CUDA学习(三十六)
内置的矢量类型:
char, short, int, long, longlong, float, double:
这些是从基本整数和浮点类型派生的矢量类型。 它们是结构,第一,第二,第三和第四个组件分别可以通过字段x,y,z和w访问。 它们都带有一个构造函数,形式为make_ <type name>; 例如:
int2 make_int2(int x, int y);它创建一个类型为int2的向量,其值为(x,y)
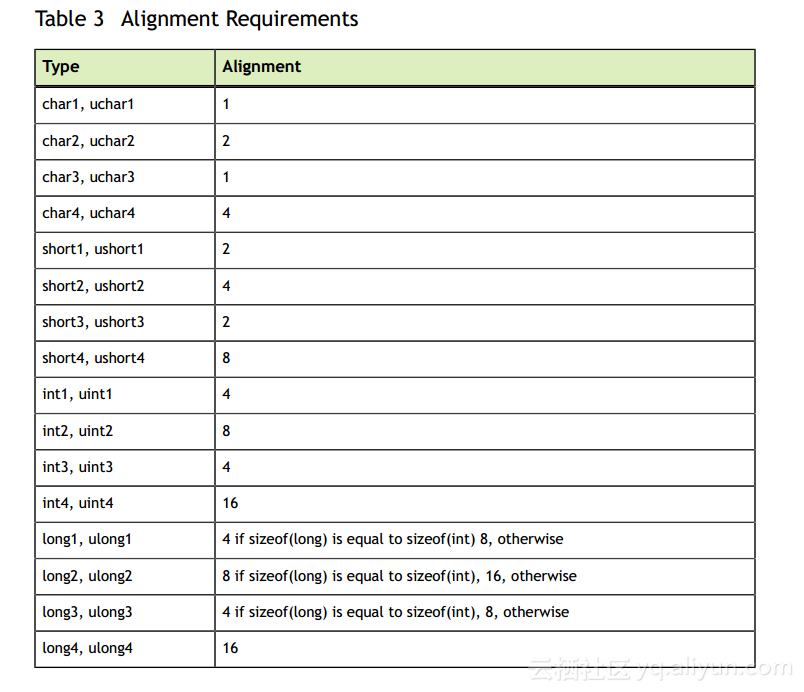
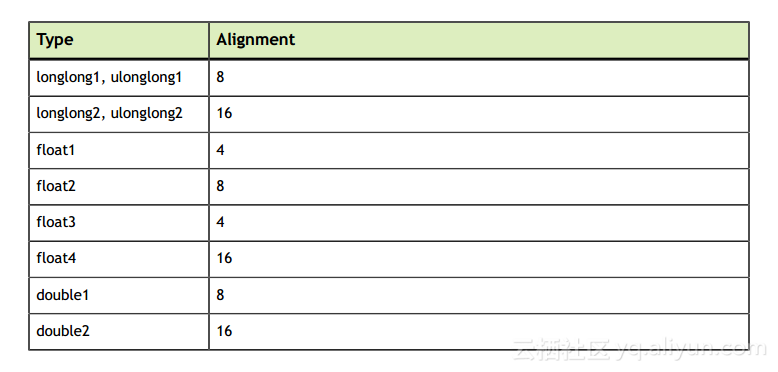
表3列出了矢量类型的对齐要求:
dim3:
此类型是基于uint3的整数矢量类型,用于指定尺寸。 当定义类型为dim3的变量时,任何未指定的组件都被初始化为1。
内置变量:
内置变量指定网格和块的尺寸以及块和线索的索引。 它们仅在设备上执行的功能内有效;
gridDim:
此变量的类型为dim3(请参阅dim3)并包含网格(grid)的尺寸
blockIdx:
这个变量的类型是uint3(参见char,short,int,long,longlong,float,double),并在网格中包含块索引。
blockDim:
该变量的类型为dim3(请参阅dim3)并包含块的尺寸
threadIdx:
这个变量的类型为uint3(参见char,short,int,long,longlong,float,double)并包含块内的线程索引
warpSize:
此变量的类型为int,并且包含线程中的warp大小(有关warp的定义,请参见SIMT体系结构)。
记忆栅栏功能:
CUDA编程模型假设一个设备的内存模型是弱顺序的,即CUDA线程将数据写入共享内存,全局内存,页面锁定主机内存或对等设备内存的顺序不一定是 观察数据的顺序是由另一个CUDA或主机线程写入的。
例如,如果线程1执行writeXY(),并且线程2执行readXY(),如以下代码示例中所定义:
__device__ volatile int X = 1, Y = 2;
__device__ void writeXY()
{X = 10;Y = 20;
}
__device__ void readXY()
{int A = X;int B = Y;
}有可能B最终等于20,A对于线程2等于1.在一个强排序的内存模型中,唯一的可能性是:
- A equal to 1 and B equal to 2,
- A equal to 10 and B equal to 2,
- A equal to 10 and B equal to 20
内存围栏功能可以用来执行内存访问的一些排序。 内存栅栏功能在执行顺序的范围上有所不同,但它们独立于所访问的内存空间(共享内存,全局内存,页锁内存和对等设备的内存)。
void __threadfence_block();
确保:
- 在对
__threadfence_block()的调用之前,调用线程的所有线程都会观察到所有写入由调用线程所做的所有内存的全部内存,而不是在调用__threadfence_block()之后全部写入到调用线程所做的所有内存之前。 - 在对
__threadfence_block()的调用之前,调用线程所做的所有内存读取都是在调用__threadfence_block()之后的调用线程所有内存读取之前进行的。
void __threadfence();
对调用线程的块中的所有线程都起着__threadfence_block()的作用,并且还确保在调用__threadfence()之后调用线程所做的所有内存都不会被设备中的任何线程观察到, 在调用__threadfence()之前调用线程所做的所有内存。 请注意,为了确保此顺序保证为真,观察线程必须真正观察内存,而不是其缓存版本; 这通过使用挥发性限定符中详细说明的volatile关键字来保证。
void __threadfence_system(); 对调用线程的块中的所有线程都起着__threadfence_block()的作用,并确保在调用__threadfence_system()之前由设备中的所有线程,主线程和所有线程 在调用__threadfence_system()之后,在对等设备中的所有线程写入由调用线程创建的所有内存之前,
__threadfence_system()仅受计算能力2.x和更高的设备的支持
在前面的代码示例中,在X = 10之间插入栅栏函数调用; 和Y = 20; 和int A = X之间; int B = Y; 将确保对于线程2,如果B等于20,则A总是等于10.如果线程1和2属于同一个块,则使用__threadfence_block()就足够了。 如果线程1和2不属于同一个块,则必须使用__threadfence()(如果它们是来自同一设备的CUDA线程,并且必须使用__threadfence_system()(如果它们是来自两个不同设备的CUDA线程)。
