Python Statsmodels 统计包之 OLS 回归
Statsmodels 是 Python 中一个强大的统计分析包,包含了回归分析、时间序列分析、假设检
验等等的功能。Statsmodels 在计量的简便性上是远远不及 Stata 等软件的,但它的优点在于可以与 Python 的其他的任务(如 NumPy、Pandas)有效结合,提高工作效率。在本文中,我们重点介绍最回归分析中最常用的 OLS(ordinary least square)功能。
当你需要在 Python 中进行回归分析时……
import statsmodels.api as sm!!!
在一切开始之前
上帝导入了 NumPy(大家都叫它囊派?我叫它囊辟),
import numpy as np
便有了时间。
上帝导入了 matplotlib,
import matplotlib.pyplot as plt
便有了空间。
上帝导入了 Statsmodels,
import statsmodels.api as sm
世界开始了。
简单 OLS 回归
假设我们有回归模型
Y=β0+β1X1+⋯+βnXn+ε,
并且有 k 组数据 。OLS 回归用于计算回归系数 βi 的估值 b0,b1,…,bn,使误差平方
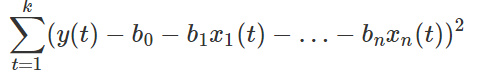
最小化。
statsmodels.OLS 的输入有 (endog, exog, missing, hasconst) 四个,我们现在只考虑前两个。第一个输入 endog 是回归中的反应变量(也称因变量),是上面模型中的 y(t), 输入是一个长度为 k 的 array。第二个输入 exog 则是回归变量(也称自变量)的值,即模型中的x1(t),…,xn(t)。但是要注意,statsmodels.OLS 不会假设回归模型有常数项,所以我们应该假设模型是
 并且在数据中,对于所有 t=1,…,k,设置 x0(t)=1。因此,exog的输入是一个 k×(n+1) 的 array,其中最左一列的数值全为 1。往往输入的数据中,没有专门的数值全为1的一列,Statmodels 有直接解决这个问题的函数:sm.add_constant()。它会在一个 array 左侧加上一列 1。(本文中所有输入 array 的情况也可以使用同等的 list、pd.Series 或 pd.DataFrame。)
并且在数据中,对于所有 t=1,…,k,设置 x0(t)=1。因此,exog的输入是一个 k×(n+1) 的 array,其中最左一列的数值全为 1。往往输入的数据中,没有专门的数值全为1的一列,Statmodels 有直接解决这个问题的函数:sm.add_constant()。它会在一个 array 左侧加上一列 1。(本文中所有输入 array 的情况也可以使用同等的 list、pd.Series 或 pd.DataFrame。)
确切地说,statsmodels.OLS 是 statsmodels.regression.linear_model 里的一个函数(从这个命名也能看出,statsmodel 有很多很多功能,其中的一项叫回归)。它的输出结果是一个 statsmodels.regression.linear_model.OLS,只是一个类,并没有进行任何运算。在 OLS 的模型之上调用拟合函数 fit(),才进行回归运算,并且得到 statsmodels.regression.linear_model.RegressionResultsWrapper,它包含了这组数据进行回归拟合的结果摘要。调用 params 可以查看计算出的回归系数 b0,b1,…,bn。
简单的线性回归
上面的介绍绕了一个大圈圈,现在我们来看一个例子,假设回归公式是:

我们从最简单的一元模型开始,虚构一组数据。首先设定数据量,也就是上面的 k 值。
nsample = 100
然后创建一个 array,是上面的 x1 的数据。这里,我们想要 x1 的值从 0 到 10 等差排列。
x = np.linspace(0, 10, nsample)
使用 sm.add_constant() 在 array 上加入一列常项1。
X = sm.add_constant(x)
然后设置模型里的 β0,β1,这里要设置成 1,10。
