[译] 或许你并不需要 Rust 和 WASM 来提升 JS 的执行效率 — 第二部分
以下内容为本系列文章的第二部分,如果你还没看第一部分,请移步或许你并不需要 Rust 和 WASM 来提升 JS 的执行效率 — 第一部分。
我尝试过三种不同的方法对 Base64 VLQ 段进行解码。
第一个是 decodeCached,它与 source-map 使用的默认实现方式完全相同 — 我已经在上面列出了:
function decodeCached(aStr) {var length = aStr.length;var cachedSegments = {};var end, str, segment, value, temp = {value: 0, rest: 0};const decode = base64VLQ.decode;var index = 0;while (index < length) {// Because each offset is encoded relative to the previous one,// many segments often have the same encoding. We can exploit this// fact by caching the parsed variable length fields of each segment,// allowing us to avoid a second parse if we encounter the same// segment again.for (end = index; end < length; end++) {if (_charIsMappingSeparator(aStr, end)) {break;}}str = aStr.slice(index, end);segment = cachedSegments[str];if (segment) {index += str.length;} else {segment = [];while (index < end) {decode(aStr, index, temp);value = temp.value;index = temp.rest;segment.push(value);}if (segment.length === 2) {throw new Error('Found a source, but no line and column');}if (segment.length === 3) {throw new Error('Found a source and line, but no column');}cachedSegments[str] = segment;}index++;}
}
decodeNoCaching。它实际上就是没有缓存的 decodeCached。每个分段都被单独解码。我使用 Int32Array 来进行 segment 存储,而不再使用 Array。
function decodeNoCaching(aStr) {var length = aStr.length;var cachedSegments = {};var end, str, segment, temp = {value: 0, rest: 0};const decode = base64VLQ.decode;var index = 0, value;var segment = new Int32Array(5);var segmentLength = 0;while (index < length) {segmentLength = 0;while (!_charIsMappingSeparator(aStr, index)) {decode(aStr, index, temp);value = temp.value;index = temp.rest;if (segmentLength >= 5) throw new Error('Too many segments');segment[segmentLength++] = value;}if (segmentLength === 2) {throw new Error('Found a source, but no line and column');}if (segmentLength === 3) {throw new Error('Found a source and line, but no column');}index++;}
}
最后,第三个是 decodeNoCachingNoString,它尝试通过将字符串转换为 utf8 编码的 Uint8Array 来避免处理 JavaScript 字符串。这个优化受到了下面的启发:JS VM 将数组加载优化成单独内存访问的可能性更高。由于 JS VM 使用的不同的字符串表示层级和结构非常复杂,所以将 String.prototype.charCodeAt 优化到相同的水准会更加困难。
我对比了两个版本,一个是将字符串编码为 utf8 的版本,另一个是使用预编码字符串的版本。用后面的这个“优化”版本,我想评估一下,通过数组 ⇒ 字符串 ⇒ 数组的转化,可以给我们带来多少的性能提升。“优化”版本的实现方式是我们将 source map 以加载到数组缓冲区,直接从该缓冲区解析它,而不是先把它转为字符串。
let encoder = new TextEncoder();
function decodeNoCachingNoString(aStr) {decodeNoCachingNoStringPreEncoded(encoder.encode(aStr));
}function decodeNoCachingNoStringPreEncoded(arr) {var length = arr.length;var cachedSegments = {};var end, str, segment, temp = {value: 0, rest: 0};const decode2 = base64VLQ.decode2;var index = 0, value;var segment = new Int32Array(5);var segmentLength = 0;while (index < length) {segmentLength = 0;while (arr[index] != 59 && arr[index] != 44) {decode2(arr, index, temp);value = temp.value;index = temp.rest;if (segmentLength < 5) {segment[segmentLength++] = value;}}if (segmentLength === 2) {throw new Error('Found a source, but no line and column');}if (segmentLength === 3) {throw new Error('Found a source and line, but no column');}index++;}
