SqueezeNet网络讲解
原文地址: https://zhuanlan.zhihu.com/p/31558773
引言
SqueezeNet是Han等提出的一种轻量且高效的CNN模型,它参数比AlexNet少50x,但模型性能(accuracy)与AlexNet接近。在可接受的性能下,小模型相比大模型,具有很多优势:(1)更高效的分布式训练,小模型参数小,网络通信量减少;(2)便于模型更新,模型小,客户端程序容易更新;(3)利于部署在特定硬件如FPGA,因为其内存受限。因此研究小模型是很有现实意义的。Han等将CNN模型设计的研究总结为四个方面:
(1)模型压缩:对pre-trained的模型进行压缩,使其变成小模型,如采用网络剪枝和量化等手段;
(2)CNN微观结构:对单个卷积层进行优化设计,如采用1x1的小卷积核,还有很多采用可分解卷积(factorized convolution)结构或者模块化的结构(blocks, modules);
(3)CNN宏观结构:网络架构层面上的优化设计,如网路深度(层数),还有像ResNet那样采用“短路”连接(bypass connection);
(4)设计空间:不同超参数、网络结构,优化器等的组合优化。
SqueezeNet也是从这四个方面来进行设计的,其设计理念可以总结为以下三点:
(1)大量使用1x1卷积核替换3x3卷积核,因为参数可以降低9倍;
(2)减少3x3卷积核的输入通道数(input channels),因为卷积核参数为:(number
of input channels) * (number of filters) * 3 * 3.
(3)延迟下采样(downsample),前面的layers可以有更大的特征图,有利于提升模型准确度。目前下采样一般采用strides>1的卷积层或者pool layer。
SqueezeNet网络结构
SqueezeNet网络基本单元是采用了模块化的卷积,其称为Fire module。Fire模块主要包含两层卷积操作:一是采用1x1卷积核的squeeze层;二是混合使用1x1和3x3卷积核的expand层。Fire模块的基本结构如图1所示。在squeeze层卷积核数记为 ,在expand层,记1x1卷积核数为
,而3x3卷积核数为
。为了尽量降低3x3的输入通道数,这里让
的值小于
与
的和。这算是一个设计上的trick。
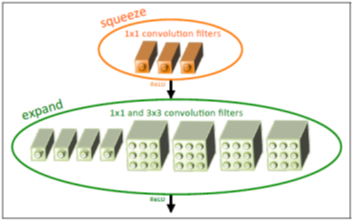
图1 Fire模块的基本结构示意图
整个SqueezeNet就是使用Fire基本模块堆积而成的,网络结构如图2所示,其中左图是标准的SqueezeNet,其开始是一个卷积层,后面是Fire模块的堆积,值得注意的是其中穿插着stride=2的maxpool层,其主要作用是下采样,并且采用延迟的策略,尽量使前面层拥有较大的feature map。中图和右图分别是引入了不同“短路”机制的SqueezeNet,这是借鉴了ResNet的结构。具体每个层采用的参数信息如表1所示。
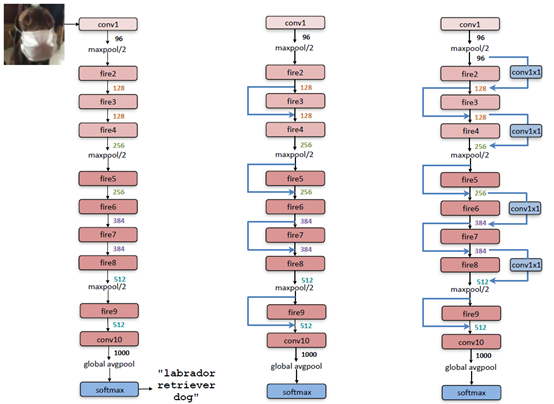
图2 SqueezeNet网络结构
下面说一下SqueezeNet的一些具体的实现细节:
(1)在Fire模块中,expand层采用了混合卷积核1x1和3x3,其stride均为1,对于1x1卷积核,其输出feature map与原始一样大小,但是由于它要和3x3得到的feature map做concat,所以3x3卷积进行了padding=1的操作,实现的话就设置padding=”same”;
(2)Fire模块中所有卷积层的激活函数采用ReLU;
(3)Fire9层后采用了dropout,其中keep_prob=0.5;
(4)SqueezeNet没有全连接层,而是采用了全局的avgpool层,即pool size与输入feature map大小一致;
(5)训练采用线性递减的学习速率,初始学习速率为0.04。
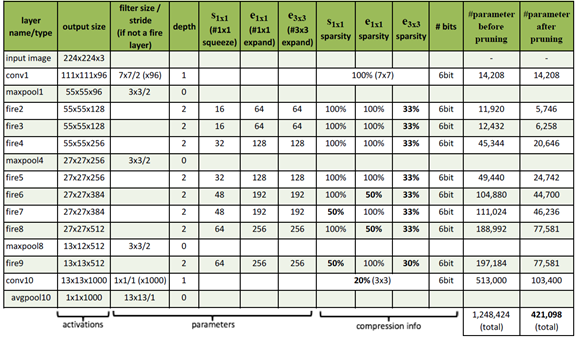
表1 SqueezeNet各层参数信息
SqueezeNet性能
从网络结构来看,SqueezeNet也算是设计精良了,但是最终性能还是要实验说话。论文作者将SqueezeNet与AlexNet在ImageNet上做了对比,值得注意的是,不仅对比了基础模型之间的差异,还对比了模型压缩的性能,其中模型压缩主要采用的技术有SVD,网络剪枝(network pruning)和量化(quantization)等。具体的对比结果如表2所示。首先看一下基准模型的性能对比,SqueezeNet的Top-1优于AlexNet,Top-5性能一样,但是最重要的模型大小降低了50倍,从240MB->4.8MB,这个提升是非常有价值的,因为这个大小意味着有可能部署在移动端。作者并没有止于此,而是继续进行了模型压缩。其中SVD就是奇异值分解,而所谓的网络剪枝就是在weight中设置一个阈值,低于这个阈值就设为0,从而将weight变成系数矩阵,可以采用比较高效的稀疏存储方式,进而降低模型大小。值得一提的Deep Compression技术,这个也是Han等提出的深度模型压缩技术,其包括网络剪枝,权重共享以及Huffman编码技术。这里简单说一下权重共享,其实就是对一个weight进行聚类,比如采用k-means分为256类,那么对这个weight只需要存储256个值就可以了,然后可以采用8 bit存储类别索引,其中用到了codebook来实现。关于Deep Compression详细技术可以参加文献[2]。从表2中可以看到采用6 bit的压缩,SqueezeNet模型大小降到了0.47MB,这已经降低了510倍,而性能还保持不变。为了实现硬件加速,Han等还设计了特定的硬件来高效实现这种压缩后的模型,具体参加文献[3]。顺便说过题外话就是模型压缩还可以采用量化(quantization),说白了就是对参数降低位数,比如从float32变成int8,这样是有道理,因为训练时采用高位浮点是为了梯度计算,而真正做inference时也许并不需要这么高位的浮点,TensorFlow中是提供了量化工具的,采用更低位的存储不仅降低模型大小,还可以结合特定硬件做inference加速。
