《Python机器学习——预测分析核心算法》——2.3 对“岩石vs.水雷”数据集属性的可视化展示...
本节书摘来异步社区《Python机器学习——预测分析核心算法》一书中的第2章,第2.3节,作者:【美】Michael Bowles(鲍尔斯),更多章节内容可以访问云栖社区“异步社区”公众号查看。
2.3 对“岩石vs.水雷”数据集属性的可视化展示
可视化可以提供对数据的直观感受,这个有时是很难通过表格的形式把握到的。此节将介绍很有用的可视化方法。分类问题和回归问题的可视化会有所不同。在有鲍鱼和红酒数据集的章节中看到回归问题的可视化方法。
2.3.1 利用平行坐标图进行可视化展示
对于具有多个属性问题的一种可视化方法叫作平行坐标图(parallel coordinates plot)。图2-2为平行坐标图的基本样式。图右边的向量([1 3 2 4])代表数据集中某一行属性的值。这个向量的平行坐标图如图2-2中的折线所示。这条折线是根据属性的索引值和属性值画出来的。整个数据集的平行坐标图对于数据集中的每一行属性都有对应的一条折线。基于标签对折线标示不同的颜色,更有利于观测到属性值与标签之间的关系。(在Wikipedia输入“parallel coordinates”会检索出更多的例子。)
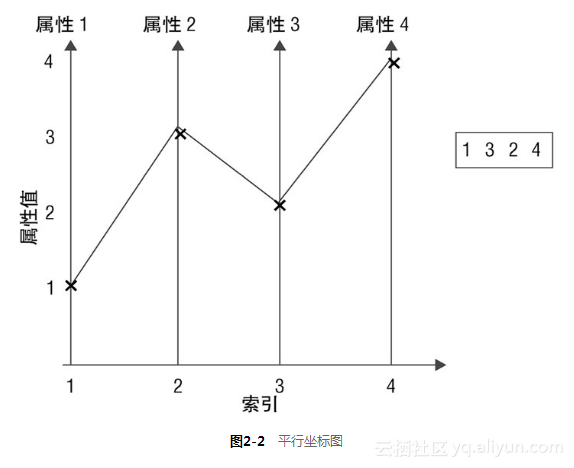
代码清单2-6展示了如何获得“岩石vs.水雷”数据集的平行坐标图。图2-3为结果。折线根据对应的标签赋予不同的颜色:R(岩石)是蓝色,M(水雷)是红色。有时候图画出来后标签(类别)之间可以很明显地区分出来。著名的“鸢尾花数据集”类别之间就可以很明显地区分出来,这就是机器学习算法进行分类应该达到的效果。对应“岩石vs.水雷”数据集则看不到明显的区分。但是有些区域蓝色和红色的折线是分开的。沿着图的底部,蓝色的线要突出一点儿,在属性索引30~40之间,蓝色的线多少要比红色的线高一些。[1]这些观察将有助于解释和确认某些预测的结果。
代码清单2-6 实数值属性的可视化:平行坐标图-linePlots.py
__author__ = 'mike_bowles'
import pandas as pd
from pandas import DataFrame
import matplotlib.pyplot as plot
target_url = ("https://archive.ics.uci.edu/ml/machine-learning-"
"databases/undocumented/connectionist-bench/sonar/sonar.all-data")#read rocks versus mines data into pandas data frame
rocksVMines = pd.read_csv(target_url,header=None, prefix="V")for i in range(208):#assign color based on "M" or "R" labelsif rocksVMines.iat[i,60] == "M":pcolor = "red"else:pcolor = "blue"#plot rows of data as if they were series datadataRow = rocksVMines.iloc[i,0:60]dataRow.plot(color=pcolor)plot.xlabel("Attribute Index")
plot.ylabel(("Attribute Values"))
plot.show()```<div style="text-align: center"><img src="https://yqfile.alicdn.com/650ab5cd482e35defd49513378ac50cbb96acf02.png" width="" height="">
</div>####2.3.2 属性和标签的关系可视化
另外一个需要了解的问题就是属性之间的关系。获得这种成对关系的快速方法就是绘制属性与标签的交会图(cross-plots)。代码清单2-7展示了如何产生代表性属性对的交会图。这些交会图(又叫作散点图,scatter plots)展示了这些属性对之间关系的密切程度。代码清单2-7 属性对的交会图-corrPlot.pyauthor = 'mike_bowles'
import pandas as pd
from pandas import DataFrame
import matplotlib.pyplot as plot
target_url = ("https://archive.ics.uci.edu/ml/machine-learning-"
"databases/undocumented/connectionist-bench/sonar/sonar.all-data")
read rocks versus mines data into pandas data frame
rocksVMines = pd.read_csv(target_url,header=None, prefix="V")
calculate correlations between real-valued attributes
