学习黑马JVM的笔记
JVM详解
- 一、JVM介绍
- 1.什么是JVM?
- 2.有什么好处
- 3.学习路线
- 二、内存结构
- 1.程序计数器(Program Counter Registe)
- 1.定义
- 2.作用
- 3.特点
- 4.演示
- 2.虚拟机栈(Java Virtual Machine Stacks)
- 1.定义
- 2.演示
- 3.问题解析
- 4.栈内存溢出
- 5.线程运行诊断(linux中)
- 3.本地方法栈
- 4.堆(Heap)
- 1.定义
- 2.特点
- 3.堆内存溢出
- 4.堆内存诊断
- 1.jps工具
- 2.jmap工具
- 3.jconsole工具
- 4.演示
- 1.jps
- 2.jmap
- 3.jconsole
- 4.jvisualvm 也是一个可视化工具,功能更加强大
- 5.方法区
- 1.定义
- 2.特点
- 3.组成
- 4.方法区内存溢出
- 1.8以前导致永久代内存溢出
- 1.8以后导致元空间内存溢出
- 5.运行时常量池
- 6.StringTable(串池)
- 1.StringTable特性
- 2.StringTable位置
- 3.StringTable垃圾回收
- 4.StringTable性能调优
- 6.直接内存
- 1.定义
- 2.ByteBuffer
- 3.直接内存内存溢出
- 4.直接内存释放原理
- 5.分配和回收原理
- 6.禁用显示回收对直接内存的影响
- 三、垃圾回收
- 1.如何判断对象可以回收
- 1.引用计数法
- 1.定义
- 2.弊端
- 2.可达性分析算法(java虚拟机采用的方法)
- 1.定义
- 2.哪些对象可以作为GC Root?
- 3.如何查看GC Root对象
- 3.五种引用
- 1.强引用:
- 2.软引用:
- 3.弱引用
- 4.虚引用:
- 5.终结器引用:
- 2.垃圾回收算法
- 1.标记清除算法
- 2.标记整理算法
- 3.复制算法
- 3.分代回收
- 3.1相关VM参数
- 4.垃圾回收器
- 1.相关概念
- 1.并行收集
- 2.并发收集
- 3.吞吐量
- 2.串行回收器
- 1.特点
- 2.Serial收集器
- 3.ParNew 收集器
- 4.Serial Old 收集器
- 3.吞吐量优先
- 1.Parallel Scavenge 收集器
- 2.**Parallel Old 收集器**
- 4.响应时间优先
- 1.CMS 收集器
- 5.G1
- 1.定义
- 2.使用场景
- 3.相关JVM参数
- 4.G1垃圾回收阶段
- 1.Young Collection(新生代收集)
- 2.Young Collection+ Concurrent Mark(新生代收集+并发标记)
- 3.Mixed Collection(混合收集)
- 5.Full GC
- 6.Young Collection 跨代引用
- 7.Remark(重新标记)
- 8.JDK 8u20 字符串去重
- 9.JDK 8u40 并发标记类卸载
- 10.JDK 8u60 回收巨型对象
- 11.JDK 9并发标记起始时间的调整
- 5.垃圾回收调优
- 5.GC 调优
- 1.调优领域
- 2.确定目标
- 3.最快的GC是不发生GC
- 4.新生代调优
- 5.幸存区调优
- 6.老年代调优
- 四、类加载与字节码技术
- 1.类文件结构
- 1.魔数
- 2.版本
- 3.常量池
- 4.访问标识与继承信息
- 5.Field信息
- 6.Method信息
- 7 附加属性
- 2.字节码指令
- 1.入门
- 2 javap 工具
- 3.图解方法执行流程
- 1.代码
- 2.编译后的字节码文件
- 3.**常量池载入运行时常量池**
- 4.**方法字节码载入方法区**
- 5.main 线程开始运行,分配栈帧内存
- 4.通过字节码指令来分析问题
- 5.构造方法
- 1.cinit()V
- 2.init()V
- 6.方法调用
- 7.多态原理
- 8.异常处理
- try-catch
- 多个single-catch
- finally
- finally中的return
- 被吞掉的异常
- finally不带return
- 3.语法糖 编译器处理
- 1.默认构造函数
- 2.自动拆装箱
- 3.泛型集合取值
- 4.可变参数
- 5.foreach
- 6.switch字符串
- 7.switch枚举
- 8.枚举类
- 9.匿名内部类
- 4.类加载阶段
- 1.加载
- 2.链接
- 1.验证
- 2.准备
- 3.解析
- 3.初始化
- 1.发生时机
- 2.以下情况不会初始化
- 5.类加载器
- 1.基本介绍
- 2.启动类加载器
- 3.扩展类加载器
- 4.应用程序类加载器
- 5.双亲委派模式
- 概念
- 6.线程上下文类加载器
- 7.自定义类加载器
- 1.使用场景
- 2.步骤
- 3.案例
- 8.破坏双亲委派模式
- 6.运行期优化
- 1.即时编译
- 1.分层编译
- 2.既时编译器(JIT)与解释器的区别
- 3.逃逸分析
- 4.方法内联
- 1.**内联函数**
- **2.JVM内联函数**
- 5.字段优化
- 2.反射优化
- 五、内存模型
- 1.JAVA内存模型(JMM)
- 2.原子性
- 1.问题提出:结果不一定为0
- 2.问题分析
- 3.解决方法
- 3.可见性
- 1.问题提出:退不出的循环
- 2.问题分析
- 3.解决方法
- 4.有序性
- 1.问题提出:诡异的结果?
- 2.问题分析
- 3.解决方法
- 4.有序性理解
- 指令重排
- 5.double-checked locking 模式实现单例
- 5.happens-before
- 6.CAS与原子类
- 1.CAS
- 2.乐观锁与悲观锁
- 3.原子操作类
- 7.synchronized优化
- 1.轻量级锁
- 2.膨胀锁
- 3.重量锁
- 4.偏向锁
- 5.其他优化
- 1.减少上锁的时间
- 2.减少锁的粒度
- 3.锁粗化
- 4.锁消除
- 5.读写分离
一、JVM介绍
1.什么是JVM?
JVM(Java Virtual Machine) :java程序的运行环境(Java 二进制字节码的运行环境)
2.有什么好处
1.一次编写,到处运行
2.自动内存管理,垃圾回收功能
JVM是一套规范
3.学习路线
JVM内存结构
垃圾回收
类加载与字节码技术
内存模型
![]()
二、内存结构
1.程序计数器(Program Counter Registe)
1.定义
Program Counter Register 程序计数器(寄存器)
2.作用
- 记住下一条jvm指令的执行地址
3.特点
- 线程是私有的
- 不会存在内存溢出(唯一不会出现溢出的区)
4.演示
1.记住下一条jvm指令的执行地址
Java源代码经过编译成为二进制字节码(JVM指令),二进制字节码经过解释器翻译为机器码,机器码交给CPU执行;
程序计数器 (通过寄存器来实现) 在解释器执行时将下一条指令地址记住,解释器下次就会根据程序计数器中指令地址区执行下一条指令。
![]()
2.线程是私有的
有多个线程,每个线程会有一个时间片,在线程1执行的时候会执行线程1的字节码,时间片用完会停止执行给其他线程使用。每个线程都有自己的程序寄存器。![]()
2.虚拟机栈(Java Virtual Machine Stacks)
1.定义
Java Virtual Machine Stacks (Java 虚拟机栈 )
- 每个线程运行时需要的内存,称为虚拟机栈
- 每个栈由多个栈帧(Frame)组成,对应着每次方法调用时所占用的内存
- 每个线程只能有一个活动栈帧(正在运行的方法),对应着当前正在执行的那个方法
2.演示
每个方法运行时需要的内存就是一个栈帧
![]()
3.问题解析
1,垃圾回收是否涉及栈内存?