一个常见的用例是线程消耗其他线程产生的一些数据,如以下内核代码示例所示,该内核计算一个调用中N个数字的和。 每个块首先将数组的一个子集相加并将结果存储在全局内存中。 当所有块完成时,最后完成的块从全局内存中读取这些部分和,并将它们相加以获得最终结果。 为了确定哪个块最后完成,每个块以原子方式递增一个计数器,以通过计算并存储其部分和(参见关于原子函数的原子函数)来表明它已完成。 最后一个块是接收等于gridDim.x-1的计数器值的块。 如果在存储部分总和和递增计数器之间没有放置栅栏,计数器可能会在部分总和存储之前递增,因此可能会达到gridDim.x-1,并且让最后一个块在实际更新之前开始读取部分总和 在记忆中。
内存围栏功能只影响线程对内存操作的排序; 它们不确保这些内存操作对其他线程可见(如__syncthreads()对块内的线程所做的操作(请参阅同步函数))。 在下面的代码示例中,通过将结果变量声明为volatile来确保内存操作对结果变量的可见性(请参阅“易失性限定符”)。
__device__ unsigned int count = 0;
__shared__ bool isLastBlockDone;
__global__ void sum(const float* array, unsigned int N,volatile float* result)
{// Each block sums a subset of the input array.float partialSum = calculatePartialSum(array, N);if (threadIdx.x == 0) {// Thread 0 of each block stores the partial sum// to global memory. The compiler will use// a store operation that bypasses the L1 cache// since the "result" variable is declared as// volatile. This ensures that the threads of// the last block will read the correct partial// sums computed by all other blocks.result[blockIdx.x] = partialSum;// Thread 0 makes sure that the incrementation// of the "count" variable is only performed after// the partial sum has been written to global memory.__threadfence();// Thread 0 signals that it is done.unsigned int value = atomicInc(&count, gridDim.x);// Thread 0 determines if its block is the last// block to be done.isLastBlockDone = (value == (gridDim.x - 1));}// Synchronize to make sure that each thread reads// the correct value of isLastBlockDone.__syncthreads();if (isLastBlockDone) {// The last block sums the partial sums// stored in result[0 .. gridDim.x-1]float totalSum = calculateTotalSum(result);if (threadIdx.x == 0) {// Thread 0 of last block stores the total sum// to global memory and resets the count// varialble, so that the next kernel call// works properly.result[0] = totalSum;count = 0;}}
}
CUDA学习(三十六)相关推荐
- 推荐系统遇上深度学习(三十六)--Learning and Transferring IDs Representation in E-commerce...
