BNN - 基于low-bits量化压缩的跨平台深度学习框架
写在最前
本文介绍阿里IDST部门研发、基于low-bits量化压缩的深度学习框架BNN(Binary Neural Network),BNN具有以下特点:
1) 跨平台:BNN可以在不同的主流硬件平台上进行部署,包括ARM系列移动端处理器、Intel系列服务器以及正在开发中的NVidia的图形处理器;
2)压缩比高:使用了自研发low-bits量化压缩技术,在算法精度几乎无损的前提下能达到40-100倍压缩率,而且我们也提供无需重新训练的压缩方式,极大简化了迭代周期;
3)内嵌高度优化的矩阵运算库GEMMi8:和市面多种主流计算库相比GEMMi8有多至4倍的性能优势;
4)框架灵活:无第三方依赖,BNN定制化后大小不超过200K。
基于以上技术,BNN的手机端加速效果比市面上同类产品的快2-3倍;
AI趋势
近年来,人工智能已经逐渐融入到我们的日常生活,而深度学习作为其中一个分支,在计算机视觉、语音识别等领域也取得了重大突破。深度学习的开源框架也层出不穷,如Caffe[1],Tensorflow[2]等等。与此同时,各大芯片巨头(Intel、NVidia、Xilinx、ARM)也在硬件加速领域动作频频,纷纷推出针对人工智能加速的解决方案,连互联网巨头谷歌也花巨资研发了自己的硬件加速芯片TPU。
另一方面,如图1所示,随着移动互联网、IoT的蓬勃发展,数据采集、传送量日益增大,云和端的数据传送瓶颈已经浮现,传统的本地采集+云处理方式已经不能满足未来发展的需求,所以为了减轻云端服务的压力,同时满足良好的用户体验、兼顾保护用户隐私,行业领头企业决定将计算任务适当前移,纷纷推出自己的移动端深度学习框架,如脸书的Caffe2Go,腾讯的NCNN,百度的MDL。与服务端不同,移动端深度学习框架受限于严格的设备硬件,在框架大小、性能、内存消耗、模型大小方面都有很高的要求。
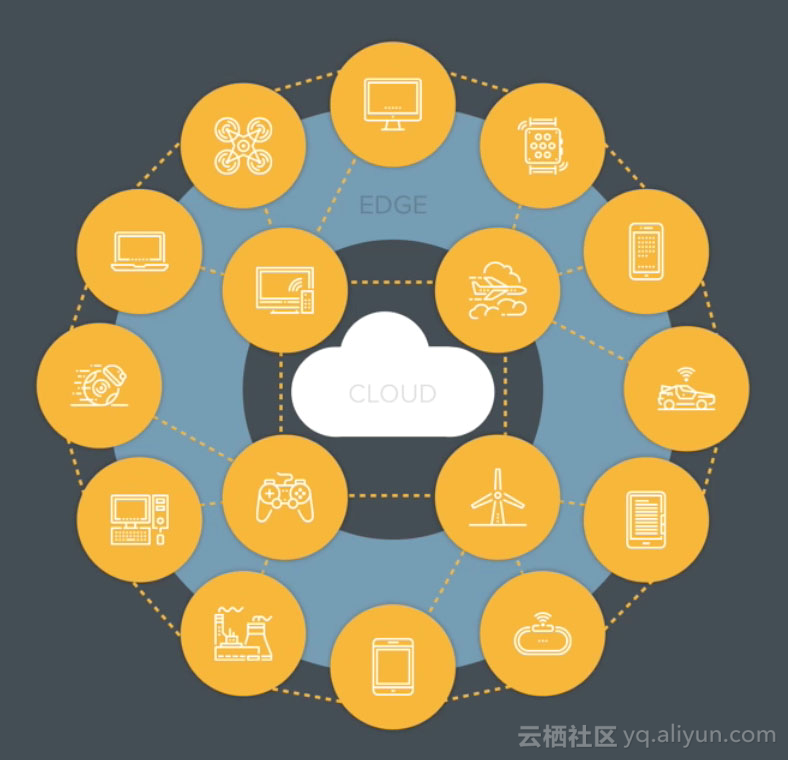
图1:边缘计算(云和端之间的数据传输将成为瓶颈)
AI开发人员一方面需要设计端到端的算法方案,对算法效果进行调优。另一方面需要调研纷繁复杂的深度学习框架和硬件平台组合,确定前向方案,并为了达到上线的性能和成本要求进一步调优,此时往往会涉及到重新调整端到端算法方案,加长了产品迭代周期。为了解决这个瓶颈和痛点,我们提出了跨硬件平台的深度学习前向框架,便于开发者使用和部署,同时针对核心量化压缩以及矩阵运算进行了深度优化,从而在性能上有了进一步的保障。
BNN && GEMMi8
