2、MapReduce的job提交启动过程
2019独角兽企业重金招聘Python工程师标准>>> 
1、MR任务提交流程图
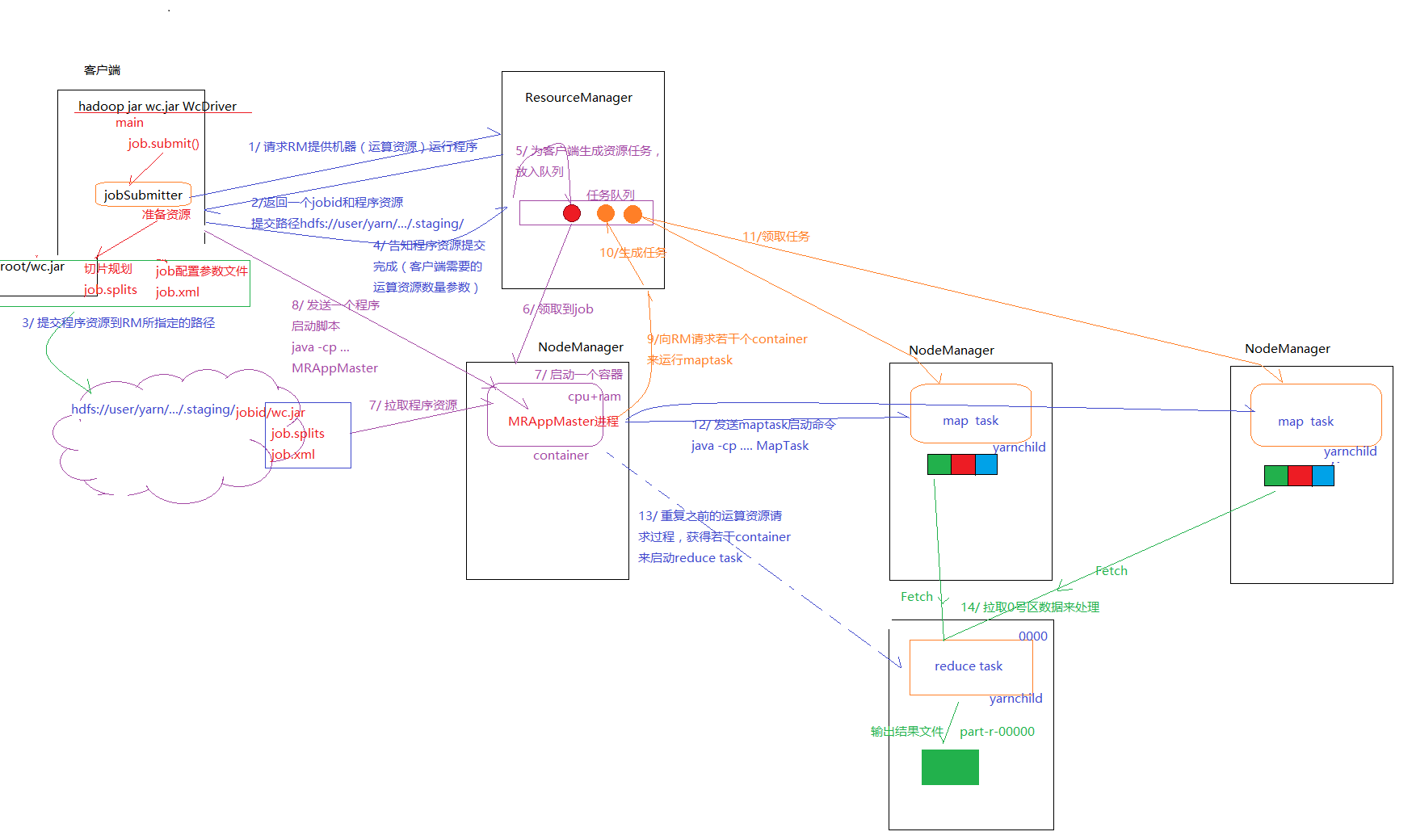
2、流程分析
1、首先在提交job之前,FileInputFormat调用getsplits();获得分片信息,并且序列化为一个job.split文件。接着再讲job的配置信息转变成一个xml文件。 =>所以总共有job.jar、job.split、job.xml三个文件
2、第一步准备好后,向resourceManager请求提供机器运行程序。
3、resourceManager向客户端返回一个job文件上传的路径XXX/staging和一个jobID。
4、Client往这个路径上传已经准备好的那三个文件。接这个告诉resourceManager已经上传完成,并且告知需要的资源。
5、resourceManager生成一个资源任务放入resourceManager的任务队列中,这个资源任务描述了:作业存放的路径、需要的运行资源等。
6、由NodeManager轮询任务列表,获得这个任务,根据资源任务信息创建一个容器,并且将job作业信息下载下来,接着通知resourceManager已经下载完成。
7、resourceManager通知Client,资源准备好了,处理这个任务的NameManager的iP和端口是多少。
8、Client向这个NodeManager发送启动MRAppMaster的命令脚本,启动Mrappmaster。
9、MrAppMaster启动后,读取job.xml,job.split文件,知道需要多少mapTask和reduceTask进程。而且每个Task的资源需求,接着向ResourceManager请求这些资源。
10、ResourceManager同样创建一些资源任务,放入任务队列中。等待NodeManager轮询处理。
11、NanoManager拿到这个MapTask任务后,创建一个容器并且下载job.jar、job.split、job.xml文件,后向resourceManager返回确认。resourceManager最后想MrappMaster返回准备完成的信息。
12、MrAppMaster向NanoManager发送启动MapTask的命令脚本启动MapTask。
13、重复MapTask过程的资源请求步骤,请求ReduceTask。
3、总结
job运行有两种方式:
1、(开发debug模拟阶段)直接在idea中运行,(不需要打包) 利用hadoop 的client jar包,其中有一个localRunner.jar来模拟。但是这种方式必须在电脑上安装hadoop,并且必须在安装目录下bin文件夹中加入如下两个文件

下载地址:https://download.csdn.net/download/luoyepiaoxin/8860033
引入maven依赖
-- 必须引入依赖<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-common</artifactId><version>2.6.4</version></dependency>-- 如果想直接读取的是HDFS上的文件,则需要引入依赖<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>2.6.4</version></dependency>-- 并且在代码中指定HDFS//指定HDFS的实现方式设置默认文件系统为HDFS,同时伪装自己的身份为rootconf.set("fs.hdfs.impl",org.apache.hadoop.hdfs.DistributedFileSystem.class.getName());conf.set("fs.default.name", "hdfs://cmAgent2:8022");System.setProperty("HADOOP_USER_NAME", "root");2、(生产部署阶段)在idea中打包好,然后提交到集群中,最后使用hadoop jar XXXX。直接在集群中启动。
注意:在打包的时候需要将上面的那几行代码注释
总体依赖如下<dependencies><!--这个是必须的,common里面提供了rpc等功能--><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.6.4</version></dependency><!--这个也是必须的--><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>2.6.4</version></dependency><!--这个是本地debug运行才需要的--><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-common</artifactId><version>2.6.4</version></dependency><!--这个是本地debug的时候,需要读取HDFS上的文件才需要,如果是读取本地文件则不需要--><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>2.6.4</version></dependency></dependencies>
