彻底搞懂Scrapy的中间件(三)
在前面两篇文章介绍了下载器中间件的使用,这篇文章将会介绍爬虫中间件(Spider Middleware)的使用。
爬虫中间件
爬虫中间件的用法与下载器中间件非常相似,只是它们的作用对象不同。下载器中间件的作用对象是请求request和返回response;爬虫中间件的作用对象是爬虫,更具体地来说,就是写在spiders文件夹下面的各个文件。它们的关系,在Scrapy的数据流图上可以很好地区分开来,如下图所示。
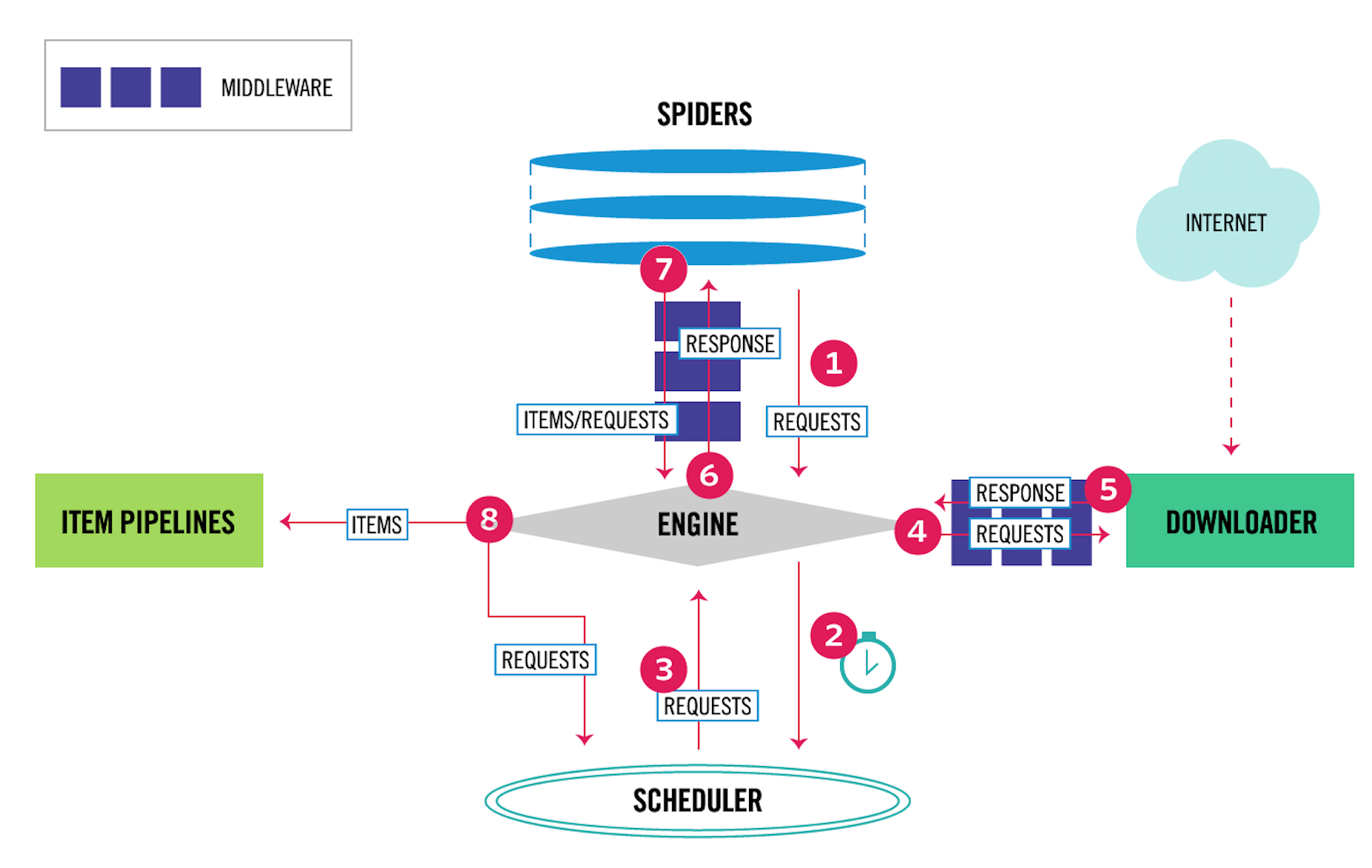
其中,4、5表示下载器中间件,6、7表示爬虫中间件。爬虫中间件会在以下几种情况被调用。
- 当运行到
yield scrapy.Request()或者yield item的时候,爬虫中间件的process_spider_output()方法被调用。 - 当爬虫本身的代码出现了
Exception的时候,爬虫中间件的process_spider_exception()方法被调用。 - 当爬虫里面的某一个回调函数
parse_xxx()被调用之前,爬虫中间件的process_spider_input()方法被调用。 - 当运行到
