2019腾讯广告大赛总结
总结比赛的整个心情: 想找个比赛好好实践一下, 结果碰到了腾讯广告大赛, 所以直接找队友参加了. 因为开始比赛时间较晚, 组队太晚, 队友信心不足中途跑票, 经历了几次换队友之后才算是正式进入状态, 开始一路艰难前进到复赛的过程, 不过有点遗憾, 最后比赛数据太大, 加一波新特征需要1-2天的时间, 方案和想法陷入瓶颈, 所以最终比赛结果也只到复赛为止了. 没能有更好的成绩有点遗憾, 但是之后观看了赛后的视频后, 我觉得高手的实力真是强, 我解决实际问题的思维还是太粗浅了, 即使是知道各种理论技术但是仍然无法实际作出很好的效果,真是硬伤.. .. 不过确实是真正的学到很多东西. 尤其是观看和分析赛后视频, 我觉得大佬和我之间的差距可能有10个我... 我还是好好学习吧.. 以上是整个比赛的心(fei)情(hua)记录.
最有用的一句话: 一定要仔细观看最终结果的答辩视频, 真是的非常开拓思路.
1. 赛题理解
比赛分为初赛和复赛两个题目:
初赛是: 提供历史n天的曝光广告的数据(特定流量上采样), 包括对应每次曝光的流量特征(用户属性和广告位等时空信息)以及曝光广告的设置和竞争力分数;测试集是新的一批广告设置(有完全新的广告id, 也有老的广告id修改了设置), 要求预估这批广告的日曝光。
其实问题对应实际业务中的召回问题, 召回本质的本质是海量数据中快速找到匹配用户特征的大批样本, 做的海量的规则匹配, 所以其实模型的精细度要求不高, 对机器的性能要求很高. 但是在比赛中这点问题不存在.
但是比赛的难点是通过召回的广告记录和所有的广告预测曝光量, 因为召回的广告即使被召回了也会被各种业务策略和模型排序确定最终的CTR分数, 只有topk的广告会被展示, 那么从中间到最后展出的过程被缺失, 这种预测就很困难. 所以初期我们的模型非常粗暴. 全靠trick进入复赛.复赛是: 根据广告请求的竞价记录, 用户记录和所有广告特征预测广告的曝光量. 一个广告请求召回200个广告, 一个广告一天会多次请求召回.
问题对应的实际业务中的对精排过程, 只有被召回的广告才有机会曝光, 200个召回中大约有1-2被曝光.
问题的难点在与建模方式和数据的构建. 一种是直接建模, 一种是间接建模. 直接建模是统计每个广告每天的曝光量作为label, 直接预测最后的曝光量, 这种方式简单, 数据量小, 容易操作. 一种是间接建模, 预测被召回的广告是否被曝光, 统计最后的曝光. 这种方式需要将请求队列和广告拼接起来, 拼接后的数据量达到7亿, 服务器也没有办法支持处理, 同时,大量的广告是没有曝光的, 所以正负样本分布差距非常大, 对模型挑战很大. 所以我们最后选择了第一种方法, 把整个问题当作预估CTR问题来处理.- 评价指标:
- 单调性: 出价越高, 曝光量越高
- SAMPE: 对称均方根误差,

2. 建模方式
- 初赛是选用所有在一天中没有操作的广告数据, 我们认为没有操作的广告的出价和状态是可以完全对应当天的曝光数据. 但是现在分析看来, 我们对操作数据的分析太少, 没有仔细考虑每次操作的内容, 比如修改的是广告状态? 出价和还是目标人群? 后来发现操作数据几乎每次都是修改出价, 但是出价特征完全没有被用到, 所以一开始我的数据构造方式就太复杂. 观察队友发现, 队友保留所有操作数据的广告, 训练数据量有40万. 效果就很好.所以下次记住不需要把数据构造的太详细, 可以用多种构造方式, 比如抽取1个月的, 1个周的这样方式, 而不是用某些条件卡.
