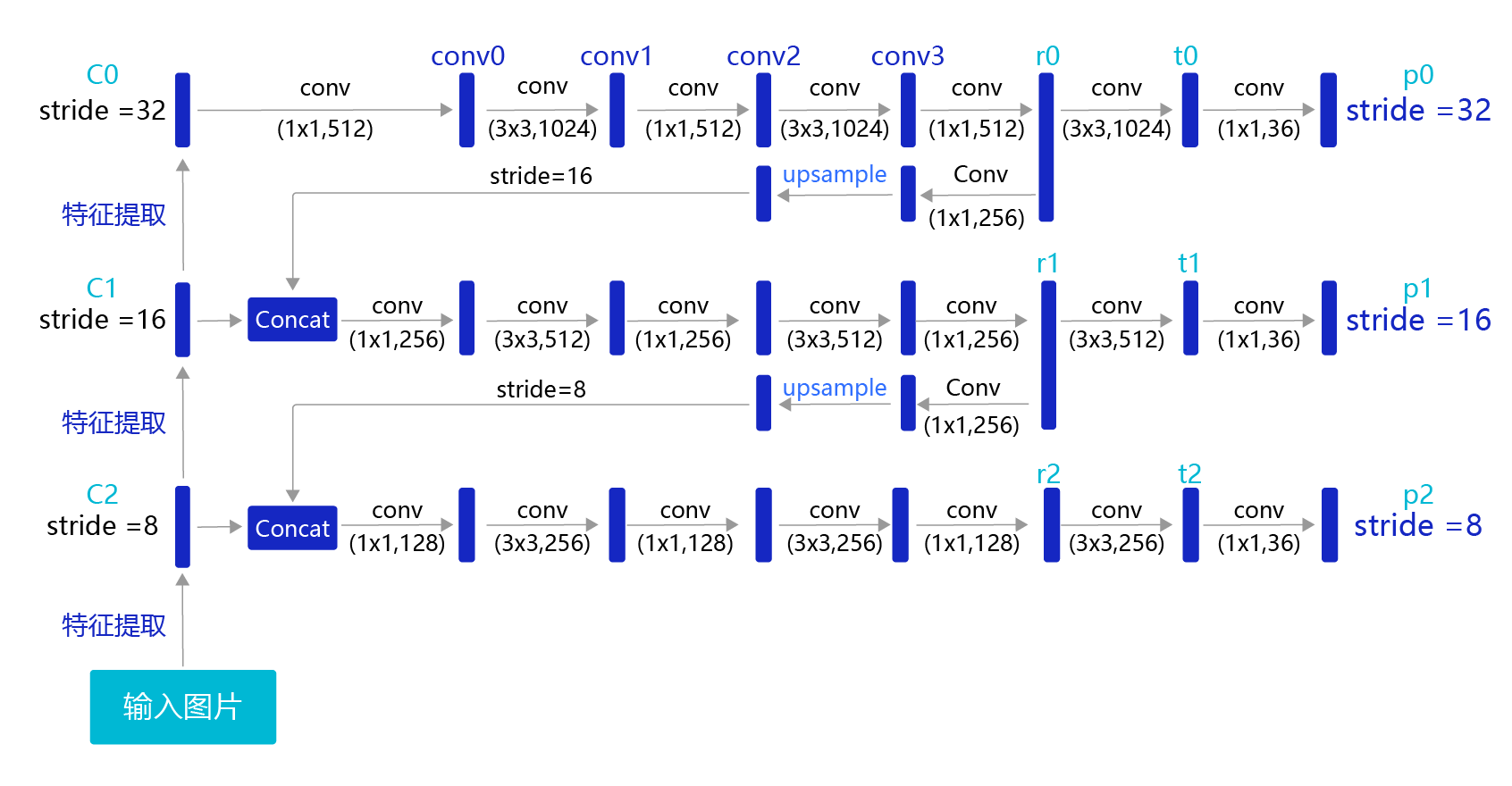
YOLOv3在每个区域的中心位置产生3个锚框,在3个层级的特征图上产生锚框的大小分别为P2 [(10×13),(16×30),(33×23)],P1 [(30×61),(62×45),(59× 119)],P0[(116 × 90), (156 × 198), (373 × 326]。越往后的特征图上用到的锚框尺寸也越大,能捕捉到大尺寸目标的信息;越往前的特征图上锚框尺寸越小,能捕捉到小尺寸目标的信息。
因为有多尺度的检测,所以需要对上面的代码进行较大的修改,而且实现过程也略显繁琐,所以推荐大家直接使用飞桨 paddle.vision.ops.yolo_loss API,关键参数说明如下:
paddle.vision.ops.yolo_loss(x, gt_box, gt_label, anchors, anchor_mask, class_num, ignore_thresh, downsample_ratio, gt_score=None, use_label_smooth=True, name=None, scale_x_y=1.0)
- x: 输出特征图。
- gt_box: 真实框。
- gt_label: 真实框标签。
- ignore_thresh,预测框与真实框IoU阈值超过ignore_thresh时,不作为负样本,YOLOv3模型里设置为0.7。
- downsample_ratio,特征图P0的下采样比例,使用Darknet53骨干网络时为32。
- gt_score,真实框的置信度,在使用了mixup技巧时用到。
- use_label_smooth,一种训练技巧,如不使用,设置为False。
- name,该层的名字,比如’yolov3_loss’,默认值为None,一般无需设置。
对于使用了多层级特征图产生预测框的方法,其具体实现代码如下:
# 定义上采样模块
class Upsample(paddle.nn.Layer):def __init__(self, scale=2):super(Upsample,self).__init__()self.scale = scaledef forward(self, inputs):# get dynamic upsample output shapeshape_nchw = paddle.shape(inputs)shape_hw = paddle.slice(shape_nchw, axes=[0], starts=[2], ends=[4])shape_hw.stop_gradient = Truein_shape = paddle.cast(shape_hw, dtype='int32')out_shape = in_shape * self.scaleout_shape.stop_gradient = True# reisze by actual_shapeout = paddle.nn.functional.interpolate(x=inputs, scale_factor=self.scale, mode="NEAREST")return outclass YOLOv3(paddle.nn.Layer):def __init__(self, num_classes=7):super(YOLOv3,self).__init__()self.num_classes = num_classes# 提取图像特征的骨干代码self.block = DarkNet53_conv_body()self.block_outputs = []self.yolo_blocks = []self.route_blocks_2 = []# 生成3个层级的特征图P0, P1, P2for i in range(3):# 添加从ci生成ri和ti的模块yolo_block = self.add_sublayer("yolo_detecton_block_%d" % (i),YoloDetectionBlock(ch_in=512//(2**i)*2 if i==0 else 512//(2**i)*2 + 512//(2**i),ch_out = 512//(2**i)))self.yolo_blocks.append(yolo_block)num_filters = 3 * (self.num_classes + 5)# 添加从ti生成pi的模块,这是一个Conv2D操作,输出通道数为3 * (num_classes + 5)block_out = self.add_sublayer("block_out_%d" % (i),paddle.nn.Conv2D(in_channels=512//(2**i)*2,out_channels=num_filters,kernel_size=1,stride=1,padding=0,weight_attr=paddle.ParamAttr(initializer=paddle.nn.initializer.Normal(0., 0.02)),bias_attr=paddle.ParamAttr(initializer=paddle.nn.initializer.Constant(0.0),regularizer=paddle.regularizer.L2Decay(0.))))self.block_outputs.append(block_out)if i < 2:# 对ri进行卷积route = self.add_sublayer("route2_%d"%i,ConvBNLayer(ch_in=512//(2**i),ch_out=256//(2**i),kernel_size=1,stride=1,padding=0))self.route_blocks_2.append(route)# 将ri放大以便跟c_{i+1}保持同样的尺寸self.upsample = Upsample()def forward(self, inputs):outputs = []blocks = self.block(inputs)for i, block in enumerate(blocks):if i > 0:# 将r_{i-1}经过卷积和上采样之后得到特征图,与这一级的ci进行拼接block = paddle.concat([route, block], axis=1)# 从ci生成ti和riroute, tip = self.yolo_blocks[i](block)# 从ti生成piblock_out = self.block_outputs[i](tip)# 将pi放入列表outputs.append(block_out)if i < 2:# 对ri进行卷积调整通道数route = self.route_blocks_2[i](route)# 对ri进行放大,使其尺寸和c_{i+1}保持一致route = self.upsample(route)return outputsdef get_loss(self, outputs, gtbox, gtlabel, gtscore=None,anchors = [10, 13, 16, 30, 33, 23, 30, 61, 62, 45, 59, 119, 116, 90, 156, 198, 373, 326],anchor_masks = [[6, 7, 8], [3, 4, 5], [0, 1, 2]],ignore_thresh=0.7,use_label_smooth=False):"""使用paddle.vision.ops.yolo_loss,直接计算损失函数,过程更简洁,速度也更快"""self.losses = []downsample = 32for i, out in enumerate(outputs): # 对三个层级分别求损失函数anchor_mask_i = anchor_masks[i]loss = paddle.vision.ops.yolo_loss(x=out, # out是P0, P1, P2中的一个gt_box=gtbox, # 真实框坐标gt_label=gtlabel, # 真实框类别gt_score=gtscore, # 真实框得分,使用mixup训练技巧时需要,不使用该技巧时直接设置为1,形状与gtlabel相同anchors=anchors, # 锚框尺寸,包含[w0, h0, w1, h1, ..., w8, h8]共9个锚框的尺寸anchor_mask=anchor_mask_i, # 筛选锚框的mask,例如anchor_mask_i=[3, 4, 5],将anchors中第3、4、5个锚框挑选出来给该层级使用class_num=self.num_classes, # 分类类别数ignore_thresh=ignore_thresh, # 当预测框与真实框IoU > ignore_thresh,标注objectness = -1downsample_ratio=downsample, # 特征图相对于原图缩小的倍数,例如P0是32, P1是16,P2是8use_label_smooth=False) # 使用label_smooth训练技巧时会用到,这里没用此技巧,直接设置为Falseself.losses.append(paddle.mean(loss)) #mean对每张图片求和downsample = downsample // 2 # 下一级特征图的缩放倍数会减半return sum(self.losses) # 对每个层级求和
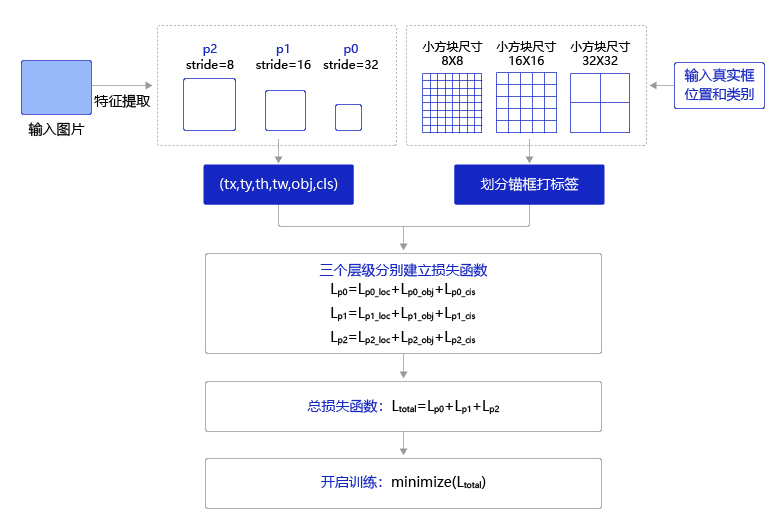
开启端到端训练
训练过程如 图20 所示,输入图片经过特征提取得到三个层级的输出特征图P0(stride=32)、P1(stride=16)和P2(stride=8),相应的分别使用不同大小的小方块区域去生成对应的锚框和预测框,并对这些锚框进行标注。
P0层级特征图,对应着使用 32 × 32 32\times32 32×32大小的小方块,在每个区域中心生成大小分别为 [ 116 , 90 ] [116, 90] [116,90], [ 156 , 198 ] [156, 198] [156,198], [ 373 , 326 ] [373, 326] [373,326]的三种锚框。
P1层级特征图,对应着使用 16 × 16 16\times16 16×16大小的小方块,在每个区域中心生成大小分别为 [ 30 , 61 ] [30, 61] [30,61], [ 62 , 45 ] [62, 45] [62,45], [ 59 , 119 ] [59, 119] [59,119]的三种锚框。
P2层级特征图,对应着使用 8 × 8 8\times8 8×8大小的小方块,在每个区域中心生成大小分别为 [ 10 , 13 ] [10, 13] [10,13], [ 16 , 30 ] [16, 30] [16,30], [ 33 , 23 ] [33, 23] [33,23]的三种锚框。
将三个层级的特征图与对应锚框之间的标签关联起来,并建立损失函数,总的损失函数等于三个层级的损失函数相加。通过极小化损失函数,可以开启端到端的训练过程。
图20:端到端训练流程
训练过程的具体实现代码如下:
############# 这段代码在本地机器上运行请慎重,容易造成死机#######################import time
import os
import paddleANCHORS = [10, 13, 16, 30, 33, 23, 30, 61, 62, 45, 59, 119, 116, 90, 156, 198, 373, 326]ANCHOR_MASKS = [[6, 7, 8], [3, 4, 5], [0, 1, 2]]IGNORE_THRESH = .7
NUM_CLASSES = 7def get_lr(base_lr = 0.0001, lr_decay = 0.1):bd = [10000, 20000]lr = [base_lr, base_lr * lr_decay, base_lr * lr_decay * lr_decay]learning_rate = paddle.optimizer.lr.PiecewiseDecay(boundaries=bd, values=lr)return learning_rateif __name__ == '__main__':TRAINDIR = '/home/aistudio/work/insects/train'TESTDIR = '/home/aistudio/work/insects/test'VALIDDIR = '/home/aistudio/work/insects/val'paddle.set_device("gpu:0")# 创建数据读取类train_dataset = TrainDataset(TRAINDIR, mode='train')valid_dataset = TrainDataset(VALIDDIR, mode='valid')test_dataset = TrainDataset(VALIDDIR, mode='valid')# 使用paddle.io.DataLoader创建数据读取器,并设置batchsize,进程数量num_workers等参数train_loader = paddle.io.DataLoader(train_dataset, batch_size=10, shuffle=True, num_workers=0, drop_last=True, use_shared_memory=False)valid_loader = paddle.io.DataLoader(valid_dataset, batch_size=10, shuffle=False, num_workers=0, drop_last=False, use_shared_memory=False)model = YOLOv3(num_classes = NUM_CLASSES) #创建模型learning_rate = get_lr()opt = paddle.optimizer.Momentum(learning_rate=learning_rate,momentum=0.9,weight_decay=paddle.regularizer.L2Decay(0.0005),parameters=model.parameters()) #创建优化器# opt = paddle.optimizer.Adam(learning_rate=learning_rate, weight_decay=paddle.regularizer.L2Decay(0.0005), parameters=model.parameters())MAX_EPOCH = 200for epoch in range(MAX_EPOCH):for i, data in enumerate(train_loader()):img, gt_boxes, gt_labels, img_scale = datagt_scores = np.ones(gt_labels.shape).astype('float32')gt_scores = paddle.to_tensor(gt_scores)img = paddle.to_tensor(img)gt_boxes = paddle.to_tensor(gt_boxes)gt_labels = paddle.to_tensor(gt_labels)outputs = model(img) #前向传播,输出[P0, P1, P2]loss = model.get_loss(outputs, gt_boxes, gt_labels, gtscore=gt_scores,anchors = ANCHORS,anchor_masks = ANCHOR_MASKS,ignore_thresh=IGNORE_THRESH,use_label_smooth=False) # 计算损失函数loss.backward() # 反向传播计算梯度opt.step() # 更新参数opt.clear_grad()if i % 10 == 0:timestring = time.strftime("%Y-%m-%d %H:%M:%S",time.localtime(time.time()))print('{}[TRAIN]epoch {}, iter {}, output loss: {}'.format(timestring, epoch, i, loss.numpy()))# save params of modelif (epoch % 5 == 0) or (epoch == MAX_EPOCH -1):paddle.save(model.state_dict(), 'yolo_epoch{}'.format(epoch))# 每个epoch结束之后在验证集上进行测试model.eval()for i, data in enumerate(valid_loader()):img, gt_boxes, gt_labels, img_scale = datagt_scores = np.ones(gt_labels.shape).astype('float32')gt_scores = paddle.to_tensor(gt_scores)img = paddle.to_tensor(img)gt_boxes = paddle.to_tensor(gt_boxes)gt_labels = paddle.to_tensor(gt_labels)outputs = model(img)loss = model.get_loss(outputs, gt_boxes, gt_labels, gtscore=gt_scores,anchors = ANCHORS,anchor_masks = ANCHOR_MASKS,ignore_thresh=IGNORE_THRESH,use_label_smooth=False)if i % 1 == 0:timestring = time.strftime("%Y-%m-%d %H:%M:%S",time.localtime(time.time()))print('{}[VALID]epoch {}, iter {}, output loss: {}'.format(timestring, epoch, i, loss.numpy()))model.train()
预测
预测过程流程 图21 如下所示:
图21:预测流程
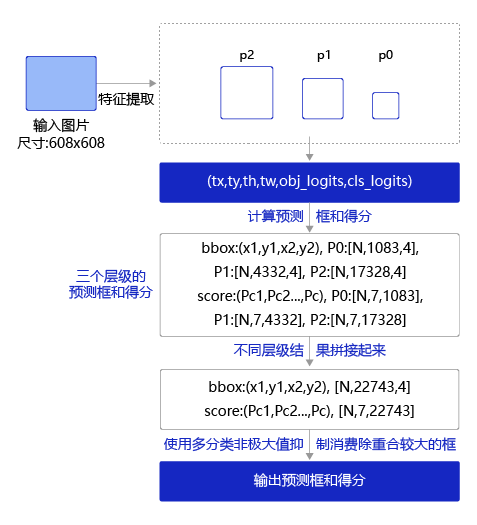
预测过程可以分为两步:
- 通过网络输出计算出预测框位置和所属类别的得分。
- 使用非极大值抑制来消除重叠较大的预测框。
对于第1步,前面我们已经讲过如何通过网络输出值计算pred_objectness_probability, pred_boxes以及pred_classification_probability,这里推荐大家直接使用paddle.vision.ops.yolo_box,关键参数含义如下:
paddle.vision.ops.yolo_box(x, img_size, anchors, class_num, conf_thresh, downsample_ratio, clip_bbox=True, name=None, scale_x_y=1.0)
- x,网络输出特征图,例如上面提到的P0或者P1、P2。
- img_size,输入图片尺寸。
- anchors,使用到的anchor的尺寸,如[10, 13, 16, 30, 33, 23, 30, 61, 62, 45, 59, 119, 116, 90, 156, 198, 373, 326]
- class_num,物体类别数。
- conf_thresh, 置信度阈值,得分低于该阈值的预测框位置数值不用计算直接设置为0.0。
- downsample_ratio, 特征图的下采样比例,例如P0是32,P1是16,P2是8。
- name=None,名字,例如’yolo_box’,一般无需设置,默认值为None。
返回值包括两项,boxes和scores,其中boxes是所有预测框的坐标值,scores是所有预测框的得分。
预测框得分的定义是所属类别的概率乘以其预测框是否包含目标物体的objectness概率,即
s c o r e = P o b j ⋅ P c l a s s i f i c a t i o n score = P_{obj} \cdot P_{classification} score=Pobj⋅Pclassification
在上面定义的类YOLOv3下面添加函数,get_pred,通过调用paddle.vision.ops.yolo_box获得P0、P1、P2三个层级的特征图对应的预测框和得分,并将他们拼接在一块,即可得到所有的预测框及其属于各个类别的得分。
# 定义YOLOv3模型
class YOLOv3(paddle.nn.Layer):def __init__(self, num_classes=7):super(YOLOv3,self).__init__()self.num_classes = num_classes# 提取图像特征的骨干代码self.block = DarkNet53_conv_body()self.block_outputs = []self.yolo_blocks = []self.route_blocks_2 = []# 生成3个层级的特征图P0, P1, P2for i in range(3):# 添加从ci生成ri和ti的模块yolo_block = self.add_sublayer("yolo_detecton_block_%d" % (i),YoloDetectionBlock(ch_in=512//(2**i)*2 if i==0 else 512//(2**i)*2 + 512//(2**i),ch_out = 512//(2**i)))self.yolo_blocks.append(yolo_block)num_filters = 3 * (self.num_classes + 5)# 添加从ti生成pi的模块,这是一个Conv2D操作,输出通道数为3 * (num_classes + 5)block_out = self.add_sublayer("block_out_%d" % (i),paddle.nn.Conv2D(in_channels=512//(2**i)*2,out_channels=num_filters,kernel_size=1,stride=1,padding=0,weight_attr=paddle.ParamAttr(initializer=paddle.nn.initializer.Normal(0., 0.02)),bias_attr=paddle.ParamAttr(initializer=paddle.nn.initializer.Constant(0.0),regularizer=paddle.regularizer.L2Decay(0.))))self.block_outputs.append(block_out)if i < 2:# 对ri进行卷积route = self.add_sublayer("route2_%d"%i,ConvBNLayer(ch_in=512//(2**i),ch_out=256//(2**i),kernel_size=1,stride=1,padding=0))self.route_blocks_2.append(route)# 将ri放大以便跟c_{i+1}保持同样的尺寸self.upsample = Upsample()def forward(self, inputs):outputs = []blocks = self.block(inputs)for i, block in enumerate(blocks):if i > 0:# 将r_{i-1}经过卷积和上采样之后得到特征图,与这一级的ci进行拼接block = paddle.concat([route, block], axis=1)# 从ci生成ti和riroute, tip = self.yolo_blocks[i](block)# 从ti生成piblock_out = self.block_outputs[i](tip)# 将pi放入列表outputs.append(block_out)if i < 2:# 对ri进行卷积调整通道数route = self.route_blocks_2[i](route)# 对ri进行放大,使其尺寸和c_{i+1}保持一致route = self.upsample(route)return outputsdef get_loss(self, outputs, gtbox, gtlabel, gtscore=None,anchors = [10, 13, 16, 30, 33, 23, 30, 61, 62, 45, 59, 119, 116, 90, 156, 198, 373, 326],anchor_masks = [[6, 7, 8], [3, 4, 5], [0, 1, 2]],ignore_thresh=0.7,use_label_smooth=False):"""使用paddle.vision.ops.yolo_loss,直接计算损失函数,过程更简洁,速度也更快"""self.losses = []downsample = 32for i, out in enumerate(outputs): # 对三个层级分别求损失函数anchor_mask_i = anchor_masks[i]loss = paddle.vision.ops.yolo_loss(x=out, # out是P0, P1, P2中的一个gt_box=gtbox, # 真实框坐标gt_label=gtlabel, # 真实框类别gt_score=gtscore, # 真实框得分,使用mixup训练技巧时需要,不使用该技巧时直接设置为1,形状与gtlabel相同anchors=anchors, # 锚框尺寸,包含[w0, h0, w1, h1, ..., w8, h8]共9个锚框的尺寸anchor_mask=anchor_mask_i, # 筛选锚框的mask,例如anchor_mask_i=[3, 4, 5],将anchors中第3、4、5个锚框挑选出来给该层级使用class_num=self.num_classes, # 分类类别数ignore_thresh=ignore_thresh, # 当预测框与真实框IoU > ignore_thresh,标注objectness = -1downsample_ratio=downsample, # 特征图相对于原图缩小的倍数,例如P0是32, P1是16,P2是8use_label_smooth=False) # 使用label_smooth训练技巧时会用到,这里没用此技巧,直接设置为Falseself.losses.append(paddle.mean(loss)) #mean对每张图片求和downsample = downsample // 2 # 下一级特征图的缩放倍数会减半return sum(self.losses) # 对每个层级求和def get_pred(self,outputs,im_shape=None,anchors = [10, 13, 16, 30, 33, 23, 30, 61, 62, 45, 59, 119, 116, 90, 156, 198, 373, 326],anchor_masks = [[6, 7, 8], [3, 4, 5], [0, 1, 2]],valid_thresh = 0.01):downsample = 32total_boxes = []total_scores = []for i, out in enumerate(outputs):anchor_mask = anchor_masks[i]anchors_this_level = []for m in anchor_mask:anchors_this_level.append(anchors[2 * m])anchors_this_level.append(anchors[2 * m + 1])boxes, scores = paddle.vision.ops.yolo_box(x=out,img_size=im_shape,anchors=anchors_this_level,class_num=self.num_classes,conf_thresh=valid_thresh,downsample_ratio=downsample,name="yolo_box" + str(i))total_boxes.append(boxes)total_scores.append(paddle.transpose(scores, perm=[0, 2, 1]))downsample = downsample // 2yolo_boxes = paddle.concat(total_boxes, axis=1)yolo_scores = paddle.concat(total_scores, axis=2)return yolo_boxes, yolo_scores
第1步的计算结果会在每个小方块区域上生成多个预测框,而这些预测框中很多都有较大的重合度,因此需要消除重叠较大的冗余检测框。
下面示例代码中的预测框是使用模型对图片预测之后输出的,这里一共选出了11个预测框,在图上画出预测框如下所示。在每个人像周围,都出现了多个预测框,需要消除冗余的预测框以得到最终的预测结果。
# 画图展示目标物体边界框
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from matplotlib.image import imread
import math# 定义画矩形框的程序
def draw_rectangle(currentAxis, bbox, edgecolor = 'k', facecolor = 'y', fill=False, linestyle='-'):# currentAxis,坐标轴,通过plt.gca()获取# bbox,边界框,包含四个数值的list, [x1, y1, x2, y2]# edgecolor,边框线条颜色# facecolor,填充颜色# fill, 是否填充# linestype,边框线型# patches.Rectangle需要传入左上角坐标、矩形区域的宽度、高度等参数rect=patches.Rectangle((bbox[0], bbox[1]), bbox[2]-bbox[0]+1, bbox[3]-bbox[1]+1, linewidth=1,edgecolor=edgecolor,facecolor=facecolor,fill=fill, linestyle=linestyle)currentAxis.add_patch(rect)plt.figure(figsize=(10, 10))filename = '/home/aistudio/work/images/section3/000000086956.jpg'
im = imread(filename)
plt.imshow(im)currentAxis=plt.gca()# 预测框位置
