Word2Vec-VS-fastText
原文链接: http://chenhao.space/post/89252767.html
word2vec
Skip-Gram
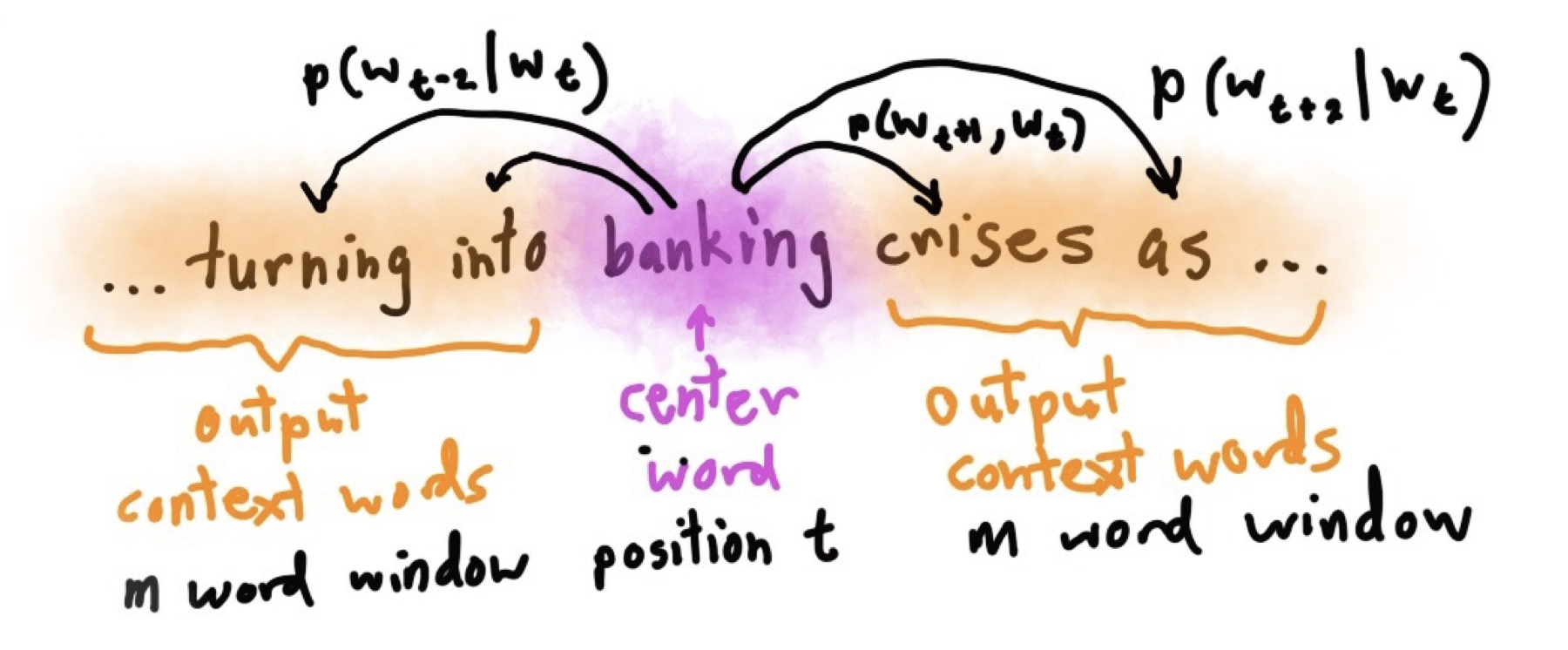
跳字模型其实就是利用中心词预测上下文词这种方法来训练词向量。我们会得到跳字模型其实就是利用中心词预测上下文词这种方法来训练词向量。我们会得到两个向量,第一个是中心词向量,另一个是上下文词的向量。而我们是用跳字模型得到的中心词向量作为词的表征向量。
![]()
其中矩阵 WWW 和 W′W'W′ 就是我们训练得到的两个权重矩阵,ddd 表示的是词表征向量的维度,VVV 表示的是词的个数。WWW 就是所有中心词向量的合成的矩阵,W′W'W′ 是所有上下文词向量合成的矩阵。
下图可能看起来更直观一点:
![]()
计算:
假设这个词在词典中索引为iii,当它为中心词时向量表示为viv_ivi,而为背景词时向量表示为uiu_iui(背景词=上下文词)。设中心词wcw_cwc在词典中索引为ccc,背景词wow_owo在词典中索引为ooo,给定中心词生成背景词的条件概率可以通过对向量内积做softmax运算而得到:
P(wo∣wc)=exp(uo⊤vc)∑i∈Vexp(ui⊤vc),P(w_o \mid w_c) = \frac{\text{exp}(\boldsymbol{u}_o^\top \boldsymbol{v}_c)}{ \sum_{i \in \mathcal{V}} \text{exp}(\boldsymbol{u}_i^\top \boldsymbol{v}_c)}, P(wo∣wc)=∑i∈Vexp(ui⊤vc)exp(uo⊤vc),
VVV是词典索引集合,假设给定一个长度为TTT的文本序列,设时间步ttt的词为w(t)w^{(t)}w(t)。假设给定中心词的情况下背景词的生成相互独立,当背景窗口大小为mmm时,跳字模型的似然函数即给定任一中心词生成所有背景词的概率:
∏t=1T∏−m≤j≤m,j≠0P(w(t+j)∣w(t)),\prod_{t=1}^{T} \prod_{-m \leq j \leq m,\ j \neq 0} P(w^{(t+j)} \mid w^{(t)}), t=1∏T−m≤j≤m,j=0∏P(w(t+j)∣w(t)),
训练中我们通过最大化似然函数来学习模型参数,即最大似然估计。这等价于最小化以下损失函数:
−1T∑t=1T∑−m≤j≤m,j≠0logP(w(t+j)∣w(t)).-\frac{1}{T} \sum_{t=1}^{T} \sum_{-m \leq j \leq m,\ j \neq 0} \text{log}\, P(w^{(t+j)} \mid w^{(t)}). −T1t=1∑T−m≤j≤m,j=0∑logP(w(t+j)∣w(t)).
将第一个条件概率公式取log,得到:
logP(wo∣wc)=uo⊤vc−log(∑i∈Vexp(ui⊤vc))\log P(w_o \mid w_c) =\boldsymbol{u}_o^\top \boldsymbol{v}_c - \log\left(\sum_{i \in \mathcal{V}} \text{exp}(\boldsymbol{u}_i^\top \boldsymbol{v}_c)\right) logP(wo∣wc)=uo⊤vc−log(i∈V∑exp(ui⊤vc))
通过微分,我们可以得到上式中 vcv_cvc 的梯度:
∂logP(wo∣wc)∂vc=uo−∑j∈Vexp(uj⊤vc)uj∑i∈Vexp(ui⊤vc)=uo−∑j∈V(exp(uj⊤vc)∑i∈Vexp(ui⊤vc))uj=uo−∑j∈VP(wj∣wc)uj.\frac{\partial \text{log}\, P(w_o \mid w_c)}{\partial \boldsymbol{v}_c} = \boldsymbol{u}_o - \frac{\sum_{j \in \mathcal{V}} \exp(\boldsymbol{u}_j^\top \boldsymbol{v}_c)\boldsymbol{u}_j}{\sum_{i \in \mathcal{V}} \exp(\boldsymbol{u}_i^\top \boldsymbol{v}_c)}\\ = \boldsymbol{u}_o - \sum_{j \in \mathcal{V}} \left(\frac{\text{exp}(\boldsymbol{u}_j^\top \boldsymbol{v}_c)}{ \sum_{i \in \mathcal{V}} \text{exp}(\boldsymbol{u}_i^\top \boldsymbol{v}_c)}\right) \boldsymbol{u}_j\\ = \boldsymbol{u}_o - \sum_{j \in \mathcal{V}} P(w_j \mid w_c) \boldsymbol{u}_j. ∂vc∂logP(wo∣wc)=uo−∑i∈Vexp(ui⊤vc)∑j∈Vexp(uj⊤vc)uj=uo−j∈V∑(∑i∈Vexp(ui⊤vc)exp(uj⊤vc))uj=uo−j∈V∑P(wj∣wc)uj.
