转载-聊一聊深度学习的activation function
目录
- 1. 背景
- 2. 深度学习中常见的激活函数
- 2.1 Sigmoid函数
- 2.2 tanh函数
- 2.3 ReLU函数
- 2.4 Leaky ReLu函数
- 2.5 ELU(Exponential Linear Units)函数
- 3. 小结
- Reference
文章来源于夏飞-聊一聊深度学习的activation function;
文章核心内容未作改变,部分排版会有少许变化;
1. 背景
深度学习的基本原理是基于人工神经网络,信号从一个神经元进入,经过非线性的activation function,传入到下一层神经元;再经过该层神经元的activate,继续往下传递,如此循环往复,直到输出层。正是由于这些非线性函数的反复叠加,才使得神经网络有足够的capacity来抓取复杂的pattern,再各个领域取得state-of-the-art的结果。显而易见,activate function在深度学习中举足轻重,也是很活跃的研究领域之一。目前来讲,选择怎样的activation function不在于它能否模拟真正的神经元,而是在于能够便于优化整个神经网络。下面我们简单聊一下各类函数的特点以及为什么现在优先推荐ReLU函数。
2. 深度学习中常见的激活函数
2.1 Sigmoid函数
\[ \sigma = \dfrac{1}{1+e^{-x}} \]
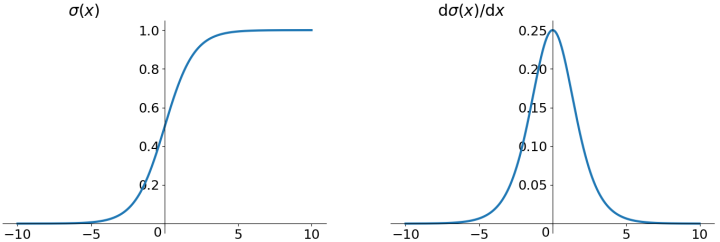
Sigmoid函数是深度学习领域开始时使用频率较高的activation function。它是便于求导的平滑函数,其导数为\(\sigma(x)(1-\sigma(x))\),这是优点。然而,Sigma有三大缺点:
- 容易出现gradient vanishing
- 函数输出并不是zero-centered
- 幂运算相对来讲比较耗时
2.1.1 Gradient Vanishing
优化神经网络的方法是Back Propagation,即导数的后向传递:先计算输出层对应的loss,然后将loss以导数的形式不断向上一层网络传递,修正相应的参数,达到降低loss的目的。Sigmoid函数在深度网络中常常会导致导数逐渐变为0,使得参数无法被更新,神经网络无法被优化。原因在于两点:
(1)在上图中容易看出,\(\sigma(x)\)中\(x\)较大或较小时,导数接近于0,而后向传递的数学依据时微积分求导的链式法则,当前层的导数需要之前各层导数的乘积,几个小数的相乘,结果会很接近于0;
(2)Sigmoid导数的最大值时0.25,这意味着导数在每一层至少会被压缩为原来的1/4,通过两层后被变为1/16,...,通过10层后为1/1048576。请注意这里时“至少”,导数达到最大值这种情况还是很少见的。
2.1.2 输出不是zero-centered
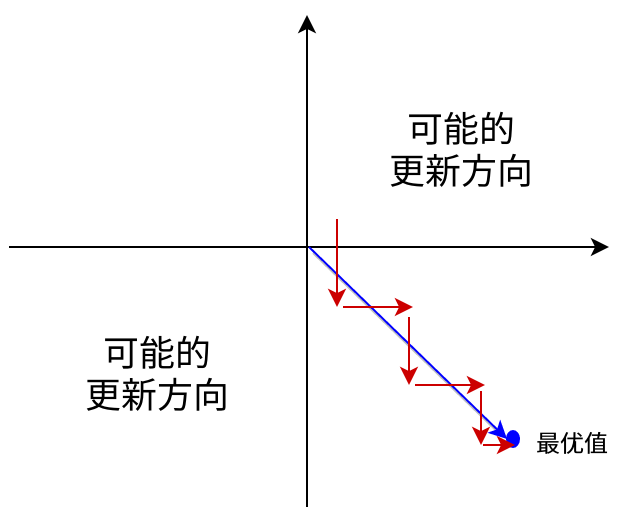
Sigmoid函数的输出值恒大于0,这会导致模型训练的收敛速度变慢。举例来讲,对\(\sigma(\sum_iw_ix_i+b)\),如果所有\(x_i\)均为正数或负数,那么其对\(w_i\)的导数总是正数或负数,这会导致如下图红色箭头所示的阶梯式更新,这显然并非一个好的优化路径。深度学习往往需要大量时间来处理大量数据,模型的收敛速度时尤为重要的。所以,总体上来讲,训练深度学习网络尽量使用zero-centered数据(可以通过数据预处理实现)和zero-centered输出。
2.1.3 幂运算相对耗时
相对于前两项,这其实并不是一个大问题,我们目前是具备相应计算能力的,但面对深度学习中庞大的计算量,最好能省则省 :-)。之后我们会看到,在ReLu函数中,需要做的仅仅是一个thresholding,相对幂运算来讲会快很多。
2.2 tanh函数
\[ tanh(x) = \dfrac{e^x-e^{-x}}{e^x+e^{-x}} \]
