阿里重磅发布大规模图神经网络平台AliGraph,架构算法解读
图神经网络(GNN)主要是利用神经网络处理复杂的图数据,它将图数据转换到低维空间,同时最大限度保留结构和属性信息,并构造一个用于训练和推理的神经网络。在实际应用中,为了加速GNN训练和新算法的快速迭代,设计一套统一的图计算框架面临着巨大的挑战。近日,阿里巴巴在阿里云峰会北京站上重磅推出了大规模图神经网络平台AliGraph,本文是AI前线第74篇论文导读,我们将深入了解阿里图神经网络库AliGraph背后的系统架构细节和内部自研的GNN算法原理。
介绍
图作为一种复杂的模型,已广泛应用于各种现实应用中的建模和管理数据。典型的例子包括社交网络、物理系统、生物网络和知识图谱等。图分析探索隐藏在图数据中的潜在洞察,在过去的十年,引起了人们极大的关注。它们在许多领域发挥了重要的作用,如节点分类、链接预测、图聚类和推荐系统等。
由于传统的图分析任务经常面临着高额的计算和空间成本,一种称为图嵌入(GE)的新范式为解决此类问题提供了一种高效的方法。具体地说,图嵌入(GE)是将图数据转换为低维空间,以最大程度保留图中结构和内容信息。之后,生成的嵌入作为特征输入到下游机器学习任务中。此外,结合深度学习技术,通过将图嵌入(GE)与卷积神经网络(CNN)相结合,提出了图神经网络(GNN)。在CNN中,采用共享权重和多层结构来增强其学习能力。图是最典型的局部连接结构,共享权值以降低计算成本,多层结构是处理层次模式的关键同时可以捕获各种变化尺寸的特征。GNN是CNN在图上的一种推广。因此,GNN不但拥有图嵌入(GE)的灵活性,而且在有效性和鲁棒性两个方面展示了其优越性。
GNN面临的挑战
当前已有大量论文贡献了大量精力在开发图嵌入(GE)和GNN算法方面上,这些工作主要集中在没有或者有少量辅助信息的简单图上。然而,大数据和复杂系统的兴起揭示了图数据上的新洞察。这是一种共识,绝大多数与现实商业场景相关的图数据表现出四个特点,即大规模、异构、属性化和动态。例如,现在的电商的图通常包含数十亿个顶点和边,这些顶点和边具有各种类型和丰富的属性,并且会随着时间的推移快速演变。这些特性为嵌入和表征图数据带来了巨大的挑战,如下所示:
GNN的核心步骤特别针对网格结构(grid structures)进行了优化,但不适用于不规则欧几里得空间中的图。因此,现有的GNN方法无法在具有极大尺寸的真实图上进行缩放。第一个问题是如何提高大规模图上GNN的时间和空间效率?
不同类型的对象从不同的视角描述数据。它们提供了丰富的信息,但是增加了将图信息映射到单个空间的难度。因此,第二个问题是如何将异构信息优雅地集成到一个统一的嵌入结果中?
属性信息可以进一步增强嵌入结果的能力并且使图嵌入规约成为可能。在不考虑属性信息的情况下,这些算法只能直推学习,而忽略了预测未知实例的必要性。然而,拓扑结构信息和非结构属性信息通常呈现在两个不同的空间中。因此,第三个问题是如何统一保存和定义它们的信息?
由于GNN的效率较低,从零开始更新结构和上下文信息,然后重新计算图嵌入结果非常昂贵。因此,第四个问题是如何设计动态的有效增量GNN方法?
论文贡献
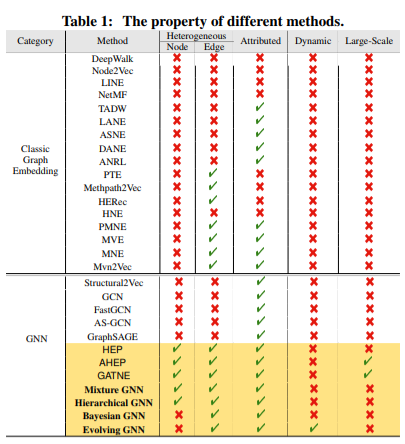
为了应对上述挑战,大量的研究工作致力于设计高效并且有效的GNN方法。在表1中,基于不同工作的关注点以及我们内部开发的模型(黄色阴影部分),我们对一系列流行的GE和GNN模型进行了分类。
如图所示,大多数现有方法同时集中在一个或两个属性上。然而,现实世界中的商业数据通常面临更多的挑战。为了缓解这种情况,在本文中,我们提出了一个全面而系统的GNN解决方案。我们设计并实现了一个名为AliGraph的图神经网络平台,它提供了一套对应的系统和算法来解决更实际的问题,以更好地支持各种GNN方法和应用。
AliGraph的主要贡献包括:
系统
在Aligraph的基础组件中,我们构建了一个支持GNN算法和应用的系统。系统结构是从通用GNN方法中抽象出来的,它由存储层、采样层和操作层组成。具体来说,存储层应用了三种新技术,即结构化和属性化的特定存储,图划分和缓存一些重要顶点的领域,来存储大规模的原始数据以满足高级操作和算法的快速数据访问要求。
采样层优化了GNN方法中的关键采样操作。我们将抽样方法分为三类,即横向抽样(TRAVERSE)、领域抽样(NEIGHBORHOOD)和反向抽样(NEGATIVE),并提出了在分布式环境下进行采样操作的无锁方法。
操作层提供了GNN算法中两个常用的应用操作的优化实现,即聚合(AGGREGATE)和组合(COMBINE)。我们应用缓存策略来存储中间结果,以加速计算过程。这些组件是共同设计和共同优化的,以使整个系统有效和可扩展。
算法
系统提供了一个灵活的接口来设计GNN算法。我们的研究结果表明,所有现有的GNN方法都可以很容易地在我们系统上实现。此外,我们内部还为实际需求开发了几个新的GNN算法。如表1所示,我们内部开发的方法用黄色阴影表示,每种方法在处理实际问题时都更加灵活和实用。
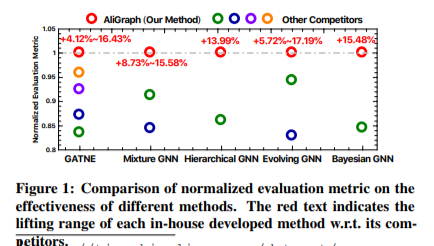
AliGraph平台已经在阿里巴巴公司内部实际部署。实验结果从系统和算法两方面验证了其有效性和效率。如图1所示,我们内部在AliGraph平台上开发的GNN模型,将标准化评估指标提高了4.12%-17.19%。其中数据来自阿里巴巴的电商平台淘宝,我们会将此数据集(预计在2019年5月)贡献给社区,以推动该领域进一步发展。
预备知识
在本节中,表2总结了本文中常见的符号和标记。

属性异构图
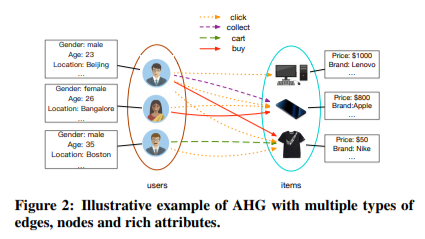