start_requests()的时候,爬虫中间件的process_start_requests()方法被调用。
在中间件处理爬虫本身的异常
在爬虫中间件里面可以处理爬虫本身的异常。例如编写一个爬虫,爬取UA练习页面http://exercise.kingname.info/exercise_middleware_ua ,故意在爬虫中制造一个异常,如图12-26所示。
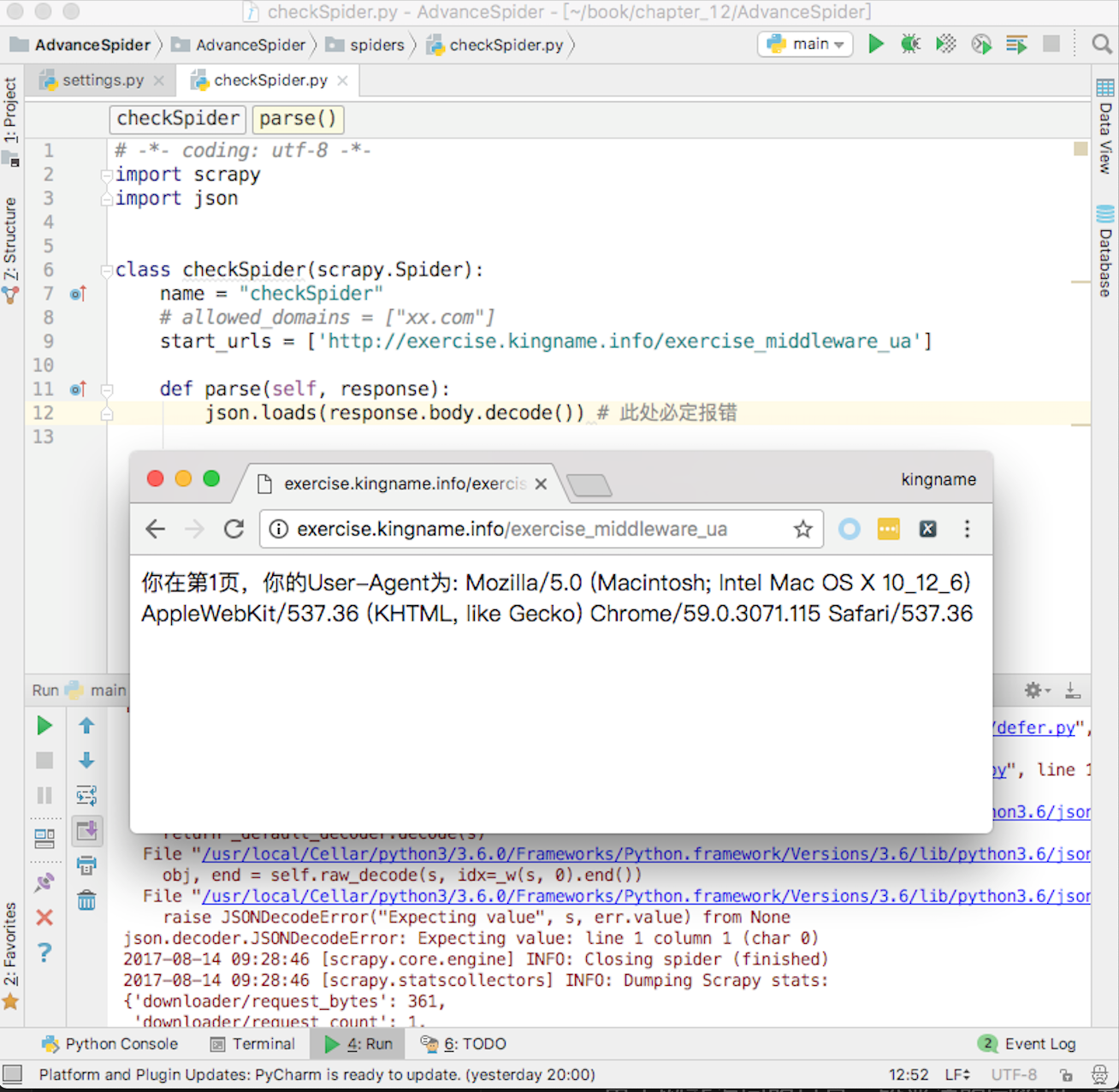
由于网站返回的只是一段普通的字符串,并不是JSON格式的字符串,因此使用JSON去解析,就一定会导致报错。这种报错和下载器中间件里面遇到的报错不一样。下载器中间件里面的报错一般是由于外部原因引起的,和代码层面无关。而现在的这种报错是由于代码本身的问题导致的,是代码写得不够周全引起的。
为了解决这个问题,除了仔细检查代码、考虑各种情况外,还可以通过开发爬虫中间件来跳过或者处理这种报错。在middlewares.py中编写一个类:
class ExceptionCheckSpider(object):def