boxes = np.array([[4.21716537e+01, 1.28230896e+02, 2.26547668e+02, 6.00434631e+02],[3.18562988e+02, 1.23168472e+02, 4.79000000e+02, 6.05688416e+02],[2.62704697e+01, 1.39430557e+02, 2.20587097e+02, 6.38959656e+02],[4.24965363e+01, 1.42706665e+02, 2.25955185e+02, 6.35671204e+02],[2.37462646e+02, 1.35731537e+02, 4.79000000e+02, 6.31451294e+02],[3.19390472e+02, 1.29295090e+02, 4.79000000e+02, 6.33003845e+02],[3.28933838e+02, 1.22736115e+02, 4.79000000e+02, 6.39000000e+02],[4.44292603e+01, 1.70438187e+02, 2.26841858e+02, 6.39000000e+02],[2.17988785e+02, 3.02472412e+02, 4.06062927e+02, 6.29106628e+02],[2.00241089e+02, 3.23755096e+02, 3.96929321e+02, 6.36386108e+02],[2.14310303e+02, 3.23443665e+02, 4.06732849e+02, 6.35775269e+02]])# 预测框得分
scores = np.array([0.5247661 , 0.51759845, 0.86075854, 0.9910175 , 0.39170712,0.9297706 , 0.5115228 , 0.270992 , 0.19087596, 0.64201415, 0.879036])# 画出所有预测框
for box in boxes:draw_rectangle(currentAxis, box)这里使用非极大值抑制(non-maximum suppression, nms)来消除冗余框。基本思想是,如果有多个预测框都对应同一个物体,则只选出得分最高的那个预测框,剩下的预测框被丢弃掉。
如何判断两个预测框对应的是同一个物体呢,标准该怎么设置?
如果两个预测框的类别一样,而且他们的位置重合度比较大,则可以认为他们是在预测同一个目标。非极大值抑制的做法是,选出某个类别得分最高的预测框,然后看哪些预测框跟它的IoU大于阈值,就把这些预测框给丢弃掉。这里IoU的阈值是超参数,需要提前设置,YOLOv3模型里面设置的是0.5。
比如在上面的程序中,boxes里面一共对应11个预测框,scores给出了它们预测"人"这一类别的得分。
- Step0:创建选中列表,keep_list = []
- Step1:对得分进行排序,remain_list = [ 3, 5, 10, 2, 9, 0, 1, 6, 4, 7, 8],
- Step2:选出boxes[3],此时keep_list为空,不需要计算IoU,直接将其放入keep_list,keep_list = [3], remain_list=[5, 10, 2, 9, 0, 1, 6, 4, 7, 8]
- Step3:选出boxes[5],此时keep_list中已经存在boxes[3],计算出IoU(boxes[3], boxes[5]) = 0.0,显然小于阈值,则keep_list=[3, 5], remain_list = [10, 2, 9, 0, 1, 6, 4, 7, 8]
- Step4:选出boxes[10],此时keep_list=[3, 5],计算IoU(boxes[3], boxes[10])=0.0268,IoU(boxes[5], boxes[10])=0.0268 = 0.24,都小于阈值,则keep_list = [3, 5, 10],remain_list=[2, 9, 0, 1, 6, 4, 7, 8]
- Step5:选出boxes[2],此时keep_list = [3, 5, 10],计算IoU(boxes[3], boxes[2]) = 0.88,超过了阈值,直接将boxes[2]丢弃,keep_list=[3, 5, 10],remain_list=[9, 0, 1, 6, 4, 7, 8]
- Step6:选出boxes[9],此时keep_list = [3, 5, 10],计算IoU(boxes[3], boxes[9]) = 0.0577,IoU(boxes[5], boxes[9]) = 0.205,IoU(boxes[10], boxes[9]) = 0.88,超过了阈值,将boxes[9]丢弃掉。keep_list=[3, 5, 10],remain_list=[0, 1, 6, 4, 7, 8]
- Step7:重复上述Step6直到remain_list为空。
最终得到keep_list=[3, 5, 10],也就是预测框3、5、10被最终挑选出来了,如下图所示。
# 画图展示目标物体边界框
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from matplotlib.image import imread
import math# 定义画矩形框的程序
def draw_rectangle(currentAxis, bbox, edgecolor = 'k', facecolor = 'y', fill=False, linestyle='-'):# currentAxis,坐标轴,通过plt.gca()获取# bbox,边界框,包含四个数值的list, [x1, y1, x2, y2]# edgecolor,边框线条颜色# facecolor,填充颜色# fill, 是否填充# linestype,边框线型# patches.Rectangle需要传入左上角坐标、矩形区域的宽度、高度等参数rect=patches.Rectangle((bbox[0], bbox[1]), bbox[2]-bbox[0]+1, bbox[3]-bbox[1]+1, linewidth=1,edgecolor=edgecolor,facecolor=facecolor,fill=fill, linestyle=linestyle)currentAxis.add_patch(rect)plt.figure(figsize=(10, 10))filename = '/home/aistudio/work/images/section3/000000086956.jpg'
im = imread(filename)
plt.imshow(im)currentAxis=plt.gca()boxes = np.array([[4.21716537e+01, 1.28230896e+02, 2.26547668e+02, 6.00434631e+02],[3.18562988e+02, 1.23168472e+02, 4.79000000e+02, 6.05688416e+02],[2.62704697e+01, 1.39430557e+02, 2.20587097e+02, 6.38959656e+02],[4.24965363e+01, 1.42706665e+02, 2.25955185e+02, 6.35671204e+02],[2.37462646e+02, 1.35731537e+02, 4.79000000e+02, 6.31451294e+02],[3.19390472e+02, 1.29295090e+02, 4.79000000e+02, 6.33003845e+02],[3.28933838e+02, 1.22736115e+02, 4.79000000e+02, 6.39000000e+02],[4.44292603e+01, 1.70438187e+02, 2.26841858e+02, 6.39000000e+02],[2.17988785e+02, 3.02472412e+02, 4.06062927e+02, 6.29106628e+02],[2.00241089e+02, 3.23755096e+02, 3.96929321e+02, 6.36386108e+02],[2.14310303e+02, 3.23443665e+02, 4.06732849e+02, 6.35775269e+02]])scores = np.array([0.5247661 , 0.51759845, 0.86075854, 0.9910175 , 0.39170712,0.9297706 , 0.5115228 , 0.270992 , 0.19087596, 0.64201415, 0.879036])left_ind = np.where((boxes[:, 0]<60) * (boxes[:, 0]>20))
