NIN:Network in Network
1 前言
在上一篇文章中笔者介绍了一种可复用的网络模型VGG,在接下来的这篇文章中将向大家介绍另外一种网络模型“Network in Network,NiN(网络中的网络)”。这是一篇是新加坡国立大学2014年发表在顶会ICLR上的一篇论文[1]。笔者在写这篇文章之前其实也没有看过这篇论文,不过当笔者看完这篇论文后发现其动机真的不错,哪怕是放到现在笔者感觉也不会过时。下面就让我们一起来看看这篇论文。公众号后台回复“论文”即可获得下载链接!
2 动机
笔者一直都认为,决定一篇论文的质量很大程度上会依赖于论文作者对于论文动机的描述。这也就是说为什么要写这篇论文?目的是什么?因此,首先我们就来看看今天要介绍的这个模型的动机在哪儿。
作者在论文的摘要部分描述到:传统的卷积层使用的都是“卷积+非线性变换”的组合来对输入的数据进行特征提取;而作者们却同时在卷积层之间还加入了一个小的微型网络来提取更加抽象的特征。那作者为什么要这么做呢?在介绍部分作者继续提到:传统CNN中的卷积核都是可以看作是一种泛化的线性模型(GLM),它并不足以应付更加抽象的特征提取。什么意思呢?你是不是想要说“卷积+非线性变换”怎么还能说它是线性模型?作者继续说到:
By abstraction we mean that the feature is invariant to the variants of the same concept. GLM can achieve a good extent of abstraction when the samples of the latent concepts are linearly separable. Thus conventional CNN implicitly makes the assumption that the latent concepts are linearly separable.
本来就晕晕乎乎的你,读完这几句话你肯定更是不知所云了。什么叫“invariant to the variants of the same concept”?什么又是“ samples of the latent concepts”?CNN解决的怎么就是线性可分的问题了,难道你之前学的是一个假的CNN?
笔者一开始读到这句的时候同样也是云里雾里的,经过反复多次的阅读与揣摩结合一些资料[2] [3] [4],才算是理解了作者想要表达的内容是什么。要理解这几句话的关键就在于要弄明白“invariant to the variants of the same concept”的含义。在这里"concept"指的应该是在特征提取过程中所形成的某一类特征元素。因此,作者认为传统的GLM在特征提取的过程中根本不能区分这些中间过程里所形成的特征元素,除非这些特征元素是线性可分的。所以,在作者的眼里,传统CNN有效的一个假设就是这些特征元素能够线性可分。
![]()
图 1. 不同卷积层的特征结构图[5]
例如在一个用于识别汽车图片的卷积网络模型中,靠前的卷积层会被用于提取一些粗糙的原始的特征(如:线段、棱角等);而靠后的卷积层则会以前面的为基础提取到更为高级一些的特征(如:轮胎、车门等)。同时,在每个阶段里所形的这些特征原始都被称之为 “latent concept”,因为事实上还有很多抽像的特征我们人类是无法辨认的(它可能是有用的特征,也可能不是),所以被称为“latent”。作者认为,传统的GLM在进行每一阶段的特征提取中,根本不足以区分这些特征元素——例如某个卷积层可能提取得到了很多“轮胎”这一类的same concept,但是GLM区分不了这些非线性的特征(到底是哪一类汽车的轮胎)——所以导致最终的任务精度不那么的尽如人意。
到此,对于作者的动机我们总算是弄清楚了,接下来我们再来看看作者是以什么样的技术手段来实现这一动机的。
3 技术手段
任何一篇论文在提出一个合理动机之后都会给出一种相应的技术方案来实现这一动机。那NIN实现动机的技术方案又是什么呢?简单来说就是通过在原始CNN的网络层之间,再插入一些浅层的全连接网络。之所以这么做是因为作者认为:可以先利用这个浅层的网络来对各个阶段里所形成的非线性特征元素进行特征表示,然后再通过卷积层来完成分类类别间线性不可分的抽象表示,以此来提高模型最后的任务精度。
![]()
图 2. NiN 网络模型结构图
如图2所示便是NIN的网络结构图,可以明显的发现每个卷积层之间的多了一些全连接层操作。同时,在NiN最后的分类部分,作者还摒弃了传统的通过多次全连接来进行分类的处理,采用的是将最后输出的特征图以全局最大池化的方式来获得样本属于每个类别的置信度值,接着通过softmax层完成分类。