process_spider_exception(self, response, exception, spider):print(f'返回的内容是:{response.body.decode()}\n报错原因:{type(exception)}')return None这个类仅仅起到记录Log的作用。在使用JSON解析网站返回内容出错的时候,将网站返回的内容打印出来。
process_spider_exception()这个方法,它可以返回None,也可以运行yield item语句或者像爬虫的代码一样,使用yield scrapy.Request()发起新的请求。如果运行了yield item或者yield scrapy.Request(),程序就会绕过爬虫里面原有的代码。
例如,对于有异常的请求,不需要进行重试,但是需要记录是哪一个请求出现了异常,此时就可以在爬虫中间件里面检测异常,然后生成一个只包含标记的item。还是以抓取http://exercise.kingname.info/exercise_middleware_retry.html这个练习页的内容为例,但是这一次不进行重试,只记录哪一页出现了问题。先看爬虫的代码,这一次在meta中把页数带上,如下图所示。

爬虫里面如果发现了参数错误,就使用raise这个关键字人工抛出一个自定义的异常。在实际爬虫开发中,读者也可以在某些地方故意不使用try ... except捕获异常,而是让异常直接抛出。例如XPath匹配处理的结果,直接读里面的值,不用先判断列表是否为空。这样如果列表为空,就会被抛出一个IndexError,于是就能让爬虫的流程进入到爬虫中间件的process_spider_exception()中。
在items.py里面创建了一个ErrorItem来记录哪一页出现了问题,如下图所示。
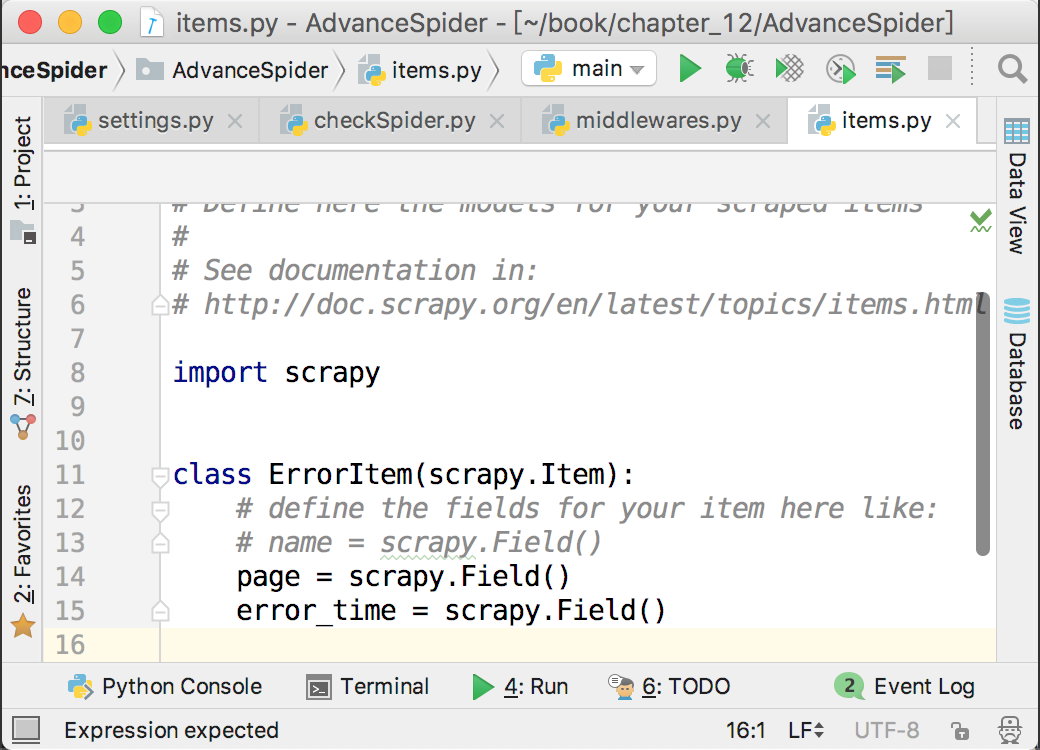
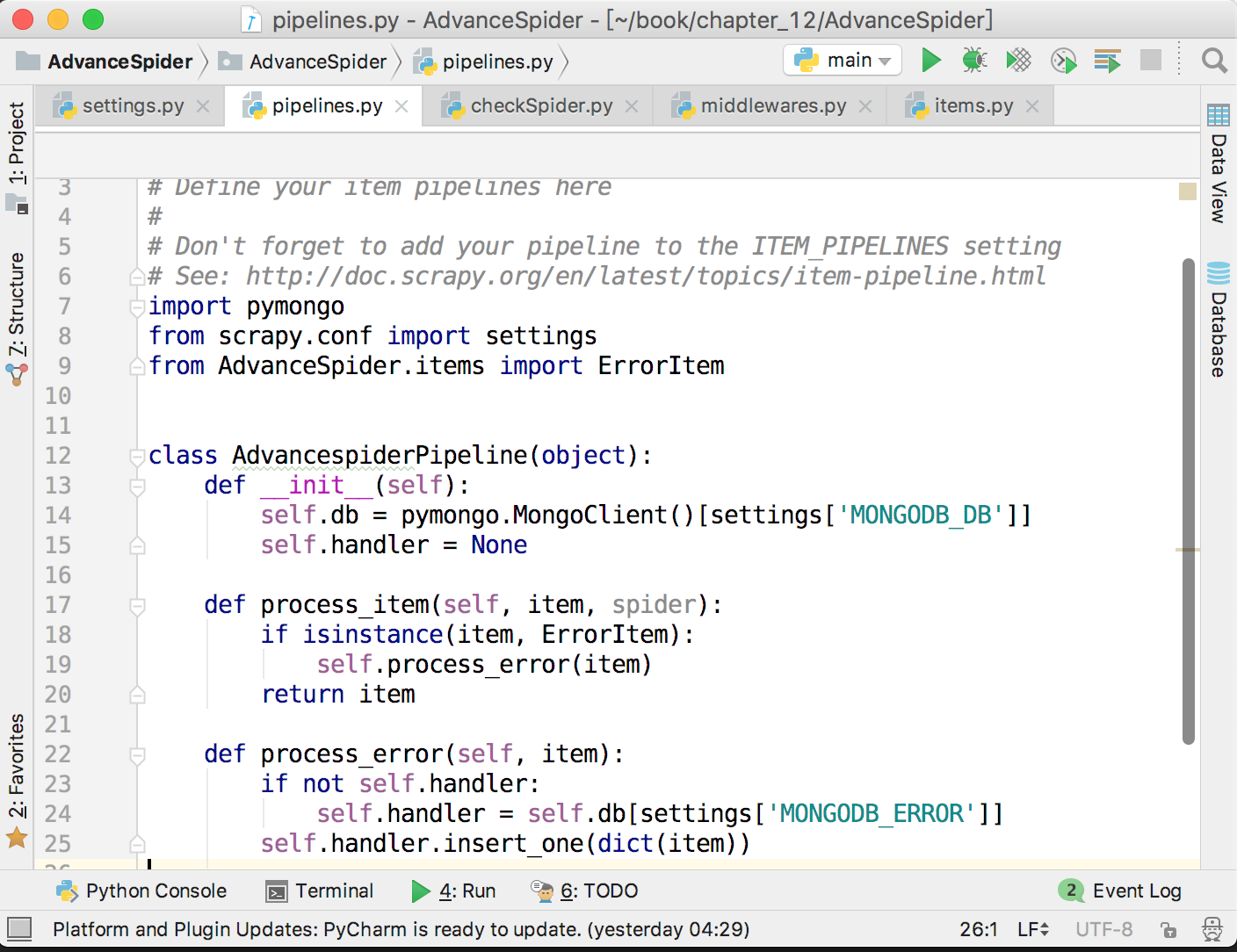
接下来,在爬虫中间件中将出错的页面和当前时间存放到ErrorItem里面,并提交给pipeline,保存到MongoDB中,如下图所示。
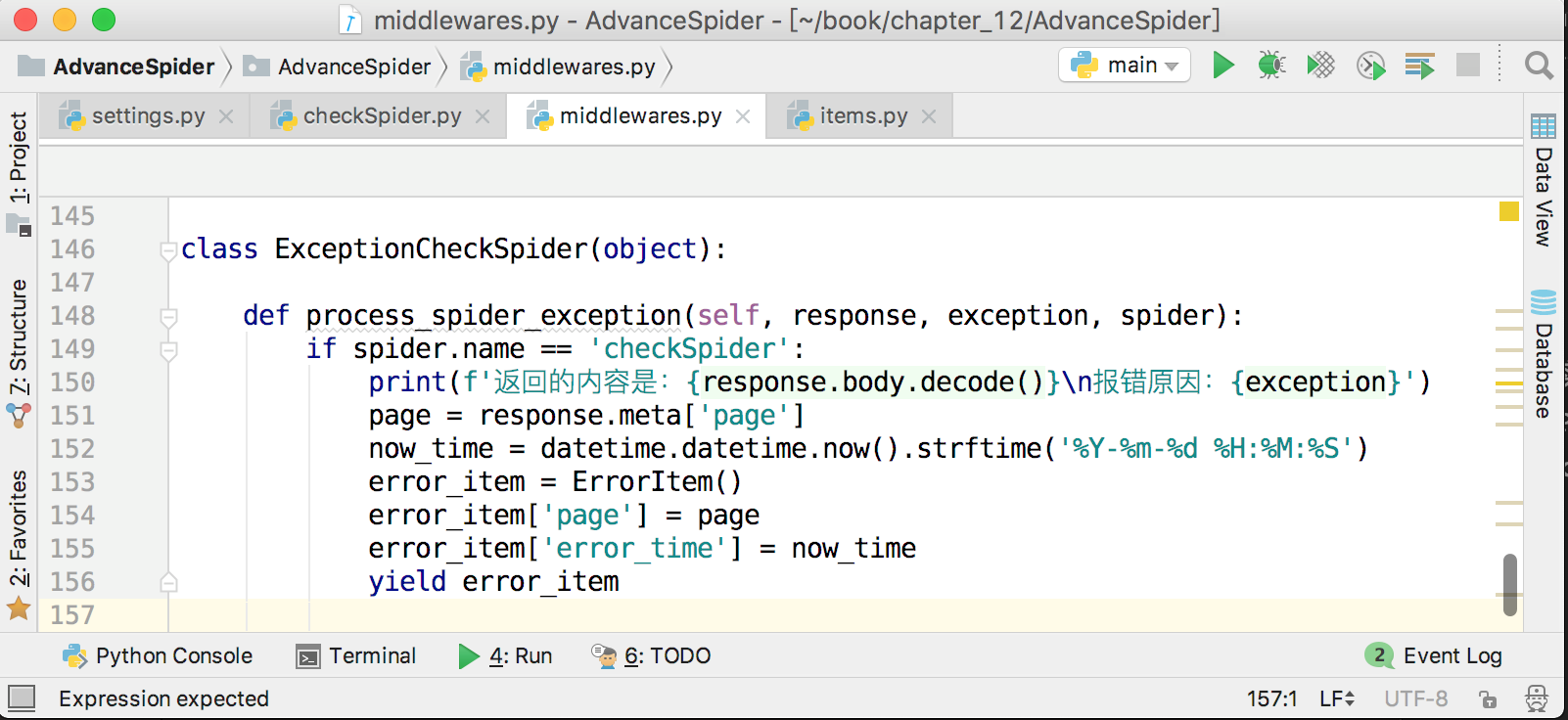
这样就实现了记录错误页数的功能,方便在后面对错误原因进行分析。由于这里会把item提交给pipeline,所以不要忘记在settings.py里面打开pipeline,并配置好MongoDB。储存错误页数到MongoDB的代码如下图所示。
