ansys电力变压器模型_最佳变压器模型的超参数优化
ansys电力变压器模型
The goal of any Deep Learning model is to take in an input and generate the correct output. The nature of these inputs and outputs, which can vary wildly from application to application, depends on the specific job that the model should perform. For example, a dog breed classification model might take images as its input and generate the name of the dog breed (or a numeric label corresponding to the breed) as the output. Another model might accept a text description of a dog as its input and generate the name of the dog breed as its output. The first model is an example of a computer vision model, whereas the latter is an example of a natural language processing (NLP) model.
任何深度学习模型的目标都是接受输入并生成正确的输出。 这些输入和输出的性质(可能因应用程序而异)取决于模型应执行的特定工作。 例如,犬种分类模型可能将图像作为其输入,并生成犬种的名称(或与该犬种相对应的数字标签)作为输出。 另一个模型可能接受狗的文字描述作为其输入,并生成狗的品种名称作为其输出 。 第一个模型是计算机视觉模型的示例,而第二个模型是自然语言处理(NLP)模型的示例。
参数与超参数 (Parameters Vs Hyperparameters)
The internals of both models will consist of many fancy parts (convolutional layers, attention mechanisms, etc.), each tailored for their specific task. From a high-level perspective, all of these components constitute a set of parameters (or weights) which determine what the output will be for any given input. Training a deep learning model is the process of finding the set of values for these parameters which yield the best results on the given task.
这两个模型的内部将由许多精美的部分(卷积层,注意力机制等)组成,每个部分都针对其特定任务进行了量身定制。 从高级的角度来看,所有这些组件都构成一组参数 (或权重 ),这些参数确定任何给定输入的输出是什么。 训练深度学习模型是为这些参数找到一组值的过程,这些值在给定任务上产生最佳结果。
By contrast, hyperparameters are the factors which control the training process itself. The learning rate, the number of training epochs/iterations, and the batch size are some examples of common hyperparameters. The values chosen for the hyperparameters has a significant impact on the learned parameters, and by extension, the performance of the model.
相比之下, 超参数是 控制训练过程本身的因素。 学习率 , 训练时期/迭代次数和批量大小是常见超参数的一些示例。 为超参数选择的值对学习的参数以及模型的性能有很大的影响。
In a nutshell, the parameters are what the model learns, and the hyperparameters determine how well (or how badly) the model learns.
简而言之, 参数是模型学习的内容,而超参数则确定模型学习的好坏程度。
超参数优化 (Hyperparameter Optimization)
Just like we have various techniques to train model parameters, we also have methods to find the best hyperparameter values. The process of finding the best hyperparameter values, which enables the model to discover the best set of parameters to perform a given task, is hyperparameter optimization.
就像我们有各种训练模型参数的技术一样,我们也有找到最佳超参数值的方法。 查找最佳超参数值的过程(使模型能够发现执行给定任务的最佳参数集)是超参数优化 。
As a loose analogy, think about overclocking a CPU. By optimizing things like voltages, temperatures, clock frequencies, etc. (the hyperparameters), you can get the CPU to perform at higher speeds despite not changing the CPU architecture (the model), or the components of the CPU (the parameters of the model).
作为一个宽松的类比,考虑对CPU超频。 通过优化电压,温度,时钟频率等(超参数) ,即使不更改CPU架构(模型)或CPU组件(CPU 的参数 ) ,也可以使CPU以更高的速度执行。 型号) 。
Knowing what hyperparameters optimization is, you might wonder whether it is needed whenever you train a model. After all, many of us don’t bother with overclocking our CPUs considering they typically perform well out-of-the-box. Just like with modern-day CPUs, state-of-the-art deep learning models can generally perform well even without hyperparameter optimization. As long as you stick to sensible defaults, the power of SOTA pre-trained models combined with transfer learning is sufficient to produce a model with satisfactory performance.
了解什么是超参数优化,您可能想知道每当训练模型时是否需要它。 毕竟,考虑到它们通常开箱即用的性能,我们很多人都不必为CPU超频而烦恼。 就像现代CPU一样,即使没有超参数优化,最新的深度学习模型也可以正常运行。 只要您坚持合理的默认设置 ,SOTA预训练模型与转移学习相结合的功能就足以产生性能令人满意的模型。
But, when you don’t consider “good enough” to be good enough, hyperparameter optimization is a vital tool in your toolbox to help your model go the extra mile.
但是,当您认为“不够好”不够好时,超参数优化是工具箱中至关重要的工具,可帮助您的模型发挥更大作用。
使用简单变压器的超参数优化 (Hyperparameter Optimization with Simple Transformers)
Simple Transformers is a library designed to make the training and usage of Transformer models as easy as possible. In keeping with this idea, it has native support for hyperparameter optimization through the W&B Sweeps feature.
Simple Transformers是一个旨在使Transformer模型的培训和使用尽可能简单的库。 与这个想法保持一致,它通过W&B Sweeps功能为超参数优化提供了本机支持。
Simple Transformers is built upon the incredible Transformers library by Hugging Face whose contribution to making NLP accessible to everyone cannot be overstated!
Simple Transformers是Hugging Face在不可思议的Transformers库的基础上构建的,它对使每个人都可以使用NLP的贡献不可夸大!
This article will focus on using the Simple Transformers library, along with W&B Sweeps, to perform hyperparameter optimization on the Recognizing Textual Entailment [1] task of the SuperGLUE [2] benchmark. The task is a binary classification on a sentence pair as described below.
本文将重点介绍如何使用Simple Transformers库以及W&B Sweeps对SuperGLUE [2]基准测试的Recognizing Textual Entailment [1]任务执行超参数优化。 任务是对句子对的二进制分类,如下所述。
Textual Entailment Recognition has been proposed recently as a generic task that captures major semantic inference needs across many NLP applications, such as Question Answering, Information Retrieval, Information Extraction, and Text Summarization. This task requires to recognize, given two text fragments, whether the meaning of one text is entailed (can be inferred) from the other text.
文本蕴涵识别是最近提出的一项通用任务,可以捕获许多NLP应用程序中的主要语义推断需求,例如问题回答 , 信息检索 , 信息提取和文本摘要 。 在给定两个文本片段的情况下,此任务需要识别一个文本的含义是否与另一文本有关(可以推断)。
— Recognizing Textual Entailment —
— 认识文本蕴涵 —
In this guide, we will conduct three main tasks to highlight the value of hyperparameter optimization and to see how you can customize the optimization process.