本文介绍的文章题目为<Learning and Transferring IDs Representation in E-commerce>,下载地址为:https://arxiv.org ...
- Java多线程学习三十六:主内存和工作内存的关系
CPU 有多级缓存,导致读的数据过期 由于 CPU 的处理速度很快,相比之下,内存的速度就显得很慢,所以为了提高 CPU 的整体运行效率,减少空闲时间,在 CPU 和内存之间会有 cache 层,也就 ...
- OpenCV学习笔记(三十六)——Kalman滤波做运动目标跟踪 OpenCV学习笔记(三十七)——实用函数、系统函数、宏core OpenCV学习笔记(三十八)——显示当前FPS OpenC
OpenCV学习笔记(三十六)--Kalman滤波做运动目标跟踪 kalman滤波大家都很熟悉,其基本思想就是先不考虑输入信号和观测噪声的影响,得到状态变量和输出信号的估计值,再用输出信号的估计误差加 ...
- JavaScript学习(三十六)—移动的小球
JavaScript学习(三十六)-移动的小球 代码如下: <!DOCTYPE html> <html lang="en"><head>< ...
- 推荐系统三十六式——学习笔记(三)
由于工作需要,开始学习推荐算法,参考[极客时间]->[刑无刀大牛]的[推荐系统三十六式],学习并整理. 3 原理篇之紧邻推荐 3.1 协同过滤 要说提到推荐系统中,什么算法最名满天下,我想一定是 ...
- VTK学习笔记(三十六)VTK图像填充
VTK学习笔记(三十六)VTK图像填充 1.官方示例 2.其他例子 总结 1.官方示例 来自官方示例代码,自己只是添加了理解. 代码: #include <vtkCamera.h> #in ...
- Slicer学习笔记(三十六)slicer坐标系
Slicer学习笔记(三十六)slicer坐标系 1.坐标系统 1.1.世界坐标系 1.2.解剖坐标系 1.3.图像坐标系 1.4.图像变换 1.5.二维示例或计算IJtoLS矩阵 1.6.与其他软件 ...
- NeHe OpenGL教程 第三十六课:从渲染到纹理
转自[翻译]NeHe OpenGL 教程 前言 声明,此 NeHe OpenGL教程系列文章由51博客yarin翻译(2010-08-19),本博客为转载并稍加整理与修改.对NeHe的OpenGL管线 ...
- 嵌入式实时操作系统ucos-ii_「正点原子NANO STM32开发板资料连载」第三十六章 UCOSII 实验 1任务调度...
1)实验平台:alientek NANO STM32F411 V1开发板2)摘自<正点原子STM32F4 开发指南(HAL 库版>关注官方微信号公众号,获取更多资料:正点原子 第三十六章 ...
- 知识图谱论文阅读(八)【转】推荐系统遇上深度学习(二十六)--知识图谱与推荐系统结合之DKN模型原理及实现
学习的博客: 推荐系统遇上深度学习(二十六)–知识图谱与推荐系统结合之DKN模型原理及实现 知识图谱特征学习的模型分类汇总 知识图谱嵌入(KGE):方法和应用的综述 论文: Knowledge Gra ...
最新文章
- Flask的HelloWorld程序
- django2 mysql配置_Django:Python3.6.2+Django2.0配置MySQL 转载
- 分库分表 vs NewSQL数据库
- Oracle内部错误:ORA-00600[2608]一例
- 台湾大学林轩田机器学习技法课程学习笔记13 -- Deep Learning
- python网络编程实例简析
- 详解链表在前端的应用,顺便再弄懂原型和原型链!
- mybatis 动态SQL-foreach标签
- 系统提示“无法删除文件,无法读取源文件或磁盘”的解决办法
- 计算机文化基础清华大学PPT,数据库基础知识清华大学计算机文化基础.ppt
- pip更新不成功/Python虚拟环境下如何更新pip(Pycharm)
- 我将出席 .NET Day in China 的圆桌讨论:探讨开发者就业话题
- 小虾米闯江湖服务器维护中,小虾米闯江湖数据总结及中期注意事项一览
- C# WebService 远程服务器返回错误:(500)内部服务器错误
- 快速免费对接快递鸟圆通快递单号查询api接口
- iOS开发脚踏实地学习day02-图片查看器和TOM猫
- hbase 使用lzo_装配HBase LZO
- Python—获取电脑的锁屏壁纸
- 程序员副业之如何利用空余时间从博客中赚钱?
- D3学习笔记之常用比例尺