azure 入门_Azure Databricks入门指南
azure 入门
This article serves as a complete guide to Azure Databricks for the beginners. Here, you will walk through the basics of Databricks in Azure, how to create it on the Azure portal and various components & internals related to it.
本文是面向初学者的Azure Databricks的完整指南。 在这里,您将了解Azure中Databricks的基础知识,如何在Azure门户上创建它以及与之相关的各种组件和内部组件。
Systems are working with massive amounts of data in petabytes or even more and it is still growing at an exponential rate. Big data is present everywhere around us and comes in from different sources like social media sites, sales, customer data, transactional data, etc. And I firmly believe, this data holds its value only if we can process it both interactively and faster.
系统正在处理PB级甚至更多的海量数据,并且仍在以指数级的速度增长。 大数据无处不在,并且来自不同的来源,例如社交媒体网站,销售,客户数据,交易数据等。我坚信,只有当我们能够交互且更快地进行处理时,这些数据才有价值。
Apache Spark is an open-source, fast cluster computing system and a highly popular framework for big data analysis. This framework processes the data in parallel that helps to boost the performance. It is written in Scala, a high-level language, and also supports APIs for Python, SQL, Java and R.
Apache Spark是一个开放源代码的快速集群计算系统,是用于大数据分析的非常流行的框架。 该框架并行处理数据,有助于提高性能。 它是用高级语言Scala编写的,并且还支持Python,SQL,Java和R的API。
Now the question is:
现在的问题是:
什么是Azure Databricks,它与Spark有何关系? (What is Azure Databricks and how is it related to Spark?)
Simply put, Databricks is the implementation of Apache Spark on Azure. With fully managed Spark clusters, it is used to process large workloads of data and also helps in data engineering, data exploring and also visualizing data using Machine learning.
简而言之,Databricks是Apache Spark在Azure上的实现。 借助完全托管的Spark集群,它可用于处理大型数据工作量,还有助于数据工程,数据探索以及使用机器学习对数据进行可视化。
While I was working on databricks, I find this analytic platform to be extremely developer-friendly and flexible with ease to use APIs like Python, R, etc. To explain this a little more, say you have created a data frame in Python, with Azure Databricks, you can load this data into a temporary view and can use Scala, R or SQL with a pointer referring to this temporary view. This allows you to code in multiple languages in the same notebook. This was just one of the cool features of it.
当我处理数据块时,我发现此分析平台对开发人员非常友好且灵活,并且易于使用Python,R等API。要对此进行更多说明,请说您已经使用Python创建了一个数据框架,在Azure Databricks中,您可以将该数据加载到临时视图中,并且可以将Scala,R或SQL与指向该临时视图的指针一起使用。 这使您可以在同一笔记本中以多种语言进行编码。 这只是它的酷功能之一。
为什么选择Azure Databricks? (Why Azure Databricks?)
Evidently, the adoption of Databricks is gaining importance and relevance in a big data world for a couple of reasons. Apart from multiple language support, this service allows us to integrate easily with many Azure services like Blob Storage, Data Lake Store, SQL Database and BI tools like Power BI, Tableau, etc. It is a great collaborative platform letting data professionals share clusters and workspaces, which leads to higher productivity.
显然,采用Databricks在大数据世界中正变得越来越重要和相关,原因有两个。 除了多语言支持之外,该服务还使我们可以轻松地与许多Azure服务集成,例如Blob存储,Data Lake Store,SQL数据库和BI工具(例如Power BI,Tableau等)。这是一个出色的协作平台,可让数据专业人员共享群集和工作空间,从而提高了生产率。
大纲 (Outline)
Before we get started digging Databricks in Azure, I would like to take a minute here to describe how this article series is going to be structured. I intend to cover the following aspects of Databricks in Azure in this series. Please note – this outline may vary here and there when I actually start writing on them.