为了解决上述问题,我们提出了一套基于量化压缩的跨平台深度学习框架:BNN(Binary Neural Network),一个高度优化的轻量深度学习前向框架,使用C/C++语言开发,跨平台,支持读取Caffe模型文件,主要处理卷积神经网络。与市面上大多数移动端解决方案不同,我们的量化压缩技术不仅针对模型的权重,还涉及到输入的特征向量压缩。针对这一特性我们在模型文件和内存大小得到裁剪的同时还对框架的性能做了大量优化。
另一方面,矩阵乘法是深度学习的核心,也是神经网络中耗时最多的步骤。例如在卷积神经网络中,70%以上的耗时花在卷积层,而在很多深度学习框架中卷积过程被转化成了矩阵乘法的数学模型,因此我们针对性地设计了一套矩阵计算库GEMMi8(General Matrix Multiplication for Int8),内嵌在BNN框架中。GEMMi8是一个低精度矩阵乘法库,兼容x86/ARM架构,可运行在云端、移动端,以及开发中的GPU图形处理器。
在BNN和GEMMi8的性能优化方面我们做了很多工作,性能的评测上我们将GEMMi8与市面上大量的数学计算库在不同架构上做了矩阵乘法性能对比,包括Tensorflow默认的计算库Eigen[3]和在移动端有很高评价、Caffe使用的计算库OpenBLAS[4],Arm公司自研的Arm Compute Library[5],还有大名鼎鼎的Intel MKL[6],Google的Gemmlowp[7]。评测选择了10个矩阵乘法规模作为基准用例,具体见附录,单线程环境,大部分数据来自实际神经网络中的矩阵大小,评测结果参见图2和图3。
可以看出矩阵乘法方面,无论是x86架构还是移动端的ARM,GEMMi8相比其它计算库都明显的性能优势(除了用例8,这是由于我们暂时还没有根据矩阵的形状做针对性的优化),高效的矩阵运算库大大缩短了BNN处理神经网络阶段的耗时。
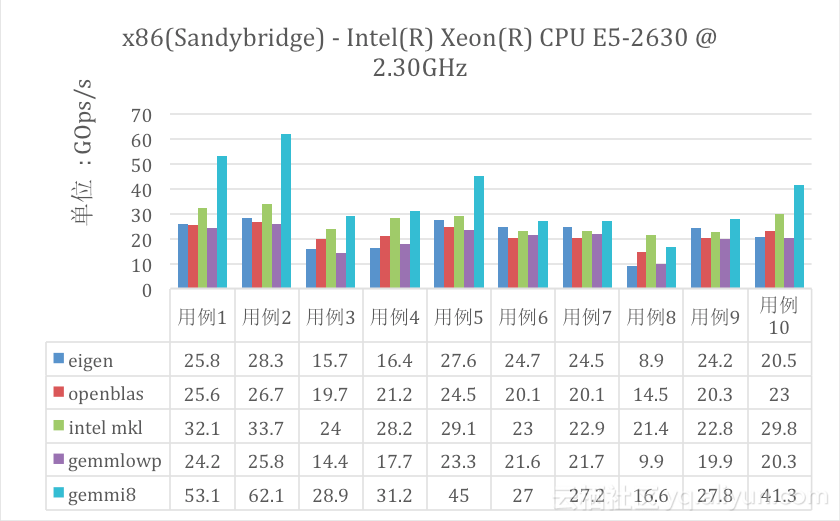
图2: x86架构矩阵乘法评测
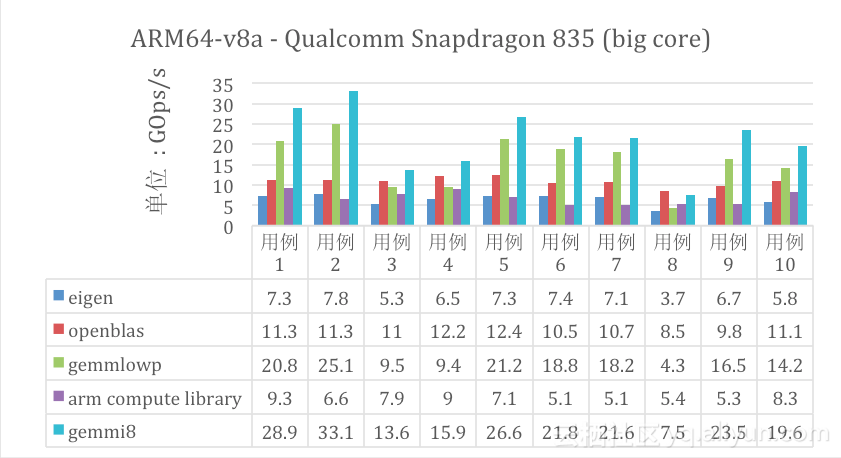
图3: ARM架构矩阵乘法评测
总体来说,BNN具有以下几个特性(图4):
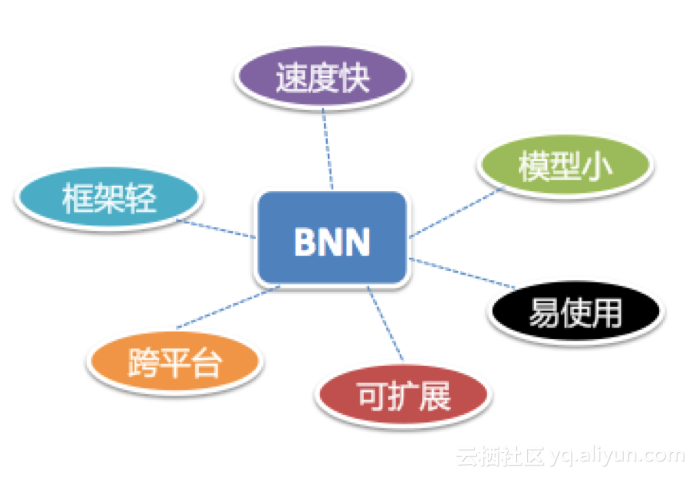
图4: BNN六大特性
1. 压缩率高
在模型压缩方面,我们采用低精度整型代替浮点数据类型,再结合密集存储等技术,在算法准确率几乎无损的前提条件下可以达到40-100倍的压缩率。而且我们也提供无需重新训练的压缩方式,极大简化了迭代周期。目前我们已将模型压缩方案在IDST的Gauss平台服务化,用户可以将训练好的模型上传至云端自动压缩,或者直接在Gauss训练模型,后者的精度更高。关于模型压缩相关算法[8] ,我们后续会单独介绍。