在本指南中,我们将执行三个主要任务,以突出显示超参数优化的价值并了解如何自定义优化过程。
Train a model with sensible defaults.
训练具有合理默认值的模型。
Conduct a sweep to optimize basic hyperparameters.
进行扫描以优化基本超参数 。
Conduct a sweep for more advanced hyperparameter optimization.
进行扫描以进行更高级的超参数优化 。
For each task, we will be training RoBERTa-Large [3] models on the RTE dataset. Let’s get our development environment set up and the dataset downloaded so we can get down to training!
对于每个任务,我们将在RTE数据集上训练RoBERTa-Large [3]模型。 让我们建立开发环境并下载数据集,以便进行培训!
建立 (Setup)
Install Anaconda or Miniconda Package Manager from here.
从这里安装Anaconda或Miniconda Package Manager。
Create a new virtual environment and install packages.
创建一个新的虚拟环境并安装软件包。
Create a new virtual environment and install packages.
conda create -n simpletransformers python pandas tqdm wandb创建一个新的虚拟环境并安装软件包。
conda create -n simpletransformers python pandas tqdm wandbCreate a new virtual environment and install packages.
conda create -n simpletransformers python pandas tqdm wandbconda activate simpletransformers创建一个新的虚拟环境并安装软件包。
conda create -n simpletransformers python pandas tqdm wandbconda activate simpletransformersCreate a new virtual environment and install packages.
conda create -n simpletransformers python pandas tqdm wandbconda activate simpletransformersconda install pytorch cudatoolkit=10.2 -c pytorchNote: choose the Cuda toolkit version installed on your system.创建一个新的虚拟环境并安装软件包。
conda create -n simpletransformers python pandas tqdm wandbconda activate simpletransformersconda install pytorch cudatoolkit=10.2 -c pytorch注意:选择在系统上安装的Cuda工具包版本。Install Apex if you are using fp16 training. Please follow the instructions here.
如果您正在使用fp16培训,请安装Apex。 请按照此处的说明进行操作。
Install Simple Transformers.
安装简单的变形金刚。
Install Simple Transformers.
pip install simpletransformers安装简单的变形金刚。
pip install simpletransformers
资料准备 (Data Preparation)
Download the data from here.
从此处下载数据。
Extract the archive to
data/. (Should contain 3 files,train.jsonl,val.jsonl,test.jsonl)将存档提取到
data/。 (应包含3个文件,train.jsonl,val.jsonl,test.jsonl)
The function given below can be used to read these jsonl files and convert the data into the Simple Transformers input format (Pandas DataFrame with the three columns text_a, text_b, labels).
下面给出的函数可用于读取这些jsonl文件并将数据转换为Simple Transformers 输入格式 (具有三列text_a, text_b, labels Pandas DataFrame)。
Since we will be using this function in many places, add it to a file utils.py at the root of the project so that it can be imported as needed.
由于我们将在许多地方使用此函数,因此请将其添加到项目根目录的utils.py文件中,以便可以根据需要将其导入。
The RTE dataset contains three sub-datasets.
RTE数据集包含三个子数据集。
- Train set (labelled) — To be used for training models.训练集(标记)—用于训练模型。
- Validation set (labelled) — To be used for validation (hyperparameter optimization, cross-validation, etc.)验证集(标记)—用于验证(超参数优化,交叉验证等)
- Test set (unlabelled) — Predictions made on this set can be submitted for scoring.测试集(未标记)—可以将对此集所做的预测提交评分。
To avoid having to submit predictions to test our final models, we will split the validation set into two random parts and use one for validation (eval_df) and the other for testing (test_df).
为了避免必须提交预测来测试最终模型,我们将验证集分为两个随机部分,一个用于验证( eval_df ),另一个用于测试( test_df )。
Running the data_prep.py file shown above will create eval_df and test_df which we will use to validate and test our models.
运行上面显示的data_prep.py文件将创建eval_df和test_df ,我们将使用它们来验证和测试我们的模型。
用合理的默认值训练模型 (Training a Model with Sensible Defaults)
With experience, most people tend to develop an intuition about important hyperparameters and what values will work for those hyperparameters. In my experience, two of the most critical hyperparameters to consider when training a Transformer model on an NLP task is the learning rate and the number of training epochs.
凭经验,大多数人倾向于对重要的超参数以及对于那些超参数适用的值有一种直觉。 以我的经验,在NLP任务上训练Transformer模型时要考虑的两个最关键的超参数是学习率和训练时期的数量。
Training for too many epochs or using too high a learning rate typically leads to catastrophic forgetting with the model often resorting to generating the same output/label to any given input. On the other hand, an insufficient number of training epochs or too low a learning rate results in a sub-par model.
训练太多的时间段或使用太高的学习率通常会导致灾难性的遗忘 ,因为模型通常诉诸于对任何给定的输入生成相同的输出/标签。 另一方面,训练时期数量不足或学习率太低会导致模型低于标准。
My go-to values for these two hyperparameters is usually a learning rate of 5e-5 and 2 or 3 training epochs (I increase the number of training epochs for smaller datasets).
我对这两个超参数的取值通常是5e-5的学习率和2或3 训练时期 (对于较小的数据集,我增加了训练时期的数量)。
However, I found that my intuition has failed me when I applied these values to training a model on the RTE dataset. The model ended up predicting the same label for all inputs, suggesting that the learning rate is too high. Lowering the learning rate to 1e-5 was sufficient to avoid this issue.
但是,当我将这些值应用于RTE数据集上的模型训练时,我的直觉使我失败了。 该模型最终为所有输入预测了相同的标签,这表明学习率太高。 将学习率降低到1e-5足以避免此问题。
The script below shows how you can train a model with sensible defaults.
下面的脚本显示了如何训练具有合理默认值的模型。
You can refer to the Simple Transformers docs (here and here) for details on the model_args attributes if needed.
如果需要,可以参考Simple Transformers文档( 此处 和 此处 )以获取有关 model_args 属性的 详细信息 。
As the RTE task uses accuracy as the metric in the SuperGLUE benchmark, we will do the same.
由于RTE任务使用准确性作为SuperGLUE基准测试中的指标,因此我们将做同样的事情。
The model achieves an accuracy of 0.8116 using the sensible default hyperparameter values. The confusion matrix for the model is given below.
