Mars——基于矩阵的统一分布式计算框架
背景
Python
Python 是一门相当古老的语言了,如今,在数据科学计算、机器学习、以及深度学习领域,Python 越来越受欢迎。
大数据领域,由于 hadoop 和 spark 等,Java 等还是占据着比较核心的位置,但是在 spark 上也可以看到,pyspark 的用户占据很大一部分。
深度学习领域,绝大部分的库(tensorflow、pytorch、mxnet、chainer)都支持 Python 语言,且 Python 语言也是这些库上使用最广泛的语言。
对 MaxCompute 来说,Python 用户也是一股重要力量。
PyData(numpy、scipy、pandas、scikit-learn、matplotlib)
Python 在数据科学领域,有非常丰富的包可以选择,下图展示了整个 Python 数据科学技术栈。
![]()
可以看到 numpy 作为基础,在其上,有 scipy 面向科学家,pandas 面向数据分析,scikit-learn 则是最著名的机器学习库,matplotlib 专注于可视化。
对 numpy 来说,其中最核心的概念就是 ndarray——多维数组,pandas、scikit-learn 等库都构建于这个数据结构基础之上。
问题
虽然 Python 在这些领域越来越流行,PyData 技术栈给数据科学家们提供了多维矩阵、DataFrame 上的分析和计算能力、基于二维矩阵的机器学习算法,但这些库都仅仅受限于单机运算,在大数据时代,数据量一大,这些库的处理能力都显得捉襟见肘。
虽然大数据时代,有各种各样基于 SQL 的计算引擎,但对科学计算领域,这些引擎都不太适合用来进行大规模的多维矩阵的运算操作。而且,相当一部分用户,尤其是数据科学家们,习惯于使用各种成熟的单机库,他们不希望改变自己的使用习惯,去学习一些新的库和语法。
此外,在深度学习领域,ndarray/tensor 也是最基本的数据结构,但它们仅仅限制在深度学习上,也不适合大规模的多维矩阵运算。
基于这些考量,我们开发了 Mars,一个基于 tensor 的统一分布式计算框架,前期我们关注怎么将 tensor 这层做到极致。
我们的工作
