2021年秋季版 CMU数据库15-445/645 Note1~4
2021年秋季版 CMU数据库15-445/645 Note翻译
NOTE
这也就是说这并不是一门教你如何使用数据库去构建应用程序、网站或者其他东西课,也不是一门教你如何去管理和部署数据库的课。
我们所注重的是教你如何去构建和设计软件,这才是数据库管理系统
本文前四章翻译用的是知乎 https://www.zhihu.com/column/c_1298236285451513856 taoting的,后面开始是本人(菜鸟)自己译的。
文章目录
- Introduction
- 1 数据库
- 2 平面文件
- 3 数据库管理系统(DBMS)
- 4 关系模型
- 5 数据操纵语言(DML)
- 6 关系代数
- Intermediate SQL
- 1 关系语言
- 2 SQL历史
- 3 聚合
- 4 字符串操作
- 5 输出重定向
- 6 输出控制
- 7 嵌套查询
- 8 窗口函数
- 9 公用表表达式(CTE)
- Database Storage I
- 1 存储
- 2 硬盘数据库概述
- 3 数据库 vs. 操作系统
- 4 文件存储
- 5 数据库的页
- 6 数据库的堆
- 7 页布局
- 8 元组布局
- Database Storage II
- 1 数据表示
- 2 工作类型
- 3 存储模型
Introduction
1 数据库
数据库是对现实世界的某些方面建模的相互关联的数据有组织的集合(例如对学生属于班这个关系建模,对数字音乐商城建模)。人们经常混淆数据库(database)和数据库管理系统(database management system)(例如MySQL,Oracle,MongoDB),数据库管理系统是一个管理数据库的软件。
设想一个为数字音乐商城(例如Spotify)建模的数据库,数据库保存艺术家和每个艺术家有哪些专辑的信息。
2 平面文件
DBMS将数据库存在逗号分隔文件(CSV)中,每个实体都被存在于自己的文件中。当应用程序想要去读取或更新记录的时候,它每次都必须去解析文件。每个实体有自己的属性,在每个文件中,不同的记录将被分布在不同的行中,每个记录的每个属性都由逗号分隔。
例如
![]()
查找“Ice Cube” 的出道年份
![]()
回到之前数字音乐商店的例子中,它有2个文件:一个是艺术家,一个是专辑。一个艺术家可能有名字、出生时间和国家等属性,专辑可能有名字、艺术家、发布时间等属性。
Issues with Flat File(平面文件的问题):
- Data Integrity(数据完整性)
- 我们如何确保每个专辑的艺术家是相同的?
- 如果有人在专辑发布时间写了一个非法字符该怎么办?
- 我们如何在一个专辑中存多个艺术家?
- 当我们删除一张带有专辑的艺术家时会发生什么?
- Implementation(实现)
- 我们如何找到一个特定的记录?
- 如果我们想要创建一个新的应用使用相同的数据库?
- 如果2个线程尝试在相同的时间去写一个相同的文件?
- Durability(持久性)
- 如果当你的程序正在更新数据的时候机器坏了该怎么办?
- 如果你为了高可用想对数据库进行分片并部署到不同的机器上该怎么办?
3 数据库管理系统(DBMS)
*数据库管理系统(DBMS)*是一个软件,它允许应用程序在数据库中存储和分析信息。
通用的DBMS被设计成允许定义,创建,更新和管理数据库。
早期的DBMS
数据库应用程序通常很难构建和维护,因为逻辑层和物理层之间存在紧密的耦合。逻辑层是数据库拥有哪些实体和属性,而物理层是如何存储这些实体和属性。早期,物理层被定义在应用程序的代码中,如果我们想要修改物理层,我们必须修改代码来匹配新的物理层。
4 关系模型
Ted Codd意识到每次更改物理层的时候都要重写DBMS。因此在1970年他提出了关系模型来避免这种情况。其中关系模型有3个关键点:
- 用简单的数据结构存储数据(关系)。
- 通过高层语言访问数据。
- 物理存储留待实现。
数据模型是描述数据在数据库中的一系列的概念。关系模型是数据模型中的一个例子。
模式是使用给定数据模型对特定数据集合的描述。
关系数据模型定义了3个概念:
- **Structure(结构):**关系的定义及其内容,这是关系拥有的属性以及这些属性可以包含的值。
- **Integrity(完整):**确保数据满足约束条件,一个例子是年份必须为数字。
- **Manipulation(操纵):**如何访问和修改数据。
关系一个是无序集合,它代表了实体属性的联系。因为关系是无序的,所以DBMS可以以任何方式存储,并允许优化。
元组是关系中属性值的集合。最初,值必须是原子或标量,但是现在的值可以是列表甚至是嵌套的数据结构(比如json)。每个属性都可以是NULL,它代表这个属性值是未定义的。
一个有n个属性的关系称之为n维关系
Keys(键)
一个关系的主键唯一定义一个元组。如果你没有定义主键,一些DBMS会自动创建一个内部主键。同时大多数DBMS支持自动生成key,所以应用程序无需管理递增主键。