- 复赛是选用历史记录中所有召回的广告
3. 尝试模型
1. LR: 只使用ID特征和离散特征, LR的效果特别好, 但是随着加入数值特征, LR的效果越来越差, 即使在LGB模型已经验证过能提分的特征加入, 效果也特别差, 所以LR模型只能作为初期的简单模型.
2. LGB: LGB是我们比赛中重点使用的模型,也是所有参赛者广泛使用的模型, 很多参赛者的NN模型效果都没有LGB的效果好. LGB不需要处理缺失值和离散值, 随便就可以样本放进去的到的一个结果, 可以直接简单高效地验证想法, 所以我们一直用LGB做特征主模型和特征筛选. LGB的调参也主要调树的深度, 叶子节点的最小样本数量, 分类器数量, K折交叉验证, 强烈防止过拟合就可以.
3. LGB+LR: 分析LR模型不适合处理连续值, 所以我们用LGB离散化连续值, 将LGB的叶子节点位置输入到LR中, 效果也很不错.
4. LGB+FM: 因为LGB+LR的方法效果不错, 所以我们想如果换了更强的模型的话,效果应该会更好, 但是事实上, LGB+FM的效果很差, 比单独的LGB, LR和FM效果都差, 我们认为是FM模型因为要学习V向量, 大量的稀疏值使V向量学习不到位, 所以效果很差, 所以这也是经常看到树+LR, 但是看不到树+FM的原因吧, FM适合稠密向量, 所以一般用向量的embedding输入到FM可以取得很好的效果.
