SVM实战:如何进行乳腺癌检测
如何在 sklearn 中使用 SVM
SVM 既可以做回归,也可以做分类器。
当用 SVM 做回归的时候,我们可以使用 SVR 或 LinearSVR,即support vector regression
LinearSVR用来处理线性可分的数据,也就是说,使用的线性核函数
如果是针对非线性的数据,需要用到 SVC。在 SVC 中,我们既可以使用到线性核函数(进行线性划分),也可以使用高纬的核函数进行非线性划分。
如何创建一个 SVM 分类器呢?
我们首先使用 SVC 的构造函数:model = svm.SVC(kernel=‘rbf’, C=1.0, gamma=‘auto’),这里有三个重要的参数 kernel、C 和 gamma。
kernel 代表核函数的选择,它有四种选择,只不过默认是 rbf,即高斯核函数。
![]()
线性核函数优点:是在数据线性可分的情况下使用的,运算速度快,效果好。 缺点:不能处理线性不可分的数据。
多项式核函数:可以将数据从低维空间映射到高维空间, 缺点是参数比较多,计算量大
高斯核函数:可以将数据从低维空间映射到高维空间,但相比于多项式核函数来说所需的参数比较少,通常性能也不错。
了解深度学习的同学应该知道 sigmoid 经常用在神经网络的映射中,因此当选用 sigmoid 核函数时,SVM 实现的是多层神经网络。
参数 C 代表目标函数的惩罚系数,惩罚系数指的是分错样本时的惩罚程度,默认情况下为 1.0。当 C 越大的时候,分类器的准确性越高,但同样容错率会越低,泛化能力会变差。
参数 gamma 代表核函数的系数,默认为样本特征数的倒数,即 gamma = 1 / n_features。
我们使用 model.fit(train_X,train_y),传入训练集中的特征值矩阵 train_X 和分类标识 train_y。特征值矩阵就是我们在特征选择后抽取的特征值矩阵(当然你也可以用全部数据作为特征值矩阵)。分类标识就是人工事先针对每个样本标识的分类结果。
我们可以使用 prediction=model.predict(test_X) 来对结果进行预测,传入测试集中的样本特征矩阵 test_X,可以得到测试集的预测分类结果 prediction。
同样我们也可以创建线性 SVM 分类器,使用 model=svm.LinearSVC()。由于 LinearSVC 对线性分类做了优化,对于数据量大的线性可分问题,使用 LinearSVC 的效率要高于 SVC。
如果你不知道数据集是否为线性,可以直接使用 SVC 类创建 SVM 分类器。
如何用 SVM 进行乳腺癌检测
选用的数据集:点击下载
数据集来自美国威斯康星州的乳腺癌诊断数据集
数据集截图展示:
![]()
涉及的字段名解释如下:
![]()
在 569 个患者中,一共有 357 个是良性,212 个是恶性。其中有30个字段,由于按找平均数,最大值,便准差维度描述,所以,实质只有10个特征值。
处理步骤:
1、首先我们需要加载数据源;
2、可视化描述数据,用“完全合一”原则处理数据,根据需要选择特征值(或特征工程)
3、在训练集中训练模型,在测试集中检测模型
# encoding=utf-8
import pandas as pd
import numpy as np
data = pd.read_csv("C://Users//baihua//Desktop//data.csv",encoding='utf-8') #这里要注意,如果文件中有中文,本地文件一定要转换成 UTF-8的编码格式
# 数据探索
# 因为数据集中列比较多,我们需要把 dataframe 中的列全部显示出来
pd.set_option('display.max_columns', None)
print(data.columns)
print(data.head(5))
print(data.describe())
# 将 B 良性替换为 0,M 恶性替换为 1
data['diagnosis']=data['diagnosis'].map({'M':1,'B':0})![]()
#数据清洗
# 将特征字段分成 3 组
import pandas as pd
import numpy as np
features_mean= list(data.columns[2:12])
features_se= list(data.columns[12:22])
features_worst=list(data.columns[22:32])
# 数据清洗
# ID 列没有用,删除该列
#ata.drop(columns=['id'],axis=1,inplace=True)
# 将肿瘤诊断结果可视化
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn import svm
from sklearn import metrics
from sklearn.preprocessing import StandardScaler
plt.show()
# 用热力图呈现 features_mean 字段之间的相关性
corr = data[features_mean].corr()
plt.figure(figsize=(14,14))
# annot=True 显示每个方格的数据
sns.heatmap(corr, annot=True)
plt.show()
![]()
热力图中对角线上的为单变量自身的相关系数是 1。颜色越浅代表相关性越大。
所以你能看出来 radius_mean、perimeter_mean 和 area_mean 相关性非常大,compactness_mean、concavity_mean、concave_points_mean 这三个字段也是相关的,因此我们可以取其中的一个作为代表。
那么如何进行特征选择呢?
