分布式机器学习(下)-联邦学习
原文链接:https://zhuanlan.zhihu.com/p/114028503
本视频来源于Shusen Wang讲解的《分布式机器学习》,总共有三讲,内容和连接如下:
- 并行计算与机器学习(上)
- 并行计算与机器学习(下)
- 联邦学习:技术角度的讲解
这节课的内容是联邦学习。联邦学习是一种特殊的分布式机器学习,是最近两年机器学习领域的一个大热门。联邦学习和传统分布式学习有什么区别呢?什么是Federated Averaging算法?联邦学习有哪些研究方向呢?我将从技术的角度进行解答。 这节课的主要内容:
- 分布式机器学习
- 联邦学习和传统分布式学习的区别
- 联邦学习中的通信问题
- Federated Averaging算法
- 联邦学习中的隐私泄露和隐私保护
- 联邦学习中的安全问题(拜占庭错误、data poisoning、model poisoning)
- 总结
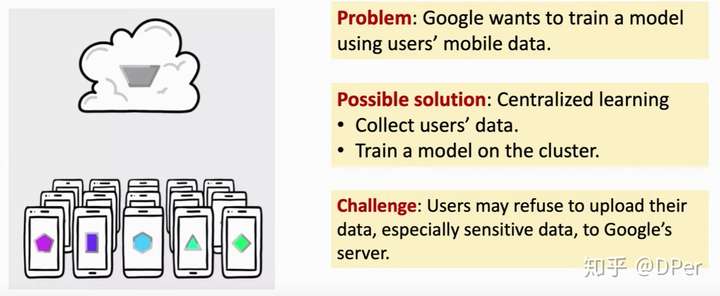
联邦学习有很实际的应用,如移动端会产生数据,但是server,比如谷歌想要从用户那里的数据进行学习。那么一种显然的解决方法就是把数据收集起来,然后学习。但是,现实生活中有着一定的限制,可能处于法律要求或者用户拒绝上传属于,没有一个中心节点可以得到所有的数据,呢么我们该如何去学习模型呢?这个就叫联邦学习。

联邦学习和传统的分布式学习有什么区别呢,主要有以下四点:
- 用户对于自己的设备和有着控制权。
- Worker节点是不稳定的,比如手机可能突然就没电了,或者进入了电梯突然没信号了。
- 通信代价往往比计算代价要高。
- 分布在Worker节点上的数据并不是独立同分布的(not IID)。因此很多已有的减少通信次数的算法就不适用了。
- 节点负载不平衡,有的设备数据多有的设备数据少。比如有的用户几天拍一张照片有的用户一天拍好多照片,这给建模带来了困难。如果给图片的权重一样,那么模型可能往往取决于拍图片多的用户,拍照少的用户就被忽略了。如果用户的权重相同,这样学出来的模型对拍照多的用户又不太好了。负载不平衡也给计算带来了挑战,数据少的用户可能一下子算了很多epoc了,数据多的用户还早着。这一点上,联邦学习不像传统的分布式学习可以做负载均衡,即将一个节点的数据转移到另一个节点。
对于联邦学习,当下有这么几个研究热点:
Research Direction 1: Communication Efficiency
我们回顾一下并行梯度下降中(parallel gradient descent),第 个worker执行了哪些任务