2.速度快
我们投入了大部分精力在性能优化上,主要使用的技术有SIMD,多线程,矩阵分块,cache命中率,流水线,指令预取等等,其中核心模块根据不同的硬件架构使用向量化的汇编语言编写,性能业界领先。我们在实际项目中发现,某些场景使用FP32数据类型的传统深度学习框架优化到一定程度后,性能的瓶颈往往在内存读写(Memory Bound),当内存带宽占满后即使处理器提供更高效的运算指令(如浮点数FMA)也无法进一步获得加速。而量化后的低精度整数占用内存远小于FP32,可以获得更高的传输效率,避免CPU在访存上过多地等待。关于BNN在移动端的性能评测,我们将BNN和基于OpenBLAS的Caffe以及腾讯公司的NCNN框架做了对比。考虑到当前移动端硬件配置以摩尔定律递增,不难猜测在不久的将来运行在移动设备的网络模型也会越来越大,我们采用了resnet18网络模型做图像识别,如图5所示,BNN with gemmi8的网络前向性能,是市面上同类产品的2-3倍。
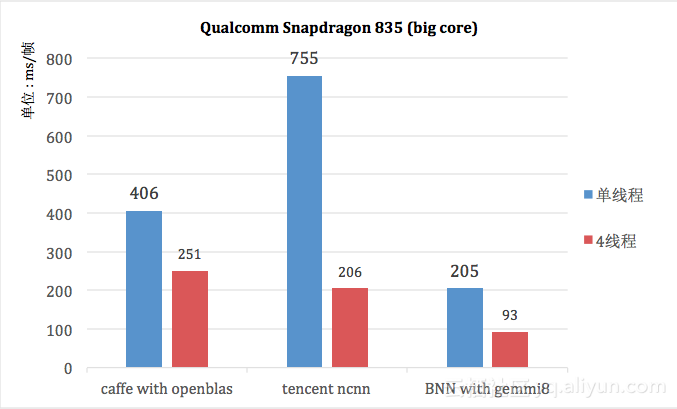
图5: BNN与其它框架性能端上对比
3.框架轻
框架无第三方依赖,BNN+GEMMi8定制化后大小不超过200K,可轻松移植到手机端运行。
4.跨硬件平台
目前BNN已经可以在Intel x86和ARM的主流CPU上运行,无论是服务器端、移动端、还是IoT场景(如门禁人脸识别、车载设备)都可以运行我们的框架,对GPU端、FPGA的支持也将稍后发布。
5.可扩展
针对不同的业务,可添加用户自定义网络层,增加了框架的灵活性。虽然目前仅支持Caffe,后续会逐步增加对主流人工智能框架的支持。
6.易使用
从离线的模型压缩到在线的网络前向过程提供自动化服务,无烦杂的人工干预过程。
使用方法
BNN框架的使用也非常简单(如图6所示),针对训练好的Caffe模型,我们在Gauss平台上有模型压缩的对外服务,也可以使用我们提供的离线工具自动量化,量化后的文件可以直接被BNN框架读取。
目前BNN只支持Caffe的离线模型量化,后期会逐渐添加对其它主流深度学习框架(如Tensorflow)模型的支持。
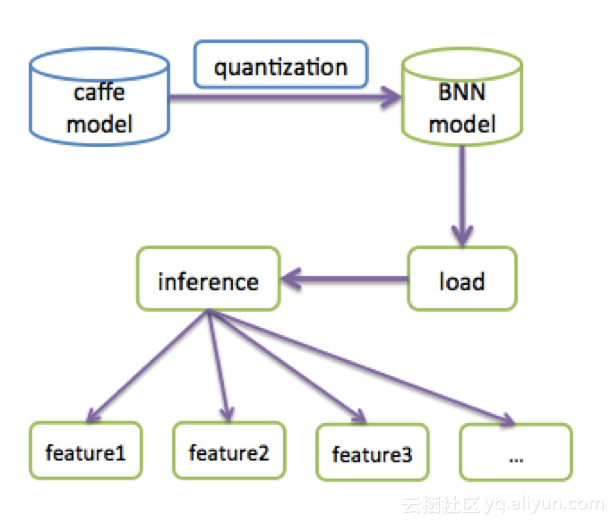
图6: BNN使用流程
图7: 端上人脸识别
写在最后
在业务落地方面,BNN正接入了集团内多个BU的产品,包括黄图识别,安全部人脸识别项目(如图7),手淘直播等等。