我们将相关系数较大的特征中,选择一个进行代表;比如我们选择radius_mean 和 compactness_mean。
这样我们就可以把原来的 10 个属性缩减为 6 个属性,代码如下:
# 特征选择,只选择了平均值这一维度,并且还去除了相关系数较大的特征值
features_remain = ['radius_mean','texture_mean', 'smoothness_mean','compactness_mean','symmetry_mean', 'fractal_dimension_mean'] 对特征进行选择之后,我们就可以准备训练集和测试集:
在训练之前,我们需要对数据进行规范化,这样让数据同在同一个量级上,避免因为维度问题造成数据误差:
# 抽取 30% 的数据作为测试集,其余作为训练集
train, test = train_test_split(data, test_size = 0.3)# in this our main data is splitted into train and test
# 抽取特征选择的数值作为训练和测试数据
train_X = train[features_remain]
train_y=train['diagnosis']
test_X= test[features_remain]
test_y =test['diagnosis']# 采用 Z-Score 规范化数据,保证每个特征维度的数据均值为 0,方差为 1
ss = StandardScaler()
train_X = ss.fit_transform(train_X)
test_X = ss.transform(test_X)``最后我们可以让 SVM 做训练和预测了:创建 SVM 分类器
model = svm.SVC()
用训练集做训练
model.fit(train_X,train_y)
用测试集做预测
prediction=model.predict(test_X)
print('准确率: ', metrics.accuracy_score(prediction,test_y))
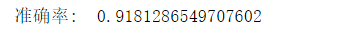提问:本例中我们使用默认核函数,请你用 LinearSVC,选取全部的特征(除了 ID 以外)作为训练数据,看下你的分类器能得到多少的准确度呢?上例中,只换核函数:
model = svm.LinearSVC()
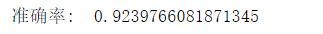
现在,我们将原来平均值特征,换成所有的特征值,特征选择
print(data.columns)#去除无用id,和结果指标’diagnosis’,剩下的作为我们的特征值
features_remain = [‘radius_mean’, ‘texture_mean’, ‘perimeter_mean’,
‘area_mean’, ‘smoothness_mean’, ‘compactness_mean’, ‘concavity_mean’,
‘concave points_mean’, ‘symmetry_mean’, ‘fractal_dimension_mean’,
‘radius_se’, ‘texture_se’, ‘perimeter_se’, ‘area_se’, ‘smoothness_se’,
‘compactness_se’, ‘concavity_se’, ‘concave points_se’, ‘symmetry_se’,
‘fractal_dimension_se’, ‘radius_worst’, ‘texture_worst’,
‘perimeter_worst’, ‘area_worst’, ‘smoothness_worst’,
‘compactness_worst’, ‘concavity_worst’, ‘concave points_worst’,
‘symmetry_worst’, ‘fractal_dimension_worst’]
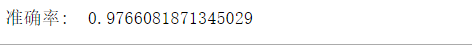SVM实战:如何进行乳腺癌检测相关推荐
- R语言生存分析COX回归分析实战:以乳腺癌数据为例
R语言生存分析COX回归分析实战:以乳腺癌数据为例 目录
- 谷歌医疗AI又有新进展:转移性乳腺癌检测准确率达99%
李根 发自 凹非寺 量子位 报道 | 公众号 QbitAI Google AI大战乳腺癌,现在进入2.0时代. 在最新公布的进展中,Google深度学习算法在转移性乳腺癌的检测精度测试中,准确率达到 ...