}
下面是我在 Chrome Dev66.0.3343.3(V86.6.189)和 Firefox Nightly60.0a1 中运行我的基准测试得到的结果(2018-02-11):
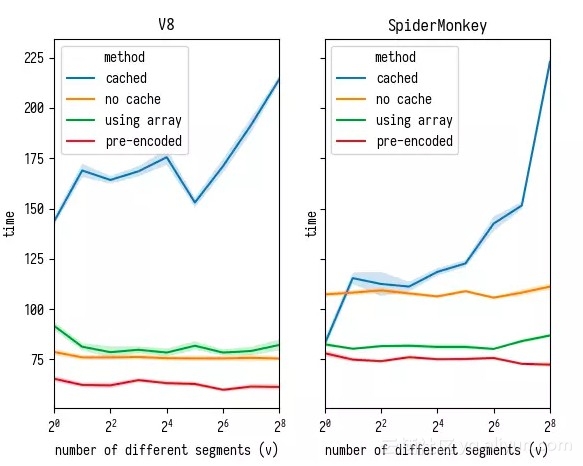
注意几点:
- 在 V8 和 SpiderMonkey 上,使用缓存的版本比的其他版本都要慢。随着缓存数量的增加,其性能急剧下降 — 而无缓存版本的性能不会受此影响;
- 在 SpiderMonkey 上,将字符串转换为类型化数组再去解析是有利的,而在 V8 上直接字符访问的速度就已经足够快了 - 所以只有在把将字符串到数组的转换移出基准的情况下,使用数组是有利的。(例如,你将你的数据一开始就加载到类型数组中)
我很怀疑 V8 团队近年来没有改进过 charCodeAt 的性能 — 我清楚地记得 Crankshaft 没有花费力气把 charCodeAt 作为特定字符串的调用方法,反而是将其扩大到所有以字符串表示的代码块都能使用,使得从字符串加载字符比从类型数组加载元素慢。
我浏览了 V8 问题跟踪器,发现了下面几个问题:
- Issue 6391: StringCharCodeAt slower than Crankshaft;
- Issue 7092: High overhead of String.prototype.charCodeAt in typescript test;
- Issue 7326: Performance degradation when looping across character codes of a string;
这些问题的评论当中,有些引用了 2018 年 1 月末以后的提交版本,这表明正在积极地进行 charCodeAt 的性能改善。出于好奇,我决定在 Chrome Beta 版本中重新运行我的基准测试,并与 Chrome Dev 版本进行比较。
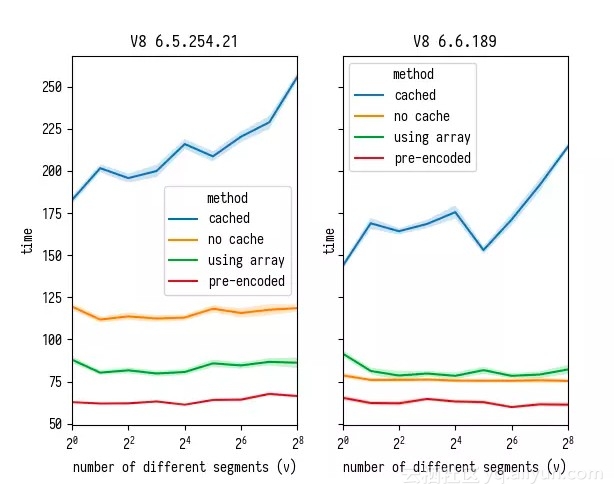
事实上,通过比较可以发现 V8 团队的所有提交都是卓有成效的:charCodeAt 的性能从“6.5.254.21”版本到“6.6.189”版本得到了很大提高。 通过对比“无缓存”和“使用数组”的代码行,我们可以看到,在老版本的 V8 中,charCodeAt 的表现差很多,所以只是将字符串转换为“Uint8Array”来加快访问速度就可以带来效果。然而,在新版本的 V8 中,只是在解析内部进行这种转换的话,并不能带来任何效果。
但是,如果您可以不通过转换,就能直接使用数组而不是字符串,那么就会带来性能的提升。 这是为什么呢? 为了解答这个问题,我在 V8 运行以下代码:
function foo(str, i) {return str.charCodeAt(i);
}let str = "fisk";foo(str, 0);
foo(str, 0);
foo(str, 0);
%OptimizeFunctionOnNextCall(foo);
foo(str, 0);
╭─ ~/src/v8/v8 ‹master›
╰─$ out.gn/x64.release/d8 --allow-natives-syntax --print-opt-code --code-comments x.js
这个命令产生了一个巨大的程序集列表,这个证实了我的怀疑,V8 的 “charCodeAt” 仍然没有针对特定的字符串进行特殊处理。这种弱点似乎源自 V8 中的这个代码,它可以解释为什么数组访问速度快于字符串的 charCodeAt 的处理。
解析改进
基于这些发现,我们可以从 source-map 解析代码中删除被解析分段的缓存,再测试影响效果。
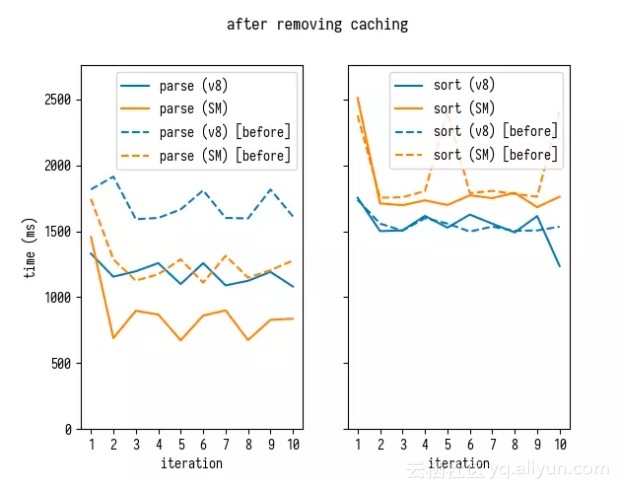
就像我们的基准测试预测的那样,缓存对整体性能是不利的:删除它可以大大提升解析时间。
优化排序 - 算法改进
现在我们改进了解析性能,让我们再看一下排序。
有两个正在排序的数组:
originalMappings数组使用compareByOriginalPositions比较器进行排序;generatedMappings数组使用compareByGeneratedPositionsDeflated比较器进行排序。
优化 originalMappings 排序
我首先看了一下 compareByOriginalPositions。
function compareByOriginalPositions(mappingA, mappingB, onlyCompareOriginal) {var cmp = strcmp(mappingA.source, mappingB.source);if (cmp !== 0) {return cmp;}cmp = mappingA.originalLine - mappingB.originalLine;if (cmp !== 0) {return cmp;}cmp = mappingA.originalColumn - mappingB.originalColumn;if (cmp !== 0 || onlyCompareOriginal) {return cmp;}cmp = mappingA.generatedColumn - mappingB.generatedColumn;if (cmp !== 0) {return cmp;}cmp = mappingA.generatedLine - mappingB.generatedLine;if (cmp !== 0) {return cmp;}return strcmp(mappingA.name, mappingB.name);
}