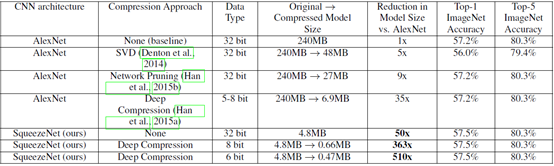
表2 SqueezeNet与AlexNet的对比结果
除了上面的工作,作者还探索了网络的设计空间,包括微观结构和宏观结构,微观结构包括各个卷积层的维度等设置,宏观结构比如引入ResNet的短路连接机制,详细内容可以参考原论文[1]。
SqueezeNet的TensorFlow实现
Fire模块中的expand层可以看成两个普通的卷积层,然后做concat,所以SqueezeNet很容易使用TensorFlow实现:
class SqueezeNet(object):def __init__(self, inputs, nb_classes=1000, is_training=True):# conv1net = tf.layers.conv2d(inputs, 96, [7, 7], strides=[2, 2],padding="SAME", activation=tf.nn.relu,name="conv1")# maxpool1net = tf.layers.max_pooling2d(net, [3, 3], strides=[2, 2],name="maxpool1")# fire2net = self._fire(net, 16, 64, "fire2")# fire3net = self._fire(net, 16, 64, "fire3")# fire4net = self._fire(net, 32, 128, "fire4")# maxpool4net = tf.layers.max_pooling2d(net, [3, 3], strides=[2, 2],name="maxpool4")# fire5net = self._fire(net, 32, 128, "fire5")# fire6net = self._fire(net, 48, 192, "fire6")# fire7net = self._fire(net, 48, 192, "fire7")# fire8net = self._fire(net, 64, 256, "fire8")# maxpool8net = tf.layers.max_pooling2d(net, [3, 3], strides=[2, 2],name="maxpool8")# fire9net = self._fire(net, 64, 256, "fire9")# dropoutnet = tf.layers.dropout(net, 0.5, training=is_training)# conv10net = tf.layers.conv2d(net, 1000, [1, 1], strides=[1, 1],padding="SAME", activation=tf.nn.relu,name="conv10")# avgpool10net = tf.layers.average_pooling2d(net, [13, 13], strides=[1, 1],name="avgpool10")# squeeze the axisnet = tf.squeeze(net, axis=[1, 2])self.logits = netself.prediction = tf.nn.softmax(net)def _fire(self, inputs, squeeze_depth, expand_depth, scope):with tf.variable_scope(scope):squeeze = tf.layers.conv2d(inputs, squeeze_depth, [1, 1],strides=[1, 1], padding="SAME",activation=tf.nn.relu, name="squeeze")# squeezeexpand_1x1 = tf.layers.conv2d(squeeze, expand_depth, [1, 1],strides=[1, 1], padding="SAME",activation=tf.nn.relu, name="expand_1x1")expand_3x3 = tf.layers.conv2d(squeeze, expand_depth, [3, 3],strides=[1, 1], padding="SAME",activation=tf.nn.relu, name="expand_3x3")return tf.concat([expand_1x1, expand_3x3], axis=3)总结
本文简单介绍了移动端CNN模型SqueezeNet,其核心是采用模块的卷积组合,当然做了一些trick,更重要的其结合深度模型压缩技术,因此SqueezeNet算是结合了小模型的两个研究方向:结构优化和模型压缩。
参考资料
- SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size.
