NAACL 2022 | 字节和加州大学提出ConST模型,探讨对比学习如何助力语音翻译?
原文链接:https://www.techbeat.net/article-info?id=3692
作者:叶蓉
前言
全球化下应用最广泛的 AI 技术是什么?机器翻译必然是其中之一。除了纯文本信息的传播,随着流媒体越来越普及,语音翻译有着越来越广泛的应用:大到国际会议的翻译,小到电影电视等视频翻译的字幕。


图:Netflix推出的韩剧《鱿鱼游戏》(Squid Game) 翻译成 31 种语言“火”遍全球90个国家,“椪糖挑战"也随之在TikTok上就掀起热潮。
:::
语音翻译甚至出现在当下火热的“VR/AR技术”中,「火山引擎」和「亮亮视野」在2021年共同打造了AR眼镜,支持翻译功能,服务于会议场景,也可以帮助许多听残人士,为他们的世界加上了字幕,令人着实体验到了科技给生活带来的便利。
今年,Google I/O 大会上谷歌也展示了AR眼镜进行语音翻译成文字的原型,惊艳到了不少科技发烧友。
![]()
图为谷歌CEO桑德尔在I/O大会上展示AR眼镜项目
:::
以上的这些应用,其实都离不开语音翻译技术的加持。如何更方便快速地将语音翻译系统部署到这些端上?这是近年来业界和学术界最关心的课题之一。
端到端语音翻译
语音翻译的传统方法是串联起语音识别(automatic speech recognition, ASR)系统和机器翻译(machine translation, MT)系统,这样的方法被称为语音识别-机器翻译级联系统 (cascaded system)。另一方面,因为部署方便,端到端语音翻译 (end-to-end speech translation) 新技术最近获得了极大的关注。端到端语音翻译无需得到语音的转写内容,直接将语音转化为目标端的语言,这显然更为直接简洁。然而,标注好的“语音-转写-翻译”数据远远不如文本翻译那么丰富,这成了端到端语音翻译模型训练的一大瓶颈。
