2021 MoDnet-V 抠图网络论文学习笔记
文章目录
- 论文名
- *KeyPoint*
- *Overview*
- *Keywords*
- 摘要
- 引言
- 相关工作
- 图像抠图
- 视频抠图
- 场景背景建模
- 方法
- 回顾MODNet
- 概述MODNet-V
- 背景恢复模块(BRM)
- Patch细化Module (PRM)
- 训练损失
- 实验
- 数据集
- 训练策略
- 性能比较
- 结论
论文名
代码地址
KeyPoint
Overview
无需trimap
MODNet- v的参数只有MODNet的1/3,但却达到了与MODNet相当甚至更好的性能
本文将恢复后的背景(background restoration)替代了trimap作为一个抠图先验,**而需要trimap进行抠图的网络本质上是在针对不同区域进行不同程度的细化动作
细化阶段,将原始分辨率的图像裁剪成8x8个小块,细化模型只处理误差概率高的小块。当图像有2k或更高的分辨率时,基于patch的细化这种策略有两个可能的问题。
首先,patch总数与图像分辨率成正比,这意味着在高分辨率下,patch的选择和裁剪会更加耗时。
其次,随着图像分辨率的提高,每个8x8区域所包含的信息会大大减少。结果,伪影很可能出现在精细补丁的边缘。
引入了一个新的patch细化模块(PRM),将固定大小的patch变为固定数量的patch,同时,PRM对初始粗糙alpha蒙版应用自适应池化层和两个卷积层来预测尺寸为(k, k)的缺陷图(由GCT提出),其中每个像素值对应每个patch的缺陷概率(flaw probability)。最后,PRM只细化缺陷概率高于预定义阈值ξ的补丁。
idea:可以将一个图片划分为大小不同的patch,对这些patch进行评分。
一般抠图网络的思路是先将大概的轮廓提取出来(semantic),然后在进行细化(refine),因为细化需要很多的计算资源,最后进行融合(fusion)。对于trimap实际上给定了过渡的区域,那么就可以直接在过渡区域进行细化,所以trimap抠图精度相对于没有trimap的精度要高很多,而且速度应该也会更快。
Keywords
BRM
PRM patch细化模块(PRM)
binary mask
background features
background restoration
matting prior
auxiliary trimap
matting guidance
Background Matting V2
patch
flaw map
摘要
为了更精确地解决具有挑战性的肖像视频抠图问题,现有作品通常会应用一些消光先验,需要用户付出额外的努力才能获得,如带注释的修剪或背景图像。在这项工作中,我们观察到,我们可以从输入的视频本身恢复它,而不是要求用户明确地提供背景图像。为此,我们首先提出了一种新的背景恢复模块(BRM),从输入视频中动态恢复背景图像。BRM非常轻量,可以很容易地集成到现有的抠图模型中。通过将BRM与最近的图像抠图模型MODNet相结合,我们提出了用于人像视频抠图的MODNet- v。得益于BRM提供的强背景先验,MODNet- v的参数只有MODNet的1/3,但却达到了与MODNet相当甚至更好的性能。我们的设计允许MODNet-V在 单个 NVIDIA 3090 GPU上以端到端方式进行训练。最后,我们引入了一个新的patch细化模块(PRM),以适应MODNet-V的高分辨率视频,同时保持MODNet-V的轻量级和快速。
