Python3 爬取豆瓣电影信息
原文链接: Python3 爬取豆瓣电影信息
上一篇: python3 爬取电影信息
下一篇: neo4j 查询
豆瓣api
https://developers.douban.com/wiki/?title=movie_v2
请求码返回表
http://blog.unvs.cn/archives/douban-oauth-2-0-error_code.html
限制请求数目为40次每分钟
超过次数会出现
| msg | "rate_limit_exceeded2: 1.85.33.69" |
| code | 112 |
| request | "GET /v2/movie/26313744" |
爬取链接
https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=%E7%94%B5%E5%BD%B1&start=1格式说明
https://movie.douban.com/j/new_search_subjects?
sort=T
&range=0,10
&tags=%E7%94%B5%E5%BD%B1
&start=1sort=T 按照类型排序
&range=0,10 选取电影的评分范围
&tags=%E7%94%B5%E5%BD%B1 标签为电影
&start=1 开始的索引返回20个电影的json数据
豆瓣电影api
返回指定编号电影的信息
https://api.douban.com/v2/movie/1295644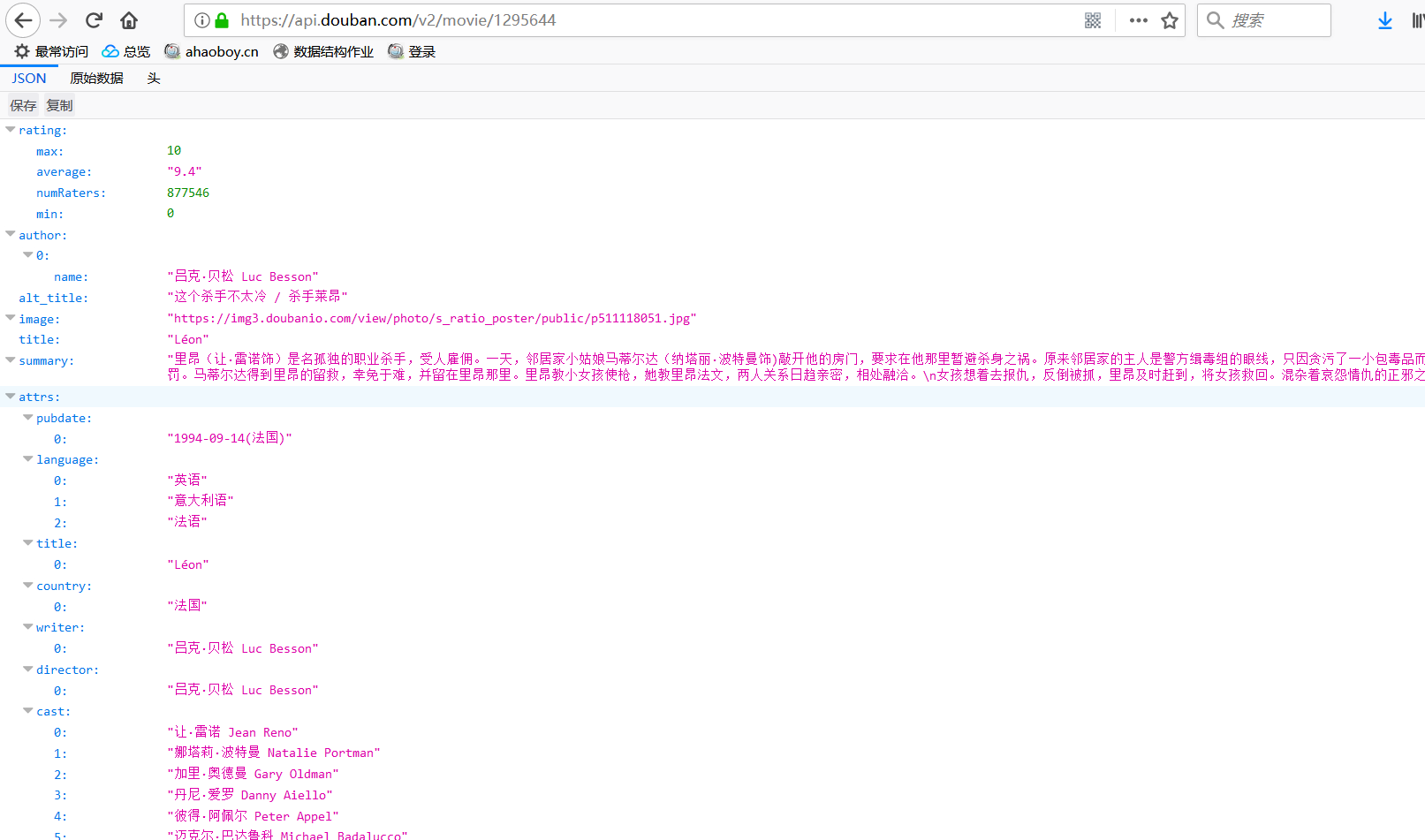
由于豆瓣有反爬虫机制,需要考虑一下怎么能够把这些信息全部爬取出来...
