使用Python爬取网页图片
使用Python爬取网页图片
 李晓文
李晓文
近一段时间在学习如何使用Python进行网络爬虫,越来越觉得Python在处理爬虫问题是非常便捷的,那么接下来我就陆陆续续的将自己学习的爬虫知识分享给大家。
首先在进行实战前,我们需要了解几个常用的函数和正则表达式:
一、几个常用的函数
这里介绍的函数是来自于requests扩展包,他们是findall,search和sub函数:
findall(pattern, string, flags=0)
pattern:为正则表达式
string:为字符串
search(pattern, string, flags=0)
pattern:为正则表达式
string:为字符串
findall与search的区别
findall将遍历所有满足条件的内容,而search一般与group(n)搭配使用,选出满足条件的某个内容。
sub(pattern, repl, string, count=0, flags=0)
pattern:为正则表达式
repl:需要替换的内容
string:为原字符串
二、几个常用的爬虫正则表达式
Python爬虫最常用的三个正则表达式为点号,星号,问号和圆括号:
点号:匹配除“\r\n”之外的任何单个字符,可以理解为一个占位符
举例:
x = '1q2wwyxliuwyx3e4rwyxshunwyx1q2wwyxxiangwyx3e4r'
re.findall('wyx.',x)
Out[1]: ['wyxl', 'wyx3', 'wyxs', 'wyx1', 'wyxx', 'wyx3']
返回"wyx"和紧跟其后的第一个字符
re.findall('wyx...',x)
Out[2]: ['wyxliu', 'wyx3e4', 'wyxshu', 'wyx1q2', 'wyxxia', 'wyx3e4']
返回"wyx"和紧跟其后的第一第二个字符
所以可以将点号(.)理解为一个占位符,而且这个占位符可以代表一切字符。
星号:匹配前一个字符任意次
x = '1q2wwyxliuwyx3e4rwyxshunwyx1q2wwyxxiangwyx3e4r'
re.findall('wyx*',x)
Out[3]: ['wyx', 'wyx', 'wyx', 'wyx', 'wyxx', 'wyx']
星号(*)前一个字符为x,所以返回结果中可以找到x的任意次,x字符串中有两个连续的x,所以返回结果中第5个元素就会有两个x。
问号:匹配前一个字符0次或1次,与星号的不同在于其最多匹配一次。
x = '1q2wwyxliuwyx3e4rwyxshunwyx1q2wwyxxiangwyx3e4r'
re.findall('wyx?',x)
Out[4]: ['wyx', 'wyx', 'wyx', 'wyx', 'wyx', 'wyx']
结果显示,返回结果的第五个元素仅含有一个x。
点星组合(.*):贪婪算法,尽可能多的匹配数据
re.findall('wyx.*wyx',x)
Out[5]: ['wyxliuwyx3e4rwyxshunwyx1q2wwyxxiangwyx']
从返回的结果就可以理解“贪婪”的概念了,结果一次性返回wyx与wyx之间的所有内容。
点星问组合(.*?):非贪婪算法,尽可能少的匹配数据
