Spatial Transformer Networks(STN)详解
目录
- 1、STN的作用
- 1.1 灵感来源
- 1.2 什么是STN?
- 2、STN网络架构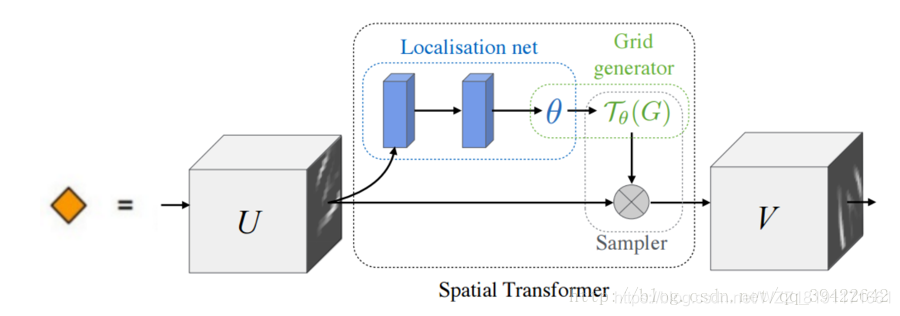
- 3、Localisation net是如何实现参数的选取的?
- 3.1 如何实现平移变换
- 3.2 如何实现缩放变换
- 3.3 如何实现旋转变换
- 3.4 如何实现裁剪变换
- 3.5 总结
- 4、Grid generator如何实现像素点坐标的对应关系?
- 4.1 为什么会有坐标的问题?
- 4.2 仿射变换关系
- 5、Sampler实现坐标求解的可微性
- 5.1 小数坐标问题的提出
- 5.2 解决输出坐标为小数的问题
- 5.3 Sampler的数学原理
- 6、Spatial Transformer Networks(STN)
- 7、STN 代码实现
- 参考资料
- 注意事项
1、STN的作用
1.1 灵感来源
普通的CNN能够显示的学习平移不变性,以及隐式的学习旋转不变性,但attention model 告诉我们,与其让网络隐式的学习到某种能力,不如为网络设计一个显式的处理模块,专门处理以上的各种变换。因此,DeepMind就设计了Spatial Transformer Layer,简称STL来完成这样的功能。
1.2 什么是STN?
关于平移不变性 ,对于CNN来说,如果移动一张图片中的物体,那应该是不太一样的。假设物体在图像的左上角,我们做卷积,采样都不会改变特征的位置,糟糕的事情在我们把特征平滑后后接入了全连接层,而全连接层本身并不具备 平移不变性 的特征。但是 CNN 有一个采样层,假设某个物体移动了很小的范围,经过采样后,它的输出可能和没有移动的时候是一样的,这是 CNN 可以有小范围的平移不变性 的原因。
![]()
如上图所示,如果是手写数字识别,图中只有一小块是数字,其他大部分地区都是黑色的,或者是小噪音。假如要识别,用Transformer Layer层来对图片数据进行旋转缩放,只取其中的一部分,放到之后然后经过CNN就能识别了。我们发现,它其实也是一个layer,放在了CNN的前面,用来转换输入的图片数据,其实也可以转换feature map,因为feature map说白了就是浓缩的图片数据,所以Transformer layer也可以放到CNN里面。
2、STN网络架构
上图是Spatial Transformer Networks的网络结构,它主要由3部分组成,它们的功能和名称如下:参数预测:Localisation net、坐标映射:Grid generator、像素的采集:Sampler。
![]()
上图展示了一个平移变换的过程,也就是STN所做的事情。假设左边是Layer l−1的输出,也就是STN的输入,最右边为变换后的结果。假设是一个全连接层,n,m代表输出的值在输出矩阵中的下标,输入的值通过权值w,做一个组合,完成这样的变换。
假如要生成a11la_{11}^{l}a11l,那就是将左边矩阵的九个输入元素,全部乘以一个权值,加权相加:a11l=w1111la11l−1+w1112la12l−1+w1113la13l−1+⋯+w1133la33l−1a_{11}^{l}=w_{1111}^{l} a_{11}^{l-1}+w_{1112}^{l} a_{12}^{l-1}+w_{1113}^{l} a_{13}^{l-1}+\cdots+w_{1133}^{l} a_{33}^{l-1}a11l=w1111la11l−1+w1112la12l−1+w1113la13l−1+⋯+w1133la33l−1。这仅仅是a11la_{11}^{l}a11l的值,其他的结果也是这样算出来的,具体的计算公式如下所示:anml=∑i=13∑j=13wnm,ijlaijl−1a_{n m}^{l}=\sum_{i=1}^{3} \sum_{j=1}^{3} w_{n m, i j}^{l} a_{i j}^{l-1}anml=i=1∑3j=1∑3wnm,ijlaijl−1通过调整这些权值,就可以达到缩放和平移的目的,其实这就是变换的基本思路。在整个的变换过程中,会涉及到3个关键的问题需要去解决,具体的问题如下所示:
- 问题1-应该如何确定这些参数?