在我们开始在Azure中挖掘Databricks之前,我想花一点时间来描述本系列文章的结构。 我打算在本系列中介绍Azure中Databricks的以下方面。 请注意–当我实际开始在其上书写时,此轮廓可能在此处和此处有所不同。
- How to access Azure Blob Storage from Azure Databricks 如何从Azure Databricks访问Azure Blob存储
- Processing and exploring data in Azure Databricks 在Azure Databricks中处理和浏览数据
- Connecting Azure SQL Databases with Azure Databricks 将Azure SQL数据库与Azure Databricks连接
- Load data into Azure SQL Data Warehouse using Azure Databricks 使用Azure Databricks将数据加载到Azure SQL数据仓库中
- Integrating Azure Databricks with Power BI 将Azure Databricks与Power BI集成
- Run an Azure Databricks Notebook in Azure Data Factory and many more… 在Azure数据工厂中运行Azure Databricks Notebook等
In this article, we will talk about the components of Databricks in Azure and will create a Databricks service in the Azure portal. Moving further, we will create a Spark cluster in this service, followed by the creation of a notebook in the Spark cluster.
在本文中,我们将讨论Azure中Databricks的组件,并将在Azure门户中创建Databricks服务。 更进一步,我们将在此服务中创建一个Spark集群,然后在Spark集群中创建一个笔记本。
The below screenshot is the diagram puts out by Microsoft to explain Databricks components on Azure:
下面的屏幕快照是Microsoft发布的用于解释Azure上的Databricks组件的图:
There are a few features worth to mention here:
这里有一些功能值得一提:
- Databricks Workspace – It offers an interactive workspace that enables data scientists, data engineers and businesses to collaborate and work closely together on notebooks and dashboards Databricks工作区 –它提供了一个交互式工作区,使数据科学家,数据工程师和企业可以在笔记本和仪表板上进行协作并紧密合作
- Databricks Runtime – Including Apache Spark, they are an additional set of components and updates that ensures improvements in terms of performance and security of big data workloads and analytics. These versions are released on a regular basis Databricks运行时 –包括Apache Spark,它们是一组额外的组件和更新,可确保在大数据工作负载和分析的性能和安全性方面进行改进。 这些版本会定期发布
- As mentioned earlier, it integrates deeply with other services like Azure services, Apache Kafka and Hadoop Storage and you can further publish the data into machine learning, stream analytics, Power BI, etc. 如前所述,它与Azure服务,Apache Kafka和Hadoop Storage等其他服务进行了深度集成,您可以将数据进一步发布到机器学习,流分析,Power BI等中。
- Since it is a fully managed service, various resources like storage, virtual network, etc. are deployed to a locked resource group. You can also deploy this service in your own virtual network. We are going to see this later in the article 由于这是一项完全托管的服务,因此会将各种资源(如存储,虚拟网络等)部署到锁定的资源组。 您也可以在自己的虚拟网络中部署此服务。 我们将在本文后面看到
- Databricks File System (DBFS) – This is an abstraction layer on top of object storage. This allows you to mount storage objects like Azure Blob Storage that lets you access data as if they were on the local file system. I will be demonstrating this in detail in my next article in this series Databricks文件系统(DBFS) –这是对象存储之上的抽象层。 这使您可以挂载Azure Blob存储之类的存储对象,使您可以像访问本地文件系统一样访问数据。 我将在本系列的下一篇文章中详细演示这一点。
Now that we have a theoretical understanding of Databricks and its features, let’s head over to the Azure portal and see it in action.
现在,我们对Databricks及其功能有了理论上的了解,让我们转到Azure门户,看看它的作用。
创建一个Azure Databricks服务 (Create an Azure Databricks service)
Like for any other resource on Azure, you would need an Azure subscription to create Databricks. In case you don’t have, you can go here to create one for free for yourself.