再根据 vc=vc−∂L∂vcv_c=v_c-\frac{\partial L}{\partial v_c}vc=vc−∂vc∂L 来迭代它。
CBOW
连续跳字模型是由上下文词(或背景词)生成中心词。
因为连续词袋模型的背景词有多个,我们将这些背景词向量取平均,再与 WWW 相乘,得到一个Hidden layer,再与 W′W'W′ 相乘,这里的 W′W'W′ 就是我们要训练得到的中心词向量集合成的矩阵。
![]()
给定一个长度为T的文本序列,设时间步ttt的词为w(t)w^{(t)}w(t),背景窗口大小为mmm。连续词袋模型的似然函数是由背景词生成任一中心词的概率:
∏t=1TP(w(t)∣w(t−m),…,w(t−1),w(t+1),…,w(t+m)).\prod_{t=1}^{T} P(w^{(t)} \mid w^{(t-m)}, \ldots, w^{(t-1)}, w^{(t+1)}, \ldots, w^{(t+m)}). t=1∏TP(w(t)∣w(t−m),…,w(t−1),w(t+1),…,w(t+m)).
连续词袋模型的最大似然估计等价于最小化损失函数:
−∑t=1TlogP(w(t)∣w(t−m),…,w(t−1),w(t+1),…,w(t+m)).-\sum_{t=1}^T \text{log}\, P(w^{(t)} \mid w^{(t-m)}, \ldots, w^{(t-1)}, w^{(t+1)}, \ldots, w^{(t+m)}). −t=1∑TlogP(w(t)∣w(t−m),…,w(t−1),w(t+1),…,w(t+m)).
而给定背景词生成中心词的条件概率为:
P(wc∣wo1,…,wo2m)=exp(12muc⊤(vo1+…+vo2m))∑i∈Vexp(12mui⊤(vo1+…+vo2m)).P(w_c \mid w_{o_1}, \ldots, w_{o_{2m}}) = \frac{\text{exp}\left(\frac{1}{2m}\boldsymbol{u}_c^\top (\boldsymbol{v}_{o_1} + \ldots + \boldsymbol{v}_{o_{2m}}) \right)}{ \sum_{i \in \mathcal{V}} \text{exp}\left(\frac{1}{2m}\boldsymbol{u}_i^\top (\boldsymbol{v}_{o_1} + \ldots + \boldsymbol{v}_{o_{2m}}) \right)}. P(wc∣wo1,…,wo2m)=∑i∈Vexp(2m1ui⊤(vo1+…+vo2m))exp(2m1uc⊤(vo1+…+vo2m)).
记 Wo={wo1,…,wo2m}\mathcal{W}_o= \{w_{o_1}, \ldots, w_{o_{2m}}\}Wo={wo1,…,wo2m},且 vˉo=(vo1+…+vo2m)/(2m)\bar{\boldsymbol{v}}_o = \left(\boldsymbol{v}_{o_1} + \ldots + \boldsymbol{v}_{o_{2m}} \right)/(2m)vˉo=(vo1+…+vo2m)/(2m) ,则:
P(wc∣Wo)=exp(uc⊤vˉo)∑i∈Vexp(ui⊤vˉo).P(w_c \mid \mathcal{W}_o) = \frac{\exp\left(\boldsymbol{u}_c^\top \bar{\boldsymbol{v}}_o\right)}{\sum_{i \in \mathcal{V}} \exp\left(\boldsymbol{u}_i^\top \bar{\boldsymbol{v}}_o\right)}. P(wc∣Wo)=∑i∈Vexp(ui⊤vˉo)exp(uc⊤vˉo).
求导:
∂logP(wc∣Wo)∂voi=12m(uc−∑j∈Vexp(uj⊤vˉo)uj∑i∈Vexp(ui⊤vˉo))=12m(uc−∑j∈VP(wj∣Wo)uj).\frac{\partial \log\, P(w_c \mid \mathcal{W}_o)}{\partial \boldsymbol{v}_{o_i}} = \frac{1}{2m} \left(\boldsymbol{u}_c - \sum_{j \in \mathcal{V}} \frac{\exp(\boldsymbol{u}_j^\top \bar{\boldsymbol{v}}_o)\boldsymbol{u}_j}{ \sum_{i \in \mathcal{V}} \text{exp}(\boldsymbol{u}_i^\top \bar{\boldsymbol{v}}_o)} \right) = \frac{1}{2m}\left(\boldsymbol{u}_c - \sum_{j \in \mathcal{V}} P(w_j \mid \mathcal{W}_o) \boldsymbol{u}_j \right). ∂voi∂logP(wc∣Wo)=2m1⎝⎛uc−j∈V∑∑i∈Vexp(ui⊤vˉo)exp(uj⊤vˉo)uj⎠⎞=2m1⎝⎛uc−j∈V∑P(wj∣Wo)uj⎠⎞.