引言
肖像视频抠图的目的是从给定的视频序列中提取前景肖像。在许多实际应用中,如交互式视频编辑中的特效生成和在线会议中的背景替换,实时准确地解决这一任务至关重要。由于该任务的病态性,视频抠图是一个具有挑战性的问题,早期的工作[12,4,49,43]通常期望用户为每一帧或连续的几个关键帧提供像素方向的trimap,这是一个有用的先验,具有很好的抠图结果。然而,这个trimap在实时应用程序中不可用,因为它需要人工注释。为了缓解这个问题,背景抠图[31]建议使用预捕获的背景。作为附加输入的图像。虽然背景抠图实现了实时性,但它需要用户事先提供额外的背景,在动态背景场景(即背景内容变化的视频)中会失败。
最近的一些方法[48,35,32,24]尝试仅从输入图像预测蒙版,而不需要辅助的trimap先验。然而,在困难的情况下,比如背景复杂的图像,这些方法往往产生令人不满意的alpha蒙版,因为缺失抠图先验增加了模型学习的难度。
在这项工作中,我们观察到,通过在连续的视频帧中动态累积和更新背景内容,我们可以恢复一个有意义的背景图像,它的内容随着视频背景的变化而动态变化,以作为抠图任务的先验。具体来说,在一个视频序列中,前景人物的姿态和位置通常在不同帧之间不断变化,这意味着这些帧中的背景内容通常是不同的和互补的。通过一帧一帧地积累和完成缺少的背景内容,我们可以为下一帧生成背景图像。与背景抠图[31]相比,我们的方法不需要任何用户的努力。此外,如果我们允许背景内容不断更新,我们可以处理动态背景的视频。
基于我们的观察,我们提出了一种新的背景恢复模块(BRM)来帮助动态恢复图像背景。BRM保持两个潜在变量:(1)背景特征表示恢复的背景,(2)二进制掩码表示恢复的背景像素。在每一帧时间,BRM执行两个步骤:
- 首先,它使用当前帧的背景特征作为抠图模型的先验,以产生预测的阿尔法蒙版。
- 其次,从当前输入帧中提取新的背景像素,并将这些背景像素积累为背景特征。在这一步中,BRM还将更新现有的背景像素,以处理具有动态背景的视频序列。BRM的设计非常轻量级,计算开销可以忽略不计。
在不修改原始模型架构的情况下,BRM可以很容易的集成到现有的抠图模型中。
如果我们将背景恢复作为消光先验,我们可以将其视为MODNet[24]中人像视频抠图目标的子目标,并将BRM与MODNet结合,形成新的视频消光模型MODNet- v。得益于BRM之前提供的背景,本文提出的MODNet- v只有1/3的参数,但却达到了与MODNet相当甚至更好的性能。此外,我们还引入了一个新的patch细化模块(PRM),使MODNet-V适应高分辨率视频。
- 首先,我们观察到视频帧的背景可以从它的前一帧恢复,并验证了使用恢复的背景作为视频抠图先验的可行性。
- 其次,我们提出了一种新的背景恢复模块(BRM)来恢复视频抠图的背景先验。
- 第三,我们提出了一种新的轻量级模型MODNet-V,该模型包含上述BRM和新提出的patch细化模块(PRM)。我们的新模型在模型大小、推理速度和抠图性能/稳定性方面取得了显著的改进。
相关工作
图像抠图