我注意到,映射首先由 source 组件进行排序,然后再由其他组件处理。source 指定映射最先来自哪个源文件。一个显而易见的想法是,我们可以将 originalMappings 变成数组的集合:originalMappings [i] 是包含第 i 个源文件所有映射的数组,而不再使用巨大的 originalMappings 数组直接将来自不同源文件的映射混在一起。通过这种方式,我们可以把从源文件解析出来的映射排序存到不同的 originalMappings [i] 数组中,然后对单个较小的数组再进行排序。
实际上是个[桶排序](https://en.wikipedia.org/wiki/Bucket_sort)
这是我们在解析循环中做的:
if (typeof mapping.originalLine === 'number') {// This code used to just do: originalMappings.push(mapping).// Now it sorts original mappings already by source during parsing.let currentSource = mapping.source;while (originalMappings.length <= currentSource) {originalMappings.push(null);}if (originalMappings[currentSource] === null) {originalMappings[currentSource] = [];}originalMappings[currentSource].push(mapping);
}
在那之后:
var startSortOriginal = Date.now();
// The code used to sort the whole array:
// quickSort(originalMappings, util.compareByOriginalPositions);
for (var i = 0; i < originalMappings.length; i++) {if (originalMappings[i] != null) {quickSort(originalMappings[i], util.compareByOriginalPositionsNoSource);}
}
var endSortOriginal = Date.now();
originalMappings [i] 数组的方式,这样可以保证是公平的。
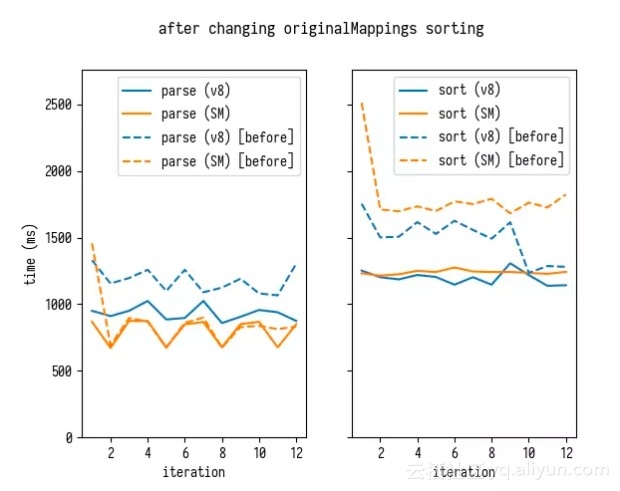
这个算法改进可同时提升 V8 和 SpiderMonkey 上的排序速度,还可以改进 V8 上的解析速度。
解析速度的提升是由于处理 originalMappings 数组的消降低了:生成一个单一的巨大的 originalMappings 数组比生成多个较小的 originalMappings [i] 数组要消耗更多。不过,这只是我的猜测,没有经过任何严格的分析。
优化 generatedMappings 排序
让我们看一下 generatedMappings 和 compareByGeneratedPositionsDeflated 比较器。
function compareByGeneratedPositionsDeflated(mappingA, mappingB, onlyCompareGenerated) {var cmp = mappingA.generatedLine - mappingB.generatedLine;if (cmp !== 0) {return cmp;}cmp = mappingA.generatedColumn - mappingB.generatedColumn;if (cmp !== 0 || onlyCompareGenerated) {return cmp;}cmp = strcmp(mappingA.source, mappingB.source);if (cmp !== 0) {return cmp;}cmp = mappingA.originalLine - mappingB.originalLine;if (cmp !== 0) {return cmp;}cmp = mappingA.originalColumn - mappingB.originalColumn;if (cmp !== 0) {return cmp;}return strcmp(mappingA.name, mappingB.name);
}
这里我们首先比较 generatedLine 的映射。一般对比原始的源文件,可能会生成更多的行,所以将 generatedMappings 分成多个单独的数组是没有意义的。
但是,当我看到解析代码时,我注意到了以下的内容:
while (index < length) {if (aStr.charAt(index) === ';') {generatedLine++;// ...} else if (aStr.charAt(index) === ',') {// ...} else {mapping = new Mapping();mapping.generatedLine = generatedLine;// ...}
}
generatedLine 的地方,这意味着 generatedLine 是单调增长的 — 意味着 generatedMappings 数组已经被 generatedLine 排序了,所以对整个数组排序没有意义。相反,我们可以对每个较小的子数组进行排序。我们把代码改成下面这样:
let subarrayStart = 0;
while (index < length) {if (aStr.charAt(index) === ';') {generatedLine++;// ...// Sort subarray [subarrayStart, generatedMappings.length].sortGenerated(generatedMappings, subarrayStart);subarrayStart = generatedMappings.length;} else if (aStr.charAt(index) === ',') {// ...} else {mapping = new Mapping();mapping.generatedLine = generatedLine;// ...}
}
// Sort the tail.