left_boxes = boxes[left_ind]
left_scores = scores[left_ind]colors = ['r', 'g', 'b', 'k']# 画出最终保留的预测框
inds = [3, 5, 10]
for i in range(3):box = boxes[inds[i]]draw_rectangle(currentAxis, box, edgecolor=colors[i])非极大值抑制的具体实现代码如下面的nms函数的定义,需要说明的是数据集中含有多个类别的物体,所以这里需要做多分类非极大值抑制,其实现原理与非极大值抑制相同,区别在于需要对每个类别都做非极大值抑制,实现代码如下面的multiclass_nms所示。
# 非极大值抑制
def nms(bboxes, scores, score_thresh, nms_thresh, pre_nms_topk, i=0, c=0):"""nms"""inds = np.argsort(scores)inds = inds[::-1]keep_inds = []while(len(inds) > 0):cur_ind = inds[0]cur_score = scores[cur_ind]# if score of the box is less than score_thresh, just drop itif cur_score < score_thresh:breakkeep = Truefor ind in keep_inds:current_box = bboxes[cur_ind]remain_box = bboxes[ind]iou = box_iou_xyxy(current_box, remain_box)if iou > nms_thresh:keep = Falsebreakif i == 0 and c == 4 and cur_ind == 951:print('suppressed, ', keep, i, c, cur_ind, ind, iou)if keep:keep_inds.append(cur_ind)inds = inds[1:]return np.array(keep_inds)# 多分类非极大值抑制
def multiclass_nms(bboxes, scores, score_thresh=0.01, nms_thresh=0.45, pre_nms_topk=1000, pos_nms_topk=100):"""This is for multiclass_nms"""batch_size = bboxes.shape[0]class_num = scores.shape[1]rets = []for i in range(batch_size):bboxes_i = bboxes[i]scores_i = scores[i]ret = []for c in range(class_num):scores_i_c = scores_i[c]keep_inds = nms(bboxes_i, scores_i_c, score_thresh, nms_thresh, pre_nms_topk, i=i, c=c)if len(keep_inds) < 1:continuekeep_bboxes = bboxes_i[keep_inds]keep_scores = scores_i_c[keep_inds]keep_results = np.zeros([keep_scores.shape[0], 6])keep_results[:, 0] = ckeep_results[:, 1] = keep_scores[:]keep_results[:, 2:6] = keep_bboxes[:, :]ret.append(keep_results)if len(ret) < 1:rets.append(ret)continueret_i = np.concatenate(ret, axis=0)scores_i = ret_i[:, 1]if len(scores_i) > pos_nms_topk:inds = np.argsort(scores_i)[::-1]inds = inds[:pos_nms_topk]ret_i = ret_i[inds]rets.append(ret_i)return rets
下面是完整的测试程序,在测试数据集上的输出结果将会被保存在pred_results.json文件中。
# 计算IoU,矩形框的坐标形式为xyxy,这个函数会被保存在box_utils.py文件中
def box_iou_xyxy(box1, box2):# 获取box1左上角和右下角的坐标x1min, y1min, x1max, y1max = box1[0], box1[1], box1[2], box1[3]# 计算box1的面积s1 = (y1max - y1min + 1.) * (x1max - x1min + 1.)# 获取box2左上角和右下角的坐标x2min, y2min, x2max, y2max = box2[0], box2[1], box2[2], box2[3]# 计算box2的面积s2 = (y2max - y2min + 1.) * (x2max - x2min + 1.)# 计算相交矩形框的坐标xmin = np.maximum(x1min, x2min)ymin = np.maximum(y1min, y2min)xmax = np.minimum(x1max, x2max)ymax = np.minimum(y1max, y2max)# 计算相交矩形行的高度、宽度、面积inter_h = np.maximum(ymax - ymin + 1., 0.)inter_w = np.maximum(xmax - xmin + 1., 0.)intersection = inter_h * inter_w# 计算相并面积union = s1 + s2 - intersection# 计算交并比iou = intersection / unionreturn iou
import json
import os
ANCHORS = [10, 13, 16, 30, 33, 23, 30, 61, 62, 45, 59, 119, 116, 90, 156, 198, 373, 326]
ANCHOR_MASKS = [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
VALID_THRESH = 0.01
NMS_TOPK = 400
NMS_POSK = 100
NMS_THRESH = 0.45