使用合理的默认超参数值,该模型的精度为0.8116 。 该模型的混淆矩阵如下。
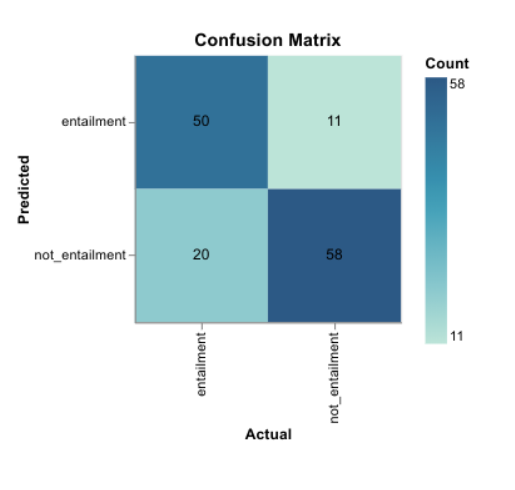
You can also see the full training progress as well as other metrics here.
您还可以在 此处 查看完整的培训进度以及其他指标 。
Not bad, but let’s see what hyperparameter optimization can do.
不错,但是让我们看看超参数优化可以做什么。
基本超参数优化 (Basic Hyperparameter Optimization)
The W&B Sweeps [4] integration in Simple Transformers simplifies the process of conducting hyperparameter optimization.
简单变压器中的W&B Sweeps [4]集成简化了进行超参数优化的过程。
The Sweep configuration can be defined through a Python dictionary which specifies the metric to be optimized, the search strategy to use, and the hyperparameters to be optimized.
可以通过Python字典定义Sweep配置,该字典指定要优化的指标,要使用的搜索策略以及要优化的超参数。
I highly recommend looking through the docs for more information regarding how a Sweep can be configured.
我强烈建议您仔细阅读 文档 ,以获取有关如何配置扫描的更多信息。
For our basic hyperparameter optimization, we will focus on the same two hyperparameters as in the earlier section, i.e. learning rate and the number of training epochs.
对于我们的基本超参数优化,我们将重点关注与前面部分相同的两个超参数,即学习率和训练时期的数量 。
The Sweep configuration can be defined as shown below.
可以如下所示定义扫描配置。
Note: You can use any of the configuration options of a Simple Transformer model as a parameter to be optimized during the Sweep.
注意:可以 在扫描期间使用Simple Transformer模型的 任何 配置选项 作为要优化的参数。
Here, we are using the bayes (Bayesian Optimization) search strategy to optimize the hyperparameters.
在这里,我们使用bayes (贝叶斯优化)搜索策略来优化超参数。
Bayesian Optimization uses a gaussian process to model the function and then chooses parameters to optimize the probability of improvement.
贝叶斯优化使用高斯过程对函数建模,然后选择参数以优化改进的可能性。
— W&B docs —
— W&B文档 —
The metric we want to optimize is the accuracy and the goal is obviously to maximize it. Note that the metric to be optimized must be logged to W&B.
我们要优化的指标是accuracy ,目标显然是使其最大化。 请注意,要优化的指标必须记录到W&B。
The parameters to be optimized is the learning_rate and the num_train_epochs. Here, the learning rate can take any value from 0 to 4e-4 while the number of training epochs can be any integer from 1 to 40.
要优化的参数是learning_rate和num_train_epochs 。 在这里,学习率可以取0到4e-4任何值,而训练时期的数量可以是1到40任何整数。
W&B Sweeps can also speed up the hyperparameter optimization by terminating any poorly performing runs (early_terminate). This uses the hyperband algorithm, as explained here.
W&B Sweeps还可以通过终止任何性能不佳的运行( early_terminate )来加速超参数优化。 本品采用超高频带算法,如解释在这里 。
The final requirement for the Sweep is a function which can be called to train a model with a given set of hyperparameter values.
扫描的最终要求是一个函数,可以调用该函数来训练具有给定的一组超参数值的模型。
The function will initialize the wandb run, set up the Simple Transformers model, train the model, and finally sync the results.
该函数将初始化wandb运行,设置Simple Transformers模型,训练模型,最后同步结果。
The set of hyperparameter values for the current run are contained in wandb.config, which can be passed to a Simple Transformers model. All Simple Transformers models accept a sweep_config keyword argument and will automatically update the model_args based on the wandb.config passed to sweep_config.
当前运行的超参数值集包含在wandb.config ,可以将其传递给Simple Transformers模型。 所有简单的变形金刚模型接受sweep_config关键字参数,并会自动更新model_args基础上, wandb.config传递给sweep_config 。
We also make sure that the accuracy metric is calculated on the validation set (eval_df) as the model is trained. All eval_model() and train_model() methods in Simple Transformers accepts keyword-arguments consisting of the name of a metric and a metric function. This is used here to calculate the accuracy on the eval_df. (More info in the docs)
我们还确保在训练模型时,根据验证集( eval_df )计算accuracy度量。 Simple Transformers中的所有eval_model()和train_model()方法都接受由参数名称和度量函数组成的关键字参数。 在此用于计算eval_df的accuracy 。 ( 文档中的 更多信息 )
Putting all of this together into a single Python file gives us the script below.
将所有这些放到一个Python文件中,即可得到以下脚本。
Now we let this run!
现在我们让它运行!
The W&B dashboard provides many graphs and visualizations which include a lot of valuable information. The graphic below plots the accuracy obtained by each model trained during the Sweep (~13 hours for 48 runs).
W&B仪表板提供许多图形和可视化效果,其中包括很多有价值的信息。 下图显示了在扫频期间训练的每个模型获得的精度(48次运行约13小时)。

Breaking down these 48 runs according to the accuracy achieved gives us the following:
根据获得的精度细分这48个运行,可以得到以下结果:
10 runs achieved an accuracy greater than 0.8
10次运行的精度大于 0.8
23 runs achieved an accuracy of exactly 0.5507
23个运行实现准确 0.5507的精度
15 runs achieved an accuracy of exactly 0.4493
15个运行实现准确 0.4493的精度
These results might seem a little weird (multiple runs with the exact same accuracy score) until you consider the fact that Transformer models can be prone to breaking entirely when trained with bad hyperparameter values. This leads to the model predicting the same label for any input, explaining the models with identical accuracy scores (there are two possible accuracies due to the imbalanced labels in the test set).