近似训练
由于条件概率使用了softmax运算,每一步的梯度计算都包含词典大小数目的项的累加。对于含几十万或上百万词的较大词典,每次的梯度计算开销可能过大。如:
P(wo∣wc)=exp(uo⊤vc)∑i∈Vexp(ui⊤vc)P(w_o \mid w_c) = \frac{\text{exp}(\boldsymbol{u}_o^\top \boldsymbol{v}_c)}{ \sum_{i \in \mathcal{V}} \text{exp}(\boldsymbol{u}_i^\top \boldsymbol{v}_c)} P(wo∣wc)=∑i∈Vexp(ui⊤vc)exp(uo⊤vc)
它的分母引入了 ∑i∈V\sum_{i \in \mathcal{V}}∑i∈V ,是因为skip-gram模型考虑了每个背景词可能是字典中任意一个词(skip-gram由中心词预测背景词)。这样分母之和为1,但也造成了庞大的计算开销。
为了降低该计算复杂度,引入两种近似训练方法,即负采样(negative sampling)或层序softmax(hierarchical softmax)。
Hierarchical Softmax
Hierarchical softmax 使用一个二叉树来表示词表中的所有词。树中的每个叶结点都是词典中的一个单词,而且只有一条路径从根结点到叶结点。
![]()
假设 L(w)L(w)L(w) 为从二叉树的根结点到词 www 的叶结点的路径(包括根结点和叶结点)上的结点数。设 n(w,j)n(w,j)n(w,j) 为该路径上第 jjj 个结点,并设该结点的背景词向量为 un(w,j)u_{n(w,j)}un(w,j)。如上图,L(w3)=4L(w3)=4L(w3)=4。层序softmax将跳字模型中的条件概率近似表示为:
P(wo∣wc)=∏j=1L(wo)−1σ([[n(wo,j+1)=leftChild(n(wo,j))]]⋅un(wo,j)⊤vc),P(w_o \mid w_c) = \prod_{j=1}^{L(w_o)-1} \sigma\left( [\![ n(w_o, j+1) = \text{leftChild}(n(w_o,j)) ]\!] \cdot \boldsymbol{u}_{n(w_o,j)}^\top \boldsymbol{v}_c\right), P(wo∣wc)=j=1∏L(wo)−1σ([[n(wo,j+1)=leftChild(n(wo,j))]]⋅un(wo,j)⊤vc),
其中的 σ\sigmaσ 是 sigmoidsigmoidsigmoid 函数,leftChild(n)leftChild(n)leftChild(n) 是结点 nnn 的左子结点:如果判断 xxx 为真,[[x]]=1[\![ x ]\!]=1[[x]]=1;反之 [[x]]=−1[\![ x ]\!]=-1[[x]]=−1。
例入计算给定词 wcw_cwc 生成词 w3w_3w3 的条件概率:
P(w3∣wc)=σ(un(w3,1)⊤vc)⋅σ(−un(w3,2)⊤vc)⋅σ(un(w3,3)⊤vc).P(w_3 \mid w_c) = \sigma(\boldsymbol{u}_{n(w_3,1)}^\top \boldsymbol{v}_c) \cdot \sigma(-\boldsymbol{u}_{n(w_3,2)}^\top \boldsymbol{v}_c) \cdot \sigma(\boldsymbol{u}_{n(w_3,3)}^\top \boldsymbol{v}_c). P(w3∣wc)=σ(un(w3,1)⊤vc)⋅σ(−un(w3,2)⊤vc)⋅σ(un(w3,3)⊤vc).