现有的抠图方法大多以辅助trimap作为先验。早期的传统方法可分为基于采样的方法[13,15,16,19,22,23,37]和基于亲和的方法[1,2,3,9,17,28,29]。然而,这些方法只利用图像像素的低级属性。相反,最近基于深度学习的方法利用了来自神经网络的高级语义信息,显著改善了匹配结果。例如Cho等[10]提出将神经网络与close-form matting[29]和KNN matting[9]结合起来。Xu等人[45]引入了第一个用于图像抠图的端到端神经网络。此外,有些方法通过结合从附加的网络学习到的额外信息(如最优trimaps[7]、前景信息[20]等)来提高alpha预测的准确性。
然而,在实践中注释trimap是非常昂贵和耗时的。为了解决这个问题,一些最近的方法要么直接从输入图像预测alpha蒙版[39,28,50,8,32,35,48],要么采用辅助先验[38]。在这些方法中,有两种不同的输入:不同对象类别的自然图像和人像图像。对于不同对象类别的自然图像,Qiao et al.[35]应用注意机制,Zhang et al.[48]整合前景和背景的概率图进行alpha预测。对于肖像图像抠图,Shen等人[39]在使用图像抠图层学习拉普拉斯矩阵之前,先使用全卷积网络生成伪trimap。Chen et al.[8]首先预测一个低分辨率的分割图,然后将其作为抠图引导。Liu等人的[32]在一个三级耦合管道中使用粗略注释的数据。Sengupta等人的[38]提供了额外的背景图像作为预测阿尔法蒙版和前景的替代辅助线索。
视频抠图
虽然我们可以简单地对每帧应用上述算法进行视频抠图,但它会导致时间上的不相干。以往基于trimap的视频抠图方法[12,4,43,49]考虑帧的时间关系,通过进行时空优化,生成相干的trimaps或mattes。
- 例如,Chuang等人的[12]通过光流将有限数量的用户定义关键帧的trimap传播到整个序列,并使用贝叶斯蒙版预测阿尔法蒙版。
- Bai等人的[4]通过时间蒙版滤波器改善时间相干性,同时保留单个帧上的蒙版结构。
- Zou等人的[49]通过稀疏低秩表示构造的非局部结构连接时空关系。除了使用低级颜色特征的方法外,一些基于学习的方法还使用深层结构和语义特征。
- 一些方法[11,30,52]利用多帧的非局部抠图拉普拉斯编码时间相干性。Sun等人[43]通过时空特征聚合模块引入了trimap传播网络。近年来,无trimap的视频抠图方法备受关注。
- Ke等人[24]将抠图目标划分为三个子目标,并学习每个子目标在真实世界中的人像抠图中的一致性。但由于没有综合考虑帧间的时间关系,该方法无法实现帧间预测的一致性。
- 在Sengupta等人[38]设计的基础上,Lin等人[31]还为实时人像视频抠图提供了额外的背景图像。这种额外的背景是提高视频抠图性能的有力前提,这已经被Lin等人[31]的研究证明。
- 然而,使用采集的背景图像作为先验有两个主要的缺点,这极大地限制了背景抠图在实践中的应用。首先,如果使用捕获的背景图像,背景必须是静态的,这意味着即使在后面有小的干扰(如光线的变化和轻微的抖动)会影响到抠图效果。
- 其次,背景图像需要用户额外的努力来捕捉,这个过程必须仔细地完成,以确保获得的背景图像与视频序列对齐。为了解决上述问题,本文提出了一种新的BRM模块,该模块从历史帧中恢复背景,并将其作为未来帧的抠图先验。
场景背景建模
场景背景建模[6,33]就是从视频序列中估计出一幅没有前景物体的清晰背景图像,这有助于识别视频中移动的前景物体。场景背景建模方法始终遵循相同的方案。他们首先利用前几帧预测一个不可靠的背景模型,然后通过在线过程对视频序列中提取的前景对象进行分析,逐步更新背景模型。
