SQL Server中的批处理排序和嵌套循环
Continuing my blog post series after 24HOP Russia “Query Processor Internals – Joins”. In this (and the next one) blog post, we will talk about the Nested Loop Post Optimization Rewrite optimizations.
在24HOP Russia“查询处理器内部-联接”之后,继续我的博客文章系列 。 在这篇(以及下一篇)博客文章中,我们将讨论嵌套循环帖子优化重写优化。
Some of you may know that a Nested Loop join algorithm preserves order of the outer table.
你们中的某些人可能知道嵌套循环联接算法保留了外部表的顺序。
Here is Craig’s Freedman (from the Query Optimizer Team, Microsoft) post:
这是Craig的Freedman(来自Microsoft的查询优化器团队)帖子:
Let’s first setup some test data.
让我们首先设置一些测试数据。
create database nldb;
go
use nldb;
go
create table dbo.SalesOrder(SalesOrderID int identity primary key, CustomerID int not null, SomeData char(30) not null);
go
with nums as (select top(1000000)rn = row_number() over(order by (select null))frommaster..spt_values v1,master..spt_values v2,master..spt_values v3
)
insert dbo.SalesOrder(CustomerID, SomeData)
select rn%500000, str(rn,30) from nums;
go
create index ix_CustomerID on dbo.Salesorder(CustomerID);
go
Now we will issue two queries. I use an index hint for demonstration purposes only, there might be no hint needed in real life for such a situation.
现在,我们将发出两个查询。 我仅将索引提示用于演示目的,在现实生活中可能不需要这种提示。
select * from dbo.SalesOrder with(index(ix_CustomerID)) where CustomerID < 500;
select * from dbo.SalesOrder with(index(ix_CustomerID)) where CustomerID < 1000;
The plans are almost the same:
计划几乎相同:
But the results:
但是结果:
Obviously, the sort order is different. That is one of the examples showing, that you should never rely on the “default” sort order, as there is no such thing. The only way to get a desired sort order is to add an explicit outer order by in your query.
显然,排序顺序是不同的。 这是显示示例之一,您不应该依赖“默认”排序顺序,因为没有这种事情。 获得所需排序顺序的唯一方法是在查询中添加显式外部顺序。
Ok, but still, why the sort order is different.
好的,但是为什么排序顺序不同。
隐式批处理排序和嵌套循环运算符 (Implicit Batch Sort and Nested Loop operator)
Let’s examine the Nested Loop operator details.
让我们检查嵌套循环运算符的详细信息。
You may notice the Optimized property set to true. That is not very informative, what does it mean – “optimized”. Luckily, we have an explanation in the Craig Freedman’s blog for Nested Loop:
您可能会注意到Optimized属性设置为true。 这不是非常有用的信息,它的意思是“优化”。 幸运的是,我们在Craig Freedman的Blog中为Nested Loop做了一个解释:
What I love in Craig’s posts, that every insignificant (from the first glance) word has a solid meaning.
我喜欢克雷格(Craig)的帖子,每个微不足道的词(乍看之下)都有明确的含义。
The catch, even for an experienced users, is that both plans has an “Optimized=true” keyword in the Nested Loop Join plan operator, but only in the second query, the reordering is done.
即使对于有经验的用户,要注意的是, 两个计划在Nested Loop Join计划运算符中都有一个“ Optimized = true”关键字,但是仅在第二个查询中才进行重新排序。
Why do the reordering?
为什么要重新排序?
The purpose is to minimize random access impact. If we perform an Index Seek (with a partial scan, probably) we read the entries in the index order, in our case, in the order of CustomerID, which is clearly seen on the first result set. The index on CustomerID does not cover our query, so we have to ask the clustered index for the column SomeData, and actually, we perform one another seek, seeking by the SalesOrderID column. This is a random seek, so what if, before searching by the SalesOrderID we will sort by that key, and then issue an ordered sequence of Index Seeks, turning the random acces into the sequential one, wouldn’t it be more effective?
目的是最小化随机访问的影响。 如果执行索引查找(可能会进行部分扫描),则将按索引顺序(在我们的情况下,按照CustomerID的顺序)读取条目,这在第一个结果集中可以清楚地看到。 CustomerID上的索引不涵盖我们的查询,因此我们必须向聚集索引查询SomeData列,实际上,我们通过SalesOrderID列进行另一次搜索。 这是一个随机查找,因此,如果在按SalesOrderID搜索之前,我们将按该键排序,然后发出一个有序的Index Seeks序列,将随机访问转换为顺序访问,会不会更有效?
Yes, it would in some cases, and that is what “optimized” property tells us about. However, we remember, that it is not necessarily leads to the real reordering. As for comparing the real impact, I will refer you to the actual Craig’s post or leave it as a homework.
是的,在某些情况下会这样,这就是“优化”属性所能说明的。 但是,我们记得,它不一定会导致真正的重新排序。 至于实际影响的比较,我将把您推荐给实际的Craig职位,或者将其留作家庭作业。
How it is implemented inside SQL Server?
它如何在SQL Server内部实现?