外键代表一个关系的一个属性映射到另一个关系的一个属性。
5 数据操纵语言(DML)
数据操纵语言(DML)是一种数据库存储数据和检索数据的语言。它分为2种类型:
- **Procedural (程序性的):**该查询指定了DBMS查找的策略。
- **Non-Procedural (非程序性的) (声明性) :**该查询仅仅指定了需要什么数据而不是如何获取它。
6 关系代数
关系代数是一个在关系中检索和操纵元组基础操作的集合。每个操作以一个或多个关系作为输入,并输出一个新的关系。我们可以组合使用这些关系代数来创建更复杂的查询。
Select(选择)
Select输入1个关系,并输出满足特定选择谓词的所有元组。谓词就像一个过滤器,我们可以使用连接词和逻辑词组合多个谓词。
语法: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tXDYdu5v-1632829488809)(https://www.zhihu.com/equation?tex=%5Csigma+_%7Bpredicate%7D%28R%29)]
Projection(投影)
Projection输入1个关系,并输出仅包含特定属性的所有元组,你可以在输入关系中重新排列属性的顺序,也可以操纵这些值。
语法: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4msCDmLV-1632829488812)(https://www.zhihu.com/equation?tex=%5Cpi+_%7BA1%2CA2%2C…%2CAn%7D%28R%29)]
Union(并集)
Union输入2个关系并输出1个关系,该关系包含至少出现在1个关系中的所有元组。注意:2个输入关系必须拥有相同的属性值。
语法: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9yh1v9RH-1632829488815)(https://www.zhihu.com/equation?tex=%28R%5Ccup+S%29)]
Intersection(交集)
Intersection输入2个关系并输出1个关系,该关系包含同时出现在2个关系中的所有元组。注意:2个输入关系必须拥有相同的属性值。
语法: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ydjet2jo-1632829488816)(https://www.zhihu.com/equation?tex=%28R%5Ccap+S%29)]
Difference(差集)
Difference输入2个关系并输出1个关系,该关系包含出现在第1个关系中但不出现在第2个关系中的所有元组。注意:2个输入关系必须拥有相同的属性值。
语法: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U9pJSF0m-1632829488818)(https://www.zhihu.com/equation?tex=%28R-S%29)]
Product(乘积)
Product输入2个关系并输出1个关系,该关系包含输入元组的所有可能组合。
语法: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uaGj49TV-1632829488820)(https://www.zhihu.com/equation?tex=%28R%5Ctimes+S%29)]
Join(连接)
Join输入2个关系并输出1个包含所有元组的关系,该元组是2个元组的组合,其中对于共享的每个属性,2个元组的属性值必须相同。
语法: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZaK0N6oJ-1632829488821)(https://www.zhihu.com/equation?tex=%28R%5CJoin+S%29)]
Observation(总结)
关系代数是一种过程语言,他定义了如何查询的高层表示。例如 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g4ucOdar-1632829488822)(https://www.zhihu.com/equation?tex=%5Csigma+%7Bb_id%3D102%7D%28R%5CJoin+S%29)] 表示首先join R和S然后进行select。而 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I4MiSjzp-1632829488823)(https://www.zhihu.com/equation?tex=%28R%5CJoin%28%5Csigma+%7Bb_id%3D102%7D%28S%29%29%29)] 将会先select S,然后再进行join。