Mars 的核心用 python 实现,这样做的好处是能利用到现有的 Python 社区的工作,我们能充分利用 numpy、cupy、pandas 等来作为我们小的计算单元,我们能快速稳定构建我们整个系统;其次,Python 本身能轻松和 c/c++ 做继承,我们也不必担心 Python 语言本身的性能问题,我们可以对性能热点模块轻松用 c/cython 重写。
接下来,主要集中介绍 Mars tensor,即多维矩阵计算的部分。
Numpy API
Numpy 成功的一个原因,就是其简单易用的 API。Mars tensor 在这块可以直接利用其作为我们的接口。所以在 numpy API 的基础上,用户可以写出灵活的代码,进行数据处理,甚至是实现各种算法。
下面是两段代码,分别是用 numpy 和 Mars tensor 来实现一个功能。
import numpy as npa = np.random.rand(1000, 2000)
(a + 1).sum(axis=1)import mars.tensor as mta = mt.random.rand(1000, 2000)
(a + 1).sum(axis=1).execute()这里,创建了一个 1000x2000 的随机数矩阵,对其中每个元素加1,并在 axis=1(行)上求和。
目前,Mars 实现了大约 70% 的 Numpy 常用接口。
可以看到,除了 import 做了替换,用户只需要通过调用 execute 来显式触发计算。通过 execute 显式触发计算的好处是,我们能对中间过程做更多的优化,来更高效地执行计算。
不过,静态图的坏处是牺牲了灵活性,增加了 debug 的难度。下个版本,我们会提供 instant/eager mode,来对每一步操作触发计算,这样,用户能更有效地进行 debug,且能利用到 Python 语言来做循环,当然性能也会有所损失。
使用 GPU 计算
Mars tensor 也支持使用 GPU 计算。对于某些矩阵创建的接口,我们提供了 gpu=True 的选项,来指定分配到 GPU,后续这个矩阵上的计算将会在 GPU 上进行。
import mars.tensor as mta = mt.random.rand(1000, 2000, gpu=True)
(a + 1).sum(axis=1).execute()这里 a 是分配在 GPU 上,因此后续的计算在 GPU 上进行。