在您考虑到在使用错误的超参数值进行训练时,Transformer模型可能易于完全损坏的事实之前,这些结果似乎有些奇怪(多次运行具有完全相同的准确度得分)。 这将导致模型针对任何输入预测相同的标签,并以相同的准确度得分来解释模型(由于测试集中的标签不平衡,因此存在两种可能的准确性)。
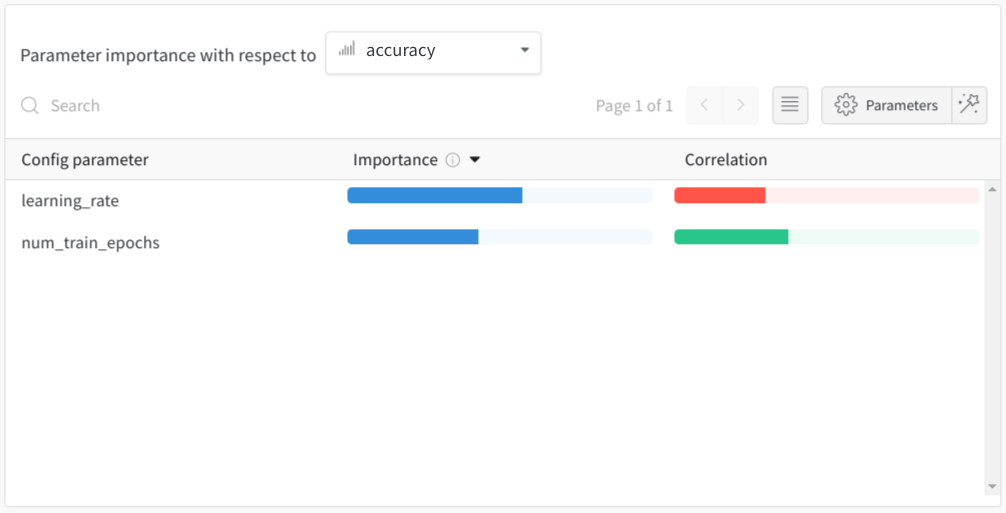
This hypothesis is confirmed in the Parameter Importance visualization.
此假设已在“参数重要性”可视化中得到确认。

Here, we have the impact of the two hyperparameters on the final accuracy obtained. The learning_rate has a very high negative correlation to the accuracy as high learning rates results in models which predict the same label for all inputs.
在这里,我们对获得的最终精度有两个超参数的影响。 learning_rate与准确性有非常高的负相关性,因为高学习率会导致预测所有输入的标签相同的模型。
The Parallel Coordinates plot below bears out the same theory.
下面的“平行坐标”图支持相同的理论。
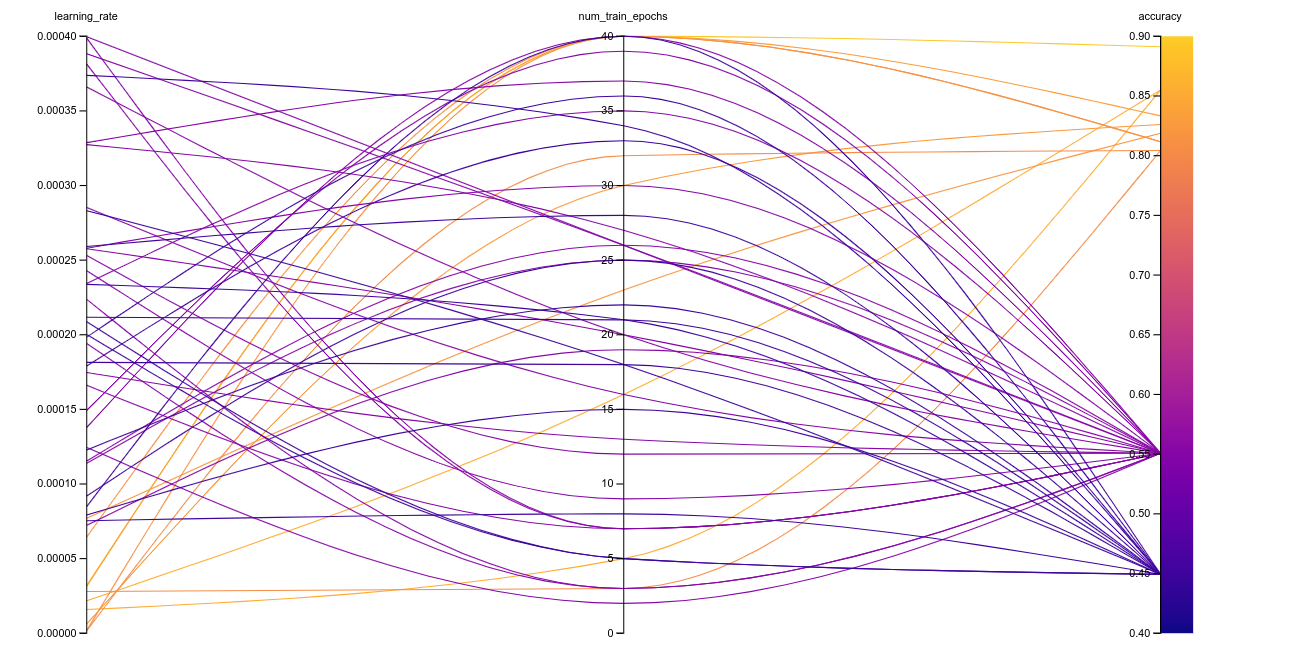
Focusing on the runs with accuracy above 0.8 further reinforces this idea.
专注于精度高于0.8的运行进一步强化了这一想法。

Interestingly, the number of training epochs also starts to play a more significant role when using learning rate values in this range.
有趣的是,当使用此范围内的学习率值时,训练时期的数量也开始发挥更大的作用。
Feel free to dig into the Sweep results here!
随时在这里浏览 Sweep结果!
Now, let’s see how a model trained with these hyperparameters performs on the test set.
现在,让我们看看使用这些超参数训练的模型如何在测试集上执行。
Reminder: The model is trained on the train set, the Sweep is evaluated on the validation set (eval_df), the final model (using the best hyperparameter values) will be assessed on the test set (test_df).