3.1 MLP Convolution Layers
在NIN中,作者采用了一个三层的全连接网络来作为一个block插入到卷积层之间,但其具体的细节又是怎么样的呢?是将整个特征图reshape成一个向量进行处理吗?从作者在论文介绍部分和MLP Convolution Layers部分的介绍可知,这里的全连接操作实质上就等价于卷积核窗口为 [ 1 × 1 ] [1\times1] [1×1]的卷积操作。因此,我们在实现这个网络的时候也并不需要做任何的全连接操作,只需要做多次窗口大小为 [ 1 × 1 ] [1\times1] [1×1]的卷积即可,这也就相当于在整个特征图的角度做了一次全连接操作。
同时作者还说到,之所以使用全连接网络来作为这个block原因有两点:①全连接网络能够很好的与卷积网络进行转换,即用 [ 1 × 1 ] [1\times1] [1×1]的卷积就可以等价的代替全连接;②全连接网络可以很容易的到达较深的深度,以此来得到更加抽象的特征表示。
最后,作者还从跨通道组合的角度来解释了 [ 1 × 1 ] [1\times1] [1×1]卷积的合理性。这是因为 [ 1 × 1 ] [1\times1] [1×1]窗口的卷积核在执行卷积的过程中,实际上就是对不同通道上同一位置处的特征值进行了一次线性组合。因此,这就可以根据最终训练得到的这个 [ 1 × 1 ] [1\times1] [1×1]的卷积核权重参数来确定每个特征通道的重要性占比(有点注意力机制的味道),并进行融合形成一个通道。作者认为,这种做法的好处就是能够使得模型具有跨特征图交互的能力。那如果要从跨通道交互的角度来解释论文的动机,又该怎么理解呢?欢迎各位读者加群进行交流。
3.2 Global Average Pooling
在传统的卷积网络中,模型在最后进行分类的时候往往都是将最后一层卷积的输出变形成一个向量,然后再将其输入到一个全连接网络中来完成分类任务。但是作者认为这样做的弊端在于最后这部分的全连接网络及其容易过拟合(因为最后一个卷积层reshape后的向量可能高达数十万维),进而限制了模型的整体泛化能力。
在这篇文章中,作者提出了通过以全局平均池化的方式来代替这部分全连接网络。如图3所示,全局平均池化的具体做法是取最后卷积输出的特征图中每一个特征图的均值来作为其中一个类别的logit值。然后再将其输入到softmax分类层进行分类。因此,这也就意味着如果你需要完成的是一个 k k k分类的任务,那么模型最后的卷积输出一定得含有 k k k个通道数。
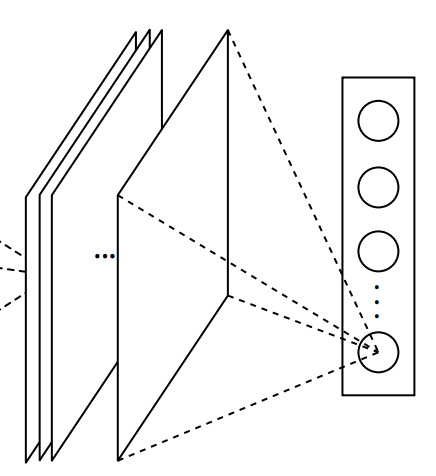 图 3. 全局平均池化图
图 3. 全局平均池化图
为什么NiN的作者会采用这一做法呢?作者认为这样做的好处在于:①用全局平均池化来衔接卷积层特征图和分类器会更加自然,这样也就可以很合理的将全局平均后的特征图解释成是每个类别所对应的分类置信度;②全局平局池化层没有任何参数,这既减少了参数优化的工作又很好的避免了过拟合现象,并且进一步全局平局池化还考虑到了特征图的空间信息。
视频讲解: https://www.zhihu.com/zvideo/1319043697736974336
4 实现
在介绍完网络结构之后我们就来看看如何通过Pytorch来实现这么一个网络模型。不过比较遗憾的是在原始论文中并没有详细的列出网络的配置(如卷积时的步长,是否填充等),但好在经过细致的搜索找到了作者公布在GitHub上的详细配置参数[7]。与此同时,笔者也参考了一些其他人的实现后[6],整理出了下面的代码。
4.1 前向传播
如下所示就是整个NiN网络的前向传播部分:
class NiN(nn.Module):def __init__(self,init_weights=True):super(NiN, self).