NUM_CLASSES = 7if __name__ == '__main__':TRAINDIR = '/home/aistudio/work/insects/train/images'TESTDIR = '/home/aistudio/work/insects/test/images'VALIDDIR = '/home/aistudio/work/insects/val'model = YOLOv3(num_classes=NUM_CLASSES)params_file_path = '/home/aistudio/yolo_epoch50.pdparams'model_state_dict = paddle.load(params_file_path)model.load_dict(model_state_dict)model.eval()total_results = []test_loader = test_data_loader(TESTDIR, batch_size= 1, mode='test')for i, data in enumerate(test_loader()):img_name, img_data, img_scale_data = dataimg = paddle.to_tensor(img_data)img_scale = paddle.to_tensor(img_scale_data)outputs = model.forward(img)bboxes, scores = model.get_pred(outputs,im_shape=img_scale,anchors=ANCHORS,anchor_masks=ANCHOR_MASKS,valid_thresh = VALID_THRESH)bboxes_data = bboxes.numpy()scores_data = scores.numpy()result = multiclass_nms(bboxes_data, scores_data,score_thresh=VALID_THRESH, nms_thresh=NMS_THRESH, pre_nms_topk=NMS_TOPK, pos_nms_topk=NMS_POSK)for j in range(len(result)):result_j = result[j]img_name_j = img_name[j]total_results.append([img_name_j, result_j.tolist()])print('processed {} pictures'.format(len(total_results)))print('')json.dump(total_results, open('pred_results.json', 'w'))json文件中保存着测试结果,是包含所有图片预测结果的list,其构成如下:
[[img_name, [[label, score, x1, y1, x2, y2], …, [label, score, x1, y1, x2, y2]]],
[img_name, [[label, score, x1, y1, x2, y2], …, [label, score, x1, y1, x2, y2]]],
…
[img_name, [[label, score, x1, y1, x2, y2],…, [label, score, x1, y1, x2, y2]]]]
list中的每一个元素是一张图片的预测结果,list的总长度等于图片的数目,每张图片预测结果的格式是:
[img_name, [[label, score, x1, y1, x2, y2],…, [label, score, x1, y1, x2, y2]]]
其中第一个元素是图片名称image_name,第二个元素是包含该图片所有预测框的list, 预测框列表:
[[label, score, x1, x2, y1, y2],…, [label, score, x1, y1, x2, y2]]
预测框列表中每个元素[label, score, x1, y1, x2, y2]描述了一个预测框,label是预测框所属类别标签,score是预测框的得分;x1, y1, x2, y2对应预测框左上角坐标(x1, y1),右下角坐标(x2, y2)。每张图片可能有很多个预测框,则将其全部放在预测框列表中。
模型效果及可视化展示
上面的程序展示了如何读取测试数据集的图片,并将最终结果保存在json格式的文件中。为了更直观的给读者展示模型效果,下面的程序添加了如何读取单张图片,并画出其产生的预测框。
- 创建数据读取器以读取单张图片的数据
# 读取单张测试图片
def single_image_data_loader(filename, test_image_size=608, mode='test'):"""加载测试用的图片,测试数据没有groundtruth标签"""batch_size= 1def reader():batch_data = []img_size = test_image_sizefile_path = os.path.join(filename)img = cv2.imread(file_path)img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)H = img.shape[0]W = img.shape[1]img = cv2.resize(img, (img_size, img_size))mean = [0.485, 0.456, 0.406]std = [0.229, 0.224, 0.225]mean = np.array(mean).reshape((1, 1, -1))std = np.array(std).reshape((1, 1, -1))out_img = (img / 255.0 - mean) / stdout_img = out_img.astype('float32').transpose((2, 0, 1))img = out_img #np.transpose(out_img, (2,0,1))im_shape = [H, W]batch_data.append((image_name.split('.')[0], img, im_shape))if len(batch_data) == batch_size:yield make_test_array(batch_data)batch_data = []return reader
- 定义绘制预测框的画图函数,代码如下。
# 定义画图函数
INSECT_NAMES = ['Boerner', 'Leconte', 'Linnaeus', 'acuminatus', 'armandi', 'coleoptera', 'linnaeus']# 定义画矩形框的函数
def draw_rectangle(currentAxis, bbox, edgecolor = 'k', facecolor = 'y', fill=False, linestyle='-'):# currentAxis,坐标轴,通过plt.gca()获取# bbox,边界框,包含四个数值的list, [x1, y1, x2, y2]# edgecolor,边框线条颜色# facecolor,填充颜色# fill, 是否填充# linestype,边框线型# patches.Rectangle需要传入左上角坐标、矩形区域的宽度、高度等参数rect=patches.Rectangle((bbox[0], bbox[1]), bbox[2]-bbox[0]+1, bbox[3]-bbox[1]+1, linewidth=1,edgecolor=edgecolor,facecolor=facecolor,fill=fill, linestyle=linestyle)currentAxis.add_patch(rect)# 定义绘制预测结果的函数
def draw_results(result, filename, draw_thresh=0.5):plt.figure(figsize=(10, 10))im = imread(filename)plt.imshow(im)currentAxis=plt.gca()colors = ['r', 'g', 'b', 'k', 'y', 'c', 'purple']for item in result:box = item[2:6]label = int(item[0])name = INSECT_NAMES[label]if item[1] > draw_thresh:draw_rectangle(currentAxis, box, edgecolor = colors[label])plt.text(box[0], box[1], name, fontsize=12, color=colors[label])