多任务累进学习
如何克服这瓶颈?知识蒸馏[1]、预训练[2][3]、多任务学习[4][5]… 纷纷被验证可以缓解数据缺少带来的问题,提升翻译质量。其中多任务学习确实是一种简单可行的解决之道,实践证明同时训练语音翻译 (ST)、语音识别 (ASR) 、机器翻译 (MT) 确实有更好的泛化能力。
其中 XSTNet[4]是一个比较典型的可以支持多任务累进学习的结构。在输入端,它既可以接受语音输入,又可以接受文本输入。对于语音输入,利用 wav2vec2 [6] 和几层卷积层提取语音特征;模型中的 transformer encoder 和 decoder 是“语音-到-文本”和“文本-到-文本”共享的。训练方面,采用“多任务累进学习”的意思是,模型(1)先用“文本-到-文本”数据对Transformer Encoder和Decoder进行预训练,(2)然后再多任务共同优化语音翻译、文本翻译、语音识别任务。
![]()
多任务累进学习框架 XSTNet[4] 的图示
:::
模态鸿沟——多任务累进学习无法解决的痛
虽然多任务学习模型获得了不错的效果,可是当我们从表示角度,观察重语音和文本两个不同模态的表示时,我们发现两者依旧存在鸿沟,如下图中 (a) current models 所示,现在的多任务学习模型中,同一句话,同一个意思,语音和文本的表示依旧有较大差距,而我们期望的是,对于同一句话,比如语音的 “it’s a nice day!” 和文本的 “it’s a nice day!” 的表示应该是相近的(如 (b) Expected 所示)。
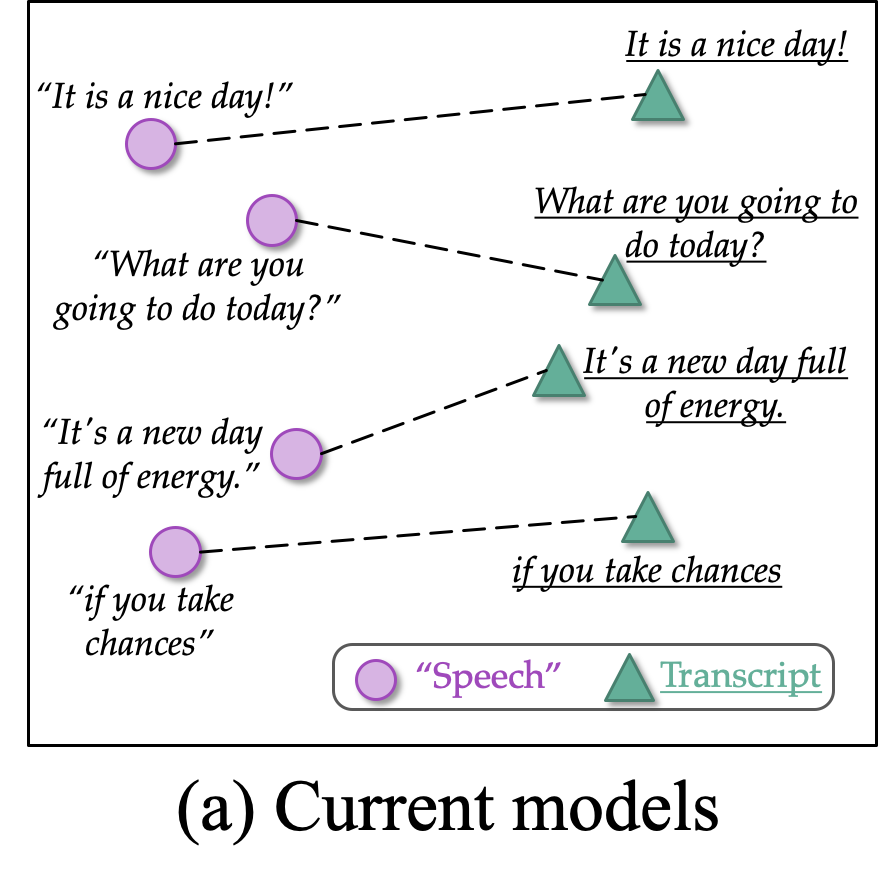