Let’s issue the query with some extra trace flags, showing the output physical tree (the tree of the physical operators) and the converted tree (the tree of the physical operators converted to a plan tree and ready to be compiled into the executable plan by the Query Executor component).
让我们向查询发出一些额外的跟踪标志,以显示输出物理树(物理运算符的树)和转换后的树(物理运算符的树已转换为计划树,并准备被编译为可执行计划)。查询执行程序组件)。
select * from dbo.SalesOrder with(index(ix_CustomerID)) where CustomerID < 1000
option(recompile, querytraceon 3604, querytraceon 8607, querytraceon 7352
);
The first one (1) is the output tree of the physical operators, the result of the optimization. The second one (2) is the converted tree ready to become a plan, for the execution compilation.
第一个(1)是物理运算符的输出树,是优化的结果。 第二个(2)是准备好成为执行编译计划的已转换树。
Notice the in the first one we have no mysterious nodes, like “??? ???”. But we have two of them in the second one. That is the result of Post Optimization Rewrites phase introducing some extra optimizations for the Nested Loops.
请注意,在第一个中,我们没有神秘的节点,例如“ ???”。 ???”。 但是第二个中有两个。 这是后期优化重写阶段的结果,为嵌套循环引入了一些额外的优化。
The node (a) is for the optimization – called “Prefetching” and displayed as “WithUnorderedPrefetch = true” in the plan properties. This is not the topic of this post, but you may refer to the useful links later in this post to read more about it.
节点(a)用于优化-称为“预取”,并在计划属性中显示为“ WithUnorderedPrefetch = true”。 这不是本文的主题,但是您可以参考本文后面的有用链接以了解更多信息。
The second one (b) is for the Batch Sort – our case.
第二个(b)用于批次排序-我们的情况。
You may be interested to know if there is a special iterator for that mysterious node in the executable plan, and there is one. It is called CQScanBatchSortNew. Here how it looks like in the WinDbg call stack.
您可能想知道可执行计划中是否有针对该神秘节点的特殊迭代器,并且有一个。 它称为CQScanBatchSortNew。 这里是WinDbg调用堆栈中的外观。
The marked area represents a call to the iterator CQScanBatchSortNew which is responsible for the “OPTIMIZED” property and sorting optimization.
标记的区域表示对迭代器CQScanBatchSortNew的调用,该迭代器负责“ OPTIMIZED”属性和排序优化。
Below you may also see the Prefetch iterator (CQScanRangePrefetchDelay), mentioned above.
在下面,您可能还会看到上述的预取迭代器(CQScanRangePrefetchDelay)。
Not pretending to the any drawing skills, but to be clear, the artificial plan, with those artificially drawn operators might look like this.
不假装任何绘图技能,但要明确一点,那些人工绘制的操作员的人工计划可能看起来像这样。
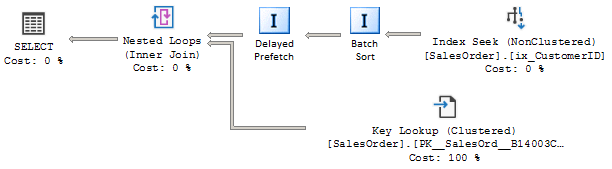
显式批量排序和嵌套循环 (Explicit Batch Sort and Nested Loop)
The implicit batch sort optimization is a lightweight optimization, which is done on the Post Optimization Rewrite phase; however, that kind of optimization might be done before, by explicitly introducing the Sort operator. The decision to do one or another is a cost based decision.
隐式批处理排序优化是一种轻量级优化,它在后期优化重写阶段完成; 但是,可以通过显式引入Sort运算符来进行这种优化。 做一个或另一个的决定是基于成本的决定。
First, let’s fool the optimizer to pretend there is much more rows (just to not create a huge test database):
首先,让我们愚弄优化器以假装还有更多行(只是为了不创建庞大的测试数据库):
update statistics dbo.SalesOrder with rowcount = 10000000, pagecount = 400000
Now consider this example:
现在考虑以下示例:
select * from dbo.SalesOrder with(index(ix_CustomerID)) where CustomerID < 10000
option(recompile, maxdop 1, querytraceon 3604, querytraceon 8607
);
I’m using the hints again only for the easy demonstration, it is not necessary in the real life.
我仅将这些提示用于简单演示,在现实生活中没有必要。
The plan is now:
现在的计划是:
The sort operator properties clearly show that the order is a clustered index order.
排序运算符属性清楚地表明该顺序是聚簇索引顺序。
Unlikely the OPTIMZED property and implicit Batch Sort, this kind of decision is done before the Post Optimization Rewrite, and we may see the explicit sort operator in the output physical tree.
与OPTIMZED属性和隐式批处理排序不同,此类决策是在后优化重写之前完成的,我们可能会在输出物理树中看到显式排序运算符。
Though they are doing the similar function and serve similar goals, they are slightly different
尽管它们执行相似的功能并达到相似的目标,但它们还是略有不同
- The implicit sort is done before the Post Optimization Rewrite 隐式排序在后期优化重写之前完成
- The implicit batch sort may not spill to disk and is net compromise between the explicit sort and not sorted requests 隐式批处理排序可能不会溢出到磁盘,并且是显式排序和未排序请求之间的网络折衷
- Different TF to manage them =) 不同的TF来管理它们=)
魔法TF (Magical TFs)
There are three of them. All are well known but probably needs some clarification.