与Azure上的任何其他资源一样,您将需要Azure订阅才能创建Databricks。 如果没有,您可以到这里免费为自己创建一个。
Sign in to the Azure portal and click on Create a resource and type databricks in the search box:
登录到Azure门户 ,然后单击“ 创建资源” , 然后在搜索框中键入databricks :
Click on the Create button, as shown below:
单击创建按钮,如下所示:
You will be brought to the following screen. Provide the following information:
您将被带到以下屏幕。 提供以下信息:
- Subscription– Select your subscription 订阅–选择您的订阅
- Resource group – I am using the one I have already created (azsqlshackrg), you can create a new also for this 资源组–我正在使用已经创建的资源组(azsqlshackrg),您也可以为此创建一个新的资源组
- Workspace name – It is the name (azdatabricks) that you want to give for your databricks service 工作区名称–这是您要为databricks服务指定的名称(azdatabricks)
- Location – Select region where you want to deploy your databricks service, East US 位置–选择要在美国东部部署数据砖服务的区域
- here 此处。
Afterward, hit on the Review + Create button to review the values submitted and finally click on the Create button to create this service:
然后,单击“ 审阅+创建”按钮以查看提交的值,最后单击“ 创建”按钮以创建此服务:
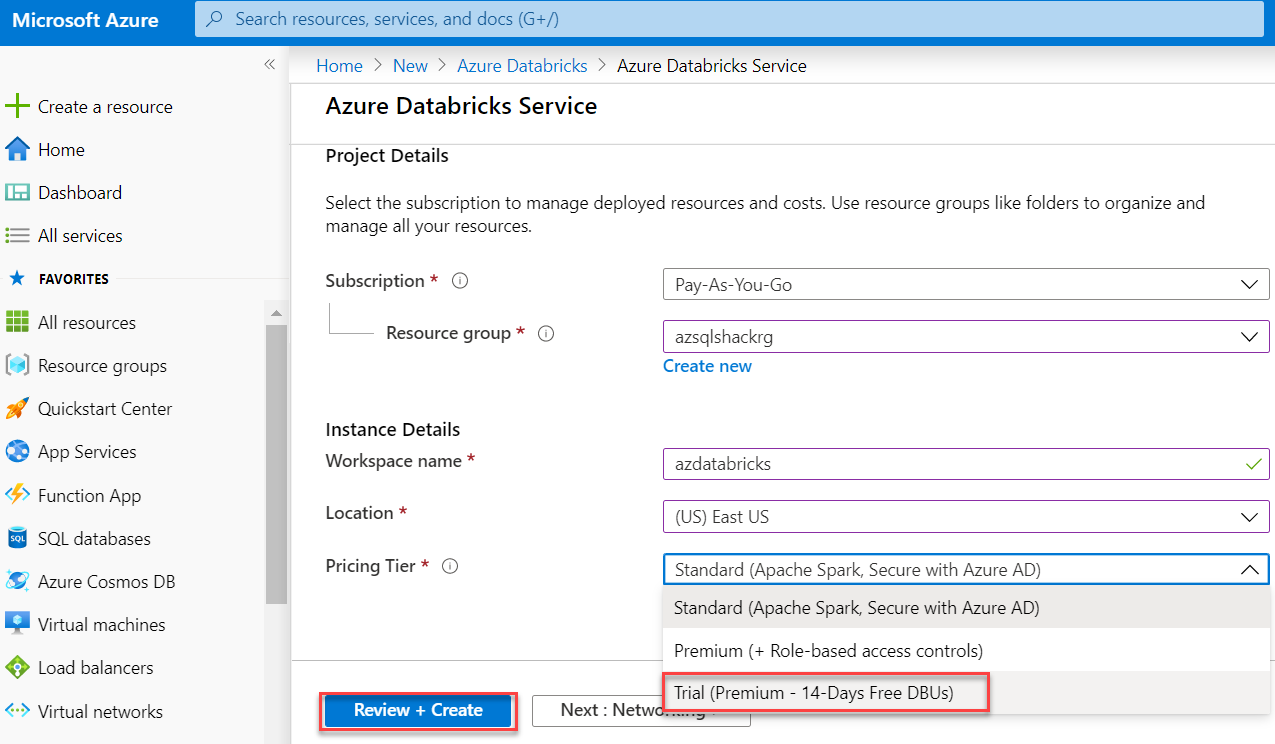
Once it is created, click on “Go to resource” option in the notification tab to open the service that you have just created:
创建完毕后,在通知选项卡中单击“转到资源”选项以打开您刚刚创建的服务:
You can see several specifics like URL, pricing details, etc. about your databricks service on the portal.