答:没有涉及,栈帧在运行完方法是将方法弹出栈,被自动回收掉,根本不需要垃圾回收。
2,栈内存是越大越好吗?
答:不是,栈内存越大,会让线程数变小,因为物理内存是一定的。
3.方法内的局部变量是否线程安全?
答:如果方法内局部变量没有逃离方法的作用范围,它是线程安全的。
如果是局部变量引用了对象,并逃离方法的作用范围,需要考虑线程安全。(传入对象且返回对象需要考虑线程安全)
4.栈内存溢出
- 栈帧过多导致栈内存溢出
- 栈帧过大导致栈内存溢出
5.线程运行诊断(linux中)
定位
- 用 top 定位那个进程对CPU的占用过高
- ps H -eo pid,tid,%cpu | grep 进程id (用ps命令进一步定位是哪个线程引起的cpu占用过高)
- jstack 进程id
- 可以根据线程id找到有问题的线程,进一步定位到问题代码的行号
3.本地方法栈
本地方法接口:不是由Java编写的方法
调用本地方法时就是使用的本地方法栈。
native method
![]()
程序计数器和栈都是线程私有的
4.堆(Heap)
1.定义
Heap 堆
- 通过new 关键字,创建对象都会使用堆内存
2.特点
- 他是线程共享的,堆中对象都需要考虑线程安全的问题
- 有垃圾回收机制
3.堆内存溢出
对象内的内存满了,就会溢出。就像一直在一个ArrayList中一致添加数据就会导致堆内存溢出,下列代码就会导致堆内存溢出
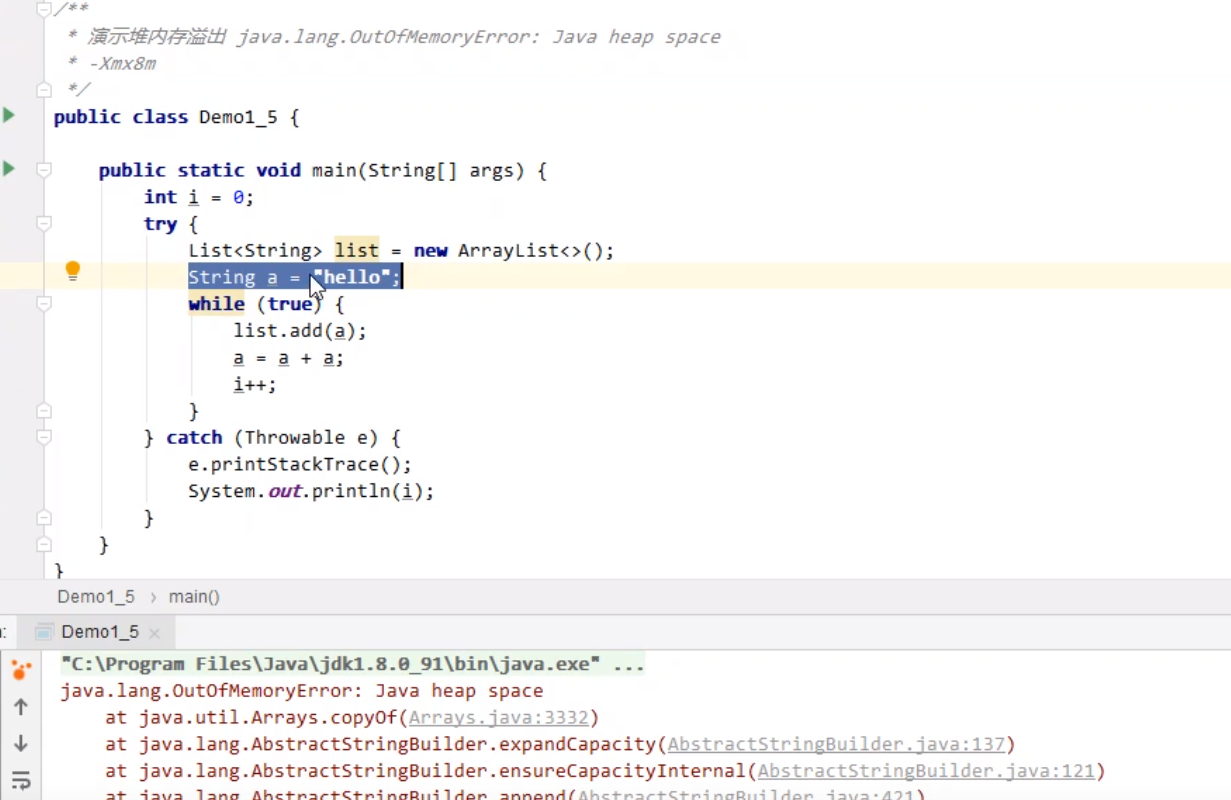
4.堆内存诊断
windos中
1.jps工具
- 查看当前系统中有哪些Java进程
- 列出所有正在运行的java进程,其中jps命令也是一个java程序,前面的数字就是对应的进程id。
2.jmap工具
- 查看堆内存占用情况 jmap -heap 进程号
3.jconsole工具
- 图形界面的,多功能的监测工具,可以连续监测
4.演示
1.jps
![]()
2.jmap
jmap -heap 进程号
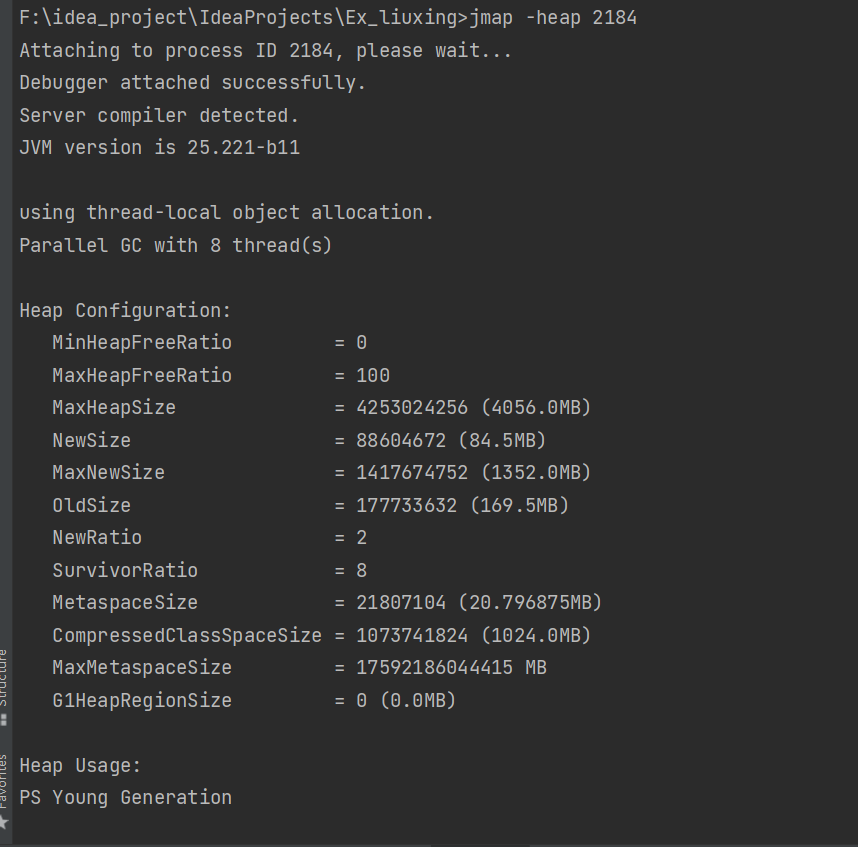
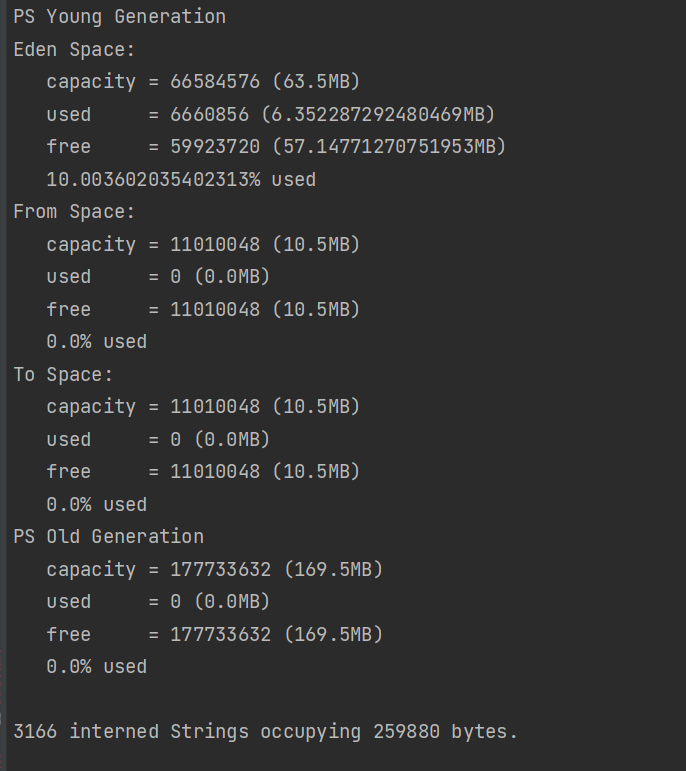
3.jconsole
![]()
4.jvisualvm 也是一个可视化工具,功能更加强大
![]()
5.方法区
1.定义
Method Area 方法区
2.特点
线程共享的区域
启动时创建
存储跟类结构相关的信息,属性、方法、构造方法
3.组成
1.6版本:PermGen 永久代(实现)
1.7版本及以后:Metaspace 元空间(实现)
永久代:字符串常量池在方法区中
方法区在jvm内存中
元空间:字符串常量池在堆中
方法区在本地内存
![]()
4.方法区内存溢出
- 1.8以前会导致永久代内存溢出
演示永久代内存溢出java. lang. OutOfMemoryError: PermGen space
-XX:MaxPermSize=8m
- 1.8之后会导致元空间内存溢出
演示元空间内存溢出java. lang . OutOfMemoryError: Metaspace
-XX:MaxMetaspaceSize=8m
1.8以前导致永久代内存溢出
![]()
1.8以后导致元空间内存溢出
![]()
可能溢出场景:spring、mybatis
5.运行时常量池
- 常量池:就是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量等信息
- 运行时常量池:常量池是*.class文件中的,当该类被加载,他的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址
![]()
二进制字节码(类基本信息,常量池,类方法定,包含了虚拟机指令)
![]()
![]()
6.StringTable(串池)
程序运行时会将常量池中的字符串放入StringTable(串池)
字符串在java程序中被大量使用,为了避免每次都创建相同的字符串对象及内存分配,JVM内部对字符串对象的创建做了一定的优化(一组指针指向Heap中的String对象的内存地址)。
1.7版本之前StringTable放在方法区中,1.7之后放在堆中。原因:方法区的内存空间太小。
重点:下面判断
![]()
结果输出为false。s4是一个String对象,底层会用到StringBuilder的tostring方法创建对象。