这2个表达式将会产生相同的答案,但是如果S是十亿的数据集合中只有一个元组满足b_id=102,那么使用 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i65cVJFn-1632829488825)(https://www.zhihu.com/equation?tex=%28R%5CJoin%28%5Csigma+%7Bb_id%3D102%7D%28S%29%29%29)] 的速度会比 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pvGXB6qG-1632829488825)(https://www.zhihu.com/equation?tex=%5Csigma+%7Bb_id%3D102%7D%28R%5CJoin+S%29)] 快很多。
一个比较好的方式是直接描述你想要的结果,然后DBMS会决定如何进行计算。SQL完全可以做到这点,因为它是在关系模型数据库上编写查询的一种标准。
Intermediate SQL
1 关系语言
在20世纪70年代,Edgar Codd发布了一篇关于关系模型的论文。最初,他只定义了数据库在关系模型上运行查询的数学符号。
用户只需要使用声明性的语言指定他们想要的结果(例如SQL)。数据库有责任去决定最有效率的计划并返回结果。
关系代数基于set(无序,没有重复),SQL基于bag(无序,有重复)。
2 SQL历史
用于关系型数据库的声明式查询语言,最初是在20世纪70年代作为IBM System R项目的一部分开发的。IBM最初称为“SEQUEL”(Structured English Query Language 结构化英文查询语言)。在20世纪80年代改名为“SQL”(Structured Query Language 结构化查询语言)。
这个语言由不同种类的命令组成:
- **Data Manipulation Language (DML 数据操纵语言):**SELETE(查询),INSERT(插入),UPDATE(更新)和DELETE(删除)。
- **Data Definition Language (DDL 数据定义语言):**定义表,索引,视图和另外对象的模式。
- **Data Control Language (DCL 数据控制语言):**安全,访问控制。
SQL不是一个死(一成不变)的语言,每隔几年就会添加新功能。SQL-92标准是一个数据库支持SQL的最低要求。每个供应商都在一定程度上遵循标准,但同时他们也有很多自己的扩展语法。
3 聚合
聚合函数接受一批元组作为输入并产生单个标量作为输出。聚合函数只能用于SELECT的输出列。
例子:获取学生用“@cs”登录的数量。下列3个查询是等价的:
SELECT COUNT(*) FROM student WHERE login LIKE '%@cs';
SELECT COUNT(login) FROM student WHERE login LIKE '%@cs';
SELECT COUNT(1) FROM student WHERE login LIKE '%@cs';
可以使用多个聚合函数在一个SELECT语句块中:
SELECT AVG(gpa), COUNT(sid)FROM student WHERE login LIKE '%@cs';
一些聚合函数支持DISTINCT关键字:
SELECT COUNT(DISTINCT login)FROM student WHERE login LIKE '%@cs';
同时输出聚合函数列和非聚合函数列是未定义行为(e.cid在这里是未定义行为)
注:未定义行为指该行为标准中未定义,不同数据库可能会返回不同的结果(甚至可能会报错)
SELECT AVG(s.gpa), e.cidFROM enrolled AS e, student AS sWHERE e.sid = s.sid;
因此,其他非聚合函数的列必须使用GROUP BY命令进行聚合:
SELECT AVG(s.gpa), e.cidFROM enrolled AS e, student AS sWHERE e.sid = s.sidGROUP BY e.cid;
HAVING:聚合后进行过滤,像WHERE子句中使用GROUP BY过滤这样
SELECT AVG(s.gpa) AS avg_gpa, e.cidFROM enrolled AS e, student AS sWHERE e.sid = s.sidGROUP BY e.cid
HAVING avg_gpa > 3.9;
4 字符串操作
SQL标准规定字符串区分大小写并只能使用单引号。有些函数可以在查询的任何地方使用并操纵字符串。
**Pattern Matching(模式匹配):**LIKE关键字被用于在谓词中的字符串匹配。
- “%” 匹配任何子串(包括空串)。
- “_” 匹配单个字符。
**Concatenation(连接):**两个竖线(“||”)会连接2个或多个字符串变成1个字符串。
5 输出重定向