BNN只是IDST在人工智能算法服务化(AI-as-a-Service)的一个开端,我们的脚步并未放缓,我们希望能够搭建更加完善的服务化框架(如profiling),让人工智能开发者/算法工程师更加专注在场景和端到端方案的设计上。

图8: 手机端图像实时分类
附录
矩阵测试用例表,用例2-10来自googlenet和resnet18。
|
用例/矩阵规模 |
Row,Col,Depth |
|
用例1 |
500,500,500 |
|
用例2 |
2000,2000,2000 |
|
用例3 |
64,3136,64 |
|
用例4 |
128,784,64 |
|
用例5 |
256,196,2304 |
|
用例6 |
512,49,2304 |
|
用例7 |
512,49,4608 |
|
用例8 |
32,12544,27 |
|
用例9 |
1024,49,1024 |
|
用例10 |
128,3136,128 |
Reference
1. Caffe (https://github.com/BVLC/caffe)
2. Tensorflow (https://github.com/tensorflow/tensorflow)
3. Eigen (https://bitbucket.org/eigen/eigen/src)
4. OpenBLAS (https://github.com/xianyi/OpenBLAS)
5. Arm Compute Library (https://github.com/ARM-software/ComputeLibrary)
6. Intel MKL (https://software.intel.com/en-us/mkl)
7. Gemmlowp (https://github.com/google/gemmlowp)
8. Extremely Low Bit Neural Network: Squeeze the Last Bit Out with ADMM (https://arxiv.org/abs/1707.09870)
作者 :李谋、窦则胜、孔建钢、冷聪、李禺、李昊、顾震宇、戴宗宏。
BNN - 基于low-bits量化压缩的跨平台深度学习框架相关推荐
- 一种基于子序列的亚细胞定位预测的深度学习框架(DeepLncLoc: a deep learning frame work for long non-coding RNA subcellular)
一种基于长链非编码RNA子序列的亚细胞定位预测的深度学习框架 期刊:biorxiv 文章地址:https://www.biorxiv.org/content/10.1101/2021.03.13.43 ...