结果为true
1.StringTable特性
- 常量池中的字符串仅是符号, 在被用到时才会转化为对象
- 利用串池的机制,避免创建重复的字符串对象
- 字符串变量拼接的原理是StringBuilder(1.8)
- 字符串常量拼接的原理是编译期优化(编译时会先去串池中查看是否有这个这个字符串对象,有的话就不用创建)
- 使用intern方法,主动将串池中还没有的字符串对象放入串池
- 1.8 将字符串对象尝试放入串池,如果有则不会放入,如果没有则放入串池,会把串池的对象返回。
- 注意:此时如果调用intern方法成功,堆内存与串池中的字符串对象是同一个对象;如果失败,则不是同一个对象
- 1.6 将字符串对象尝试放入串池,如果有则不会放入,如果没有则会把此对象复制一份,放入串池,会把串池中的对象返回。
- 注意:此时无论调用intern方法成功与否,串池中的字符串对象和堆内存中的字符串对象都不是同一个对象
- 1.8 将字符串对象尝试放入串池,如果有则不会放入,如果没有则放入串池,会把串池的对象返回。
1.8
![]()
![]()
因为ab在最开始就创建,串池中已经有ab这个字符串,new String(“ab”) 在堆里是一个对象,用intern方法,发现字符串常量池中有ab,所以s与ab不相等。
1.6.例题:
![]()
最后false,x2是堆中的对象,x1是常量中cd,所以false.
2.StringTable位置
1.7版本之前StringTable放在方法区中,1.7之后放在堆中。原因:方法区的内存空间太小。
![]()
![]()
-Xmx10m
打印并查看串池信息:-XX:+PrintStringTableStatistics
3.StringTable垃圾回收
StringTable在内存紧张时,会发生垃圾回收
![]()
4.StringTable性能调优
调整
-XX:StringTableSize=桶个数
6.直接内存
1.定义
direct memory
不属于jvm管理
- 常见于nio操作时,用于数据缓冲区
- 分配回收成本高,但读写性能高
- 不受JVM内存回收管理
2.ByteBuffer
使用ByteBuffer比使用io的性能更高。
![]()
在没有用ByteBuffer时,系统的内部操作时下面这样的
![]()
使用了直接内存后,系统内部操作如下图。不再需要经过系统缓存区传给java缓冲区,他们共同划出一块缓冲区,java代码和系统都可以直接访问,大大的提升了效率。少了缓冲区的复制操作。
![]()
3.直接内存内存溢出
![]()
4.直接内存释放原理
直接内存的回收不是通过JVM的垃圾回收来释放的,拿到Unsafe对象,然后调用去分配和调用内存
![]()
5.分配和回收原理
- 使用了Unsafe 对象完成直接内存的分配回收,并主动回收需要主动调用freeMemory方法
- ByteBuffer的实现类内部,使用了Cleaner (虚引用) 来监测ByteBuffer对象,一旦ByteBuffer对象被垃圾回收,那么就会由ReferenceHandler线程通过Cleaner的clean方法调用freeMemory来释放直接内存
6.禁用显示回收对直接内存的影响
-XX:+DisableExpIicitGC 显式的
使用上面命令后,代码中调用显式回收将没有作用
System.gc();
三、垃圾回收
1.如何判断对象可以回收
1.引用计数法
1.定义
只要对象被引用就+1,引用两次就+2,如果某个变量不在引用就-1,当对象引用计数为0的时候就会被垃圾回收
2.弊端
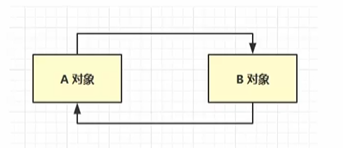 循环引用,A对象引用B对象,B对象引用计数+1,B对象引用A,A对象引用计数+1。当没有谁再引用他们,他们不能被垃圾回收,因为引用计数没有归零。python在早期垃圾回收用的引用计数法。
循环引用,A对象引用B对象,B对象引用计数+1,B对象引用A,A对象引用计数+1。当没有谁再引用他们,他们不能被垃圾回收,因为引用计数没有归零。python在早期垃圾回收用的引用计数法。
2.可达性分析算法(java虚拟机采用的方法)
1.定义
- java虚拟机中的垃圾回收器采用的是可达性分析算法
- 扫描堆中的对象,看是否能够沿着GC Root(根对象) 为起点的引用链找到该对象,找不到就可以进行垃圾回收
2.哪些对象可以作为GC Root?