稀疏矩阵
Mars tensor 支持创建稀疏矩阵,不过目前 Mars tensor 还只支持二维稀疏矩阵。比如,我们可以创建一个稀疏的单位矩阵,通过指定 sparse=True 即可。
import mars.tensor as mta = mt.eye(1000, sparse=True, gpu=True)
b = (a + 1).sum(axis=1)这里看到,gpu 和 sparse 选项可以同时指定。
基于 Mars tensor 的上层建筑
这部分在 Mars 里尚未实现,这里提下我们希望在 Mars 上构建的各个组件。
DataFrame
相信有部分同学也知道 PyODPS DataFrame,这个库是我们之前的一个项目,它能让用户写出类似 pandas 类似的语法,让运算在 ODPS 上进行。但 PyODPS DataFrame 由于 ODPS 本身的限制,并不能完全实现 pandas 的全部功能(如 index 等),而且语法也有不同。
基于 Mars tensor,我们提供 100% 兼容 pandas 语法的 DataFrame。使用 mars DataFrame,不会受限于单个机器的内存。这个是我们下个版本的最主要工作之一。
机器学习
scikit-learn 的一些算法的输入就是二维的 numpy ndarray。我们也会在 Mars 上提供分布式的机器学习算法。我们大致有以下三条路:
- scikit-learn 有些算法支持 partial_fit,因此,我们直接在每个 worker 上调用 sklearn 的算法。
- 提供基于 Mars 的 joblib 后端。由于 sklearn 使用 joblib 来做并行,因此,我们可以通过实现 joblib 的 backend,来让 scikit-learn 直接跑在 Mars 的分布式环境。但是,这个方法的输入仍然是 numpy ndarray,因此,总的输入数据还是受限于内存。
- 在 Mars tensor 的基础上实现机器学习算法,这个方法需要的工作量是最高的,但是,好处是,这些算法就能利用 Mars tensor 的能力,比如 GPU 计算。以后,我们需要更多的同学来帮我们贡献代码,共建 Mars 生态。
细粒度的函数和类