re.findall('wyx.*?wyx',x)
Out[6]: ['wyxliuwyx', 'wyxshunwyx', 'wyxxiangwyx']
而这次的返回结果就完全不同于上面的结果,它尽可能少的返回满足正则表达式的结果,从而将1大串切割为3小串。
圆括号():返回所需信息
re.findall('wyx(.*?)wyx',x)
Out[7]: ['liu', 'shun', 'xiang']
很明显,通过括号的操作,就直接将想提取的内容抠下来了。
三、半自动化的图片爬虫
本次爬虫的实验来自于当当网有关Python书籍的url,即:
url = Python-当当网
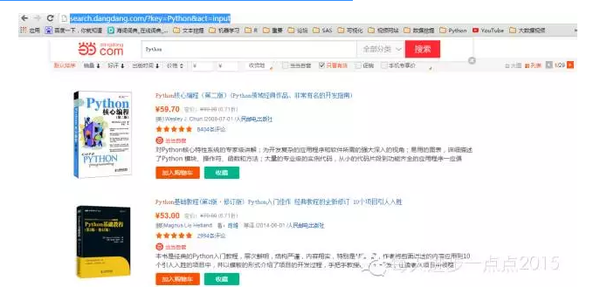
在爬取该网页的图片之前,我们需要了解一下网页源代码中有关图片的模式:

发现关于图片的链接存在两种模式,即"<img src='(.*?)' alt"和"img data-original='(.*?)' src",所以我们需要按两种方式提取图片。
首先,将网页源代码复制出来,粘贴到Pic文本文件中,并将内容读取到Content对象中:
f = open('Pic.txt','r')
Content = f.read()
f.close
其次,分别用两种模型提取出图片链接
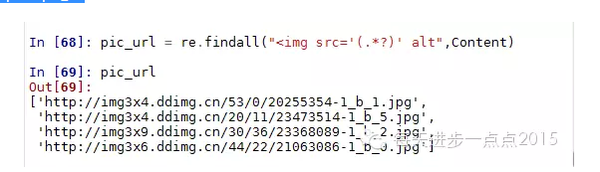
pic_url = re.findall("<img src='(.*?)' alt",Content)
print pic_url
pic_url2 = re.findall("img data-original='(.*?)' src",Content)
print pic_url2

以上两种模式的图片链接已下载好,接下来就是将这两个列表合并:
pic_url.extend(pic_url2)
最后,通过遍历pic_url中的图片链接,将图片下载并保存到指定的目录下:
import requests #导入所需扩展包
i = 0
for url in pic_url: #开始遍历pic_url中的每个元素
print 'Downloding: ' + url
Pic = requests.get(url)
fp = open('Pic\\' + str(i) + '.jpg','wb') #保存文件
fp.write(Pic.content) #将文件写入到指定的目录文件夹下
fp.close()
i = i + 1
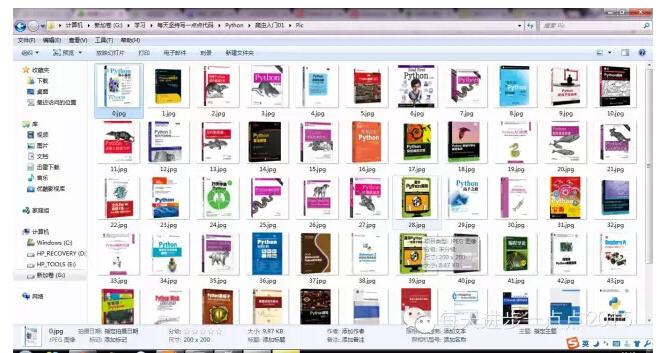
我们看看Pic文件夹是否含有下载好了的文件呢?
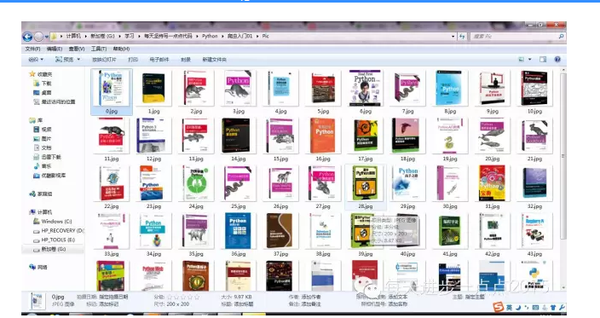
Perfect,网页中的图片全都下载下来啦,很简单吧。有兴趣的同学还不赶快动手试试?
----------------------------------------------
使用Python爬取网页图片相关推荐
- 利用python爬取网页图片
学习python爬取网页图片的时候,可以通过这个工具去批量下载你想要的图片 开始正题: 我从尤物网去爬取我喜欢的女神的写真照,我们这里主要用到的就两个模块 re和urllib模块,有的时候可能会用到t ...