爬取简介信息,每页20条一共不到10000条,注意每次爬取需要停止1s,为了防止反爬虫机制
url_base = 'https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=%E7%94%B5%E5%BD%B1&start={0}'all_page = 500
import requests
import timesave_dir = 'D:/data/douban/movie_list'for i in range(all_page):url = url_base.format(i * 20)print(url)text = requests.get(url).textpath = save_dir + '/page_' + str(i) + '.json'with open(path, mode='w+', encoding='utf8') as f:f.write(text)time.sleep(2)
合并id
import json
import os# 获取所有电影id和名称movie_dir = 'd:/data/douban/movie_page'movie_csv = []
for p in os.listdir(movie_dir):path = movie_dir + '/' + pwith open(path, mode='r', encoding='utf8') as f:js = json.load(f)['data']for i in js:print(i)movie_csv.append([i['id'], i['title'], i['url']])print(len(movie_csv))
with open('movie_info.csv', mode='w+', encoding='utf8') as f:f.write('id,title,url\n')for i in movie_csv:f.write(','.join(i) + '\n')
获取所有电影详情
import time
import requests
import json# 获取所有电影id
movie_ids = []
with open('movie_info.csv', encoding='utf8') as f:f.readline()for i in f.readlines():movie_ids.append(i.split(',')[0].strip())print(len(movie_ids))url_base = 'https://api.douban.com/v2/movie/{0}'
save_dir = 'd:/data/douban/movie_info'
for i in movie_ids:url = url_base.format(i)text = requests.get(url).textpath = save_dir + '/m_' + str(i) + '.json'print(url)with open(path, mode='w+', encoding='utf8') as f:f.write(text)time.sleep(1)
注意编码问题
爬取电影详情页面
# https://movie.douban.com/subject/26378579/import time
import requests
import json# 获取所有电影id
movie_ids = []
with open('movie_info.csv', encoding='utf8') as f:f.readline()for i in f.readlines():movie_ids.append(i.split(',')[0].strip())print(len(movie_ids))url_base = 'https://movie.douban.com/subject/{0}/'
save_dir = 'd:/data/douban/movie_info_html'
for i in movie_ids:url = url_base.format(i)text = requests.get(url).textpath = save_dir + '/m_' + str(i) + '.html'print(url)with open(path, mode='w+', encoding='utf8') as f:f.write(text)time.sleep(1)豆瓣API爬取结果
