网络、浏览器专题重点知识(含原理)
文章目录
- 一、前言
- URL 和 URI
- 二、互联网如何运作?/ 浏览器怎么通过互联网获取到网页数据的
- 三、输入url到页面展示经历的步骤
- 3.1 宏观层面
- 3.2 微观层面的详细流程
- 1. 用户输入URL
- 2. URL请求过程
- (1)查找缓存
- (2)DNS解析获取IP地址(具体DNS的说明可见七)
- (3)建立TCP连接:TCP 三次握手
- (4)浏览器发送 HTTP 请求
- (5)服务器处理请求并响应数据
- (6)断开连接:TCP 四次挥手
- 3. 准备渲染进程
- 4. 提交文档
- 5. 浏览器解析渲染页面
- 四、浏览器是如何运作的?
- 4.1 不同浏览器的内核
- 4.2 浏览器的多进程结构
- 4.3 chrome 的4种进程模型
- 4.4 当在浏览器地址栏输入内容时,浏览器内部会发生什么事情?(更详细的见三)
- 1. 用户输入URL阶段+DNS+请求数据+处理和返回数据
- 2. 渲染页面阶段
- 3. 重排重绘
- 4. 优化重排重绘带来的页面动画卡顿的问题
- 5. 渲染流水线
- 6. 渲染流程总结
- 五、JS 的运行原理(重点:JS 引擎)
- 5.1 js 继承了以下四种语言各自的特性
- 5.2 奇怪的 js
- 5.3 JIT
- 5.4 JS 引擎
- js引擎执行的大致流程(新V8)
- 5.5 以 V8 为例了解 JS 引擎编译和优化 JS
- 1. 早期的V8引擎
- 2. 新的V8架构
- 3. 新的V8引擎在处理JS过程中的一些优化策略
- 4. deoptimization
- 5. 新V8架构的好处
- 六、跨域问题
- 6.1 出现跨域的原因
- 6.2 跨域的概念
- 6.3 非同源的限制
- 6.4 跨域解决方法
- 1. 通过 JSONP 跨域
- 2. 跨域资源共享(CORS)
- 前端设置
- 后端设置
- 3. nginx 代理跨域
- 1)nginx配置解决iconfont跨域
- 2)nginx反向代理接口跨域
- 4. nodejs 中间件代理跨域
- ① 非vue框架的跨域(2次跨域)
- ② vue框架的跨域(1次跨域)
- 5. document.domain + iframe 跨域
- 6. location.hash + iframe 跨域
- 7. window.name + iframe跨域
- 8. postMessage跨域
- 9. WebSocket协议跨域
- 七、DNS到底是什么?
- 1. DNS的解释
- 2. DNS劫持/DNS污染
最近在面试,网络的知识问的比较多也比较深,特别涉及到一些原理和实现方法的问题就比较难,本文主要记录的是浏览器运行和渲染,互联网运行,JS运行的原理知识,其中还涉及到很多细节的知识,如果你感兴趣的话,就接着往下看8,希望你有点耐心,看完你一定会有收获的!也欢迎你和我交流探讨,指出我的错误!
一、前言
URL 和 URI
URL(Uniform Resource Locator),统一资源定位符,用于定位互联网上资源,俗称网址。
URI是Web上可用的每种资源 - HTML文档、图像、视频片段、程序,由一个通用资源标志符(Universal Resource Identifier, 简称"URI")进行定位。
URL 的格式由下列三部分组成::
- 第一部分是协议(或称为服务方式);
- 第二部分是存有该资源的主机IP地址(有时也包含port号);
- 第三部分是主机资源的详细地址。
URI 一般由三部分组成:
- 访问资源的命名机制。
- 存放资源的主机名。
- 资源自身的名称。由路径表示。
URL 和 URI 的区别
| URL 和 URI 的区别 |
|---|
| URL(统一资源定位符)主要用于链接网页,网页组件或网页上的程序,借助访问方法(http,ftp,mailto等协议)来检索位置资源。相反,URI(统一资源标识符)用于定义项目的标识,此处单词标识符表示将一个资源与其他资源区分开,而不管使用的方法(URL或URN) |
| URL是URI的一种,是URI命名机制的一个子集 |
| URL指定要使用的协议类型,而URI不涉及协议规范 |
二、互联网如何运作?/ 浏览器怎么通过互联网获取到网页数据的
从小问题入手:如何访问问哔哩哔哩站点的数据?
当我的电脑连入互联网之后,将会获得一个编号地址(Internet Protocol address IP地址),现在 bilibili 的服务器也连入互联网,也分的一个IP地址,常说的访问某某网站,其实就是访问的这个网站的服务器。
假设我的电脑想通过访问 index.html 来获取 b 站首页内容,此时就称我的电脑为客户端(面向客户的应用程序),B站服务器为服务端,即客户端-服务端模型。客户端通过互联网和服务端通信。客户端给服务器发送消息说想要获取 index.html 内容,消息就转化为电子信号,通过电缆传输给B站的服务器,在服务器端电子信号将转化为计算机可以使用的文本数据,这一切的实现都是通过 TCP/IP 协议族 实现的。
TCP/IP协议族有四层:
- 应用层:提供特定于应用程序的协议 HTTP、FTP、IMAP(邮件)
- 传输控制层:发送数据包到计算机上使用特定的端口号的应用程序
- 网络层:使用IP地址将数据包发送并路由到特定的计算机
- 链路层:将二进制数据包与网络信号相互之间转换
IPv4 地址空间是2^32次方,IPv6(128位) 是:2^128
在b站这个例子中:
![]()
- 首先使用应用层的 HTTP 协议请求获取 HTML 文本,需要发送一个消息,消息在发送前会被分解为许多片段(称为数据包);
- 进入传输控制层中的 TCP 层后,每个数据包都会被分配一个端口号, TCP是面向连接的可靠的字节流的服务协议。 可靠是因为必须经过3次握手建立连接后才能传输数据;
- 进入网络层中的IP层后,每个数据包将会赋予目标计算机的IP地址,其中每个数据包都是独立的。IP 是不可靠的无连接协议,所以有可能会乱序到达目标地址或在传输过程中丢失,这些问题都交给 TCP 来处理。当数据包过大时,在IP层会进行分包,由于在物理链路层每个数据包走的物理链路,传输速度也不一样,就导致数据包没有按顺序到达目的地,当 TCP 会根据数据包上携带的序列号来进行排序重组,且发送方在一定时间内没有收到接收方的 ack 时,则发送方会重新传送该数据包;
- 链路层将数据包的文本信息转换为电子信号,通过电缆传输,在电缆另一端的路由器检查每个数据包的目标地址,并将其发送到目标地址,最终数据包到达服务器;
- 然后数据包从TCP/IP 协议族的底部开始向上运行,客户端添加的所有路由数据(IP地址、端口号)都将从数据包中剥离出来,当到达栈顶应用层时,数据包恢复成最初识的形式,通过端口号将数据传送给当前服务器,监听该端口的应用程序,应用程序根据当前请求数据做出反应,返回的内容将以同样的方式返回给我的电脑。
更广的角度看互联网是怎么运作的?
- 首先我们的电脑通过调制解调器 modem(“猫”),”猫“将电子信号转换成可沿普通电话传线送的模拟信号后,在公共电话网络进行传输;
- 公共电话网络通过连接 ISP(Internet Service Provider 互联网服务提供商,如:移动、联通)来接入互联网,数据包经过电话网络和 ISP 后,路由到ISP的主干网络,数据包通常会从此经过多个路由器,并经过多个主干网直到找到目的地;
- 互联网主干网由许多相互连接的大型网络(网络服务提供商 NSP)组成,NSP是为ISP提供网络主干服务的公司,ISP从NSP那里批量购入带宽,为客户提供网络接入服务,NSP网络通过网络访问点NAP相连来交换数据包流量,每个NSP都必须连接到至少3个网络访问点,数据包流量可能会通过NAP从的NSP的一个主干跳到另一个NSP的主干。
互联网很复杂,那互联网是如何帮助数组包找到正确的路线吧数据包送到目的地呢?