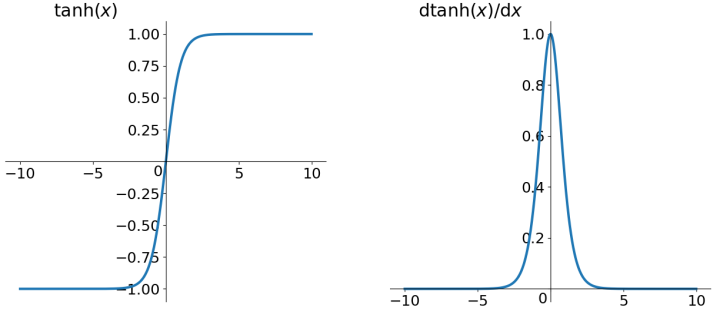
tanh读作Hyperbolic Tangent,如上图所示,它解决了zero-centered的输出问题,然而,gradient vanishing的问题和幂运算的问题仍然存在。
2.3 ReLU函数
\[ ReLU = max(0, x) \]
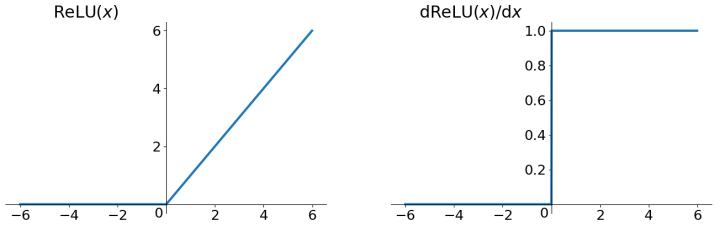
ReLU函数其实就是一个取最大值函数,注意这并不是全区间可导的,但是我们可以取sub-gradient,如上图所示。ReLU虽然简单,但是确实近几年的重要成果,有以下几大优点:
- 解决了gradient vanishing的问题(在正区间)
- 计算速度非常快,只需要判断输入是否大于0
- 收敛速度快于Sigmoid和tanh
ReLU也有几个需要特别注意的问题:
(1)ReLU的输出不是zero-centered
(2)Dead ReLU Problem,指的是某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。有两个主要原因可能导致这种情况产生:
- 非常不幸的参数初始化,这种情况比较少见;
- learning rate太高导致在训练过程中参数更新太大,不幸使网络进入这种状态。解决方法可以采用Xavier初始化方法,以及避免将learning rate设置太大或使用adagrad等自动调节learning rate的算法;
尽管存在这两个问题,ReLU目前仍是最常用的activation function,在搭建人工神经网络的时候推荐优先尝试;
2.4 Leaky ReLu函数
\[ f(x) = max(0.01x, x) \]
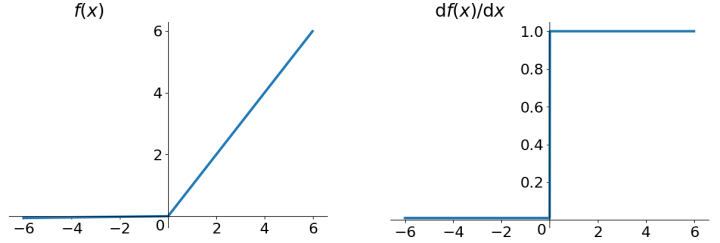
人们为了解决Dead ReLU Problem,提出了将ReLU的前半段设为\(0.01x\)而非0。另外一种直观的想法是基于参数的方法,即Parametric ReLU:\(f(x)=max(\alpha x,x)\),其中\(\alpha\)可由back propagation学出来。理论上来讲,Leaky ReLU有ReLU的所有优点,外加不会有Dead ReLU问题,但是实际操作当中,并没有完全证明Leaky ReLU总是好于ReLU。
2.5 ELU(Exponential Linear Units)函数
\[ f(x)=\begin{cases}x, &if\ x > 0 \cr\alpha(e^x-1), &otherwise\end{cases} \]
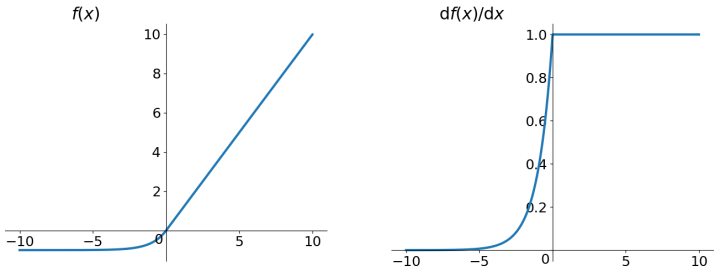
ELU也是为解决ReLU存在的问题而提出,显然,ELU有ReLU的基本所有优点,以及:
- 不会有Dead ReLU问题
- 输出的均值接近于0,zero-centered
它的一个小问题在于计算量稍大。类似于Leaky ReLU,理论上虽然好于ReLU,但在实际使用中目前并没有好的证据ELU总是优于ReLU。
3. 小结
建议使用ReLU函数,但是要注意初始化和learning rate的设置;可以尝试用Leaky ReLU或ELU函数;不建议使用tanh,尤其是Sigmoid函数;
Reference
- Udacity Deep Learning Courses
- Stanford CS231n Course
转载于:https://www.cnblogs.com/chenzhen0530/p/10656683.html
转载-聊一聊深度学习的activation function相关推荐
- 聊一聊深度学习的activation function
转载自:https://zhuanlan.zhihu.com/p/25110450 TLDR (or the take-away) 优先使用ReLU (Rectified Linear Unit) 函 ...
