词嵌入生成词向量_使用词嵌入创建诗生成器
词嵌入生成词向量
AI创意助手 (AI creative assistant)
With new and more complex language models coming out in recent times, sometimes it feels like an overwhelming task to make your initial steps into the natural language processing world.
随着最近出现的新的和更复杂的语言模型,有时候进入自然语言处理世界的第一步似乎是一项艰巨的任务。
The purpose of this guide is to provide a fair simple project, a poem generator, to grasp your hands on the NLP world using just one technique: word embeddings.
本指南的目的是提供一个简单的项目(一个诗歌生成器),以仅使用一种技术(词嵌入)来掌握NLP领域。
那么什么是词嵌入? (So what are word embeddings?)
Word embeddings are n-dimensional vectorial representations of words, that somehow capture their meaning based on the context existing on a corpus. Stated in another way: words that are used in similar ways in a specific corpus(collection of texts), will have similar vectors.
词嵌入是词的n维矢量表示,它可以基于语料库中存在的上下文以某种方式捕获其含义。 换句话说:在特定语料库(文本集合)中以相似方式使用的单词将具有相似的向量。
And the fun part of having numerical representation of words is that now we can use them in math operations like computing similarity, a measure that we will use in our poem generator.
单词数值表示的有趣之处在于,现在我们可以在数学运算中使用它们,例如计算相似性,这是我们将在诗歌生成器中使用的一种度量。
Similarity is used to quantify the sameness between two vectors. It computes the cosine of the angle between them, which results in a value of 1 for vectors with the same orientation an 0 when the angle is 90°.
相似性用于量化两个向量之间的相似性。 它计算它们之间的角度的余弦值,对于具有相同方向的矢量,当角度为90°时,值为1;值为0。

We will use this property to search for likeness between words and sentences.
我们将使用此属性搜索单词和句子之间的相似性。
算法 (The algorithm)
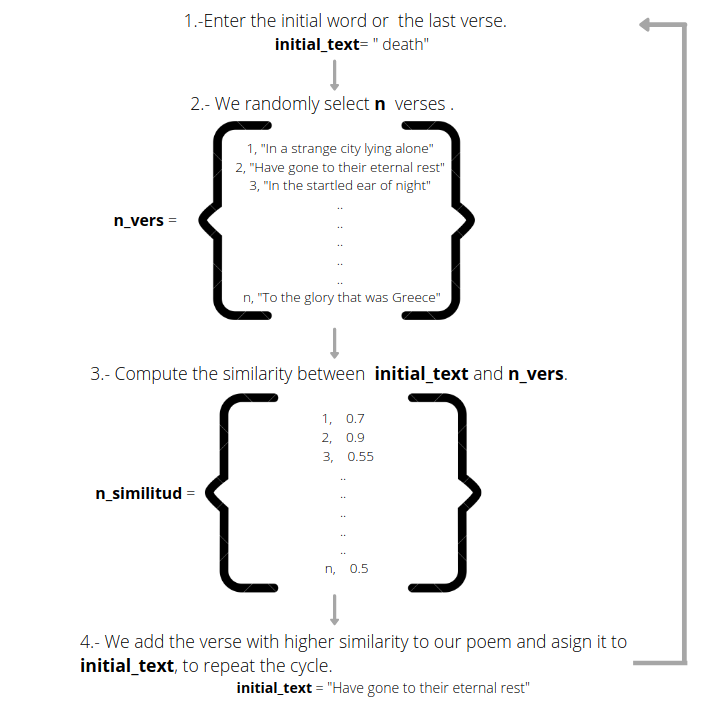
Our goal is to create a new poem with an input initial word. First, we will randomly select verses, and then we will calculate the similarity between those verses and our initial word. Later, we will select the verse with the highest score and add it to the poem. We will repeat this process but using the last verse as the initial word until the poem is complete.
我们的目标是用输入的首字母写一首新诗。 首先,我们将随机选择经文,然后计算这些经文与初始词之间的相似度。 稍后,我们将选择得分最高的诗歌并将其添加到诗歌中。 我们将重复此过程,但将最后一首诗作为首字母,直到这首诗完成为止。
For this specific guide, I choose to use Edgar Allan Poe poems.
对于本指南,我选择使用埃德加·爱伦·坡的诗歌。
资料收集 (Data recollection)
First, we need to collect the poems that will be the source for our project. To do this we will create a web-scraper in Python, that gather the poems of a specific writer( Edgar Allan Poe in my case) from mypoeticside.com site and save them to a .csv file.
首先,我们需要收集诗歌,这些诗歌将成为我们项目的源头。 为此,我们将使用Python创建一个网络抓取工具,从mypoeticside.com网站上收集特定作家(在我的情况下为Edgar Allan Poe)的诗歌并将其保存到.csv文件中。
数据清理和准备 (Data cleaning and preparation)
We will create a function that takes our previously created .csv file and split the poems into verses, based on a regular expression that we choose. Then, we will also erase and replace some undesired characters from the verses ( colons, for example) in order to make the resulting poem looks more well connected and cohesive.
