网页版微博HTML解析和提取,爬虫聚焦——以新浪微博为例
爬虫聚焦——以新浪微博为例
标签:#思想##技术##爬虫#
时间:2017/03/29 17:35:12
作者:Vanessa He
网络爬虫是实现网页数据获取的一般方法,并且需要先成功模拟微博登陆后,再进入设定好的入口URL 地址,将网页内容按某种策略以文本形式存于某存储系统中, 同时抓取网页中其他的可用来作为二级爬行入口的有效地址, 直到满足已定抓取条件或抓取结束后爬虫程序停止。但是,由于网页是通过HTML语言标记元素的,所以在获取网页信息时候需针对数据的不同标签分别进行抓取。这一获取方法实现的前提是需要先登陆微博,只有在登陆成功之后网页的相应cookie值才会被保存下来,但是,由于微博平台的相关设置,一般的网络爬虫获取数据的限制很大,所以如何取得微博网站的“信任”也是一大重要问题。同时,由于微博数据形式的多样化,包含文本、表情、超链接、地理位置、用户关系等,这也增加了获取数据的难度。除此之外,微博爬虫程序存在一个效率较低的问题,同时这种方式获取的数据往往是杂乱的,因此如何规范获取数据和提高爬取效率又是另一大问题。所以说,“爬虫”,懂了都简单,刚入门还是要好好花点心思的哦。
#### **一、知彼**
在研究微博数据的获取方法之前,需要先了解微博页面的信息架构,明确我们需要获取的数据在网页上的呈现形式,然后分析网页的源代码和网页数据流情况,确定微博界面解析和页面数据获取的必要技术手段,这样,才能更好的发现待解决的问题并提出解决方案。
如果想要分析面向特定话题的微博页面(话题主页和评论页),其信息结构如下(这里博主随意选了“和颐酒店女生遇袭”话题页面来分析):
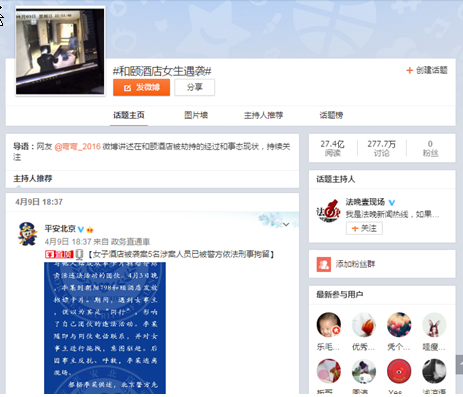


关于面向特定话题的微博发帖界面,如图所示,微博话题主页界面有非常清晰地区块划分,除去那些与话题内容无关的价值信息无关的模块之后,主要分为标题栏、发帖栏、话题主持人栏和最新参与用户栏,其中发帖栏可分为主持人推荐栏和热门评论或者时评团栏两大区块,而热门评论或者时评团栏实际上却是由3个15条帖子模块组成,每15条帖子模块的地址都不一样,这是微博所独有的页面结构特点,果然也对页面信息数据的获取增加了一定的难度。然后,话题页面的最下方是可以跳转第几页或者点击下一页的翻页模块。


关于特定话题的微博数据还包括对于重点帖的评论,如图所示,如“和颐酒店遇袭”事件,对于这一社会话题而言,最开始是由某微博用户自己发起的,所以最开始大多网络用户都是对话题发起者的发帖进行评论的,这些评论信息是对于该话题的重要信息来源,因此,评论信息也是对微博数据研究的重要方面。
综上所述,从技术层面来看,这些模块都是使用基于CSS技术的代码来实现,模块之间的区分是通过
这样的标识来分割,因此模块之间都是有清晰地分界,便于我们来分析整个微博页面的结构。
#### **二、知己**
通过对特定话题下的微博网页信息结构的分析,我们不难发现微博数据是在静态网页上呈现的,这相比动态的网页而言就简单一点,静态的网页上的信息是通过HTML语法编码实现,这一点我们通过微博后台源代码就可以得到验证,这样的网页上可以包含数字、文字、表情、图片、视频和链接等,而内容的多样性也增加了数据获取的难度。
针对HTML网页的数据获取方法,结合微博网页的特点,首先对某一URL下的页面进行解析形成树,然后对树中目标数据进行遍历操作,从而获取到目标数据。然而,真实的特定话题下的微博页面数据被分割成了很多区块,这些区块有的是按照所在位置进行区分的,有的是通过一些特殊的标签进行数据组织的,并且不同区块下数据的定位地址也不一样,这样的话,同一个话题页面下的页面解析需要对该网页中数据的多个地址进行分别解析和相同标签的遍历操作,所幸的是,微博正文发帖的部分虽然被分成了4块,但是每一区块的HTML标签基本没有变化,这样的话,只需要在网页的解析方面做出改变即可,最后将获取的数据再存储在同一个数据库中就完成了数据的获取。
结合特定话题下的微博网页的信息结构的分析,微博数据的获取主要是通过对浏览器地址和通过json返回地址两种地址的解析来获取网页数据,现将两种方式的微博数据的获取流程归纳如图:

通过以上获取流程介绍,特定话题下的数据获取方法主要包括以下:
**1、Jsoup的HtmlParse技术**
作为Java的HTML网页解析器,Jsoup提供了很多有用的API,所以可直接通过URL地址和文件加载Document对象,也可以直接解析html字符串或者body片段,还可以通过CSS、DOM或jQuery操作方法等进行直接的数据(HTML的文本、属性、元素)读取和操作。使用其解析网页的优势在于能快速的解析HTML代码,并且能在解析的过程中保证结果的较为准确性,而这样的优势离不开jsoup选择器的作用。使用Jsoup解析html之前,因为使用Jsoup解析网页过程中会涉及Node、Element、Document等类的使用,所以需要先了解DOM结构。
Node是在解析HTML过程中,文档、标签、属性、文本和注释都被看成结点,这样就会被构造成一个节点树。Element一般包括标记名称、属性和子节点等。在一个Element中,可以进行数据提取和结点遍历等操作。作为装载html的文档类,Document是Jsoup中具有重要地位的核心类。使用这三类的目的是为了select选择器在进行逐级标签选择时能够准确的抽取目标数据,而且这样还便于文档的遍历操作。
Jsoup因可使用与jQuery类似的选择器检索和查找元素而更加优越,它还可以从元素集合中直接抽取文本、属性和html内容,并且Jsoup仅仅需要一行代码就可以实现目的,而其他的HTML解析器也许需要多行代码才能实现同样的功能。

选择器通过使用Element.select(String selector)和Elements.select(String selector)两种方法可以查找匹配目标元素,Select方法可作用于Document、Element或Elements,并支持CSS或jQuery语法,最终返回元素列表(Elements)。
**2、正则表达式**
正则表达式是通过利用一些事先已经定义好的特殊符号对字符串进行逻辑过滤的操作,其目的主要是通过简单的字符匹配代替复杂的简化字符串的代码程序,从而实现字符串处理的便捷性和高效性。

#### **三、百战百殆**
根据以上功能需求分析,爬虫程序大致可分为微博平台模拟登陆、数据抓取和数据存储三个模块。具体来看,微博平台模拟登陆模块是后两大模块实现的基础,其中最核心的部分是数据获取模块,是实现面向特定话题下的微博数据获取的关键模块,第三个模块是抓取过程的收尾工作,是对抓取过程得到数据的具体展现。下面详细阐述:

(1)微博平台模拟登陆模块:该部分功能是参考真实微博平台成功登陆过程,设计爬虫程序登陆模拟代码,得到有效的URL合法地址,并以此地址为“引子”,便于实现目标网址的用户登录问题,从而实现目标网址数据的获取。技术上来看,这部分主要分为加密登陆账号和密码和获取合法地址两部分。在模拟用户的登陆中,需要先将事先传输的用户名和密码分别进行64位编码和RSA算法编码,然后再将编码的结果发送给微博服务器,服务器审核验证通过后便返回一串字符;而获取合法地址部分将分析返回的一串字符,目的是得到URL合法地址。
(2)微博数据抓取模块:该部分功能是在已登陆的状态下,首先通过话题的MD5编码与网页地址进行拼接成完整微博话题地址,然后再向微博服务器请求网页HTML解析并传给客户端,最后从解析结果中获取目标数据,获取到目标话题的信息以及用户的信息。同时,这一模块还实现了获取新的URL的功能,以便下一阶段的数据获取。技术上来看,这部分主要分为话题地址拼接、HTML解析代码获得和目标数据获得三部分。在成功登陆的基础上,通过对已成话题的话题名称进行MD5编码或直接利用分类话题的代码,将其与已知的地址进行拼接,从而获取到目标URL地址;然后HTML代码获取部分将会从目标URL地址中针对目标数据所在标签范围获取HTML代码;最后目标数据获得部分分析HTML并从中抽取选定字段的目标数据。
(3)微博数据存储模块:该部分功能是有效地存获取模块所得的数据进入特定数据表中,便于用户随时随地查看和处理。技术上来看,本模块主要是将微博数据抓取模块所得到的数据列表进行循环存入数据库中,以便用户对锁喉取数据进行相关利用和处理。
总结技术实现,流程如下:

网页版微博HTML解析和提取,爬虫聚焦——以新浪微博为例相关推荐
- Python爬虫【二】爬取PC网页版“微博辟谣”账号内容(selenium同步单线程)
专题系列导引 爬虫课题描述可见: Python爬虫[零]课题介绍 – 对"微博辟谣"账号的历史微博进行数据采集 课题解决方法: 微博移动版爬虫 Python爬虫[一]爬取移 ...
- Python爬虫【四】爬取PC网页版“微博辟谣”账号内容(selenium多线程异步处理多页面)
专题系列导引 爬虫课题描述可见: Python爬虫[零]课题介绍 – 对"微博辟谣"账号的历史微博进行数据采集 课题解决方法: 微博移动版爬虫 Python爬虫[一]爬取移 ...
- Python爬虫【三】爬取PC网页版“微博辟谣”账号内容(selenium单页面内多线程爬取内容)
专题系列导引 爬虫课题描述可见: Python爬虫[零]课题介绍 – 对"微博辟谣"账号的历史微博进行数据采集 课题解决方法: 微博移动版爬虫 Python爬虫[一]爬取移 ...
- Python实现爬取移动端网页版微博用户信息及(部分)粉丝和(部分)关注信息(一)
电脑端网页版微博weibo.com的处理相对复杂,先从最简单的移动端weibo.cn开始.因为微博系统限制,移动端只能查看前20页关注和粉丝信息,所以对于关注或粉丝超过200的用户,只能获取部分粉丝和 ...
- 微博html5版打不开,PC端网页版微博就是打不开是什么问题啊!缓 – 手机爱问
2014-01-18 为什么今天我网页版登录不了....但是微博桌面和手机客户端都能登录呢?我清除过cookie和缓存了.... 微博账号提示异常/不存在导致无法登录,主要有以下几种情况: 1.帐号出 ...
- 微信协议网页版微信协议解析
最近在做个微信机器人,所以研究了网页版的微信协议及相关接口,在这里简单总结一下. 从表面上看,对于网页版微信我们的使用流程是这样的: 很简单,只有四步,但如果细化到内里细节的话,上面这简单四步的背后其 ...
- js逆向系列:解决网页版微博登陆的js加密(2020.9.1最新版)
一.前言 博主最近沉迷js逆向,向各网站开刀,于是决定拿比较经典的微博登陆js加密来作为案例给大家讲解一下. 二.分析过程 我们先从这个登录界面进行调试.先随便填写账号密码,找到登陆的请求接口. 很容 ...
- 利用Fiddler中的FiddlerScript自动保存抖音PC网页版视频链接(相当于一个爬虫)
目标网址: https://www.douyin.com/ 准备工具: 1.配置好的Fiddler 代码配置方法 首先找到Fiddler中的FiddlerScript 找到Go to 选择OnBefo ...
- 微博登录记录pythonurllib_定向爬虫 - Python模拟新浪微博登录
当我们试图从新浪微博抓取数据时,我们会发现网页上提示未登录,无法查看其他用户的信息. 模拟登录是定向爬虫制作中一个必须克服的问题,只有这样才能爬取到更多的内容. 实现微博登录的方法有很多,一般我们在模 ...
- python+selenium 爬取微博(网页版)并解决账号密码登录、短信验证
使用python+selenium 爬取微博 前言 为什么爬网页版微博 为什么使用selenium 怎么模拟微博登录 一.事前准备 二.Selenium安装 关于selenium 安装步骤 三.sel ...
最新文章
- go channel 缓冲区最大限制_GO语言圣经学习笔记(八)Goroutines和Channels
- python3.6安装scrapy-win7安装python3.6.1及scrapy
- C语言关于static的解析
- 关于vc中Warning: skipping non-radio button in group的警告
- 零基础入门Python I/O:从print函数开始
- 深入浅出VC++串口编程--第三方类
- 深入系统底层trace
- “父亲项目”走进澳洲校园 助父子建立联系
- windows2003密码忘记了该如何处理
- java put请求_计算机毕业设计中用java实现小程序推送(springboot实现)
- [数学建模]数学规划模型
- 如何卸载CAD?怎么把CAD彻底卸载干净重新安装的方法
- 2. 查询表product——统计所有库存商品的总价值
- 今日头条、抖音创始人张一鸣
- Linux-lsxxx
- 魅族手机突然显示无服务器,魅族Flyme6是悟空请来的?Bug竟然有这么多?
- 使用注解开发(重点)
- 符号之间,记住你所需要的正则表达式
- 电脑c语言跟英语关系大吗,英语和数学不好能学好C语言吗
- 中国制造2025主攻方向是智能制造