- 深度学习这么调参训练_聊一聊深度学习中的调参技巧?
本期问题能否聊一聊深度学习中的调参技巧? 我们主要从以下几个方面来讲.1. 深度学习中有哪些参数需要调? 2. 深度学习在什么时候需要动用调参技巧?又如何调参? 3. 训练网络的一般过程是什么? 1. ...
- 聊一聊深度学习的weight initialization
转载自:https://zhuanlan.zhihu.com/p/25110150 TLDR (or the take-away) Weight Initialization matters!!! 深 ...
- 谷歌工程师:聊一聊深度学习的weight initialization
TLDR (or the take-away) Weight Initialization matters!!! 深度学习中的weight initialization对模型收敛速度和模型质量有重要影 ...
- 【Todo】【转载】深度学习神经网络 科普及八卦 学习笔记 GPU SIMD
上一篇文章提到了数据挖掘.机器学习.深度学习的区别:http://www.cnblogs.com/charlesblc/p/6159355.html 深度学习具体的内容可以看这里: 参考了这篇文章:h ...
- [转载]机器学习深度学习经典资料汇总,全到让人震惊
自学成才秘籍!机器学习&深度学习经典资料汇总 转自:中国大数据: http://www.thebigdata.cn/JiShuBoKe/13299.html [日期:2015-01-27] 来 ...
- 【转载】深度学习数学基础(二)~随机梯度下降(Stochastic Gradient Descent, SGD)
Source: 作者:Evan 链接:https://www.zhihu.com/question/264189719/answer/291167114 来源:知乎 著作权归作者所有.商业转载请联系作 ...
- 崇志宏 【转载】深度学习进阶规划(论文阅读顺序推荐)--东南大学
阅读文献是搞清楚深度学习本质的基本方式,转载按照顺序阅读文献的整理,对大家会有很好的帮助! 东南大学 崇志宏 1 Deep Learning History ...
- 聊一聊深度学习做寿命预测
本博客的码字背景 最近马上就研三了,回顾一路从小白开始入门深度学习做机械核心零部件寿命预测的历程吧. 1.本科期间未接触过python,深度学习相关的内容. 2.研究生在寿命预测方向入门画的时间比较长 ...
最新文章
- elasticsearch api中的Bulk API操作
- 算法题目中经典问题(易错点)
- 22、java中的注解
- mysql修改校对集_MySQL 图文详细教程之校对集问题
- 一步步学习SPD2010--第十二章节--理解可用性和可接入性(5)--测试可用性
- 分享两个必应壁纸接口,可用来获取高质量壁纸和故事
- 囧。。。不知不觉破解了IDMan。。。木有注意最后一步咋破的。。。
- 模电Aus,Uo/Us,童诗白例2.3.3。
- 海康Ehome协议的的PS流分析
- 计算机无法识别1136打印机,惠普HP M1136打印机驱动安装失败的多种解决办法
- UT000020: Connection terminated as request was larger than 10485760
- git使用大全,强大的项目管理工具
- “我应为王”,比尔盖茨名言--author :邵京国
- android jnl的mk文件,动态语言与静态语言
- 这些排查内存问题的命令,你用过多少?
- 关于鸿蒙系统传统文化的作文,【热门】传统文化作文汇编6篇
- js原生常用知识点总结
- 京东集团副总裁李大学:像CEO一样思考 - Dancen的专栏 - 博客频道 - CSDN.NET
- java2019面试题北京
- OpenCV梯度运算、礼帽与黑帽