为了全面描述现实世界中的商业数据,实际图往往包含丰富的内容信息,如顶点的多种类型、边的多种类型和属性等,因此我们进一步定义属性异构图(AHG)。AHG是一个元组(V,ε,W,TV,TE,AV,AE),其中V,ε和W跟简单图具有相同的含义。T(V):V–\u0026gt;F(V)和T(E):ε–\u0026gt;F(E)表示顶点类型和边类型的映射函数。为了确保异构性,我们要求|FV|大于等于2和(或)|FE|大于等于2。A(v)和A(E)两个函数,为每个顶点v和每个边e分配一些表征其属性的特征向量。我们将顶点v和边e的第i个特征向量分别表示为x(v,i)和w(e,i)。AHG的一个例子如图2所示,它包含两种类型的顶点,即user和item,以及连接它们的四种类型的边。
动态图
现实世界中图通常随着时间而演化。给定一个时间间隔[1,T],动态图是一个系列的图G(1),G(2),…,G(T)。对于每个t大于等于1并且小于等于T,G(T)是一个简单图或者一个AHG。为了便于记忆,我们添加一个上标t来表示时间戳t处对象的对应状态。例如,V(t) 和E(t)分别表示图G(t)的顶点集和边集合。
问题定义
给定一个输入图G,它是一个简单的图或者AHG,预先定义一个嵌入维度d ∈ N,其中d \u0026lt;\u0026lt; |V|,在尽可能保留图性质的前提下,嵌入问题是将图G转换到d维空间。GNN是一种特殊的图嵌入方法,它将神经网络应用在图上,学习嵌入结果。注意,在本文中,我们主要关注顶点级别的嵌入。也就是说,对于每个顶点v,嵌入输出结果是一个d维度的向量h(v)。我们在第7节中讨论未来工作中,我们还将考虑边的嵌入、子图嵌入甚至是整个图的嵌入。
AliGraph系统详解
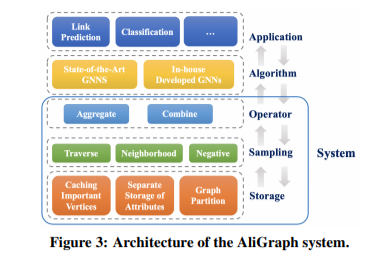
Aligraph平台架构如图3所示,我们设计并实现了一个底层系统(用浅蓝色方块标记),以更好地支持高级别的GNN算法和应用。本节将介绍该系统的详细信息,在第3.1节中,我们抽象了一个GNN的通用框架来解释为什么我们的系统是这样设计的;第3.2至3.5介绍了系统中每个关键组件的设计和实现细节。
3.1 GNN算法框架
在本小节中,我们将为GNN算法抽象为一个通用框架。一系列经典的GNN,如 Structure2Vec,GCN,FastGCN,AS-GCN和GraphSAGE 可以通过在框架中实例化操作器来描述。GNN框架的输入包含一个图G,嵌入维度d ∈ N,每个顶点 v ∈ V的顶点特征x(v),邻居的最大跳数k(max)。对于每个顶点 v ∈ V,GNN的输出是一个嵌入向量h(v),将被送入下游机器学习任务,如分类、链接预测等。
算法1是对GNN框架的描述。在最开始,顶点v的嵌入向量h(v)(0)被初始化为等于输入属性向量x(v)。然后,在每个k处,每个顶点v聚合其邻居顶点的嵌入向量,以更新自身的嵌入向量。具体地说,我们应用样本函数在顶点v的领域集Nb(v) 的基础上提取一个顶点的子集S,用聚合函数对所有顶点u ∈ S的嵌入进行聚合,得到一个向量 h^(v),并将h^(v)与 h(v)(k-1) 通过组合函数生成嵌入向量h(v)(k) 。在处理完所有的顶点后,嵌入向量被归一化。最后,经过k(max) 跳后,
h(v)(k(max)) 作为顶点v的嵌入结果 h(v)返回。

基于上面描述的GNN框架,我们构建了AliGraph平台的系统架构,如上一节图3所示。平台总体由五层组成,其中三个底层构成了系统以支持算法层和应用层。在系统内部,存储层对不同类型的原始数据进行组织和存储,以满足高级操作和算法的快速数据访问要求。
在此基础上,通过算法1,我们发现三个主要的算子在各种GNN算法中起着重要的作用,即采样、聚合和组合。其中,采样操作为聚合和组合操作奠定了基础,因为它直接控制了要处理的信息范围。因此,我们设计了采样层来访问存储,以便快速准确地生成训练样本。在此之上,操作层专门优化聚合和组合函数。在系统的基础上,可以在算法层构建GNN算法,为应用层的实际任务提供服务。
3.2 存储
在本小节中,我们将讨论如何存储和组织原始数据。存储现实世界的图的空间成本非常大,常见的电子商务图可以包含数百亿个节点和数百亿个边,存储成本很容易超过10TB。图的大尺寸给有效访问带来了巨大的挑战,特别是在集群的分布式环境中。为了更好地支持高级运算操作和算法,我们在AliGraph的存储层中应用了以下三种策略。
图分区
Aligraph平台建立在一个分布式环境中,因此整个图被切分并分别存储在不同的work节点。图分区的目标是最小化交叉边(crossing edges)的数量,其的端点(endpoints)分布在不同的work节点上。为此,文献工作中提出一系列算法。
我们实现了四个内置的图分区算法:(1)METIS;(2)顶点切割和边切割分区;(3)2-D分区;(4)流式分区策略,这四种算法适用于不同的环境。简而言之,METIS专门处理稀疏图;顶点切割和边切割分区在稠密图上表现更好;在woker数量固定时,通常使用2-D分区;而流式分区方法通常应用于边更新频繁的图上。用户可以根据自己的需要选择最佳的分区策略,此外,他们还可以将其他图分区算法实现为系统中的插件。
在算法2中,第1-4行给出了图分区的界面。对于每个边e,第4行中的通用ASSIGN函数将根据它的端点(endpoint)计算出e在哪个woker节点中。

单独存储属性
对于AHG,我们需要在每个work节点中存储分区图的结构和属性。图的结构信息可以简单地用邻接表存储。也就是说,对于每个顶点v,我们存储它的邻居集Nb(v)。然而,对于两个顶点的属性和边,不建议将它们存储在邻接表中。原因有两方面:
属性通常需要更多的空间。例如,存储顶点id的空间成本最多为8字节,而顶点上的属性可能在0.1KB到1KB之间。
不同顶点和边之间的属性有很大的重叠。例如,许多顶点可能具有相同的标记”man“,表示其性别。因此,单独存储属性更为合理。
在我们的系统中,我们通过构建两个索引I(v)和I(e)分别在顶点和边上存储属性。如图4所示,在邻接表中,对于每个顶点u,我们将属性Av(u)的索引存储在I(v)中。对于每个边(u,v),我们也将属性Ae(u,v)存储在I(e)中。假设N(D)和N(L)分别是邻居数量的平均值和属性长度的平均值。设N(D)为顶点和边上不同属性的数目。显然,我们单独存储策略将空间成本从O(n*ND*NL)降低到O(n*ND+NA*NL)。
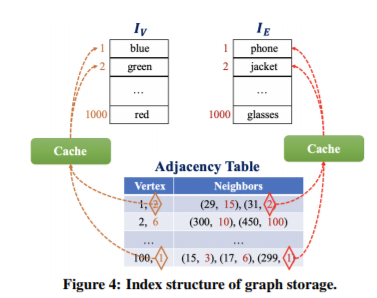
缓存重要顶点的邻居
在每个work节点,我们进一步提出了一种局部缓存重要顶点的邻居的方法,以降低通信成本。如果一个顶点v经常被其他顶点访问,我们可以在它发生的每个分区中存储它的外部邻居。这样做可以大大降低其他顶点通过v访问相邻顶点的开销。但是,如果v的邻居数目很大,存储v的邻居的多个副本也会产生巨大的存储空间成本。为了更好地权衡,我们定义了一个度量来评估每个顶点的重要性,决定一个顶点是否值得缓存。
假设Di(v)(k)和Do(v)(k)分别表示顶点v的k-hop 入和出的邻居的数目。那么Di(v)(k)和Do(v)(k)就可以衡量缓存顶点v的外部邻居的收益和成本。因此,顶点v第k重要性表示为Imp(v)(k),定义如下:
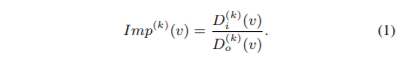
在算法2中,第5-9行给出了缓存重要顶点的邻居的过程。假设h表示邻居的最大深度。对于每个顶点v,我们缓存顶点v的1到k-hop的外部邻居顶点,在Imp(v)(k)大于等于τk的条件下。其中,τk是用户指定的阈值。注意,将h设置为一个小数字(通常为2)就足够支持一系列实际的GNN算法。实际上,我们发现τk不是一个敏感参数。通过实验评估,将τk设置为0.2左右可以在缓存成本和收益之间进行最佳的权衡。
有趣的是,我们发现要缓存的顶点只是整个图的一小部分。Di(v)(1)和Do(v)(1)在实际图中经常服从幂律分布。也就是说,在图中只有很少的顶点具有较大的出入度。基于此,我们得到了以下两个定理。

定理2表明图中只有极少数顶点是重要级别比较高的,这意味着,我们只需缓存少量重要顶点就可以显著降低图遍历的成本。
3.3 采样
回想一下,GNN算法依靠聚合邻居信息来生成每个顶点的嵌入。然而,现实世界图的度的分布往往是偏度的,这使得卷积运算难以操作。为了解决这个问题,现有的GNN通常采用各种抽样策略来对大小一致的邻居子集进行抽样。由于它的重要性,我们在AliGraph中抽象了一个特定的采样层来优化采样策略。
概要
形式上,采样函数接受一个顶点子集V(T)的输入,抽取一个小的子集V(S),|V(S)|\u0026lt;\u0026lt;|V(T)|。通过对现有GNN模型的调研,我们抽象出三种不同的采样器,即遍历、邻域、负采样。
遍历(TRAVERSE):用于从整个分区图中,采样一批顶点或边。
邻域(NEIGHBORHOOD):将生成顶点的上下文。该顶点的上下文可以是一个或多个hop邻居,用于对该顶点进行编码。
负采样(NEGATIV):用于生成负样本以加速训练过程的收敛。
实现
在文献中,抽样方法对提高GNN算法的效率和准确性起着重要的作用。在我们的系统中,采样器都以插件的形式存在。这三种采样器可以实现如下:
对于遍历采样器,他们从局部图中获取数据。
对于领域采样器,他们可以从本地存储获取一跳(one-hop)邻居,也可以从本地缓存获取多跳(multi-hop)邻居。如果没有缓存顶点的邻居,则需要从远程图服务器调用。当获取一批顶点的上下文时,我们首先将顶点划分为子批,并从相应的图服务器上获得返回结果后,每个子批的上下文将被拼接在一起。
负采样器通常从本地图服务器生成样本。对于某些特殊情况,可能需要从其他图服务器进行负采样。负采样在算法上是灵活的,我们不需要批量调用所有的图服务器。
总之,一个典型的采样阶段可以实现为如图5所示。

我们可以通过采用动态权重的几种有效采样策略来加速训练。我们在采样器的反向计算中实现更新操作,就像反向传播的运算一样。所以,当需要更新时,我们应该做的是为采样器注册一个梯度函数。更新模式是同步还是异步,由训练算法决定。
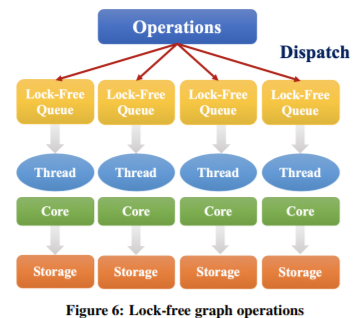
到目前为止,读取和更新都将在内存中的图存储上进行,这可能导致性能下降。根据邻居需要,该图由源顶点分割。在此基础上,我们将图服务器上的顶点分组。每个组都将与一个请求流桶相关,其中的操作(包括读取和更新)都与该组中的顶点有关。桶是一个无锁队列,如图6所示,我们将每个bucket绑定到一个CPU内核,然后,桶中的每个操作都按顺序处理,不加锁进一步提高了系统的效率。
3.4 运算符
概要
采样后,输出的数据被对齐,处理起来就会容易很多。在采样器上,我们需要一些类似GNN的运算符来使用它们。在我们的系统中,我们抽象了两种运算符,即聚合和组合。他们的作用如下:
聚合:收集每个顶点的邻居信息以生成统一的结果。例如,算法1中的聚合算法将一系列向量h(u)映射到单个向量h^(v),其中u属于v的采样邻居节点。h^(v)是一个中间结果为了进一步生成h(k)(v)。聚合函数从周围邻居收集信息,它可以用作卷积操作。各种聚合方法被应用在不同的GNN中,例如,元素平均值、最大池化神经网络和LSTM。