转载于:https://my.oschina.net/liufukin/blog/795826
2、MapReduce的job提交启动过程相关推荐
- zookeeper源码分析之一服务端启动过程
zookeeper简介 zookeeper是为分布式应用提供分布式协作服务的开源软件.它提供了一组简单的原子操作,分布式应用可以基于这些原子操作来实现更高层次的同步服务,配置维护,组管理和命名.zoo ...
- CentOS6启动过程总结与GRUB问题修复
转载地址:https://www.2cto.com/net/201609/549564.html 一.CentOS 6 的启动流程 第一步:加电自检(POST) 主要检查硬件设备是否存在并能正常运行, ...
- Tomcat源码解析三:tomcat的启动过程
Tomcat组件生命周期管理 在Tomcat总体结构 (Tomcat源代码解析之二)中,我们列出了Tomcat中Server,Service,Connector,Engine,Host,Context ...
- 你所不知道的SQL Server数据库启动过程(用户数据库加载过程的疑难杂症)
转http://www.cnblogs.com/zhijianliutang/p/4100103.html 前言 本篇主要是上一篇文章的补充篇,上一篇我们介绍了SQL Server服务启动过程所遇到的 ...
- laravel的启动过程解析(转)
转载地址:https://www.cnblogs.com/lpfuture/p/5578274.html 如果没有使用过类似Yii之类的框架,直接去看laravel,会有点一脸迷糊的感觉,起码我是这样 ...
- Linux开机启动过程(3):显示模式初始化和进入保护模式
内核启动过程,第三部分 本文是在原文基础上经过本人的修改. 显示模式初始化和进入保护模式 这一章是内核启动过程的第三部分,在前一章中,我们的内核启动过程之旅停在了对 set_video 函数的调用(这 ...
- Linux开机启动过程(2):内核启动的第一步
在内核安装代码的第一步 本文是在原文基础上经过本人的修改. 内核启动的第一步 在上一节中我们开始接触到内核启动代码,并且分析了初始化部分,最后我们停在了对main函数(main函数是第一个用C写的函数 ...
- [20160229]探究oracle的启动过程.txt
[20160229]探究oracle的启动过程.txt --昨天自己研究了sys.bootstrap$,链接http://blog.itpub.net/267265/viewspace-2016219 ...
- 实验三:跟踪分析Linux内核的启动过程 ----- 20135108 李泽源
实验要求: 使用gdb跟踪调试内核从start_kernel到init进程启动 详细分析从start_kernel到init进程启动的过程并结合实验截图撰写一篇署名博客,并在博客文章中注明" ...
最新文章
- idea实用快捷键_idea万能快捷键,你不知道的17个实用技巧!!!
- 新手攻略熔炉_【新手攻略】快速入门
- linux 连接wifi wpa2,RHEL等Linux系统使用wpa_supplicant以WPA-PSK/WPA2-PSK连接WIFI
- JS的DOM和BOM
- php正文重复度,百度如何判断网页文章的重复度?两个页面相似度确认方法介绍...
- 【实体对齐·HGCN】Jointly Learning Entity and Relation Representations for Entity Alignment
- python的精髓_教你玩转Python!一文总结Python入门到精髓的窍门
- bootstrap table的属性sidePagination设置不当导致数据不显示
- idea 2018 3.3版本破解
- vi 编辑器使用错误
- 计算机键盘中复制粘贴快捷键,电脑复制粘贴快捷键
- python数据分析-numpy学习
- “双一流”哈尔滨工程大学成立人工智能有关学院,打造一流学科群!
- 参考文献中期刊/会议如何缩写
- python 组合数字和字符_python无限生成不重复(字母,数字,字符)组合的方法
- 马克思主义哲学笔记(二)
- 汽车保险客户分类问题
- 用Python试了试人脸识别
- [运维] proxmox ve 与 vSphere 对比
- JLINK的SW调试模式连线方式