答:都是依靠路由器!!!
路由器上的路由表记录了其子网络的所有IP地址,不知道上层网络所包含的IP地址,当数据包到达路由器,路由器检查路由表上是否由目的地的IP地址,如果有则直接发给那个网络,否则就向上层发送数据去寻找该IP的路由器,直到到达NSP主干网为止,连接到NSP骨干网的路由器具有最大的路由表,通过该表可以将数据包路由到正确的骨干网,然后开始向下传播进入越来越小的网络直到找到目的地为止。
但我们不可能记住每个网站的IP地址,这就出现了域名和DNS(分布式数据库),DNS记录了域名和IP地址的对应关系,当一个网站的IP地址变化后,只需要重新绑定域名和IP的对应关系,而不会影响到用户的操作,因为用户还是使用的域名访问,在浏览器中输入网址时,浏览器首先连接到DNS服务器,获取到该域名的IP地址后,浏览器再连接访问该 IP 的服务器。
![]()
![]()
三、输入url到页面展示经历的步骤
3.1 宏观层面
在整个过程中,浏览器的主进程、渲染进程和网络进程参与了工作,它们的主要分工如下:
- 浏览器进程:主要负责管理各个子进程、页面交互和文件存储功能
- 渲染进程:主要负责将网络进程中加载好的HTML、CSS、Javascript 和图片等资源进行解析渲染,(对于 Chrome 来说其渲染引擎 blink 和 JS 解析引擎 V8 都是在这个进程中工作的)
- 网络进程:主要负责发起HTTP请求,将服务器返回的资源进行下载
从浏览器进程的角度来分析输入URL到页面展示经历的过程:
- 浏览器进程接收到用户输入的URL地址后,会将其URL地址转发给网络进程;
- 网络进程发起真正的HTTP请求;
- 随后,网络进程接收到服务器返回的响应头数据,开始解析响应头数据,并将数据转发给浏览器主进程;
- 浏览器主进程接收到响应头数据,发送一个名为"提交文档”的消息给渲染进程;
- 渲染进程接收到该消息之后,便和网络进程建立一个管道,开始准备接收HTML数据;
- 之后,渲染进程向浏览器主进程发送一个"确认提交"的信息,此时便等于告诉浏览器可以开始接收和解析数据了;
- 浏览器进程中接收到渲染进程"确认提交"的消息之后,便开始移除旧的文档,更新页面。
![]()
3.2 微观层面的详细流程
1. 用户输入URL
判断输入的URL 是否符合URL 规范,如果符合地址栏根据输入的内容加上协议,组成完整的URL,比如:baidu.com> https://baidu.com
用户回车或者开始搜索的时候,表示当前页面将要被替换;标签页面的图标进入的加载状态,但是页面还是旧的页面,需要等待提交文档阶段;
2. URL请求过程
(1)查找缓存
首先查询浏览器本地是否缓存了需要请求的资源:
- 如果有缓存,直接返回给浏览器进程;
- 如果没有缓存,重新进行网络请求;
(2)DNS解析获取IP地址(具体DNS的说明可见七)
- 浏览器会首先查看本地硬盘的 hosts 文件,查看其中有没有和这个域名对应的IP地址,如果有就直接使用 hosts 文件里面的 IP 地址和服务器建立连接;
- 如果没有,浏览器会发出一个 DNS请求到本地DNS服务器 ;
- 本地DNS服务器会首先查询它的缓存记录,如果缓存中有此条记录,就可以直接返回结果,此过程是递归的方式进行查询。如果没有,本地DNS服务器还要向DNS根服务器进行查询;
- 根DNS服务器没有记录具体的域名和IP地址的对应关系,而是返回域服务器的地址。这种过程是迭代的过程;
- 本地DNS服务器继续向域服务器发出请求,域服务器收到请求之后,返回域名解析服务器的地址;
- 本地DNS服务器向域名解析服务器发出请求,域名解析服务器收到请求之后,返回域名与 ip 映射关系信息,然后本地 DNS 服务器将 ip 地址返回给用户电脑,同时将映射信息保存到其缓存中,以备下次别的用户查询时快速反应。
![]()
![]()
(3)建立TCP连接:TCP 三次握手
![]()
![]()
核心思想:TCP 为什么要 3 次握手?其原因是客户端需要确认服务器端的发送和接收能力完好,服务器端也需要确认客户端的发送和接收能力完好。
- 第一次握手:服务端可以确定客户端的发送功能完好;
- 第二次握手:客户端可以确定服务端的发送和接收功能完好,但此时服务端还不能确定客户端的接收功能是否完好,所以需要第三次握手告诉服务器客户端能够接收;
- 第三次握手:服务器端确认客户端接收功能完好。
(4)浏览器发送 HTTP 请求
一个HTTP请求报文由请求行(request line)、请求头部(header)、空行和请求实体4个部分组成。浏览器端开始构建请求行、请求头和请求体等信息,将浏览器的一些基础信息和cookie等信息添加到请求头中,然后向服务器发送构建好的请求报文。
(5)服务器处理请求并响应数据
服务端接受到请求报文之后,会根据报文信息生成响应头、响应行和响应体等数据,等网络进程接受到响应头和响应行之后,就可以解析响应头中的内容。等网络进程解析完成响应头信息之后,将会将其转发给浏览器进程处理。
影响后续流程的两个信息:
响应行中的301/302状态码 执行重定向
解析响应头时还需要注意一个重定向的操作:如果返回的是响应行信息为301/302,代表需要进行重定向至其他URL地址,此时网络进程会从响应头中读取到location字段的值,并重新发起http/https请求。响应头中的Content-Type
网络进程会首先基于响应头中的Content-Type字段来确定服务器返回的何种类型的资源文件,因为不同的资源类型浏览器对其处理不一样:如果这里接收到的是一个text/html类型的文件的话,那么意味这是一个HTML类型的文件,此时网络进程将响应头数据转发给浏览器进程,浏览器进程就通知渲染进程要准备渲染了。
而如果是一个application/octet-stream也就是二进制字节流类型的文件,那么浏览器会将其提交给下载管理器进行下载。
(6)断开连接:TCP 四次挥手
![]()
![]()
核心思想:TCP为什么需要四次挥手?其原因是:释放连接是释放双向的连接,客户端到服务器端 and 服务器端到客户端。具体一点来说,就是确认客户端和服务端的发送和接收功能都关闭;
- 第一次挥手:服务器知道客户端关闭了发送功能;
- 第二次挥手:客户端知道服务器关闭了接收功能;经过一二次挥手,客户端到服务端的连接就关闭了,但此时服务器端到客户端的连接依旧还在,也就是说,服务器还可以向客户端发送消息,客户端也可以接收;
- 第三次挥手:客户端知道服务器关闭了发送功能;
- 第四次挥手:服务器知道客户端关闭了接收功能;
3. 准备渲染进程
- 服务器返回响应体,并且Content-Type 类型不是下载,这时候要进入渲染进程;
- 浏览器主进程会为每一个标签页都准备一个渲染进程,但是如果几个页面是同一个站点一个根源(站点与站点之间的协议和根域名相同,那么根域名下的所有子域名以及所有端口号组成的站点都属于同一站点),如果从一个页面打开了另一个新页面,而新页面和当前页面属于同一站点的话,那么新页面会复用父页面的渲染进程;
- 渲染进程准备好之后,还不能立即进入文档解析状态,因为此时的文档数据还在网络进程中,并没有提交给渲染进程,下一步就是提交文档阶段。
4. 提交文档
- 当浏览器进程接收到网络进程的响应头数据之后,便向渲染进程发起“提交文档”的消息;
- 渲染进程接收到“提交文档”的消息后,会和网络进程建立传输数据的“管道”;
- 等文档数据传输完成之后,渲染进程会返回“确认提交”的消息给浏览器进程;
- 浏览器进程收到消息之后,开始更新页面的状态,包括了安全状态、地址栏的 URL、前进后退的历史状态,并更新 Web 页面。
5. 浏览器解析渲染页面
一旦文档确认提交之后,渲染进程就开始解析资源和渲染页面了,注意浏览器的渲染页面不是等待所有资源都加载完成之后才开始渲染,而是一边解析一遍渲染的,这也是为什么有的页面会先给用户呈现文字,然后图片等资源才会随后加载。
详细的渲染过程见第四点
四、浏览器是如何运作的?