由于σ(x)+σ(−x)=1\sigma(x)+\sigma(-x) = 1σ(x)+σ(−x)=1,给定中心词 wcw_cwc 生成词典 V\mathcal{V}V 中任一词的条件概率之和为1这一条件也将满足:
∑w∈VP(w∣wc)=1\sum_{w \in \mathcal{V}} P(w \mid w_c) = 1 w∈V∑P(w∣wc)=1
这种方法最大的优势是计算概率的时间复杂度仅仅是 O(log2∣V∣)\mathcal{O}(\text{log}_2|\mathcal{V}|)O(log2∣V∣).
Negative Sampling
Negative Sampling 每次让一个训练样本仅仅更新一小部分的权重参数,从而降低梯度下降过程中的计算量。
以skip-gram为例,如一个句子“The quick brown fox jumps over the lazy dog”。如果 vocabulary 大小为1万时, 当输入样本 ( “fox”, “quick”) 到神经网络时, “ fox” 经过 one-hot 编码,在输出层我们期望对应 “quick” 单词的那个神经元结点输出 1,其余 9999 个都应该输出 0。在这里,这9999个我们期望输出为0的神经元结点所对应的单词我们为 negative word。Negative Sampling 的想法是将随机选择一小部分的 negative words,比如选 10个 negative words 来更新对应的权重参数。
fastText
FastText 是一个用于高效学习单词表示和句子分类的库。
论文:Enriching Word Vectors with Subword Information
来源:ACL 2016
Introduction
这篇论文提出了用 character n-grams 的向量之和来代替简单的词向量的方法,以解决简单 word2vec 无法处理同一词的不同形态(the morphology of words)的问题。例如,“dog”和“dogs”分别用两个不同的向量表示,而模型中并未直接表达这两个向量之间的关系。
而子词嵌入的思想可以考虑到有些词形态间的联系。例如,我们可以从“dog”“dogs”和“dogcatcher”的字面上推测它们的关系。这些词都有同一个词根“dog”,但使用不同的后缀来改变词的含义。而且,这个关联可以推广至其他词汇。例如,“dog”和“dogs”的关系如同“cat”和“cats”的关系。
Model
本篇论文的模型是基于Skip-gram进行改动的。
![]()
以单词“where”,n-gram 以n=3为例。“where”被charater n-gram表示为:
<wh,whe,her,ere,re><wh, whe, her, ere, re> <wh,whe,her,ere,re>
以及特殊子词 “<where>”“<where>”“<where>” ,把它们相加得到词“where”的词表征。
该模型就相当于把skip-gram的中心词的词表征做了一些变换。训练过程与skip-gram一致。
Conclusion
- fastText提出了子词嵌入方法。它在word2vec中的跳字模型的基础上,将中心词向量表示成单词的子词向量之和。
- 子词嵌入利用构词上的规律,通常可以提升生僻词表示的质量。
论文:Bag of Tricks for Efficient Text Classification
来源:ACL 2016
Introduction
虽然神经网络模型在文本分类中取得了很好的表现,但是它们在训练和测试时的速度相对较慢,限制了它们在非常大的数据集上的使用。所以作者提出了fastText,它适合大型数据 + 高效的训练速度,并进行了两个任务的实验,标签预测和情感分析。
实验结果表明fastText的准确性方面与深度学习分类器相当,在训练和评估方面快了几个数量级。
Model architecture
该模型是基于CBOW进行改动的。
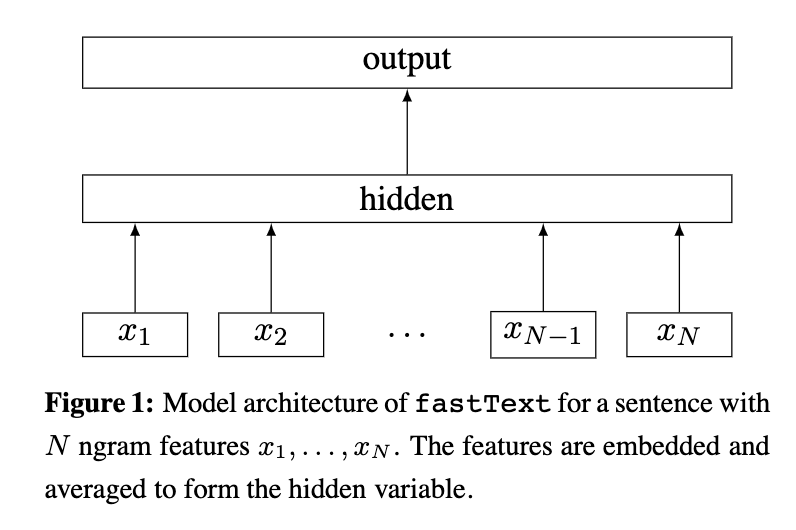
Input layer:输入是多个单词及其n-gram特征,这些特征用来表示单个文本。(因为词袋模型不考虑词序的问题,若将词序信息添加进去又会造成过高的计算代价。文章为了把word order引入,使用了N-gram feature, 并使用哈希算法高效的存储n-gram信息。)
Hidden layer:由输入层求和并平均,乘以权重矩阵A得到的。
Output layer:linear + softmax,输出分类类别。
我们要最大化下面对数似然函数:
∑n=1Nynlog(f(BAxn))\sum_{n=1}^N y_nlog(f(BAx_n)) n=1∑Nynlog(f(BAxn))
也就是要最小化负的对数似然函数(loss function):