组合: 负责如何使用顶点的邻居来描述顶点。在算法1中,组合函数映射两个向量h(v)(k-1)和h^(v)为一个向量h(v)(k)。组合函数可以将前一跳和领域的信息集成到一个统一的空间中。通常,现有的GNN方法中,h(v)(k-1)和h^(u)求和然后输入到神经网络中。
实现
采样器和类似GNN的运算符不仅可以前向运算,还可以反向运算,以便更新参数,使整个模型成为端到端的训练网络。考虑到图数据的特点,为了获得更好的性能,可以考虑大量的优化。一个典型的运算符由前向和后向的运算组成,以便参与到深层网络的训练中。用户可以在基于运算符的基础上,快速构建GNN算法。
为了进一步加速这两个算子的运算,我们通过应用策略将中间结果向量h(v)(k)缓存。在训练过程中的每个mini-batch中,所有顶点我们可以共享采样邻居集合。同样,在同一个mini-batch中,对于所有的k\u0026gt;=1且k\u0026lt;=k(max),我们也可以共享向量h(v)(k)。为此,我们将k(max)个h^v(1)、h^v(2)、…h^v(kmax)向量存储为mini-batch中所有顶点的最新向量。在聚合函数中,我们利用向量h^v(1)、h^v(2)、…h^v(kmax)来获取h^(v)。然后,我们通过应用组合函数计算h^(v)和h(v)(k-1)来获得h^(v)(k)。最后,存储的向量h^(k)通过h^(v)(k)更新。通过这种策略,运算符的计算成本可以大大减小。
方法论
在系统的基础上,我们来讨论算法的设计。我们的研究结果表明,现有的GNN在AliGraph上非常容易创建。此外,我们还提出了一系列新的GNN算法,以解决第1节中总结的真实世界的图数据嵌入的四个新挑战。它们在AliGraph平台算法层以插件形式供用户使用。
4.1 GNN最佳实践
由于AliGraph平台是基于通用GNN算法抽象出来的,因此现有的GNN可以很容易地在这个平台上实现。具体来说,表1中列出的GNN都可以按照算法1中的框架构建在AliGraph中。这里我们以GraphSAGE为例进行简要介绍,其他GNN也可以用类似的方式实现。对于GraphSAGE,它应用简单的逐节点采样,从每个顶点的相邻集中提取一个子集。显然,这一采样策略通过我们的采样运算符很容易就能实现。然后,我们需要在算法1中实例化聚合和组合函数。GraphSAGE可以在第4行的聚合函数中应用加权元素平均。此外,也可以使用其他更复杂的函数,如maxpooling 神经网络和LSTM神经网络。在其他的GNN方法中,如GCN、FastGCN和AS-GCN,我们可以在抽样、聚合和组合上替换不同的策略。
4.2 阿里内部开发的GNNs
我们内部开发的GNN专注于不同方面,例如:采样(AHEP)、复合边(GATNE)、多模态(Mixture GNN)、层次(Hierarchical GNN)、动态(Evolving GNN)和多源信息(Bayesian GNN)。
AHEP算法
该算法是为了减轻传统嵌入传播(EP)算法在异构网络(HEP)上的繁重计算和存储成本而设计的。HEP遵循GNN的总体框架,对AHG进行了细微修改。
在HEP中,所有的顶点嵌入都是以迭代的方式生成的。在第k次hop中,对于每个顶点v和每个节点类型c,c中v的所有邻居u,传播其嵌入h(u,c)给v来重构一个h^(v,c)嵌入。然后,跨所有节点类型连接h^(v,c)嵌入来更新v的嵌入。但是,在AHEP(HEP用自适应抽样)中,我们只对重要的邻居进行抽样,而不考虑所有邻居。
我们设计了一个度量,通过结合每个顶点的结构信息和特征来评估其重要性。之后,根据相应的概率分布,分别对不同类型的所有邻居进行采样。我们仔细设计了概率分布,以最小化抽样方差。在特定任务中,为了优化AHEP算法,损失函数一般可以描述为:
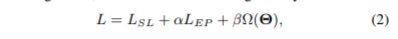
其中,L(SL)是批处理中监督学习的损失,L(EP)是批处理采样时的嵌入传播损失,Ω(Θ)是所有可训练参数的正则化,α, β是两个超参数。根据第5节的实验结果验证,AHEP的运行速度比HEP快得多,同时达到了相当的精度。
GATNE算法
该算法用于处理顶点和边上具有异构和属性信息的图。为了解决上述问题,我们提出了一种既能捕获丰富属性信息,又能利用不同节点类型的多重拓扑结构新方法,即通用的属性多重异构网络嵌入,简称GATNE。
每个顶点的整体嵌入结果由三部分组成:通用嵌入、特定嵌入和属性嵌入,分别对应描述结构信息、异构信息和属性信息。对于每个顶点v和任何节点类型c,通用的嵌入b(v)和属性嵌入f(v)保持相同。设t为可调超参数,当1 ≤ t^ ≤ t时 g(v,t^)是元-特定嵌入。特定嵌入是通过连接所有的g(v,t^)得到。然后,对于每种类型c,所有的h(v,c)嵌入如下:
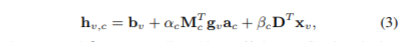
其中,α©和β©是反映特定嵌入和属性嵌入重要性的两个可调参数;利用注意力机制计算系数矩阵a©;M© and D是两个可训练的变化矩阵。最终嵌入结果h(v)可以通过连接所有的h(v,c)。
嵌入可以应用类似于随机游走的方法学习。具体来说,在随机游走中给定c类型的顶点v和窗口大小p,设v(-p),v(-p+1),…v,v(1),…v§表示其上下文。我们需要最小化negative log-likelihood:
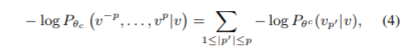
Mixture GNN算法
该模型是一个混合的GNN模型,用于处理多模态的异构图。在这个模型中,我们扩展了异构图上的skip-gram模型,以适应异构图上的多义场景。在传统的skip-gram模型中,我们试图寻找参数为θ的图嵌入,通过最大化似然函数:
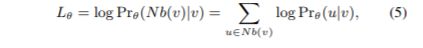
其中,Nb(v)表示v的邻居,Prθ(u|v)表示softmax函数,在我们对异构图上的设置中,每个节点有多感知。为了区分它们,假设P是节点感知的已知分布。我们将目标函数改写为:
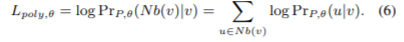
此时,很难结合负采样方法直接优化等式(6)。或者,我们推导出一个新的方程(6)的下界L(low),并尝试最大化L(low)。我们发现下界L(low)可以用负采样近似。因此,在现有的工作中,如Deepwalk和node2vec中,通过稍微修改采样过程,可以很容易地实现训练过程。
层次GNN算法
当前的GNN方法本质上是扁平的,并不学习图的层次表征。这个限制对于明确研究不同类型用户行为的相似性问题时尤其明显。层次GNN算法模型组合了层次结构,增强了GNN的表达能力。
假设H(k)表示在GNN的k步之后,计算节点的嵌入矩阵。A是图G的邻接矩阵,在算法1中,传统的GNN迭代学习H(k)通过组合H(k-1)、A和一些可训练的参数θ(k)。开始,我们设置H(0)=X,其中X表示节点特征的矩阵。在我们的层次GNN中,我们以层级方式学习嵌入结果。具体来说,让A(l)和X(l)分别表示第l层中的邻接矩阵和节点特征矩阵。通过输入A(l)和X(l)到单层GNN来学习第l层的节点嵌入向量结果矩阵Z(l)。
在此之后,我们对图中的一些顶点进行聚类,并将邻接矩阵A(l)更新为A(l+1)。设S(l)表示在第l层中的可学习的赋值矩阵。S(l)中的每一行和每一列分别对应第l层和(l+1)层中的一个聚类。S(l)可以通过在另外一个pooling GNN的A(l)和X(l)上应用softmax函数获得。利用Z(l)和S(l),我们可以为第l+1层获得一个新的粗粒度邻接矩阵A(l+1)=S(l)(T)*A(l)*S(l)和一个新的特征矩阵X(l+1)=S(l)(T)*Z(l)。如第5节所验证的,多层的层次GNN比单层传统GNN更有效。
动态演化的(Evolving)GNN算法
这个模型用于在动态网络设置中的顶点嵌入。我们的目标是学习图序列(G(1),G(2),G(3),…G(T))中顶点的表征。
为了捕获动态图的演化性质,我们将演化链接分为两种类型:(1)正常演化代表边的大部分合理的变化;(2)突发链接代表稀有和异常的边演化。
在此基础上,以交错方式学习动态图中的所有顶点的嵌入。在时间戳t处,图G(t)上找到的正常和突发的链接与GraphSAGE模型集成,以生成G(t)中每个顶点v的嵌入结果h(v)。然后,我们利用变分自动编码器和RNN模型对图G(t+1)上的正常和突发信息进行预测。该过程在迭代中执行,以在每个时间戳t输出每个顶点v的嵌入结果。
贝叶斯GNN算法
该模型通过贝叶斯框架集成了两种信息源,即知识图谱嵌入或行为图嵌入。它模拟了认知科学中人类的理解过程,在这个过程中,每一种认知都是通过调整特定任务下的先验知识来驱动的。具体来说,给定一个知识图G和G中的一个实体(顶点)v,它的基础嵌入h(v)是通过纯粹考虑G本身来学习的,它描述了G中的先验知识,然后根据hv生成一个特定任务下的嵌入z(v),并对该任务生成一个修正项δv,也就是:
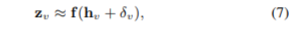
其中,f是一个非线性函数。注意,学习精确的δv和f似乎是不可行的,因为实体v有不同的δv,f函数非常复杂。为了处理这个函数,通过考虑二阶信息,我们应用生成模型从h(v)到z(v)。具体地说,对于每个实体v,我们从一个高斯分布N(0,s(v)(2))中采样出修正变量δv。其中,s(v)由h(v)的相关系数决定。然后,对于每个v1和v2实体对,我们从另外一个高斯分布中采样z(v1)-z(v2):
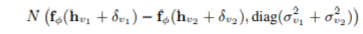
其中,φ表示函数f可训练的参数。δv的后验均值是u^(v),φ^是结果参数。我们应用h(v)+u^(v)作为修正的知识图谱的嵌入,fφ(h(v)+u^(v))作为修正的特定任务的嵌入。
实验
5.1 系统评估
在本小节中,我们从存储、采样、运算的角度评估AliGraph平台中底层系统的性能(图构建和缓存邻居节点)。所有实验都在两个数据集上进行的,如表3所示,Taobao-small和Taobao-large,后者的存储容量是前者的六倍之大。它们都代表了淘宝电子商务平台中用户和物品的子图。
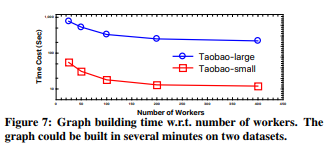
图构建
图构建的性能在图计算平台中起着核心作用。AliGraph支持多种来自不同文件系统的各种原始数据,无论是否分区。图7显示了在两个数据集上worker节点构建图所消耗的时间成本。我们观察到以下两个结果:(1)随着woker节点数量增加,构建图的时间明显缩短了;(2)AliGraph可以在几分钟内构建大型图,如:Taobao-large花费5分钟。这比通常需要几个小时(比如,PowerGraph)构建图的大多数技术高效得多。
缓存邻居的有效性
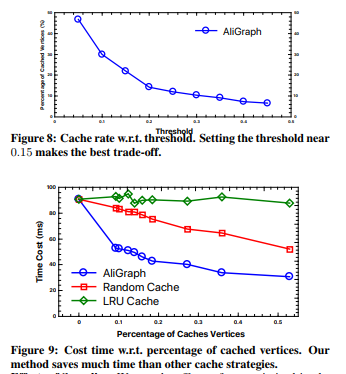
我们研究了缓存重要顶点的k跳(k-hop)邻居的效果。在我们的缓存算法中,为了分析Di(k)和Dv(k),我们为方程1中的Imp(v)设置阈值。在实验中,我们局部缓存所有顶点的一跳(1-hop)邻居,并改变控制缓存二跳(2-hop)邻居的阈值。我们逐渐将阈值从0.05增加到0.45,以测试其敏感性和有效性。