dataRow2 = rocksVMines.iloc[1,0:60]
dataRow3 = rocksVMines.iloc[2,0:60]
plot.scatter(dataRow2, dataRow3)
plot.xlabel("2nd Attribute")
plot.ylabel(("3rd Attribute"))
plot.show()
dataRow21 = rocksVMines.iloc[20,0:60]
plot.scatter(dataRow2, dataRow21)
plot.xlabel("2nd Attribute")
plot.ylabel(("21st Attribute"))
plot.show()
图2-4和图2-5为来自“岩石vs.水雷”数据集的两对属性的散点图。“岩石vs.水雷”数据集的属性是声纳返回的取样值。声纳返回的信号又叫啁啾信号 ,因为它是一个脉冲信号,开始在低频,然后上升到高频。这个数据集的属性就是声波由岩石或水雷反射回来的时间上的取样。这些返回的声学信号携带的时间与频率的关系与发出的信号是一样的。数据集的60个属性是返回的信号在60个不同时间点的取样(因此是60个不同的频率)。你可能会估计相邻的属性会比隔一个的属性更相关,因为在相邻时间上的取样在频率上的差别应该不大。<div style="text-align: center"><img src="https://yqfile.alicdn.com/8a2f4ea1dceeae64e40ffd315e073bae593fd68b.png" width="" height="">
</div>这种直观感受在图2-4和图2-5中得到了证实。图2-4中的点要比图2-5中的点更集中于一条直线。如果想进一步了解数值相关和散点图的形状两者之间的关系,请在wikipedia搜索“correlation(相关)”相关页面。基本上,如果散点图上的点沿着一条“瘦”直线排列,则说明这两个变量强相关;如果这些点形成一个球型,则说明这些点不相关。应用同样原则,可以画出任何一个属性与最终目标(标签)的散点图,研究两者之间的相关性。若对应目标是实数(回归问题),则画出的散点图会与图2-4和图2-5十分相似。“岩石vs.水雷”数据集是一个分类问题,目标是二值的,但是遵循同样的步骤。代码清单2-8展示如何画出标签和第35个属性的散点图。为什么选用第35个属性作为展示属性与标签关系的例子,灵感来自于平行坐标图2-3。这个平行坐标图显示岩石数据与水雷数据在属性索引值35左右有所分离。则标签与索引值35附近的属性的关系也应该显示这种分离,正如图2-6和图2-7所示。代码清单2-8 分类问题标签和实数值属性之间的相关性-targetCorr.pyauthor = 'mike_bowles'
import pandas as pd
from pandas import DataFrame
import matplotlib.pyplot as plot
from random import uniform
target_url = ("https://archive.ics.uci.edu/ml/machine-learning-"
"databases/undocumented/connectionist-bench/sonar/sonar.all-data")
read rocks versus mines data into pandas data frame
rocksVMines = pd.read_csv(target_url,header=None, prefix="V")
change the targets to numeric values
target = []
for i in range(208):
#assign 0 or 1 target value based on "M" or "R" labels
if rocksVMines.iat[i,60] == "M":target.append(1.0)
else:target.append(0.0)
plot 35th attribute
dataRow = rocksVMines.iloc[0:208,35]
plot.scatter(dataRow, target)
plot.xlabel("Attribute Value")
plot.ylabel("Target Value")
plot.show()
To improve the visualization, this version dithers the points a little
and makes them somewhat transparent
target = []
for i in range(208):
assign 0 or 1 target value based on "M" or "R" labels
# and add some ditherif rocksVMines.iat[i,60] == "M":target.append(1.0 + uniform(-0.1, 0.1))
else:target.append(0.0 + uniform(-0.1, 0.1))#plot 35th attribute with semi-opaque pointsdataRow = rocksVMines.iloc[0:208,35]