- Python爬取网页图片至本地
Python爬取网页图片至本地 爬取网页上的图片至本地 参考代码如下: # -*- codeing = utf-8 -*- import requests import rephotos = [] h ...
- python爬取网页图片详解
文章目录 什么是爬虫 爬取网页图片实现步骤 第一步:打开所操作的网站(任意一个网站) 第二步:通过python访问这个网站 第三步:点击F12查询相关信息 第四步:爬取图片,下载到本地 第五步:显示测 ...
- Python 爬取网页图片
因为训练数据需求,需要爬取一些图片做训练.爬取的是土巴兔 网站的 家装图片 根据风格进行爬取图片 http://xiaoguotu.to8to.com/list-h3s13i0 可以看到该页面上每一个 ...
- java爬取网页并保存_第九讲:Python爬取网页图片并保存到本地
上一讲我们说了如何把网页的数据通过分析后存储到数据库,我们这次讲如何将网页上的图片提取并下载到本地. 思路如下: 我们本次要爬取的是昵图网首页的图片. 1.首先分析我们要爬取的网页的代码结构,每个网页 ...
- 第九讲:Python爬取网页图片并保存到本地
上一讲我们说了如何把网页的数据通过分析后存储到数据库,我们这次讲如何将网页上的图片提取并下载到本地. 思路如下: 我们本次要爬取的是昵图网首页的图片. 1.首先分析我们要爬取的网页的代码结构,每个网页 ...
- python爬取一张图片并保存_第九讲:Python爬取网页图片并保存到本地
上一讲我们说了如何把网页的数据通过分析后存储到数据库,我们这次讲如何将网页上的图片提取并下载到本地. 思路如下: 我们本次要爬取的是昵图网首页的图片. 1.首先分析我们要爬取的网页的代码结构,每个网页 ...
- 第十讲:Python爬取网页图片并保存到本地,包含次层页面
上一讲我们讲到了从昵图网的首页下载图片到本地,但是我们发现首页上面的大部分链接其实都可以进入到二级页面. 在二级页面里面,我们也可以同样进行图片的下载,通过层层循环我们可以把网址的一部分图片下载到本地 ...
- python爬取动态页面并保存_第十讲:Python爬取网页图片并保存到本地,包含次层页面...
上一讲我们讲到了从昵图网的首页下载图片到本地,但是我们发现首页上面的大部分链接其实都可以进入到二级页面. 在二级页面里面,我们也可以同样进行图片的下载,通过层层循环我们可以把网址的一部分图片下载到本地 ...
最新文章
- Spring,你为何中止我的事务?
- eclipse上安装hadoop后报错 Error:org.hadoop.security.AccessControlException:Permission
- mysql 截取字符串部分值,Mysql字符串截取_获取指定字符串中的数据
- 像程序员一样思考:如何仅使用JavaScript,HTML和CSS来构建Snake
- python之禅星号_Python之禅
- java basic data type,DataStage Basic学习笔记
- matlab代码:考虑实时市场联动的电力零售商鲁棒定价策略
- 俄罗斯技术宅教你如何花5万美元制作家用DNA测序仪
- Java 学习笔记(二十一)
- python营销骗局_利用Python对天猫店铺销售进行分析.下
- 诺贝尔奖计算机二级,计算机二级ppt真题:制作介绍诺贝尔奖ppt
- C#人脸识别入门篇(Step by step 人脸识别)
- SWPUCTF2022 校内赛道部分 wp
- iOS进度条 自定义圆角 UIProgressView
- 计算机网络第一次革命,强国挑战答题答案:计算机工业革命是近代以来人类社会经历的第()次科技革命。...
- Java中的网络编程(TCP与UDP)
- linux下编译自己的静态库时依赖其他的动态库,使用时出现“undefined reference to”
- 笔记本做家庭电影服务器系统,用Helix Server搭建电影服务器 -电脑资料
- Db2干净卸载Linux,如何在Linux下干净卸载db2数据库
- UG塑胶模具设计的全过程