5. FM: 这是我们使用的第二好的模型, 和LGB使用一样的数据, FM模型就是可以直接提高0.2个点, 损失减低10+左右. 但是缺点是没有现成的特征权重输出, 不能作为特征选择器.
6. DIN: 这篇文章讲DIN,还不错可以参考: https://www.jianshu.com/p/73b6f5d00f46?utm_campaign=maleskine&utm_content=note&utm_medium=reader_share&utm_source=weibo
7. DIEN: 参考链接:https://ask.hellobi.com/blog/wenwen/18279
8. NFFM: 这是前几年的冠军模型, 被郭大开源出来了, 原理效果很强大, 原理很复杂, 使用也很复杂, 我们勉强使用上, 但是效果一般
9. AFM: Attention Factorization Machine, 也是阿里的前几年的模型, 使用效果也一般. 观察自身经验和其他队伍发现, NN模型效果确实没有想象中的那么好.
4. 不足之处
1. 我们主要花费了大量精力创造新特征, 但是新特征的效果都很差, 投入和产出严重不成比例
2. 构造数据时没有考虑时间窗口, 这也是我们比top10最大的差别, 他们几乎都把前10天, 前7天, 前3天, 昨天的历史数据作为特征,并且都取得了很好的成绩
3. 使用的NN模型效果都不好, 为什么不好, 我们没有仔细研究
4. 没有提出和改进现有的模型, 我们几乎是把现有的可用模型都用了一下,但是看所有的冠军视频发现, 他们都对模型进行了改造(损失函数和模型结构), 这也是我们之间的差距
