scrapy爬虫代理——利用crawlera神器,无需再寻找代理IP
一、crawlera平台注册
首先申明,注册是免费的,使用的话除了一些特殊定制外都是free的。
1、登录其网站 https://dash.scrapinghub.com/account/signup/
填写用户名、密码、邮箱,注册一个crawlera账号并激活
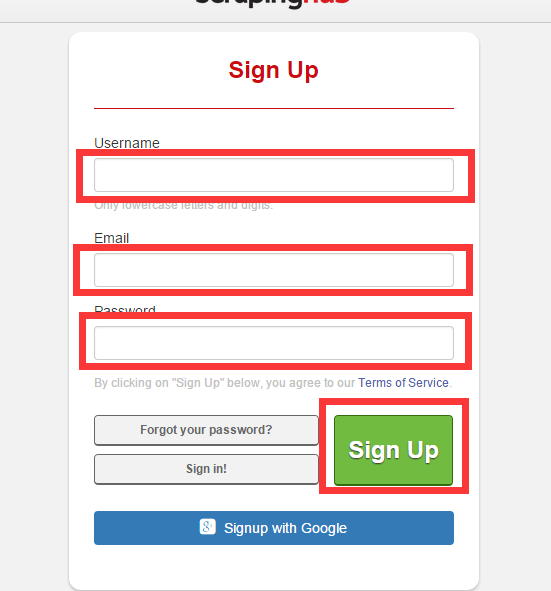
2、创建Organizations,然后添加crawlear服务
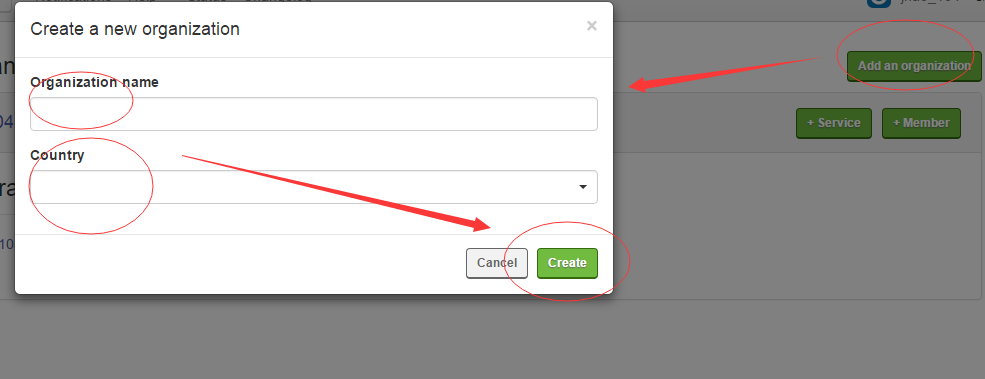
然后点击 +Service ,在弹出的界面点击Crawlear,输入名字,选择信息就创建成功了。
创建成功过后点击你的Crawlear名字便可以看到API的详细信息。
二、部署到srcapy项目
1、安装scarpy-crawlera
pip install 、easy_install 随便你采用什么安装方式都可以
pip install scrapy-crawlera2、修改settings.py
如果你之前设置过代理ip,那么请注释掉,加入crawlera的代理
DOWNLOADER_MIDDLEWARES = {# 'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': 110,# 'partent.middlewares.ProxyMiddleware': 100,
'scrapy_crawlera.CrawleraMiddleware': 600
}为了是crawlera生效,需要添加你创建的api信息(如果填写了API key的话,pass填空字符串便可)
CRAWLERA_ENABLED = True
CRAWLERA_USER = '<API key>'
CRAWLERA_PASS = ''为了达到更高的抓取效率,可以禁用Autothrottle扩展和增加并发请求的最大数量,以及设置下载超时,代码如下
CONCURRENT_REQUESTS = 32
CONCURRENT_REQUESTS_PER_DOMAIN = 32
AUTOTHROTTLE_ENABLED = False
DOWNLOAD_TIMEOUT = 600如果在代码中设置有 DOWNLOAD_DELAY的话,需要在setting.py中添加
CRAWLERA_PRESERVE_DELAY = True如果你的spider中保留了cookies,那么需要在Headr中添加
DEFAULT_REQUEST_HEADERS = {# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',# 'Accept-Language': 'zh-CN,zh;q=0.8','X-Crawlera-Cookies': 'disable'
}三、运行爬虫
这些都设置好了过后便可以运行你的爬虫了。这时所有的request都是通过crawlera发出的,信息如下

更多的crawlera信息请参考官方文档:http://doc.scrapinghub.com/index.html
https://my.oschina.net/jhao104/blog/512384
scrapy爬虫代理——利用crawlera神器,无需再寻找代理IP相关推荐
- win7 ie10代理设置不能用 设置完代理后点确定 回头再打开代理设置对钩并没有选上
IE代理服务器设置失效,比如勾选上了代理设置,或者改了代理服务器的端口,改好后关闭重新打开,发现没有更改设置, 可以注册表里cmd运行窗口输入 regedit HKEY_CURRENT_USER/So ...