//System Class
//Natice Stack(本地栈)
//锁(同步锁机制)
//Thread(活动线程)
a. java虚拟机栈中的引用的对象。
b.本地方法栈中的JNI(native方法)引用的对象
c.方法区中的类静态属性引用的对象。(一般指被static修饰的对象,加载类的时候就加载到内存中。)(static object)
d.方法区中的常量引用的对象。 (object)
3.如何查看GC Root对象
通过MAT工具(Eclipse的Memory Analyzer)
3.五种引用
![]()
1.强引用:
只有GC Root 都不引用该对象时,才会回收强引用对象。
2.软引用:
有用但非必须的引用
1.当GC Root 不在指向软引用对象时,且内存不足时,会回收软引用所引用的对象。
2.可以配合引用队列来释放软引用自身。
如上图 B对象不在引用A2对象且内存不足时,软引用所引用的A2对象会被回收。
使用:
public class Demo1 {public static void main(String[] args) {final int _4M = 4*1024*1024;//使用软引用对象 list和SoftReference是强引用,而SoftReference和byte数组则是软引用List<SoftReference<byte[]>> list = new ArrayList<>();SoftReference<byte[]> ref= new SoftReference<>(new byte[_4M]);}
}
软引用本身不会被清理,需要使用引用队列
public class Demo1 {public static void main(String[] args) {final int _4M = 4*1024*1024;//使用引用队列,用于移除引用为空的软引用对象ReferenceQueue<byte[]> queue = new ReferenceQueue<>();//使用软引用对象 list和SoftReference是强引用,而SoftReference和byte数组则是软引用List<SoftReference<byte[]>> list = new ArrayList<>();SoftReference<byte[]> ref= new SoftReference<>(new byte[_4M],queue);//遍历引用队列,如果有元素,则移除Reference<? extends byte[]> poll = queue.poll();while(poll != null) {//引用队列不为空,则从集合中移除该元素list.remove(poll);//移动到引用队列中的下一个元素poll = queue.poll();}}
}
3.弱引用
1.当GC Root 不再指向弱引用对象时,不管内存是否不足,会回收弱引用所引用的对象。
2.可以配合引用队列来释放弱引用自身。
弱引用的使用和软引用类似,只是将 SoftReference 换为了 WeakReference
4.虚引用:
必须配合引用队列使用,主要配合 ByteBuffer 使用,当虚引用对象所引用的对象被回收以后,虚引用对象就会被放入引用队列中,由 Reference Handler 线程调用虚引用相关方法释放直接内存。
- 虚引用的一个体现是释放直接内存所分配的内存,当被引用对象ByteBuffer被垃圾回收以后,虚引用对象Cleaner就会被放入引用队列中,然后调用Cleaner的clean方法来释放直接内存
- 如上图,B对象不再引用ByteBuffer对象,ByteBuffer就会被回收。但是直接内存中的内存还未被回收。这时需要将虚引用对象Cleaner放入引用队列中,然后调用它的clean方法来释放直接内存
5.终结器引用:
无需手动编码,在其内部配合引用队列使用,
在垃圾回收时,终结器引用入队(被引用对象 暂时没有被回收),再由 Finalizer 线程通过终结器引用找到被引用对象并调用它的 finalize 方法,第二次 GC 时才能回收被引用对象
- 当某个对象不再被其他的对象所引用时,会先将终结器引用对象放入引用队列中,然后根据终结器引用对象找到被引用的对象,然后调用被引用对象的finalize方法。调用以后,该对象再第二次GC就可以被垃圾回收了
- 如上图,B对象不再引用A4对象。这是终结器引用对象就会被放入引用队列中,引用队列会根据它,找到它所引用的对象。然后调用被引用对象的finalize方法。调用以后,该对象就可以被垃圾回收了
引用队列:软引用和弱引用可以配合引用队列
2.垃圾回收算法
1.标记清除算法
![]()
定义:在执行垃圾回收时,先标记完引用对象,然后垃圾收集器根据标识清除没有被标记的对象
优点:速度快
缺点:容易产生大量的内存碎片,如上图,清理没有引用的对象后,会存在内存的空间浪费。
2.标记整理算法
![]()
定义:在执行垃圾回收时,先标记完引用的对象,然后清除没有被引用的对象,最后整理剩余的空间,避免因内存碎片导致的问题。
优点:不会存在内存碎片
缺点:速度慢,因为整理内存是为了避免内存浪费,所以整理需要消耗一定的时间,导致效率较低。
时间换取空间
3.复制算法
![]()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BwuRDFiy-1666189640764)(C:\Users\刘星\AppData\Roaming\Typora\typora-user-images\image-20210809153023339.png)]
定义:将内存分为两个等大小的区域,FROM和TO。先将FROM中被GC Root引用的对象进行标记,将存活的对象从FROM放入TO中,再回收FROM区域中没有被引用的对象。然后交换FROM和TO。
优点:这样避免的内存碎片的问题。
缺点:但需要双倍的内存空间。
空间换取时间
3.分代回收
![]()
![]() 回收流程
回收流程
- 对象首先分配在伊甸园区域
- 新生代伊甸园空间不足时,就会触发minor gc,伊甸园和幸存区From中存活的的对象复制到幸存区To中,存活的对象年龄加1并交换幸存区from和幸存区to。
- minor gc会引发stop the world ,暂停其他用户的线程,等垃圾回收结束后,用户线程才恢复。
- 当对象寿命超过阈值时,会从新生代注入到老年代,最大寿命是15(4bit)。
- 当老年代空间不足,会先尝试触发minor gc, 如果空间仍不足,那么就触发full gc,stop the world 的时间更长。
3.1相关VM参数
堆初始大小 :-Xms
堆最大大小 -Xmx 或 -XX:MaxHeapSize=size
新生代大小: -Xmn 或 (-XX:NewSize=size + -XX:MaxNewSize=size )
幸存区比例(动态): -XX:InitialSurvivorRatio=ratio 和 -XX:+UseAdaptiveSizePolicy
幸存区比例 :-XX:SurvivorRatio=ratio