5. 没有将ID和非ID特征分开建树
6. 没有将新旧广告分开5. 冠军方案学习
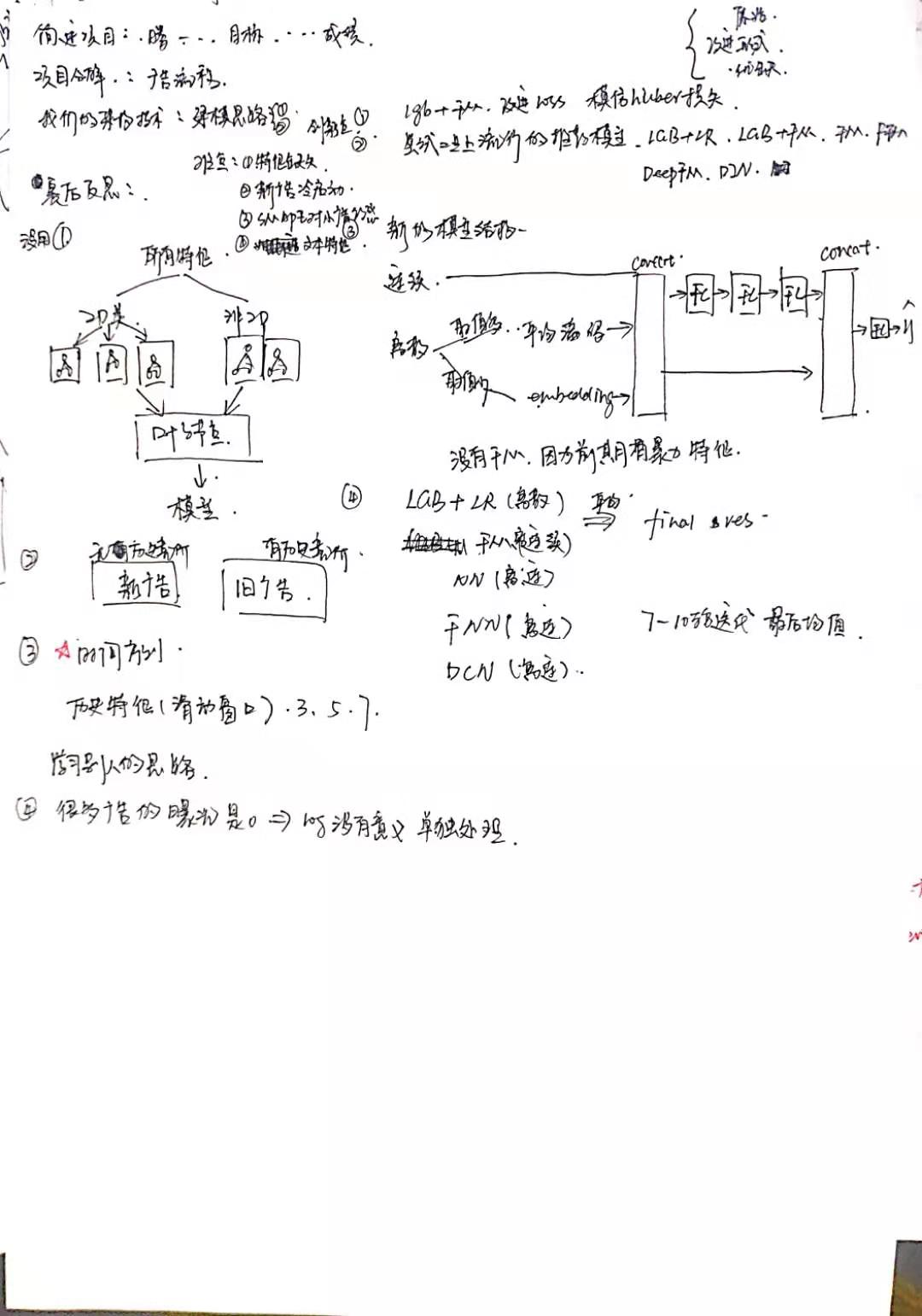
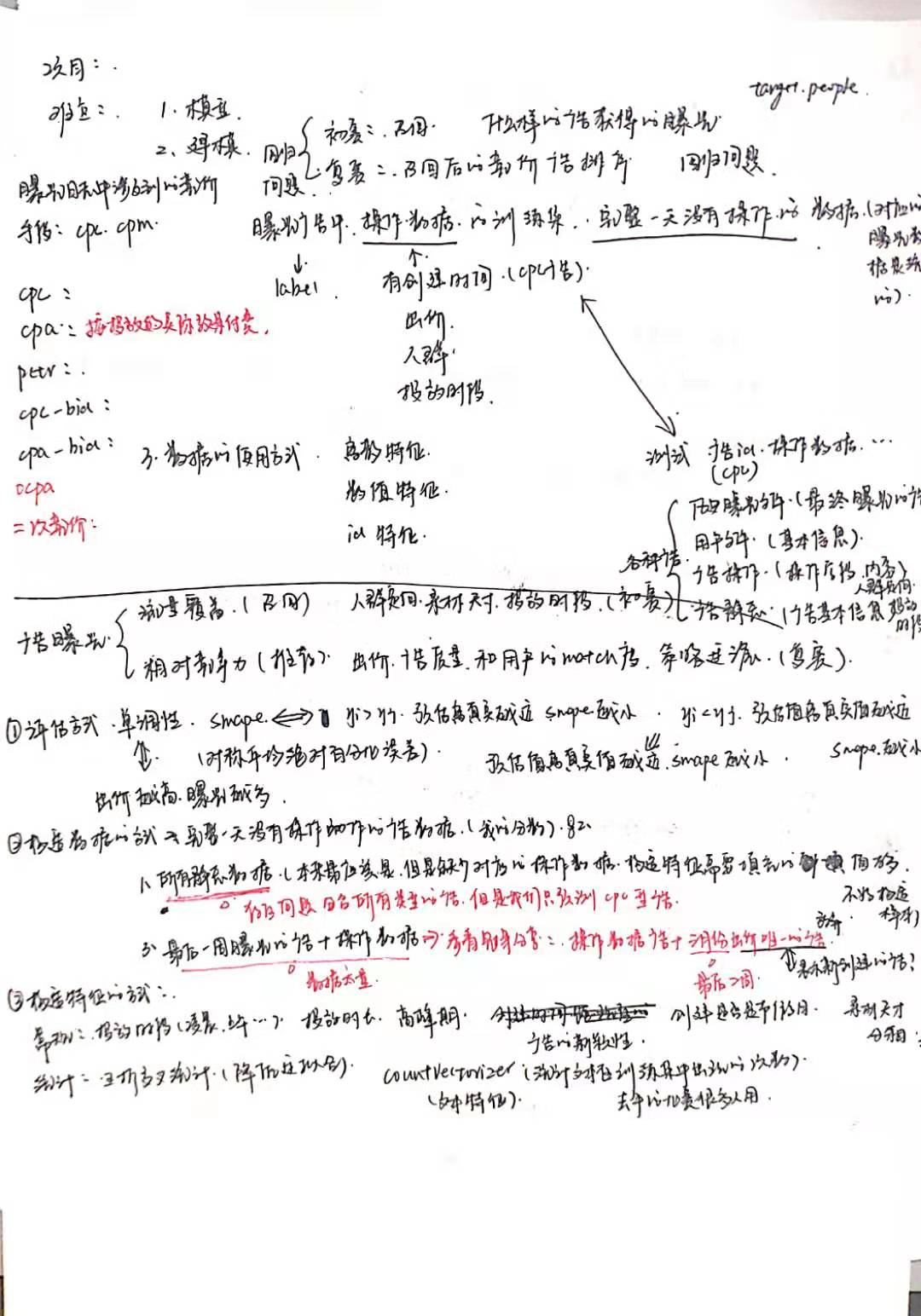
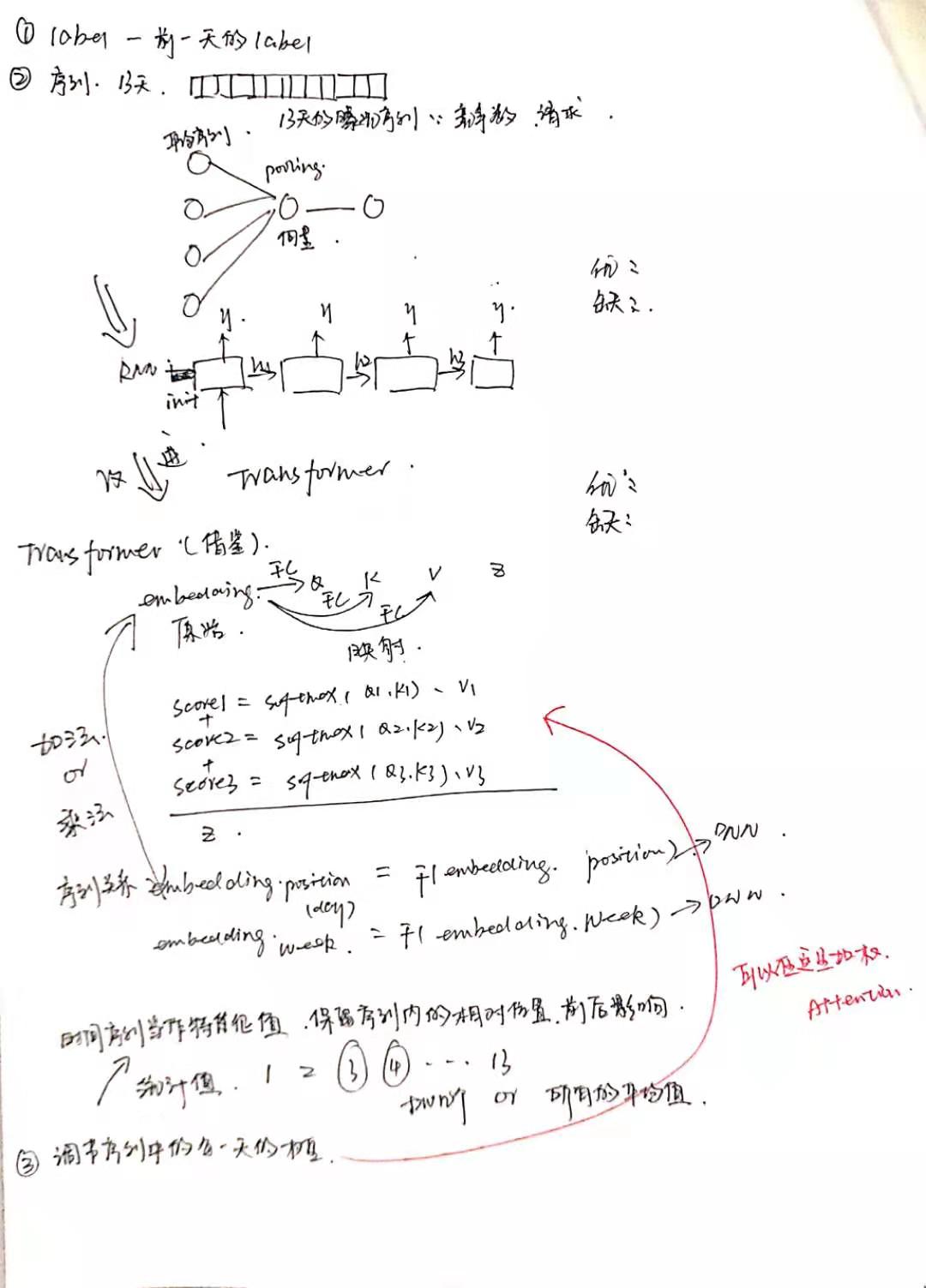
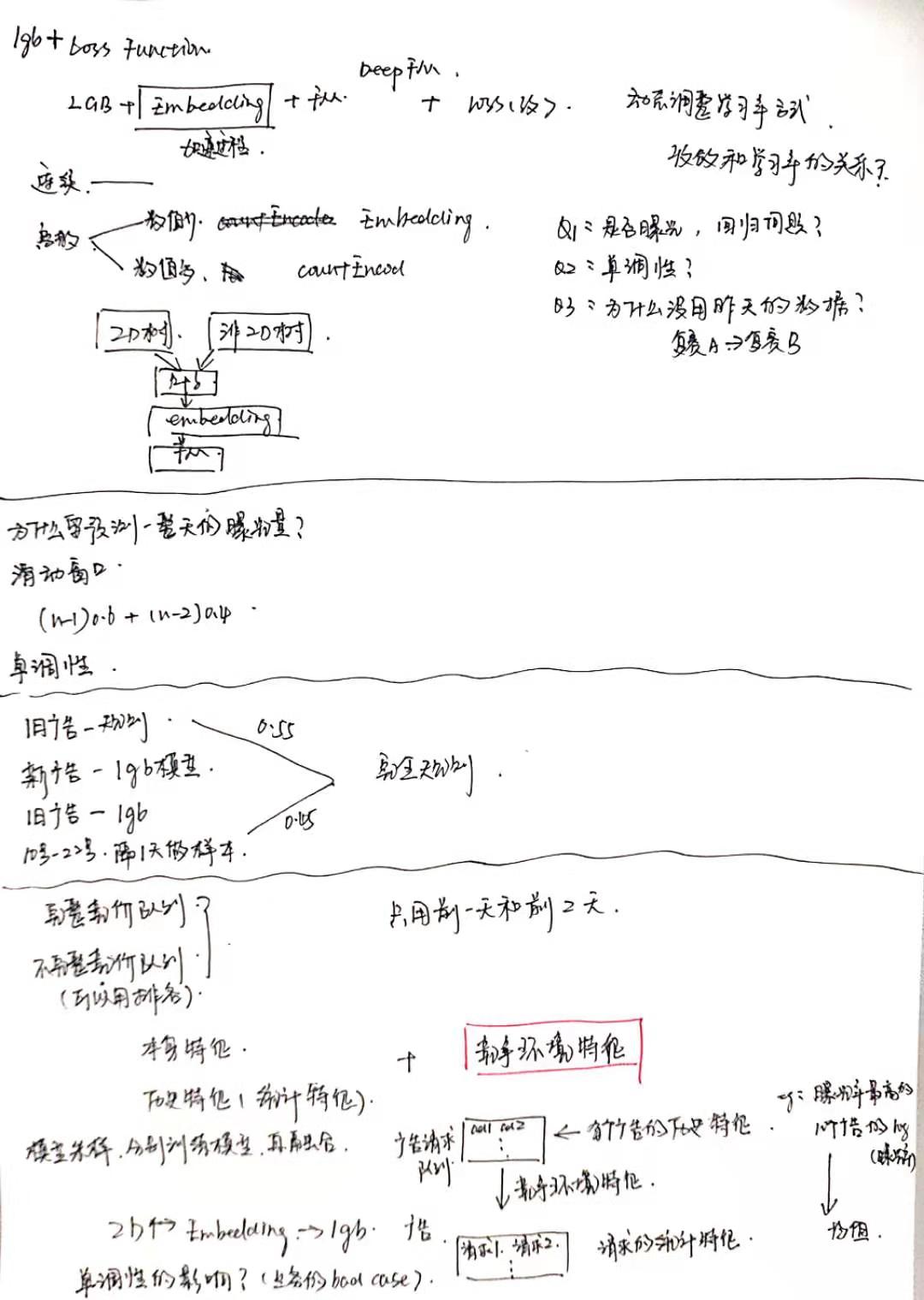
比赛答辩视频链接: https://view.inews.qq.com/a/ZLV2019070400475200?openid=o04IBAONoSbUZBrEEivHaI840UKQ&key=&version=1700042d&devicetype=iOS12.3&wuid=oDdoCt3Y0kvuuSxPi4I8CmWrEOb0&isShare=1&from=singlemessage&cv=0x70000001&dt=6&lang=zh_CN&pass_ticket=pHCeguGZAI8KatQNreoVvCDKfDDP7lZvD7tErQ1VvUkzMcHrf8ZE6YumbqxxWVzg
比赛记录的文件:
https://shimo.im/docs/ANpAeX6OxDkqKLFI
特征工程, 每次想到好的特征就记录下来 https://shimo.im/docs/U9DHxLTSFnMLyNBq