- 微信正在用的深度学习框架开源!支持稀疏张量,基于C++开发
点击上方"视学算法",选择加"星标"或"置顶" 重磅干货,第一时间送达 鱼羊 发自 凹非寺 量子位 报道 | 公众号 QbitAI 微信正用 ...
- 【开源项目推荐-ColugoMum】这群本科生基于国产深度学习框架PaddlePadddle开源了零售行业解决方案
零售行业是我国非常重要的行业之一,随着手机支付和购物用户数量的不断提高,以及数字化技术的不断发展,零售行业的企业尤其是线下体验店对数字化转型的意愿不断加强,未来我国智慧零售行业有望持续快速发展. 那么 ...
- 基于Ubuntu 18.04机器人操作系统环境和深度学习环境配置
基于Ubuntu 18.04机器人操作系统环境和深度学习环境配置详解 CUDA+Cudnn+ROS+anaconda+ubuntu装机必备 笔记本双系统安装 U盘启动项安装ubuntu18.04.1 ...
- 深度学习框架量化感知训练的思考及OneFlow的解决方案
作者 | BBuf 原文首发于公众号GiantPandaCV 0x0.总览 相信不少小伙伴都了解或者使用了一些深度学习框架比如PyTorch,TensorFlow,OneFlow(也是笔者目前正在参与 ...
- 基于人脸的常见表情识别(1)——深度学习基础知识
基于人脸的常见表情识别(1)--深度学习基础知识 神经网络 1. 感知机 2. 多层感知机与反向传播 卷积神经网络 1. 全连接神经网络的2大缺陷 2. 卷积神经网络的崛起 卷积神经网络的基本网络层 ...
- 深度学习框架量化感知训练的思考及OneFlow的一种解决方案
[GiantPandaCV导语]这篇文章分享的是笔者最近在OneFlow做的一个项目,将Pytorch FX移植到OneFlow之后实现了自动量化感知训练动态图模型(在Pytorch和OneFlow中 ...
- 基于岭回归的数据增强与深度学习模型
作者:禅与计算机程序设计艺术 <基于岭回归的数据增强与深度学习模型>技术博客文章 <基于岭回归的数据增强与深度学习模型> 引言 随着深度学习技术的快速发展,模型压缩.数据增强成 ...
- 【深度学习】基于PyTorch深度学习框架的序列图像数据装载器
作者 | Harsh Maheshwari 编译 | VK 来源 | Towards Data Science 如今,深度学习和机器学习算法正在统治世界.PyTorch是最常用的深度学习框架之一,用于 ...
最新文章
- 手动部署OpenStack环境(六:出现的问题与解决方案总结)
- android 释放so,在安卓项目里部署so文件你需要知道的知识
- 我国人工智能五大开放创新平台集体亮相
- Objective-C 2.0属性(Property)介绍
- 网站外链发布的细节注意事项!
- DELPHI加密字串(异或运算加密)
- gitlab在centons环境下的安装及使用
- 纯c语言实现的改进暗通道去雾算法测试程序(附赠大量测试图像),基于改进暗通道先验算法的图像去雾...
- 对比学习有多火?文本聚类都被刷爆了…
- ruby 生成哈希值_哈希 Ruby中的运算符
- python的异步网络编程_python异步网络编程怎么使socket关闭之后立即执行一段代码?...
- 查询一个表中一个字段相同的数据_最实用MySQL 查询当天、本周,本月、上一个月的数据...
- mysql:Error while performing database loggin with the mysql driver
- Unity实现鼠标点击指定位置导航角色
- stm32f107ptp时钟同步
- 重写iView中Modal对话框取消和确定按钮
- 华为云obs对象存储使用教程
- php 截掉最后一个字符_php 截取并删除字符串最后一个字符的方法
- weex实现文本省略效果
- Spark简介、生态系统