sortGenerated(generatedMappings, subarrayStart);
我没有使用 快速排序 来排序子数组,而是决定使用插入排序,类似于一些 VM 用于 Array.prototype.sort 的混合策略。
注意:如果输入数组已经排序,插入排序会比快速排序更快...事实证明,用于基准测试的映射实际上是排序过的。如果我们期望 generatedMappings 在解析之后几乎都是被排序过的,那么在排序之前先简单地检查 generatedMappings 是否已经排序会更有效率。
const compareGenerated = util.compareByGeneratedPositionsDeflatedNoLine;function sortGenerated(array, start) {let l = array.length;let n = array.length - start;if (n <= 1) {return;} else if (n == 2) {let a = array[start];let b = array[start + 1];if (compareGenerated(a, b) > 0) {array[start] = b;array[start + 1] = a;}} else if (n < 20) {for (let i = start; i < l; i++) {for (let j = i; j > start; j--) {let a = array[j - 1];let b = array[j];if (compareGenerated(a, b) <= 0) {break;}array[j - 1] = b;array[j] = a;}}} else {quickSort(array, compareGenerated, start);}
}
这产生以下结果:

排序时间急剧下降,而解析时间稍微增加 — 这是因为代码将 generatedMappings 作为解析循环的一部分进行排序,使得我们的分解略显无意义。让我们对比下改善总时间(解析和排序一起)。
改善总时间
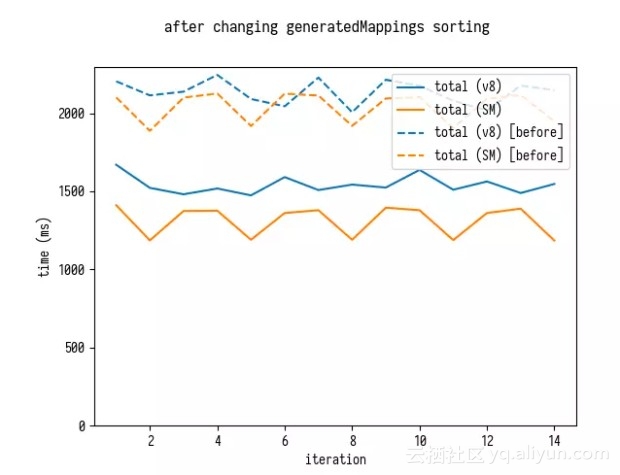
现在很明显,我们大大提高了整体映射解析性能。
我们还可以做些什么来改善性能吗?
是的:我们可以从 asm.js/WASM 指南中抽出一页,而不用在 JavaScript 代码基础上全部换作使用 Rust。
优化解析 - 降低 GC 压力
我们正在分配成千上万的 Mapping 对象,这给 GC 带来了相当大的压力 - 然而我们并不是真的需要这样的对象 - 我们可以将它们打包成一个类型数组。这是我的做法。
几年前,我对 Typed Objects 提案感到非常兴奋,该提案将允许 JavaScript 程序员定义结构体和结构体数组以及很多令人惊喜的东西,这样很方便。但不幸的是,推动该提案的领导者离开去做其他方面的工作,这让我们不得不要么自己动手,要么使用 C++代码来编写这些东西。
首先,我将 Mapping 从一个普通对象变成一个指向类型数组的一个包装器,它将包含我们所有的映射。
function Mapping(memory) {this._memory = memory;this.pointer = 0;
}
Mapping.prototype = {get generatedLine () {return this._memory[this.pointer + 0];},get generatedColumn () {return this._memory[this.pointer + 1];},get source () {return this._memory[this.pointer + 2];},get originalLine () {return this._memory[this.pointer + 3];},get originalColumn () {return this._memory[this.pointer + 4];},get name () {return this._memory[this.pointer + 5];},set generatedLine (value) {this._memory[this.pointer + 0] = value;},set generatedColumn (value) {this._memory[this.pointer + 1] = value;},set source (value) {this._memory[this.pointer + 2] = value;},set originalLine (value) {this._memory[this.pointer + 3] = value;},set originalColumn (value) {this._memory[this.pointer + 4] = value;},set name (value) {this._memory[this.pointer + 5] = value;},
};
然后我调整了解析和排序代码,如下所示:
BasicSourceMapConsumer.prototype._parseMappings = function (aStr, aSourceRoot) {// Allocate 4 MB memory buffer. This can be proportional to aStr size to// save memory for smaller mappings.this._memory = new Int32Array(1 * 1024 * 1024);this._allocationFinger = 0;let mapping = new Mapping(this._memory);// ...while (index < length) {if (aStr.charAt(index) === ';') {// All code that could previously access mappings directly now needs to// access them indirectly though memory.sortGenerated(this._memory, generatedMappings, previousGeneratedLineStart);} else {this._allocateMapping(mapping);// ...// Arrays of mappings now store "pointers" instead of actual mappings.generatedMappings.push(mapping.pointer);if (segmentLength > 1) {// ...originalMappings[currentSource].push(mapping.pointer);}}}// ...for (var i = 0; i < originalMappings.length; i++) {if (originalMappings[i] != null) {quickSort(this._memory, originalMappings[i], util.compareByOriginalPositionsNoSource);}}
};BasicSourceMapConsumer.prototype._allocateMapping = function (mapping) {let start = this._allocationFinger;let end = start + 6;if (end > this._memory.length) { // Do we need to grow memory buffer?let memory = new Int32Array(this._memory.length * 2);memory.set(this._memory);this._memory = memory;}this._allocationFinger = end;let memory = this._memory;mapping._memory = memory;mapping.pointer = start;mapping.name = 0x7fffffff; // Instead of null use INT32_MAX.mapping.source = 0x7fffffff; // Instead of null use INT32_MAX.