- 最传统的背景建模方法是基于高斯分布的[34,5]。然后,Stauffer和Grimson设计了一种基于混合高斯概率密度函数的像素级颜色强度变化建模[41,42]。
- Zivkovic[51]在高斯混合模型的基础上,引入了自适应高斯混合模型,这是一种介于中值混合和空间分割之间的迭代方法。
- 一些方法[27,40]进一步改进了用于背景建模的高斯混合模型。此外,Kim等人[25]用codebook method建立了背景的建模。
- Laugraud等人的[26]基于运动检测生成背景。
- Javed et al.[21]通过鲁棒主成分分析(RPCA)将背景-前景建模定义为低秩矩阵分解问题。
- 最近,一些基于深度学习的方法也出现了。这些方法将无权重神经网络[14]、卷积神经网络[18,36]和自动编码器[46,47]应用于场景背景建模任务。动态背景的存在、光照的变化、长时间的静态前景以及摄像机抖动引起的全局运动都对场景背景建模的性能产生了深刻的影响。在本文中,我们尝试通过BRM的设计来减少动态背景、光照变化等因素的影响。
方法
回顾MODNet
![]()
图1所示。MODNet-V体系结构。我们的框架由采用[24]的MODNet组件、背景恢复模块(BRM)和补丁细化模块(PRM)组成。在每个时间戳中,BRM提供一个恢复的背景特征bgFt−1bgF^{t-1}bgFt−1作为抠图先验和在二进制掩模bgM的引导下更新bgFbgFbgF。在MODNet分量从ItI^tIt的下样本版本预测alpha蒙版αp\alpha_pαp之后,PRM检测αp\alpha_pαp中的错误补丁,并在原始输入分辨率中对这些补丁进行细化。
MODNet[24]提出将具有挑战性的抠图目标分解为三个子目标,分别是语义估计、细节预测和语义细节融合。如图1(a)所示,在每个时间戳中,MODNet(记为fmodf_{mod}fmod)从输入图像帧ItI^tIt预测出一个α蒙版αpt\alpha_p^tαpt,为:
αpt=fmod(It)=F(spt,dpt)=F(S(It),D(S(It),It))\alpha_p^t=f_{mod}(I^t)=\mathcal{F}(s_p^t,d_p^t)=\mathcal{F}( \mathcal{S}(I^t),\mathcal{D}(\mathcal{S}(I^t),I^t)) αpt=fmod(It)=F(spt,dpt)=F(S(It),D(S(It),It))
其中S、D和F是MODNet的三个分支。(spt,dpt)(s_p^t,d_p^t)(spt,dpt)分别对预测的语义和细节进行分析。但是,式(2)不将任何抠图先验作为输入并且忽略了时间信息,导致在复杂场景下预测的alpha蒙版不理想,视频帧间预测的alpha蒙版不一致。
概述MODNet-V
为了克服MODNet的上述问题,我们提出了MODNet- v,一种包含新提出的BRM和PRM的轻量级视频抠图模型。BRM从历史帧中恢复背景信息。在MODNet-V中,我们利用BRM恢复的背景信息作为抠图先验,将其输入到语义分支中。这样的先验可能包含了视频抠图所必需的时间信息。我们通过以下方式连接BRM到S:
spt=S(It,B(It))s_p^t=\mathcal{S}(I^t, \mathcal{B}(I^t)) spt=S(It,B(It))