比赛方对题的说明 https://shimo.im/docs/PhgtExl0gBolUc9J
比赛中收藏的帖子:
冠军贴, 内容一般, 最后的方案还可以. https://zhuanlan.zhihu.com/p/72762888
deepctr库, 包含很多CTR模型, https://github.com/shenweichen/DeepCTR
鱼佬知乎
大赛经历 https://coladrill.github.io/2018/06/21/2018%E8%85%BE%E8%AE%AF%E5%B9%BF%E5%91%8A%E7%AE%97%E6%B3%95%E5%A4%A7%E8%B5%9B%E7%BB%8F%E5%8E%86/
https://zhuanlan.zhihu.com/p/64155946
https://www.jianshu.com/p/fc414615664c?utm_campaign=hugo&utm_medium=reader_share&utm_content=note&utm_source=weixin-friends
模型区别:可借鉴 https://www.zhihu.com/question/62109451/answer/196385050?from=singlemessage&isappinstalled=0&utm_medium=social&utm_oi=735466071745662976&utm_source=wechat_session&s_r=0
https://github.com/BruceWuLiangjian/My_Tencent2017_Final_Coda_Allegro-master
https://blog.csdn.net/Bryan__/article/details/79623239
https://github.com/DiligentPanda/Tencent_Ads_Algo_2018
https://github.com/nzc/tencent-contest TNNM 模型可以试一下!!
讲TNNM不错的文章 https://zhuanlan.zhihu.com/p/38443751
https://github.com/guoday/Tencent2018_Lookalike_Rank7th
https://github.com/ouwenjie03/tencent-ad-game
模型预估交叉验证 https://github.com/pinkmala/-ctr-/blob/master/TrainModel.ipynb
https://blog.csdn.net/weixin_42280517/article/details/82386749
[1] https://zhuanlan.zhihu.com/p/40479648
[2]https://zhuanlan.zhihu.com/p/38341881
[3]https://www.zhihu.com/question/20874105/answer/41562872 只看特征部分