};exports.compareByOriginalPositionsNoSource =function (memory, mappingA, mappingB, onlyCompareOriginal) {var cmp = memory[mappingA + 3] - memory[mappingB + 3]; // originalLineif (cmp !== 0) {return cmp;}cmp = memory[mappingA + 4] - memory[mappingB + 4]; // originalColumnif (cmp !== 0 || onlyCompareOriginal) {return cmp;}cmp = memory[mappingA + 1] - memory[mappingB + 1]; // generatedColumnif (cmp !== 0) {return cmp;}cmp = memory[mappingA + 0] - memory[mappingB + 0]; // generatedLineif (cmp !== 0) {return cmp;}return memory[mappingA + 5] - memory[mappingB + 5]; // name
};
正如你所看到的,可读性确实受到了很大影响。理想情况下,我希望在需要处理对应分段时分配临时的“映射”对象。然而,这种代码风格将严重依赖于虚拟机通过_allocation sinking_,_scalar replacement_或其他类似的优化来消除这些临时包装分配的能力。不幸的是,在我的实验中,SpiderMonkey 无法很好地处理这样的代码,因此我选择了更多冗长且容易出错的代码。
这种几乎纯手工进行内存管理的方式在 JS 中是不多见的。这就是为什么我认为在这里值得提出,“oxidized” source-map 实际上需要用户手动管理它的生命周期,以确保 WASM 资源被释放。
重新运行基准测试,证明缓解 GC 压力产生了很好的改善效果。
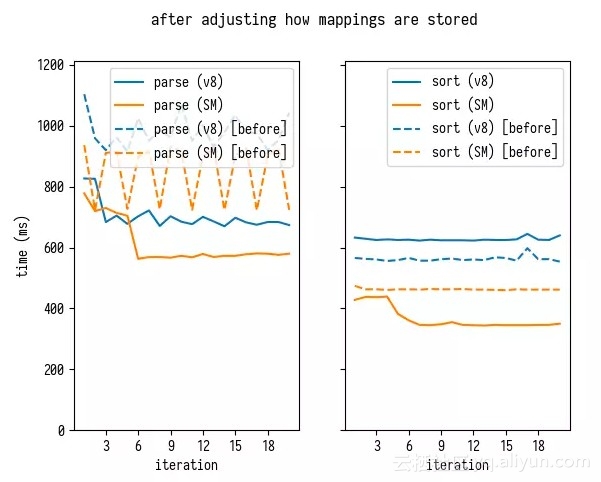
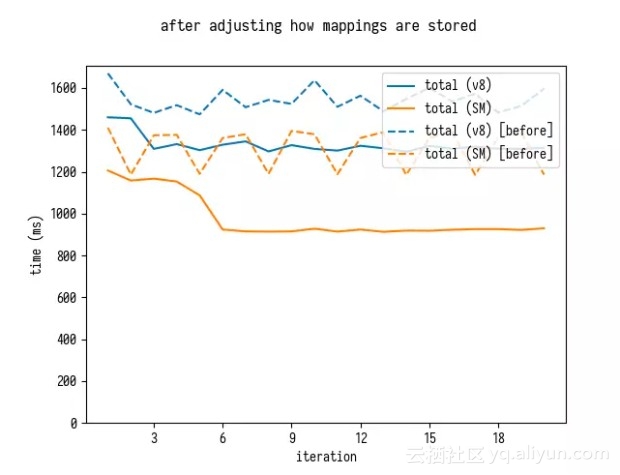
有趣的是,在 SpiderMonkey 上,这种方法对于解析和排序都有改善效果,这对我来说真是一个惊喜。
SpiderMonkey 性能断崖
当我使用这段代码时,我还发现了 SpiderMonkey 中令人困惑的性能断崖现象:当我将预置内存缓冲区的大小从 4 MB 增加到 64 MB 来衡量重新分配的消耗时,基准测试显示当进行第 7 次迭代后性能突然下降了。
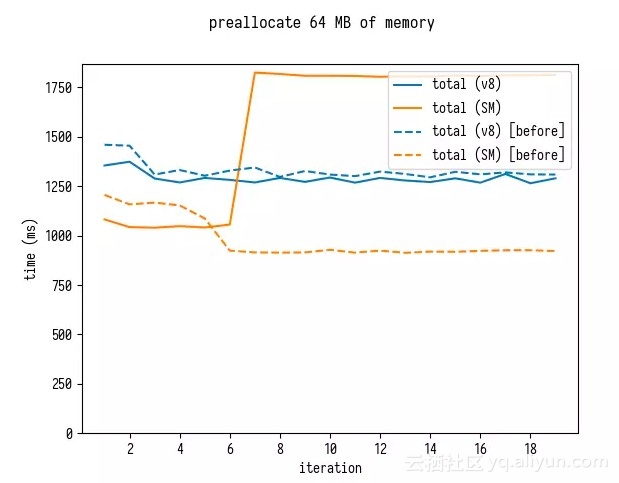
这看起来像某种多态性,但我不能立即就搞明白如何改变数组的大小可以导致这样的多态行为。
我很困惑,但我找到了一个 SpiderMonkey 黑客 Jan de Mooij,他很快识别出 罪魁祸首是 asm.js 从 2012 年开始的相关优化......然后他将它从 SpiderMonkey 中删除,这样就不会有人再遇到这种情况了。
优化分析 - 使用 Uint8Array 替代字符串。
最后,如果我们使用 Uint8Array 代替字符串来解析,我们又可以得到小的改善效果。
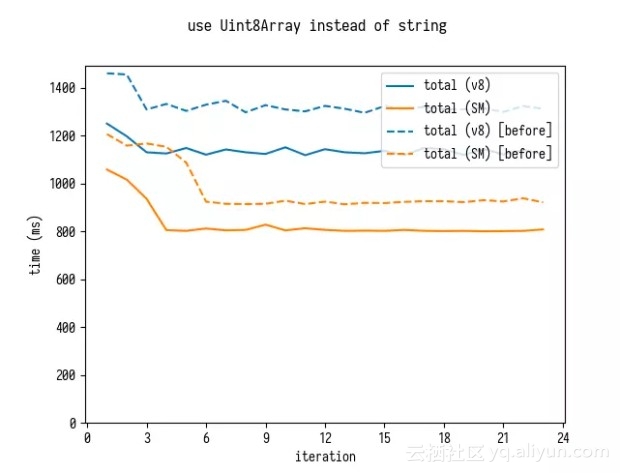
需要我们重写 source-map,直接使用类型数组解析映射而不再使用 JavaScript 的字符串方法 JSON.decode 进行解析。我没有做过这样的改写,但我想应该没有什么问题。
对基线的总体改进
这是开始的情况:
$ d8 bench-shell-bindings.js
...