除了可以直接给用户返回结果,你还可以告诉数据库存储结果到另外一张表,然后你可以在后续查询中访问这些数据。
- **New Table(新表):**存储查询的输出到新表中。
SELECT DISTINCT cid INTO CourseIds FROM enrolled;
- **Existing Table(已存在的表):**存储查询的输入到已经存在表中。目标表必须有相同的列数和相同的类型,列名可以和输出列不匹配。
INSERT INTO CourseIds (SELECT DISTINCT cid FROM enrolled);
6 输出控制
由于SQL是无序的,你必须使用ORDER BY子句去对结果进行排序:
SELECT sid FROM enrolled WHERE cid = '15-721'ORDER BY grade DESC;
你可以使用多个ORDER BY子句做更复杂的排序:
SELECT sid FROM enrolled WHERE cid = '15-721'ORDER BY grade DESC, sid ASC;
你可以使用任意的表达式在ORDER BY子句中:
SELECT sid FROM enrolled WHERE cid = '15-721'ORDER BY UPPER(grade) DESC, sid + 1 ASC;
通常,数据库会返回所有符合条件的元组。你可以使用LIMIT子句去限制返回元组的数量:
SELECT sid, name FROM student WHERE login LIKE '%@cs'LIMIT 10;
同时也可以提供offset去获得一个结果的区间:
SELECT sid, name FROM student WHERE login LIKE '%@cs'LIMIT 10 OFFSET 20;
除非你使用一个ORDER BY子句搭配LIMIT,否则数据库可能在每次查询会返回不同的元组,因为关系模型不在意顺序。
7 嵌套查询
嵌套查询可以使单个查询中运行更复杂的查询。外部查询的作用域在内部查询中(内部查询可以访问外部查询的属性),反之不行。
内部查询可以出现在查询的几乎所有地方:
- SELECT输出目标:
SELECT (SELECT 1) AS one FROM student;
\2. FROM子句:
SELECT nameFROM student AS s, (SELECT sid FROM enrolled) AS eWHERE s.sid = e.sid;
\3. WHERE子句:
SELECT name FROM studentWHERE sid IN ( SELECT sid FROM enrolled );
例子:获取所有报名“15-445”的学生名字
SELECT name FROM studentWHERE sid IN ( SELECT sid FROM enrolled WHERE cid = '15-445' );
注意,根据sid出现的不同位置,它拥有不同的作用域。
Nest Query Results Expressions(嵌套查询表达式):
- ALL:必须满足子查询中所有的行
- ANY:必须满足子查询中至少1行
- IN:等价于ANY()
- EXISTS:至少1行被返回
8 窗口函数
跨元组执行“移动”计算。和聚合一样,但它依然返回原始元组。
**Functions(函数):**窗口函数可以是上面讨论的任意的聚合函数。同时还有一些特殊的窗口函数:
- ROW_NUMBER:当前行的number
- RANK:当前行的排序
**Grouping(分组):**OVER子句指定当计算窗口函数的时候如何分组。使用PARTITION BY去指定分组。
SELECT cid, sid, ROW_NUMBER() OVER (PARTITION BY cid)FROM enrolled ORDER BY cid;
你也可以在OVER中使用ORDER BY去确定结果的顺序 (与上一句话功能相同),即使数据库内部存储结构发生改变也不会影响结果。
SELECT *, ROW_NUMBER() OVER (ORDER BY cid)FROM enrolled ORDER BY cid;
重点:RANK函数在窗口函数排序后计算,ROW_NUBMER函数在排序前计算。
9 公用表表达式(CTE)
公用表表达式(CTE)是窗口函数和嵌套查询的替代方法去编写更加复杂的查询。可以认为CTE是在单次查询的一个临时表。
WITH子句将内部查询的输出绑定到临时的结果。
例子:生成一个CTE叫cteName包含1个tuple的1个属性,属性值为1。这个查询返回了cteName的所有属性及值。
WITH cteName AS (SELECT 1
)
SELECT * FROM cteName;
你可以绑定输出列的名字在AS之前:
WITH cteName (col1, col2) AS (SELECT 1, 2
)
SELECT col1 + col2 FROM cteName;
单个查询可以包括多个CTE的定义:
WITH cte1 (col1) AS (SELECT 1