提醒:在训练集上训练模型,在验证集( eval_df ) 上评估Sweep ,在测试集( test_df ) 上评估最终模型(使用最佳超参数值 )。
This script uses the hyperparameter values which yielded the best accuracy on eval_df during the sweep.
该脚本使用超参数值,该值在扫描期间在eval_df上产生了最佳精度。
learning_rate = 0.00003173num_train_epochs = 40The model trained with these hyperparameter values obtains an accuracy of 0.8768, a significant improvement over the sensible defaults model (0.8116).
用这些超参数值训练的模型获得0.8768的准确度,比明智的默认模型( 0.8116 )有了显着改进。
Looking at the Confusion Matrix for the predictions on the test set:
查看混淆矩阵以获取测试集上的预测:
Clearly, our hyperparameter optimization has paid off!
显然,我们的超参数优化已获得回报!
You can also see the full training progress as well as other metrics here.
您还可以在 此处 查看完整的培训进度以及其他指标 。
高级超参数优化 (Advanced Hyperparameter Optimization)
In the previous section, we saw that the learning rate plays a vital role in the performance of a trained model. Having too high a learning rate results in broken models, while training a model with a too low learning rate can result in an under fitted model or a model stuck in local minima.
在上一节中,我们看到学习率在训练模型的性能中起着至关重要的作用。 学习速率过高会导致模型损坏,而训练速率过低的模型则会导致拟合不足的模型或陷入局部最小值的模型。
One potential solution to this conundrum relies on the fact that the learning rate doesn’t seem to affect all parts of the model equally. For instance, the classification layer added on top of the Transformer model layers is far less prone to breaking under higher learning rates. This is likely because the classification layer is initialized randomly when fine-tuning a pre-trained model. I.e. the classification layer is not a pre-trained layer and therefore doesn’t have any acquired knowledge to lose through catastrophic forgetting. On the other hand, the classification layer is potentially more likely to get stuck in local minima (with low learning rates), precisely because it is randomly initialized.
解决这一难题的一种可能的解决方法是, 学习率似乎并不会平等地影响模型的所有部分。 例如,在较高的学习率下,添加到Transformer模型层之上的分类层就不太容易被破坏。 这可能是因为在对预训练模型进行微调时会随机初始化分类层 。 也就是说, 分类层不是经过预先训练的层,因此没有灾难性的遗忘而失去的任何获得的知识。 另一方面,正是因为随机初始化, 分类层才更有可能陷入局部最小值( 学习率较低 )中。
The same phenomena can be observed, albeit to a lesser extent (and with less consistency), when comparing the impact of the learning rate on the early layers Vs the latter layers. The earlier layers can be more prone to catastrophic forgetting than the final layers.
当比较学习率对早期层与后层的影响时,可以观察到相同的现象,尽管程度较小(一致性较低)。 与最后几层相比,更早的几层更容易遭受灾难性的遗忘 。
With Simple Transformers, we can define different learning rates for each named parameter (weight) in a Transformer model. Conveniently, we can also set learning rates for any given layer in the model (24 layers for RoBERTa-LARGE). Let’s see if we can combine this feature with the knowledge we have regarding the effect of the learning rate to push our model towards even better performance.
使用简单的Transformer,我们可以为Transformer模型中的每个命名 参数(权重)定义不同的学习率 。 方便地,我们还可以为模型中的任何给定层(RoBERTa-LARGE为24层)设置学习率 。 让我们看看是否可以将此功能与我们对学习率的影响所拥有的知识相结合,从而将模型推向更高的性能。
While we can try to optimize the learning rate for each layer separately, I am choosing to bundle the layers into four equal groups, each containing six consecutive layers. This should make it easier for us to visualize the Sweep results and may also make it easier for the Sweep to optimize the hyperparameters as there are fewer variables.
虽然我们可以尝试分别优化每个层的学习率 ,但我选择将这些层分成四个相等的组,每个组包含六个连续的层。 这应该使我们更容易看到Sweep结果,也可能使Sweep更容易优化超参数,因为变量变少了。
The classification layer of a RoBERTa model has four named parameters, each of which will be optimized individually. Alternatively, these could also be combined into a single group (this may be the more logical choice), but I am keeping them separate for demonstration purposes.
RoBERTa模型的分类层具有四个命名参数 ,每个参数将分别进行优化。 或者,也可以将它们组合成一个组(这可能是更合逻辑的选择),但是出于演示目的,我将它们分开。
Tip: All Simple Transformers models have a get_named_parameters() method which returns a list of all parameter names in the model.
提示:所有Simple Transformers模型都有一个 get_named_parameters() 方法,该方法返回模型中所有参数名称的列表。
Again, we will start by setting up a configuration for our Sweep.
同样,我们将从为Sweep设置配置开始。
We are using the insights gained from the basic hyperparameter optimization to set a smaller maximum value for the learning rates of the Transformer model layers while giving more leeway to the classification layer parameters.
我们利用从基本超参数优化中获得的见解,为Transformer模型层的学习率设置较小的最大值,同时为分类层参数提供更多的回旋余地。
A quick side-note on using custom parameter groups with Simple Transformers adapted from the docs:
关于将自定义参数组与从文档改编的简单变压器一起使用的简短说明:
The model_args (in this case, a ClassificationArgs object) of a Simple Transformers model has three attributes associated with configuring custom parameter groups.
Simple Transformers模型的model_args (在这种情况下,为ClassificationArgs model_args对象)具有与配置自定义参数组关联的三个属性。
custom_layer_parameterscustom_layer_parameterscustom_parameter_groupscustom_parameter_groupstrain_custom_parameters_onlytrain_custom_parameters_only
自定义图层参数 (Custom layer parameters)
custom_layer_parameters makes it more convenient to set the (PyTorch) optimizer options for a given layer or set of layers. This should be a list of Python dicts where each dict contains a layer key and any other optional keys matching the keyword arguments accepted by the optimizer (e.g. lr, weight_decay). The value for the layer key should be an int (must be numeric) which specifies the layer (e.g. 0, 1, 11).