- 问题2-图片的像素点可以当成坐标,在平移过程中怎么实现原图片与平移后图片的坐标映射关系?
- 问题3-参数调整过程中,权值一定不可能都是整数,那输出的坐标有可能是小数,但实际坐标都是整数的,如果实现小数与整数之间的连接?
3、Localisation net是如何实现参数的选取的?
3.1 如何实现平移变换
![]()
对于平移变换而言,比如从a11l−1a_{11}^{l-1}a11l−1平移到a21la_{21}^{l}a21l,得到的a21la_{21}^{l}a21l可以使用下式来表示:a21l=w2111la11l−1+w2112la12l−1+w2113la13l−1+⋯+w2133la33l−1a_{21}^{l}=w_{2111}^{l} a_{11}^{l-1}+w_{2112}^{l} a_{12}^{l-1}+w_{2113}^{l} a_{13}^{l-1}+\cdots+w_{2133}^{l} a_{33}^{l-1} a21l=w2111la11l−1+w2112la12l−1+w2113la13l−1+⋯+w2133la33l−1,当w2111l=1w_{2111}^{l}=1w2111l=1,其余均为0时,上式则可以简化为:a21l=1∗a11l11a_{21}^{l}=1 * a_{11}^{l_{1} 1} a21l=1∗a11l11,这样就完成了整个平移变换,其它的平移也可以使用类似的方法来获得。
3.2 如何实现缩放变换
如果想要放大一张图片,只需要在X轴和Y轴方向上同时X2就可以啦,这样就可以达到放大的效果。上述过程可以用下图中的矩阵表达式来表示。缩小图片的原理和放大图片的原理很相似,具体的实现细节请看下图。
![]()
3.3 如何实现旋转变换
一个圆圈的角度是360度,我们可以通过控制水平和竖直两个方向来实现旋转。
![]()
由点A旋转θ度角,到达点B.得到下式:x′=Rcosαy′=Rsinα\begin{array}{l}{x^{\prime}=R \cos \alpha} \\ {y^{\prime}=R \sin \alpha}\end{array} x′=Rcosαy′=Rsinα 由A点可得下式:x=Rcos(α+θ)y=Rsin(α+θ)\begin{array}{l}{x=R \cos (\alpha+\theta)} \\ {y=R \sin (\alpha+\theta)}\end{array} x=Rcos(α+θ)y=Rsin(α+θ) 将上式展开可得:x=Rcosαcosθ−Rsinαsinθy=Rsinαcosθ+Rcosαsinθ\begin{array}{l}{x=R \cos \alpha \cos \theta-R \sin \alpha \sin \theta} \\ {y=R \sin \alpha \cos \theta+R \cos \alpha \sin \theta}\end{array} x=Rcosαcosθ−Rsinαsinθy=Rsinαcosθ+Rcosαsinθ 把未知数α替换掉可得下式:x=x′cosθ−y′sinθy=y′cosθ+x′sinθ\begin{aligned} x &=x^{\prime} \cos \theta-y^{\prime} \sin \theta \\ y &=y^{\prime} \cos \theta+x^{\prime} \sin \theta \end{aligned} xy=x′cosθ−y′sinθ=y′cosθ+x′sinθ 总而言之,我们可以简单的理解为cosθ,sinθ就是控制这样的方向的,把它当成权值参数,写成矩阵形式,就完成了旋转操作。
![]()
3.4 如何实现裁剪变换
剪切变换相当于将图片沿x和y两个方向拉伸,且x方向拉伸长度与y有关,y方向拉伸长度与x有关,用矩阵形式表示前切变换如下:
![]()
3.5 总结
通过上面的分析,我们发现所有的这些操作,只需要六个参数[2X3]就可以实现各种变换功能啦,所以我们可以把feature map U作为输入,过连续若干层计算(如卷积、FC等),回归出参数θ,在我们的例子中就是一个[2,3]大小的6维仿射变换参数,用于下一步计算。
4、Grid generator如何实现像素点坐标的对应关系?