- python爬虫天气实例scrapy_python爬虫之利用scrapy框架抓取新浪天气数据
scrapy中文官方文档:点击打开链接 Scrapy是Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘 ...
- 爬虫学习笔记(十)—— Scrapy框架(五):下载中间件、用户/IP代理池、settings文件
一.下载中间件 下载中间件是一个用来hooks进Scrapy的request/response处理过程的框架. 它是一个轻量级的底层系统,用来全局修改scrapy的request和response. ...
- Scrapy爬虫实战:使用代理访问
Scapy爬虫实战:使用代理访问 Middleware 中间件设置代理 middlewares.py settings.py spider 配置meta使用proxy 快代理 前面我们简单的设置了he ...
- Scrapy爬虫设置代理ip
在应用爬虫的时候我们经常会遇到ip被封的情况,这样我们想要的数据就不能及时下载下来,那么怎么办呢?当然是使用代理ip了,下面来看看scrapy中怎么使用代理ip. 一.开放代理 import rand ...
- scrapy爬虫-代理设置
scrapy爬虫-代理设置 1.请求头User-Agent代理设置** 1.1 找到middlewares.py 1.2 找到一个绑定的DownloaderMiddlewar(生成scrapy爬虫目录 ...
- 爬虫实战(一)—利用requests、mongo、redis代理池爬取英雄联盟opgg实时英雄数据
概述 可关注微信订阅号 loak 查看实际效果. 代码已托管github,地址为:https://github.com/luozhengszj/LOLGokSpider 包括了项目的所有代码. 此篇文 ...
- 用scrapy爬虫设置了ip代理报错是怎么回事
那么遇到这种情况大家也不用慌,我们可以采取以下措施: 1.放慢爬取速度,减少对于目标网站带来的压力,但会减少单位时间类的爬取量.测试出网站设置的限制速度阈值,设置合理的访问速度. 2.时间间隔访问,对 ...
- Scrapy爬虫及案例剖析
来自:ytao 由于互联网的极速发展,所有现在的信息处于大量堆积的状态,我们既要向外界获取大量数据,又要在大量数据中过滤无用的数据.针对我们有益的数据需要我们进行指定抓取,从而出现了现在的爬虫技术,通 ...
最新文章
- 硕士生两年发14篇论文!获浙大最高层次奖学金!
- svn命令行使用说明
- C/C++中extern关键字详解与应用
- 【玩转cocos2d-x之九】动作类CCAction
- 5个Vue.js项目的令人敬畏的模板
- java遍历数组练习(for循环、foreach)
- Flask安装首页显示
- .ashx文件与.ashx.cs
- 《30天自制操作系统》03_day_学习笔记
- motion blur matlab,Motion Blur app
- java数组函数_Java数组
- MFC——在共享DLL中使用MFC、在静态库中使用MFC
- 安装rational rose软件详细教程(不用注册账号)
- hencoder学习自定义view(1)
- win10跳过计算机密码,win10开机密码忘了怎么办
- 大数据与云计算、物联网三者的区别和关联
- win8连接wifi成功但受限制_win8平板电脑魔兽评测 Win8平板Pi游戏平板电脑测评PO W1流畅运行...
- Unreal Engin_Maya插件ArtV1_001初认Artv1创建一个带绑定的人物对其进行简单的设置
- 输入框内只能输入数字,输入其他内容不显示
- 买了腾讯云服务器怎么ping,腾讯云服务器如何禁止Ping的功能