这里B\mathcal{B}B表示BRM。另一个模块,PRM,以基于patch的方式对Eq.(2)预测的alpha蒙版进行细化。因此,MODNet- v可以处理高分辨率(如1080p或2k)图像,计算开销比MODNet小得多。我们附加PRM如下:
αpt=P(F(spt,dpt))\alpha_p^t=\mathcal{P}(\mathcal{F}(s_p^t, d_p^t)) αpt=P(F(spt,dpt))
这里P\mathcal{P}P表示PRM。结合Eq.(2)(3)(4)可以得到MODNet-V的推理公式:
αpt=P(F(S(It,B(It)),D(S(It,B(It)),It)))\alpha_p^t=\mathcal{P}(\mathcal{F}(\mathcal{S}(I^t, \mathcal{B}(I^t)),\mathcal{D}(\mathcal{S}(I^t, \mathcal{B}(I^t)),I^t))) αpt=P(F(S(It,B(It)),D(S(It,B(It)),It)))
得益于BRM和PRM,我们还可以简化MODNet- v中使用的MODNet骨干网,进一步减少计算开销。具体来说,我们做了三个修改:(1)降低S\mathcal{S}S的输入分辨率,(2)删除最后一个编码器块(32x下采样块),(3)去掉几个D\mathcal{D}D中的卷积层。在接下来的两个小节中,我们将分别对BRM和PRM进行深入研究。
背景恢复模块(BRM)

图2给出了BRM的体系结构。在每个时间戳中,BRM有两个职责。
首先,BRM应该为预测当前帧的alpha蒙版提供一个背景信息。
其次,BRM应该从当前帧中提取背景信息,并对其进行累积,以改善恢复后的背景。
在我们的设计中,BRM通过维护(1)一个背景特征bgFbgFbgF来存储背景信息,(2)一个二进制掩码bgMbgMbgM来表示需要恢复的背景的像素。
对于第一个任务,来自前一个时间戳的背景特性bgFt−1bgF^{t-1}bgFt−1将被视为当前帧的先验。在实践中,我们将bgFt−1bgF^{t-1}bgFt−1与ItI^tIt连接,4x下采样的低水平特征e4×te_{4\times}^te4×t从S\mathcal{S}S预测预测的alpha蒙版αt\alpha^tαt。对于第二个任务,BRM通过以下方法提取当前帧的背景信息bgItbgI^tbgIt:
bgIt=(1−spt)⊗e4×tbgI^t=(1-s_p^t)\otimes e_{4\times}^t bgIt=(1−spt)⊗e4×t
其中⊗\otimes⊗表示元素级乘积,bgItbgI^tbgIt在bgm和sp的指导下积累了bgf,总结在alg1中。通过这种方式,bgF可以在不需要任何用户努力的情况下为alpha蒙版预测提供强先验或辅助输入。注意,对于第一个视频帧,bgf和bgm都被初始化为0。
![]()
Patch细化Module (PRM)
尽管MODNet经过精心设计以减少推断时间,但在处理1080p或更高分辨率的图像时,它仍然很慢。为了加快高分辨率图像的抠图过程,Background Matting V2[31]提出首先从下采样的输入图像生成粗α蒙版,然后将其上采样到原始尺寸进行细化。在细化阶段,将原始分辨率的图像裁剪成8x8个小块,细化模型只处理误差概率高的小块。然而,我们注意到,当图像有2k或更高的分辨率时,这种策略有两个可能的问题。
首先,patch总数与图像分辨率成正比,这意味着在高分辨率下,patch的选择和裁剪会更加耗时。