4.1 为什么会有坐标的问题?
由上面的公式,我们可以发现,无论如何做旋转,缩放,平移,只用到六个参数就可以了,具体如下图所示:
![]()
缩放的本质,其实就是在原样本上面进行采样,获得对应的像素点,通俗点说,就是输出的图片(i,j)的位置上,要对应输入图片的哪个位置?
![]()
如图所示旋转缩放操作,我们把像素点看成是坐标中的一个小方格,输入的图片U∈RHxWxCU \in R^{H x W x C}U∈RHxWxC可以是一张图片,或者feature map,其中H表示高,W表示宽,C表示颜色通道。经过变换Tθ(G)T_{\theta}(G)Tθ(G),θ是上一个部分(Localisation net)生成的参数,生成了图片V∈RH′xW′xCV \in R^{H^{\prime} x W^{\prime} x C}V∈RH′xW′xC,它的像素相当于被贴在了图片的固定位置上,用G=GiG=G_{i}G=Gi表示,像素点的位置可以表示为Gi={xit,yit}G_{i}=\left\{x_{i}^{t}, y_{i}^{t}\right\}Gi={xit,yit},这就是我们在这一阶段要确定的坐标。
4.2 仿射变换关系
![]()
上图展示的是一个坐标转换变换关系:其中(xit,yit)\left(x_{i}^{t}, y_{i}^{t}\right)(xit,yit)表示的是输出目标图片的坐标,(xis,yis)\left(x_{i}^{s}, y_{i}^{s}\right)(xis,yis)表示原图片的坐标,AθA_{\theta}Aθ表示仿射关系。我们的仿射变换关系是:从目标图片------->原图片。作者在论文中写的比较模糊,比较满意的解释是坐标映射的作用,其实是让目标图片在原图片上采样,每次从原图片的不同坐标上采集像素到目标图片上,而且要把目标图片贴满,每次目标图片的坐标都要遍历一遍,是固定的,而采集的原图片的坐标是不固定的,因此用这样的映射。
![]()
如图所示,假设只有平移变换,这个过程就相当于一个拼图的过程,左图是一些像素点,右图是我们的目标,我们的目标是确定的,目标图的方框是确定的,图像也是确定的,这就是我们的目标,我们要从左边的小方块中拿一个小方块放在右边的空白方框上,因为一开始右边的方框是没有图的,只有坐标,为了确定拿过来的这个小方块应该放在哪里,我们需要遍历一遍右边这个方框的坐标,然后再决定应该放在哪个位置。所以每次从左边拿过来的方块是不固定的,而右边待填充的方框却是固定的,所以定义从目标图片------->原图片的坐标映射关系更加合理,且方便。
5、Sampler实现坐标求解的可微性
5.1 小数坐标问题的提出
我们可以假设一下我们的权值矩阵的参数是如下这几个数,x,y分别表示的是他们的下标,经过变换后,可以得到如下的变换关系。
![]()
前面举的例子中,权值都是整数,计算的结果也必定是整数,如果不是整数呢?
