杰出数据科学家的关键技能是什么?

本文为 AI 研习社编译的技术博客,原标题 :
What is the key skill that the best data scientists have?
作者 | André Sionek
翻译 | kylechenoO、Ophria
校对 | 酱番梨 整理 | 菠萝妹
原文链接:
https://towardsdatascience.com/what-is-the-key-skill-that-the-best-data-scientists-have-655edea228ac
学习如何应用不同的Python或R算法真的很简单:众所周知, 我们只需要修改一两行代码,就能将线性回归迁移到神经网络、SVM,或者你喜欢的其他模型。
定义超参数也不是那么困难:只需为这些参数创建一个交叉验证和网格搜索,以提高模型精度。部署一个模型可能会更为复杂,需要有一点点耐心和坚持、大量的教程和不断尝试与试错,您就可以上传一个每分钟可以处理数百万个请求的模型(或者您可以使用诸如marvin这样的工具,它将替你做大量的工作)。但究竟是什么让你突显出你的优势呢?最优秀的数据科学家需要掌握的关键技能又是什么?
简而言之:关键在于知道如何根据数据创建分析视图。
交易数据库-那些存储交易数据的数据库,如订单、付款、访问日志等-是为存储应用程序交易数据而定制的,对数据科学没有直接帮助。构建这些数据库的开发人员却不这么认为,也许不应该考虑如何使用这些数据进行分析。他们只是简单地创建了数据模型,以提高应用程序的性能。
尝试创建基于事务的机器学习模型是行不通的,除非你希望对某一项事务进行预测。数据科学家工作时通常需要基于数据分析。那么,究竟应该如何基于数据分析呢?它又如何区别于基于事务?
分析数据库究竟是什么?
分析数据库是为了某项特定的研究而设计的。基于客户流失的预测与基于购物车中的产品推荐不同。然而,两者的数据源可能是相同的:事务性数据库。客户流失预测必须对每个客户的行为数据进行分组,因此可以随着时间的推移观察客户的行为。至于产品推荐,数据必须按会话分组,以预测哪些项目与购物车关联。

能够创建分析数据库比精通多种算法更重要。
了解如何创建分析基础是数据科学家需要培养的最重要技能之一。同时,它也是课程、MOOC和教程中教得较少的课程之一。为了将事务性数据转换为可以分析的数据,必须真正了解你正在处理的业务。这一点,加上批判性思维,是正确界定问题的基础。
创建目标与分析数据一致性并不容易:它需要一个长期的调研过程,这往往会让您的经理失望。
数据科学家经常需要target来训练他/她的模型。如果看一看Kaggle,你会发现无数的比赛和数据集,其中的target已经定义,并可以在培训和评估中直接使用。但是,事务性数据库通常没有准备好的target。数据科学家必须明确客户何时需要放弃服务, 以便创建客户流失模型。并且需要定义什么是不良付款行为,即使难以预测到。创建目标和分析数据一致性并不是那么容易:它需要一个长期的调查过程,这通常会让您的经理失望(直到现在,他们都相信自己拥有所有的数据,他们所需要的只是一个数据科学家)。
事实上,数据科学远大于将数据输入模型并评估性能指标的即插即用过程。
数据探索
设想一种情况,在这种情况下,您有一个数据库,几个销售分析师根据行为概况对销售线索进行分类。为了对客户进行分类,分析师必须在谈判过程中判断销售线索的行为,然后为客户选择一个适当的描述并填写一张表格。我们这里有一些潜在的问题:
在同一谈判过程中,分析师对潜在客户的判断不一定与其他分析师的判断相同。不同的分析师可以对同一个潜在客户可能会进行不同的分类。
分析师真的了解每个行为特征代表什么吗?是否有明确的标准来将潜在客户分类为“描述X”而不是“描述Y”?
在收集期间,流程是否发生变化,如插入新的行为类别/描述?如果是这样的话,那么在定义目标时,你必须决定如何考虑它们。
如何收集数据?在与潜在客户的每次新接触中,行为模式是否都会改变,以便分析师真正选择最佳的模式?