Mars 的核心,其实是一个基于 Actor 的细粒度的调度引擎。因此,实际上,用户可以写一些并行的 Python 函数和类,来进行细粒度的控制。我们可能会提供以下几种接口。
函数
用户能写普通的 Python 函数,通过 mars.remote.spawn 来将函数调度到 Mars 上来分布式运行
import mars.remote as mrdef add(x, y):return x + ydata = [(1, 2),(3, 4)
]for item in data:mr.spawn(add, item[0], item[1])利用 mr.spawn,用户能轻松构建分布式程序。在函数里,用户也可以使用 mr.spawn,这样,用户可以写出非常精细的分布式执行程序。
类
有时候,用户需要一些有状态的类,来进行更新状态等操作,这些类在 Mars 上被称为 RemoteClass。
import mars.remote as mrclass Counter(mr.RemoteClass):def __init__(self):self.value = 0def inc(self, n=1):self.value += ncounter = mr.spawn(Counter)
counter.inc()目前,这些函数和类的部分尚未实现,只是在构想中,所以届时接口可能会做调整。
内部实现
这里,我简单介绍下 Mars tensor 的内部原理。
客户端
在客户端,我们不会做任何真正的运算操作,用户写下代码,我们只会在内存里用图记录用户的操作。
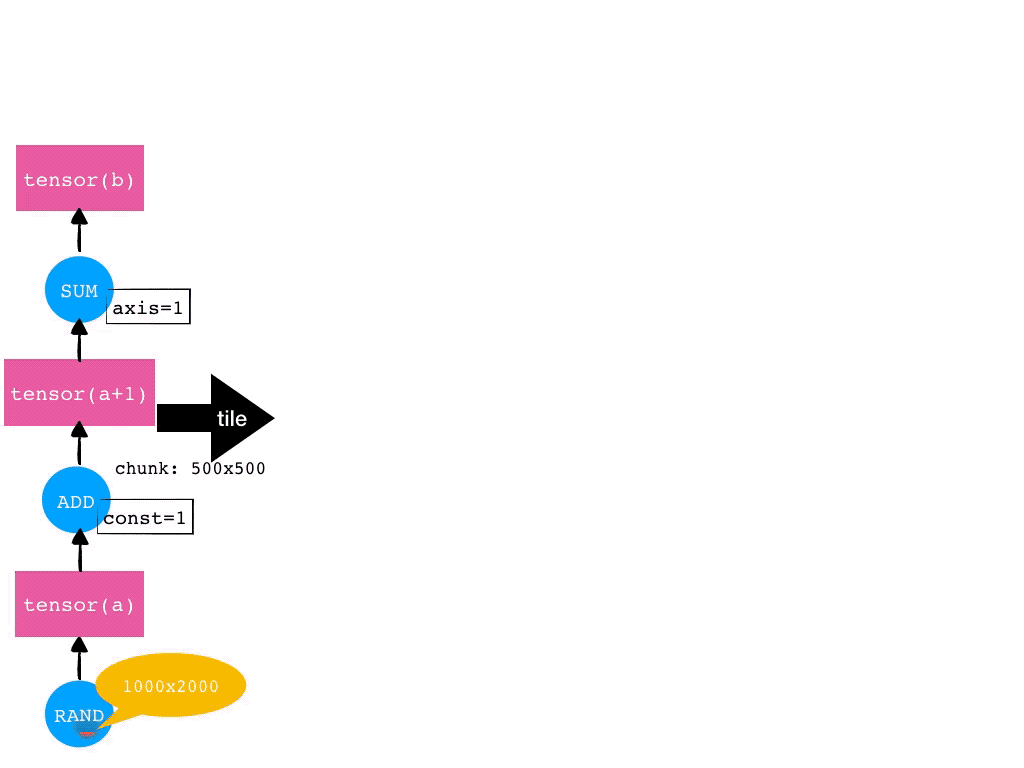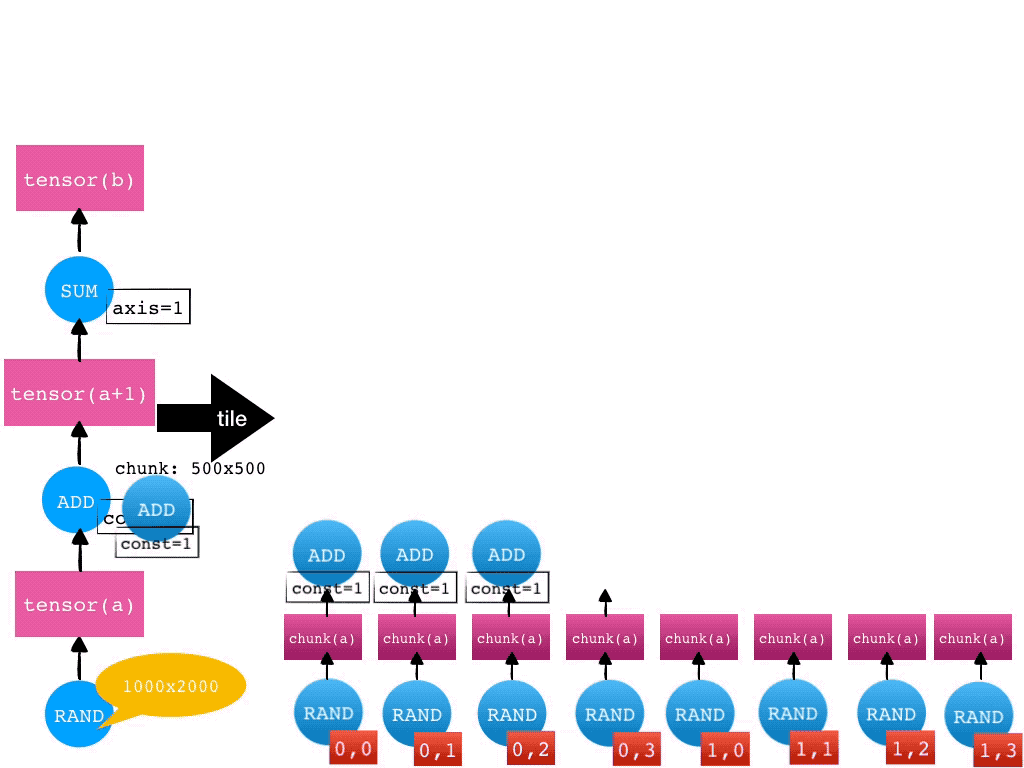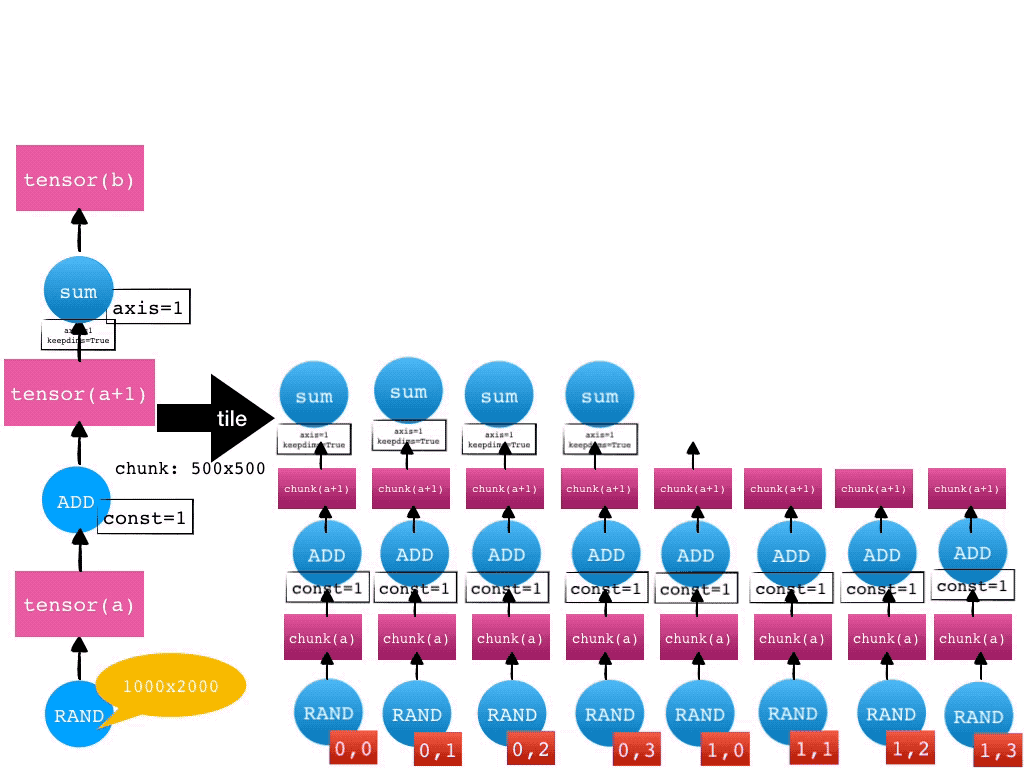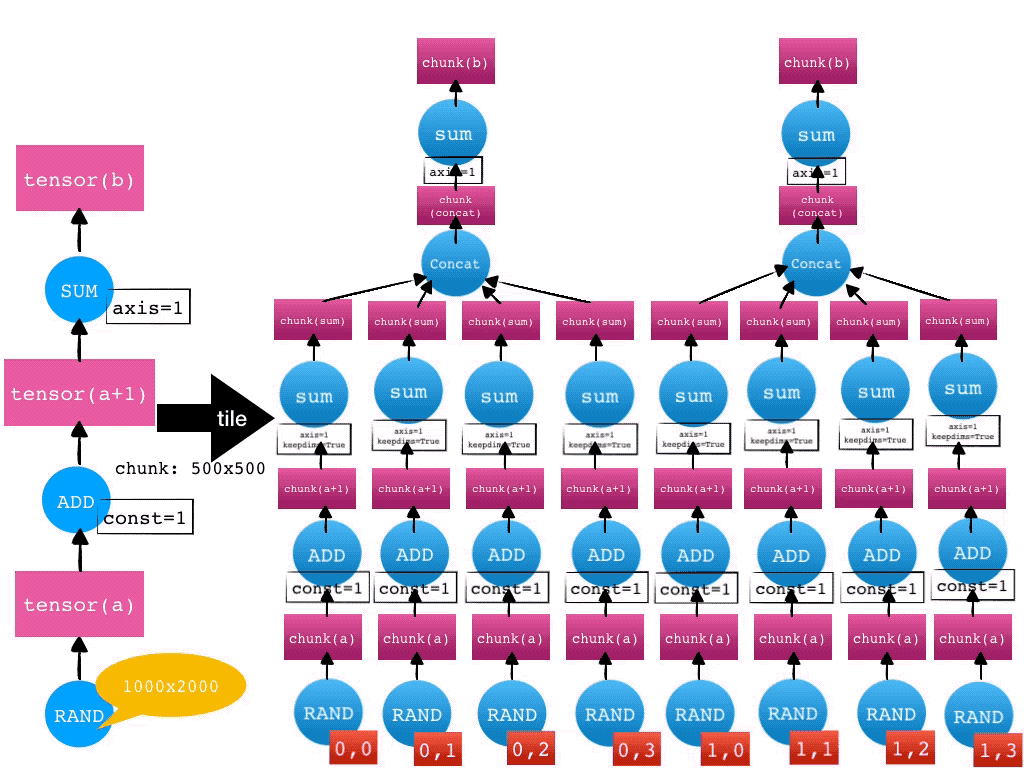
对于 Mars tensor 来说,我们有两个重要的概念,operand 和 tensor,分别如下图的蓝色圆和粉色方块所示。Operand 表示算子,tensor 表示生成的多维数组。
比如,下图,用户写下这些代码,我们会依次在图上生成对应的 operand 和 tensor。