以 chrome 浏览器为例
浏览器的结构大致可分为:用户界面、浏览器引擎、渲染引擎
- 用户界面:用于展示除标签页窗口之外的其他用户界面的内容
- 渲染引擎(浏览器核心,常称为浏览器内核):负责渲染用户请求的页面内容,渲染引擎下还有很多小的模块(如:负责网络请求的网络模块,用于解释和执行js的js解释器)
- 浏览器引擎:在用户界面和渲染引擎之间,用于在用户界面和渲染引擎之间传递数据。还有数据持久层(帮助浏览器存储各种数据,如:cookie)
4.1 不同浏览器的内核
IE:Trident
Firefox:Gecko
Safari:Webkit
Chrome / Opera / Edge:基于 Webkit 改造的 Blink
![]()
4.2 浏览器的多进程结构
当今浏览器是一个多进程结构,但早期的浏览器是单进程结构
早期的浏览器单进程结构:
![]()
单进程结构引发了很多问题:
- 不稳定:其中一个线程卡死可能会导致整个进程出问题,比如你打开多个标签页,其中一个标签卡死可能会导致浏览器无法运行
- 不安全:浏览器之间是可以共享数据的,那 js 岂不是可以随意访问浏览器进程内的所有数据
- 不流畅:一个进程需要负责太多事情,导致效率低下
所以当今的浏览器选择了多进程结构,根据进程功能不同,浏览器可拆分为:
![]()
- 浏览器进程:负责chrome浏览器处标签页以外的界面,包括地址栏、书签、后退和前进按钮,以及负责与浏览器的其他进程协调工作;
- 网络进程:负责发起接收网络请求;
- GPU进程:负责整个浏览器界面的渲染;
- 插件进程:负责控制网站使用的所有插件,例如:flash;
- 渲染器进程:用来控制显示tab标签内所有内容,浏览器在默认情况下会为每个标签页都创建一个渲染器进程
4.3 chrome 的4种进程模型
chrome一共有4种进程模型,不同的进程模式会对 tab 进程做不同的处理。
- Process-per-site-instance (default) :同一个 site-instance 使用一个进程,chromium为每个实例创建一个渲染器进程,访问不同站点和同一站点的不同页面都会创建新的进程
- Process-per-site:同一个 site 使用同一个进程
- Process-per-tab: 每个 tab 使用一个进程
- Single process :所有 tab 共用一个进程
4.4 当在浏览器地址栏输入内容时,浏览器内部会发生什么事情?(更详细的见三)
1. 用户输入URL阶段+DNS+请求数据+处理和返回数据
当在地址栏中输入内容时,浏览器进程的UI线程会捕捉我输入的内容,如果输入的网址,则UI线程会启动一个网络线程(这是浏览器进程中的,不是网络进程,网络进程时发起http请求来请求 DNS 进行域名解析,接着开始连接服务器获取数据。如果输入的是关键词,浏览器就知道你是要使用搜索功能,于是就会使用默认配置的搜索引擎进行查询 ;
![]()
当网络线程获取到数据后,会通过Safe Browsing(谷歌内部的一套站点安全系统,通过检测该站点的数据来判断是否安全)来检查站点是否是恶意站点,如果是则会提示个警告页面,告诉我这个站点有安全问题,浏览器会阻止我的访问,但我也可以强行继续访问。当返回数据准备完毕并且安全校验通过时,网络线程会通知UI线程我准备好了,该你了。
![]()
2. 渲染页面阶段
然后 UI 线程会创建渲染器进程来渲染页面,浏览器进程通过 IPC 管道将数据传递给渲染器进程,进入渲染流程。渲染器进程接收到数据(html(往往里面会包含css、js、image资源))。
渲染器进程的核心任务:将 html、js、css、image 等资源渲染成用户可以交互的 web 页面。渲染器进程的主线程将 html 进行解析,构造DOM结构。
HTML 首先通过 Tokeniser 标记化,通过词法分析将输入的 html 内容解析成多个标记,根据识别后的标记进行DOM树构造,在DOM树创造过程中会创建docement对象,然后建立以 document 为根节点的DOM树。
需要注意的是:html 代码中往往会引入一些额外的资源,如 js、css、图片等。图片和CSS这些资源需要通过网络下载或者从缓存中直接加载,这些资源不会阻塞 html 的解析,因为他们不会影响DOM的生成,当在解析过程中遇到 script 标签时,就会停止 html 解析,转而加载解析并执行 js,因为 js 可能会改变当前页面HTML的结构,有可能在js中由添加或删除节点等其他会影响 html 结构的操作,所以 script 标签一定要放在合适的位置,或者使用 async 或 defer 属性来异步加载 js。
![]()
在 html 解析完成后,我们会获得一个DOM Tree,但此时我们还不知道DOM tree上的每个节点长什么样子,这是主线程需要解析css,并确定每个DOM节点的计算样式。
![]()
![]()
在知道DOM结构和每个节点的样式后,接下来需要知道每个节点放在页面上的哪个位置,也就是节点的坐标以及该节点需要占用多大的区域,这个阶段被称为 layout布局,主线程通过遍历dom和计算好的样式来生成Layout tree,Layout tree上的每个节点都记录了x,y坐标和边框尺寸。
![]()
需要注意的是:DOM tree 和Layout tree并不是一一对应的,设置了display:none的不会出现在Layout tree上,而在before伪类中添加了content值的元素,content里的内容会出现在Layout tree上不会出现在DOM tree上,因为DOM是通过html解析获得并不关心样式,而Layout tree是DOM tree结合CSSOM tree来生成的。
![]()
知道了元素的大小形状和位置这还不够,我们还需要知道以什么样的顺序绘制(paint)这个节点,毕竟像z-index属性会影响节点绘制的层级关系,如果我们按照DOM的层级结构来绘制,则会导致错误的渲染。所以为了保证在屏幕上展示正确的层级,主线程遍历Layout tree创建一个绘制记录表(Paint Record),该表记录了绘制的顺序,该阶段被称为绘制。
![]()
![]()
知道了节点的绘制顺序,就该把这些信息转化为像素点显示在屏幕上,这种行为被称为栅格化(Rastering)。
chrome早期的栅格化方案是只栅格化用户可视区域的内容,当用户滚动页面时,再栅格化更多的内容来填充缺失的部分,这种方案会导致展示延迟。现在 chrome 的栅格化流程叫做合成(composting),合成是一种将页面的各个部分分成多个图层,分别对其进行栅格化,并在合成器线程的技术中单独合成页面的技术,简单来说就是页面所有的元素按照某种规则进行分图层,并把图层都栅格化好,然后只需要把可视区的内容组合成一帧展示给用户即可。
![]()
主线程遍历layout tree生成 layer(图层)tree,当 layer tree 生成完毕和绘制顺序确定后,主线程将这些信息传递给合成器线程。
![]()
![]()
合成器线程将每个图层栅格化,由于一层可能像页面的整个长度一样大,因此合成器线程将他们切分为许多图块,然后将每个图块发送给栅格化线程。
![]()
栅格化线程栅格化每个图块,并将它们存储到GPU内存中
![]()
当图块栅格化完成后,合成器线程将收集称为”draw quads“的图块信息(栅格线程传来),这些信息里记录了图块在内存中的位置和在页面哪个位置绘制图块的信息,根据这些信息合成器线程生成了一个合成器帧(Compositor Frame)
![]()
然后这个合成器帧通过IPC传送给浏览器进程,接着浏览器进程将合成器帧传送到GPU,然后GPU渲染展示到屏幕上,这时就可以看到页面的内容。
![]()
但当页面发生变化时,都会生成一个新的合成器帧,然后重复上面的动作
![]()
3. 重排重绘
当改变一个元素的尺寸位置属性时,会重新进行样式计算、布局绘制以及后面的所有流程,这种行为称为重排
当改变一个元素的颜色属性时,不会重新触发布局,但还是会触发样式计算和绘制,这是重绘。
重排和重绘都会占用主线程,js也是运行在主线程,就会出现抢占执行时间的问题。当在一帧的时间内布局绘制结束后还有剩余时间,js就会拿到主线程的使用权,如果js执行时间过长就会导致在下一帧开始时js没有及时归还主线程,导致下一帧动画没有按时渲染,就会出现页面动画的卡顿,
![]()
有什么优化手段吗???