我们将创建一个函数,该函数将使用我们先前创建的.csv文件,并根据我们选择的正则表达式将诗歌分为诗歌。 然后,我们还将删除并替换诗句中一些不需要的字符(例如冒号),以使生成的诗看起来更加紧密和凝聚。
We will save the verses in a new .csv file.
我们将这些经文保存在一个新的.csv文件中。
诗歌生成器 (Poem generator)
The poem generator takes the .csv file from the previous step, an initial word and the number of verses of the new poem as inputs.
诗生成器将上一步中的.csv文件,初始单词和新诗的经文数作为输入。
The process starts with our initial word, which ideally should be a widely used word in order to increase the chances of finding a verse with a high similarity. Then, we randomly select n number of verses from the corpus and calculate the similarity between them and our initial word.
该过程从我们的初始单词开始,理想情况下,该单词应该是广泛使用的单词,以增加找到具有高度相似性的经文的机会。 然后,我们从语料库中随机选择n个经文,并计算它们与初始词之间的相似度。
We will use pretained vectors from the Spacy library, specifically the “en_core_web_md” model, that was trained on the Common Crawl dataset. We will also compute the similarity using the same library function.
我们将使用Spacy库中的保留矢量,特别是在Common Crawl数据集上训练的“ en_core_web_md”模型。 我们还将使用相同的库函数来计算相似度。
Finally, we select the highest score verse and repeat this process until the poem is complete.
最后,我们选择得分最高的诗歌并重复此过程,直到诗歌完成为止。
格式化这首诗 (Formatting the poem)
In order to format correctly our newly created poem, we will create a function that uppercase the first verse letter and add a point to the end of the poem.
为了正确格式化我们新创建的诗,我们将创建一个函数,该函数将首诗首字母大写并在诗尾添加一个点。
结果 (Results)
I personally choose to generate short poems with 4 verses, in order to minimize the chances that the result will lack of coherence.
我个人选择用四节诗作短诗,以最大程度地减少结果缺乏连贯性的可能性。
These are some of the results that I liked the most:
这些是我最喜欢的一些结果:

In general, most of the generated poems are entertaining to read, and even though sometimes the result might lack coherence, most of the cases it goes unnoticed how they were created.
总的来说,大多数诗歌都是有趣的阅读作品,尽管有时结果可能缺乏连贯性,但大多数情况下却没有注意到它们是如何创作的。
Hope you enjoyed this guide and feel free to contact me on Linkedin or Twitter.
希望您喜欢本指南,并随时通过Linkedin或Twitter与我联系。
翻译自: https://towardsdatascience.com/creating-a-poems-generator-using-word-embeddings-bcc43248de4f
词嵌入生成词向量
相关文章:
- 端到端车道线检测_如何使用Yolov5创建端到端对象检测器?
- 深度学习 检测异常_深度学习用于异常检测:全面调查
- 自我监督学习和无监督学习_弱和自我监督的学习-第3部分
- 聊天工具机器人开发_聊天机器人-精致的交流工具? 还是您的客户服务团队不可或缺的成员?...
- 自我监督学习和无监督学习_弱和自我监督的学习-第4部分
- ai星际探索 爪子_探索AI地牢
- 循环神经网络 递归神经网络_递归神经网络-第5部分
- 用于小儿肺炎检测的无代码AI
- 建筑业建筑业大数据行业现状_建筑—第2部分
- 脸部识别算法_面部识别技术是种族主义者吗? 先进算法的解释
- ai人工智能对话了_产品制造商如何缓解对话式AI中的偏见
- 深度神经网络 轻量化_正则化对深度神经网络的影响
- dbscan js 实现_DBSCAN在PySpark上的实现
- 深度学习行人检测简介_深度学习简介
- ai初创企业商业化落地_初创企业需要问的三个关于人工智能的问题
- scikit keras_使用Scikit-Learn,Scikit-Opt和Keras进行超参数优化
- 异常检测时间序列_DeepAnT —时间序列的无监督异常检测
- 机器学习 结构化数据_聊天机器人:根据结构化数据创建自然语言
- mc2180 刷机方法_MC控制和时差方法
- 城市ai大脑_激发AI研究的大脑五个功能
- 神经网络算法优化_训练神经网络的各种优化算法
- 算法偏见是什么_人工智能中的偏见有什么作用?
- 查看-增强会话_会话助手平台-Hinglish Voice等!
- 可解释ai_人工智能解释
- 机器学习做自动聊天机器人_聊天机器人业务领袖指南
- 神经网络 代码python_详细使用Python代码和数学构建神经网络— II
- tensorflow架构_TensorFlow半监督对象检测架构
- 最牛ai波士顿动力上台阶_波士顿动力的位置如何使美国成为人工智能的关键参与者...