当用户显式调用 execute 的时候,我们会将这个图提交到 Mars 的分布式执行环境。
我们客户端部分,并不会对语言有任何依赖,只需要有相同的 tensor graph 序列化,因此可以用任何语言实现。下个版本我们要不要提供 Java 版本的 Mars tensor,我们还要看是不是有用户需要。
分布式执行环境
Mars 本质上是一个对细粒度图的执行调度系统。
对于 Mars tensor 来说,我们接收到了客户端的 tensor 级别的图(粗粒度),我们要尝试将其转化成 chunk 级别的图(细粒度)。每个 chunk 以及其输入,在执行时,都应当能被内存放下。我们称这个过程叫做 tile。
在拿到细粒度的 chunk 级别的图后,我们会将这个图上的 Operand 分配到各个 worker 上去执行。
总结
Mars 在九月份的云栖大会发布,目前我们已经在 Github 开源:https://github.com/mars-project/mars 。我们项目完全以开源的方式运作,而不是简单把代码放出来。
期待有更多的同学能参与 Mars,共建 Mars。
努力了很久,我们不会甘于做一个平庸的项目,我们期待对世界做出一点微小的贡献——我们的征途是星辰大海!
原文链接
本文为云栖社区原创内容,未经允许不得转载。
Mars——基于矩阵的统一分布式计算框架相关推荐
- Nat. Commun. | 基于最优传输的单细胞数据集成统一计算框架
本文介绍由同济大学控制科学与工程系的洪奕光和中国科学院数学与系统科学研究院的万林共同通讯发表在 Nature Communications 的研究成果:单细胞数据集成可以提供细胞的全面分子视图.然而, ...
- Hadoop技术(二)资源管理器YARN和分布式计算框架MapReduce
资源管理器YARN和分布式计算框架MapReduce 第一章 Hadoop MapReduce 是什么 一 MapReduce 介绍 1. 基本介绍 2. MR数据流程方向 3. MR 原语/ 核心思 ...
- 基于python的深度学习框架有_《用Python实现深度学习框架》上市
朋友们,<用Python实现深度学习框架>已经由人民邮电出版社出版上市了.在这本书中,我们带领读者仅用Python+Numpy实现一个基于计算图的深度学习框架MatrixSlow.本书讲解 ...