![]()
假如权值是小数,那得到的值也一定是小数,1.6,2.4,但是没有元素的下标索引是小数呀。那不然取最近吧,那就得到2,2了,也就是与a22la_{22}^{l}a22l对应了。
5.2 解决输出坐标为小数的问题
使用上面的四舍五入显然是不能进行梯度下降来回传梯度的。由于梯度下降是一步一步调整的,而且调整的数值都比较小,哪怕权值参数有小范围的变化,虽然最后的输出也会有小范围的变化,比如一步迭代后,结果有:1.6→1.64,2.4→2.38。但是即使有这样的改变,结果依然是a22l1→a22la_{22}^{l_{1}} \rightarrow a_{22}^{l}a22l1→a22l的对应关系没有一点变化,所以output依然没有变,我们没有办法微分了,也就是梯度依然为0呀,梯度为0就没有可学习的空间呀。所以我们需要做一个小小的调整。
仔细思考一下这个问题是什么造成的,我们发现其实在推导SVM的时候,我们也遇到过相同的问题,当时我们如果只是记录那些出界的点的个数,好像也是不能求梯度的,当时我们是用了hing loss,来计算一下出界点到边界的距离,来优化那个距离的,我们这里也类似,我们可以计算一下到输出[1.6,2.4]附近的主要元素,如下所示,计算一下输出的结果与他们的下标的距离,可得:
![]()
然后做如下更改:
![]()
他们对应的权值都是与结果对应的距离相关的,如果目标图片发生了小范围的变化,这个式子也是可以捕捉到这样的变化的,这样就能用梯度下降法来优化了。
5.3 Sampler的数学原理
论文作者对我们前面的过程给出了非常严密的证明过程,以下是我对论文的转述。每次变换,相当于从原图片(xis,yis)\left(x_{i}^{s}, y_{i}^{s}\right)(xis,yis)中,经过仿射变换,确定目标图片的像素点坐标(xit,yit)\left(x_{i}^{t}, y_{i}^{t}\right)(xit,yit)的过程,这个过程可以用公式表示为:
![]()
kernel k表示一种线性插值方法,比如双线性插值,更详细的请参考该链接,ϕx,ϕy\phi_{x}, \phi_{y}ϕx,ϕy表示插值函数的参数;UnmcU_{n m}^{c}Unmc表示位于颜色通道C中坐标为(n,m)的值。
如果使用双线性插值,则可以使用下式来表示:
![]()
为了允许反向传播回传损失,我们可以求对该函数求偏导:
![]()
对于yisy_{i}^{s}yis的偏导也类似,如果就能实现这一步的梯度计算,而对于=∂xis∂θ,∂yis∂θ=\frac{\partial x_{i}^{s}}{\partial \theta}, \frac{\partial y_{i}^{s}}{\partial \theta}=∂θ∂xis,∂θ∂yis的求解也很简单,所以整个过程按照Localisation net←Grid generator←Sampler的梯度回传就能走通了。
6、Spatial Transformer Networks(STN)
![]()
将这三个组块结合起来,就构成了完整STN网络结构了。这个网络可以加入到CNN的任意位置,而且相应的计算量也很少。将 spatial transformers 模块集成到 cnn 网络中,允许网络自动地学习如何进行 feature_map 的转变,从而有助于降低网络训练中整体的代价。定位网络中输出的值,指明了如何对每个训练数据进行转化。
7、STN 代码实现
STN结构示例如下所示:
class STN(nn.HybridBlock):##继承HybridBlock模块,可以方便的hybrid,将命令式编程转换为符号式提升性能但损失了一定的灵活性def __init__(self):super(STN, self).__init__()with self.name_scope():# 使用name_scope可以自动给每一层生成独一无二的名字方便读取特定层# Spatial transformer localization-network# loc 定义了两层卷积网络loc = self.localization = nn.HybridSequential() loc.add(nn.Conv2D(8, kernel_size=7))loc.add(nn.MaxPool2D(strides=2))loc.add(nn.Activation(activation='relu'))loc.add(nn.Conv2D(10, kernel_size=5))loc.add(nn.MaxPool2D(strides=2))loc.add(nn.Activation(activation='relu'))# 采用两层全连接层,回归出仿射变换所需的参数θ(6,) # Regressor for the 3 * 2 affine matrixfc_loc = self.fc_loc = nn.HybridSequential()fc_loc.add(nn.Dense(32,activation='relu'))# 将该层w初始化为全零,b初始化为[1,0,0,0,1,0]fc_loc.add(nn.Dense(3 * 2,weight_initializer='zeros'))# Spatial transformer network forward function# 使用hybrid_forward需要增加F参数,它会自动判定前向过程中调用nd还是sym def hybrid_forward(self,F, x): xs = self.localization(x)xs = xs.reshape((-1, 10 * 3 * 3))theta = self.fc_loc(xs)theta = theta.reshape((-1, 2*3))# MxNet 已经定义好了相应的产生网格和采样的函数接口grid = F.GridGenerator(data=theta, transform_type='affine',target_shape=(28,28),name='grid')x = F.BilinearSampler(data=x,grid=grid,name='sampler' )return x
主体网络代码如下所示:
class Net(nn.HybridBlock):def __init__(self):super(Net, self).__init__()# 对输入图片进行STN变换后送入一个简单的两层卷积,两层全连接网络with self.name_scope():self.model = nn.HybridSequential()self.model.add(STN())self.model.add(nn.Conv2D(10, kernel_size=5))self.model.add(nn.MaxPool2D())self.model.add(nn.Activation(activation='relu'))self.model.add(nn.Conv2D(20, kernel_size=5))self.model.add(nn.Dropout(.5))self.model.add(nn.MaxPool2D())self.model.add(nn.Activation(activation='relu'))self.model.add(nn.Flatten())self.model.add(nn.Dense(50))self.model.add(nn.Activation(activation='relu'))self.model.add(nn.Dropout(.5))self.model.add(nn.Dense(10))def hybrid_forward(self,F, x):for i,b in enumerate(self.model):x = b(x)return x
参考资料
[1] STN论文
[2] 参考博客1
[3] 参考博客2
注意事项
[1] 该博客转载自该博客;
[2] 由于个人能力有限,该博客可能存在很多的问题,希望大家能够提出改进意见。
[3] 如果您在阅读本博客时遇到不理解的地方,希望您可以联系我,我会及时的回复您,和您交流想法和意见,谢谢。
[4] 本人业余时间承接各种本科毕设设计和各种小项目,包括图像处理(数据挖掘、机器学习、深度学习等)、matlab仿真、python算法及仿真等,有需要的请加QQ:1575262785详聊,备注“项目”!!!