- 从server接收模型参数
- 根据
和本地数据计算梯度
- 将
发送给server
然后server接收了所有用户的 之后,这么做:
- 接收
- 计算:
- 做一次梯度下降,更新模型参数:
- 然后将新的参数发送给用户,等待用户数据重复执行下一轮迭代
那么我们看一下 federated averaging algorithm,其可以用更少的通信次数达到收敛。
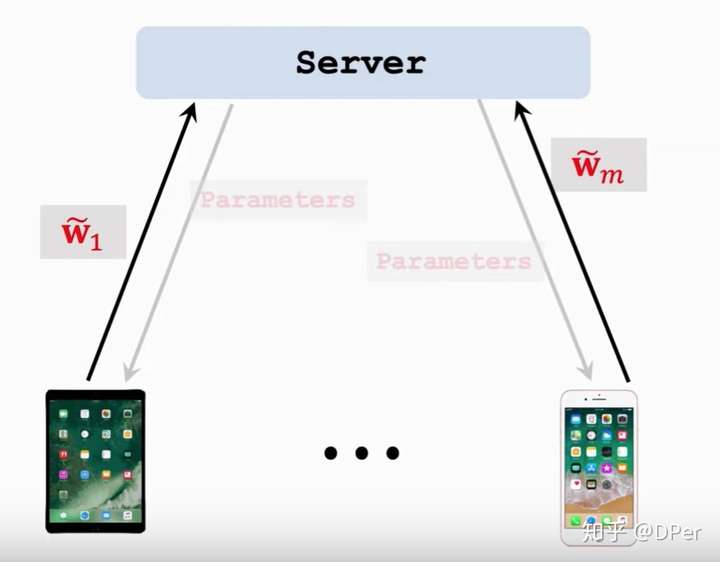
一开始还是sever把参数 发送给worker节点,但是worker和之前就不一样了:
- 接收参数
- 迭代以下过程:
- 利用
- 本地化更新:
- 利用
- 将
发送给server
然后server接收了全部的 之后,这么更新
- 从用户那里接收
- 用以下方程更新
,这个新的模型就叫
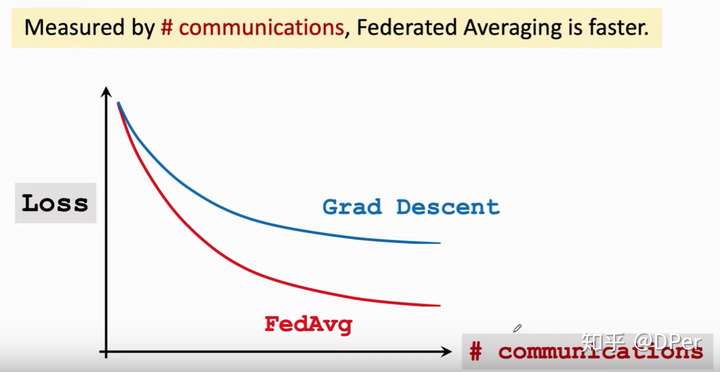
我们把Federated Averaging和梯度下降对比一下,如果以communication为横轴,那么有上图,可见用相同次数的通信,Federated Averaging收敛的更快。两次通信之间Federated Averaging让worker节点做大量计算,以牺牲计算量为代价换取更小的通信次数。如果横轴以epochs为横轴,有以下结果:
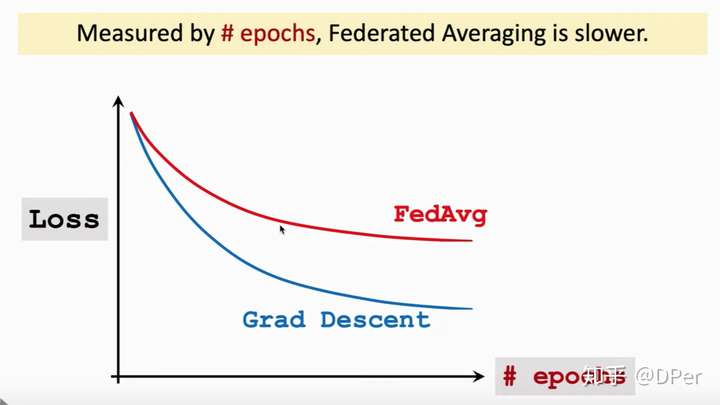
我们可以看到相同次数的epochs,梯度下降的收敛更快。

Federated Averaging算法首次由[1]提出,但是没有理论证明,论文[2]证明了Federated Averaging算法对于对同分布数据是收敛的,论文[3]首次证明了Federated Averaging算法对非独立同分布的数据也是收敛的,论文[4]和[3]得到了类似的结论,但是结果晚一点出来。

减少通信次数是个大问题,减少通信次数并不是Federated Averagin这篇文章首次提出的,这里就列了一些文章,但是这些文章大都要求数据独立同分布,这就难以用到联邦学习中。[4]不要求数据独立同分布,但是不适用于深度学习,神经网络很难求对偶问题。
Research Direction 2: Privacy
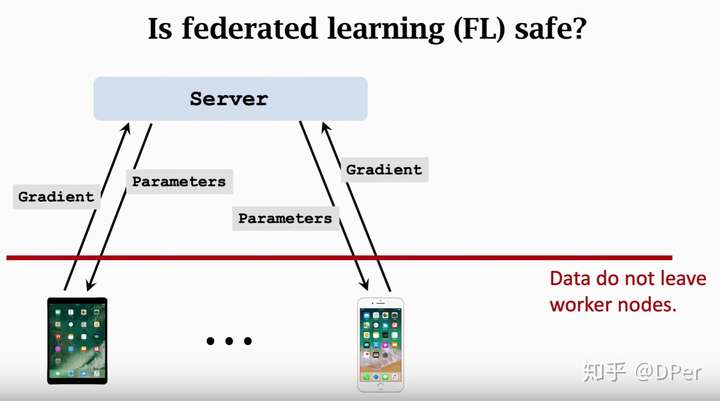
联邦学习中,用户的数据是始终没有离开用户的,那么数据是否安全呢?我们注意到算梯度的过程中实际上就是对数据进行一个变化,将数据映射到梯度。
虽然数据没有发出去,但是梯度是几乎包含数据所有信息的,所以一定程度上,可以通过梯度反推出数据的。