当然有!!
4. 优化重排重绘带来的页面动画卡顿的问题
第一种就是通过 requestAnimationFrame() API,这个方法会在每一帧被调用,通过API的回调,我们可以把JS运行任务分成一些更小的任务块(分到每一帧),在每一帧时间用完前暂停js执行,归还主线程,这样在下一帧开始时主线程就可以按时布局和绘制
![]()
第二种 栅格化不占用主线程,只在合成器线程和栅格线程中运行,意味着他不会和js抢占主线程,css有个动画属性transform,通过该属性实现的动画不会经过布局和绘制,而是直接运行在合成器线程和栅格线程,所以不会受到主线程中JS的影响,更重要的是,通过transform实现的动画由于不需要经过布局绘制样式计算等操作,所以节省了很多运算时间
![]()
5. 渲染流水线
当网络进程将资源提交给渲染进程的时候,此时渲染进程就要开始渲染页面了。浏览器的渲染机制是十分复杂的,所以渲染会被划分为很多子阶段,输入的HTML、CSS、JS以及图片等资源经过这些阶段,最终输出像素展示到页面上,我们把浏览器的这样一个处理流程叫做渲染流水线。
按照渲染的时间顺序,我们把浏览器的渲染时间段分为以下几个子阶段,需要注意的是每一个子阶段的输出都会当做下一个子阶段的输入,这也符合实际的工厂流水线的场景。
6. 渲染流程总结
1、渲染进程将 HTML 内容转换为能够读懂的 DOM 树结构
2、渲染引擎将 CSS 样式表转化为浏览器可以理解的 styleSheets,计算出 DOM 节点的样式
3、创建布局树,并计算元素的布局信息。
4、对布局树进行分层,并生成分层树。
5、为每个图层生成绘制列表,并将其提交到合成线程。
6、合成线程将图层分成图块,并在光栅化线程池中将图块转换成位图。
7、合成线程发送绘制图块命令 DrawQuads 给浏览器进程
8、浏览器进程根据 DrawQuads 消息生成页面,并显示到显示器上。
五、JS 的运行原理(重点:JS 引擎)
5.1 js 继承了以下四种语言各自的特性
![]()
![]()
5.2 奇怪的 js
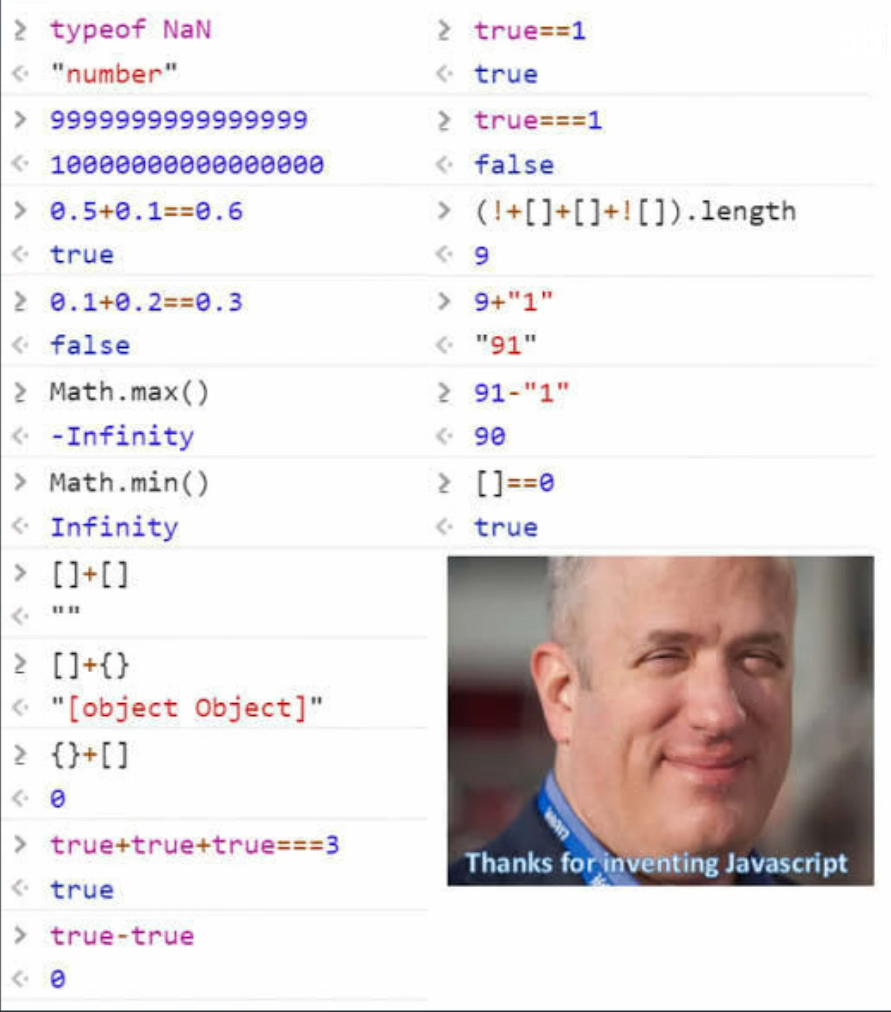
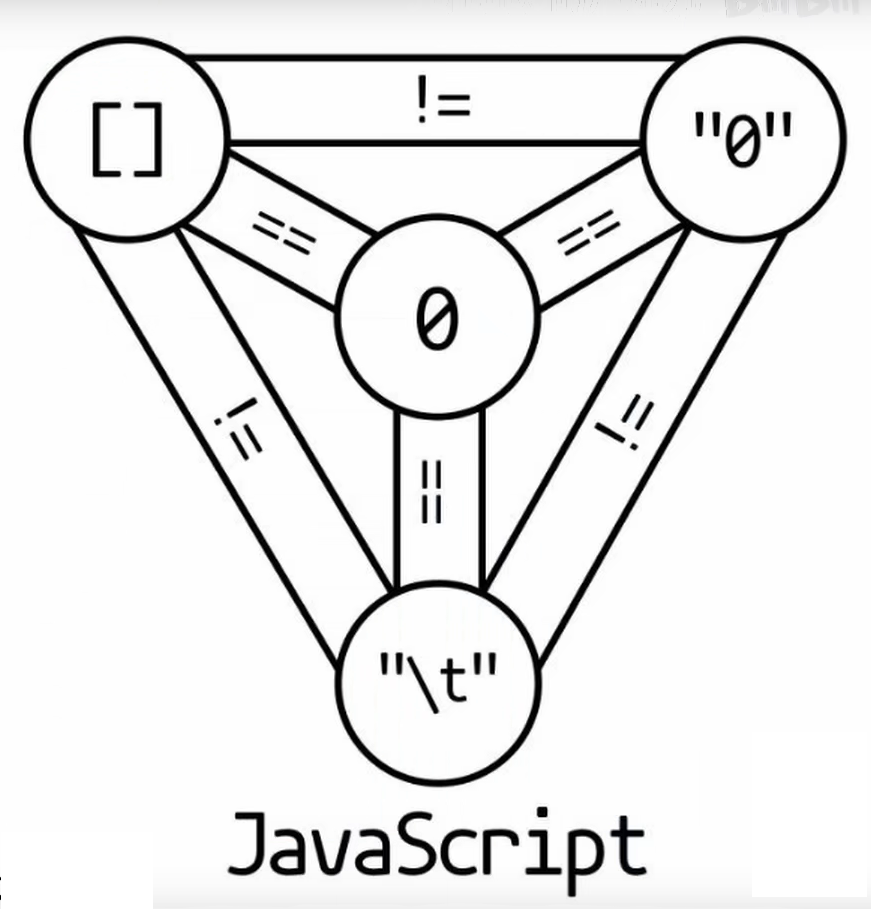
5.3 JIT
js是动态类型语言,但这也导致了我们在运行前无法得知变量的类型,只有在运行期间,才能确定各个变量的类型,这就导致了 js 无法在运行前编译出更加迅速的低级的语言代码(机器代码)。尽管如此,js执行起来还是很快,这是为什么呢???这是因为现在的 JavaScript 引擎都使用了一个技术:Just-In-Time Compilation 运行时编译,简称 JIT,就是在运行阶段生成机器代码,而不是提前生成,JIT 把代码的运行和生成机器代码同时进行
![]()
5.4 JS 引擎
js 是一门高级语言,他被计算机CPU执行前,需要通过某种程序将 JS 转换为低级的机器语言并执行,这种程序就被称为 JavaScript 引擎,JavaScript 有许多引擎:
- Chrome:V8引擎
- webkit:JavaScriptCore
- Mozila:SpiderMonkey
- QuickJS
- Hermes
![]()
js引擎执行的大致流程(新V8)
- 首先将JS源码通过解析器(parser)解析成抽象语法树AST;
- 接着通过解释器(interpreter)将AST编译成字节码btyecode,字节码是跨平台的一种中间表示,不同于最后的机器代码。字节码与平台无关,能够在不同的操作系统上运行;
- 字节码最后通过编译器(compiler)生成机器代码,由于不同的处理器平台使用的机器代码会有差异,所以编译器会根据当前平台来编译出相应的机器代码
![]()
5.5 以 V8 为例了解 JS 引擎编译和优化 JS
JS 的引擎是V8,node.js 运行时环境也是V8引擎,electron的底层引擎也是V8.
简单来说,V8是一个接收JavaScript代码,编译代码然后执行的C++程序,编译后的代码可以运行在多种操作系统多种处理器上运行。
V8主要负责的工作:
- 编译和执行 JS 代码
- 处理调用栈
- 内存的分配
- 垃圾回收
![]()
1. 早期的V8引擎