__init__()self.nin = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=192, kernel_size=5, stride=1, padding=2),nn.ReLU(inplace=True),nn.Conv2d(in_channels=192, out_channels=160, kernel_size=1, stride=1, padding=0),nn.ReLU(inplace=True),nn.Conv2d(in_channels=160, out_channels=96, kernel_size=1, stride=1, padding=0),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2, padding=1),nn.Dropout(0.5),nn.Conv2d(in_channels=96, out_channels=192, kernel_size=5, stride=1, padding=2 ),nn.ReLU(inplace=True),nn.Conv2d(in_channels=192, out_channels=192, kernel_size=1, stride=1, padding=0),nn.ReLU(inplace=True),nn.Conv2d(in_channels=192, out_channels=192, kernel_size=1, stride=1, padding=0),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2, padding=1),nn.Dropout(0.5),nn.Conv2d(in_channels=192, out_channels=192, kernel_size=3, stride=1, padding=1 ),nn.ReLU(inplace=True),nn.Conv2d(in_channels=192, out_channels=192, kernel_size=1, stride=1, padding=0),nn.ReLU(inplace=True),nn.Conv2d(in_channels=192, out_channels=10, kernel_size=1, stride=1, padding=0),nn.ReLU(inplace=True),nn.AvgPool2d(kernel_size=8),nn.Flatten())if init_weights:self._initialize_weights()def forward(self, x):return self.nin(x)def _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight)if m.bias is not None:nn.init.constant_(m.bias, 0)
从代码中可以看出,前两个mlp中的第一次卷积操作采用的都是 [ 5 × 5 ] [5\times5] [5×5]的卷积核,且都填充了两圈零;最后一个mlp中的第一次卷积采用的是 [ 3 × 3 ] [3\times3] [3×3]的卷积核;同时,仅仅只有前两个mlp结束后使用了Dropout操作。可以发现在上面的代码中,我们还采用了kaiming_normal_()初始化方法来对模型中卷积操作的参数进行了初始化。
4.2 训练网络
在原始论文中,作者采用了CIFAR10、CIFAR100、SVHN和MNIST这4个数据集来进行实验对比。由于MNIST这个数据集在前面我们已经多次用到过了,在本次示例中我们就以CIFAR10为例来进行实验。
 图 4. CIFAR10数据集
图 4. CIFAR10数据集
如图4所示就是CIFAR10数据集,它每张图片的形状均为 [ 32 × 32 × 3 ] [32\times32\times3] [32×32×3],同时它包含有10个类别,每个类别中都有6000张图片;其中训练集共有5万张,测试机共有1万张。如果你因为网络原因无法下载该数据集,也可私信公众号回复“数据集”获取网盘下载链接。下面就是具体的训练代码:
def train(self):train_iter, test_iter = load_dataset(batch_size=self.batch_size,resize=None)loss = nn.CrossEntropyLoss(reduction='mean')optimizer = torch.optim.Adam(self.net.parameters(), lr=self.learning_rate) # 定义优化器device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')self.net.to(device)for epoch in range(self.epochs):for i, (x, y) in enumerate(train_iter):x, y = x.to(device), y.to(device)logits = self.net(x)l = loss(logits, y)optimizer.zero_grad()l.backward()optimizer.step() # 执行梯度下降if i % 50 == 0:acc = (logits.argmax(1) == y).float().mean()print("Epochs[{}/{}]---batch {}---acc {:.4}---loss {:.4}".format(epoch + 1, self.epochs, i, acc, l))self.net.eval() # 切换到评估模式print("Epochs[{}/{}]--acc on test {:.4}".format(epoch + 1, self.epochs,self.evaluate(test_iter, self.net, device)))self.net.train() # 切回到训练模式if (epoch+1)%100==0:for param_group in optimizer.param_groups:param_group['lr'] *= 0.8print("learning rate:", param_group['lr'])if __name__ == '__main__':model = NiN()nin = MyModel(model=model, batch_size=128, epochs=800, learning_rate=0.0004)nin.train()
由于论文中并没有过多提及训练部分的详情,所以笔者这里就按照通用的方法定义了优化器、迭代轮数等。同时,这里也没有按照论文中所说的当训练结果不再提升时就将学习率缩小到上一次的 10 % 10\% 10%,而是每100轮迭代缩小 80 % 80\% 80%。完整代码可以参见[8]。
4.3训练结果
Epochs[800/800]---batch 0---acc 1.0 ---loss 0.001347
Epochs[800/800]---batch 50---acc 1.0 ---loss 0.001293
Epochs[800/800]---batch 100---acc 1.0 ---loss 0.005267
Epochs[800/800]---batch 150---acc 1.0 ---loss 0.001384
Epochs[800/800]---batch 250---acc 1.0 ---loss 0.001659
Epochs[800/800]---batch 300---acc 0.9922 ---loss 0.002211
Epochs[800/800]---batch 350---acc 1.0 ---loss 0.0164
Epochs[800/800]---acc on test 0.8643
learning rate : 6.710886400000004e-5
从图5可以看到,NiN模型在没有进行图像增强的处理下,其在测试集上的准确率能够达到 89.59 % 89.59\% 89.59%,而笔者的这一最好结果只有 87.53 % 87.53\% 87.53%。
 图 5. 论文模型结果图
图 5. 论文模型结果图
由于时间的关系,笔者也没有过多去研究训练过程中参数的详细设置和图像增强,所以最后笔者在CIFAR10上的结果与论文中的结果存在着一点差距,如果有朋友能够完全复现论文中的结果也欢迎一起交流。
5 总结
在这篇文章中,笔者首先介绍了论文NiN的动机;然后顺着论文的思路解释了作者是如何通过设计新的网络架构来实现这一动机的:包括引入“网络中的网络”这一全新的设计理念,以及通过全局池化操作来代替最后的全连接部分;最后笔者还以CIFAR10数据集为例进行实验。值得一说的是,作者从跨通道组合的角度来解释 [ 1 × 1 ] [1\times1] [1×1]卷积的作用也是一个非常好的视角,它既有着全连接操作的理念同时还有着注意力的味道,使得我们对于 [ 1 × 1 ] [1\times1] [1×1]的卷积有了更加深刻的认识。在下一篇的文章中,我们将开始学习卷积网络中的第五个经典模型GoogLeNet。
本次内容就到此结束,感谢您的阅读!如果你觉得上述内容对你有所帮助,欢迎关注并传播本公众号!若有任何疑问与建议,请添加笔者微信’nulls8’或加群进行交流。青山不改,绿水长流,我们月来客栈见!
引用
[1]Lin M, Chen Q, Yan S. Network in network[J]. arXiv preprint arXiv:1312.4400, 2013.