−1N∑n=1Nynlog(f(BAxn))-\frac{1}{N} \sum_{n=1}^N y_nlog(f(BAx_n)) −N1n=1∑Nynlog(f(BAxn))
其中,AAA 和 BBB 均是权重矩阵,xnx_nxn 是文档nnn归一化后的n-gram feature,yny_nyn 是label,fff 是softmax函数(当分类的类别数较多时,会使用hierarchical softmax加速)。
| Word2Vec | fastText | |
|---|---|---|
| 输入 | one-hot形式的单词的向量 | embedding过的单词的词向量和n-gram向量 |
| 输出 | 对应的是每一个term,计算某term概率最大 | 对应的是分类的标签 |
Word2Vec用CBOW模型训练词向量得到word embedding,而fastText是用已经训练好的单词的word embedding和n-gram向量来进行文本分类。所以它的模型简单,训练速度非常快,适合用于大数据集。
Experiments
![]()
h=10h=10h=10 表示10个hidden units,也就是使用了10维的特征。
FastText最大的特点是模型简单,只有一层的隐层以及输出层,因此训练速度非常快。
Others
Hash
由于n-gram的量远比词的数量大的多,完全存下所有的n-gram是不太现实的。Fasttext采用了Hash桶的方式,把所有的n-gram都哈希到buckets个桶中,哈希到同一个桶的所有n-gram共享一个embedding vector。如下图所示:
![]()
用哈希的方式既能保证查找时O(1)O(1)O(1)的效率,又可能把内存消耗控制在O(bucket×dim)O(bucket×dim)O(bucket×dim)范围内。不过这种方法潜在的问题是存在哈希冲突,不同的n-gram可能会共享同一个embedding。如果桶大小取的足够大,这种影响会很小。
参考资料
- 动手深度学习-李沐著
- Distributed Representations of Words and Phrases and their Compositionality(2013)
- Bag of Tricks for Efficient Text Classification(2016)
- Enriching Word Vectors with Subword Information
- http://web.stanford.edu/class/cs224n/
- https://www.paperweekly.site/papers/notes/132
- http://albertxiebnu.github.io/fasttext/
- [https://github.com/NLP-LOVE/ML-NLP/tree/master/NLP/16.2%20fastText](https://github.com/NLP-LOVE/ML-NLP/tree/master/NLP/16.2 fastText)
- [[https://github.com/llhthinker/NLP-Papers/blob/master/distributed%20representations/2017-11/Enriching%20Word%20Vectors%20with%20Subword%20Information/note.md](https://github.com/llhthinker/NLP-Papers/blob/master/distributed representations/2017-11/Enriching Word Vectors with Subword Information/note.md)]([https://github.com/llhthinker/NLP-Papers/blob/master/distributed%20representations/2017-11/Enriching%20Word%20Vectors%20with%20Subword%20Information/note.md](https://github.com/llhthinker/NLP-Papers/blob/master/distributed representations/2017-11/Enriching Word Vectors with Subword Information/note.md))
Word2Vec-VS-fastText相关推荐
- 使用Gensim来实现Word2Vec和FastText
2019-12-01 19:35:16 作者:Steeve Huang 编译:ronghuaiyang 导读 嵌入是NLP的基础,这篇文章教你使用Gensim来实现Word2Vec和FastText, ...