左图:多任务学习框架下语音和文本两者表示之间依旧存在差距;右图:我们所期望的两个模态表示:相同意思的语音和文本应该有相近的表示。
:::
所以怎样才能缩小两个模态的表示的鸿沟,从而提升语音翻译的表现呢?
这里给大家介绍在字节跳动 AI-Lab 与 UCSB 发表在 NAACL 2022 的长文:Cross-modal Contrastive Learning for Speech Translation[7]。本文提出 ConST 模型,其在语音翻译上获得了当前最好的效果。此外,本文探讨了如何将跨模态对比学习更好利用到语音翻译上。
![]()
:::
论文地址:
https://arxiv.org/abs/2205.02444
代码地址:
https://github.com/ReneeYe/ConST
ConST:利用对比学习解决模态鸿沟
ConST 模型依旧采取了可接受双头输入的结构,对于语音有特有的 S-Enc 学习表征,transformer encoder decoder模块是语音和文本共享的。ConST的模型结构如下图所示。
![]()
图:ConST模型架构和训练损失函数——多任务损失和对比损失的加权和
:::
训练方面,包含了多项损失函数:
- 语音翻译、语音识别、文本机器翻译三大任务的交叉熵损失函数:LST,LASR,LMT\mathcal{L}_{\mathrm{ST}}, \mathcal{L}_{\mathrm{ASR}}, \mathcal{L}_{\mathrm{MT}}LST,LASR,LMT