),
cte2 (col2) AS (SELECT 2
)
SELECT * FROM cte1, cte2;
在WITH后添加RECURSIVE关键字允许CTE引用自己。
例子:打印1到10的序列
WITH RECURSIVE cteSource (counter) AS ((SELECT 1)UNION(SELECT counter + 1 FROM cteSourceWHERE counter < 10)
)
SELECT * FROM cteSource;
Database Storage I
1 存储
我们将会专注于”面向磁盘“的数据库架构并假定数据库中的大部分数据存在非易失的硬盘中。
在存储架构的顶层,这里的设备最接近CPU,它的存储速度最快,但是它的容量也最小并且非常昂贵。离CPU越远时,设备容量越大但速度越慢,同时每GB的价格也越便宜。
Volatile Devices(易失设备):
- 易失意味着如果你切断了电源,数据将会丢失。
- 易失存储支持以字节为单位的快速的随机访问。这意味着程序可以跳到任何字节地址并获得这里的数据。
- 出于我们的目的,我们总是将这个存储称为“内存”(memory)。
Non-Volatile Devices(非易失设备):
- 非易失意味着存储设备不需要提供持久的电力去保持数据的存储。
- 它以块/页为单位。这意味着为了读取一个特定偏移的数据,程序需要先读取4KB的页到内存中,并从内存中读取这个数据。
- 非易失存储在原理上(设计上)对顺序访问速度快(它可以同时读取多个连续的数据块)。
- 我们将它称为“硬盘”(disk)。但我们不会区分固态硬盘(SSD)和机械硬盘(HDD)。
近年来有一个新的存储设备叫做非易失内存,他可能是以后的潮流。这个设备吸收了两者的优点:它的速度和内存一样快,同时可以和硬盘一样可以持久化存储。但我们在这门课中不会讨论这个设备。
由于假设数据库的数据存储在硬盘上,数据库的组件将会负责在非易失的硬盘和易失的内存中移动数据,因为系统无法直接在硬盘上操作数据。
由于硬盘速度非常慢,我们将会专注于如何隐藏(弱化)硬盘的延迟,而不是专注于寄存器的优化和使用缓存优化。如果我们从L1缓存中读取一个数据需要0.5秒,那我们从SSD中读取该数据需要1.7天,从HDD中读取需要16.5周。
2 硬盘数据库概述
数据库的数据存在硬盘中,数据被组织成页,第一个页是目录页。为了操作数据,数据库需要从内存中获取数据。我们通过缓冲池(buffer pool)去管理数据从硬盘和内存之间的移动。数据库也有一个执行引擎去运行查询。这个执行引擎会向缓冲池获取一个特定的页,缓冲池会管理好在内存中的页,并返回给执行引擎一个指向特定页的指针。同时,缓冲池管理器会保证当执行引擎在访问页的时候该页不会被换出。
3 数据库 vs. 操作系统
数据库的一个高层的设计目标是支持数据库存储的数据大小超过可用内存的大小。读取/写入数据到硬盘中是一个非常低效的操作,所以我们必须管理好这些操作。我们不希望从硬盘读取数据的时候出现大的空挡从而拖慢其他操作的速度。同时我们希望数据库在等待数据读取的时候可以同时运行其他查询。
这个高层的设计目标像虚拟内存,在虚拟内存中有一个较大的地址空间和一个供操作系统从磁盘引入页面的位置。
实现虚拟内存的一种方式是使用mmap去映射一个文件的内容到一个内存地址空间,操作系统负责从硬盘和内存之间移动页。但不幸的是,如果mmap遇到页错误,进程将被阻塞。
- 如果你要写页,你永远不要考虑在数据库中使用mmap。
- 数据库总是希望自己可以控制操作,并且可以做的更好,因为他知道有哪些数据将要被访问,有哪些查询将要被运行。
- 操作系统不是你的朋友。
操作系统支持以下操作:
- madvise:告诉操作系统什么时候你计划读取特定的页。
- mlock:告诉操作系统不要将内存交换到硬盘上。
- msync:告诉操作系统同步内存的内容到硬盘上。
出于正确性和性能原因,我们不建议在数据库中使用mmap。
即使系统也提供一些看起来类似的功能,但数据库自己实现这些功能可以控制的更好,并且能获得更好的性能。
4 文件存储
在最基本的形式中,数据库将数据存成文件。一些数据库可能使用文件层次结构(多文件),另一些可能使用单文件(例如SQLite)。
但操作系统不知道这些文件内容的意义,只有数据库知道如何解密这些文件,因为这些文件是数据库由特定的方式编码的。
数据库的存储管理器负责管理数据文件。它将文件表示为页的集合。它还跟踪哪些数据被读写到页中,以及页中有多少空闲的空间。
5 数据库的页
数据库将数据组织在一个或多个文件中,这些文件在存储在页中,他们具有固定大小的块。页中可以包括不同类别的数据(元组,索引)。当然大多数系统不会在一个页中混合存储这些类别。一些系统可能会要求页是自我包含的(self-contained),这意味着读取页的信息在页本身中。
每个页都有一个唯一的标识符。如果数据是单文件的,那页id可以是简单的用偏移表示。大多数数据库都有一个中间层来映射页id到文件路径和偏移的对应关系。高层的系统会直接询问特定的页id,存储管理器将会转换页id到文件路径和偏移并去寻找这个页。