Spatial Transformer Networks(STN)详解相关推荐
- Deformable ConvNets--Part2: Spatial Transfomer Networks(STN)
转自:https://blog.csdn.net/u011974639/article/details/79681455 Deformable ConvNet简介 关于Deformable Convo ...
- 详细解读Spatial Transformer Networks(STN)-一篇文章让你完全理解STN了
Spatial Transformer Networks https://blog.jiangzhenyu.xyz/2018/10/06/Spatial-Transformer-Networks/ 2 ...
- Spatial Transformer Networks(STN)
详细解读Spatial Transformer Networks(STN)-一篇文章让你完全理解STN了_多元思考力-CSDN博客_stn
- 【论文学习】STN —— Spatial Transformer Networks
Paper:Spatial Transformer Networks 这是Google旗下 DeepMind 大作,最近学习人脸识别,这篇paper提出的STN网络可以代替align的操作,端到端的训 ...
- 注意力机制——Spatial Transformer Networks(STN)
Spatial Transformer Networks(STN)是一种空间注意力模型,可以通过学习对输入数据进行空间变换,从而增强网络的对图像变形.旋转等几何变换的鲁棒性.STN 可以在端到端的训练 ...
- 论文阅读:Spatial Transformer Networks
文章目录 1 概述 2 模型说明 2.1 Localisation Network 2.2 Parameterised Sampling Grid 3 模型效果 参考资料 1 概述 CNN的机理使得C ...
- 深度学习之图像分类(十九)-- Bottleneck Transformer(BoTNet)网络详解
深度学习之图像分类(十九)Bottleneck Transformer(BoTNet)网络详解 目录 深度学习之图像分类(十九)Bottleneck Transformer(BoTNet)网络详解 1 ...
- 空间转换网络(Spatial Transformer Networks)
空间转换网络(Spatial Transformer Networks) 普通的CNN能够显示的学习平移不变性,以及隐式的学习旋转不变性,但attention model 告诉我们,与其让网络隐式的学 ...
- Spatial Transformer Networks 论文解读
paper title:Spatial Transformer Networks paper link: https://arxiv.org/pdf/1506.02025.pdf oral or de ...
最新文章
- Android系统中设置TextView等的行间距
- weblogic服务器保存图片失败解决办法
- mybatis中的查询缓存
- ubuntu下安装phpredis的模块扩展
- Jquery实际应用,判断radio,selelct,checkbox是否选中及选中的值
- Devexpress GridView 提交焦点列
- Cesium:加载本地高程/地形数据
- java中的测试类_java中测试类的方法
- eeprom和编程器固件 k2_斐讯K2编程器刷breed换固件小白教程
- HTML 小型进销库存界面模板
- 2022CPA财务成本管理-企业管理专题Corporate Goverance【完结】
- Nginx网站服务与LNMP架构部署(详解)
- Java中的委托和继承(Delegation and Inheritance)
- 林深时见鹿,海蓝时见鲸
- 计算机教学研修心得英语,2020英语教师继续教育学习心得体会范文(精选4篇)...
- 12864LCD驱动ST7567
- 陈力:传智播客古代 珍宝币 泡泡龙游戏开发第十二讲:盒子的定位方式
- 读《浪潮之颠》的收获
- 密立根测油滴实验c语言测试,密立根油滴实验
- 杭州人才招聘会:高校毕业生就业招聘大会