beta = np.array([1, 10])
然后还要在数据中加上误差项,所以生成一个长度为k的正态分布样本。
e = np.random.normal(size=nsample)
由此,我们生成反应项 y(t)。
y = np.dot(X, beta) + e
好嘞,在反应变量和回归变量上使用 OLS() 函数。
model = sm.OLS(y,X)
然后获取拟合结果。
results = model.fit()
再调取计算出的回归系数。
print(results.params)
得到
[ 1.04510666, 9.97239799]
和实际的回归系数非常接近。
当然,也可以将回归拟合的摘要全部打印出来。
print(results.summary())
得到
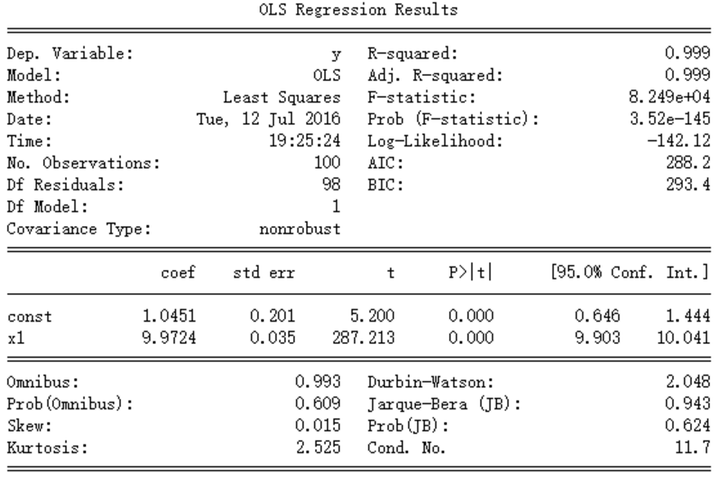
中间偏下的 coef 列就是计算出的回归系数。
我们还可以将拟合结果画出来。先调用拟合结果的 fittedvalues 得到拟合的 y 值。
y_fitted = results.fittedvalues
然后使用 matplotlib.pyploft 画图。首先设定图轴,图片大小为 8×6。
fig, ax = plt.subplots(figsize=(8,6))
画出原数据,图像为圆点,默认颜色为蓝。
ax.plot(x, y, 'o', label='data')
画出拟合数据,图像为红色带点间断线。
ax.plot(x, y_fitted, 'r--.',label='OLS')
放置注解。
ax.legend(loc='best')
得到

在大图中看不清细节,我们在 0 到 2 的区间放大一下,可以见数据和拟合的关系。
加入改变坐标轴区间的指令
ax.axis((-0.05, 2, -1, 25))

高次模型的回归
假设反应变量 Y 和回归变量 X 的关系是高次的多项式,即
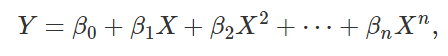
我们依然可以使用 OLS 进行线性回归。但前提条件是,我们必须知道 X 在这个关系中的所有次方数;比如,如果这个公式里有一个 .5项,但我们对此并不知道,那么用线性回归的方法就不能得到准确的拟合。
虽然 X 和 Y 的关系不是线性的,但是 Y 和 的关系是高元线性的。也就是说,只要我们把高次项当做其他的自变量,即设
。那么,对于线性公式
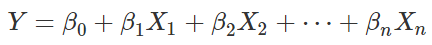 可以进行常规的 OLS 回归,估测出每一个回归系数 βi。可以理解为把一元非线性的问题映射到高元,从而变成一个线性关系。
可以进行常规的 OLS 回归,估测出每一个回归系数 βi。可以理解为把一元非线性的问题映射到高元,从而变成一个线性关系。
下面以
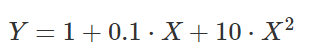 为例做一次演示。
为例做一次演示。
首先设定数据量,也就是上面的 k 值。
nsample = 100
然后创建一个 array,是上面的 x1 的数据。这里,我们想要 x1 的值从 0 到 10 等差排列。
x = np.linspace(0, 10, nsample)
再创建一个 k×2 的 array,两列分别为 x1 和 x2。我们需要 x2 为 x1 的平方。
X = np.column_stack((x, x**2))
使用 sm.add_constant() 在 array 上加入一列常项 1。
X = sm.add_constant(X)
然后设置模型里的 β0,β1,β2,我们想设置成 1,0.1,10。
beta = np.array([1, 0.1, 10])
然后还要在数据中加上误差项,所以生成一个长度为k的正态分布样本。
e = np.random.normal(size=nsample)
由此,我们生成反应项 y(t),它与 x1(t) 是二次多项式关系。
y = np.dot(X, beta) + e
在反应变量和回归变量上使用 OLS() 函数。
model = sm.OLS(y,X)
然后获取拟合结果。
results = model.fit()
再调取计算出的回归系数。
print(results.params)