JS 引擎在编译和执行 JS 代码时都会用到3个重要的组件:
![]()
解析器(parser):负责将JS源码解析成抽象语法树AST;
解释器(interpreter):负责将AST编译成字节码btyecode,同时解释器也有直接解释执行bytecode的能力;
编译器(compiler)”负责编译运行出更高效的机器代码。
但在 V8<5.9版本之前,V8 引擎没有解释器,却有两个编译器,其编译流程如下:
- JS 源码通过解析器解析生成抽象语法树AST;
- 然后由 Full-codegen 编译器直接使用 AST 来编译出机器代码,而不进行任何中间转换。 Full-codegen 编译器也称基准编译器,因为他生成的是一个基准的未被优化的机器代码,这样的好处是当我第一次执行 JS 的时候就是直接使用了高效的机器代码,因为没有中间字节码产生,也就不需要解释器;
- 当代码运行一段时间后,V8中的分析器线程收集了足够的数据来帮助另一个编译器—Crankshaft 来做代码优化,然后需要优化的代码重新解析生成 AST,然后 Crankshaft使用生成好的 AST 再生成优化后的机器代码来提升运行效率,所以 Crankshaft 编译器又称为优化编译器
![]()
这样设计的初衷是好的,减少了 AST到字节码的转换时间,提高外部浏览器中 JS 的执行性能,但也存在许多问题:(文章地址:https://v8.dev/blog/lauching-ignition-and-turbofan)
- 生成的机器码会占用大量的内存,有的代码仅执行一次,没有必要直接生成机器码;
- 缺少中间层的机器码,很多性能优化策略无法实施,导致 V8 性能提升缓慢;
- 之前的编译器(Crankshaft)无法很好支持和优化新的 JS 语法特性,无法拥抱未来。
所有提出新的V8架构
2. 新的V8架构
- 首先 JS源码还是通过解析器解析生成抽象语法树AST;
- 但在获得AST后,加入了解释器Ignition,AST 通过 Ignition 生成 bytecode 字节码,此时AST就被清除掉了,释放内存空间;
- 生成的bytecode直接被解释器执行,同时生成的btyecode将作为基准执行模型,字节码更加简洁,生成的字节码大小相当于等效的基准机器代码的 25%~50% 左右;
- 在代码不断地运行过程中,解释器收集到恨锁可以用来优化代码的信息,如:变量的类型,哪些函数执行的效率较高,这些信息被发送给V8引擎新的编译器 TurboFan,turbofan会根据这些信息和字节码来编译出经过优化的机器代码
3. 新的V8引擎在处理JS过程中的一些优化策略
- 如果函数知识声明,未被调用,则该函数不会被解析生成AST,也就不会生成字节码;
- 如果函数只被调用一次,则 Ignition 生成字节码后就直接被解释执行了,turbofan 不会进行优化编译,因为他需要 ignition 收集函数执行时的类型信息,这就要求函数至少执行大于一次,Turbofan才能进行优化;
- 如果函数被调用多次,则它有可能会被识别为热点函数,当 Ignition 收集的类型信息确定后,这是Turbofan 则会将 bytecode 编译为优化后的机器代码,以提高代码的执行性能。之后执行这个函数时,就直接运行优化后的机器代码
4. deoptimization
需要注意的是:
在某些情况下,优化后的机器代码可能会被逆向还原成字节码,这个过程叫做deoptimization,这是因为JS是一个动态类型语言,会导致Ignition收集到的信息时错误的
![]()
举个例子:比如有个sum(x,y)函数,JS引擎并不知道参数x,y是什么类型,但在后面的多次调用中,传入的x,y都是整型,sum函数被识别未热点函数,解释器将收集到的类型信息和字节码发送给编译器,于是编译器生成的优化后的机器代码中就假定了sum函数的参数是整型,之后遇到该函数的调用就直接使用运行更快的机器代码,但如果此时你用sum函数时传入了字符串,就会出现问题,机器代码不知道如何处理字符串的参数,于是就需要进行deoptimization回退到字节码处,由解释器来解释执行。所以尽量不要把一个变量类型变来变去,对传入函数的参数类型也最好保持固定,否则会给V8引擎带来影响,损失一定的性能.