[Stats samples: 5, total: 24050 ms, mean: 4810 m
s, stddev: 155.91063145276527 ms]
$ sm bench-shell-bindings.js
...
[Stats samples: 7, total: 22925 ms, mean: 3275 ms, stddev: 269.5999093306804 ms]
这是我们完成时的情况:
$ d8 bench-shell-bindings.js
...
[Stats samples: 22, total: 25158 ms, mean: 1143.5454545454545 ms, stddev: 16.59358125226469 ms]
$ sm bench-shell-bindings.js
...
[Stats samples: 31, total: 25247 ms, mean: 814.4193548387096 ms, stddev: 5.591064299397745 ms]
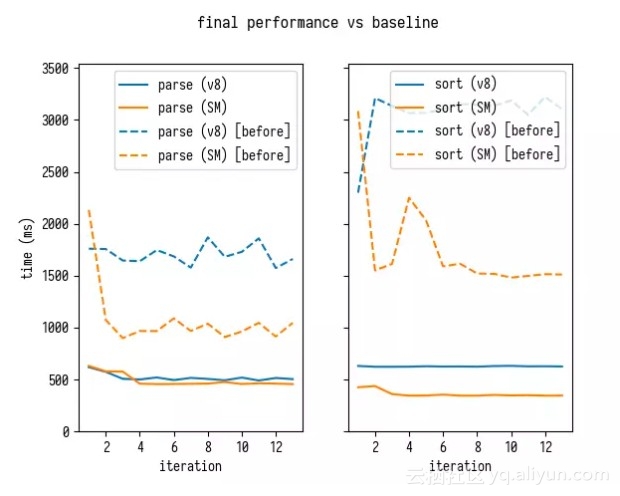
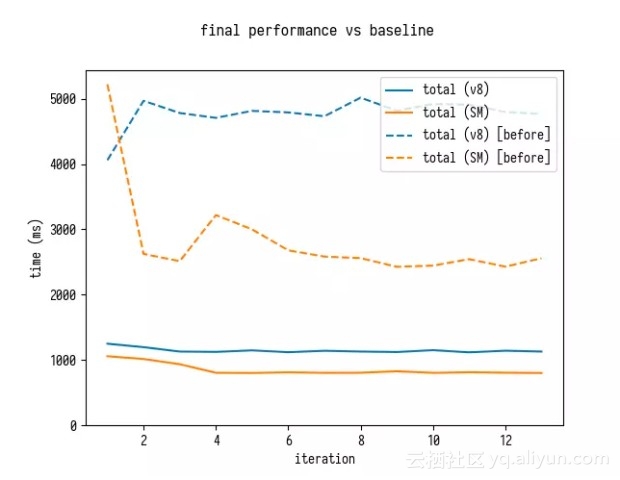
这是 4 倍的性能提升!
也许值得注意的是,尽管这并不是必须的,但我们仍然对所有的 originalMappings 数组进行了排序。只有两个操作使用到 originalMappings:
allGeneratedPositionsFor它返回给定线的所有生成位置;eachMapping(..., ORIGINAL_ORDER)它按照原始顺序对所有映射进行迭代。
如果我们假设 allGeneratedPositionsFor 是最常见的操作,并且我们只在少数 originalMappings [i] 数组中搜索,那么无论何时我们需要搜索其中的一个,我们都可以通过对 originalMappings [i] 数组进行排序来大大提高解析时间。
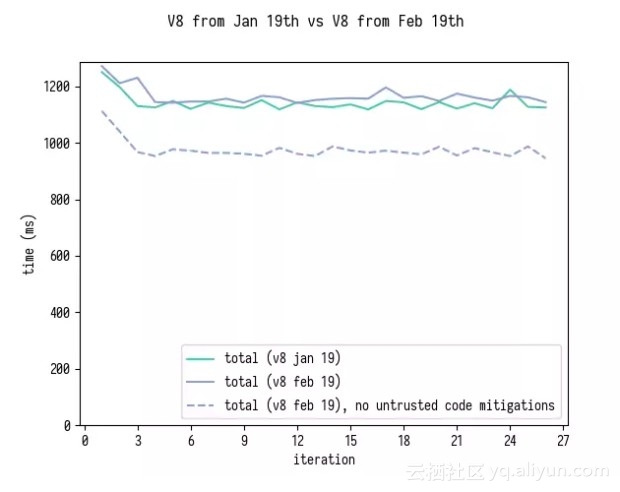
最后比较 1 月 19 日的 V8 和 2 月 19 日的 V8 分别对应包含和不包含减少不可信代码的修改。
比较 Oxidized source-map 版本
继 2 月 19 日发布这篇文章之后,我收到一些反馈要求将我改进的 source-map 与使用 Rust 和 WASM 的主线的 Oxidized source-map 相比较。
快速查看 parse_mappings 的 Rust 源代码,发现 Rust 版本没有排序原始映射,只会生成等价的 generatedMappings 并且排序。为了匹配这种行为,我通过注释掉 originalMappings [i] 数组的排序来调整我的 JS 版本。
这里是仅仅是解析的对比结果(其中还包括对 generatedMappings 进行排序),然后对所有 generatedMappings 进行解析和迭代。
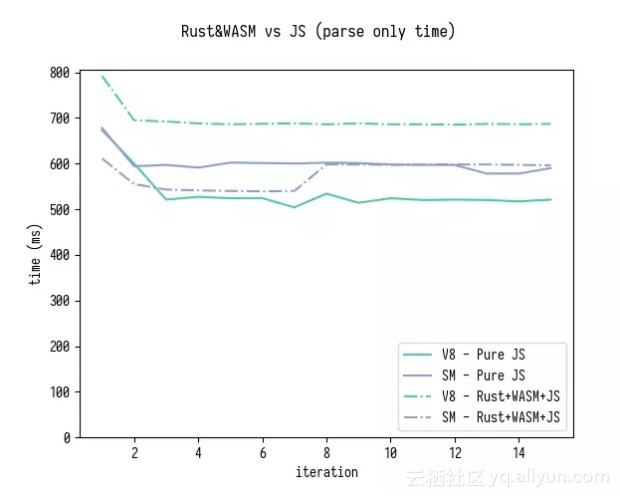
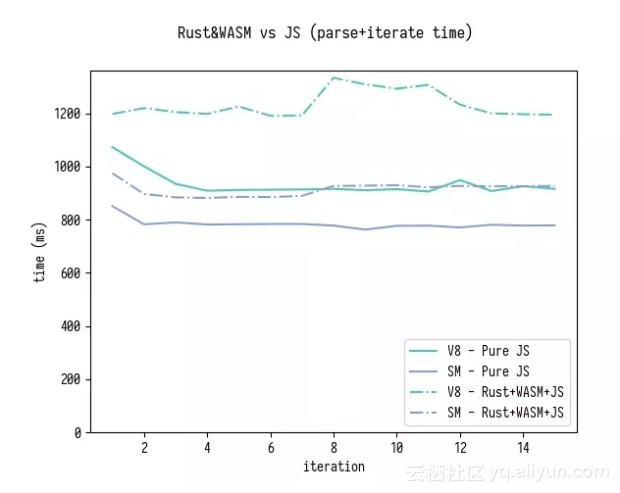
正如你可以看到 WASM+Rust 版本在 SpiderMonkey 上的速度现在增加了大约 15%,而在 V8 上的速度也大致相同。
学习
对于 JavaScript 开发人员
分析器是你的朋友
以各种形式进行分析和性能跟踪是获得高性能的最佳方法。它允许您在代码中放置热点,来揭示运行时的潜在问题。基于这个原因,不要回避使用像 perf 这样的底层分析工具 - “友好”的工具可能不会告诉你整个状况,因为它们隐藏了底层的分析。
不同的性能问题需要不同的方法去分析并能够可视化地去收集分析结果。一定确保您熟悉各种可用的工具。
算法很重要
能够根据抽象复杂性来推理你的代码是一项重要的技能。快速排序一个具有十万个元素的数组好呢?还是快速排序 3333 个数组,每个子数组有 30 元素更好呢?
数学计算可以告诉我们((100000 log 100000)比(3333 倍的 30 log 30)大 3 倍)- 如果数据量越大,通常能够数学变换就会变得越重要。