激活爬虫中间件
爬虫中间件的激活方式与下载器中间件非常相似,在settings.py中,在下载器中间件配置项的上面就是爬虫中间件的配置项,它默认也是被注释了的,解除注释,并把自定义的爬虫中间件添加进去即可,如下图所示。
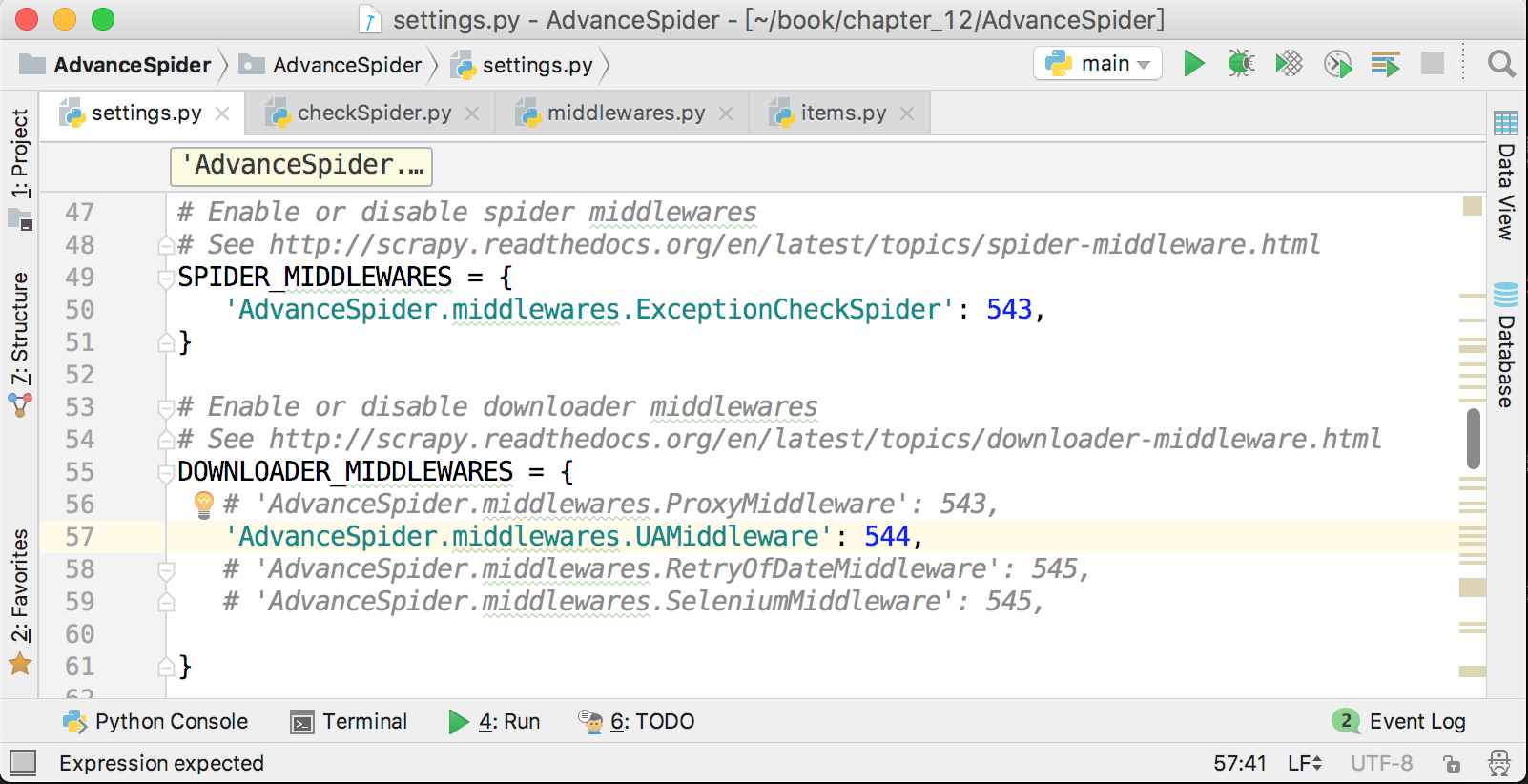
Scrapy也有几个自带的爬虫中间件,它们的名字和顺序如下图所示。

下载器中间件的数字越小越接近Scrapy引擎,数字越大越接近爬虫。如果不能确定自己的自定义中间件应该靠近哪个方向,那么就在500~700之间选择最为妥当。
爬虫中间件输入/输出
在爬虫中间件里面还有两个不太常用的方法,分别为process_spider_input(response, spider)和process_spider_output(response, result, spider)。其中,process_spider_input(response, spider)在下载器中间件处理完成后,马上要进入某个回调函数parse_xxx()前调用。process_spider_output(response, result, output)是在爬虫运行yield item或者yield scrapy.Request()的时候调用。