其次,随着图像分辨率的提高,每个8x8区域所包含的信息会大大减少。结果,伪影很可能出现在精细补丁的边缘。
在本工作中,我们提出了一个新的补丁细化模块(PRM)。如图3所示,与Background Matting V2中大小固定的patch不同,我们将输入的图像划分为固定数量的patch。在这些补丁中,错误的补丁将被细化,并与其他正确的补丁结合,形成一个新的alpha蒙版。
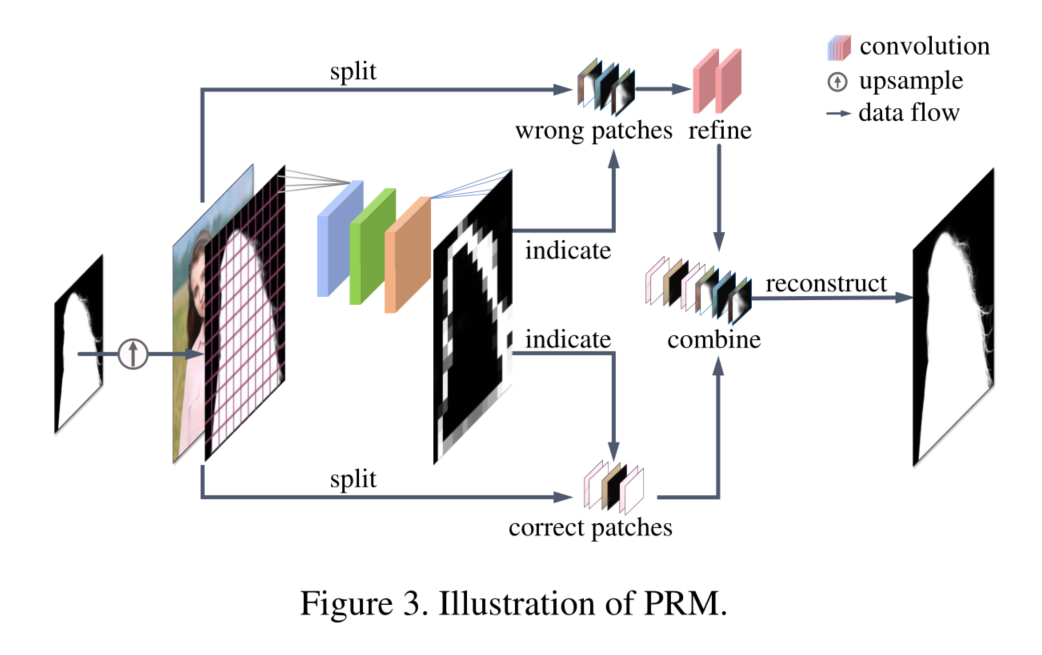
形式上,对于尺寸为(h, w)的输入图像,PRM首先对其进行向下采样,并预测出初始粗α蒙版。然后,PRM将初始粗糙alpha蒙版上采样为原始图像大小,并将其分为k×k个尺寸 (h/ k,w /k)的patch。同时,PRM对初始粗糙alpha蒙版应用自适应池化层和两个卷积层来预测尺寸为(k, k)的缺陷图(由GCT提出),其中每个像素值对应每个patch的缺陷概率(flaw probability)。最后,PRM只细化缺陷概率高于预定义阈值ξ的补丁。
在实践中,对于分辨率为4k及以下的图像,我们设置k= 16(最大补丁大小仅仅为256×256)。对于分辨率高于4k的图像,我们设置k= 32。我们设置ξ= 0.01,这限制了只有15%的补丁有大于ξ的缺陷概率。这意味着,PRM可以减少约6.5倍的细化费用,从而使MODNet-V能够处理高分辨率的图像。在不同的输入分辨率下,我们的PRM选择补丁的时间是一致的。此外,得益于更大的补丁分辨率,我们的PRM可以有效地减少精细边界上的伪影(如头发区域)。
训练损失
我们使用与MODNet相同的损失函数来学习alpha蒙版。此外,我们提出了一个显式约束Lbg\mathcal{L}_{bg}Lbg来测量真实背景图像bggtbg_g^tbggt和从bgFtbgF^tbgFt预测的背景图像bgptbg_p^tbgpt之间的差异,如下所示:
Lbg=∑t=1Nγ(bgpt−bggt)2+ϵ2\mathcal{L}_{bg} = \sum_{t=1}^N{\gamma\sqrt{(bg_p^t-bg_g^t)^2+\epsilon^2}} Lbg=t=1∑Nγ(bgpt−bggt)2+ϵ2
其中ϵ\epsilonϵ是一个很小的常数,γ\gammaγ是一个二进制掩模等于4在肖像边缘否则为1。γ\gammaγ的目的是为了让Lbg\mathcal{L}_{bg}Lbg更多的集中在困难区域的抠图。我们也计算LαH\mathcal{L}_{\alpha H}LαH在真实高分辨率alpha 蒙版αHg\alpha_{}H_gαHg和预测的高分辨率alpha蒙版之间的约束为PRM:
LαH=γ(αHp−αHg)2+ϵ2\mathcal{L}_{\alpha H} = {\gamma\sqrt{(\alpha H_p -\alpha H_g)^2+\epsilon^2}} LαH=γ(αHp−αHg)2+ϵ2
实验
数据集
我们跟随MODNet在标记和未标记的数据集上训练我们的网络。我们使用Background Matting V2提出的VideoMatte240K数据集[31]作为标记前景,并使用来自互联网的约1000个视频片段作为未标记数据。注意,我们还在每个视频中标注了一帧作为标记数据。为了得到一个有标记的训练样本,我们从一个视频序列中随机抽取10个连续的帧,并通过平移和仿射操作将它们与一个由单一背景图像生成的动态背景序列组合在一起。对于每个视频序列,我们将其与20幅背景图像进行合成,最终构建出包含9680个视频的数据集。