管理者是否要求准确地对其分类?如果要求分析师回答的只是一个“无聊”的过程,那么很有可能有些分类是“因为他们必须”填写的。当行为模式总是以相同的顺序呈现给分析师时,这个问题变得更加明显:目标可能偏向于第一个选项。
在这个过程之后,您可能会得出这样的结论:到目前为止收集的数据是完全无用的,因为没有标准和过程。这肯定会让很多人失望(甚至你也可能会失望)。
为信用违约预测创建分析数据库(行为评分)
为了使创建分析数据库的过程更清晰,让我们看看正确定义问题和创建用于执行预测的分析数据库所需的一组过程的示例。

创建一个预测客户信用违约的模型涉及一系列业务和技术决策,这些决策必须由数据科学家做出。
假设你与金融服务部门合作,并且面临以下问题:
我们需要创建一个模型来识别哪些客户在不久的将来不会支付他们的发票。
为此,你需要创建描述客户付款的变量。然后有必要创建一个回归模型,能够区分好的和坏的付款人。最后,你需要计算客户好坏的概率。
1.定义目标是什么
在数据库中的任何地方都找不到一个类别变量,它指示某个客户是好的还是坏的付款人。首先,有必要定义什么是好客户或坏客户。为此,我们可以研究逾期付款。例如,你可能会发现平均延迟为20天,但75%的发票在到期日后17天内支付。
你可以通过逾期天数内的付款来设计累积分布。因此,你将能够核实,30天后,87%的发票已经支付。但6个月后,这个百分比将上升到90%。然后,我们可以使用贝叶斯推理来预测客户在逾期30天后支付发票的概率。
代码查看请点击链接:https://ai.yanxishe.com/page/TextTranslation/1405
我们可以得出的结论是,如果客户的付款已经延迟了30天,那么他/她将来偿还债务的可能性非常低(只有23%)。要决定什么是好的或坏的付款行为,需要对业务有深入的了解,因为你需要了解这种可能性是否足够低,以便将延迟30天以内的客户分类为好的付款方,而那些超过30天的客户则是坏的付款方。
2.创建观察和性能框架
我们感兴趣的是,利用过去一段时间内客户行为的数据,预测未来一段时间内客户违约的可能性。选择这些框架的大小是一个比统计更重要的业务/谈判决策,请记住,它们必须足够大,能够包含多个客户的行为观察结果。窗口太短会增加观察结果的方差,因此模型会失去精度。
定义:
根据客户过去12个月的行为,我想预测他/她在未来6个月内成为一个好付款人的可能性。
为了实现这一定义,你需要:
定义至少比当前日期早6个月的观察点。
定义一个观察框架,该框架在观察点之前12个月开始并在其中结束。
定义一个性能框架,该框架在观察点之后扩展6个月。
定义一个好的付款人是什么。我们刚才做的!
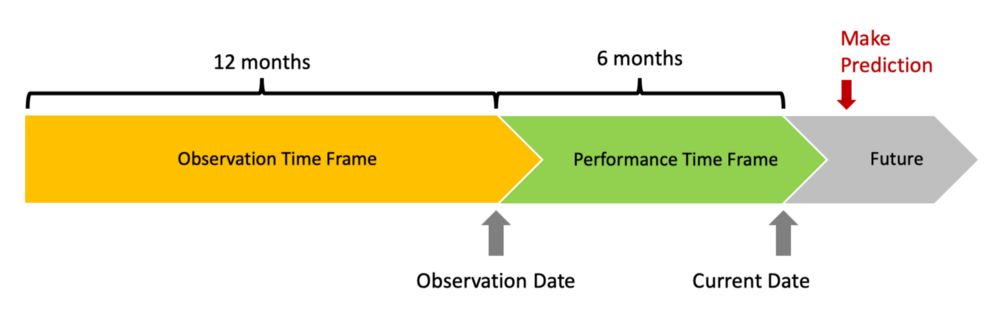
在创建分析数据库的过程中,时间框架问题是一个非常重要的步骤。
注意,这个定义带来了一些含义:
你需要至少18个月的数据
你的预测必然会有一个时间框架。每次运行模型时,它都会计算出未来6个月内的默认概率。
在分析数据库中创建特征时,观察点和时间范围的大小始终是您的参考。
3.创建目标功能
既然我们已经定义了什么是我们的目标,什么是观察和性能框架,我们就可以最终在数据库上创建目标了。为此,您将计算绩效时间范围内每个客户的最大逾期天数,并根据以下规则创建一个好的付款方变量:
if max(delay) >= 30 days then is bad = 0 If max(delay) < 30 days then is good = 1