在这个方法处理完成以后,数据如果是item,就会被交给pipeline;如果是请求,就会被交给调度器,然后下载器中间件才会开始运行。所以在这个方法里面可以进一步对item或者请求做一些修改。这个方法的参数result就是爬虫爬出来的item或者scrapy.Request()。由于yield得到的是一个生成器,生成器是可以迭代的,所以result也是可以迭代的,可以使用for循环来把它展开。
def process_spider_output(response, result, spider):for item in result:if isinstance(item, scrapy.Item):# 这里可以对即将被提交给pipeline的item进行各种操作print(f'item将会被提交给pipeline')yield item或者对请求进行监控和修改:
def process_spider_output(response, result, spider):for request in result:if not isinstance(request, scrapy.Item):# 这里可以对请求进行各种修改print('现在还可以对请求对象进行修改。。。。')request.meta['request_start_time'] = time.time()yield request本文节选自我的新书《Python爬虫开发 从入门到实战》完整目录可以在京东查询到 https://item.jd.com/12436581.html
转载于:https://www.cnblogs.com/xieqiankun/p/know_middleware_of_scrapy_3.html
彻底搞懂Scrapy的中间件(三)相关推荐
- 彻底搞懂 Scrapy 的中间件
彻底搞懂Scrapy的中间件(一):https://www.cnblogs.com/xieqiankun/p/know_middleware_of_scrapy_1.html 彻底搞懂Scrapy的中 ...
- 彻底搞懂Scrapy的中间件(一)
中间件是Scrapy里面的一个核心概念.使用中间件可以在爬虫的请求发起之前或者请求返回之后对数据进行定制化修改,从而开发出适应不同情况的爬虫. "中间件"这个中文名字和前面章节讲到 ...