图8说明了缓存顶点百分比和阈值的情况。当阈值小于0.2时,缓存顶点百分比急剧下降,之后变得相对稳定。这是因为顶点的重要性服从幂率分布,正如我们定理2中证明那样。为了在缓存成本和收益之前进行良好的权衡,我们根据图9将阈值设置为0.2,并且只需要缓存大约20%的额外顶点。
我们还比较了基于重要性的缓存策略和另外两种策略,即随机策略(缓存随机选择一小部分顶点的邻居)和LRU替换策略。图9说明了时间成本和缓存顶点百分比的关系。实验结果表明我们的随机策略方法节省了大约40%-50%的时间成本,LRU替换策略节省了大约50%-60%的时间成本。这仅仅是因为:(1)随机选择的顶点不太可能被访问;(2)LRU策略由于经常替换缓存顶点而增加了额外的成本。然而,我们基于重要性的缓存顶点更容易被其他顶点访问。
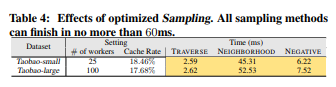
抽样的影响
我们测试了采样优化实现的影响。表4显示了三种抽样方法的时间成本,其中批处理大小512、缓存率为20%。我们发现:(1)采样方法非常有效,完成时间在几毫秒到不到60毫秒之间;(2)采样时间随着图大小缓慢增长,虽然Taobao-large是Taobao-small的六倍,但是两个数据集的采样时间却相当接近。这些观察结果验证了我们的采样方法的实现是有效且可扩展的。
算子的影响
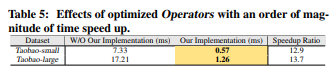
我们进一步研究了我们在聚合、组合算子上实现的影响。表5显示了这两个运算符的时间成本,在我们提出的实现中,时间成本可以加快一个数量级。这是因为我们应用了缓存策略来消除中间嵌入向量的冗余计算,这再次证明了AliGraph平台的优点。
5.2 算法评估
5.2.1实验设置
数据集
我们在实验中使用了两个数据集,包括一个来自Amazon和Taobao-small的公共数据集。
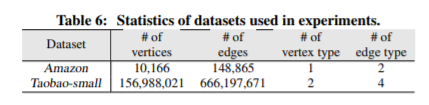
数据集的统计数据汇总在表6中,他们两个都是AHG。Amazon公共数据集是从亚马逊电子产品类别下的产品元数据抽取的。在这个图中,每个顶点代表一个具有属性的产品,每个边连接两个由同一个用户共同查看或者共同购买的产品。它有两个顶点,即user和item,以及user和item之间的四种边类型,即点击、添加到preference、添加到购物车和购买行为。
算法
我们实现了所有在本文中提出的算法。为了进行比较,我们还实现了一些不同类别的有代表性的图嵌入算法,如下所示:
C1:Homogeneous GE 方法。比较的方法包括:DeepWalk、LINE和Node2Vec。这些方法只能应用于纯结构信息的普通图。
C2:带属性的GE方法。 比较方法包括ANRL,它可以生成嵌入捕获结构和属性信息。
C3:异构(Heterogeneous)的GE方法。比较方法包括Methpath2Vec、PMNE、MVE和MNE。MethPath2Vec只能处理具有多种类型顶点的图,而其他三种方法只能处理具有多种类型边的图。PMNE包括三种不同的方法来扩展Node2Vec方法,分别表示为PMNE-n,PMNE-r和PMNE-c。
C4:基于GNN的方法。比较方法包括Structural2Vec、GCN、Fast-GCN、AS-GCN、GraphSAGE和HEP。
为了公平起见,所有的算法都通过在我们的系统上应用优化的运算符来实现。如果一个方法不能处理属性或多个类型的顶点,我们在嵌入过程中会忽略这些信息。我们为具有相同边类型的每个子图生成嵌入,并将它们连接在一起作为基于异构的GNN的最终结果。请注意,在我们的检查中,我们不会比较我们提出的每个GNN算法。因为每个算法设计的侧重点不同。我们将详细介绍每个GNN算法的竞争对手,报告其实验结果。
指标
我们评估了所提出方法的效率和有效性。该算法的执行时间可以用于简单地衡量效率。为了测量有效性,我们将算法应用于广泛采用的链接预测任务,在推荐等现实场景中发挥着重要作用。我们随机抽取一部分数据作为训练集,其余部分作为测试集。为了测量结果的质量,我们使用了四个常用的指标,即ROC曲线下的面积(ROC-AUC)、PR曲线(PR-AUC)、F1分数和命中召回率(HR Rate)。值得注意的是,每个度量在不同类型的边之间取平均值。
参数
对于所有的算法,我们设置嵌入向量的维度d为20。
5.2.1 实验结果
AHEP算法
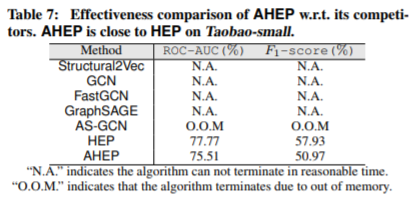
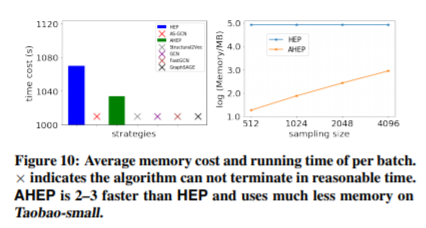
AHEP算法的目标是快速获得嵌入结果同时不会牺牲太多的精度。在表7中,我们展示了在Taobao-small数据集上,AHEP算法和其他算法比较的结果。在图10中,我们说明了不同算法的时间和空间成本。
显然,我们有以下观察:(1)在Taobao-small数据集上,HEP和AHEP是唯一两种能够在合理的时间和空间限制下产生结果的算法。然而,AHEP比HEP快2-3倍,而且比HEP占用的内存要小的多。(2)在结果质量方面,AHEP的ROC-AUC和F1评分与HEP相当。实验结果表明,利用最短的时间和空间,AHEP可以产生与HEP相似的结果。
GATNE算法
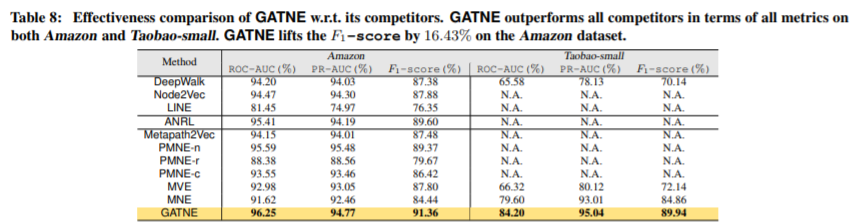
GATNE的目标是处理具有顶点和边的异构和属性信息的图。我们将GATNE算法以及其竞争对手的比较结果显示在表8中。
显然,我们发现GATNE在所有度量指标方面都优于现有的方法。例如,在Taobao-small数据集上,GATNE将ROC-AUC、PR-AUC和F1得分分别提高了4.6%、1.84%和5.08%。这仅仅是因为GATNE同时捕获顶点和边的异构信息以及属性信息。同时,我们发现GATNE的训练时间与woker节点数呈现线性关系。GATNE模型收敛在不到两个小时内,在150个节点的分布式环境下。验证了GATNE方法的高效性和可扩展性。