- ASP.NET Google Maps Javascript API V3 实战基础篇一检测用户位置
ASP.NET Google Maps Javascript API V3 实战基础篇一检测用户位置 对于一些基本的东西,google maps JavaScript api v3 文档已经讲解得足够 ...
- Python实战项目:高血压检测项目调查问卷接口的测试
Python实战项目:高血压检测项目调查问卷接口的测试 在前面的Python实战项目中介绍过高血压检测项目和自动化综合测试的相关内容,那么如何结合自动化综合测试的内容进行高血压检测项目的测试呢,尤其是 ...
- 机器学习——K近邻算法及乳腺癌检测分类
一.引言 KNN可用于分类和回归,用于分类时是多分类方法. 注意:由于此方法根据预测点近邻的各类点的个数多少来确定该预测点的类别,因此原始类别数据不均衡,将严重影响最终分类效果. 二.KNN分类思想 ...
- 【Android自动化】AccessibilityService实战-微信僵尸好友检测
0x1.引言 上节我们学习了AccessibilityService无障碍的基础知识,并写了一个简单的微信自动登录的小案例.相信大家都意犹未尽,所以本节安排一波实战 -- 微信僵尸好友检测. 啥是 僵 ...
- HOG人体特征提取+SVM分类器训练进行人体检测
1.HOG特征: 方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子.它通过计算和统计图像局部区域的 ...
- 信用卡欺诈检测python_Python机器学习实战:信用卡欺诈检测
原标题:Python机器学习实战:信用卡欺诈检测 本文作者:唐宇迪 ,文末有彩蛋!本期送书python! 故事背景:原始数据为个人交易记录,但是考虑数据本身的隐私性,已经对原始数据进行了类似PCA的处 ...
- 【AI实战】微小目标检测模型MMDet-RFLA--训练环境从零开始搭建
[AI实战]微小目标检测模型MMDet-RFLA--训练环境搭建 RFLA介绍 环境搭建 安装依赖 参考 RFLA介绍 官方连接 https://github.com/Chasel-Tsui/mmde ...
最新文章
- android 上传pdf文件,Android 加载PDF文件
- 用CSS 给网页装潢[3] -构造文本
- 开机启动加载驱动过程中调用PostMessage函数出错
- OceanBase如何解决支付宝数据库的高一致性
- JDK 14 调试神器了解一下?
- 区块链技术沙龙最全回顾:我们需要做怎样的区块链?
- 重要的ui组件——Behavior
- sql server linux性能,详细了解SQL Server 2008性能和性能优化
- C#中的引用传递、值传递
- Android 面试题总结
- git、cocoapod组件化开发常用命令
- 用setTimeout代替setInterval
- torchvision中Transform的normalize参数含义, 自己计算mean和std,可视化后的情况,其他必要的数据增强方式
- 容器技术Docker K8s 18 容器服务ACK基础与进阶-容器网络管理
- 电脑闪光代码_清华姚班毕业生开发新特效编程语言,99行代码实现冰雪奇缘,网友:大神厉害了!创世的快乐...
- (三)五款常用的java开发工具(快来看看吧)
- php怎么在表格里插图片大小,如何批量插入图片到Word文档表格中并自动排版调整尺寸...
- Windows 2000 单词表
- 使用EXCEL计算日期差时间差
- 03独立按键控制LED移动
热门文章
- 洛谷——P1177 【模板】快速排序
- 18行代码AC_排序 HDU - 1106(sstream简单解法)
- git stash 强制恢复_git操作与分支管理规范
- python笔记之序列(list的基本使用和常用操作)
- mac开启64位内核
- Eclipse 中修改android的Default debug keystore 搬家、备份后启动Android PANIC :Could not open D:\java2\android\and
- string.h包含哪些函数_多个函数组合拳专治不规则时间转化难题|Excel134
- python函数内部返回的值_Python中函数的返回值示例浅析
- python博客开发教程_Django 博客开发教程 12 - 评论
- c++builder启动了怎么停止_App 竟然是这样跑起来的 —— Android App/Activity 启动流程分析...