plot.scatter(dataRow, target, alpha=0.5, s=120)
plot.xlabel("Attribute Value")
plot.ylabel("Target Value")
plot.show()`
如果把M用1代表,R用0代表,就会得到如图2-6所示的散点图。在图2-6中可以看到一个交会图常见的问题。当其中一个变量只取有限的几个值时,很多点会重叠在一起。如果这种点很多,则只能看到很粗的一条线,分辨不出这些点是如何沿线分布的。
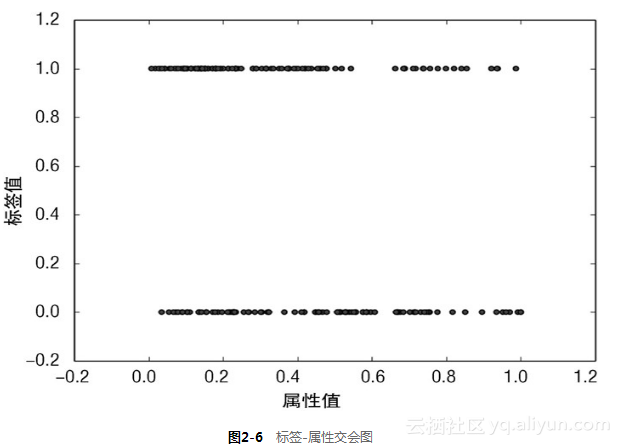
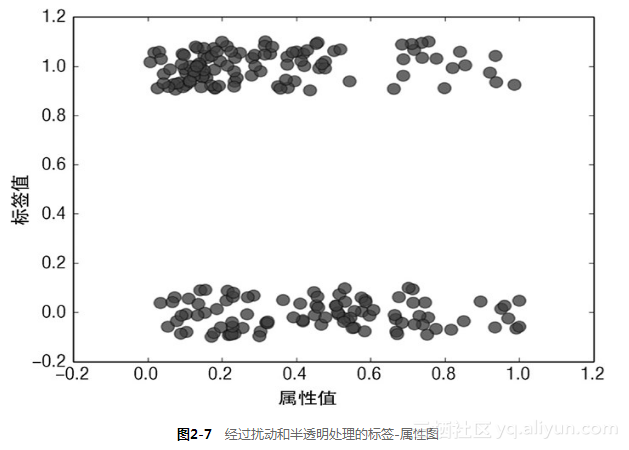
代码清单2-8产生了第二图,通过2个小技巧克服了上述的问题。每个点都加上一个小的随机数,产生了少量的离散值(这里是对标签值进行了处理)。标签值最初是0或1。在代码中可以看到,标签值加上了一个在−0.1和0.1之间均匀分布的随机数,这样就把这些点分散开,但是又不至于把这2条线混淆。此外,这些点绘制时取alpha=0.5,这样这些点就是半透明的。那么在散点图中若多个点落在一个位置就会形成一个更黑的区域,这时需要对数据做一些微调使你能看到你想看到的。
这两种方法的效果如图2-7所示。可以注意到第35个属性在左上方的点更加集中一些,然而在下面的数据从右到左分布得更加均匀些。上方的数据对应水雷的数据。下面的数据对应岩石的数据。由图观察可知,可以因此建立一个分类器,判断第35个属性是否大于或小于0.5。如果大于0.5,就判断为岩石,如果小于0.5,就判断为水雷。在第35个属性值小于0.5的实例中,水雷的分布要更密集,而且在属性值小于0.5的实例中,岩石的分布要稀疏得多。这样就可以获得一个比随机猜测好些的结果。
在第5章和第7章将会看到更系统的构建分类器的方法。它们会用到所有的属性,而不仅仅是一、二个属性。当看到它们是如何做决策时,可以回头看看本章的例子就会理解为什么它们的选择是明智的。
两个属性(或一个属性、一个标签)的相关程度可以由皮尔逊相关系数(Pearson’s correlation coefficient)来量化。给定2个等长的向量u和v(如公式2-1和公式2-2所示)。首先u的所有元素都减去u的均值(见公式2-3)。对v也做同样的事情。
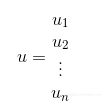
公式2-1 向量u的元素
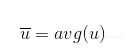
公式2-2 向量u的均值
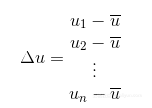
公式2-3 向量u中每个元素都减去均值
以向量Δu相同的定义方式,对应第二个向量v,定义向量Δv。
则u和v之间的皮尔森相关系数如公式2-4所示。
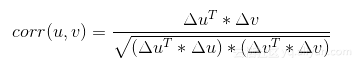
公式2-4 皮尔森相关系数定义
代码清单2-9展示了用该函数计算图2-3和图2-5中属性对的相关系数。相关系数和图中展示的结果一致,索引值距离比较近的属性间相关系数也比较高。
代码清单2-9 对属性2和属性3、属性2和属性21 分别计算各自的皮尔森相关系数-corrCalc.py
__author__ = 'mike_bowles'
import pandas as pd
from pandas import DataFrame
from math import sqrt
import sys
target_url = ("https://archive.ics.uci.edu/ml/machine-learning-"
"databases/undocumented/connectionist-bench/sonar/sonar.all-data")#read rocks versus mines data into pandas data frame
rocksVMines = pd.read_csv(target_url,header=None, prefix="V")#calculate correlations between real-valued attributes
dataRow2 = rocksVMines.iloc[1,0:60]
dataRow3 = rocksVMines.iloc[2,0:60]
dataRow21 = rocksVMines.iloc[20,0:60]mean2 = 0.0; mean3 = 0.0; mean21 = 0.0
numElt = len(dataRow2)
for i in range(numElt):mean2 += dataRow2[i]/numEltmean3 += dataRow3[i]/numEltmean21 += dataRow21[i]/numEltvar2 = 0.0; var3 = 0.0; var21 = 0.0