您可以在门户网站上看到有关您的数据块服务的一些细节,例如URL,定价详细信息等。
Click on Launch Workspace to open the Azure Databricks portal; this is where we will be creating a cluster:
单击启动工作区以打开Azure Databricks门户; 这是我们将要创建集群的地方:
You will be asked to sign-in again to launch Databricks Workspace.
系统将要求您再次登录以启动Databricks Workspace。
The following screenshot shows the Databricks home page on the Databricks portal. On the Workspace tab, you can create notebooks and manage your documents. The Data tab below lets you create tables and databases. You can also work with various data sources like Cassandra, Kafka, Azure Blob Storage, etc. Click on Clusters in the vertical list of options:
以下屏幕快照显示了Databricks门户上的Databricks主页。 在工作区选项卡上,您可以创建笔记本并管理文档。 下面的“ 数据”选项卡使您可以创建表和数据库。 您还可以使用各种数据源,例如Cassandra,Kafka,Azure Blob Storage等。在垂直选项列表中单击“ 群集 ”:
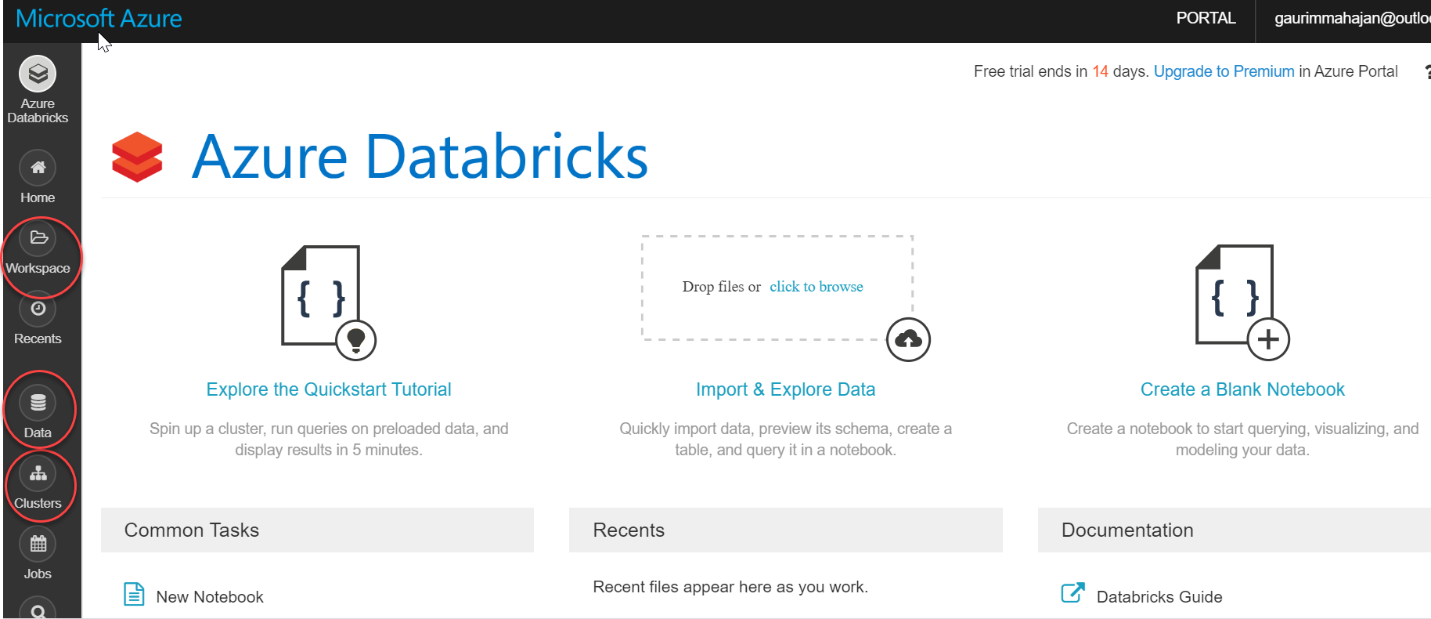
Create a Spark cluster in Azure DatabricksClusters in databricks on Azure are built in a fully managed Apache spark environment; you can auto-scale up or down based on business needs. Click on Create Cluster below on the Clusters page:
在Azure数据砖中创建Spark群集Azure上的数据砖中的群集在完全托管的Apache Spark环境中构建; 您可以根据业务需求自动放大或缩小。 单击“ 群集”页面下方的“ 创建群集” :
The following screenshot shows several configuration options to create a new databricks cluster. I am creating a cluster with 5.5 runtime (a data processing engine), Python 2 version and configured Standard_F4s series (which is good for low workloads). Since it is a demonstration, I am not enabling auto-scaling and also enabling the option to terminate this cluster if it is idle for 120 mins.