- 139.深度学习分布式计算框架-2
139.1 Spark MLllib MLlib(Machine Learnig lib) 是Spark对常用的机器学习算法的实现库,同时包括相关的测试和数据生成器. MLlib是MLBase一部分, ...
- 人机交互系统(2.1)——深度学习分布式计算框架
1 为什么需要分布式计算? 在这个数据爆炸的时代,产生的数据量不断地在攀升,从GB,TB,PB到ZB.挖掘其中数据的价值也是企业在不断地追求的终极目标.但是要想对海量的数据进行挖掘,首先要考虑的就是海 ...
- 分布式系列之分布式计算框架Flink深度解析
Flink作为主流的分布式计算框架,满足批流一体.高吞吐低时延.大规模复杂计算.高可靠的容错和多平台部署能力.本文简要介绍了Flink中的数据流处理流程以及基本部署架构和概念,以加深对分布式计算平台的 ...
- Ray - 面向增强学习场景的分布式计算框架
如果关注这个领域的同学可能知道,Ray其实在去年就已经在开源社区正式发布了,只不过后来就一直没有什么太大动静,前段时间也是因为机缘巧合,我又回头学习了解了一下,顺便总结如下: Ray是什么? Ray ...
- 分布式计算框架Hadoop核心组件
Hadoop作为成熟的分布式计算框架在大数据生态领域已经使用多年,本文简要介绍Hadoop的核心组件MapReduce.YARN和HDFS,以加深了解. 1.Hadoop基本介绍 Hadoop是分布式 ...
- 分布式计算框架Hadoop核心组件概述
Hadoop作为成熟的分布式计算框架在大数据生态领域已经使用多年,本文简要介绍Hadoop的核心组件MapReduce.YARN和HDFS,以加深了解. 1.Hadoop基本介绍 Hadoop是分布式 ...
最新文章
- 亚马逊部分 AWS DNS 系统遭 DDoS 攻击,已达数小时之久
- 抄作业了!6 大 Flask 开源实战项目推荐
- Flink应用实战案例50篇(一)- Flink SQL 在京东的优化实战
- java实现短信上行源码_Java 发送短信验证码 示例源码
- python设计模式5-原型模式
- 共享一个可用的谷歌相机
- Obsidian V0.14.6版本下实时渲染总是出Bug,时常渲染不出来
- python微信推送{u‘errcode‘: 40008, u‘errmsg‘: u‘invalid message type rid: 6111061f-19703d5b
- C语言:链表(动态)创建之头插法和尾插法
- mysql服务重启后不见了_Win10更新后,MySQL服务莫名消失的问题
- 记毕业季——回忆四年大学,青春无悔【正能量】
- 关于串联匹配电阻其作用
- 鸿蒙希夷太清太虚的意思,希夷的意思
- 卡方检验的基本原理详解
- ASO优化:iOS如何做好ASO推广
- \t\t开心学国学(转载)
- python 结束 serve_forever_如何使用Python脚本启动和停止包含“http.server.serveforever”的Python脚本...
- Java使用EasyExcel导出简单、复杂excel,以及多个excel打包导出下载zip
- Tensorflow2.0+Anaconda + Windows10+cuda10.0+python3.7+spyder安装教程
- 【vite+vue3.0】基于vite写一个将md文件渲染为js文件的插件
热门文章
- mysql分布式如何实现原理_分布式通讯协议实现原理
- java实验金额转换_java 数字金额转换中文金额
- 2.3.0配置 spark_配置scala 2.11.12的spark-2.3.0 maven依赖项的问题
- 【LeetCode笔记 - 每日一题】375. 猜数字游戏 II (Java、DFS、动态规划)
- php中文本设置随机颜色,php 产生随机整数,随机字符串,随机颜色等类用法
- linux 帮助文档管理,Linux系统帮助文件使用——man命令
- 编译php时的configure,PHP编译configure时常见错误
- python 最小二乘回归 高斯核_从简单数学建模开始:08最小二乘准则的应用(附python代码)...
- 唯有自己变得强大_真正的自立,唯是让自己变得更加强大
- wan口有流量但电脑上不了网_wan口有ip地址但是上不了网怎么办?