得到
[ 0.95119465, 0.10235581, 9.9998477]
获取全部摘要
print(results.summary())
得到
 拟合结果图如下
拟合结果图如下
 在横轴的 [0,2] 区间放大,可以看到
在横轴的 [0,2] 区间放大,可以看到

哑变量
一般而言,有连续取值的变量叫做连续变量,它们的取值可以是任何的实数,或者是某一区间里的任何实数,比如股价、时间、身高。但有些性质不是连续的,只有有限个取值的可能性,一般是用于分辨类别,比如性别、婚姻情况、股票所属行业,表达这些变量叫做分类变量。在回归分析中,我们需要将分类变量转化为哑变量(dummy variable)。
如果我们想表达一个有 d 种取值的分类变量,那么它所对应的哑变量的取值是一个 d 元组(可以看成一个长度为 d 的向量),其中有一个元素为 1,其他都是 0。元素呈现出 1 的位置就是变量所取的类别。比如说,某个分类变量的取值是 {a,b,c,d},那么类别 a 对应的哑变量是(1,0,0,0),b 对应 (0,1,0,0),c 对应 (0,0,1,0),d 对应 (0,0,0,1)。这么做的用处是,假如 a、b、c、d 四种情况分别对应四个系数 β0,β1,β2,β3,设 (x0,x1,x2,x3) 是一个取值所对应的哑变量,那么
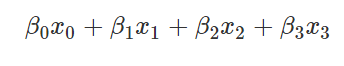
可以直接得出相应的系数。可以理解为,分类变量的取值本身只是分类,无法构成任何线性关系,但是若映射到高元的 0,1 点上,便可以用线性关系表达,从而进行回归。
Statsmodels 里有一个函数 categorical() 可以直接把类别 {0,1,…,d-1} 转换成所对应的元组。确切地说,sm.categorical() 的输入有 (data, col, dictnames, drop) 四个。其中,data 是一个 k×1 或 k×2 的 array,其中记录每一个样本的分类变量取值。drop 是一个 Bool值,意义为是否在输出中丢掉样本变量的值。中间两个输入可以不用在意。这个函数的输出是一个k×d 的 array(如果 drop=False,则是k×(d+1)),其中每一行是所对应的样本的哑变量;这里 d 是 data 中分类变量的类别总数。
我们来举一个例子。这里假设一个反应变量 Y 对应连续自变量 X 和一个分类变量 Z。常项系数为 10,XX 的系数为 1;Z 有 {a,b,c}三个种类,其中 a 类有系数 1,b 类有系数 3,c 类有系数 8。也就是说,将 Z 转换为哑变量 (Z1,Z2,Z3),其中 Zi 取值于 0,1,有线性公式
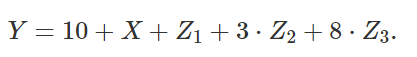 可以用常规的方法进行 OLS 回归。
可以用常规的方法进行 OLS 回归。
我们按照这个关系生成一组数据来做一次演示。先定义样本数量为 50。
nsample = 50
设定分类变量的 array。前 20 个样本分类为 a。
groups = np.zeros(nsample, int)
之后的 20 个样本分类为 b。
groups[20:40] = 1
最后 10 个是 c 类。
groups[40:] = 2
转变成哑变量。
dummy = sm.categorical(groups, drop=True)
创建一组连续变量,是 50 个从 0 到 20 递增的值。
x = np.linspace(0, 20, nsample)
将连续变量和哑变量的 array 合并,并加上一列常项。
X = np.column_stack((x, dummy))
X = sm.add_constant(X)
定义回归系数。我们想设定常项系数为 10,唯一的连续变量的系数为 1,并且分类变量的三种分类 a、b、c 的系数分别为 1,3,8。
beta = [10, 1, 1, 3, 8]
再生成一个正态分布的噪音样本。
e = np.random.normal(size=nsample)
最后,生成反映变量。
y = np.dot(X, beta) + e
得到了虚构数据后,放入 OLS 模型并进行拟合运算。
result = sm.OLS(y,X).fit()