除了了解对数之外,你还需要知道一些常识,并且能够评估你的代码在平均和最糟糕的情况下的使用情况:哪些操作很常见,昂贵的运算成本如何摊销,昂贵的运算摊销带来的坏处是什么?
虚拟机也在工作。问题开发者!
不要犹豫,与开发人员讨论奇怪的性能问题。并非所有事情都可以通过改变自己的代码来解决。俄国谚语说道:“制作罐子的不是上帝!”虚拟机开发人员也是人,他们也一样会犯错误。只要把问题理清,他们也相当擅长把这些问题修复。一封邮件或或一个聊天消息或 DM 可能为您节省通过外部 C++ 代码进行调试的时间。
虚拟机仍然需要一点帮助
有时候您也需要编写一些底层代码或者了解一些底层的实现细节,这样有助于挖掘 JavaScript 的最后一丝性能。
人们可能希望有更好的语言级别的工具来实现这一点,但是我们能不能实现还有待观察。
对于语言实现者/设计者
巧妙的优化必须是可检测的
如果您的运行时具有任何内置的智能优化,那么您需要提供一个直观的工具来诊断这些优化失败的时间并向开发人员提供可操作的反馈。
在 JavaScript 这样的语言环境中,至少有像 profiler 这样的分析工具为您单个操作提供一种专业化方法来检测,以确定虚拟机优化的结果是好是坏并且指出原因。
这种排序的自检工具不能依赖于在虚拟机的某个版本上打个特殊的补丁,然后输出一堆毫无可读性的调试结果。相反,它应该是你需要的任何时候,只要打开调试工具窗口,它就能把结果呈现出来。
语言和优化必须是朋友
最后,作为一名语言设计师,您应该尝试预测语言缺乏哪些特性,从而更容易编写出性能良好的代码。市场上的用户是否需要手动设置和管理内存?我确定他们是的。如果大多数人使用了您的语言最后都写出大量性能很低的代码,那就只能通过添加大量的语言特性或者通过其他途径来提升代码的性能。(例如,通过更复杂的优化或请求用户用 Rust 重构代码)
以下是一些语言设计的通用法则:如果要为您的语言添加新特性,请确保运算过程的合理性,而且这些特性很容易被理解和检测。从整个语言层面去考虑优化工作,而不是对一些使用频率很低、性能相对较差的非核心特性去做优化工作。
后记
我们在这篇文章中发现的优化大致分成三个部分:
- 算法改进;
- 如何优化完全独立的代码和有潜在依赖关系的代码;
- 针对 V8 的优化方法。
无论您使用哪种编程语言,都需要考虑到算法性能。当您在本身就“比较慢”的编程语言中使用糟糕的算法时,您能更容易的注意到这一点,但是如果只是换成使用“比较快”的编程语言,还继续使用相同的算法,即使问题会有所缓解,但依然无法从根本上解决问题。这篇文章中的很大一部分内容都致力于这个部分的优化:
- 对子数组排序优化效果要优于对整个数组进行排序优化;
- 讨论使用或者不使用缓存的优缺点。
第二部分是单态性。由于多态性而导致的性能降低不是 V8 特有的问题。这也不是一个 JS 特有的问题。您可以通过不同的实现方式,甚至跨语言的去应用单态。有些语言(Rust,实际上)已经在引擎内为您实现。
最后一个也是最有争议的部分是参数适配问题。
最后,使用映射表示法进行的优化(将单个对象封装到单个类型数组中)横跨了文中提及的三个部分。这是建立在对 GCed 系统的局限性和性能花销,以及 JS 虚拟机作了哪些特殊优化的基础上进行的。
所以... 为什么我选择了这个标题?这是因为我坚信第三部分涉及的问题都会随着时间的推移而被修复。其他部分可通过常用编程语言进行跨语言实现。
很显然,每个开发人员和每个团队都可以自由的去选择,到底是花费 N 小时去分析,阅读和思考他们的 JavaScript 代码,还是花费 M 小时用 X 语言重写他们的东西。
但是:(a)每个人都需要充分意识到这种选择是存在的;(b)语言设计者和实现者应该共同努力使这样的选择越来越不明显 - 也就是说在语言特征和工具方面开展工作,减少“第 3 部分”优化的需求。
原文发布时间为:2018年06月29日
原文作者:elang
本文来源:掘金 如需转载请联系原作者
[译] 或许你并不需要 Rust 和 WASM 来提升 JS 的执行效率 — 第二部分相关推荐
- Rust 构建 Wasm 模块
Rust 构建 Wasm 模块 文章目录 Rust 构建 Wasm 模块 正文 1. 安装 1.1 使用 Rustup 安装 Rust 1.2 安装 wasm-pack 1.3 CLion 配置 2. ...