https://www.zhihu.com/question/20874105/answer/41562872
转载于:https://www.cnblogs.com/x739400043/p/11218906.html
2019腾讯广告大赛总结相关推荐
- 2019腾讯广告算法大赛-冠军之路
点击上方"Datawhale",选择"星标"公众号 第一时间获取价值内容 写在前面 历时三个月腾讯广告算法大赛已经告一段落,在前两届成功经验的基础上,今年大赛在 ...
- 2019腾讯广告算法大赛完美收官,算法达人鹅厂“出道”
7月8日,2019腾讯广告算法大赛"终极之战"在深圳腾讯滨海大厦顺利举行.在前两届成功经验的基础上,今年大赛在赛题专业性和赛事体验上都有了更大的提升,进而吸引了更多海内外优秀选手参 ...
- 2019腾讯广告算法大赛 决赛 Rank16解决方案
2019腾讯广告算法大赛 决赛 Rank16解决方案 参考文章: (1)2019腾讯广告算法大赛 决赛 Rank16解决方案 (2)https://www.cnblogs.com/xianbin7/p ...
- 2019腾讯广告算法大赛方案分享(冠军)
写在前面 队伍介绍:哈尔滨工业大学二年级硕士生刘育源.中山大学微软亚洲研究院联合培养博士生郭达雅和京东算法工程师王贺. 本文将给出冠军完整方案,全文内容架构将依托于答辩PPT,具体细节也会结合代码进行 ...