大多数数据库使用固定长度的页去避免支持可变长度的页所需的工程开销。例如,使用可变长度的页,删除一个页可能会造成文件的一个碎片,数据库并不能很轻易的使用新的页填充这个碎片(比如大小过小,造成新的碎片等等)。
这里有3个数据库中page的概念:
- 硬件的页(通常为4KB)
- 操作系统的页(4KB)
- 数据库的页(1-16KB)
存储设备保证对硬件的页大小的数据原子写操作。如果硬件的页是4KB,操作系统尝试去写4KB到硬盘中,这4KB要不完全写入成功,要不完全写入失败(不存在写入部分成功的情况)。这意味着如果数据库的页大于硬件的页,数据库将会使用额外的操作去保证安全的写入数据。因为当系统崩溃时,程序可能写入了部分数据。
6 数据库的堆
数据库有2种方式可以找到页在硬盘上的位置,堆文件组织是一种方式。
一个堆文件是一个页面的无序集合,其中元组以随机的顺序存储。
数据库可以使用链表或页字典的方式通过页id来定位页在硬盘上的位置。
- **Linked List(链表):**头部的页有一个指向空闲页的指针和一个数据页的指针。然而,如果数据库正在寻找一个特定的页,他需要顺序扫描数据页直到该页被找到。
- **Page Directory(页字典):**数据库维护一个特殊的页,它存储着每个数据页的位置以及每个页上的空闲空间。
7 页布局
每个页包含一个头部记录着每个页的元信息:
- 页大小
- 校验和
- 数据库版本
- 事务可见性
- 是否自我包含(比如Oracle需要这个)
布局数据的一种方法是跟踪有多少元组存储在一个页中,并在每次添加新元组时追加到尾部。然而,当元组被删除或者元组有变长属性的情况下问题就出现了。
有2种主要的方法在page中布局数据:(1)槽页(2)日志结构
**Slotted Pages(槽页):**页映射槽到偏移。
- 这是目前的数据库最常用的方法。
- 头记录使用槽的数量、最后使用的槽的起始位置和一个跟踪了每个槽的起始位置的槽数组。
- 当插入一个元组的时候,槽数组将从前往后插入,元组数据将从后往前插入。当槽数组和元组数据相遇的时候说明当前页已满。
**Log-Structured(日志结构):**数据库存储日志代替存储数据
- 存储数据库如何被修改的记录(插入,更新,删除)。
- 为了读取记录,数据库需要从前往后扫描日志文件去重建元组。
- 写入速度快,读取速度非常慢。
- 在仅追加的情况下效果非常好,因为数据库不会回滚和更新数据。
- 为了避免读取过慢,数据库可以创建索引并跳到日志中特定的位置。它可以周期性的压缩日志。(如果有一个元组被更新了,我们可以只存储插入一个元组。)但压缩的问题会导致数据库的写放大。(他会一遍一遍的重写相同的数据。)
8 元组布局
一个元组的本质是一连串的字节。数据库将这些字节解释成属性类型和相应的值。
**Tuple Header(元组头部):**包含元组的元数据
- 一些关于数据库并发控制的信息(例如哪个事务创建/修改这个元组)。
- 标记NULL的位图(bitmap)。
- 注意,数据库不需要在这里存储数据库模式的元数据。
**Tuple Data(元组数据):**每个属性真实的数据
- 属性通常按照你创建表的时候的顺序存储。
- 大多数数据库不允许一个元组超过页的大小。
Unique Identifier(唯一标识):
- 在数据库中的每个页都被赋予一个唯一的标识。
- 最常见的表示:页id + (偏移或槽号)。
- 应用程序不能依赖这些id来做任何事。
**Denormalized Tuple Data(规范化的元组数据):**如果2个表是相关联的,数据库可以预先连接他们,这2个表会存在相同的页中。这样做可以让数据库只加载1个页而不是加载2个单独的页,从而大大提高速度。然而,它将会导致更新操作的代价非常大因为数据库对每个元组需要更多的空间。
Database Storage II
1 数据表示
元组里的数据本质上就是字节数组,DBMS知道如何去解释这些字节到真正的属性值。数据表示模式是DBMS如何通过字节去存储值。
有5种高层数据类型可以存储在元组中:整数、浮点数、固定精度数字、变长数据、日期/时间。
Integers(整数)
大多数DBMS使用IEEE-754标准的C/C++类型去编码整数,这些值是定长的。
例子:INTEGER, BIGINT, SMALLINT, TINYINT
Variable Precision Numbers(浮点数)
这些不精确的、精度变化的数字(浮点数)使用IEEE-754标准的C/C++类型去编码,这些值也是定长的。
操作浮点数的速度比操作固定精度的数字的速度要快,因为CPU可以直接对浮点数直接进行操作。然而,由于数字表示是不精确的,所以在计算的时候会出现误差。
例子:FLOAT, REAL
Fixed-Point Precision Numbers(固定精度数字)
这些是具有任意精度和小数位数的数字类型。它们通常以精确的,可变长度的二进制表示(像字符串一样)存储,另外还会存储元数据,这些元数据告诉系统数据的长度和小数点的位置。
当数据精确性要求很高的时候可以使用这种类型,但DBMS会花费更高的代价去进行计算。