- Rust: 基于 napi-rs 开发 Node.js 原生模块
Rust: 基于 napi-rs 开发 Node.js 原生模块 文章目录 Rust: 基于 napi-rs 开发 Node.js 原生模块 完整代码示例 背景 & napi 环境/工具链准备 ...
- 从Rust到远方:ASM.js星系
来源: https://mnt.io/2018/08/28/from-rust-to-beyond-the-asm-js-galaxy/ 这篇博客文章是这一系列解释如何将Rust发射到地球以外的许多星 ...
- rust比java慢,rust为什么跑得比js慢
问题描述 实现一个计算斐波那契数列的递归函数, rust代码和js代码在我的电脑上耗时都是11秒, js甚至比rust快一点 问题出现的环境背景 本人刚接触rust,听说它的性能可以和C++媲美,所以 ...
- 一行“无用”的枚举反使Rust执行效率提升10%,编程到最后都是极致的艺术!
最近不少读者都留言说博客中的代码越来越返璞归真,但讨论的问题反倒越来越高大上了,从并发到乱序执行再到内存布局各种放飞自我. 其实这倒不是什么放飞,只是Rust对我来说学习门槛太高了,学习过程中的挫败感 ...
- react结合rust编写wasm图像处理
源码:https://github.com/yirandidi/react_vite_wasm 结果测试:https://yirandidi.github.io/react_vite_wasm/ rs ...
- RTE 大会回顾 | WebAssembly 在音视频领域内的一些实践
WebAssembly 自2015年发展至今已经过去了将近5年的时间,而"Web 音视频领域"则是近些年来它的众多经典实践所涌现的地方.基于 MVP 标准提供的特性,我们已经能够对 ...
- 2019年全栈工程师技术指南和趋势!
作者:李棠辉 https://segmentfault.com/a/1190000017483325 这是一个2019年你成为前端,后端或全栈开发者的进阶指南: 1.你不需要学习所有的技术成为一个we ...
- 关于鸿蒙系统报告,华为鸿蒙操作系统研究报告:全景解构(21页)
鸿蒙微内核从底层即为物联网设计.上述可知,微内核的最大特性是仅在内核中保留 最核心功能,因此对于鸿蒙而言:连接实时性更好(响应时延降低 25.7%.时延波动率降 低 55.6%),同时结合 5G 低时 ...
- java学习(六)多线程 上
进程:进程是一个正在执行的程序,这个程序呢都有一个执行顺序,这个执行顺序是一个执行路径,或者说是一个控制单元. 所有的进程不会同时发生,而是来回切换. 线程:打个比方,一堆货物,一个人搬花十个小时,十 ...
最新文章
- .net core 中的[FromBody]
- 网易MCtalk Live:漫谈短视频平台概况,全面解读头部内容
- 1.1 sikuli 安装
- 指定端口传输_一段话告诉你什么是端口
- 外设驱动库开发笔记8:GPIO模拟I2C驱动
- MySQL企业级主从复制
- 等级保护2.0发布!过了4级的华为云如何帮助你?
- ubuntu 是基于debian gnu/linux,在 Ubuntu 或其它 GNU/Linux 系统下安装 Debian
- Flexigid Options
- 深入浅出Docker(五):基于Fig搭建开发环境
- 角色从项目经理转换ScrumMaster的一些思考和总结
- oracle 认证视频,Oracle 认证专家视频教程-OCP全套教程【98集】_IT教程网
- android 模拟点击屏幕,按键精灵后台简明教程(后台找色,后台鼠标点击等)
- 好儿优机器人_好儿优机器人app
- 微信小程序(一):微信小程序与服务器的简单链接
- IOS端APP测试日志查看方法
- 抽奖系统的实现(两种)
- 二分法查找(dichotomy)--python实现
- python守护进程进程池_Python—守护进程管理工具(Supervisor)
- USB鼠标卡顿解决办法