Mixture GNN
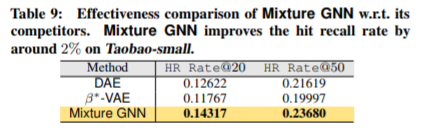
我们比较了Mixture GNN、DAE和β*-VAE方法。将嵌入结果应用于推荐任务的命中率如表9所示。注意,通过应用我们的模型,命中率提高了2%左右。同样,这种改进也在大型网络中有重要贡献。
层次GNN
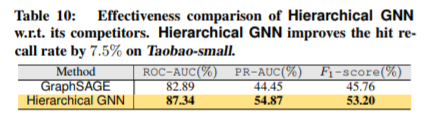
我们比较了层次GNN和GraphSAGE。结果如表10所示。分数显著提高7.5%左右。这表明我们的层次GNN可以产生更具前景的嵌入结果。
Evolving GNN
我们比较了在多分类链接预测任务中Evolving GNN和其他方法。竞争对手包括具有代表性的DeepWalk、DANE 、DNE 、TNE和GraphSAGE。这些竞争算法无法处理动态图,因此我们在动态图的每个快照上运行该算法,并报告所有时间戳的平均性能。Taobao-small数据集的比较结果如表11所示。
我们很容易发现,在所有的度量上,Evolving GNN优于所有其他方法。例如,在剧烈演变情况下,Evolving GNN将微观(micro)和宏观(macro)F1得分提高了4.2%和3.6%。这仅仅是因为我们提出的方法能够更好地捕获真实网络的动态变化,从而产生更具前景的结果。

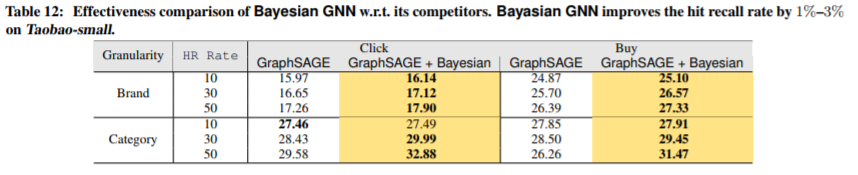
贝叶斯GNN
该模型的目标是将贝叶斯方法和传统GNN模型相结合。我们使用GraphSAGE作为基准线,并将结果与包含和不包含贝叶斯模型的结果进行比较。表12中给出了推荐结果的命中率。注意,我们同时考虑商品品牌和类别的粒度。显然,在应用贝叶斯模型时,命中召回率分别增加了1%到3%。请注意,这种改进可以为我们包含900万个item的网络带来显著的好处。
相关工作
在本节中,我们简要回顾了GE和GNN方法的最佳性能。根据第1节总结的四个挑战,我们将现有方法分类如下。
同质性
DeepWalk首先通过随机游走在图上生成一个语料库,然后,在语料库上训练一个skip-gram 模型。LINE通过保留一阶和二阶近邻来学习节点的表征。NetMF是一个统一的矩阵因式分解框架,用于理论上理解和改进DeepWalk和LINE。Node2Vec增加了两个参数来控制随机游走过程,而SDNE则提出了一种structure-preserving的嵌入方法。GCN使用卷积运算合并邻居的特征表征。GraphSAGE提供一种将结构特征信息与节点特征相结合的归纳方法。
异构性
对于具有多种顶点和(或)边的图,PMNE提出了三种方法将复合边网络投影到连续向量空间。MVE使用注意力机制将具有多视图的网络嵌入到协同后的单个向量表征中。MNE为每个节点使用一个通用嵌入和多个不同边类型的附加嵌入,这些嵌入由统一的网络嵌入模型共同学习。Mvn2Vec通过同时保存和协作建模来探索嵌入结果。HNE将内容和拓扑结构共同考虑为统一的向量表征。PTE利用标记信息构建大规模异构文本网络,并将其嵌入低位空间。Metapath2Vec和HERec将基于元路径的随机游走形式化,以构造节点的异构领域,然后利用skip-gram模型进行节点嵌入。
属性
属性网络嵌入的目的是寻找低维向量表征,以 保留拓扑和属性信息。TADW通过矩阵分解将顶点的文本特征融入到网络表征学习中。LANE在保留相关性的同时,平稳地将标签信息整合到属性网络潜入中。AANE使联合学习过程能够以分布式方式完成,从而加速属性网络嵌入。SNE提出了一种通过捕获结构邻近度和属性邻近度来嵌入社交网络的通用框架。DANE可以捕获高的非线性,并在拓扑结构和节点属性中保留各种近似性。ANRL使用邻居增强自编码器对节点属性信息进行建模,并使用skip-gram模型捕获网络结构。
动态的
实际上,一些静态方法也可以通过基于静态嵌入更新新的顶点来处理动态网络。考虑到新的顶点对原始网络的影响,扩展了skip-gram方法来更新原始顶点的嵌入。“Dynamic network embedding by modeling triadic closure process”重点捕获学习网络嵌入的三元结构属性。考虑网络结构和节点属性,“Attributed network embedding for learning in a dynamic
environment”着重于更新streaming网络的特征向量和特征值。
结论
我们从目前实际的图数据问题中总结出了四个挑战,即大规模、异构、属性和动态。基于这些挑战,我们设计并实现了AliGraph平台,它为解决更多实际问题提供了系统和算法。今后,我们重点关注但不限于以下几个方面:
边级别和子图级别嵌入的GNN;
更多的执行优化,例如,将计算变量与图数据在GNN中共同定位以减少跨网络流量,引入新的梯度优化方法,利用GNN的特点加速分布式训练,而不造成精度损失,在多GPU架构中更好地分配work节点;
Early-stop机制,有助于在没有预期结果的情况下,提前终止训练任务;
Auto-ML,有助于从各种GNN中选择最佳方法。
论文原文链接:https://arxiv.org/pdf/1902.08730.pdf
公开数据集平台:https://tianchi.aliyun.com/dataset/dataDetail?dataId=9716
更多内容,请关注AI前线

阿里重磅发布大规模图神经网络平台AliGraph,架构算法解读相关推荐
- 设无向图g如图所示_阿里重磅发布大规模图神经网络平台 AliGraph,架构算法解读...