- 彻底搞懂Scrapy的中间件(二)
在上一篇文章中介绍了下载器中间件的一些简单应用,现在再来通过案例说说如何使用下载器中间件集成Selenium.重试和处理请求异常. 在中间件中集成Selenium 对于一些很麻烦的异步加载页面,手动寻 ...
- 带你一文搞懂VMware Workstation的三种网络模式
前言: 其实VMware Workstation的三种网络模式我学的不止一遍,但每次学习自己理解的都是朦胧的概念,说自己学会了吧,一些实质性的概念转头就忘记,一点也想不起来.说自己不会吧,但是每次学习 ...
- javase开发工具包中的什么命令负责运行应用程序_想当程序员?先搞懂JavaSE、JavaEE和JavaME之间的区别吧!...
Java是一门比较灵活的编程语言,且目前行业90%的应用软件服务器端都采用Java语言进行开发,而Java编程的相关技术人才始终是各领域技术型岗位不可或缺的. 作为0基础或者想转行当程序员最好还是先搞 ...
- 一文彻底搞懂Mybatis系列(十六)之MyBatis集成EhCache
MyBatis集成EhCache 一.MyBatis集成EhCache 1.引入mybatis整合ehcache的依赖 2.类根路径下新建ehcache.xml,并配置 3.POJO类 Clazz 4 ...
- 从无到有,彻底搞懂MOSFET讲解
文章来源: 从无到有,彻底搞懂MOSFET讲解(十一) 从无到有,彻底搞懂MOSFET讲解(十) 从无到有,彻底搞懂MOSFET讲解(九) 从无到有,彻底搞懂MOSFET讲解(八) 从无到有,彻底搞懂 ...
- 彻底搞懂---三握四挥
目录 三握手 四挥手 三握手 正所谓,工欲善其事,必先利其器. 我们要想搞懂三次握手必须得先知道一些基础的东西. 我们先分析一下上图的英文都是啥东西. SYN: 代表连接请求/连接接受 ACK: 确认 ...
- 别再说不了解非接触液位传感器了?只需三分钟就能搞懂
非接触式液位传感器,顾名思义就是不用接触物体就能进行监测,从而避免遭到被监测物体的腐蚀等.那关于非接触式液位传感器,大家了解多少呢?今天TCOOP就来给大家详细介绍下,三分钟就能搞懂,快来看看吧! 一 ...
- 神了!!看完这篇文章我不仅学会了手撸vue三开关组件,还搞懂了父子组件传值
神了!!看完这篇文章我不仅学会了手撸vue三开关组件,还搞懂了父子组件传值 引子 前置知识 什么是vue组件 父子组件传值 父传子 子传父 model选项的引入 三开关组件(three-switch) ...
最新文章
- Exception loading sessions from persistent storage
- Servlet和SpringMVC补课
- 漫画:什么是 “代理模式” ?
- python基础教程攻略-python基础教程(一)
- 高动态范围图像-单图
- 5个让你充满健身动力的方法
- Virtools 3D行为编程系列(一)
- 自定义LinkedList
- 偷窃转基因玉米种子引发中美打农业官司
- html2image乱码问题,HtmlImageGenerator字体乱码问题解决、html2image放linux上乱码问题解决...
- php博客文章修改,wordpress博客如何快速修改文章阅读数
- 请听一个故事------gt;百度员工离职总结:如何做个好员工
- easyui结合java,Spring+SpringMVC+MyBatis+easyUI整合基础篇(二)牛刀小试
- 第 16 章 垃圾回收相关概念
- 深度学习花书-3.8 期望、方差与协方差
- PHP导出数据库数据字典脚本
- 点阵字模生成原理与方法
- python海龟交易源码_海龟交易系统的Python完全版 | RiceQuant米筐量化社区 交易策略论坛...
- [人工智能-综述-10]:模型评估 - 常见的模型评估指标与方法大全、汇总
- 2-AltiumDesigner原理图设计