- Deep Compression: Compressing Deep Neural Networks with Pruning,Trained Quantization and Huffman Coding.
- EIE: Efficient inference engine on compressed deep neural network.
pytorch实现:
import torch
import torch.nn as nn
import torch.nn.init as init
import torch.utils.model_zoo as model_zoo__all__ = ['SqueezeNet', 'squeezenet1_0', 'squeezenet1_1']model_urls = {'squeezenet1_0': 'https://download.pytorch.org/models/squeezenet1_0-a815701f.pth','squeezenet1_1': 'https://download.pytorch.org/models/squeezenet1_1-f364aa15.pth',
}class Fire(nn.Module):def __init__(self, inplanes, squeeze_planes,expand1x1_planes, expand3x3_planes):super(Fire, self).__init__()self.inplanes = inplanesself.squeeze = nn.Conv2d(inplanes, squeeze_planes, kernel_size=1)self.squeeze_activation = nn.ReLU(inplace=True)self.expand1x1 = nn.Conv2d(squeeze_planes, expand1x1_planes,kernel_size=1)self.expand1x1_activation = nn.ReLU(inplace=True)self.expand3x3 = nn.Conv2d(squeeze_planes, expand3x3_planes,kernel_size=3, padding=1)self.expand3x3_activation = nn.ReLU(inplace=True)def forward(self, x):x = self.squeeze_activation(self.squeeze(x))return torch.cat([self.expand1x1_activation(self.expand1x1(x)),self.expand3x3_activation(self.expand3x3(x))], 1)class SqueezeNet(nn.Module):def __init__(self, version=1.0, num_classes=1000):super(SqueezeNet, self).__init__()if version not in [1.0, 1.1]:raise ValueError("Unsupported SqueezeNet version {version}:""1.0 or 1.1 expected".format(version=version))self.num_classes = num_classesif version == 1.0:self.features = nn.Sequential(nn.Conv2d(3, 96, kernel_size=7, stride=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),Fire(96, 16, 64, 64),Fire(128, 16, 64, 64),Fire(128, 32, 128, 128),nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),Fire(256, 32, 128, 128),Fire(256, 48, 192, 192),Fire(384, 48, 192, 192),Fire(384, 64, 256, 256),nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),Fire(512, 64, 256, 256),)else:self.features = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3, stride=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),Fire(64, 16, 64, 64),Fire(128, 16, 64, 64),nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),Fire(128, 32, 128, 128),Fire(256, 32, 128, 128),nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),Fire(256, 48, 192, 192),Fire(384, 48, 192, 192),Fire(384, 64, 256, 256),Fire(512, 64, 256, 256),)# Final convolution is initialized differently form the restfinal_conv = nn.Conv2d(512, self.num_classes, kernel_size=1)self.classifier = nn.Sequential(nn.Dropout(p=0.5),final_conv,nn.ReLU(inplace=True),nn.AdaptiveAvgPool2d((1, 1)))for m in self.modules():if isinstance(m, nn.Conv2d):if m is final_conv:init.normal_(m.weight, mean=0.0, std=0.01)else:init.kaiming_uniform_(m.weight)if m.bias is not None:init.constant_(m.bias, 0)def forward(self, x):x = self.features(x)x = self.classifier(x)return x.view(x.size(0), self.num_classes)def squeezenet1_0(pretrained=False, **kwargs):r"""SqueezeNet model architecture from the `"SqueezeNet: AlexNet-levelaccuracy with 50x fewer parameters and <0.5MB model size"<https://arxiv.org/abs/1602.07360>`_ paper.Args:pretrained (bool): If True, returns a model pre-trained on ImageNet"""model = SqueezeNet(version=1.0, **kwargs)if pretrained:model.load_state_dict(model_zoo.load_url(model_urls['squeezenet1_0']))return modeldef squeezenet1_1(pretrained=False, **kwargs):r"""SqueezeNet 1.1 model from the `official SqueezeNet repo<https://github.com/DeepScale/SqueezeNet/tree/master/SqueezeNet_v1.1>`_.SqueezeNet 1.1 has 2.4x less computation and slightly fewer parametersthan SqueezeNet 1.0, without sacrificing accuracy.Args:pretrained (bool): If True, returns a model pre-trained on ImageNet"""model = SqueezeNet(version=1.1, **kwargs)if pretrained:model.load_state_dict(model_zoo.load_url(model_urls['squeezenet1_1']))return model
SqueezeNet网络讲解相关推荐
- CNN基本步骤以及经典卷积(LeNet、AlexNet、VGGNet、InceptionNet 和 ResNet)网络讲解以及tensorflow代码实现
课程来源:人工智能实践:Tensorflow笔记2 文章目录 前言 1.卷积神经网络的基本步骤 1.卷积神经网络计算convolution 2.感受野以及卷积核的选取 3.全零填充Padding 4. ...