- 2019腾讯广告算法大赛之清洗曝光广告数据集以及构造标签
首先是对清洗曝光广告日志中的脏数据进行清洗,脏数据主要包括三种情况, 第一: 该条广告记录中的广告ID不存在于静态广告数据和操作广告数据中,因为不存的话则该条数据无法构造训练集. 第二: 广告请求时间 ...
- 2019腾讯广告算法初赛第一名的模型
向AI转型的程序员都关注了这个号
- 一文梳理2019年腾讯广告算法大赛冠军方案
点击上方"Datawhale",选择"星标"公众号 第一时间获取价值内容 作为从本次比赛共157队伍中脱颖而出的冠军方案,评分达到87.9683,从数据清 ...
- 2020腾讯广告算法大赛分享(冠军)
写在前面 2019年冠军选手成功卫冕! 代码地址:https://github.com/guoday/Tencent2020_Rank1st 从初赛冠军.复赛冠军,然后到最佳答辩,一路披荆斩棘,再次感 ...
- 【数据竞赛】2020腾讯广告算法大赛冠军方案分享及代码
写在前面 2019年冠军选手成功卫冕!!! 代码地址:https://github.com/guoday/Tencent2020_Rank1st 从初赛冠军.复赛冠军,然后到最佳答辩,一路披荆斩棘,再 ...
- 备战2020腾讯广告算法大赛:(2017-2019比赛开源和数据等)
期待与各位在2020腾讯社交广告算法大赛中相遇!!! 写在前面 最近突然之间讨论腾讯广告赛的人多了不少,也有很多人加我微信讨论19年腾讯赛的方案和代码.虽然2020腾讯赛还未开始,不过大家已经提前进入 ...
最新文章
- goland go test_Go单元测试实践一,快速上手
- 服务器端调用智能合约,《精通以太坊:开发智能合约和去中心化应用》 ——3.4 远程调用以太坊客户端...
- 心电信号的PQRST模拟matlab代码(转载+自己调研汇总)
- typeorm_Nestjs 热更新 + typeorm 配置
- Java英雄:丹·艾伦
- 天地图卫星地图_AutoCAD使用卫星地图
- Android API Guides---Supporting Tablets and Handsets
- 化妆definer是什么意思_我们为什么说隔离霜是个智商税的东东!
- 使用flash在IPAD2上播放FLV效率不高
- java validate注解_JAVA 注解验证字段(例子)
- 关于TP中的M()方法与D()方法
- 关于“单元组”数量的计算
- 国际象棋游戏界面和简易棋谱规则-最新Python学习成果
- Android初学第32天
- 自我与人际沟通课程复习
- java会导致蓝屏么_电脑经常会蓝屏?可能是这些原因导致的
- 听听周报-谷歌发布首款真无线耳机 Pixel Buds|苹果发布全新头戴式耳机 Beats Solo Pro
- matlab如何绘制已知公式的曲线图,Excel怎么绘制函数曲线图像?
- 用NI的数据采集卡实现简单电子测试之2——绘制三极管输出特性曲线(面)图...
- 一周搜索热点20170528
热门文章
- 计算机键盘正确手势,打字时如何正确放置手指 正确的键盘打字手势(图文)...
- 毕业论文参考文献格式GB/T 7714的Endnote设置教程
- GAMIT/GLOBK处理流程
- mac java报内存不足_苹果电脑显示内存不足怎么办_mac提示内存不足的解决方法-系统城...
- Java 6-3 锥体体积计算
- 复习步骤7-获取权限数据CustomRealm提供subject桥梁,集成spring - 数据库获取用户权限角色等信息-shiro加密密码和盐存入数据库
- Python 计算平方数
- 计算机网络接口 rj45类型,网卡:网线接口类型(RJ45/BNC/AUIFDDI/ATM接口) -电脑资料...
- 路由器2.4G和5G有什么区别
- Mac安装 nginx (极简)