- 阿里ai人工智能平台_AI标签众包平台
- 标记偏见_人工智能的偏见
词嵌入生成词向量_使用词嵌入创建诗生成器相关推荐
- python快速生成文字云_在Python中创建文字云或标签云
作者|ISHA5 编译|Flin 来源|analyticsvidhya 介绍 从开始从事数据可视化工作的那一天起,我就爱上它了.我总是喜欢从数据中获得有用的见解. 在此之前,我只了解基本图表,例如条形 ...
- [Python]*词云图生成——默认和图片蒙版词云图
1.生成默认画布词云图 : import wordcloud as wc #导入词云库 import jieba #jieba中文分词库 import matplotlib.pyplot as plt ...
- css 引用嵌入字体不起用_使用CSS嵌入字体
css 引用嵌入字体不起用 Fonts can also be embedded into web pages: that is, the end-user sees the page text in ...
- java怎样生成epub文件_使用Zip库创建Epub文件
如果需要控制ZIP文件中条目的顺序,可以使用DotNetZip和ZipOutputStream . 你说你试过DotNetZip它(epub验证器)给你一个错误抱怨mime类型的东西 . 这可能是因为 ...
- 自然语言处理-词云生成
为什么需要生成词云 对于文本数据有个直观的了解,为后续的工作提供一定的数据可视化分析依据. 词云的生成步骤: 导入工具库 读取数据 清洗数据 统计词频保留前K个词作为词云生成库 绘制词云图 导入工具库 ...
- bert获得词向量_只需几行 Python 代码,即可用 BERT 玩转词嵌入!
作者 | Anirudh_S 译者 | Sambodhi 编辑 | 张之栋 AI 前线导读: 在自然语言处理领域中,诞生于 2018 年末的 BERT 非常的"火热".强悍如 BE ...
- python生成词向量_词向量是如何生成的
终于开了NLP的坑了(`・д・´),这次聊聊词向量是怎样生成的.现在有很多现成的模型,cbow,skip-gram,glove等,在python不同的库里面就可以调用(比如fasttext,genis ...
- 词嵌入、句向量等方法汇总
在cips2016出来之前,笔者也总结多类似词向量的内容,自然语言处理︱简述四大类文本分析中的"词向量"(文本词特征提取)事实证明,笔者当时所写的基本跟CIPS2016一章中总结的 ...
- 【论文阅读】基于层级关系的词向量:双曲空间词嵌入
树状/层级架构的实体集合有其本身特殊的性质,一般的欧式空间的向量表达难以切实表达每个节点间的关系,从而很难在后续的训练中挖掘实体间的关系.因此有些人开始试图在非欧空间中进行词向量建模,双曲空间由于其与 ...
- 词向量与词向量拼接_动态词向量算法—ELMo
传统的词向量模型,例如 Word2Vec 和 Glove 学习得到的词向量是固定不变的,即一个单词只有一种词向量,显然不适合用于多义词.而 ELMo 算法使用了深度双向语言模型 (biLM),只训练语 ...
最新文章
- UIPickerView和UIDataPicker
- C#操作Access数据库中遇到的问题(待续)
- react-native-webview禁止缩放
- python 二分查找_二分查找算法总结
- 用习惯了windows系统要怎样去认识linux系统(一)
- dd命令快速生成一个大文件
- git版本回退:error: Your local changes to the following files would be overwritten by merge
- 雷林鹏分享:PHP MySQL 创建数据库
- 木老师教笨笨课堂——系列讲座(从函数指针到委托) 四、C#的委托
- php trait编译实现,为什么PHP Trait不能实现接口?
- SVN客户端日志无法显示的解决
- python 调用dll中c或c++语言带指针,数组方法
- [UnityShader基础]04.ColorMask
- stm32 串口2空闲中断死机_STM32F373 串口空闲中断问题
- 51.com数十高层离职幕后:3年内乱因扩张失败,互联网营销
- 收发一体超声波测距离传感器模块_咸阳KUS3000 超声波额液位物位计
- 【Alpha阶段】第五次scrum meeting
- 微信小程序使用阿里云物联网API开发物联网应用
- 期刊论文添加基金项目、作者简介
- jenkins-RestAPI调用出现Error 403 No valid crumb was included in the request解决方法
热门文章
- Linux下执行程序出现 Text file busy 提示时的处理方式
- 科学问题表述是机理与机制的区别
- 传智播客 魔法属性 学习
- Atitit java wav 压缩 mp3功能总结 目录 1.1. Lame mp3编码器 1 1.2. 使用时发现错误,不支持Unsupported number of channels: 4
- Atitit.url 汉字中文路径 404 resin4 resin 解决 v2 q329
- paip.银行卡号的发卡行归属地查询
- 如何“加密”你的email地址
- (转)直击马云虞锋闭门对话,3小时谈透未来变革大势,定调千亿美元目标
- (转)软件商在做券商的事,券商在做搬运工的事,第三方正变成第三者
- (转)当你惊讶于才的胜利 它早已“入侵”投资界