custom_layer_parameters可以更方便地为给定层或一组层设置(PyTorch)优化器选项。 这应该是Python字典的列表,其中每个字典包含一个layer键以及与优化程序接受的关键字参数匹配的任何其他可选键(例如lr , weight_decay )。 对于该值layer键应该是int (必须是数字),其指定了层(例如0 , 1 , 11 )。
E.g.:
例如:
自定义参数组 (Custom parameter groups)
custom_parameter_groups offers the most granular configuration option. This should be a list of Python dicts where each dict contains a params key and any other optional keys matching the keyword arguments accepted by the optimizer (e.g. lr, weight_decay). The value for the params key should be a list of named parameters (e.g. ["classifier.weight", "bert.encoder.layer.10.output.dense.weight"]).
custom_parameter_groups提供最精细的配置选项。 这应该是Python字典的列表,其中每个字典包含一个params键以及与优化程序接受的关键字参数匹配的任何其他可选键(例如lr , weight_decay )。 params键的值应该是命名参数的列表(例如["classifier.weight", "bert.encoder.layer.10.output.dense.weight"] )。
E.g.:
例如:
仅训练自定义参数 (Train custom parameters only)
The train_custom_parameters_only option is used to facilitate the training of specific parameters only. If train_custom_parameters_only is set to True, only the parameters specified in either custom_parameter_groups or in custom_layer_parameters will be trained.
train_custom_parameters_only选项仅用于促进特定参数的训练。 如果train_custom_parameters_only设置为True ,则仅训练在custom_parameter_groups或custom_layer_parameters指定的参数。
Back to Hyperparameter Optimization:
返回超参数优化:
While you can use any of the configuration options available in a Simple Transformers model as a hyperparameter to be optimized, W&B Sweeps do not currently support configurations with nested parameters. This means that configuration options where the expected data type is a collection (dictionary, list, etc.) cannot be configured directly in a Sweep configuration. However, we can easily handle this logic ourselves.
虽然您可以将Simple Transformers模型中可用的任何配置选项用作要优化的超参数,但W&B Sweeps当前不支持带有嵌套参数的配置。 这意味着预期数据类型为集合(字典,列表等)的配置选项无法直接在Sweep配置中配置。 但是,我们可以轻松地自己处理此逻辑。
Looking at the sweep_config we defined earlier, we can observe that none of the parameters is nested, despite the fact that we want multiple layers with the same learning rate.
查看我们之前定义的sweep_config ,尽管我们希望多层具有相同的学习速率 ,但我们看sweep_config任何参数都是嵌套的。
The Sweep will give us a single value (per run) for each parameter defined in the config. We will take care of converting this into the format expected by Simple Transformers in the train() function for the Sweep.
扫描将为我们在配置中定义的每个参数提供单个值(每次运行)。 我们将负责将其转换为Sweep的train()函数中的简单转换器期望的格式。
The names of the parameters in the sweep_config were chosen to make the conversion relatively straightforward.
选择sweep_config中参数的sweep_config是为了使转换相对简单。
The name for a layer group has the format
layer_<start_layer>-<end_layer>.图层组的名称格式为
layer_<start_layer>-<end_layer>。The name for a parameter group (classifier parameters) has the format
params_<parameter name>.参数组的名称(分类器参数)的格式为
params_<parameter name>。
Based on this naming convention, let’s see how we can parse the sweep_config to extract the proper hyperparameter values.
基于此命名约定,让我们看看如何解析sweep_config来提取适当的超参数值。
First, we grab the hyperparameter values assigned to the current run. These can be accessed through the wandb.config object inside the train() method of a Sweep. Fortunately, we can convert the wandb.config to a Python dictionary which can be parsed easily.
首先,我们获取分配给当前运行的超参数值。 可以通过wandb.config的train()方法内的wandb.config对象访问它们。 幸运的是,我们可以将wandb.config转换为wandb.config解析的Python字典。
We also remove the _wandb key and rearrange the other dictionary items into a direct mapping from the parameter name to its current value.
我们还删除了_wandb键,并将其他字典项重新排列为从参数名称到其当前值的直接映射。
Next, we iterate through each of the items in the dictionary and build a dictionary in the format expected by Simple Transformers. Finally, we update the model_args (a ClassificationArgs object) with the dictionary values.
接下来,我们遍历字典中的每个项目,并以Simple Transformers期望的格式构建字典。 最后,我们用字典值更新model_args ( ClassificationArgs对象)。
Combine all of this into a Python script and we are off to the races!
将所有这些结合到Python脚本中,我们就可以开始比赛了!

In the advanced hyperparameter optimization Sweep, thirty-eight (38) of forty (40) runs achieve an accuracy higher than 0.8 (compared to 10 of 48 in the basic optimization).
在高级超参数优化Sweep中,四十(40)次运行中有三十八(38)次的精度高于0.8 (相比于基本优化中的48之10)。
The Parallel Coordinates plot is a little harder to visualize when we include all the runs, but we can focus on individual groups to get a clearer picture.
当我们包括所有行程时,“平行坐标”图很难显示,但是我们可以专注于单个组以获得更清晰的图片。

I recommend checking out the Parallel Plot (here) yourself as it has many interactive features which do a much better job of visualizing the Sweep than individual images.
我建议您亲自检查“平行绘图”( 此处 ),因为它具有许多交互式功能,与单独的图像相比,在可视化“扫描”方面做得更好。
0–6层 (Layers 0–6)

6-12层 (Layers 6–12)

第12-18层 (Layers 12–18)

第18-24层 (Layers 18–24)

0–24层,运行精度> 0.8 (Layers 0–24 for runs with accuracy > 0.8)

While this plot is admittedly a little noisy, we can still see that the better models (lighter green) do have lower learning rates for the first half of the 24 layers and higher learning rates for the other half.
尽管该图有些嘈杂,但我们仍然可以看到,更好的模型(较浅的绿色)在24层的上半部确实具有较低的学习率 ,而在下半层中则具有较高的学习率 。
运行精度大于0.8的分类层 (Classification Layers for runs with accuracy > 0.8)

The Parallel Coordinates Plot for the classification layers seems to be even noisier than the plot for the Transformer model layers. This may indicate that the classification layers are comparatively more robust and can learn good weights as long as the learning rate is high enough to avoid getting stuck in local minima.
分类层的平行坐标图似乎比Transformer模型层的图更嘈杂。 这可能表明分类层相对更健壮,并且只要学习率足够高以避免陷入局部极小值,就可以学习良好的权重。
Finally, let’s see how a model trained with the best hyperparameters found from the advanced Sweep will perform on the test set.