- 使用上面定义的single_image_data_loader函数读取指定的图片,输入网络并计算出预测框和得分,然后使用多分类非极大值抑制消除冗余的框。将最终结果画图展示出来。
import jsonimport paddleANCHORS = [10, 13, 16, 30, 33, 23, 30, 61, 62, 45, 59, 119, 116, 90, 156, 198, 373, 326]
ANCHOR_MASKS = [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
VALID_THRESH = 0.01
NMS_TOPK = 400
NMS_POSK = 100
NMS_THRESH = 0.45NUM_CLASSES = 7
if __name__ == '__main__':image_name = '/home/aistudio/work/insects/test/images/2599.jpeg'params_file_path = '/home/aistudio/yolo_epoch50.pdparams'model = YOLOv3(num_classes=NUM_CLASSES)model_state_dict = paddle.load(params_file_path)model.load_dict(model_state_dict)model.eval()total_results = []test_loader = single_image_data_loader(image_name, mode='test')for i, data in enumerate(test_loader()):img_name, img_data, img_scale_data = dataimg = paddle.to_tensor(img_data)img_scale = paddle.to_tensor(img_scale_data)outputs = model.forward(img)bboxes, scores = model.get_pred(outputs,im_shape=img_scale,anchors=ANCHORS,anchor_masks=ANCHOR_MASKS,valid_thresh = VALID_THRESH)bboxes_data = bboxes.numpy()scores_data = scores.numpy()results = multiclass_nms(bboxes_data, scores_data,score_thresh=VALID_THRESH, nms_thresh=NMS_THRESH, pre_nms_topk=NMS_TOPK, pos_nms_topk=NMS_POSK)result = results[0]
draw_results(result, image_name, draw_thresh=0.5)
通过上面的程序,清晰的给读者展示了如何使用训练好的权重,对图片进行预测并将结果可视化。最终输出的图片上,检测出了每个昆虫,标出了它们的边界框和具体类别。
总结
本章系统化的介绍了计算机视觉的各种网络结构和发展历程,并以图像分类和目标检测两个任务为例,展示了ResNet和YOLOv3等算法的实现。期望读者不仅掌握了计算机视觉模型搭建方法,也能够对提取视觉特征的方法有更深入的认知。
YOLOV3林业病虫害数据集和数据预处理-paddle教程相关推荐
- AI识虫:林业病虫害数据集和数据预处理方法
林业病虫害数据集和数据预处理方法 林业病虫害数据集和数据预处理 读取AI识虫数据集标注信息 数据读取和预处理 数据读取 使用百度与林业大学合作开发的林业病虫害防治项目中用到昆虫数据集.在这一小节中将为 ...
- 林业病虫害数据集和数据预处理方法介绍
内容都是百度AIstudio的内容,我只是在这里做个笔记,不是原创. 林业病虫害数据集和数据预处理方法介绍 在本次的课程中,将使用百度与林业大学合作开发的林业病虫害防治项目中用到昆虫数据集,关于该项目 ...
- 计算机视觉:基于YOLO-V3林业病虫害目标检测
计算机视觉:基于YOLO-V3林业病虫害目标检测 卷积神经网络提取特征 根据输出特征图计算预测框位置和类别 建立输出特征图与预测框之间的关联 计算预测框是否包含物体的概率 计算预测框位置坐标 计算物体 ...
- PyTorch基础-自定义数据集和数据加载器(2)
处理数据样本的代码可能会变得混乱且难以维护: 理想情况下,我们想要数据集代码与模型训练代码解耦,以获得更好的可读性和模块化.PyTorch 域库提供了许多预加载的数据(例如 FashionMNIST) ...
- 数据访问模式二:数据集和数据适配器(传统的数据访问模式)
上一篇文章介绍了使用DataSource控件访问数据库的过程,本节介绍利用数据适配集/数据适配器的访问数据库.这两种设计模式的差别,使得GridView的设计即要支持DataSource控件的数据绑定 ...
- 水下目标检测之数据集和数据增强方法
水下目标检测之数据集和数据增强方法 通过之前对yolov5的简单学习,发现yolov5的训练和调试都比较方便,因此希望将其运用到水下目标检测的任务中.那么首要任务就是寻找比较合适的数据集作为训练样本, ...
- pytorch自定义数据集和数据加载器
假设有一个保存为npy格式的numpy数据集,现在需要将其变为pytorch的数据集,并能够被数据加载器DataLoader所加载 首先自定义一个数据集类,继承torch.utils.data.Dat ...
- 学习率和数据集规模_数据集和数据
学习率和数据集规模 Often the words data and dataset are used interchangeably due to the understanding the wor ...
- powerbi实时刷新mysql数据库_PowerBI开发 第七篇:数据集和数据刷新
PowerBI报表是基于数据分析的引擎,数据真正的来源(Data Source)是数据库,文件等数据存储媒介,PowerBI支持的数据源类型多种多样.PowerBI Service(云端)有时不直接访 ...
最新文章
- 百度开放AI应用学习!
- 图像数据读取及数据扩增方法
- 流网络的最小割问题c语言,「网络流24题」最小路径覆盖问题
- python 数据分析学什么-如何在业余时学数据分析?
- LaTeX 笔记:NFSS 那点事儿
- Extjs Window用法详解 3 打印具体应用,是否关掉打印预览的界面
- c++ 操作oracle 最佳方式_oracle备份恢复基础详解
- IOT(32)---各大物联网平台对比
- C# WinForm 判断程序是否已经在运行,且只允许运行一个实例,附源码
- html基础内容样式
- 计算机基本知识(8000)---boot系统引导文件
- 计算机没有本地网络,网络连接里没有本地连接
- android批量转换图片格式,批量图片格式转换器
- 一线外包员工的生活经历
- postman接口测试之断言+参数化
- c语言写学程序,入门:我的第一个程序|学编程写游戏(C语言)
- sub( ,amp;) C语言,C语言与C++不同之函数定义
- 计算机无法注册打印机,电脑中打印机添加不了怎么办
- 从ResNet、DenseNet、ResNeXt、SE Net、SE ResNeXt 演进学习总结
- 做领导要会说话!高情商的18个说话技巧,受益无穷!