[2]Network In Network architecture: The beginning of Inception http://teleported.in/posts/network-in-network/#mlpconv
[3]https://openreview.net/forum?id=ylE6yojDR5yqX
[4]https://zh.d2l.ai/
[5]https://arxiv.org/abs/1311.2901
[6]https://github.com/tflearn/tflearn/blob/master/examples/images/network_in_network.py
[7]https://github.com/mavenlin/cuda-convnet/blob/master/NIN/cifar-10_def
[8]示例代码:https://github.com/moon-hotel/DeepLearningWithMe
推荐阅读
[1] VGG一个可使用重复元素的网络
[2] LeNet5的继任者AlexNet模型
[3] 卷积池化与LeNet5网络模型
NIN:Network in Network相关推荐
- DL之NIN:Network in Network算法的简介(论文介绍)、架构详解、案例应用等配图集合之详细攻略
DL之NIN:Network in Network算法的简介(论文介绍).架构详解.案例应用等配图集合之详细攻略 目录 Network in Network算法的简介(论文介绍) 1.Visualiz ...
- 深度学习:NiN(Network In Network)详细讲解与代码实现
深度学习:NiN(Network In Network)详细讲解与代码实现 网络核心思想 1*1卷积 NiN块的作用 全局池化(Global Average Pooling) 基于NiN的服装分类(P ...
- NIN(Network in Network)学习笔记
NIN(Network in Network)学习笔记 一.前言 <Network In Network>是一篇比较老的文章了(2014年ICLR的一篇paper),是当时比较牛逼的一篇论 ...
- Network in Network(NIN)网络结构详解,网络搭建
一.简介 Network in Network,描述了一种新型卷积神经网络结构. LeNet,AlexNet,VGG都秉承一种设计思路:先用卷积层构成的模块提取空间特征,再用全连接层模块来输出分类结果 ...
- 深度学习方法(十):卷积神经网络结构变化——Maxout Networks,Network In Network,Global Average Pooling
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 最近接下来几篇博文会回到神经网络结构 ...
- NiN(Network in Network) pytorch实现
NiN(Network in Network) NiN(Network in Network)是Min Lin等人在2014的论文<Network in Network>中提出的一种结构, ...
- NIN(Network in Network)
abstract 作者提出一种方法增强感受野的分辨能力(应该是指提取特征的能力),传统卷积神经网络在非线性激活函数之后接一个线性滤波器扫描输入,作者赋予感受野一个更复杂的结构(微型神经元网络)提取数据 ...
- ufldl学习笔记与编程作业:Multi-Layer Neural Network(多层神经网络+识别手写体编程)...
ufldl学习笔记与编程作业:Multi-Layer Neural Network(多层神经网络+识别手写体编程) ufldl出了新教程,感觉比之前的好,从基础讲起,系统清晰,又有编程实践. 在dee ...
- 论文阅读:Spatial context-aware network for salient object detection
论文地址:https://doi.org/10.1016/j.patcog.2021.107867 发表于:PR 2021 Abstract 显著目标检测(SOD)是计算机视觉领域的一个基本问题.本文 ...
最新文章
- 计算机组成原理DMA方式原理,计算机组成原理4(程序查询方式、程序中断方式、DMA方式及其I/O接口电路)...
- Vue-cli3.0Mock数据使用
- Mysql 死锁过程及案例详解之用户自定义锁
- javaScript解决Form的嵌套
- PHP 织梦 帝国那个好,帝国、PHPCMS及织梦对比(十):推荐位功能
- ai前沿公司_美术是AI的下一个前沿吗?
- acer软件保护卡清除工具clear_使用Windows 10内置工具释放硬盘空间的最佳方法
- android inset 标签,android – 有几个WindowInsets?
- 二、kubernetes
- UGUI 与 Spine 的完美结合
- lesson6 复数及复指数
- android通过拼音搜索中文的功能
- 布料仿真先导2-带阻尼的单个小球单摆下的拉格朗日方程列些和matlab仿真
- win10图片浏览改回原来win7的模式
- Maven Helper 插件介绍
- oracle stdevp函数,适用于sql初学,学习sql语句的一些整理,其中大多是oracle的
- ardupilot 中关键坐标系
- ant弹窗_【React】急:请问ant modal(弹出框)怎么修改样式?
- Pygame 游戏开发 图形绘制 键鼠事件
- python软件工程师面试题目及答案_Python面试题及答案汇总整理(2019版)