![]()
5. 新V8架构的好处
新的架构除了解决旧架构的问题,还带来的好处:
- 由于不需要一开始编译成机器码,而是生成了中间层的字节码,字节码生成的速度是远远大于机器码的,所以网页初始化解析执行JS的时间缩短了,网页就可以更快的onload;
- 在生成优化机器代码时,不需要从源码重新编译,而使用字节码,并且但需要deoptimization时,只需要回归到字节码解释执行就行了。
新的模块性能有更好的提升,功能模块的职能页更加清晰了,为未来JS的新功能和优化页铺平了道路
六、跨域问题
6.1 出现跨域的原因
出于浏览器的同源策略限制。同源策略(Sameoriginpolicy)是一种约定,它是浏览器最核心也最基本的安全策略,如果缺少了同源策略,则浏览器的正常功能可能都会受到影响。可以说Web是构建在同源策略基础之上的,浏览器只是针对同源策略的一种实现。同源策略会阻止一个域的javascript脚本和另外一个域的内容进行交互。所谓同源(即指在同一个域)就是两个页面具有相同的协议(protocol),主机(host)和端口号(port)。
6.2 跨域的概念
当一个请求url的协议、域名、端口三者之间任意一个与当前页面url不同即为跨域
| 当前页面url | 被请求页面url | 是否跨域 | 原因 |
|---|---|---|---|
| http://www.test.com/ | http://www.test.com/index.html | 否 | 同源(协议、域名、端口号相同) |
| http://www.test.com/ | https://www.test.com/index.html | 跨域 | 协议不同(http/https) |
| http://www.test.com/ | http://www.baidu.com/ | 跨域 | 主域名不同(test/baidu) |
| http://www.test.com/ | http://blog.test.com/ | 跨域 | 子域名不同(www/blog) |
| http://www.test.com:8080/ | http://www.test.com:7001/ | 跨域 | 端口号不同(8080/7001) |
6.3 非同源的限制
【1】无法读取非同源网页的 Cookie、LocalStorage 和 IndexedDB
【2】无法获得非同源网页的 DOM
【3】无法向非同源地址发送 AJAX 请求
6.4 跨域解决方法
1. 通过 JSONP 跨域
JSONP 是服务器与客户端跨源通信的常用方法。最大特点就是简单适用,兼容性好(兼容低版本IE),缺点是只支持 get 请求,不支持 post 请求。
核心思想:利用**<script>标签没有跨域限制**,通过<script>标签 src 属性,发送带有 callback 参数的 GET 请求,服务端将接口返回数据拼凑到 callback 函数中,返回给浏览器,浏览器解析执行,前端从而拿到 callback 函数返回的 JSON 数据。
原生 JS 实现:
<script src="http://test.com/data.php?callback=dosomething"></script>
// 向服务器test.com发出请求,该请求的查询字符串有一个callback参数,用来指定回调函数的名字// 处理服务器返回回调函数的数据
<script type="text/javascript">function dosomething(res){// 处理获得的数据console.log(res.data)}</script>
Vue.js:
this.$http = axios;
this.$http.jsonp('http://www.domain2.com:8080/login', {params: {},jsonp: 'handleCallback'
}).then((res) => {console.log(res);
})
服务器端返回:
handleCallback({"success": true, "user": "admin"})
2. 跨域资源共享(CORS)
CORS 是 “跨域资源共享”(Cross-Origin Resource Sharing)的缩写。它是 W3C 标准,属于跨源 AJAX 请求的根本解决方法。它允许浏览器向跨源服务器,发出XMLHttpRequest请求,从而克服了AJAX只能同源使用的限制。
1、普通跨域请求:只需服务器端设置Access-Control-Allow-Origin,前端无须设置。
2、带cookie跨域请求:前后端都需要进行设置
【前端设置】根据xhr.withCredentials字段判断是否带有cookie
前端设置
① 原生AJAX:
var xhr = new XMLHttpRequest(); // IE8/9需用window.XDomainRequest兼容// 前端设置是否带cookie
xhr.withCredentials = true;xhr.open('post', 'http://www.domain2.com:8080/login', true);
xhr.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded');
xhr.send('user=admin');xhr.onreadystatechange = function() {if (xhr.readyState == 4 && xhr.status == 200) {alert(xhr.responseText);}
};
② Vue
1)axios设置:
axios.defaults.withCredentials = true
2)vue-resource设置:
Vue.http.options.credentials = true
后端设置
若后端设置成功,前端浏览器控制台则不会出现跨域报错信息,反之,说明没设成功。
1)java后台
/** 导入包:import javax.servlet.http.HttpServletResponse;* 接口参数中定义:HttpServletResponse response*/// 允许跨域访问的域名:若有端口需写全(协议+域名+端口),若没有端口末尾不用加'/'
response.setHeader("Access-Control-Allow-Origin", "http://www.domain1.com"); // 允许前端带认证cookie:启用此项后,上面的域名不能为'*',必须指定具体的域名,否则浏览器会提示
response.setHeader("Access-Control-Allow-Credentials", "true"); // 提示OPTIONS预检时,后端需要设置的两个常用自定义头
response.setHeader("Access-Control-Allow-Headers", "Content-Type,X-Requested-With");
2)Nodejs后台
var http = require('http');
var server = http.createServer();
var qs = require('querystring');server.on('request', function(req, res) {var postData = '';// 数据块接收中req.addListener('data', function(chunk) {postData += chunk;});// 数据接收完毕req.addListener('end', function() {postData = qs.parse(postData);// 跨域后台设置res.writeHead(200, {'Access-Control-Allow-Credentials': 'true', // 后端允许发送Cookie'Access-Control-Allow-Origin': 'http://www.domain1.com', // 允许访问的域(协议+域名+端口)/* * 此处设置的cookie还是domain2的而非domain1,因为后端也不能跨域写cookie(nginx反向代理可以实现),* 但只要domain2中写入一次cookie认证,后面的跨域接口都能从domain2中获取cookie,从而实现所有的接口都能跨域访问*/'Set-Cookie': 'l=a123456;Path=/;Domain=www.domain2.com;HttpOnly' // HttpOnly的作用是让js无法读取cookie});res.write(JSON.stringify(postData));res.end();});
});server.listen('8080');
console.log('Server is running at port 8080...');
3. nginx 代理跨域
1)nginx配置解决iconfont跨域
浏览器跨域访问js、css、img等常规静态资源被同源策略许可,但iconfont字体文件(eot|otf|ttf|woff|svg)例外,此时可在nginx的静态资源服务器中加入以下配置。
location / {add_header Access-Control-Allow-Origin *;
}
2)nginx反向代理接口跨域
跨域原理: 同源策略是浏览器的安全策略,不是HTTP协议的一部分。服务器端调用HTTP接口只是使用HTTP协议,不会执行JS脚本,不需要同源策略,也就不存在跨越问题。
实现思路:搭建一个中转 nginx 服务器,用于转发请求。通过nginx配置一个代理服务器(域名与domain1相同,端口不同)做跳板机,反向代理访问domain2接口,并且可以顺便修改cookie中domain信息,方便当前域cookie写入,实现跨域访问。
nginx具体配置:
#proxy服务器
server {listen 81;server_name www.domain1.com;location / {proxy_pass http://www.domain2.com:8080; #反向代理proxy_cookie_domain www.domain2.com www.domain1.com; #修改cookie里域名index index.html index.htm;# 当用webpack-dev-server等中间件代理接口访问nignx时,此时无浏览器参与,故没有同源限制,下面的跨域配置可不启用add_header Access-Control-Allow-Origin http://www.domain1.com; #当前端只跨域不带cookie时,可为*add_header Access-Control-Allow-Credentials true;}
}
1)前端代码示例:
var xhr = new XMLHttpRequest();// 前端开关:浏览器是否读写cookie
xhr.withCredentials = true;// 访问nginx中的代理服务器
xhr.open('get', 'http://www.domain1.com:81/?user=admin', true);
xhr.send();
2)Nodejs后台示例:
var http = require('http');
var server = http.createServer();
var qs = require('querystring');server.on('request', function(req, res) {var params = qs.parse(req.url.substring(2));// 向前台写cookieres.writeHead(200, {'Set-Cookie': 'l=a123456;Path=/;Domain=www.domain2.com;HttpOnly' // HttpOnly:脚本无法读取});res.write(JSON.stringify(params));res.end();
});server.listen('8080');
console.log('Server is running at port 8080...');
4. nodejs 中间件代理跨域
node中间件实现跨域代理,原理大致与nginx相同,都是通过启一个代理服务器,实现数据的转发,也可以通过设置cookieDomainRewrite参数修改响应头中cookie中域名,实现当前域的cookie写入,方便接口登录认证。
① 非vue框架的跨域(2次跨域)
利用 node + express + http-proxy-middleware 搭建一个proxy服务器。
1.)前端代码示例:
var xhr = new XMLHttpRequest();// 前端开关:浏览器是否读写cookie
xhr.withCredentials = true;// 访问http-proxy-middleware代理服务器
xhr.open('get', 'http://www.domain1.com:3000/login?user=admin', true);
xhr.send();
2.)中间件服务器:
var express = require('express');
var proxy = require('http-proxy-middleware');
