python倾向匹配得分_倾向评分匹配的SPSS和R实现方法
SPSS在22版和23版加入了倾向评分匹配方法,笔者多次操作,程序界面还算友好,现给大家展示一下,供初次使用者参考。
如下图,一个数据,包括了id(病例的唯一编码)、group(干预方法)、cf1-cf6(六个混杂因子)。
操作方法:1.点击“数据”-“倾向得分匹配”,如下图:

2.弹出下图对话框,组指示符选择“group”,即干预因素,须为二分类变量;预测变量框里选入所有混杂因素,倾向变量名即每个个体的倾向评分得分变量名,可随意填写(字母或字母加数字)、匹配容差可从较小的数值填写,根据情况填写;匹配id变量名,即可输出一个变量,告诉我们每个case的匹配对象的id;数据集名称可自行填写。点击确定可得到匹配结果。

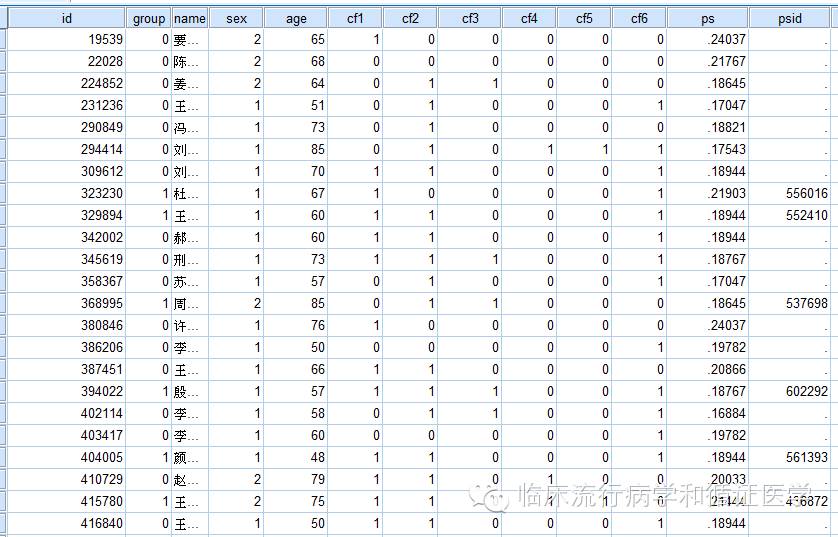
可以在下图中看到,在我们的变量后面多了两个新变量,ps即每个case的倾向得分,psid即匹配对象,第一个19539未能匹配,第八个323230匹配对象的id是556016,依次类推。
另外SPSS会将所有匹配的对象重新筛选出来生成一个新的数据,即可以用于分析的数据。
在用SPSS做倾向评分匹配时应注意:1.SPSS安装需要同意安装Python Essentials插件,否则无法使用;2.所有用于分析的变量名和界面填写的变量名必须是英文或英文加数字,不能是中文;3.匹配容差需要根据实际情况确定,如两组样本量差异较大(两组差10倍以上),可以用较小的容差,如0.001,如较小容差不能匹配,再将容差调大后重试;4.完成匹配后应对两组进行均衡性检验;5.如果一个个体有多个匹配对象,程序会从中随机选择,因此每次运行可能得到的匹配结果不同;6.SPSS程序只能进行1:1匹配。
在R程序中,提供了1:n匹配,以及多类匹配方法,现常使用MatchIt程序包进行匹配,实现起来也很容易。现将程序及说明附在下面,使用时修改相关的变量名即可。(#后为说明文字,在R中不运行)
installed.packages("MatchIt") #安装MatchIt程序包,用于匹配
library(MatchIt) #加载MatchIt程序包
installed.packages("foreign") #安装foreign程序包,用于读取SPSS数据
library(foreign) #加载foreign程序包
mydata=read.spss("E:/data3.sav") #读取数据到mydata
names(mydata) #查看数据变量名
mydata=data.frame(mydata) #将mydata转换成数据框
attach(mydata) #绑定mydata
m.out = matchit(group ~cf1 + cf2 + cf3 + cf4 + cf5 + cf6,
data = mydata, method ="nearest",
ratio = 4)
#匹配过程,method包括"exact" (exactmatching), "full" (full matching), "genetic" (geneticmatching), "nearest" (nearest neighbor matching), "optimal"(optimal matching), "subclass" (subclassification) are available.默认为"nearest".