- MobileNetv1、MobileNetv2、MobileNetv3网络讲解
目录 前言 一.MobileNetv1 1.1.传统卷积 1.2.DW卷积 1.3.深度可分离卷积(Depthwise Separable Conv) 1.4.网络架构 1.5.超参数 α , ρ \ ...
- vc6.0 简易的tcp网络讲解(二)
至于为什么用vc6.0,我用的是xp系统,没钱 有错误请指出,本人业余的(所写的代码,尽量注释清楚)通过vc6.0的直接复制粘贴即可 (代码来源于网络, 仅供学习交流,严禁用于商业用途 ) 本人参考的 ...
- VGG网络讲解——小白也能懂
目录 1.VGG网络简介 一.VGG概述 二.VGG结构简介 2.VGG的优点 3.VGG亮点所在 计算量 感受野 1.VGG网络简介 一.VGG概述 VGGNet是牛津大学视觉几何组(Visual ...
- 学习VGG(网络讲解+代码)
VGG (新手入门,如理解有误感谢指正) 论文地址 VGG是由牛津大学的Visual Geometry Group组提出的,在LSVRC 2014中获得了亚军,而冠军是GoogLeNet,后面会学习并 ...
- Docker之Docker网络讲解
查看虚拟机的网络地址情况: ip addr docker是如何处理容器网络访问: 先启动一个容器: docker run -d -P --name=tomcat01 tomcat:8.5 查看容器的网 ...
- 2014-VGG网络讲解
文章链接 文章目录 VGG 1. 简介 2. 网络 3. 代码 加载数据 创建分类网络 训练 4. 别人优化后的代码 VGG 1. 简介 其名称来源于作者所在的牛津大学视觉几何组(Visual Geo ...
- 图像分割 FCN(1):FCN网络讲解
1. 介绍 FCN网络论文:Fully Convolution Networks for Semantic Segmentation,是2015年发表在CVPR上的一篇文章.FCN网络是首个端对端的针 ...
- SDN自定义网络讲解(内部学习专用)
第一集:[https://live.csdn.net/v/157408] 第二集:[https://live.csdn.net/v/157409] 第三集:[https://live.csdn.net ...
最新文章
- sql 拆分_技术分享 | 基于分布式中间件的SQL改造指南
- php curl处理get和post请求
- mysql 5.6密钥_MySQL的密钥文件不正确
- 宜搭小技巧|自动计算日期时长,3个公式帮你敲定
- 江苏单招试题计算机原理及答案,江苏省对口单招计算机组装与维修计算机原理考题分类汇总.docx...
- 关于 “Makefile:3:***遗漏分隔符。停止 。”解决方法二
- 零基础学习AI也有快捷方式?一文帮你提升竞争力!
- 甲骨文中国数据库中心将落地,与微软数据库市场两家独大
- 已知拱高和弦长,求弧长、半径、角度
- Win10搭建gym运行atari游戏pong
- 面试过程中应注意的问题与禁忌
- 向 3D 城市模型添加外观
- spark Kafka 线程安全问题
- Bupt桌游馆--共享资源清单
- 最全数据集网站汇总,绝对是一个金矿请查收!
- 511遇见易语言学习易语言常量
- 高通平台WIFI-去掉信号标识上面的叹号和叉叉issue
- 基于turn.js库电子书在线阅读器源码
- SpringCloud Gateway获取post请求体(request body)
- 数码管显示原理与驱动方式