var app = express();app.use('/', proxy({// 代理跨域目标接口target: 'http://www.domain2.com:8080',changeOrigin: true,// 修改响应头信息,实现跨域并允许带cookieonProxyRes: function(proxyRes, req, res) {res.header('Access-Control-Allow-Origin', 'http://www.domain1.com');res.header('Access-Control-Allow-Credentials', 'true');},// 修改响应信息中的cookie域名cookieDomainRewrite: 'www.domain1.com' // 可以为false,表示不修改
}));app.listen(3000);
console.log('Proxy server is listen at port 3000...');
3.)Nodejs后台同(nginx)
② vue框架的跨域(1次跨域)
利用node + webpack + webpack-dev-server代理接口跨域。在开发环境下,由于vue渲染服务和接口代理服务都是webpack-dev-server同一个,所以页面与代理接口之间不再跨域,无须设置headers跨域信息了。
webpack.config.js部分配置:
module.exports = {entry: {},module: {},...devServer: {historyApiFallback: true,proxy: [{context: '/login',target: 'http://www.domain2.com:8080', // 代理跨域目标接口changeOrigin: true,secure: false, // 当代理某些https服务报错时用cookieDomainRewrite: 'www.domain1.com' // 可以为false,表示不修改}],noInfo: true}
}
5. document.domain + iframe 跨域
此方案仅限主域相同,子域不同的跨域应用场景。
实现原理:两个页面都通过js强制设置document.domain为基础主域,就实现了同域。
1.)父窗口:(http://www.domain.com/a.html)
<iframe id="iframe" src="http://child.domain.com/b.html"></iframe>
<script>document.domain = 'domain.com';var user = 'admin';</script>
2.)子窗口:(http://child.domain.com/b.html)
<script>document.domain = 'domain.com';// 获取父窗口中变量alert('get js data from parent ---> ' + window.parent.user);</script>
6. location.hash + iframe 跨域
实现原理: a欲与b跨域相互通信,通过中间页c来实现。 三个页面,不同域之间利用 iframe 的 location.hash 传值,相同域之间直接 js访问来通信。
具体实现:A域:a.html -> B域:b.html -> A域:c.html,a与b不同域只能通过hash值单向通信,b与c也不同域也只能单向通信,但c与a同域,所以c可通过parent.parent访问a页面所有对象。
1.)a.html:(http://www.domain1.com/a.html)
<iframe id="iframe" src="http://www.domain2.com/b.html" style="display:none;"></iframe>
<script>var iframe = document.getElementById('iframe');// 向b.html传hash值setTimeout(function() {iframe.src = iframe.src + '#user=admin';}, 1000);// 开放给同域c.html的回调方法function onCallback(res) {alert('data from c.html ---> ' + res);}</script>
2.)b.html:(http://www.domain2.com/b.html)
<iframe id="iframe" src="http://www.domain1.com/c.html" style="display:none;"></iframe>
<script>var iframe = document.getElementById('iframe');// 监听a.html传来的hash值,再传给c.htmlwindow.onhashchange = function () {iframe.src = iframe.src + location.hash;};</script>
3.)c.html:(http://www.domain1.com/c.html)
<script>// 监听b.html传来的hash值window.onhashchange = function () {// 再通过操作同域a.html的js回调,将结果传回window.parent.parent.onCallback('hello: ' + location.hash.replace('#user=', ''));};</script>
7. window.name + iframe跨域
window.name属性的独特之处:name值在不同的页面(甚至不同域名)加载后依旧存在,并且可以支持非常长的 name 值(2MB)。
1.)a.html:(http://www.domain1.com/a.html)
var proxy = function(url, callback) {var state = 0;var iframe = document.createElement('iframe');// 加载跨域页面iframe.src = url;// onload事件会触发2次,第1次加载跨域页,并留存数据于window.nameiframe.onload = function() {if (state === 1) {// 第2次onload(同域proxy页)成功后,读取同域window.name中数据callback(iframe.contentWindow.name);destoryFrame();} else if (state === 0) {// 第1次onload(跨域页)成功后,切换到同域代理页面iframe.contentWindow.location = 'http://www.domain1.com/proxy.html';state = 1;}};document.body.appendChild(iframe);// 获取数据以后销毁这个iframe,释放内存;这也保证了安全(不被其他域frame js访问)function destoryFrame() {iframe.contentWindow.document.write('');iframe.contentWindow.close();document.body.removeChild(iframe);}
};// 请求跨域b页面数据
proxy('http://www.domain2.com/b.html', function(data){alert(data);
});
2.)proxy.html:(http://www.domain1.com/proxy…
中间代理页,与a.html同域,内容为空即可。
3.)b.html:(http://www.domain2.com/b.html)
<script>window.name = 'This is domain2 data!';</script>
总结:通过iframe的src属性由外域转向本地域,跨域数据即由iframe的window.name从外域传递到本地域。这个就巧妙地绕过了浏览器的跨域访问限制,但同时它又是安全操作。
8. postMessage跨域
postMessage是HTML5 XMLHttpRequest Level 2中的API,且是为数不多可以跨域操作的 window 属性之一,它可用于解决以下方面的问题:
a.) 页面和其打开的新窗口的数据传递
b.) 多窗口之间消息传递
c.) 页面与嵌套的iframe消息传递
d.) 上面三个场景的跨域数据传递
用法:postMessage(data,origin)方法接受两个参数:
- data: html5规范支持任意基本类型或可复制的对象,但部分浏览器只支持字符串,所以传参时最好用JSON.stringify()序列化。
- origin: 协议+主机+端口号,也可以设置为"*",表示可以传递给任意窗口,如果要指定和当前窗口同源的话设置为"/"。
1.)a.html:(http://www.domain1.com/a.html)
<iframe id="iframe" src="http://www.domain2.com/b.html" style="display:none;"></iframe>
<script>var iframe = document.getElementById('iframe');iframe.onload = function() {var data = {name: 'aym'};// 向domain2传送跨域数据iframe.contentWindow.postMessage(JSON.stringify(data), 'http://www.domain2.com');};// 接受domain2返回数据window.addEventListener('message', function(e) {alert('data from domain2 ---> ' + e.data);}, false);</script>
2.)b.html:(http://www.domain2.com/b.html)
<script>// 接收domain1的数据window.addEventListener('message', function(e) {alert('data from domain1 ---> ' + e.data);var data = JSON.parse(e.data);if (data) {data.number = 16;// 处理后再发回domain1window.parent.postMessage(JSON.stringify(data), 'http://www.domain1.com');}}, false);</script>
9. WebSocket协议跨域
WebSocket protocol是HTML5一种新的协议。它实现了浏览器与服务器全双工通信,同时允许跨域通讯,是server push技术的一种很好的实现。
原生WebSocket API使用起来不太方便,我们使用Socket.io,它很好地封装了webSocket接口,提供了更简单、灵活的接口,也对不支持webSocket的浏览器提供了向下兼容。
1.)前端代码:
<div>user input:<input type="text"></div>
<script src="https://cdn.bootcss.com/socket.io/2.2.0/socket.io.js"></script>
<script>var socket = io('http://www.domain2.com:8080');// 连接成功处理socket.on('connect', function() {// 监听服务端消息socket.on('message', function(msg) {console.log('data from server: ---> ' + msg); });// 监听服务端关闭socket.on('disconnect', function() { console.log('Server socket has closed.'); });});document.getElementsByTagName('input')[0].onblur = function() {socket.send(this.value);};</script>
2.)Nodejs socket后台:
var http = require('http');
var socket = require('socket.io');// 启http服务
var server = http.createServer(function(req, res) {res.writeHead(200, {'Content-type': 'text/html'});res.end();
});server.listen('8080');
console.log('Server is running at port 8080...');// 监听socket连接
socket.listen(server).on('connection', function(client) {// 接收信息client.on('message', function(msg) {client.send('hello:' + msg);console.log('data from client: ---> ' + msg);});// 断开处理client.on('disconnect', function() {console.log('Client socket has closed.'); });
});
七、DNS到底是什么?