LST=−∑nlogP(yn∣sn)LASR=−∑nlogP(xn∣sn)LMT=−∑nlogP(yn∣xn)\begin{aligned} \mathcal{L}_{\mathrm{ST}} &=-\sum_{n} \log P\left(\mathbf{y}_{n} \mid \mathbf{s}_{n}\right) \\ \mathcal{L}_{\mathrm{ASR}} &=-\sum_{n} \log P\left(\mathbf{x}_{n} \mid \mathbf{s}_{n}\right) \\ \mathcal{L}_{\mathrm{MT}} &=-\sum_{n} \log P\left(\mathbf{y}_{n} \mid \mathbf{x}_{n}\right) \end{aligned} LSTLASRLMT=−n∑logP(yn∣sn)=−n∑logP(xn∣sn)=−n∑logP(yn∣xn)
- 此外,为了拉进相同句子的语音和文本的表示,额外引入了对比学习损失项 (contrastive loss)
LCTR=−∑s,xlogexp(sim(u,v)/τ)∑xj∈Aexp(sim(u,v(xj))/τ)\mathcal{L}_{\mathrm{CTR}}=-\sum_{s, x} \log \frac{\exp (\text{sim}(u, v) / \tau)}{\sum_{x_{j} \in \mathcal{A}} \exp \left(\text{sim}\left(u, v\left(x_{j}\right)\right) / \tau\right)} LCTR=−s,x∑log∑xj∈Aexp(sim(u,v(xj))/τ)exp(sim(u,v)/τ)
- u,vu, vu,v 对应语音和文本的表示,对于语音为经过 S-Enc 得到的隐变量 (hidden states) 的平均向 量,对于文本,则为 embedding 的平均向量。