图神经网络 (GNN) 主要是利用神经网络处理复杂的图数据,它将图数据转换到低维空间,同时最大限度保留结构和属性信息,并构造一个用于训练和推理的神经网络.在实际应用中,为了加速 GNN 训练和新算法的 ...
- 英特尔计算引擎、阿里大规模图形神经网络平台、百度飞桨平台、索尼音乐生成AI套件......重量级深度学习工业产品亮相NeurIPS 2019行业展览会!
NeurIPS 2019的正式会议将于加拿大/温哥华时间的12月9日早上8点开始.会议前一天将会举办为期一整天的行业展览会(可能是赞助商太多了--) 当别人为明天的正式会议捉急准备时,小助手已经在展览 ...
- 刚刚,阿里重磅发布机器学习平台PAI 3.0!
\u003cblockquote\u003e\n\u003cp\u003e3月21日,2019 阿里云峰会在北京召开,会上阿里巴巴重磅发布了机器学习平台PAI 3.0版本.距离PAI 2.0发布已经过 ...
- 独家解读!阿里重磅发布机器学习平台PAI 3.0
策划编辑|Natalie 编辑|Debra AI 前线导读:3 月 21 日,2019 阿里云峰会在北京召开,会上阿里巴巴重磅发布了机器学习平台 PAI 3.0 版本.距离 PAI 2.0 发布已经过 ...
- “含光”剑出,谁与争锋?阿里重磅发布首颗AI芯片含光800
作者 | 夕颜.胡巍巍 编辑 | 唐小引 出品 | AI 科技大本营(ID:rgznai100) 9 月末的杭州气温适宜,宜出游,宜在湖边餐厅浅酌一杯清茶消闲.但在钱塘江水支流河畔的云栖小镇,却完全一 ...
- 阿里云技术白皮书_对阿里重磅发布的云原生架构白皮书的初步解读
今天准备整理和分享下阿里云发布的云原生架构白皮书.在今年7月份,由阿里云20+位云原生技术专家共同编撰的<云原生架构白皮书>正式对外发布.据官方介绍,本书涵盖了云原生架构的产生缘由.阿里云 ...
- AliGraph:一个工业级的图神经网络平台
简介: 2019年12月8日,神经网络和深度学习领域的顶会NeurIPS 在加拿大温哥华召开,阿里巴巴计算平台PAI团队和达摩院智能计算实验室开发的Aligraph在Expo Day 现场进行展示. ...
- FAIR重磅发布大规模语料库XNLI:解决跨15种语言理解难题
作者 | Facebook AI 研究院和纽约大学研究团队 译者 | 盖磊 编辑 | Vincent AI 前线导读:自然语言处理系统依赖于使用基于标注数据的有监督学习提高模型的处理能力.目前,许多模 ...
- 什么是底层架构_厉害!阿里技术专家发布1500多页计算机底层架构原理解析宝典|现代汽车|计算机|原理|操作系统|存储器...
计算机被称为20世纪最伟大的发明之一 .1946年诞生的第一台电子计算机ENIAC,是一个每秒能运行5000次.重达30吨的庞然大物.如今计算机变得无处不在,以至于人们大大低估了它的复杂性一今天一 部 ...
最新文章
- python3读取excel数据-python3 读取Excel表格中的数据
- JavaScript 技术篇-js获取dom节点、html标签自定义属性的值。
- WinXP中鲜为人知的28项隐藏功能
- java操作文件爱女_Java的IO操作---File类
- 最新编程语言排名:Python超Java、JS保持领头羊
- Auto-ML之自动化特征工程
- explain和profiling分析查询SQL时间
- 蓝桥杯2021年第十二届C++省赛第九题-双向排序
- ssm提交post_SSM中get和post乱码笔记
- 求小球落地5次后所经历的路程和第5次反弹的高度
- 荣耀手机动态修改手机型号参数
- 收藏 | 电子元器件图片、名称、符号图形对照
- Qt 远程开关机 WakeOnLAN 编辑MagicPacket
- 2018年访日外国游客消费创新高 中国大陆居首
- 一、PR的初始重要设置
- HITNet: Hierarchical Iterative Tile Refinement Network for Real-time Stereo Matching--Google
- Arduino应用开发——LCD显示GIF动图
- C 语言取整的几种方法
- Arduino使用u8g2库函数驱动4线/6线OLED屏幕(I2C/SPI通讯)附带库函数详解
- Java雷电游戏要准备什么_Java 雷电游戏(未完成)
热门文章
- mysql+monitor+下载_详解MySQL监控工具 mysql-monitor
- Kotlin极简教程:第7章 面向对象编程
- Keil uVision5中配置stm32标准固件库v3.5
- usb过滤驱动inf_N卡驱动全家桶专治工具升级:专为玩家打造
- html应用多个类,html – 如何避免重复多个css类
- effective java英文版pdf_Java之Spring1:Spring简介、环境搭建、源码下载及导入MyEclipse...
- msf生成linux shellcode,MSF-Shellcode生成和使用
- Spring 详解(二):IOC 和DI
- Java设计模式(九):模板方法设计模式
- springboot 按钮权限验证_springboot学习之权限系统登录验证SpringSecurity