- bert获得词向量_NLP中的词向量对比:word2vec/glove/fastText/elmo/GPT/bert
作者:JayLou,NLP算法工程师 知乎专栏:高能NLP之路 https://zhuanlan.zhihu.com/p/56382372 本文以QA形式对自然语言处理中的词向量进行总结:包含word ...
- 词向量与词向量拼接_nlp中的词向量对比:word2vec/glove/fastText/elmo/GPT/bert
本文以QA形式对自然语言处理中的词向量进行总结:包含word2vec/glove/fastText/elmo/bert. 2020年更新:NLP预训练模型的全面总结JayLou娄杰:史上最全!PTMs ...
- 学习笔记四:word2vec和fasttext
FastText:快速的文本分类器 文章目录 一.word2vec 1.1 word2vec为什么 不用现成的DNN模型 1.2 word2vec两种模型:CBOW和Skip-gram 1.2 wor ...
- nlp中的词向量对比:word2vec/glove/fastText/elmo/GPT/bert
本文以QA形式对自然语言处理中的词向量进行总结:包含word2vec/glove/fastText/elmo/bert. 目录 一.文本表示和各词向量间的对比 1.文本表示哪些方法? 2.怎么从语言 ...
- 文本表示模型(2):静态词表示Word2Vec、FastText、GloVe
目录 文本表示模型 静态词嵌入 Word2Vec FastText GloVe 文本表示模型 文本表示模型可分为以下几种: 基于one-hot, tf-idf, textrank等的bag-of-wo ...
- 从one-hot到word2vec再到FastText
0.one-hot representation(稀疏向量) 稀疏向量,就是用一个很长的向量来表示一个词,向量的长度为词典的大小N,向量的分量只有一个1,其他全为0,1的位置对应该词在词典中的索引. ...
- word2vec模型评估_干货 | NLP中的十个预训练模型
Word2vec, Fasttext, Glove, Elmo, Bert, Flair pre-train Word Embedding源码+数据Github网址:https://github.co ...
- fastText、TextCNN、TextRNN……这里有一套NLP文本分类深度学习方法库供你选择 作者:机器人圈 / 微信号:ROBO_AI发表时间 :2017-07-28 图:pixabay
fastText.TextCNN.TextRNN--这里有一套NLP文本分类深度学习方法库供你选择 「机器人圈」编译:嗯~阿童木呀.多啦A亮 这个库的目的是探索用深度学习进行NLP文本分类的方法. 它 ...
- 【NLP】NLP重铸篇之Fasttext
文本分类 论文标题:Bag of Tricks for Efficient Text Classification 论文链接:https://arxiv.org/pdf/1607.01759.pdf ...
最新文章
- ASP.NET十七种正则表达试
- 计算机系统结构研究分支,“计算机系统结构” 课程教学探讨[J] 电子科技大学.doc...
- python处理多个excel文件-Python将多个excel文件合并为一个文件
- matlab中鼠标光标后面的阴影怎么去除,UG在绘图是拖动鼠标出现残影怎么回事?看看这个方法就知道了...
- VTK:Utilities之ExtractFaces
- Java的,与类的初始化顺序
- C++ 控制结构和函数(一) —— 控制结构
- 前端学习(1847)vue之电商管理系统电商系统的功能划分
- VBA之六--EXCEL VBA两则
- javascript函数节流、防抖及使用场景
- 恢复误删除的域用户及几个查询命令
- 开始使用Filebeat
- Flash Professional CS6 安装zxp插件
- Angularjs的http请求
- 换个角度来看看C++中的左值、右值、左值引用、右值引用
- 计算机房灭火器采用哪种类型,机房灭火器类型有哪些
- 企业规划SaaS产品时,要预防商业智能BI取数的坑
- 申请美国大学计算机专业,低GPA如何申请美国大学计算机专业
- Android智能指针——读书笔记
- 假设检验-方差齐性检验