晋升阈值: -XX:MaxTenuringThreshold=threshold
晋升详情: -XX:+PrintTenuringDistribution
GC详情: -XX:+PrintGCDetails -verbose:gc
FullGC 前 MinorGC: -XX:+ScavengeBeforeFullGC
4.垃圾回收器
1.相关概念
并行执行的线程之间不存在切换;并发操作系统会根据任务调度系统给线程分配线程的 CPU 执行时间,线程的执行会进行切换。
1.并行收集
并行:多个事情同一时刻进行
在同一时刻,有多个程序在多个处理器上运行(每个处理器运行一个程序)。
并行收集:指多条垃圾收集线程并行工作,但此时用户线程仍处于等待状态。
2.并发收集
并发: 指在某时刻只有一个事件在发生,某个时间段内由于 CPU 交替执行,可以发生多个事件。 在同一cpu上同时运行多个程序。
指用户线程与垃圾收集线程同时工作(不一定是并行的可能会交替执行)。用户程序在继续执行,而垃圾收集程序在另一个CPU上。
3.吞吐量
即CPU用于运行用户代码的时间与CPU总消耗时间的比值(吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间))。例如:虚拟机共运行100分组,垃圾收集器花掉1分钟,那么吞吐量就是99%。
2.串行回收器
-XX:+UseSerialGC = Serial + SerialOld
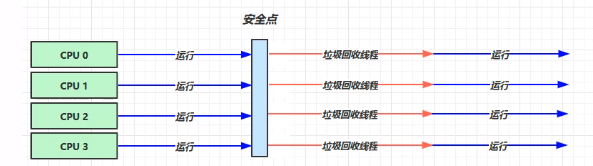
![]()
1.特点
- 单线程
- 内存较小,个人电脑(CPU核数较少)
- 安全点:让其他线程都在这个点停下来,以免垃圾回收时移动对象地址,使得其他线程找不到被移动的对象
- 因为是串行的,所以只有一个垃圾回收线程。且在该线程执行回收工作时,其他线程进入阻塞状态。
2.Serial收集器
Serial收集器是最基本的、发展历史最悠久的收集器。
特点:单线程、简单高效(与其他收集器的单线程相比),采用复制算法。对于限定单个CPU的环境来说,Serial收集器由于没有线程交互的开销,专心做垃圾收集自然可以获得最高的单线程收集效率。收集器进行垃圾回收时,必须暂停其他所有的工作线程,直到它结束(Stop The World)
3.ParNew 收集器
ParNew收集器其实就是Serial收集器的多线程版本。
特点:多线程、ParNew收集器默认开启的收集线程数与CPU的数量相同,采用复制算法,在CPU非常多的环境中,可以使用-XX:ParallelGCThreads参数来限制垃圾收集的线程数。和Serial收集器一样存在Stop The World问题
4.Serial Old 收集器
Serial Old是Serial收集器的老年代版本
特点:同样是单线程收集器,采用标记-整理算法
3.吞吐量优先
-XX:+UseParallelGC ~ -XX:+UseParallelOldGC
-XX:GCTimeRatio=ratio
-XX:MaxGCPauseMillis=ms
-XX:ParallelGCThreads=n
- 多线程
- 堆内存较大,多核CPU
- 单位时间内,STW(stop the world,停掉其他所有工作线程)时间最短
- JDK1.8默认使用的垃圾回收器
1.Parallel Scavenge 收集器
与吞吐量关系密切,故也称为吞吐量优先收集器
特点:
属于新生代收集器,也是采用复制算法的收集器(用到了新生代的幸存区),又是并行的多线程收集器(与ParNew收集器类似)
该收集器的目标是达到一个可控制的吞吐量。还有一个值得关注的点是:GC自适应调节策略(与ParNew收集器最重要的一个区别)
GC自适应调节策略:
Parallel Scavenge收集器可设置-XX:+UseAdptiveSizePolicy参数。当开关打开时不需要手动指定新生代的大小(-Xmn)、Eden与Survivor区的比例(-XX:SurvivorRation)、晋升老年代的对象年龄(-XX:PretenureSizeThreshold)等,虚拟机会根据系统的运行状况收集性能监控信息,动态设置这些参数以提供最优的停顿时间和最高的吞吐量,这种调节方式称为GC的自适应调节策略。
Parallel Scavenge收集器使用两个参数控制吞吐量:
- XX:MaxGCPauseMillis 控制最大的垃圾收集停顿时间
- XX:GCRatio 直接设置吞吐量的大小
2.Parallel Old 收集器
是Parallel Scavenge收集器的老年代版本
特点:多线程,采用标记-整理算法(老年代没有幸存区
4.响应时间优先
-XX:+UseConcMarkSweepGC ~ -XX:+UseParNewGC ~ SerialOld
-XX:ParallelGCThreads=n ~ -XX:ConcGCThreads=threads
-XX:CMSInitiatingOccupancyFraction=percent
-XX:+CMSScavengeBeforeRemark
![]()
- 多线程
- 堆内存较大,多核CPU
- 尽可能让单次STW时间变短(尽量不影响其他线程运行)
1.CMS 收集器
Concurrent Mark Sweep,一种以获取最短回收停顿时间为目标的老年代收集器
特点:基于标记-清除算法实现。并发收集、低停顿,但是会产生内存碎片
应用场景:适用于注重服务的响应速度,希望系统停顿时间最短,给用户带来更好的体验等场景下。如web程序、b/s服务。
CMS收集器的运行过程分为下列4步:
初始标记:标记GC Roots对象。速度很快但是仍存在Stop The World问题
并发标记:进行GC Roots Tracing 的过程,找出GC Roots对象所关联的对象且用户线程可并发执行
重新标记:为了修正并发标记期间因用户程序继续运行而导致标记产生变动的那一部分对象的标记记录(可达对象变不可达)。仍然存在Stop The World问题
并发清除:对没有标记的对象进行清除回收
CMS收集器的内存回收过程是与用户线程一起并发执行的
5.G1
1.定义
Garbage First
- 2004年论文发布
- 2009 JDK 6u14体验
- 2012 JDK 7u4官方支持
- 2017 JDK 9 默认
2.使用场景
- 同时注重吞吐量(Throughput)和低延迟(Low latency),默认的暂停时间是200ms。
- 超大堆内存,会将堆划分为多个等大的Region。
- 整体上是标记 - 整理算法,两个Region(区域)之间是复制算法。
3.相关JVM参数
-XX:+UserG1GC
-XX:G1HeapRegionSize=size
-XX:MaxGCPauseMillis=time
第一个参数:开启G1
第二个参数:设置Region大小,必须设置成,1,2,4,8这样的大小
第三个参数:设置暂停时间ms
4.G1垃圾回收阶段
![]()