print(result.summary())
得到
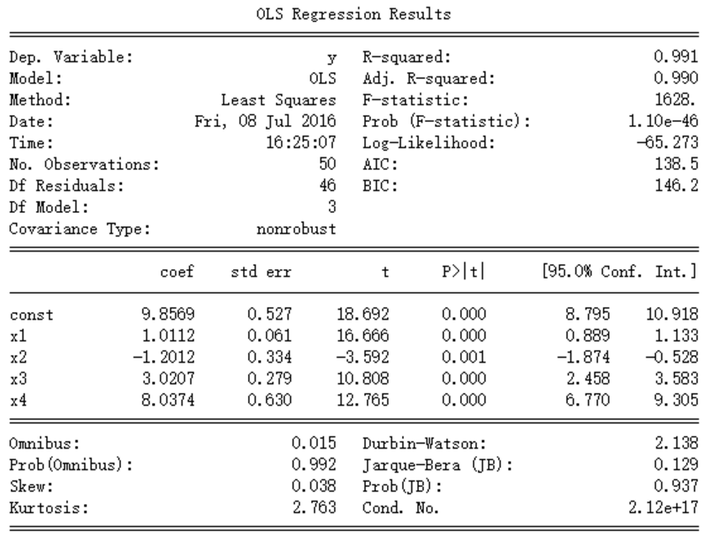
再画图出来
fig, ax = plt.subplots(figsize=(8,6))
ax.plot(x, y, 'o', label="data")
ax.plot(x, result.fittedvalues, 'r--.', label="OLS")
ax.legend(loc='best')
得出

这里要指出,哑变量是和其他自变量并行的影响因素,也就是说,哑变量和原先的 x 同时影响了回归的结果。初学者往往会误解这一点,认为哑变量是一个选择变量:也就是说,上图中给出的回归结果,是在只做了一次回归的情况下完成的,而不是分成3段进行3次回归。哑变量的取值藏在其他的三个维度中。可以理解成:上图其实是将高元的回归结果映射到平面上之后得到的图。
简单应用
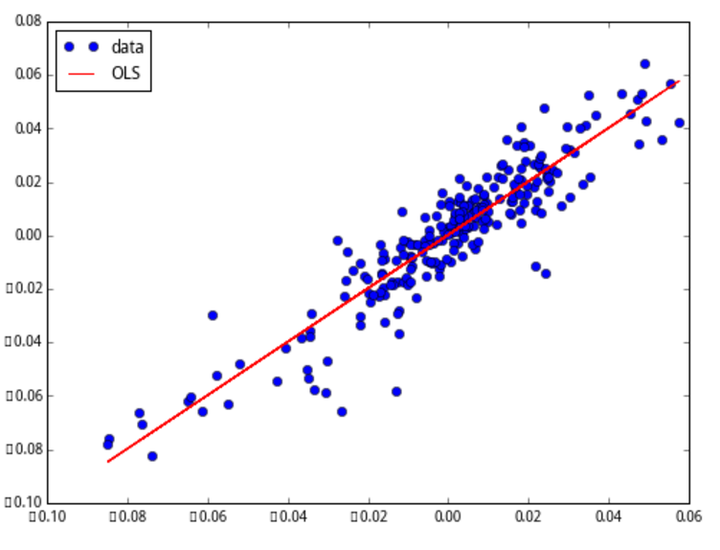
我们来做一个非常简单的实际应用。设 x 为上证指数的日收益率,y 为深证成指的日收益率。通过对股票市场的认知,我们认为 x 和 y 有很强的线性关系。因此可以假设模型
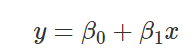 并使用 Statsmodels 包进行 OLS 回归分析。
并使用 Statsmodels 包进行 OLS 回归分析。
我们取上证指数和深证成指一年中的收盘价。
data = get_price(['000001.XSHG', '399001.XSHE'], start_date='2015-01-01', end_date='2016-01-01', frequency='daily', fields=['close'])['close']
x_price = data['000001.XSHG'].values
y_price = data['399001.XSHE'].values
计算两个指数一年内的日收益率,记载于 x_pct 和 y_pct 两个 list 中。
x_pct, y_pct = [], []
for i in range(1, len(x_price)):x_pct.append(x_price[i]/x_price[i-1]-1)
for i in range(1, len(y_price)):y_pct.append(y_price[i]/y_price[i-1]-1)
将数据转化为 array 的形式;不要忘记添加常数项。
x = np.array(x_pct)
X = sm.add_constant(x)
y = np.array(y_pct)
上吧,λu.λv.(sm.OLS(u,v).fit())!全靠你了!
results = sm.OLS(y, X).fit()
print(results.summary())
得到

恩,y=0.002+0.9991x,合情合理,或者干脆直接四舍五入到 y=x。最后,画出数据和拟合线。
fig, ax = plt.subplots(figsize=(8,6))
ax.plot(x, y, 'o', label="data")
ax.plot(x, results.fittedvalues, 'r--', label="OLS")
ax.legend(loc='best')
结语
本篇文章中,我们介绍了 Statsmodels 中很常用 OLS 回归功能,并展示了一些使用方法。线性回归的应用场景非常广泛。在我们量化课堂应用类的内容中,也有相当多的策略内容采用线性回归的内容。我们会将应用类文章中涉及线性回归的部分加上链接,链接到本篇文章中来,形成体系。量化课堂在未来还会介绍 Statsmodel 包其他的一些功能,敬请期待。
到JoinQuant查看代码并与作者交流讨论:【量化课堂】Statsmodels 统计包之 OLS 回归
Python Statsmodels 统计包之 OLS 回归相关推荐
- Statsmodels 统计包之 OLS 回归
Statsmodels 统计包之 OLS 回归 Statsmodels 是 Python 中一个强大的统计分析包,包含了回归分析.时间序列分析.假设检 验等等的功能.Statsmodels 在计量的简 ...