最后,让我们看看使用从高级Sweep中找到的最佳超参数训练的模型如何在测试集上执行。
To download a CSV file with the hyperparameters for the best run, go to the Sweep table in the W&B dashboard, search for deep-sweep (name of the best run), and click the download button (top-right). Create a directory sweep_results and save the CSV file as sweep_results/deep-sweep.csv.
要下载具有超参数的CSV文件以获得最佳运行,请转到W&B仪表板中的“扫描”表,搜索deep-sweep (最佳运行的名称),然后单击“下载”按钮(右上角)。 创建目录sweep_results并将CSV文件保存为sweep_results/deep-sweep.csv 。

The script below will train the model and evaluate it against the test set.
下面的脚本将训练模型并根据测试集对其进行评估。
The hyperparameter values extracted from deep-sweep.csv are shown below.
从deep-sweep.csv提取的超参数值如下所示。
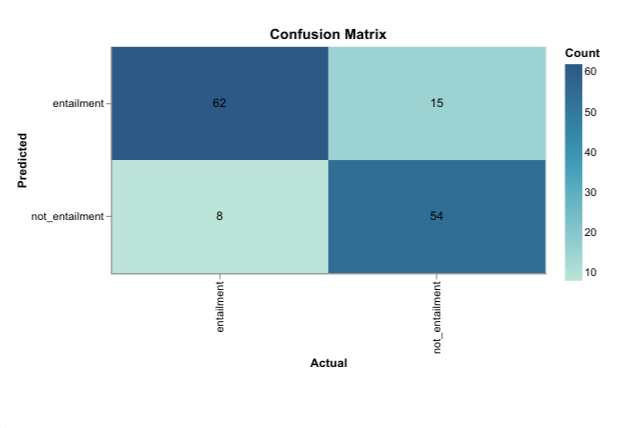
The model achieves a final accuracy score of 0.8913 on the test set.
该模型在测试集上获得0.8913的最终准确性得分。
Looking at the Confusion Matrix for the predictions on the test set:
查看混淆矩阵以获取测试集上的预测:

The accuracy gain from advanced hyperparameter optimization vs basic hyperparameter optimization (0.8913 vs 0.8768) is far more modest compared to the accuracy gain from basic hyperparameter optimization vs sensible defaults (0.8768 vs 0.8116). However, it is still a noticeable improvement over basic hyperparameter optimization.
与从基本超参数优化与明智的默认值 ( 0.8768与0.8116)相比,从高级超参数优化与基本超 参数优化获得的准确度增益( 0.8913对0.8768)相比,适度得多。 但是,它仍然是对基本超参数优化的显着改进。
结果 (Results)
准确性 (Accuracy)
混淆矩阵 (Confusion Matrix)
结语 (Wrap-Up)
- Hyperparameter Optimization can be used to train a model with significantly better performance.超参数优化可用于训练具有明显更好性能的模型。
Learning rate and the number of training epochs are two of the most critical hyperparameters to consider when training a Transformer model.
学习率和训练时期数是训练 Transformer模型时要考虑的两个最关键的超参数。
The performance gain can be increased further by using (and optimizing) distinct learning rates for the different layers of a model.
通过为模型的不同层使用(和优化)不同的学习率 ,可以进一步提高性能。
It is possible that advanced hyperparameter optimization would shine even more in situations where the task is complicated and difficult for a model to learn.
在任务复杂且模型难以学习的情况下, 高级超参数优化可能会更加耀眼。
Hyperparameter tuning can be used to find good ranges of values for critical hyperparameters, which can then be used to hone in on even better values.
超参数调整可用于为关键超参数找到合适的值范围,然后可用于调整更好的值。
[1] Giampiccolo, D., Magnini, B., Dagan, I., and Dolan, B. 2007. The third PASCAL recognizing textual entailment challenge. In Proceedings of the ACL-PASCAL workshop on textual entailment and paraphrasing (pp. 1–9).
[1] Giampiccolo,D.,B。Magnini,B.Dagan和B.Dolan,2007年。第三个承认文本蕴含挑战的PASCAL。 在ACL-PASCAL关于文本含义和释义的研讨会论文集 (第1-9页)中。
[2] Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman 2019. SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems. arXiv preprint 1905.00537.
[2] Alex Wang,Yada Pruksachatkun,Nikita Nangia,Amanpreet Singh,Julian Michael,Felix Hill,Omer Levy和Samuel R. Bowman,2019年。SuperGLUE:通用语言理解系统的粘性基准。 arXiv预印本1905.00537 。
[3] Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L. and Stoyanov, V., 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
[3] Liu,Y.,Ott,M.,Goyal,N.,Du,J.,Joshi,M.,Chen,D.,Levy,O.,Lewis,M.,Zettlemoyer,L.和Stoyanov, V.,2019年。Roberta:一种经过稳健优化的bert预训练方法。 arXiv预印本arXiv:1907.11692 。
[4] https://docs.wandb.com/sweeps
[4] https://docs.wandb.com/sweeps
翻译自: https://towardsdatascience.com/hyperparameter-optimization-for-optimum-transformer-models-b95a32b70949
ansys电力变压器模型
http://www.taodudu.cc/news/show-1874147.html
相关文章:
- 一年成为ai算法工程师_我作为一名数据科学研究员所学到的东西在一年内成为了AI领导者...
- openai-gpt_为什么GPT-3感觉像是编程
- 医疗中的ai_医疗保健中自主AI的障碍
- uber大数据_Uber创建了深度神经网络以为其他深度神经网络生成训练数据
- http 响应消息解码_响应生成所需的解码策略
- 永久删除谷歌浏览器缩略图_“暮光之城”如何永久破坏了Google图片搜索
- 从头实现linux操作系统_从头开始实现您的第一个人工神经元
- 语音通话视频通话前端_无需互联网即可进行数十亿视频通话
- 优先体验重播matlab_如何为深度Q网络实施优先体验重播
- 人工智能ai以算法为基础_为公司采用人工智能做准备
- ieee浮点数与常规浮点数_浮点数如何工作
- 模型压缩_模型压缩:
- pytorch ocr_使用PyTorch解决CAPTCHA(不使用OCR)
- pd4ml_您应该在本周(7月4日)阅读有趣的AI / ML文章
- aws搭建深度学习gpu_选择合适的GPU进行AWS深度学习
- 证明神经网络的通用逼近定理_在您理解通用逼近定理之前,您不会理解神经网络。...