因此,如果在履行期限内,客户的付款延迟超过30天,即使发票延迟付款,他/她也将被归类为不良。
我们输入0代表坏,1代表好,因为我们要定义分数越高,默认概率越低。
4.除外条款
现在我们需要对业务结构有广泛的了解,所以我们可以从我们的基地执行一些排除。实例:
排除观察点没有信用额度的所有客户
排除在观察点发票过期超过30天的所有客户,因为我们已经知道他们是坏人
排除所有从未进行过交易的客户
5.特色结构
对于本研究,必须按客户对基础进行分组。每个变量必须描述观察时间框架内客户的特定行为。以下是一些可处理变量的示例:
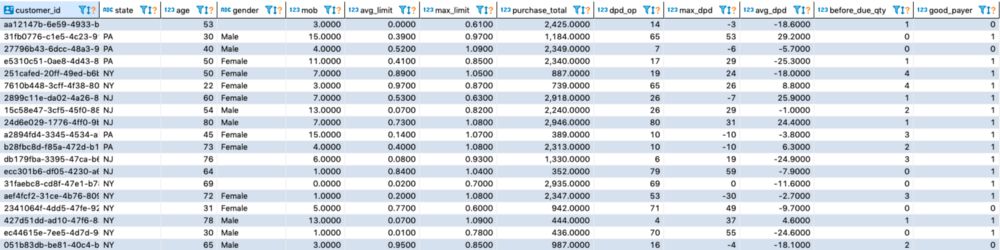
创建的分析数据库示例,用于提供预测客户违约的行为评分模型。
状态:个人信息功能-表示客户居住的省/州
年龄:个人信息功能-表示在观察点计算的客户年龄
性别:个人信息功能-表示客户的性别
MOB:客户签到到观察点后的月数
平均限额:观察12个月内限额使用的平均百分比
最大限值:观察12个月内最大限值使用百分比
采购总额:观察12个月内的采购总额
dpd_op:观察点过期天数
max_dpd:观察12个月内到期的最长天数。如果所有发票都提前支付,则可能为负数。
平均每日住院天数:观察12个月内到期的平均天数。如果所有发票都提前支付,则可能为负数。
到期前数量:观察12个月内到期前支付的发票数量。
好的付款人:target-表示客户在绩效窗口的6个月内,发票是否延迟超过30天。
6.表现的时间到了!
现在我们终于要讨论建立一个模型了!你现在可以应用你在数据科学课程中学到的所有知识。您的分析基础已经设计好,可以开始在这种情况下数据处理和应用模型的行动。
最简单的解决方案是使用上面创建的变量应用逻辑回归,以预测好的付款人目标。模型将为每个客户返回0和1之间的值,表明他/她是一个好付款人的概率。
务必正确解释结果:
分数将表明某个客户在未来6个月内不会延迟付款超过30天的可能性。
你喜欢吗?
这篇文章对你有用吗?分享!我说了什么蠢话吗?纠正我!想添加一些内容吗?请留言!
想要继续查看该篇文章相关链接和参考文献?
长按链接点击打开【杰出数据科学家的关键技能是什么?】:
https://ai.yanxishe.com/page/TextTranslation/1405
AI研习社每日更新精彩内容,观看更多精彩内容:雷锋网(公众号:雷锋网)雷锋网雷锋网
命名实体识别(NER)综述
杰出数据科学家的关键技能是什么?
初学者怎样使用Keras进行迁移学习
如果你想学数据科学,这 7 类资源千万不能错过
等你来译:
如何在神经NLP处理中引用语义结构
你睡着了吗?不如起来给你的睡眠分个类吧!
高级DQNs:利用深度强化学习玩吃豆人游戏
深度强化学习新趋势:谷歌如何把好奇心引入强化学习智能体
杰出数据科学家的关键技能是什么?相关推荐
- 数据分析中的统计概率_了解统计和概率:成为专家数据科学家
数据分析中的统计概率 Data Science is a hot topic nowadays. Organizations consider data scientists to be the Cr ...
- 什么是数据?数据科学家需要掌握哪些技能?终于有人讲明白了
导读:人们认为"数据"一词自16世纪伊始便已被定义和使用了.随着计算机技术的进步,数据一词变得越发流行.然而,数据不仅限于计算机科学和电子学领域,各个领域的应用在某种程度上使用并产 ...