- ols回归结果分析表python_Python Statsmodels 统计包之 OLS 回归
Statsmodels 是 Python 中一个强大的统计分析包,包含了回归分析.时间序列分析.假设检 验等等的功能.Statsmodels 在计量的简便性上是远远不及 Stata 等软件的,但它的优 ...
- python如何运用ols_使用OLS回归(Python,StatsModels,Pandas)预测未来值
我目前正试图在Python中实现一个MLR,我不知道如何去应用我发现的未来值的系数.使用OLS回归(Python,StatsModels,Pandas)预测未来值 import pandas as p ...
- 【教男朋友用python做计量】02.输出OLS回归结果的参数
第二节 输出OLS回归结果的参数 文章目录 第二节 输出OLS回归结果的参数 前言 回归结果提取 1.基础回归 2.输出回归结果参数 总结 前言 FBI WARNING: 上一节讲了怎样用statsm ...
- Python数模笔记-StatsModels 统计回归(2)线性回归
1.背景知识 1.1 插值.拟合.回归和预测 插值.拟合.回归和预测,都是数学建模中经常提到的概念,而且经常会被混为一谈. 插值,是在离散数据的基础上补插连续函数,使得这条连续曲线通过全部给定的离散数 ...
- Python数模笔记-StatsModels 统计回归(3)模型数据的准备
1.读取数据文件 回归分析问题所用的数据都是保存在数据文件中的,首先就要从数据文件读取数据. 数据文件的格式很多,最常用的是 .csv,.xls 和 .txt 文件,以及 sql 数据库文件的读取 . ...
- python最小二乘法拟合模型的loocc误差_线性回归模型库Statsmodels 中 OLS 回归(普通最小二乘法回归)...
Statsmodels 是 Python 中一个强大的统计分析包,包含了回归分析.时间序列分析.假设检 验等等的功能.Statsmodels 在计量的简便性上是远远不及 Stata 等软件的,但它的优 ...
- Python数模笔记-StatsModels 统计回归(1)简介
1.关于 StatsModels statsmodels(http://www.statsmodels.org)是一个Python库,用于拟合多种统计模型,执行统计测试以及数据探索和可视化. 欢迎关注 ...
- 用python进行多元OLS回归
用python进行多元OLS回归 详细解析 描述性统计输出结果 直方图输出结果 散点图输出结果 回归结果 说明 详细解析 使用jupternotebook作为编译软件进行代码实现(当然也可以用Pych ...
最新文章
- 龙芯linux内核移植开发板,基于国产龙芯GS32I的开发板的设计与嵌入式Linux的移植...
- 学习笔记 Keras:基于Python的深度学习库
- 天津财经计算机专业研究生分数线,天津财经大学各专业2015—2020年硕士研究生复试分数线汇总...
- 支付宝pc支付php,laravel框架下的pc支付宝支付接入
- RuoYi-Cloud 进阶篇_04( Seata 高可用集群 AT模式 需求实战)
- adb native raact 夜神_React Native 与 夜神模拟器的绑定
- 【XSY3350】svisor - 点分治+虚树dp
- 新年春节项目海报设计,PSD分层模板,帮你顺利交稿!
- 怎么在虚拟机上安装linux mint,如何在VirtualBox上安装Linux Mint?
- Hadoop热添加删除节点(含Hbase)
- 五行塔怎么吃第五个_朱元璋第五个儿子:被儿子举报造反,日常研究野菜怎么吃...
- Java往前拼接,利用Java程序将字符串进行排序与拼接
- Linux中vi的使用
- [自制]python批量压缩图像
- 数据分析图表配色大全,可视化设计走高级路线的一定要看
- AutoVue使用教程:如何在64位Linux上安装AutoVue
- passwd: Have exhausted maximum number of retries for servic、ssh用普通用户登录输入密码正确但是登录却提示被拒绝问题解决,su到root报错
- element的el-table-column循环渲染和自定义列
- 基于Ant的Mentions自定义公式功能
- 一矢多穿:多目标排序在爱奇艺短视频推荐中的应用