1. DNS的解释
有时你会发现一个情况,能打开QQ但是打不开网页,在网上查询解决方案时一般都会说DNS配置错误、还有什么DNS劫持、DNS污染。
我们访问一个网页,就会去访问他的 IP地址,但通常我们不会输入IP地址,因为我们记不住,所以我们通常是输入域名。就像打电话一样,我们现在都用通讯录里拨打对应名字的电话号码。为什么输入域名就能访问网页呢?原因就是我们的电脑里有一个和电话本一样的文件(hosts文件,路径C:\Windows\System32\drivers\etc\hosts),他记录着IP和域名的对应关系。
当在地址栏中输入域名时,浏览器会首先查看本地硬盘的 hosts 文件,查看其中有没有和这个域名对应的IP地址,如果有就会**使用 hosts 文件里面的 IP 地址和服务器建立连接。**但 hosts 文件是有限的,不可能记录所有域名和IP地址的对应关系,于是我们独立出来一个服务器,让这个服务器专门存储这个世界上绝大多数域名和 IP 地址的映射表。但需要访问某个网站时,先让电脑在这个服务器上查一下需要访问的域名对应的IP地址,然后再通过IP访问网站。这个服务器就是DNS服务器。他就像一个指路人一样,这样我们就只需要记住域名,然后DNS服务器会引导我们访问正确的IP地址。因此DNS服务器的反馈速度越快,就能越快的访问网站,选择一个合适的DNS显得尤为重要了。
这会来解释能打开QQ但是打不开网页的现象:
登录QQ是直接访问腾讯的服务器,QQ客户端内部已经帮我配置好了所有的IP,这里不涉及到域名解析的操作,所以可以正常的登录,但如果电脑的DNS配置错误,无法正常的访问到DNS服务器帮我做域名的解析,自然也就访问不到网站了
2. DNS劫持/DNS污染
假设一个网站的域名是www.abc.com IP地址是202.206.64.61,正常的输入www.abc.com通过DNS解析返回的应该是202.206.64.61,若因为一些恶意攻击等不为人知的操作导致返回的是202.206.64.62,这时就访问到别的网站上去了,十分影响用户体验,甚至还可能造成用户被盗号,被盗取个人信息。而用户此时是并不知情的。
暂时就先写到这里,后续会陆续更新,我已经腰酸背痛了哈哈哈!推荐B站的一位博主:objtube的卢克儿,他讲的很详细很有趣!
网络、浏览器专题重点知识(含原理)相关推荐
- 【网络】计算机网络重点知识总结
一.现在最主要的三种网络 Ø 电信网络(电话网) Ø 有线电视网络 Ø 计算机网络 (发展最快,信息时代的核心技术) 二.internet 和 Internet Ø internet 是普通名词 泛指 ...
- 作为前端你不得不知-浏览器的工作原理:网络浏览器幕后揭秘
序言 这是一篇全面介绍 WebKit 和 Gecko 内部操作的入门文章,是以色列开发人员塔利·加希尔大量研究的成果.在过去的几年中,她查阅了所有公开发布的关于浏览器内部机制的数据(请参见资源),并花 ...
- 浏览器的工作原理:新式网络浏览器幕后揭秘
一篇一年前的文章,讲的非常细致,说实话,没怎么全看懂,但是可以大体上了解一下里面的内容.文章比较长.因为HTML5ROCKS网站的css文件好像被墙了,所以决定把这篇文章搬运过来,也算是个存档吧. 那 ...
- 读书笔记 - -《Python网络编程》重点
文章目录 一.前言 二.客户/服务器网络编程简介 三.UDP 3.1 端口号 3.2 套接字 3.3 UDP分组 3.4 小结 四.TCP 4.1 TCP工作原理 4.2 绑定接口 4.3 死锁 4. ...
- 科技部:“网络空间安全”重点专项 2017年度项目申报指南建议
"网络空间安全"重点专项 2017年度项目申报指南建议 为落实<国家中长期科学和技术发展规划纲要(2006-2020年)>提出的任务,国家重点研发计划启动实施" ...
- 高教版《管理学》(第四版)重点知识整理
高等教育出版社<管理学>(第四版)重点知识整理 **注:只含本书1-13章课程,其中不包含第四章和第九章 v 第一章·管理活动与管理理论 Ø 第一节 管理活动 一.管理的定义 管理是指组织 ...
- 计算机二级vb重点知识,计算机二级《VB》历年考试重点知识
计算机二级<VB>历年考试重点知识 一.变量或常量的命名规则 1)必须以字母或汉字开头,由字母.汉字.数字或下划线组成,长度≤255个字符; 2)不能使用VB中的关键字,并尽量不与VB中标 ...
- 网络协议从入门到底层原理(11)网络爬虫、无线网络、HTTP缓存、即时通信、流媒体
补充知识 网络爬虫 网络爬虫的简易实例 robots.txt 无线网络 HTTP 缓存(Cache) 缓存 - 响应头 缓存 - 请求头 缓存的使用流程 即时通信(IM) XMPP MQTT 流媒体 ...
- ajax心得体会论文,AJAX重点知识的心得体会
下面就为大家带来一篇 AJAX重点知识的心得体会.学习还是有点帮助的,给大家做个参考吧. AJAX是什么? 是Asynchronous Javascript And XML的首字母的缩写, 它不是一门 ...
最新文章
- k8s-ingress 413 Request Entity Too Large
- 玩转springboot:整合mybatis实例
- 美团性能分析框架和性能监控平台
- 2.QLabel,QPushButton,QLineEdit,QComboBox,QCheckBox,QRadioButton,QTextEdit,QTextBrowser,QGroupBox,QSl
- 基于websocket的聊天实现逻辑(springboot)
- MySQL学习笔记_2_MySQL创建数据表(上)
- python模拟内置函数all_Python内置all函数详细介绍
- openresty 前端开发入门三之JSON篇
- 【iOS】Illegal Configuration: The Label outlet from the ViewController to the UILabel is invalid. Outl
- jQuery:节点操作、事件操作
- 最大连续子序列和的问题
- 乐高ev3编程 c语言,乐高ev3编程软件下载-乐高EV3机器人编程软件lego mindstorms ev31.0 官方版 - 极光下载站...
- 关于ASCII码和机内码
- Android快速入门之使用AdapterView展示不同风格的列表
- 简历制作器App使用条款
- win10系统上的appdata是什么文件夹可以删除吗
- opencv学习笔记(三)分离颜色通道多通道颜色混合
- DruidDataSource详解部分(一)
- 弦外雨,晚风急 吹皱芳华太无情
- 最全的数据中心(IDC)机房整体工程介绍