- 【数据科学家】什么是数据科学家? 一个关键的数据分析角色和一个利润丰厚的职业...
数据科学家的角色因行业而异,但有一些共同的技能.经验.教育和培训可以帮助你在数据科学职业生涯中占据一席之地. 什么是数据科学家? 数据科学家是分析数据专家,他们使用数据科学从大量结构化和非结构化数据中 ...
- 成为数据科学家,需具备这些技能
目前数据科学和数据科学家成为了流行词汇.当有人问你干什么,你回答说数据科学家,对方会恍然大悟,觉得特别高大上,噢,数据科学家啊,听说过.是啊,没听说过数据科学家那就out了.如果接着问,数据科学家具体 ...
- 数据科学家最需要什么技能?
本文整理了多个求职网站的信息,对雇主最希望数据科学家具备的技能进行了分析,并提供了一些建议. 数据科学家需要涉猎很多--机器学习.计算机科学.统计学.数学.数据可视化.通信和深度学习.这些领域中有几十 ...
- 避坑指南:数据科学家新手常犯的13个错误(附工具、学习资源链接)
作者:Pranav Dar 翻译:和中华 校对:张玲 本文约6000字,建议阅读10+分钟. 本文是老司机给数据科学家新手的一些建议,希望每个致力于成为数据科学家的人少走弯路. 简介 你已经决定把数 ...
- 【2016年第3期】大数据时代的数据科学家培养
朱扬勇1,2,熊贇1,2 1.复旦大学计算机科学技术学院,上海 200433:2.上海市数据科学重点实验室,上海 200433 摘要:大数据时代,最热门的职业是数据科学家(data scienti ...
- 不学好数学也想当数据科学家?不存在的
大数据文摘作品 编译:文明 修竹 高宁 天培 数据科学家需不需要有扎实的数学基础呢? 随着越来越多优秀开源项目的涌现,各类数据科学工具都实现了"半自动化",数据分析的背后数学原理似 ...
- 7个秘诀,带你由数据分析师成长为数据科学家
全文共4047字,预计学习时长8分钟 通往数据科学之路 (Aleksandr Barsukov发布于 Unsplash) 数据科学的热浪席卷大多数行业,如<哈佛商业评论>所述,数据科学家已 ...
最新文章
- 如何获取元素在父级div里的位置_前端面试题--元素的BFC特性和实例
- python语言及其应用-Python语言及其应用.PDF
- antd upload手动上传_Flask上传文件
- 关于向MySQL插入一条新纪录的问题
- 如何让nginx执行python代码_生产环境部署Python语言代码(django+uwsgi+nginx)
- kafka 分区分配及再平衡总结
- 移动开发不能不知道的事-meta
- visual studio安装dlib
- linux cron 定时任务
- 两WinForm和两WebForm传值
- OpenCV2中矩阵的归一化 normalize函数详解
- vue移动端小说阅读器vue全家桶项目,已部署到服务器可访问预览
- 二年级上册计算题_小学二年级上册应用题500道
- 图片文字怎么合并转发_微信怎么转发别人的图片带文字
- 朋友在B站魔力赏抽到的动漫周边,把我看馋了
- 大数据正当时,理解这几个术语很重要
- 安卓webview长按分享,长按选择,长按复制,仿好奇心日报长按分享自定义弹窗的实现
- Ansible中的常用模块介绍
- 学python的有哪些好书_学习python有哪些好书和学习方法?
- iWatch 开发 4: 实现iWatch 与 iPhone 之间数据发送与接收
热门文章
- Spring Boot2.x-11 使用@ControllerAdvice和@ExceptionHandler实现自定义全局异常
- Spring-依赖注入
- 三角窗 matlab,【matlab】矩形窗/三角窗/hanning窗/hamming窗/blackman窗的頻率響應圖
- 支持服务器CPU的ITX主板,Mini-ITX主板能装28核处理器,华擎推出EPC621D4I-2M主板
- 递归 累加和累乘
- 2020-12-08 Halcon初学者知识:【3-1】Halcon的语法
- 延长计算机屏幕显示时间,非充电状态下延长计算机使用时间的小诀窍!
- php foreach next,foreach next 操作数组指针移动问题,多个数连加,连除,连减,连乘php版本...
- 大型网站 linux,大型网站架构演变
- vs debug 模式生成的exe 另一台电脑_神秘的 _DEBUG 宏从何处来?