for i in range(numElt):var2 += (dataRow2[i] - mean2) * (dataRow2[i] - mean2)/numEltvar3 += (dataRow3[i] - mean3) * (dataRow3[i] - mean3)/numEltvar21 += (dataRow21[i] - mean21) * (dataRow21[i] - mean21)/numEltcorr23 = 0.0; corr221 = 0.0
for i in range(numElt):corr23 += (dataRow2[i] - mean2) * \(dataRow3[i] - mean3) / (sqrt(var2*var3) * numElt)corr221 += (dataRow2[i] - mean2) * \(dataRow21[i] - mean21) / (sqrt(var2*var21) * numElt)sys.stdout.write("Correlation between attribute 2 and 3 \n")
print(corr23)
sys.stdout.write(" \n")
sys.stdout.write("Correlation between attribute 2 and 21 \n")
print(corr221)
sys.stdout.write(" \n")Output:
Correlation between attribute 2 and 3
0.770938121191Correlation between attribute 2 and 21
0.4665480807892.3.3 用热图(heat map)展示属性和标签的相关性
对于计算少量的相关性,将相关性结果打印输出或者画成散点图都是可以的。但是对于大量的数据,就很难用这种方法整体把握相关性。如果问题有100以上的属性,则很难把散点图压缩到一页。
获得大量属性之间相关性的一种方法就是计算出每对属性的皮尔森相关系数后,将相关系数构成一个矩阵,矩阵的第ij-th个元素对应第i个属性与第j个属性的相关系数,然后把这些矩阵元素画到热图上。代码清单2-10为热图的代码实现。图2-8就是这种热图。沿着斜对角线的浅色区域证明索引值相近的属性相关性较高。正如上文提到的,这与数据产生的方式有关。索引相近说明是在很短的时间间隔内取样的,因此声纳信号的频率也接近,频率相近说明目标(标签)也类似。
代码清单2-10 属性相关系数可视化-sampleCorrHeatMap.py
__author__ = 'mike_bowles'
import pandas as pd
from pandas import DataFrame
import matplotlib.pyplot as plot
target_url = ("https://archive.ics.uci.edu/ml/machine-learning-"
"databases/undocumented/connectionist-bench/sonar/sonar.all-data")#read rocks versus mines data into pandas data frame
rocksVMines = pd.read_csv(target_url,header=None, prefix="V")#calculate correlations between real-valued attributes
corMat = DataFrame(rocksVMines.corr())#visualize correlations using heatmap
plot.pcolor(corMat)
plot.show()```<div style="text-align: center"><img src="https://yqfile.alicdn.com/503adf13b79dcdac254303e279e43c3d21f90480.png" width="" height="">
</div>属性之间如果完全相关(相关系数=1)意味着数据可能有错误,如同样的数据录入两次。多个属性间的相关性很高(相关系数>0.7),即多重共线性(multicollinearity),往往会导致预测结果不稳定。属性与标签的相关性则不同,如果属性和标签相关,则通常意味着两者之间具有可预测的关系。####2.3.4 对“岩石vs.水雷”数据集探究过程小结《Python机器学习——预测分析核心算法》——2.3 对“岩石vs.水雷”数据集属性的可视化展示...相关推荐
- 《Python机器学习——预测分析核心算法》——2.5 用实数值属性预测实数值目标:评估红酒口感...
本节书摘来异步社区<Python机器学习--预测分析核心算法>一书中的第2章,第2.5节,作者:[美]Michael Bowles(鲍尔斯),更多章节内容可以访问云栖社区"异步社 ...
- 《Python机器学习——预测分析核心算法》——2.4 基于因素变量的实数值预测:鲍鱼的年龄...
本节书摘来异步社区<Python机器学习--预测分析核心算法>一书中的第2章,第2.4节,作者:[美]Michael Bowles(鲍尔斯),更多章节内容可以访问云栖社区"异步社 ...
- 《Python机器学习——预测分析核心算法》——2.2 分类问题:用声纳发现未爆炸的水雷...