u=MeanPool(S-Enc(s))v=MeanPool(Emb(x))\begin{gathered} u=\text{MeanPool}(\text{S-Enc}(\mathbf{s})) \\ v=\text{MeanPool}(\text{Emb}(\mathbf{x})) \end{gathered} u=MeanPool(S-Enc(s))v=MeanPool(Emb(x))
给定语音,对比学习的正例为其所对应文本,而负例则为同一 batch 中的其他句子的文本。
τ\tauτ 为“温度”超参数,控制着模型区分正负例的难度,温度越低,区分正负例的难度越小。实验中,我们设置为0.02。
可选模块:挖掘更多困难样例 / mining more hard examples
此外文章还提出了四种可选的挖掘困难样例的办法,来帮助更好的拉近模态距离,从而提升效果。这四种方法从输入层 (input-level) 和表示层 (representation-level) 对原始正/负例进行扩展。包括:
span-masked augmentation: 随机 mask 原始的一小段语音输入 (0.23s)
word repetition: 将句子中的 token 随机重复几次。
cut-off: 对于语音表示随机 mask sequence 维度(对应 Sequence Cut-off)或者 feature 维度(对应feature Cut-off)。
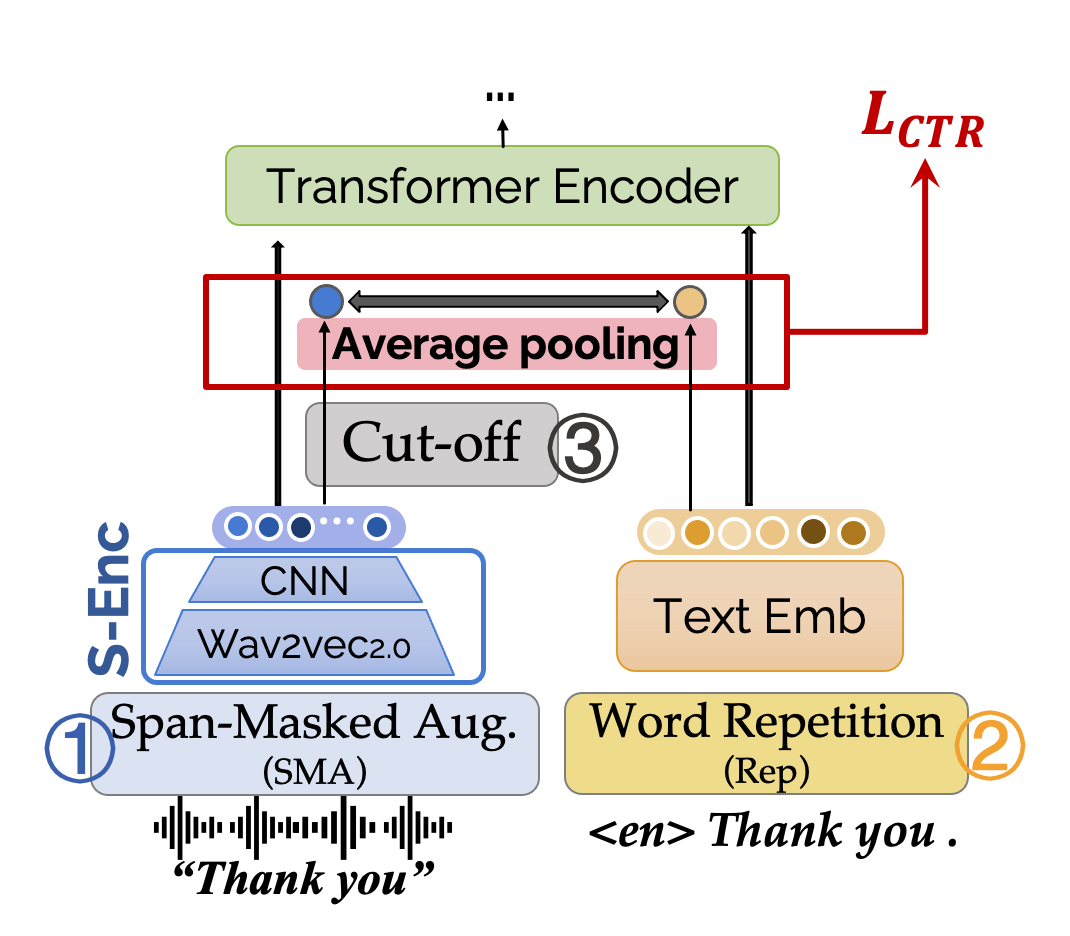
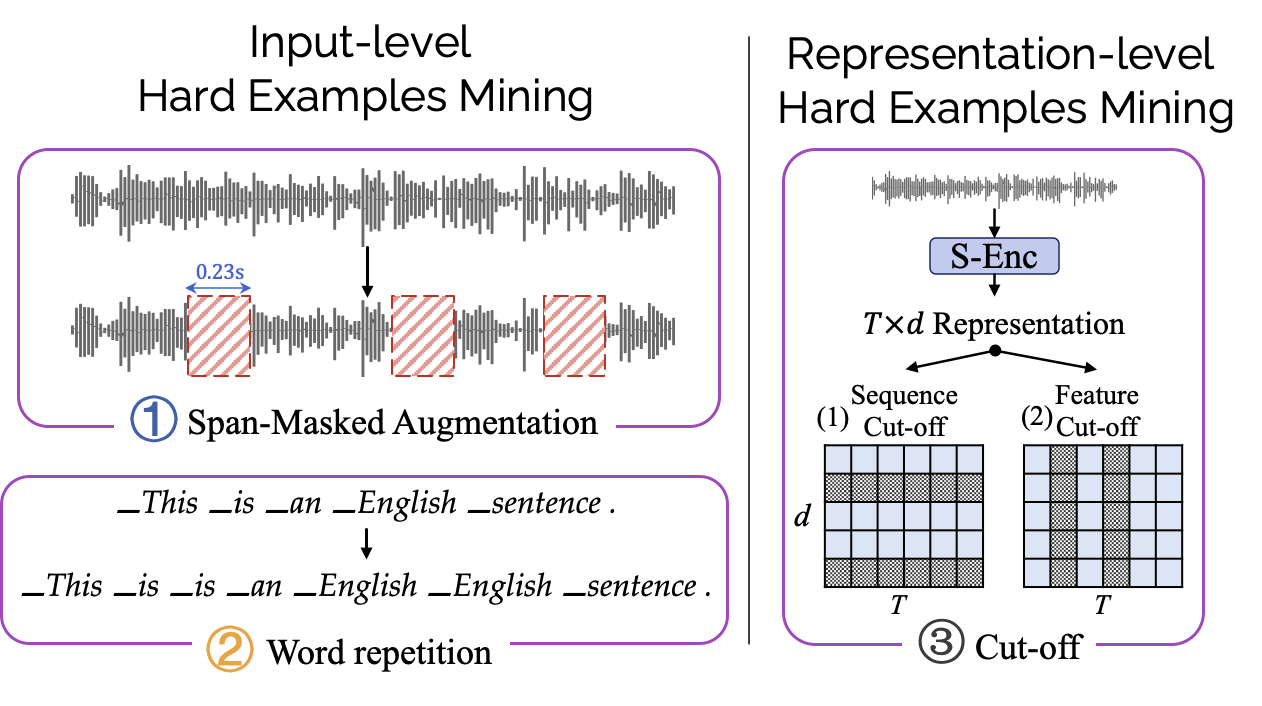
挖掘更多困难样例的几种操作的图示
:::
ConST在语音翻译上的表现和分析
8大语项获得显著翻译效果