第一阶段对新生代进行收集(Young Collection),第二阶段对新生代的收集同时会执行并发标记(Young Collection+ Concurrent Mark) ,第三阶段对新生代、新生代幸存区和老年区进行混合收集(Mixed Collection),以此循环。
Garbage First 将堆划分大小相等的一个个区域,每个区域都可以作为新生代、幸存区和老年代。
E代表伊甸园区域
S代表幸存区
O代表老年代
1.Young Collection(新生代收集)
- 会STW(Stop The World),但相对于时间还是比较短的
![]()
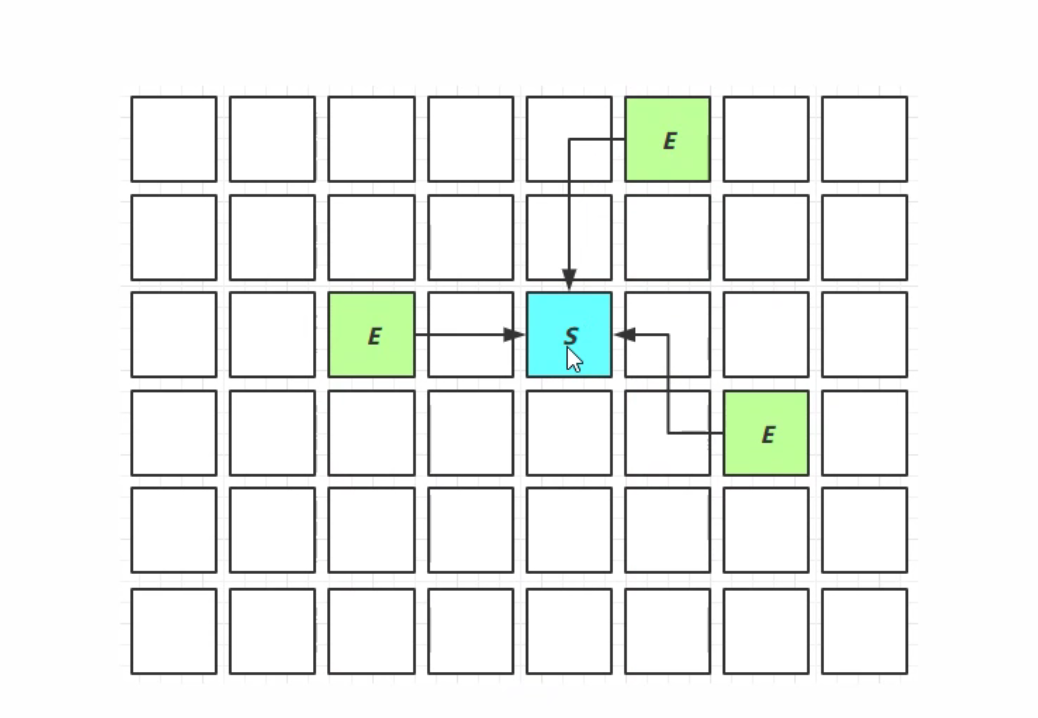
- 新生代垃圾回收会将幸存对象以复制算法复制到幸存区。
![]()
- 新生代垃圾回收会将幸存对象以复制算法复制到幸存区,幸存区存活的对象达到阈值后会以复制算法复制到老年代
2.Young Collection+ Concurrent Mark(新生代收集+并发标记)
初始标记:找到GC Root(根对象)
并发标记:和应用程序并发执行,针对区域内所有的存活对象进行标记。
在Young GC时会进行GC Root的**初始标记 **
老年代占用堆空间比例达到阈值时,进行并发标记(不会STW),由下面的JVM参数决定
-XX:InitiatingHeapOccupancyPercent=percent (默认45%)
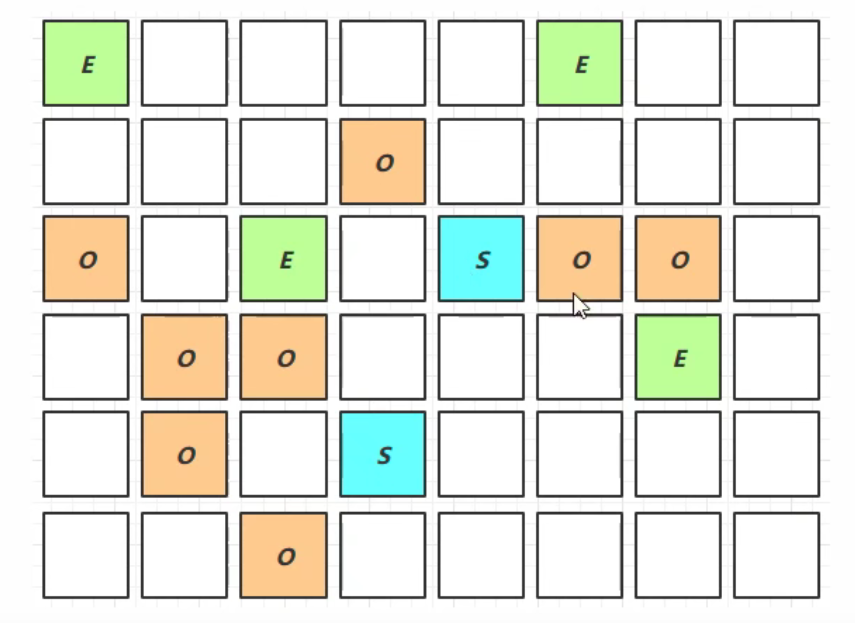 当o占到45%就进行并发标记了
当o占到45%就进行并发标记了
3.Mixed Collection(混合收集)
会对 E、S、O进行全面垃圾回收
最终标记:在并发标记的过程中,可能会漏掉一些对象,因为并发标记的同时,其他用户线程还在工作,产生一些垃圾,所以进行最终标记。清理没被标记的对象。
- 最终标记(Remark)会STW
- 拷贝存活(Evacuation)会STW
-XX:MaxGCPauseMillis=ms
![]()
过程:在进行混合回收时,新生代垃圾回收会将幸存对象以复制算法复制到幸存区,幸存区存活的对象达到阈值后会以复制算法复制到老年代,老年代中根据最大暂停时间有选择的进行回收,回收价值最高的,将老年代中存活下来的对象以复制算法重新赋值到一个新的老年代中。
5.Full GC
SerialGC
- 新生代内存不足发生的垃圾收集- minor gc
- 老年代内存不足发生的垃圾收集- full gc
ParallelGC
- 新生代内存不足发生的垃圾收集- minor gc
- 老年代内存不足发生的垃圾收集- full gc
CMS
- 新生代内存不足发生的垃圾收集- minor gc
- 老年代内存不足,并发失败后,进行串行收集 full gc
G1
- 新生代内存不足发生的垃圾收集- minor gc
- 老年代内存不足,当垃圾回收速度跟不上产生速度,退化为一个串行收集,开始Full GC
6.Young Collection 跨代引用
卡表与Remembered Set
- Remembered Set存在于E中,用于保存新生代对象对应的脏卡
- 脏卡: 老年代被划分为多个区域(一个区域512K),如果该
区域引用了新生代对象,则该区域被称为脏卡
- 脏卡: 老年代被划分为多个区域(一个区域512K),如果该
- Remembered Set存在于E中,用于保存新生代对象对应的脏卡
在引用变更时通过post-write barried + dirty card queue
concurrent refinement threads更新Remembered Set
新生代回收的跨代引用(老年代引用新生代)问题

在进行新生代回收时要找到GC Root根对象。有一部分GC Root对象是来自老年代,老年代存活的对象很多,如果遍历老年代找根对象效率非常低,采用卡表(Card Table)的技术,将老年代分成一个个Card,每个Card差不多512k, 老年代其中一个对象引用了新生代对象,那么就称这个Card为脏卡(dirty card)。
![]()
将来进行垃圾回收时不需要找整个老年代,只需要找脏卡区就行了
7.Remark(重新标记)
pre-write barrier+ satb_mark_queue
在垃圾回收时,收集器处理对象的过程中
黑色:已被处理,需要保留的
灰色:正在处理中的
白色:还未处理的
![]()
但是在并发标记过程中,有可能A被处理了以后未引用C,但该处理过程还未结束,在处理过程结束之前A引用了C,这时就会用到remark
过程如下:
- 之前C未被引用,这时A引用了C,就会给C加一个写屏障,写屏障的指令会被执行,将C放入一个队列当中,并将C变为处理中状态
- 在并发标记阶段结束以后,重新标记阶段会STW,然后将放在该队列中的对象重新处理,发现有强引用引用它,就会处理它
![]()
8.JDK 8u20 字符串去重
过程
- 将所有新分配的字符串(底层是char[])放入一个队列
- 当新生代回收时,G1并发检查是否有重复的字符串
- 如果字符串的值一样,就让他们引用同一个字符串对象
- 注意,其与String.intern的区别
- intern关注的是字符串对象
- 字符串去重关注的是char[]
- 在JVM内部,使用了不同的字符串标
优点与缺点
- 节省了大量内存
- 新生代回收时间略微增加,导致略微多占用CPU
9.JDK 8u40 并发标记类卸载
在并发标记阶段结束以后,就能知道哪些类不再被使用。如果一个类加载器的所有类都不在使用,则卸载它所加载的所有类
10.JDK 8u60 回收巨型对象
- 一个对象大于region的一半时,就称为巨型对象
- G1不会对巨型对象进行拷贝
- 回收时被优先考虑
- G1会跟踪老年代所有incoming引用,如果老年代incoming引用为0的巨型对象就可以在新生代垃圾回收时处理掉
![]()
11.JDK 9并发标记起始时间的调整
并发标记必须在堆空间占满前完成,否则退化为FullGC
JDK9之前需要使用-Xx: Initiat ingHeapOccupancyPercent
JDK9可以动态调整
-XX:InitiatingHeapoccupancyPercent 用来设置初始值
进行数据采样并动态调整
总会添加一个安全的空档空间
5.垃圾回收调优
5.GC 调优
查看虚拟机参数命令
"F:\JAVA\JDK8.0\bin\java" -XX:+PrintFlagsFinal -version | findstr "GC"
可以根据参数去查询具体的信息
1.调优领域
- 内存
- 锁竞争
- CPU占用
- IO
- GC
2.确定目标
低延迟/高吞吐量? 选择合适的GC
- CMS G1 ZGC
- ParallelGC
- Zing
3.最快的GC是不发生GC
首先排除减少因为自身编写的代码而引发的内存问题
- 查看Full GC前后的内存占用,考虑以下几个问题
- 数据是不是太多?
- 数据表示是否太臃肿
- 对象图
- 对象大小
- 是否存在内存泄漏
4.新生代调优
- 新生代的特点
- 所有的new操作分配内存都是非常廉价的
- TLAB
- 死亡对象回收零代价