例子:NUMERIC, DECIMAL
Variable-Length Data(变长数据)
他们表示任意长度的数据类型,他们通常在头部存储字符串的长度,以便跳转到下一个值,同时可能还包含数据的校验和。
大多数DBMS不允许一个元组大小超过单个页大小。有些则将数据存储在一个特别的”溢出“页上,并在元组上存储这个页的引用信息。
也有一些系统会存储大数据在额外的文件上,并在元组中记录文件指针。例如,如果数据库存储图片信息,DBMS会直接将图片存储在额外的文件中,而不是让它们在数据库中占用大量空间。这样做的缺点是DBMS无法操纵这个文件的内容,因此没有持久性和事务的保证。
例子:VARCHAR, VARBINARY, TEXT, BLOB
Dates and Times(日期和时间)
日期/时间的表示因系统的不同而不同。从unix时代开始,时间通常表示为单位时间(微/毫)秒(时间戳)。
例子:TIME, DATE, TIMESTAMP
System Catalogs(系统目录)
为了让DBMS解析元组,它需要维护一个内部的目录去告诉数据库的一些元信息。元信息包含数据库拥有哪些表和列以及他们的类型和值的顺序等信息。
大多数DBMS以表的形式在内部存储他们的目录,他们使用特殊的代码”引导“这些目录表。
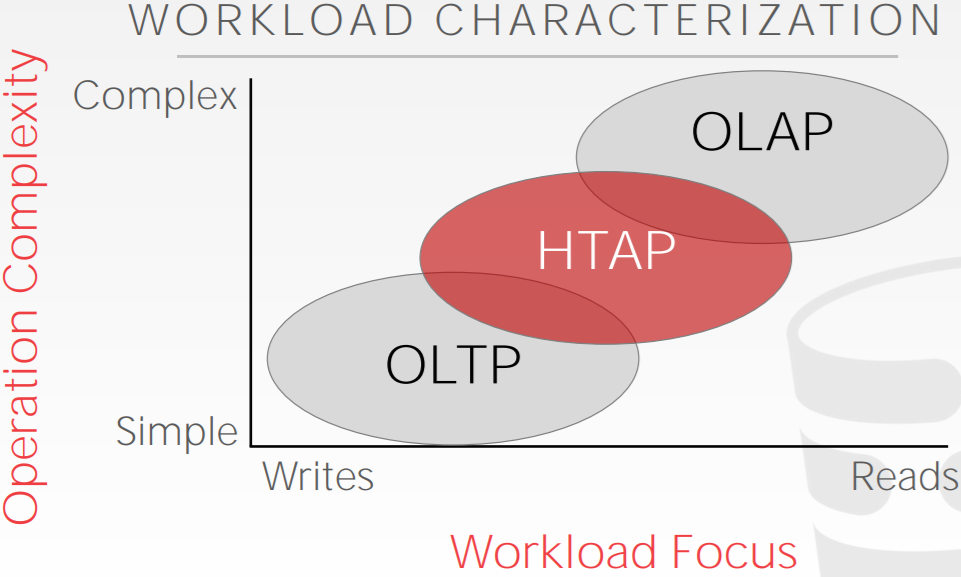
2 工作类型
数据库系统有许多不同的工作类型,工作类型指的是系统处理的请求的一般类型。这个课程将会专注于2个类型:在线事务处理(OLTP),在线分析处理(OLAP)。
OLTP: Online Transaction Processing(在线事务处理)
OLTP工作类型的特点是快速、短时间运行的操作,一次操作单个实体的简单查询和重复查询。
OLTP工作类型的一个例子是Amazon storefront。用户可以添加商品到购物车,可以下单购买,但是这些操作只影响一个账户。
OLAP: Online Analytical Processing(在线分析处理)
OLAP工作类型的特点是长时间、复杂的查询,对数据库大量数据的读取。在OLAP工作类型中,数据库系统专注于分析,并从OLTP数据库中获取新数据(一般为同步链路)。
OLAP工作类型的一个例子是Amazon对某些地理位置计算一个月内购买最多的5件商品。
HTAP: Hybrid Transaction + Analytical Processing(混合事务分析处理)
最近流行的一种新型工作类型是HTAP,它类似于在同一个数据库上同时执行OLTP和OLAP的组合。
3 存储模型
在页中存储元组有很多种方式,到目前为止,我们假设n维存储模型。
N-Ary Storage Model(NSM n维存储模型)
在n维存储模型中,DBMS将一个元组的所有属性连续的存储在单个页中,所以NSM又称为“行存”。这种方法是OLTP工作类型的理想选择,因为在OLTP场景下,数据是大量插入的,事务只操作单一的实体。DBMS只需要单次获取就能获取一个元组的所有属性。
优点:
- 快速插入、更新和删除。
- 对需要整个元组的查询友好。
缺点:
- 对大范围的扫描和查找一部分属性不友好,因为在查询中可能会获取不必要的数据来污染缓冲池。
Decomposition Storage Model(DSM 分解存储模型)
在分解存储模型中,DBMS将一个单独的属性(列)连续的存在一个块中。因此,这也被称为“列存”。该模型非常适合许多具有只读查询的OLAP工作类型,OLAP经常对一部分属性进行大范围扫描。
优点:
- 减少查询过程中浪费的数据,因为DBMS只读取查询所需的数据(制度去查询所需的属性)。
- 由于对同一属性的所有值连续存储,因此可以获得更好的压缩性能(或使用特定的压缩)。
缺点:
- 由于每个元组被存在不同的地方,因此对文件的点查、插入、更新和删除不友好。
![]()
为了将列存的元组组合回去,一般有2种常见的方法:
大多数使用的方法是*固定长度的偏移*。假设每个属性都是固定长度的,DBMS可以计算出每个元组中每个属性的偏移,然后当想要一个特定元组的属性的时候,它知道如何去跳转到某个文件某个位置。为了容纳可变长度的字段,系统可以填充字段来达到相同长度或者使用固定长度的字典来映射值(将超出长度的值存到另外的文件中并用字典记录偏移)。
另一个小众的方式是使用*嵌入式元组id*。对每个在列中的属性,DBMS同时存储一个元组id(例如主键)。系统会存储一个映射告诉如何找到每个属性id所对应的位置。但这个方法会浪费很多的存储空间,因为每个属性都会存储一个元组id。
![]()
2021年秋季版 CMU数据库15-445/645 Note1~4相关推荐
- 2021年7月国产数据库排行榜:openGauss成绩依旧亮眼,Kingbase向Top 10发起冲刺
7月份的国产数据库流行度排行榜已经揭晓.本期榜单展示的136个数据库中,近三分之二实现了评分增长.笔者认为这与6月份中国信通院发布第十二批大数据产品能力评测结果有关,65家企业的120款产品通过了本次 ...