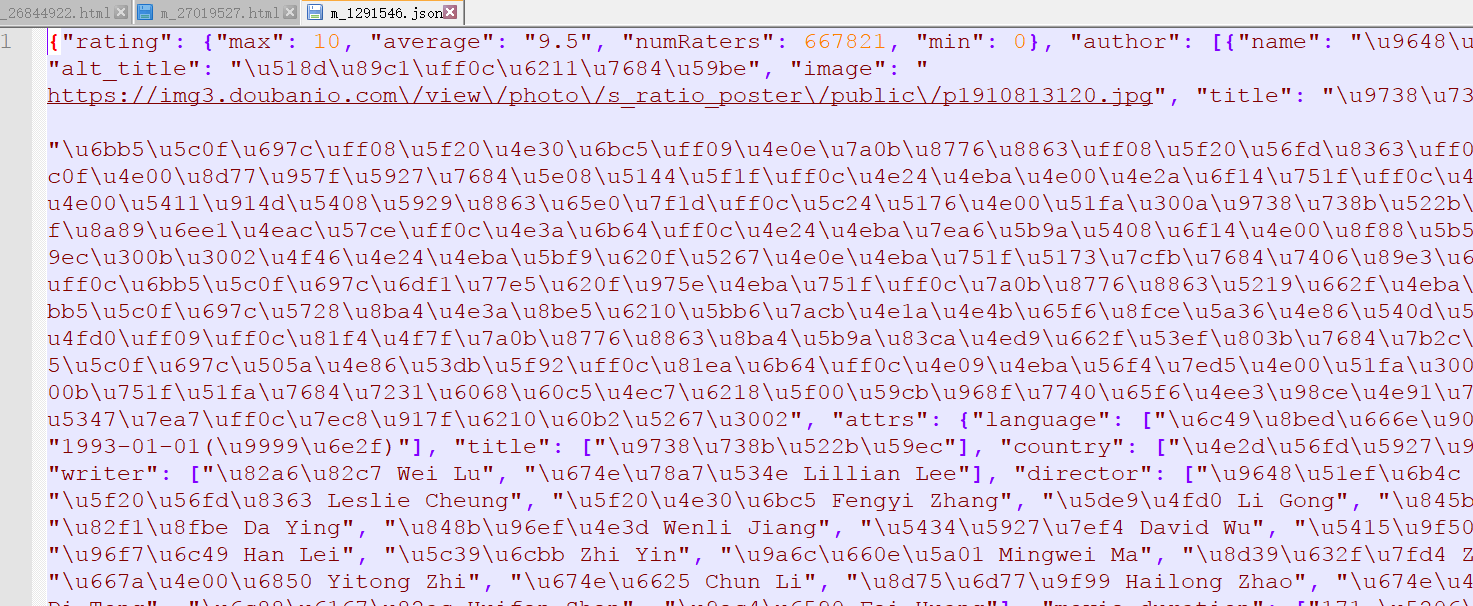
读取json文件,格式化输出,使用json 设置输出中文而不是乱码
import json
with open('m_1291546.json') as f:js = json.load(f)print(json.dumps(js,indent=2,ensure_ascii=False))
"D:\Program Files\py36\python3.exe" D:/code/pycharm/py36/db/t.py
{"rating": {"max": 10,"average": "9.5","numRaters": 667821,"min": 0},"author": [{"name": "陈凯歌 Kaige Chen"}],"alt_title": "再见,我的妾","image": "https://img3.doubanio.com/view/photo/s_ratio_poster/public/p1910813120.jpg","title": "霸王别姬","summary": "段小楼(张丰毅)与程蝶衣(张国荣)是一对打小一起长大的师兄弟,两人一个演生,一个饰旦,一向配合天衣无缝,尤其一出《霸王别姬》,更是誉满京城,为此,两人约定合演一辈子《霸王别姬》。但两人对戏剧与人生关系的理解有本质不同,段小楼深知戏非人生,程蝶衣则是人戏不分。\n段小楼在认为该成家立业之时迎娶了名妓菊仙(巩俐),致使程蝶衣认定菊仙是可耻的第三者,使段小楼做了叛徒,自此,三人围绕一出《霸王别姬》生出的爱恨情仇战开始随着时代风云的变迁不断升级,终酿成悲剧。","attrs": {"language": ["汉语普通话"],"pubdate": ["1993-01-01(香港)"],"title": ["霸王别姬"],"country": ["中国大陆","香港"],"writer": ["芦苇 Wei Lu","李碧华 Lillian Lee"],"director": ["陈凯歌 Kaige Chen"],"cast": ["张国荣 Leslie Cheung","张丰毅 Fengyi Zhang","巩俐 Li Gong","葛优 You Ge","英达 Da Ying","蒋雯丽 Wenli Jiang","吴大维 David Wu","吕齐 Qi Lü","雷汉 Han Lei","尹治 Zhi Yin","马明威 Mingwei Ma","费振翔 Zhenxiang Fei","智一桐 Yitong Zhi","李春 Chun Li","赵海龙 Hailong Zhao","李丹 Dan Li","童弟 Di Tong","沈慧芬 Huifen Shen","黄斐 Fei Huang"],"movie_duration": ["171 分钟"],"year": ["1993"],"movie_type": ["剧情","爱情","同性"]},"id": "https://api.douban.com/movie/1291546","mobile_link": "https://m.douban.com/movie/subject/1291546/","alt": "https://movie.douban.com/movie/1291546","tags": [{"count": 119042,"name": "经典"},{"count": 60501,"name": "中国电影"},{"count": 57896,"name": "爱情"},{"count": 55252,"name": "文艺"},{"count": 52815,"name": "人性"},{"count": 48132,"name": "同志"},{"count": 42505,"name": "人生"},{"count": 32240,"name": "剧情"}]
}Process finished with exit code 0
Python3 爬取豆瓣电影信息相关推荐
- python3爬取豆瓣电影信息,图片,有源码(使用简单)
首先下载安装python3安装教程 在控制台(Windows按 win+R)下载python插件: python -m pip install --upgrade pip # 更新 pip insta ...
