PrestoDB 大数据查询引擎
转自:http://www.oschina.net/p/facebook-presto
PrestoDB 大数据查询引擎
Presto是Facebook最新研发的数据查询引擎,可对250PB以上的数据进行快速地交互式分析。据称该引擎的性能是 Hive 的 10 倍以上。
PrestoDB 是 Facebook 推出的一个大数据的分布式 SQL 查询引擎。可对从数 G 到数 P 的大数据进行交互式的查询,查询的速度达到商业数据仓库的级别。
Presto 可以查询包括 Hive、Cassandra 甚至是一些商业的数据存储产品。单个 Presto 查询可合并来自多个数据源的数据进行统一分析。
Presto 的目标是在可期望的响应时间内返回查询结果。Facebook 在内部多个数据存储中使用 Presto 交互式查询,包括 300PB 的数据仓库,超过 1000 个 Facebook 员工每天在使用 Presto 运行超过 3 万个查询,每天扫描超过 1PB 的数据。此外包括 Airbnb 和 Dropbox 也在使用 Presto 产品。
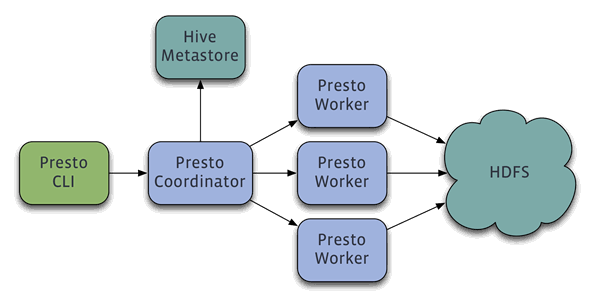
Presto 是一个分布式系统,运行在集群环境中,完整的安装包括一个协调器 (coordinator) 和多个 workers。查询通过例如 Presto CLI 的客户端提交到协调器,协调器负责解析、分析和安排查询到不同的 worker 上执行。
此外,Presto 需要一个数据源来运行查询。当前 Presto 包含一个插件用来查询 Hive 上的数据,要求:
Hadoop CDH4
远程 Hive metastore service
Presto 不使用 MapReduce ,只需要 HDFS

要求:
Mac OS X or Linux
Java 7, 64-bit
Maven 3 (for building)
Python 2.4+ (for running with the launcher script)
PrestoDB 大数据查询引擎相关推荐
- 全方位测评Hive、SparkSQL、Presto 等七个大数据查询引擎,最快的竟是……| 程序员硬核测评...
现在大数据组件非常多,众说不一,那么每个企业在不同的使用场景里究竟应该使用哪个引擎呢?易观Spark实战营团队选取了Hive.SparkSQL.Presto.Impala.HAWQ.ClickHous ...
- 开源大数据查询分析引擎
引言 大数据查询分析是云计算中核心问题之一,自从Google在2006年之前的几篇论文奠定云计算领域基础,尤其是GFS.Map-Reduce.Bigtable被称为云计算底层技术三大基石.GFS.Ma ...
- 大数据查询分析引擎比较
1.常见方案比较 首先,Hive/SparkSQL 在数据仓库的领域应用是比较广泛的,但是因为查询时延很难能够满足毫秒到秒级的要求,同时因为是离线计算,数据时效性也比较差. 其次,ES (Elasti ...
- Apache Flink 为什么能够成为新一代大数据计算引擎?
众所周知,Apache Flink(以下简称 Flink)最早诞生于欧洲,2014 年由其创始团队捐赠给 Apache 基金会.如同其他诞生之初的项目,它新鲜,它开源,它适应了快速转的世界中更重视的速 ...
- 上:Spark VS Flink – 下一代大数据计算引擎之争,谁主沉浮?
作者简介 王海涛,曾经在微软的 SQL Server和大数据平台组工作多年.带领团队建立了微软对内的 Spark 服务,主打 Spark Streaming.去年加入阿里实时计算部门,参与改进阿里基于 ...
- 分布式大数据多维分析引擎:Kylin 在百度地图的实践
2019独角兽企业重金招聘Python工程师标准>>> 1. 前言 百度地图开放平台业务部数据智能组主要负责百度地图内部相关业务的大数据计算分析,处理日常百亿级规模数据,为不同业务提 ...
- 帆软FineBI大数据Spider引擎——为海量数据分析而生
一.应用背景 随着各个业务系统的不断增加,以及各业务系统数据量不断激增,IT数据支撑方的工作变得越来越复杂.主要问题如下: 1.数据来自多个不同的系统,存在需要跨数据源分析,需要对接各种不同数据源等问 ...
- 轻量级大数据计算引擎esProc SPL,Hadoop Spark太重
前言 背景:随着大数据时代的来临,数据量不断增长,传统小机上跑数据库的模式扩容困难且成本高昂,难以支撑业务发展. 应对之法:很多用户开始转向分布式计算路线,用多台廉价的PC服务器组成集群来完成大数据计 ...
- 技术分享:如何用Solr搭建大数据查询平台
技术分享:如何用Solr搭建大数据查询平台 0×00 开头照例扯淡 自从各种脱裤门事件开始层出不穷,在下就学乖了,各个地方的密码全都改成不一样的,重要帐号的密码定期更换,生怕被人社出祖宗十八代的我,甚 ...
- Spark 凭什么成为最火的大数据计算引擎?
这年代,做数据的,没人不知道 Spark 是什么吧.作为最火的大数据计算引擎,现在基本上是各互联网大厂的标配了. 比如,字节跳动基于 Spark 构建的数据仓库,服务了几乎所有的产品线,包括抖音.今日 ...
最新文章
- 二叉树 2.0 -- 非递归遍历
- 通过Ajax方式上传文件(input file),使用FormData进行Ajax请求
- bootstrap之glyphicon字体图标
- matplotlib是python第三方库吗_python第三方库matplotlib
- MFC GDI+ 绘图
- 使用SVG绘制湖南地图
- CSS3实现的立体button
- sdk的安装与环境配置
- 栈判断字符串是否为中心对称_数据结构 Stacks 栈
- 转载: WebKit介绍及总结(一)
- CSFB和SRVCC
- Aviary集成心得
- SwiftUI Swift 内功之如何在 Swift 中进行自动三角函数计算
- Tomcat应用报redis超时的故事
- Synaptics蠕虫木马分析
- [ABC200F]Minflip Summation
- python修改csv某一列 读取csv移动文件
- 以红酒数据集分类为例做决策树的可视化
- Web服务器站点设置和IIS安装设置图解
- matlab unifit,【matlab】matlab在概率统计中的应用(二)