增强学习(五)----- 时间差分学习(Q learning, Sarsa learning)
接下来我们回顾一下动态规划算法(DP)和蒙特卡罗方法(MC)的特点,对于动态规划算法有如下特性:
- 需要环境模型,即状态转移概率PsaPsa
- 状态值函数的估计是自举的(bootstrapping),即当前状态值函数的更新依赖于已知的其他状态值函数。
相对的,蒙特卡罗方法的特点则有:
- 可以从经验中学习不需要环境模型
- 状态值函数的估计是相互独立的
- 只能用于episode tasks
而我们希望的算法是这样的:
- 不需要环境模型
- 它不局限于episode task,可以用于连续的任务
本文介绍的时间差分学习(Temporal-Difference learning, TD learning)正是具备了上述特性的算法,它结合了DP和MC,并兼具两种算法的优点。
TD Learing思想
在介绍TD learning之前,我们先引入如下简单的蒙特卡罗算法,我们称为constant-αα MC,它的状态值函数更新公式如下:
V(st)←V(st)+α[Rt−V(st)](1)(1)V(st)←V(st)+α[Rt−V(st)]
其中RtRt是每个episode结束后获得的实际累积回报,αα是学习率,这个式子的直观的理解就是用实际累积回报RtRt作为状态值函数V(st)V(st)的估计值。具体做法是对每个episode,考察实验中stst的实际累积回报RtRt和当前估计V(st)V(st)的偏差值,并用该偏差值乘以学习率来更新得到V(St)V(St)的新估值。
现在我们将公式修改如下,把RtRt换成rt+1+γV(st+1)rt+1+γV(st+1),就得到了TD(0)的状态值函数更新公式:
V(st)←V(st)+α[rt+1+γV(st+1)−V(st)](2)(2)V(st)←V(st)+α[rt+1+γV(st+1)−V(st)]
为什么修改成这种形式呢,我们回忆一下状态值函数的定义:
Vπ(s)=Eπ[r(s′|s,a)+γVπ(s′)](3)(3)Vπ(s)=Eπ[r(s′|s,a)+γVπ(s′)]
容易发现这其实是根据(3)的形式,利用真实的立即回报rt+1rt+1和下个状态的值函数V(st+1)V(st+1)来更新V(st)V(st),这种就方式就称为时间差分(temporal difference)。由于我们没有状态转移概率,所以要利用多次实验来得到期望状态值函数估值。类似MC方法,在足够多的实验后,状态值函数的估计是能够收敛于真实值的。
那么MC和TD(0)的更新公式的有何不同呢?我们举个例子,假设有以下8个episode, 其中A-0表示经过状态A后获得了回报0:
| index | samples |
|---|---|
| episode 1 | A-0, B-0 |
| episode 2 | B-1 |
| episode 3 | B-1 |
| episode 4 | B-1 |
| episode 5 | B-1 |
| episode 6 | B-1 |
| episode 7 | B-1 |
| episode 8 | B-0 |
首先我们使用constant-αα MC方法估计状态A的值函数,其结果是V(A)=0V(A)=0,这是因为状态A只在episode 1出现了一次,且其累计回报为0。
现在我们使用TD(0)的更新公式,简单起见取λ=1λ=1,我们可以得到V(A)=0.75V(A)=0.75。这个结果是如何计算的呢? 首先,状态B的值函数是容易求得的,B作为终止状态,获得回报1的概率是75%,因此V(B)=0.75V(B)=0.75。接着从数据中我们可以得到状态A转移到状态B的概率是100%并且获得的回报为0。根据公式(2)可以得到V(A)←V(A)+α[0+λV(B)−V(A)]V(A)←V(A)+α[0+λV(B)−V(A)],可见在只有V(A)=λV(B)=0.75V(A)=λV(B)=0.75的时候,式(2)收敛。对这个例子,可以作图表示:
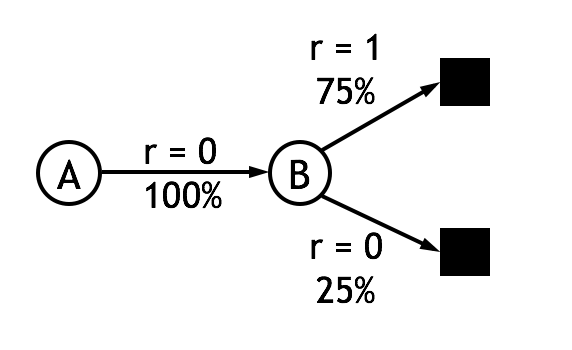
可见式(2)由于能够利用其它状态的估计值,其得到的结果更加合理,并且由于不需要等到任务结束就能更新估值,也就不再局限于episode task了。此外,实验表明TD(0)从收敛速度上也显著优于MC方法。
