差异数据的对比和整理

在我们日常的工作中,常常会遇到很多结构相同,但来源不同的数据。有时,这些数据之间完全独立,互不重叠,例如各个分公司从自己系统中导出的销售数据;但有时,这些数据之间又会有大量的重叠,例如常见的一个完整业务流程中涉及的各个系统、各个环节,都可能根据各自收到的单据进行录入。这时,如何对这些重叠数据进行对比,从而发现和纠正其中的错误,就需要我们常说的“自动对账”操作了。
在一般业务系统的设计开发中,这种对账功能的逻辑基本上都是通过循环遍历一套数据的记录,在另一套记录数据中逐一比对查找。虽然代码逻辑高度类似,但又常常因为比对所用关键字的差异,以及可能发生的需求变化而需要单独编写,最终导致开发成本居高不下,维护难度越来越大。
现在有了集算器,类似问题的处理,就会变得直观而且便捷,因为集算器中提供了真正面向集合的各种运算。具体到差异数据的对比和整理,只需要sort()和merge()两个函数既可以了。
我们以一个简化了的销售记录合并的例子来进行说明。
下表显示的两个文件old.csv和new.csv分别代表预计销售的情况和实际销售的情况,都包含了销售人员姓名userName、销售日期date、销售额saleValue、销售数量saleCount。在业务分析时,需要分别找出新增的、删除的、修改的数据行进行分析,其中userName和date作为进行比对的关键字,也称为逻辑主键:
| Old.csv | New.csv | |
|
. 1 2 3 4 5 6 7 8 9 |
userName,date,saleValue,saleCount Rachel,2015-03-01,4500,9 Rachel,2015-03-03,8700,4 Tom,2015-03-02,3000,8 Tom,2015-03-03,5000,7 Tom,2015-03-04,6000,12 John,2015-03-02,4000,3 John,2015-03-02,4300,9 John,2015-03-04,4800,4 . |
userName,date,saleValue,saleCount Rachel,2015-03-01,4500,9 Rachel,2015-03-02,5000,5 Ashley,2015-03-01,6000,5 Rachel,2015-03-03,11700,4 Tom,2015-03-03,5000,7 Tom,2015-03-04,6000,12 John,2015-03-02,4000,3 John,2015-03-02,4300,9 John,2015-03-04,4800,4 |
可以看到new.csv中的第2、3行是新增的记录,可能对应额外成交的新订单,第4行是修改的记录,可能对应成交价格变化,old.csv中第3行是删除的记录,可能对应撤销的订单。
传统逻辑的比对代码我们不再赘述,直接看一看在集算器中是如何处理的:
| A | B | |
| 1 | =file(“d:\\old.csv”).import@t(;”,”) | =file(“d:\\new.csv”).import@t(;”,”) |
| 2 | =A1.sort(userName,date) | =B1.sort(userName,date) |
| 3 | =new=[B2,A2].merge@d(userName,date) | |
| 4 | =detete=[A2,B2].merge@d(userName,date) | |
| 5 | =diff=[B2,A2].merge@d(userName,date,saleValue,saleCount) | |
| 6 | =update=[diff,new].merge@d(userName,date) | result update |
没错,就这么几行,没有循环遍历,没有查询算法优化,而且如果比对的关键字变化了,只需要修改这么一目了然的几行。让我们从上到下捋一下:
A1,B1:以逗号为分隔符读入文件,形成两个原始的数据集合。这里也可以从其他格式的文件或数据库的数据表中读取。
A2,B2:使用sort()函数,将数据按照关键字,也就是逻辑主键排序,形成新的集合。以便后面的merge()函数使用。
A3:查找新增记录,也就是关键字userName和date在集合B2中同时不在集合A2中,这就是集合的“差集”计算,是通过函数选项@d指定的,类似的还有并集@u,交集@i。计算得到一个新的集合“new”如下:

A4:这次查找被删除的记录,也就是关键字userName和date在集合A2中但不在B2中的记录,注意merger()函数前方括号中A2、B2的次序不同。同样计算得到一个新的集合“delete”结果如下:

A5:和A3一样,查找B2与A2的差集,但这次将所有字段都作为关键字,因此会找到所有变化的记录,包括修改过的和新增的记录。这个结果形成的新集合“diff”如下:
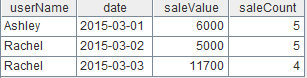
A6:很明显“diff”集合中去掉新增的记录,也就“new”集合,就是被修改过的记录,对应的集合“update”如下:

可以看到,在集合的概念下,记录的新增、删除、修改都有着直观的含义,无非就是新、老集合的不同部分,通过相应的集合运算可以非常方便的表示。
这样计算得到的结果,除了可以在计算的IDE中查看,或者通过文件处理函数输出到文件中,还可以通过JDBC方式返回给 Java 程序或其他报表工具,代码中的 B6 就显示如何将这种对账处理的结果非常简单作为结果集返回给其他系统模块,下面是Java程序中使用这个结果集的示例:
//建立esProc jdbc连接
Class.forName(“com.esproc.jdbc.InternalDriver”);
con= DriverManager.getConnection(“jdbc:esproc:local://”);
//调用esProc,其中test是脚本文件名,可接收参数
st =(com.esproc.jdbc.InternalCStatement)con.prepareCall(“call test()”);
st.execute();//执行esProc存储过程
ResultSet set = st.getResultSet();//获得计算结果
可以看到,集算器处理差异数据,真正体现和“差异”的本质含义,也就是集合的差异。事实上,这种差异数据广泛存在与各种系统之中和不同系统之间,大到银行、运营商系统中的账目数据,小到个人文件系统中的查重和版本比较,只要明确了需要对比的数据集合和关键字,就可以灵活地通过集合运算进行各种整理工作了。
差异数据的对比和整理相关推荐
- 猝灭剂BHQ-1 amine/1308657-79-5/BHQ-2 氨基/1241962-11-7者相关的物理性质还是有一定的区别,整理以下相关的数据进行对比。
西安凯新生物BHQ染料通过FRET和静态猝灭的组合工作,使研究人员能够避免荧光猝灭剂(如TAMRA)常见的残留背景信号,或dabcyl的低信噪比.BHQ-1 amine,BHQ-2 amine两者相关 ...
- 大数据框架对比:Hadoop、Storm、Samza、Spark和Flink——flink支持SQL,待看
简介 大数据是收集.整理.处理大容量数据集,并从中获得见解所需的非传统战略和技术的总称.虽然处理数据所需的计算能力或存储容量早已超过一台计算机的上限,但这种计算类型的普遍性.规模,以及价值在最近几年才 ...
- Excel如何实现两个工作表数据的对比,比较两个Excel表,两个表格对比 的绿色工具
两个不同的EXCEL表格如何进行排序对比,两个Excel表如何比较一样不一样 如何比较两个excel,使用这个工具:http://www.excelfb.com/ 点击: 表对齐比较--> 比 ...
- 瓜子IM智能客服系统的数据架构设计(整理自现场演讲)
本文由ITPub根据封宇在[第十届中国系统架构师大会(SACC2018)]现场演讲内容整理而成. 1.引言 瓜子业务重线下,用户网上看车.预约到店.成交等许多环节都发生在线下.瓜子IM智能客服系统的目 ...
- 【2022持续更新】大数据最全知识点整理-数据仓库篇
大数据最全知识点整理-数据仓库篇 1.什么是数据仓库(数仓的定义) 2.数据仓库特点 面向主题 集成性 稳定性 反映历史变化 3.数据库和数据仓库的区别 4.数仓构建流程 1) 数据调研.划分主题域 ...
- 山东大学软件学院2022-2023数据科学导论知识点整理【软工大数据课组】
每年考点变化较大,仅供参考 CSDN的排版能力有限,因此留pdf版本,祝大伙全部95+,呼呼 山东大学软件学院2022-2023数据科学导论知识点整理[软工大数据课组]-统计分析文档类资源-CSDN文 ...
- 开发各种信息管理系统的标准演示数据都帮你整理好了,少了录入演示\测试\模拟数据的烦恼了[提供下载]...
我们平时开发各种信息管理系统,往往每次都产生演示数据烦恼一些,虽然也就花1天时间就可以了搞定了,但是每次都发明很多张三\李四, 胡编乱造很不规范,而且有水平的客户一看就知道是个不成熟的系统, 本来想2 ...
- python量化投资必背代码-量化投资:用Python实现金融数据的获取与整理
小编说:数据可以说是量化投资的根本,一切投资策略都是建立在数据基础上的.本文以优矿网为例,带领大家用Python实现金融数据的获取与整理. 本文选自<Python与量化投资:从基础到实战> ...
- 运用计算机辅助电话调查的方法,第二章 统计数据的搜集、整理与显示
"对统计学家来说,当今是统计学一切最重要活动的最重要的时期." "在花费同样的时间和劳动下,完整细致地检查数据的收集过程,或者说试验过程,常常会增加10倍或12倍的收益. ...
最新文章
- springboot-mysql-pagehelper分页插件集成
- 操作系统原理第三章:进程
- 【深度学习】从R-CNN到Mask R-CNN的思维跃迁
- Wondows环境下配置Tomat
- 自然语言项目之Python语种检测代码实现
- java jar 启动项目,SpringBoot项目运行jar包启动的步骤流程解析
- 原来 8 张图,就可以搞懂「零拷贝」了!
- Spark源码学习1.6——Executor.scala
- 五种百度云盘下载速度慢解决方法
- 正态性检验ks和sw区别_非参数检验思路总结,清晰理解就靠它了!
- 迅雷 linux 命令行 版本号,在Linux系统下使用wine运行迅雷5的方法
- Locality-Aware NMS 局部感知NMS(LNMS)学习
- nodejs-CentOS64下载安装配置
- python实现树莓派监控_树莓派上安装pyaudio 及 对声音实时监控
- 港科夜闻|李嘉诚向香港科大等不同的院校捐款港币1.7亿元
- Android SD卡简单的文件读写操作
- linux 磁盘操作
- 自定义侧边栏滚动条样式
- snmp 在企业网络中的应用
- 硬盘错误:终止位置参数溢出