本文在 MuST-C 数据集的 8 个语向上进行了实验,并且尝试了引入额外 MT 数据的场景 (w/ external MT data),如下表所示,与基线模型 W-Transf. 和 XSTNet 相比,ConST 在语音翻译质量上取得了更进一步的提升,在大多语向上达到了 SOTA。
![]()
:::
有关对比学习的更多细节…
文章还对对比学习做了更多分析,包括:
对可选的困难样例挖掘模块的分析(具体可以参见paper,此处略)
利用对比学习拉近模态距离是否优于其他方式?
在在哪一层对比学习?
利用对比学习拉进模态距离是否优于其他方式?
除了可以用对比学习的方式拉近两个模态的“距离”之外,实际上还可以使用其他方式训练损失函数,比如:
CTC loss: 建模语音文本的对齐关系,常见于很多语音-到-文本的任务中。
L2 loss: 直接建模两者表示的欧式距离差距,这也常见于各种知识蒸馏 (knowledge distillation)的场景中。
::: hljs-center

:::
我们发现,虽然这三种方法,都比不加更好,但对比学习的方法,比CTC损失和L2损失更优。
对比损失加在哪一层?
观察模型结构,我们不难发现对比学习损失函数不仅仅可以在语音表示和文本词嵌入这样的“底层表征” (low-level repr.) 进行,其实也可以在过了 transformer encoder 之后,我们再用对比损失将两者的“高层表征” (high-level repr.),类似的结构可以类比[8]。那么哪种表征更值得用对比学习拉近距离呢?
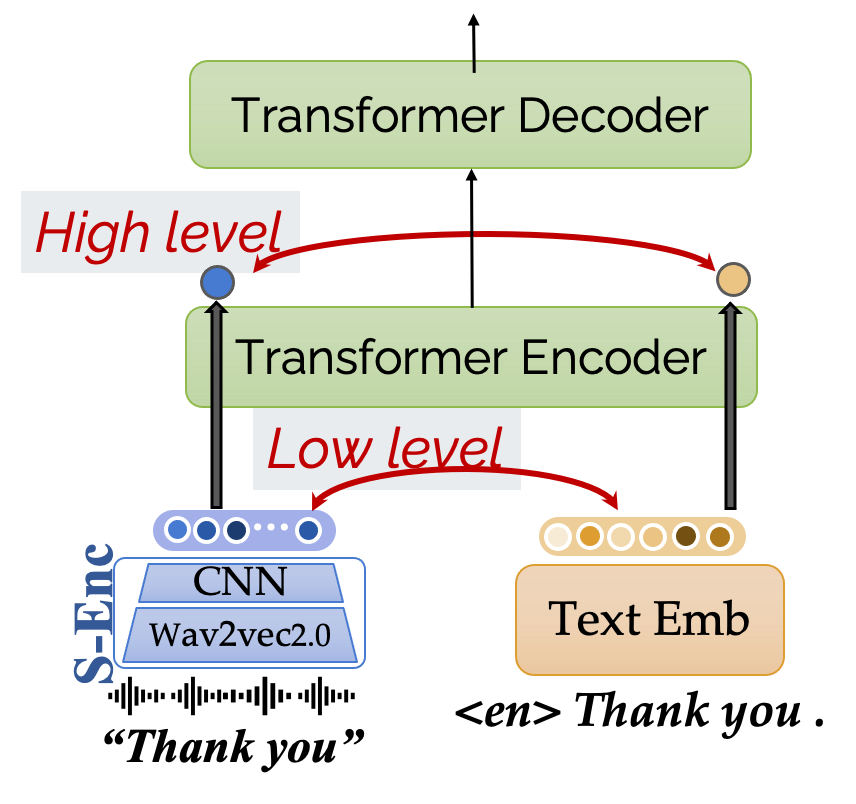
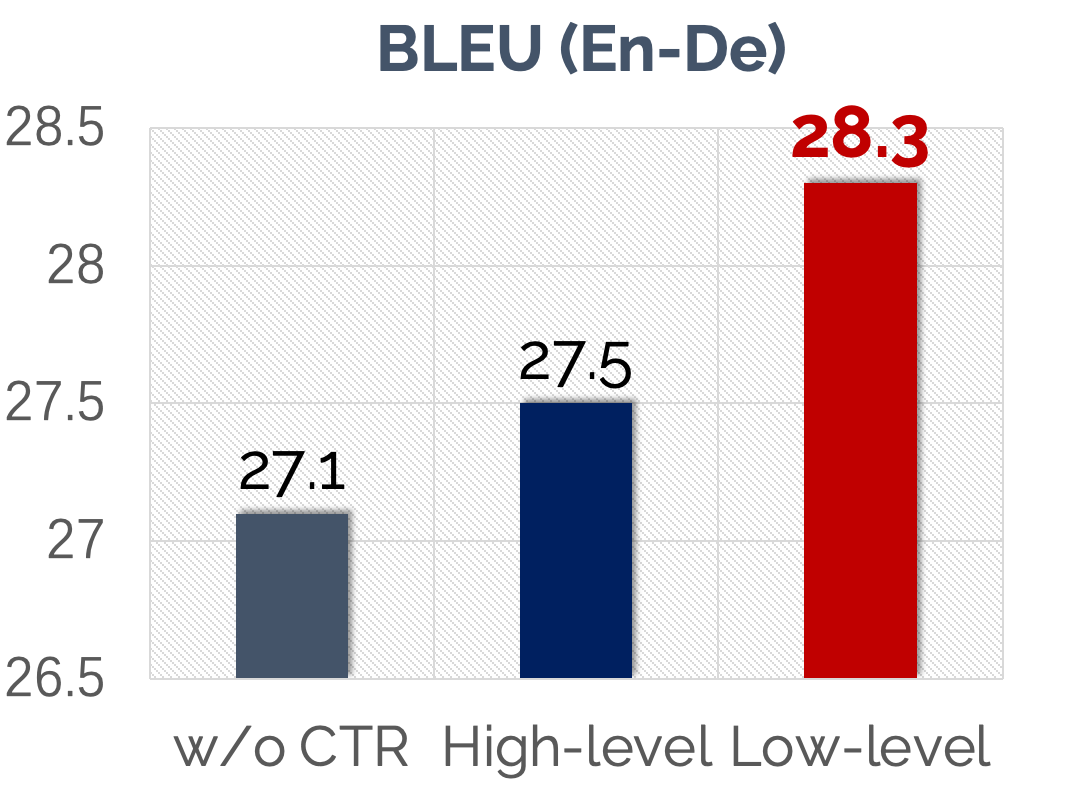
:::
根据文中的实验,我们发现对底层表征进行对比学习,对最后的翻译性能提升更大。
为何会有这种现象?也即对比学习为何奏效?文中则进行了更进一步的分析。
对比学习为何奏效?