- python爬取豆瓣电影信息可行性分析_Python爬虫实现的根据分类爬取豆瓣电影信息功能示例...
本文实例讲述了Python爬虫实现的根据分类爬取豆瓣电影信息功能.分享给大家供大家参考,具体如下: 代码的入口:if __name__ == '__main__': main()#! /usr/bin ...
- day02:requests爬取豆瓣电影信息
一.requests爬取豆瓣电影信息 -请求url: https://movie.douban.com/top250 -请求方式: get -请求头: user-agent cookies二.sele ...
- python爬取豆瓣电影信息_Python爬虫入门 | 爬取豆瓣电影信息
这是一个适用于小白的Python爬虫免费教学课程,只有7节,让零基础的你初步了解爬虫,跟着课程内容能自己爬取资源.看着文章,打开电脑动手实践,平均45分钟就能学完一节,如果你愿意,今天内你就可以迈入爬 ...
- python爬虫爬取豆瓣电影信息城市_Python爬虫入门 | 2 爬取豆瓣电影信息
这是一个适用于小白的Python爬虫免费教学课程,只有7节,让零基础的你初步了解爬虫,跟着课程内容能自己爬取资源.看着文章,打开电脑动手实践,平均45分钟就能学完一节,如果你愿意,今天内你就可以迈入爬 ...
- Python爬虫入门(爬取豆瓣电影信息小结)
Python爬虫入门(爬取豆瓣电影信息小结) 1.爬虫概念 网络爬虫,是一种按照一定规则,自动抓取互联网信息的程序或脚本.爬虫的本质是模拟浏览器打开网页,获取网页中我们想要的那部分数据. 2.基本流程 ...
- day02 requests请求库爬取豆瓣电影信息+selenium请求库
一. requests请求库爬取豆瓣电影信息 - 请求url http://movie.douban.com/top250 - 请求方式 GET - 请求头 user-agent cookies ...
- 小白都能看明白的Python网络爬虫、附上几个实用的爬虫小例子: 爬取豆瓣电影信息和爬取药监局
文章目录 网络爬虫 爬虫的基础知识 爬虫分类 requests模块 爬虫的简单案例 简单的收集器 爬取豆瓣电影信息 爬取药监局 返回数据类型 数据解析 爬取糗事百科图片(正则表达式) xpath解析数 ...
- 使用python3爬取豆瓣电影top250
经过一个多星期的学习,对python3的语法有了一定了解,马上动手做了一个爬虫,检验学习效果 目标 爬取豆瓣电影top250中每一部电影的名称.排名.链接.名言.评分 准备工作 运行平台:window ...
最新文章
- PyTorch 笔记(01)— Ubuntu 使用 pip 清华源安装 PyTorch
- 自动驾驶 | MINet:嵌入式平台上的实时Lidar点云数据分割算法,速度可达 20-80 FPS!...
- SAP R3 Create Client: T-code:SCC4
- Android-正方形的容器
- 基于注解的Spring AOP的配置和使用--转载
- Chrome浏览器手动添加Cookie的方法
- 三、致敬“张正友标定”
- configuration 命名空间_kubernetes30:monitoring命名空间处于Terminating状态的处理方法...
- Java套接字Socket编程--TCP参数
- 机器学习/深度学习测试题(一) —— 单层感知器的激活函数
- 关于vue的npm run dev和npm run build
- 分布式存储系统学习笔记(一)—什么是分布式系统(7)—跨机房部署的三种方案
- Ubuntu 关闭服务详解
- 超全!我常用的70个数据分析网址
- 如何查看linux pagesize的大小
- 宇枫资本女性刚工作理财建议
- 求2n个数中最大值和最小值的最少比较次数
- xshell各个版本下载
- Rabin-Karp算法 (拉宾-卡普)
- 计算机读心术的原理,读心术是什么原理,是真的吗