- ai智能时代教育内容的改变_人工智能正在改变我们的评论方式
- 通用大数据架构-_通用做法-第4部分
- 香草 jboss 工具_使用Tensorflow创建香草神经网络
- 机器学习 深度学习 ai_人工智能,机器学习和深度学习。 真正的区别是什么?...
- 锁 公平 非公平_推荐引擎也需要公平!
- 创建dqn的深度神经网络_深度Q网络(DQN)-II
- kafka topic:1_Topic️主题建模:超越令牌输出
- dask 于数据分析_利用Dask ML框架进行欺诈检测-端到端数据分析
- x射线计算机断层成像_医疗保健中的深度学习-X射线成像(第4部分-类不平衡问题)...
- r-cnn 行人检测_了解用于对象检测的快速R-CNN和快速R-CNN。
- 语义分割空间上下文关系_多尺度空间注意的语义分割
- 自我监督学习和无监督学习_弱和自我监督的学习-第2部分
- 深度之眼 alexnet_AlexNet带给了深度学习的世界
- ai生成图片是什么技术_什么是生成型AI?
ansys电力变压器模型_最佳变压器模型的超参数优化相关推荐
- 人口预测和阻尼-增长模型_使用分类模型预测利率-第3部分
人口预测和阻尼-增长模型 This is the final article of the series " Predicting Interest Rate with Classifica ...
- 机器学习模型定点化_机器学习模型的超参数优化
引言 模型优化是机器学习算法实现中最困难的挑战之一.机器学习和深度学习理论的所有分支都致力于模型的优化. 机器学习中的超参数优化旨在寻找使得机器学习算法在验证数据集上表现性能最佳的超参数.超参数与一般 ...
- tensorflow超参数优化_机器学习模型的超参数优化
引言 模型优化是机器学习算法实现中最困难的挑战之一.机器学习和深度学习理论的所有分支都致力于模型的优化. 机器学习中的超参数优化旨在寻找使得机器学习算法在验证数据集上表现性能最佳的超参数.超参数与一般 ...
- 【机器学习】算法模型自动超参数优化方法
什么是超参数? 学习器模型中一般有两类参数,一类是可以从数据中学习估计得到,我们称为参数(Parameter).还有一类参数时无法从数据中估计,只能靠人的经验进行设计指定,我们称为超参数(Hyper ...
- 使用Optuna的XGBoost模型的高效超参数优化
介绍 : (Introduction :) Hyperparameter optimization is the science of tuning or choosing the best set ...
- 全网最全:机器学习算法模型自动超参数优化方法汇总
什么是超参数? 学习器模型中一般有两类参数,一类是可以从数据中学习估计得到,我们称为参数(Parameter).还有一类参数时无法从数据中估计,只能靠人的经验进行设计指定,我们称为超参数(Hyper ...
- 机器学习模型的超参数优化 | 原力计划
作者 | deephub 责编 | 王晓曼 出品 | CSDN博客 头图 | CSDN付费下载自东方IC 引言 模型优化是机器学习算法实现中最困难的挑战之一.机器学习和深度学习理论的所有分支都致力于模 ...
- 模型效果差?我建议你掌握这些机器学习模型的超参数优化方法
模型优化是机器学习算法实现中最困难的挑战之一.机器学习和深度学习理论的所有分支都致力于模型的优化. 机器学习中的超参数优化旨在寻找使得机器学习算法在验证数据集上表现性能最佳的超参数.超参数与一般模型参 ...
- CS231n 卷积神经网络与计算机视觉 7 神经网络训练技巧汇总 梯度检验 参数更新 超参数优化 模型融合 等
前面几章已经介绍了神经网络的结构.数据初始化.激活函数.损失函数等问题,现在我们该讨论如何让神经网络模型进行学习了. 1 梯度检验 权重的更新梯度是否正确决定着函数是否想着正确的方向迭代,在UFLDL ...
- 机器学习模型的超参数优化用于分子性质预测
在<预测化学分子的nlogP--基于sklearn, deepchem, DGL, Rdkit的图卷积网络模型>中简单介绍了sklearn模型的使用方法. 现在来介绍一下,如何对sklea ...
最新文章
- ES6精华:字符串扩展
- 深度干货!值得精读的2018自动驾驶行业发展报告
- 在flask上使用websocket
- VTK:图像非最大抑制用法实战
- caffe学习笔记17-find-tuning微调学习
- matlab音频基频的提取,(620512681) 自相关基频提取算法的MATLAB实现
- Excel表格中如何换行
- HTML页面分享微博、QQ、微信功能
- win7系统电脑蓝屏怎么解决,如何解决win7电脑蓝屏
- 【Linux】管道实现进程间通信
- oracle 4043,oracle desc dba_data_files视图报ORA-4043错误小记
- int short型类型转换
- 用于穿戴脑机接口的脑电EEG传感芯片KS1092
- 机车计算机模糊规则表,计算机编制机车周转图有什么要求?
- 逻辑编程Prolog和回答集编程ASP
- 使用jspdf将网页转化成pdf(解决滚动条以外变成黑色问题及缺少echarts图表问题)
- Maria DB下载安装教程
- 怎么样装修好阿里巴巴国际站产品边框进度条环绕围绕效果动态gif制作代码全屏展示图片首页装修技巧方法教程视频全球旺铺阿里旺铺自定义内容装修 模板模块设置内容
- 【AD笔记】--原理图原理图库原理图
- selenium IDE版本与火狐浏览器版本
热门文章
- hdu 3996 Gold Mine ( 最大权闭合图 )
- Entity Framework 4.0 FK Properties FK Associations
- extern dllInport用法
- python pip 安装 win10 解决anacoda代理错误 ProxyError: Conda cannot proxy configuration
- 每日一句20191224
- 190509每日一句
- Atitit webservice之道 艾提拉著 目录 1. 基本说明Web Service 1 2. 基本概念与内部构成 2 2.1. Web services要使用两种技术: XML SOAP
- Atitit 虚拟经济世代 与 知识管理
- Atitit 图像处理 halcon类库的使用 范例边缘检测 attilax总结
- Atitit.病毒木马的快速扩散机制原理nio 内存映射MappedByteBuffer