将式(2)作为状态值函数的估计公式后,前面文章中介绍的策略估计算法就变成了如下形式,这个算法称为TD prediction:
输入:待估计的策略ππ
任意初始化所有V(s)V(s),(e.g.,V(s)=0,∀s∈s+e.g.,V(s)=0,∀s∈s+)
Repeat(对所有episode):
初始化状态 ss
Repeat(对每步状态转移):
a←a←策略ππ下状态ss采取的动作
采取动作aa,观察回报rr,和下一个状态s′s′
V(s)←V(s)+α[r+λV(s′)−V(s)]V(s)←V(s)+α[r+λV(s′)−V(s)]
s←s′s←s′
Until stst is terminal
Until 所有V(s)V(s)收敛
输出Vπ(s)Vπ(s)
Sarsa算法
现在我们利用TD prediction组成新的强化学习算法,用到决策/控制问题中。在这里,强化学习算法可以分为在策略(on-policy)和离策略(off-policy)两类。首先要介绍的sarsa算法属于on-policy算法。
与前面DP方法稍微有些区别的是,sarsa算法估计的是动作值函数(Q函数)而非状态值函数。也就是说,我们估计的是策略ππ下,任意状态ss上所有可执行的动作a的动作值函数Qπ(s,a)Qπ(s,a),Q函数同样可以利用TD Prediction算法估计。如下就是一个状态-动作对序列的片段及相应的回报值。
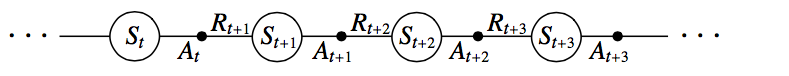
给出sarsa的动作值函数更新公式如下:
Q(st,at)←Q(st,at)+α[rt+1+λQ(st+1,at+1)−Q(st,at)](4)(4)Q(st,at)←Q(st,at)+α[rt+1+λQ(st+1,at+1)−Q(st,at)]
可见式(4)与式(2)的形式基本一致。需要注意的是,对于每个非终止的状态stst,在到达下个状态st+1st+1后,都可以利用上述公式更新Q(st,At)Q(st,At),而如果stst是终止状态,则要令Q(st+1=0,at+1)Q(st+1=0,at+1)。由于动作值函数的每次更新都与(st,at,rt+1,st+1,at+1)(st,at,rt+1,st+1,at+1)相关,因此算法被命名为sarsa算法。sarsa算法的完整流程图如下:

算法最终得到所有状态-动作对的Q函数,并根据Q函数输出最优策略ππ
Q-learning
在sarsa算法中,选择动作时遵循的策略和更新动作值函数时遵循的策略是相同的,即ϵ−greedyϵ−greedy的策略,而在接下来介绍的Q-learning中,动作值函数更新则不同于选取动作时遵循的策略,这种方式称为离策略(Off-Policy)。Q-learning的动作值函数更新公式如下:
Q(st,at)←Q(st,at)+α[rt+1+λmaxaQ(st+1,a)−Q(st,at)](5)(5)Q(st,at)←Q(st,at)+α[rt+1+λmaxaQ(st+1,a)−Q(st,at)]
可以看到,Q-learning与sarsa算法最大的不同在于更新Q值的时候,直接使用了最大的Q(st+1,a)Q(st+1,a)值——相当于采用了Q(st+1,a)Q(st+1,a)值最大的动作,并且与当前执行的策略,即选取动作atat时采用的策略无关。 Off-Policy方式简化了证明算法分析和收敛性证明的难度,使得它的收敛性很早就得到了证明。Q-learning的完整流程图如下:

小结
本篇介绍了TD方法思想和TD(0),Q(0),Sarsa(0)算法。TD方法结合了蒙特卡罗方法和动态规划的优点,能够应用于无模型、持续进行的任务,并拥有优秀的性能,因而得到了很好的发展,其中Q-learning更是成为了强化学习中应用最广泛的方法。在下一篇中,我们将引入资格迹(Eligibility Traces)提高算法性能,结合Eligibility Traces后,我们可以得到Q(λ),Sarsa(λ)Q(λ),Sarsa(λ)等算法
增强学习(五)----- 时间差分学习(Q learning, Sarsa learning)相关推荐
- 一种通用的卡尔曼滤波不动点近似和有效的时间差分学习
A Generalized Kalman Filter for Fixed Point Approximation and Efficient Temporal–Difference Learning ...