表示空间可视化
文章首先对语音和文本的底层表示进行了可视化分析:先利用 T-SNE 进行降维,然后再画 kernel density estimation 分布图。如果语音和文本两者的表示越相近,那 KDE 图的等高线应该越接近重合的状态。
![]()
:::
从图中我们发现,不优化对比学习、只有多任务学习的情况下,语音和文本的表示自然而然分成了两个类(对应左图),这也印证了我们在引入部分说的“模态鸿沟”问题。而仅仅是通过简单的对比学习损失函数,两个模态的表示就明显更好地融合在一起,更为相近。
利用语音是否可以检索语义相近的文本?
除了定性的观察表征的可视化图外,文章还展示了一个定量实验:根据语音表征找 cosine 距离最相似的文本。和前文所提到的一样,文中用了底层表示和高层表示进行召回实验。实验发现在利用底层表示进行召回时,加上对比学习,能让召回准确率提升79.2%之多。另一方面,当我们使用高层表示的时候,即使是没有对比学习,召回准确率就已经能高达94.7%了,也就是说对于高层表示,即使没有其他额外监督损失,仅仅通过多任务学习,两者已经很近了,此时再利用对比学习拉近高层表示的距离,则收益甚小。这也和上文中的“利用底层表示进行对比学习效果更好”相符合。
![]()
:::
ConST的生成效果
这里我们以英-德翻译为例,看看ConST效果
自带端到端翻译的优点:避免错误传播
音频内容为:Lights, sounds, solar panels, motors. Everything should be accessible.
级联模型输出:Licht klingt Solarpaneele, Motoren; alles sollte zugänglich sein. (❌ klingt 为动词,正确的应该是Geräusche,声音,作名词用。传统级联模型因为不知道正确的断句而导致了此错误。)
ConST输出:Licht, Geräusche, Solarpanele, Motoren, alles sollte zugänglich sein. (✅)
比多任务累进模型XSTNet在细节上翻译更准确
音频内容为:Eight years ago, when I was at the Media Lab, I started exploring this idea of how to put the power of engineers in the hands of artists and designers.
我们注意这里的一个表达 “I started exploring this idea of …”
XSTNet输出:Vor acht Jahren, als ich im Media Lab war, begann ich zu erforschen, wie man die … (遗漏了the idea的翻译)
ConST输出:Vor acht Jahren, als ich im Media Lab war, begann ich, diese Idee zu erforschen, wie man die … (✅)
想要体验端到端语音翻译?
- ConST on
NAACL 2022 | 字节和加州大学提出ConST模型,探讨对比学习如何助力语音翻译?相关推荐
- ECCV 2022 | 浙大快手提出CoText:基于对比学习和多信息表征的端到端视频OCR模型...
点击下方卡片,关注"CVer"公众号 AI/CV重磅干货,第一时间送达 点击进入-> CV 微信技术交流群 转载自:CSIG文档图像分析与识别专委会 本文是对快手和浙大联合研 ...
- 伯克利的电气工程和计算机科学专业,斯坦福大学与加州大学伯克利分校电气工程专业对比...
斯坦福大学与加州大学伯克利分校电气工程专业对比.跟着来看看吧.. 斯坦福大学(Stanford University),简称"斯坦福(Stanford)",临近世界著名高科技园区硅 ...
- 大脑也在强化学习!加州大学提出「价值决策」被大脑高效编码,登Neuron顶刊...
来源:深度强化学习实验室 本文约1200字,建议阅读5分钟 本文带你了解一项新研究人和动物的决策离不开大脑,大脑决策要靠"价值信息". [ 导读 ] 人和动物的决策离不开大脑,大脑 ...
- NeurIPS 2022|UIUC联合哥伦比亚大学提出VidIL模型,通吃小样本视觉语言任务
原文链接:https://www.techbeat.net/article-info?id=4205 作者:seven_ 近来,视觉语言模型(video-language models)已经成为多模态 ...