本节书摘来异步社区<Python机器学习--预测分析核心算法>一书中的第2章,第2.2节,作者:[美]Michael Bowles(鲍尔斯),更多章节内容可以访问云栖社区"异步社 ...
- python模型预测_《Python机器学习——预测分析核心算法》——1.5 构建预测模型的流程...
本节书摘来异步社区<Python机器学习--预测分析核心算法>一书中的第1章,第1.5节,作者:[美]Michael Bowles(鲍尔斯),更多章节内容可以访问云栖社区"异步社 ...
- 惩罚线性回归---Python机器学习:预测分析核心算法
惩罚线性回归 参考教材:Python机器学习预测分析核心算法,书中代码较为过时,借用sklearn等工具包进行了重写. 实践中遇到的绝大多数预测分析(函数逼近)问题,惩罚线性回归和集成方法都具有最优或 ...
- python分类预测_《Python机器学习——预测分析核心算法》——2.6 多类别分类问题:它属于哪种玻璃...
本节书摘来异步社区<Python机器学习--预测分析核心算法>一书中的第2章,第2.6节,作者:[美]Michael Bowles(鲍尔斯),更多章节内容可以访问云栖社区"异步社 ...
- python数据预测模型算法_《python机器学习—预测分析核心算法》:构建预测模型的一般流程...
参见原书1.5节 构建预测模型的一般流程 问题的日常语言表述->问题的数学语言重述 重述问题.提取特征.训练算法.评估算法 熟悉不同算法的输入数据结构: 1.提取或组合预测所需的特征 2.设定训 ...
- python数据预测模型算法_Python机器学习 预测分析核心算法
第1章关于预测的两类核心算法 1.1为什么这两类算法如此有用 1.2什么是惩罚回归方法 1.3什么是集成方法 1.4算法的选择 1.5构建预测模型的流程 1.5.1构造一个机器学习问题 1.5.2特征 ...
- python预测算法_Python机器学习:预测分析核心算法
领取成功 您已领取成功! 您可以进入Android/iOS/Kindle平台的多看阅读客户端,刷新个人中心的已购列表,即可下载图书,享受精品阅读时光啦! - | 回复不要太快哦~ 回复内容不能为空哦 ...
- 【Python机器学习预测分析算法实战三】预测模型性能评估及影响因素
选择并拟合一个预测算法的最终目标是获得最佳可能的效果.能够达到的性能取决于3方面的因素:问题的复杂性,模型算法的复杂性,可用数据的丰富程度. 理解函数逼近 预测问题包括两种变量: 第一种变 ...
最新文章
- segMatch:基于3D点云分割的回环检测
- 浅谈Java反射机制 之 获取类的字节码文件 Class.forName(全路径名) 、getClass()、class...
- 不同浏览器 ajax,完整的 AJAX 写法(支持多浏览器)
- android实现跑马灯效果(最小集代码)
- 【重要】如何彻底夯实CV基础,有三AI三大导师一起带你学习!
- [浪风JQuery开发]jquery最有意思的IFrame类似应用--值得深入研究
- Windows Embedded Standard 7 剪裁随笔
- [过年菜谱之]清蒸鲍鱼
- 前端开发~uni-app ·[项目-仿糗事百科] 学习笔记 ·007【uni-app和vue.js基础快速上手】
- 用户自定义函数代替游标进行循环拼接
- 如果REST应用程序应该是无状态的,那么如何管理会话?
- 使用grep命令快速定位代码位置
- 计算机网络数据链路层之使用点对点信道
- 数据可视化大屏设计经验分享
- 美团 O2O 供应链系统架构设计解析
- WSJ0中的wv文件如何转换为wav文件
- 如何更改QQ截图的快捷键
- mongodb集群修改IP地址
- 趁着中秋节来临之际,学学如何做好团队管理
- centos7 kubernetes
热门文章
- 边缘计算中高效ML的EEoI
- 使用c语言函数的小结,C语言函数指针小结(1)
- access insert语句怎么写_ySQL中特别实用的几种SQL语句送给大家
- mysql创建多个联合索引吗_高性能索引油画策略(二):多个索引是独立建立索引还是建联合索引?...
- kafka测试工具_kafka压测工具:同步方式2000+、异步方式10000+、带源码
- 64位userdata.dll丢失_因为计算机中丢失OCI.dll尝试重新安装该程序以解决此问题
- swagger-ui多端口自动切换优化
- HDU 6098 Inversion 思维
- [Asp.Net web api]基于自定义Filter的安全认证
- 如何在app应用中添加支付宝支付功能(解惑版)