论文[1]说如果一个学习的模型是有用的,那么其肯定泄露了训练数据的信息,当然这点事很显然的。[2]提出额Model Inversion方法可以根据模型反推出数据,但是攻击效果不太好,因为Model Inversion只能看到最后的参数,联邦学习中,我们可以看到每一轮的梯度都是知道的,那么可以反推出更多的信息。[1]和[3]就做了这样的事情,虽然不能完全反推出原始数据,但是可以推出很多的特征,比如用户是男是女。
文章[1]的大致思路如上,将梯度作为输入特征,然后学习一个分类器。其根本原理就是梯度带有用户信息。那么有没有办法抵御这种攻击呢,当前的主流做法就是加噪声,比如 DP。
通常是往梯度里面加噪声,但是实验效果并不理想,噪声大了的话,收敛速度就很慢,甚至学习过程进行不下去,因为目标函数不下降了。噪声小了的话隐私保护效果就不好,还是可以反推出用户数据。加噪声会导致测试准确率下降几个百分点,这在工业界是很难接受的,往往下降一个百分点会带来几十万的损失。
Research Direction 3: Adversarial Robustness
第三个研究热点让联邦学习可以抵御拜占庭错误和恶意攻击。简单说就是worker中出了叛徒,如何学到更好地模型。
[1] 提出了数据poisoning attack,[2]提出了模型poisoning 攻击。有了攻击自然有防御措施,这里就列了三种防御措施。很多方法都假设数据是独立同分布的,但这点现实生活并不满足。总而言之,攻击比较容易,防御比较困难,还没有真正有效的防御。
总结一下,联邦学习是一种比较特殊的分布式学习,目标是让多个用户不共享数据前提下共同训练一个模型,联邦学习有着其特有的挑战,首先数据不是独立同分布,另一个是数据通信代价高。然后还讲了几个研究挑战点。
欢迎关注公众号《差分隐私》
http://weixin.qq.com/r/di4EHC-E4XKerWt-93tk (二维码自动识别)
分布式机器学习(下)-联邦学习相关推荐
- 深度学习核心技术精讲100篇(四十三)-人工智能新技术-知识普及篇:一文带你深入认识下联邦学习的前世今生
前言 联邦学习(Federated Learning)作为人工智能的一个新分支,为机器学习的新时代打开了大门. 本文为您解读: 1. 联邦学习为什么这么热? 2. 联邦学习能做什么? 3. 三合一速成 ...
- 横向联邦学习下隐私保护安全聚合:问题,方法,与展望
开放隐私计算 以下文章来源于隐私计算研习社 ,作者董业 隐私计算研习社. 开放隐私计算社区 本文总结面向横向联邦学习的主要安全聚合技术路线和经典方法,对各条技术路线所处理的问题和经典方法的核心思想做一 ...