- 大部分对象用过即死(朝生夕死)
- MInor GC 所用时间远小于Full GC
- 所有的new操作分配内存都是非常廉价的
- 新生代内存越大越好么?
- 不是
- 新生代内存太小:频繁触发Minor GC,会STW,会使得吞吐量下降
- 新生代内存太大:老年代内存占比有所降低,会更频繁地触发Full GC。而且触发Minor GC时,清理新生代所花费的时间会更长
- 新生代内存设置为内容纳[并发量*(请求-响应)]的数据为宜
- 不是
5.幸存区调优
- 幸存区需要能够保存 当前活跃对象+需要晋升的对象
- 晋升阈值配置得当,让长时间存活的对象尽快晋升
6.老年代调优
四、类加载与字节码技术
![]()
1.类文件结构
首先获得.class文件
方法:
javac X:.../XX.java
以下是字节码文件
0000000 ca fe ba be 00 00 00 34 00 23 0a 00 06 00 15 09
0000020 00 16 00 17 08 00 18 0a 00 19 00 1a 07 00 1b 07
0000040 00 1c 01 00 06 3c 69 6e 69 74 3e 01 00 03 28 29
0000060 56 01 00 04 43 6f 64 65 01 00 0f 4c 69 6e 65 4e
0000100 75 6d 62 65 72 54 61 62 6c 65 01 00 12 4c 6f 63
0000120 61 6c 56 61 72 69 61 62 6c 65 54 61 62 6c 65 01
0000140 00 04 74 68 69 73 01 00 1d 4c 63 6e 2f 69 74 63
0000160 61 73 74 2f 6a 76 6d 2f 74 35 2f 48 65 6c 6c 6f
0000200 57 6f 72 6c 64 3b 01 00 04 6d 61 69 6e 01 00 16
0000220 28 5b 4c 6a 61 76 61 2f 6c 61 6e 67 2f 53 74 72
0000240 69 6e 67 3b 29 56 01 00 04 61 72 67 73 01 00 13
0000260 5b 4c 6a 61 76 61 2f 6c 61 6e 67 2f 53 74 72 69
0000300 6e 67 3b 01 00 10 4d 65 74 68 6f 64 50 61 72 61
0000320 6d 65 74 65 72 73 01 00 0a 53 6f 75 72 63 65 46
0000340 69 6c 65 01 00 0f 48 65 6c 6c 6f 57 6f 72 6c 64
0000360 2e 6a 61 76 61 0c 00 07 00 08 07 00 1d 0c 00 1e
0000400 00 1f 01 00 0b 68 65 6c 6c 6f 20 77 6f 72 6c 64
0000420 07 00 20 0c 00 21 00 22 01 00 1b 63 6e 2f 69 74
0000440 63 61 73 74 2f 6a 76 6d 2f 74 35 2f 48 65 6c 6c
0000460 6f 57 6f 72 6c 64 01 00 10 6a 61 76 61 2f 6c 61
0000500 6e 67 2f 4f 62 6a 65 63 74 01 00 10 6a 61 76 61
0000520 2f 6c 61 6e 67 2f 53 79 73 74 65 6d 01 00 03 6f
0000540 75 74 01 00 15 4c 6a 61 76 61 2f 69 6f 2f 50 72
0000560 69 6e 74 53 74 72 65 61 6d 3b 01 00 13 6a 61 76
0000600 61 2f 69 6f 2f 50 72 69 6e 74 53 74 72 65 61 6d
0000620 01 00 07 70 72 69 6e 74 6c 6e 01 00 15 28 4c 6a
0000640 61 76 61 2f 6c 61 6e 67 2f 53 74 72 69 6e 67 3b
0000660 29 56 00 21 00 05 00 06 00 00 00 00 00 02 00 01
0000700 00 07 00 08 00 01 00 09 00 00 00 2f 00 01 00 01
0000720 00 00 00 05 2a b7 00 01 b1 00 00 00 02 00 0a 00
0000740 00 00 06 00 01 00 00 00 04 00 0b 00 00 00 0c 00
0000760 01 00 00 00 05 00 0c 00 0d 00 00 00 09 00 0e 00
0001000 0f 00 02 00 09 00 00 00 37 00 02 00 01 00 00 00
0001020 09 b2 00 02 12 03 b6 00 04 b1 00 00 00 02 00 0a
0001040 00 00 00 0a 00 02 00 00 00 06 00 08 00 07 00 0b
0001060 00 00 00 0c 00 01 00 00 00 09 00 10 00 11 00 00
0001100 00 12 00 00 00 05 01 00 10 00 00 00 01 00 13 00
0001120 00 00 02 00 14
根据 JVM 规范,类文件结构如下
u4 magic
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
1.魔数
u4 magic
对应着字节码文件的0~3个字节
0000000 ca fe ba be 00 00 00 34 00 23 0a 00 06 00 15 09
表示是java
2.版本
u2 minor_version;
u2 major_version;
0000000 ca fe ba be 00 00 00 34 00 23 0a 00 06 00 15 09
00 00 表示小版本
00 34 主版本,表示52,代表JDK8
3.常量池
![]()
8~9 字节,表示常量池长度,00 23 (35) 表示常量池有 #1~#34项,注意 #0 项不计入,也没有值 0000000 ca fe ba be 00 00 00 34 00 23 0a 00 06 00 15 09
第#1项 0a 表示一个 Method 信息,00 06 和 00 15(21) 表示它引用了常量池中 #6 和 #21 项来获得 这个方法的【所属类】和【方法名】 0000000 ca fe ba be 00 00 00 34 00 23 0a 00 06 00 15 09