以下屏幕快照显示了用于创建新的数据块群集的几个配置选项。 我正在使用5.5运行时(数据处理引擎),Python 2版本和配置的Standard_F4s系列创建集群(这对于低工作负载很有用)。 由于这是一个演示,因此我不会启用自动缩放功能,也不会启用在此群集空闲120分钟时终止该群集的选项。
Finally, spin it up with a click on the Create Cluster button on the New Cluster page:
最后,单击“ 新建集群”页面上的“ 创建集群”按钮来旋转它:
Basically, you can configure your cluster as you like. Various cluster configurations, including Advanced Options, are described in great detail here on this Microsoft documentation page.
基本上,您可以根据需要配置集群。 各种集群配置,包括高级选项,中有详细描述这里这个微软文档页面上。
You can see the status of the cluster as Pending in the below screenshot. This will take some time to create a cluster:
您可以在下面的屏幕快照中看到群集的状态为Pending。 创建集群将花费一些时间:
Now our cluster is active and running:
现在我们的集群处于活动状态并正在运行:
By default, Databricks is a fully managed service, meaning resources associated with the cluster are deployed to a locked resource group, databricks-rg-azdatabricks-3… as shown below. For the Databricks Service, azdatabricks, VM, Disk and other network-related services are created:
默认情况下,Databricks是一项完全托管的服务,这意味着与群集关联的资源将被部署到锁定的资源组databricks-rg-azdatabricks-3 ……,如下所示。 对于Databricks服务, 创建了azdatabricks ,VM,磁盘和其他与网络相关的服务:
You can also notice that a dedicated Storage account is also deployed in the given Resource group:
您还可以注意到,专用的存储帐户也已部署在给定的资源组中:
Create a notebook in the Spark cluster
在Spark集群中创建笔记本
A notebook in the spark cluster is a web-based interface that lets you run code and visualizations using different languages.
spark集群中的笔记本是基于Web的界面,可让您使用不同的语言运行代码和可视化。
Once the cluster is up and running, you can create notebooks in it and also run Spark jobs. In the Workspace tab on the left vertical menu bar, click Create and select Notebook:
集群启动并运行后,您可以在其中创建笔记本,也可以运行Spark作业。 在左侧垂直菜单栏上的工作区选项卡中,单击创建 ,然后选择笔记本 :
In the Create Notebook dialog box, provide Notebook name, select language (Python, Scala, SQL, R), the cluster name and hit the Create button. This will create a notebook in the Spark cluster created above:
在“ 创建 笔记本”对话框中,提供笔记本名称,选择语言(Python,Scala,SQL,R),群集名称,然后单击“ 创建”按钮。 这将在上面创建的Spark集群中创建一个笔记本:
Since we will be exploring different facets of Databricks Notebooks in my upcoming articles, I will put a stop to this post here.
由于我们将在我即将发表的文章中探讨Databricks Notebook的不同方面,因此我将在这里停止发布。
结论 (Conclusion)
I tried explaining the basics of Azure Databricks in the most comprehensible way here. We also covered how you can create Databricks using Azure Portal, followed by creating a cluster and a notebook in it. The intent of this article is to help beginners understand the fundamentals of Databricks in Azure. Stay tuned to Azure articles to dig in more about this powerful tool.