#ratio可设置匹配比例
summary(m.out) #查看匹配情况
plot(m.out, type ="jitter") #查看匹配前后货币评分分布图
m.data1
write.csv(m.data1, file="E:/psm20160121.csv") #导出匹配数据成CSV格式,供后续分析使用.
python倾向匹配得分_倾向评分匹配的SPSS和R实现方法相关推荐
- python倾向匹配得分_在SPSS软件中实现1:1倾向性评分匹配(PSM)分析
谈起临床研究,如何设立一个靠谱的对照,有时候成为整个研究成败的关键.对照设立的一个非常重要的原则就是可比性,简单说就是对照组除了研究因素外,其他的因素应该尽可能和试验组保持一致,随机是最理想的策略!通 ...
- python倾向匹配得分_手把手教你做倾向评分匹配 -PSM
原标题:手把手教你做倾向评分匹配 -PSM 本文首发于"百味科研芝士"微信公众号,转载请注明:百味科研芝士,Focus科研人的百味需求. 各位科研芝士的朋友大家好,今天和大家分享一 ...
- python倾向匹配得分_临床研究的最后一道防线(四):倾向性评分匹配PSM在Python的实现...
临床研究的最后一道防线(四):倾向性评分匹配(propensity score matching, PSM) 在Python的实现 No.25介绍了SPSS实现倾向性评分匹配(propensity s ...
- python倾向匹配得分_数据分析36计(九):倾向得分匹配法(PSM)量化评估效果分析
1. 因果推断介绍 如今量化策略实施的效果评估变得越来越重要,数据驱动产品和运营.业务等各方的理念越来越受到重视.如今这方面流行的方法除了实验方法AB testing外,就是因果推断中的各种观察研究方 ...
- python字符串排序_列表中字符串按照某种规则排序的方法(python)
原博文 2017-05-05 16:35 − 有时候处理数据时,想要按照字符串中的数字的大小进行排序. 譬如,存在一组记录文件,分别为'1.dat','2.dat'... 当我把该文件夹中的所有记录文 ...
- python打分函数_自定义评分函数RandomForestRegress
RandomizedSearchCV中的评分函数将只计算网格中指定的每个超参数组合的模型预测数据的得分,测试折叠中平均得分最高的超参数获胜.在 它不会以任何方式改变RandomForest内部算法的行 ...
- python dataframe遍历_在pandas中遍历DataFrame行的实现方法
有如下 Pandas DataFrame: import pandas as pd inp = [{'c1':10, 'c2':100}, {'c1':11,'c2':110}, {'c1':12,' ...
- python 取反_自从用了这招pandas 空数据处理方法,python编程速度提升了不少
今天为大家带来的内容是:自从用了这招pandas 空数据处理方法,python编程速度提升了不少 文章内容主要介绍了pandas 空数据处理方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工 ...
- python 卡方检验 特征选择_结合Scikit-learn介绍几种常用的特征选择方法
特征选择(排序)对于数据科学家.机器学习从业者来说非常重要.好的特征选择能够提升模型的性能,更能帮助我们理解数据的特点.底层结构,这对进一步改善模型.算法都有着重要作用. 特征选择主要有两个功能: 减 ...
最新文章
- Metasploit远程调用Nessus出错
- ndk error: malloc was not declared in this scope
- Linux下目录/文件颜色的含义
- 通过练习题学习磁盘知识
- 计算机中隐藏的文件找不到了怎么办,我的计算机找不到隐藏文件,是怎么回事啊...
- React后台管理系统-首页Home组件
- 没数据时y轴不显示_Matplotlib数据可视化
- shell进入特权模式_GRUB引导下进Linux单用户模式的三种方式,修改root密码
- 如何删除后缀.Tater勒索病毒并解密.tater勒索病毒加密的病毒文件
- 热电偶测温方案 AD7124+Pt100冷端补偿
- C# Gooflow+layer弹出层 全js代码
- 回归系数t检验公式_最全物理公式合集,高考这一份就够了!
- 常见的宏观经济指标介绍
- android studio 底部工具栏,教大家android studio工具栏不见了如何找回
- 狂神学习系列18:Redis
- HTML实现猜数字游戏
- C#生成不重复随机数(随机宝箱)
- Java 后端服务的跨域处理
- 数码管显示“0~F”的共阳共阴数码管编码表
- python爬取贝壳找房之北京二手房源信息