- 腾讯天衍实验室联合微众银行研发医疗联邦学习 AI利器让脑卒中预测准确率达80%
近几年,医疗行业正在经历一场数字化转型,这场基于大数据和AI技术的变革几乎改变了整个行业的方方面面,将"信息就是力量"这句箴言体现的淋漓尽致,人们对人工智能寄以厚望,希望它能真正深 ...
- 关于联邦学习What、How、Who的灵魂三问
最近沉迷于学习政治经济学无法自拔,听了很多资本论相关的课程.今天也尝试通过what how who的方式介绍下联邦学习, (感谢这个领域的专家,老同学Dr Liu给我的输入) 灵魂三问指的是: 1.联 ...
- 虚拟专题:联邦学习 | 联邦学习算法综述
来源:大数据期刊 联邦学习算法综述 王健宗1 ,孔令炜1 ,黄章成1 ,陈霖捷1 ,刘懿1 ,何安珣1 ,肖京2 1. 平安科技(深圳)有限公司,广东 深圳 518063 2. 中国平安保险(集团)股 ...
- 虚拟专题:联邦学习 | 面向隐私保护的非聚合式数据共享综述
来源:通信学报 面向隐私保护的非聚合式数据共享综述 李尤慧子1, 殷昱煜1, 高洪皓2,3, 金一4, 王新珩5 1 杭州电子科技大学计算机学院,浙江 杭州 310018 2 上海大学计算机工程与科学 ...
- 【论文】联邦学习区块链 论文集(一)
1.\color{#FF0000} 1.1. Blockchained On-Device Federated Learning 关键词:联邦学习.区块链.延迟分析 主要贡献: 1)用区块链网络来代替 ...
- 【论文】联邦学习区块链 论文集(三)
21.\color{#FF0000} 21.21. Privacy-Preserving Blockchain Based Federated Learning with Differential D ...
- 顶会论文笔记:联邦学习——ATPFL: Automatic Trajectory Prediction Model Design under Federated Learning Framework
ATPFL: Automatic Trajectory Prediction Model Design under Federated Learning Framework 文章目录 ATPFL: A ...
- 联邦学习((Federated Learning,FL)
每日一诗: 题竹(十三岁应试作于楚王孙园亭) --明*张居正 绿遍潇湘外,疏林玉露寒. 凤毛丛劲节,只上尽头竿. 近期在阅读联邦学习领域相关文献,简单介绍如下文.本文仅供学习,无其它用途.如有错误,敬 ...
最新文章
- python使用fpdf生成pdf文件章节(chapter),包含:页眉、页脚、章节主题、数据排版等;
- 【解决方案】本次安装Visual Studio 所用的安装程序不完整
- MacOS常用快捷键
- MapReduce 应用:TF-IDF 分布式实现
- gentoo rt-thread scons --menuconfig libs/lxdialog/util.o: undefined reference to symbol 'nodelay'
- PHFRefreshControl
- 日常生活收缩毛孔几个小妙招 - 健康程序员,至尚生活!
- 【转载】ArrayList 中数据删除 fail fast
- html做在线预览pdf文件,html中在线预览pdf文件之pdf在线预览插件
- 前端显示文本时的格式设置
- ssh 连接linux 乱码问题,SSH 连接 Ubuntu 时的中文乱码问题
- java:eclipse:windows开发环境log4j系统找不到指定的路径
- 个人理财系统springboot项目开发(一)需求分析文档
- matlab2010安装详细图解案例
- blos硬盘启动台式计算机,戴尔台式机bios设置硬盘启动教程
- 手机H5如何对接支付宝登陆授权以及支付(H5网站支付)
- 8篇论文详解用户历史行为序列建模方法
- 冬暖夏凉究竟香不香?带恒温的TaoTronics暖风机开箱实测
- win10, cuda 9.0, python 3.5环境下复现 Flow-Guided Feature Aggregation for Video Object Detection 问题总结
- 浪漫侧影 ( 题解 )