我试图以最容易理解的方式解释Azure Databricks的基础。 我们还介绍了如何使用Azure Portal创建Databrick,然后在其中创建群集和笔记本。 本文的目的是帮助初学者了解Azure中Databricks的基础。 请继续关注Azure文章,以深入了解此强大工具。
翻译自: https://www.sqlshack.com/a-beginners-guide-to-azure-databricks/
azure 入门
azure 入门_Azure Databricks入门指南相关推荐
- azure 入门_Azure数据目录入门
azure 入门 This article talks about Azure Data Catalog and how data professionals can use it to locate ...
- Azure Event Hub完全入门指南
转需:https://www.cnblogs.com/mysunnytime/p/11634815.html Event Hub事件中心 本文的目的在于用最白的大白话,让你从"完全不懂&qu ...
- 无责任Windows Azure SDK .NET开发入门(二):使用Azure AD 进行身份验证
<編者按>本篇为系列文章,带领读者轻松进入Windows Azure SDK .NET开发平台.本文为第二篇,将教导读者使用Azure AD进行身分验证.也推荐读者阅读无责任Windows ...
- 手把手教你入门Git --- Git使用指南(Linux)
手把手教你入门Git - Git使用指南(Linux) 系统:ubuntu 18.04 LTS 本文所有git命令操作实验具有连续性,git小白完全可以从头到尾跟着本文所有给出的命令走一遍,就会对gi ...
- Flink入门——DataSet Api编程指南
简介: Flink入门--DataSet Api编程指南 Apache Flink 是一个兼顾高吞吐.低延迟.高性能的分布式处理框架.在实时计算崛起的今天,Flink正在飞速发展.由于性能的优势和兼顾 ...
- 蓝牙BLE(BlueTooth BLE)入门及爬坑指南
前言 最近比较忙,两三周没有更新简书了,公司正好在做蓝牙BLE的项目,本来觉得挺简单的东西从网上找了个框架,就咔咔地开始搞,搞完以后才发现里面还有不少坑呢,故而写一篇蓝牙BLE入门及爬坑指南,旨在帮助 ...
- Python从入门到精通 - 入门篇 (下)
上一讲回顾:Python从入门到精通 - 入门篇 (上) 接着上篇继续后面两个章节,函数和解析式. 4 函数 Python 里函数太重要了 (说的好像在别的语言中函数不重要似的).函数的通用好处就不用 ...
- python快速编程入门课后简答题答案-编程python入门 编程python入门课后习题
编程python入门 编程python入门课后习题 米粒妈咪课堂小编整理了填空.选择.判断等一些课后习题答案,供大家参考学习. 第一章 一.填空题 Python是一种面向对象的高级语言. Python ...
- 半小时入门MATLAB编程入门基础知识:
https://learnxinyminutes.com/docs/zh-cn/matlab-cn/ 半小时入门MATLAB编程入门基础知识: % 以百分号作为注释符 %{ 多行注释 可以 这样 表示 ...
最新文章
- 计算机专业大学排名_计算机专业大学排名公布:大连大学、辽宁师范大学冲进前一百...
- Python 技术篇 - 通过代码查看文本的编码类型实例演示,如何查看文件的编码类型,文件编码查看方法
- 汽车行驶姿态 -- 初识
- ios 跳转到某 app 的评价区域、由某应用跳转到其他应用
- 深入理解ajax系列第一篇——XHR对象
- java xslt 数据转换_如何将xslt结果转换为Java对象?
- python discuz搜索api_Django用内置方法实现简单搜索功能的方法
- 【链接攻击,差分攻击,去标识化代码实现】差分隐私代码实现系列(二)
- js使用base64 上传图片解决iOS手机竖屏拍摄图片发生旋转问题
- UIView layer 的对应关系
- zuul压力测试与调优
- $.each 中return问题
- matpower安装问题
- CRM 实施计划和准备的8个步骤!
- Python图像处理丨基于OpenCV和像素处理的图像灰度化处理
- CF#552div3题解
- 【数据结构】经典习题
- uniapp 自定义导航栏 动态显示或隐藏返回图标 以及buttons
- 【读论文】基于深度学习的铁路道岔转辙机故障诊断(3DESIGN)
- 埃尔米特函数的计算(C++)