- 鲁汶大学提出可端到端学习的车道线检测算法
点击我爱计算机视觉标星,更快获取CVML新技术 近日,比利时鲁汶大学提出基于可微最小二乘拟合的端到端车道线检测算法,使该任务的学习过程不再割裂,实现整体的系统最优化. 该文作者信息: 背景 众所周知, ...
- CVPR 2022 中科院、腾讯提出LAS-AT,利用“可学习攻击策略”进行“对抗训练”
关注公众号,发现CV技术之美 ▊ 1 引言 由中科院,腾讯AI实验室以及香港中文大学联合出品的硬核对抗训练的新作LAS-AT发表于CVPR2022.对抗训练被认为是抵御对抗攻击最有效的防御方法,它通常 ...
- 直播预告 | AAAI 2022论文解读:融入知识图谱的分子对比学习
「AI Drive」是由 PaperWeekly 和 biendata 共同发起的学术直播间,旨在帮助更多的青年学者宣传其最新科研成果.我们一直认为,单向地输出知识并不是一个最好的方式,而有效地反馈和 ...
- IJCAI 2022 | 鲁棒的Node-Node Level自对齐图对比学习
©作者 | Dream 单位 | 浙江大学 研究方向 | 图表示学习 本文介绍一下我们自己的工作,该论文是一篇图自监督学习的工作,被 IJCAI 2022 接收. 论文标题: RoSA: A Robu ...
- CVPR 2021 | 澳洲国立大学提出基于模型的图像风格迁移
©作者|侯云钟 学校|澳洲国立大学博士生 研究方向|计算机视觉 本文从另外一个角度解读,澳洲国立大学郑良老师实验室 CVPR 2021 新工作.一般而言,我们需要同时利用两张图片完成图像的风格迁移(s ...
最新文章
- 在 Azure 网站上使用 Memcached 改进 WordPress
- linux diff patch 生成和打补丁
- 使用锁实现多线程共用一个数据源
- Qt中的QGridLayout
- 【TF-IDF】传统方法TF-IDF解决短文本相似度问题
- lambda表达式优化反射_反射选择器表达式
- 【渝粤题库】陕西师范大学209041 金融工程学 作业(专升本)
- c语言 结构体_颖儿教你学C语言结构体,全面讲解,让程序小白玩转结构体编程...
- mui获取php表格,Mui table实现数据提取方法
- 系统分析员到底做什么?
- MOS管开关速度相关参数
- 尝试投了下 OR 被拒,领教了顶级期刊的审稿
- spring boot参数校验 告别校验胶水代码
- 高仿京东商城app、集成react-native热更新功能
- pycharm和Anaconda强强联手
- 1.金融市场,资产管理与投资基金
- 如何实现超大文件上传?
- 无线AP服务器维保内容及标准,无线AP系统维护保养规程规定
- PCB javascript实现个税5000计算
- Allegro172版本DFM规则之Annular Ring
热门文章
- 五线城市房价已大幅下跌,房地产泡沫破裂或由此开始
- 读书百客:《轮台歌奉送封大夫出师西征》赏析
- 数的变幻(魔术师的猜牌术(2))
- 大一学生《Web编程基础》期末网页制作 HTML+CSS+JavaScript 企业网页设计实例
- upfst是什么函数C语言,一种基于KF和STUPF组合滤波的SINS大方位失准角初始对准方法技术...
- Python语法备忘
- 64位字长的高性能微型计算机,地址总线字长内存容量寻址范围之间的计算
- 【ubuntu20.04设置中文输入法】
- att汇编教程 linux,att 汇编 helloworld
- 岭南师范学院计算机科学与技术专业如何,2018岭南师范学院专业排名及分数线 王牌专业有哪些...
- ECCV 2022 | 浙大快手提出CoText:基于对比学习和多信息表征的端到端视频OCR模型...