第#2项 09 表示一个 Field 信息,00 16(22)和 00 17(23) 表示它引用了常量池中 #22 和 # 23 项 来获得这个成员变量的【所属类】和【成员变量名】 0000000 ca fe ba be 00 00 00 34 00 23 0a 00 06 00 15 09
0000020 00 16 00 17 08 00 18 0a 00 19 00 1a 07 00 1b 07
略…
4.访问标识与继承信息
![]()
21 表示该 class 是一个类,公共的
0000660 29 56 00 21 00 05 00 06 00 00 00 00 00 02 00 01 05
表示根据常量池中 #5 找到本类全限定名
0000660 29 56 00 21 00 05 00 06 00 00 00 00 00 02 00 01 06
表示根据常量池中 #6 找到父类全限定名
0000660 29 56 00 21 00 05 00 06 00 00 00 00 00 02 00 01
表示接口的数量,本类为 0
0000660 29 56 00 21 00 05 00 06 00 00 00 00 00 02 00 01
5.Field信息
![]()
表示成员变量数量,本类为 0
0000660 29 56 00 21 00 05 00 06 00 00 00 00 00 02 00 01
6.Method信息
表示方法数量,本类为 2
0000660 29 56 00 21 00 05 00 06 00 00 00 00 00 02 00 01
一个方法由 访问修饰符,名称,参数描述,方法属性数量,方法属性组成
7 附加属性
00 01 表示附加属性数量
00 13 表示引用了常量池 #19 项,即【SourceFile】
00 00 00 02 表示此属性的长度
00 14 表示引用了常量池 #20 项,即【HelloWorld.java】
0001100 00 12 00 00 00 05 01 00 10 00 00 00 01 00 13 00 0001120 00 00 02 00 14
2.字节码指令
1.入门
public cn.itcast.jvm.t5.HelloWorld(); 构造方法的字节码指令
2a => aload_0 加载 slot 0 的局部变量,即 this,做为下面的 invokespecial 构造方法调用的参数
b7 => invokespecial 预备调用构造方法,哪个方法呢?
00 01 引用常量池中 #1 项,即【 Method java/lang/Object.“init”
学习黑马JVM的笔记相关推荐
- 黑马jvm课程笔记d1
目录 一.堆内存相关 1.1.定义 1.2堆内存溢出 1.2.1 堆内存内存诊断工具 二.方法区相关 2.1.方法区组成 2.2.方法区内存溢出 2.3.方法区内常量池 2.4.运行时常量池 三.St ...
- Git基础学习(黑马程序员笔记)
Git介绍 Git是目前世界上最先进的分布式版本控制系统 Git安装 官网 Git与Github 两者区别 Git是一个分布式版本库控制系统,简单的说就是一个软件,用于记录一个或若干文件内容变化,以便 ...
- JVM黑马版:笔记、应用、速查
前言 由于工作中时常和JVM打交道,但是对JVM的体系缺乏系统深入了解.日前跟随b站上黑马程序猿的课程成体系地学习了JVM,结合工作中的实践写就了此笔记. 黑马原视频地址:https://www.bi ...
- 马士兵JVM课程笔记
马士兵JVM课程笔记 GC和GC Tuning GC的基础知识 1.什么是垃圾 C语言申请内存:malloc free C++: new delete c/C++ 手动回收内存 Java: new ? ...
- JVM 深入笔记(1)内存区域是如何划分的?
JVM 深入笔记(1)内存区域是如何划分的? 作者:柳大 · Poechant 电邮:zhongchao.ustc#gmail.com (#->@) 博客:blog.csdn.net/poech ...
- Yann Lecun纽约大学《深度学习》2020课程笔记中文版,干货满满!
关注上方"深度学习技术前沿",选择"星标公众号", 资源干货,第一时间送达! [导读]Yann Lecun在纽约大学开设的2020春季<深度学习>课 ...
- 使用html记笔记,开始学习HTML,并记下笔记
开始学习HTML,并记下笔记. 外边距(不影响可见框大小,影像盒子位置) margin-top(上) right(右) bottom(下) left(左) "外边距也可以为一个负值,元素会反 ...
- 学习Python的做笔记神器——Jupyter Notebook
学习Python的做笔记神器--Jupyter Notebook 给想学好Python的同学们安利一波,Jupyter Notebook是学习Python最好的做笔记环境,没有之一哦. Jupyter ...
- 《Python深度学习》第一章笔记
<Python深度学习>第一章笔记 1.1人工智能.机器学习.深度学习 人工智能 机器学习 深度学习 深度学习的工作原理 1.2深度学习之前:机器学习简史 概率建模 早期神经网络 核方法 ...
- 《学习geometric deep learning笔记系列》第一篇,Non-Euclidean Structure Data之我见
<学习geometric deep learning笔记系列>第一篇,Non-Euclidean Structure Data之我见 FesianXu at UESTC 前言 本文是笔者在 ...
最新文章
- gpio驱动广播Android,[RK3288][Android6.0] 调试笔记 --- 通用GPIO驱动控制LED【转】
- react控制组件中元素_React Interview问题:浏览器,组件或元素中呈现了什么?
- 【转】 VC MFC 钩子 实现 自绘 窗体 标题栏 非客户区
- DMA(2) S3C2410 DMA详解(其它的其实类似)
- c语言链表桶排序,【排序】图解桶排序
- 图片轮播html1001无标题,轮播图采用js、jquery实现无缝滚动和非无缝滚动的四种案例实现,兼容ie低版本浏览器...
- 现代通信原理5.1:信号的希尔伯特变换
- 人脸识别mtcnn原理
- Firefox 扩展“此组件无法安装,因为它未通过验证。”问题的解决
- 电镀用整流电源设计matlab,高功率因数的大功率开关电镀电源研究
- 51开发板用ADC采集模拟量
- 《豪杰音乐工作室》技巧拾遗
- 【ACWing】1176. 消息的传递
- {转}tbl语言简介
- 关于国家标准、行业标准
- 裸金属云FASS高性能弹性块存储解决方案
- TLS-SRTP协议详解
- 年轻的优秀博士:网络牛人刘云浩,王新兵,朱其立
- Futures timed out after [10 seconds]. This timeout is controlled by spark.executor.heartbeatInterva
- 在外远程桌面控制家里的电脑