- 人工智障学习笔记——强化学习(4)时间差分方法
前两章我们学习了动态规划DP方法和蒙特卡洛MC方法,DP方法的特性是状态转移,状态值函数的估计是自举的(bootstrapping),即当前状态值函数的更新依赖于已知的其他状态值函数.MC方法的特性是 ...
- 单片机入门学习五 STM32单片机学习二 跑马灯程序衍生出的stm32编程基础
上篇文章 单片机入门学习四 STM32单片机学习一 跑马灯程序和创建工程 仅介绍了入门程序及其编译运行过程,下面开始对stm32的一些基础知识做一个记录. 1.stm32f103zet6(上篇问题3 ...
- javaMail学习(五)——使用javaMail给Q Q 邮 箱 账 户 发简单邮件
代码跟网 易 邮 箱的那篇差不多,除了smtp服务器地址不同之外,还需要添加"开 启 S S L 加 密 "的代码. package com.wjl.mail.utils;impo ...
- pytorch学习五、深度学习计算
来自于 https://tangshusen.me/Dive-into-DL-PyTorch/#/ 官方文档 https://pytorch.org/docs/stable/tensors.html ...
- SQL语言学习(五)流程控制函数学习
1. if()函数 SELECT IF(10<5,"正确","错误"); IFNULL(value1, value2) 如果value1不为空,返回val ...
- 强化学习应用简述---强化学习方向优秀科学家李玉喜博士创作
强化学习 (reinforcement learning) 经过了几十年的研发,在一直稳定发展,最近取得了很多傲人的成果,后面会有越来越好的进展.强化学习广泛应用于科学.工程.艺术等领域. 下面简单列 ...
- 蓝桥杯嵌入式CT117E-M4学习笔记02-STM32G431RBT6芯片学习
文章目录 前言 一.芯片简介 二.时钟学习 三.SRAM学习 四.总线矩阵学习 五.GPIO学习 总结 前言 首先学习了解一下蓝桥杯嵌入式CT117E-M4开发板的主控芯片STM32G431RBT6, ...
- 强化学习(五) - 时序差分学习(Temporal-Difference Learning)及其实例----Sarsa算法, Q学习, 期望Sarsa算法
强化学习(五) - 时序差分学习(Temporal-Difference Learning)及其实例 5.1 TD预测 例5.1 回家时间的估计 5.2 TD预测方法的优势 例5.2 随机移动 5.3 ...
最新文章
- 字符串与base64相互转换
- 第二章 基础查询 2-2 算术运算符和比较运算符
- 2、Get和post的区别
- java POI导出多张图片到表格(占位符方式)
- Android系统中的进程管理:内存的回收
- Fragment结合nineold包实现滑动tab页
- Linux I2C核心、总线与设备驱动
- 骑手送外卖获奖1500多万后又遭撤销,网友:人生大起大落不过如此
- 寻找关键之年的榜样和标准
- Windows XP终极优化设置(精心整理)
- vagaa搜索服务器没响应,Vagaa(哇嘎)搜索不到资源怎么办?
- vue 实现倒计时功能
- 在Window10子系统Ubantu创建conda环境
- Linux操作系统学习笔记【入门必备】
- HP-UX Samba服务配置手册
- python3d_Power BI将超越python和D3,成为数据可视化的福音、定性数据分析的未来?...
- 【第45期】《你好,安怡》热播,AI觉醒,奇点临近?
- 声网自研传输层协议 AUT 的落地实践丨Dev for Dev 专栏
- 超级强大的五个资源网站 想要的资源都有
- js下拉列表添加监听事件(支持所有主流浏览器)
热门文章
- centos nfs端口固定
- Documentum常见问题2—压力测试时一旦用户数超过一定数量就不能登录了
- IDEA一直卡在Resolving Maven dependency的解决办法
- c语言原始,[蓝桥杯][历届试题]回文数字 最原始的方法(C语言代码)
- hubuild 打包ios_iOS 通过HBuilder进行云端打包ipa文件
- 计算机没有autoCAD_挑战在一年内用晚上业余时间学会灵活运用CAD(1)|cad|autocad|图学|计算机|电子电路...
- 会员直推奖php程序_PHP自适应卡益源码 前台直销源码 报单费 直推奖 有内部商城...
- python监听udp端口_python检测远程udp端口是否打开
- iOS开发能用mysql吗_iOS开发之数据库的简单使用
- 资源共享冲突问题概述