一共有三个。 众所周知,但可能需要澄清。
TF 2340 – Disable Nested Loop Implicit Batch Sort on the Post Optimization Rewrite Phase
TF 2340 –在后期优化重写阶段禁用嵌套循环隐式批量排序
TF 8744 – Disable Nested Loop Prefetching on the Post Optimization Rewrite Phase
TF 8744 –在优化后的重写阶段禁用嵌套循环预取
TF 9115 – Disable both, and not only on the Post Optimization but the explicit Sort also
TF 9115 –不仅禁用后优化,还禁用显式排序
All of them, except 2340 are undocumented, so not should be used in production, be careful.
除2340外,所有这些文件均未记录,因此请勿在生产中使用,请小心。
That is all for that post.
这就是那个帖子的全部。
There are some other batch sort optimization applications, but not to do the re-write, I’d rather provide the links to further reading and some additional relevant and interesting material.
还有其他一些批处理排序优化应用程序,但不进行重写,我希望提供进一步阅读的链接以及一些其他相关和有趣的材料。
Previous article in this series:
本系列的上一篇文章:
- Hash Join Execution Internals哈希联接执行内部
翻译自: https://www.sqlshack.com/batch-sort-and-nested-loops/
SQL Server中的批处理排序和嵌套循环相关推荐
- sql server中字符集和排序规则到底什么关系
--SQLSERVER 中的排序规则 服务器>数据库>表列 --------------------------------- 排序规则简介 ----------------------- ...
- Sql Server 中汉字处理排序规则,全角半角
--1. 为数据库指定排序规则 CREATE DATABASE db COLLATE Chinese_PRC_CI_AS GO ALTER DATABASE db COLLATE Chinese_PR ...
- Sql Server 中 Order by排序(升序,降序)
--AddTime 升序,ID 升序 select * from DS_Finance ORDER BY AddTime,ID; --AddTime 升序,ID降序 select * from DS_ ...
- SQL Server中使用自定义指定顺序排序
SQL Server中使用自定义指定顺序排序 原文:SQL Server中使用自定义指定顺序排序 比如需要对SQL表中的字段NAME进行如下的排序: 张三(Z) 李四(L) 王五(W) 赵六(Z) 如 ...
- 十步优化SQL Server中的数据访问
故事开篇:你和你的团队经过不懈努力,终于使网站成功上线,刚开始时,注册用户较少,网站性能表现不错,但随着注册用户的增多,访问速度开始变慢,一些用户开始发来邮件表示抗议,事情变得越来越糟,为了留住用户, ...
- SQL Server中的执行引擎入门
简介 当查询优化器(Query Optimizer)将T-SQL语句解析后并从执行计划中选择最低消耗的执行计划后,具体的执行就会交由执行引擎(Execution Engine)来进行执行.本文旨在分类 ...
- 从TXT文本文档向Sql Server中批量导入数据
因为工作的需要,近期在做数据的分析和数据的迁移.在做数据迁移的时候需要将原有的数据导入到新建的数据库中.本来这个单纯的数据导入导出是没有什么问题的,但是客户原有的数据全部都是存在.dat文件中的.所以 ...
- SQL server 中SQL语句实战操作
学习网址链接: https://www.w3school.com.cn/sql/sql_top.asp 学习案例链接: https://wenku.baidu.com/view/720053b459f ...
- SQL Server中关于跟踪(Trace)那点事(转载)
前言 一提到跟踪俩字,很多人想到警匪片中的场景,同样在我们的SQL Server数据库中"跟踪"也是无处不在的,如果我们利用好了跟踪技巧,就可以针对某些特定的场景做定向分析,找出充 ...
最新文章
- 使用内存盘 格式化文件系统以及部署ceph-osd
- 【JQUBAR1.1】jQuery 插件发布
- (转)start_kernel 代码分析
- Source Insight中的多行注释
- 关于 varchar2 的最大长度
- 阿里NIPS 2017论文解读:如何降低TensorFlow训练的显存消耗?
- SAP Spartacus HTTP请求的错误处理机制
- 10 3 java_10.3 UiPath如何调用Java
- entity什么类型_「知否」知识地图和知识图谱是什么?
- HeadFirstJava——6_Java API
- querydsl动态 sql_QueryDSL-JPA
- 为什么要了解和使用拉姆达——走进Java Lambda(〇)
- Python 实战之淘宝手机销售分析(数据清洗、可视化、数据建模、文本分析)
- 如何做一名有趣的家长?
- iframe嵌套视频,视频全屏用不了
- RGB与HSB之间转换
- 关于桌面程序被安全软件误判为HEUR:Trojan.Win32.Generic的解决方案
- 按Backspace键删除时,会出现^H
- 谷歌浏览器保存密码,input输入框密码自动填充
- Xilinx Vivado定制IP核调用和除法器IP核的latency和resource分析