- 2021年3月国产数据库排行榜:雏凤声清阿里三连 绝代双骄华为合璧
墨墨导读:2021年3月国产数据库流行度排行榜已经出炉,在本月排行的前十名中,TiDB 仍然以领先第二名 135分 的优势稳居榜首,OceanBase 本月积分大涨跃升至第二位,达梦则是降低一位至第三 ...
- 2021年9月国产数据库排行榜:达梦奋起直追紧逼OceanBase,openGauss反超PolarDB再升一位...
点击上方"蓝字" 关注我们,享更多干货! 2021年9月国产数据库排行榜已在墨天轮(https://www.modb.pro/dbRank)发布,本月参与排名的数据库总数达到了14 ...
- 2021年10月国产数据库排行榜:达梦反超OceanBase夺榜眼,TDSQL实现“四连增”,数据生态加速建设
2021年10月国产数据库排行榜已在墨天轮发布,本月共有150家数据库参与排名.我们可以用"半江瑟瑟半江红"来形容10月份数据库分数涨跌情况.除去分数没有变化的数据库,分数上涨和下 ...
- 2021年9月国产数据库排行榜-墨天轮:达梦奋起直追紧逼OceanBase,openGauss反超PolarDB再升一位
2021年9月国产数据库排行榜已在墨天轮发布,本月参与排名的数据库总数达到了142个. 一.9月国产数据库流行度排行榜前15名 先来看看排行榜前五名,虽然PingCAP的TiDB分数本月下降31.82 ...
- 2021年7月国产数据库排行榜:openGauss高歌猛进,GBase持续下跌
作者 | JiekeXu 来源 | JiekeXu DBA之路(ID: JiekeXu_IT) 大家好,我是 JiekeXu,很高兴又和大家见面了,今天和大家一起看看 2021 年 7 月国产数据库排 ...
- 2021年7月国产数据库排行榜:openGauss高歌猛进,GBase丢失第五
匆匆岁月,光阴如梭,2021 年上半年已经从指间划过,仲夏苦夜短,开轩纳微凉,墨天轮也已经更新了7月国产数据库流行度排行榜. 2021年7月墨天轮国产数据库排行榜 纵观榜首,前四名三个月来的位置均没有 ...
- 2021年6月国产数据库大事记
本文整理了2021年6月国产数据库大事件和重要产品发布消息. 6月国产数据库大事记 6月1日,在数据库 OceanBase3.0 峰会上,OceanBase CEO 杨冰宣布首个时序数据库产品 Cer ...
- 2021年12月国产数据库排行榜: openGauss节节攀升拿下榜眼,GaussDB与TDSQL你争我夺各进一位
2021年12月的国产数据库流行度排行榜已在墨天轮发布,本月共有189家数据库参与排名.为使国产数据库排名更加专业与客观,本月起,排行榜加入了三方评测.生态.专利数.论文数等新的指标.其中三方测评方面 ...
最新文章
- phplivechat安卓app下载_PHP在线网页客服系统PHP Live Chat中文版下载
- Java中传参数--值传递和引用传递
- 这个AI“大师级”简笔画水平,惊艳到了网友:竟然不用GAN
- 共享内存 Actor并发模型到底哪个快?
- tf.reshape()
- 精心准备了10个行业30张大屏模板,0代码直接套用
- android activity传值到dialog,android 自定义AlertDialog 与Activity相互传递数据
- Linux记录-重启后磁盘丢失问题解决方案
- [转载] Python 列表(List)
- 单引号、双引号和不加引号区别
- MATLAB 图像处理基础(2)
- 家谱族谱软件用云码宗谱
- 真实的软件测试日常工作是咋样的?
- html加减乘除除数不能为零,0不能做除数(数学中0为什么不能做除数)
- 真爱,就要失去自己?
- 坑向总结 | 树莓派调用打印机打印
- Redis 部署方式(单点、master/slaver、sentinel、cluster) 概念与区别
- 获取海康摄像机/录像机rtsp视频流地址格式
- 基于ssm框架的同城物流配送网站系统
- 论文翻译-Three Stream 3D CNN with SE Block for Micro- Expression Recognition