训练策略
我们的MODNet-V采用两阶段培训策略。
在第一阶段,我们以端到端方式训练MODNet组件和BRM。为了节省GPU内存,在每次迭代中,我们选择一个随机数bert∈[1,10]表示前向帧,我们只计算第1帧和第1帧的损失进行优化,即:,在[2,T−1]帧之间没有缓存和向后的梯度。因此,我们的第一个训练阶段可以在单个RTX 3090 GPU (24G内存)中执行,批量大小为16。我们使用SGD优化器对第一阶段进行30个纪元的训练。初始学习率为0.01,在15和25个pochs中乘以0.1会降低。在第二阶段,我们只使用高分辨率标记样本训练PRM。在这个阶段,我们确定了MODNet组件和BRM的权重。我们使用学习率为0.001的SGD优化器来训练这个阶段10个纪元,并将批量大小设置为1。
性能比较
表1显示了对真实世界的人像视频抠图数据集[44]的评估,该数据集包含19个视频,711个标记帧。
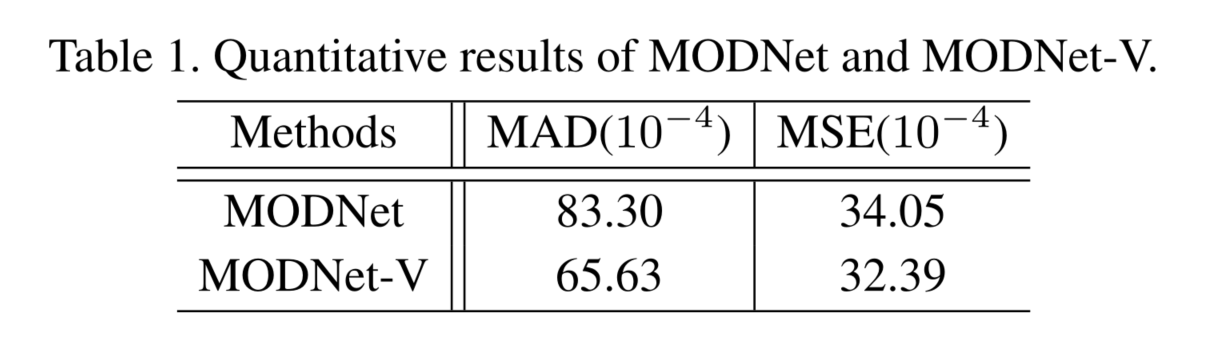
我们可以看到,MODNet- v在MAD和MSE方面都优于MODNet。在图4中,我们可视化了一个视频序列的MODNet和MODNetV的抠图结果。

结论
在本文中,我们提出了MODNet-V用于人像视频抠图。我们的架构设计基于观察到视频帧的背景可以通过积累历史帧的背景信息来恢复。在MODNet- v中,我们提出了一个轻量级的BRM,该BRM与MODNet进行迭代,以构建背景作为先验,以获得更好的蒙版效果。此外,我们引入了一种新的PRM模块,可以使我们的方法适用于高分辨率视频。对各种真实视频的结果表明,与MODNet等以往的SOTA相比,本文提出的MODNet- v可以显著提高系统的质量和稳定性。
2021 MoDnet-V 抠图网络论文学习笔记相关推荐
- 【论文学习笔记-10】ActiveStereoNet(Google ECCV2018)主动式双目相机自监督学习立体匹配网络
[论文学习笔记-10]ActiveStereoNet(Google ECCV2018)主动式双目相机自监督学习立体匹配网络) 自监督训练方法 Experiment ORAL 针对双目立体匹配中无监督存 ...
- 论文学习笔记 POSEIDON: Privacy-Preserving Federated Neural Network Learning
论文学习笔记 POSEIDON: Privacy-Preserving Federated Neural Network Learning NDSS 2021录用文章 目录 论文学习笔记 POSEID ...
- Dual Graph Attention Networks for Deep Latent Representation of Multifaceted Social...》论文学习笔记
Dual Graph Attention Networks for Deep Latent Representation of Multifaceted Social Effects in Recom ...
- SiamFC论文学习笔记
SiamFC论文学习笔记 引言 相似度学习 网络结构 损失函数的定义 优化与训练方案 总结 引言 这是我写下的第一篇博文,主要目的是提升学习自己的主动性,对自己学到的知识进行及时总结反思,也便于在后续 ...
- 《Joint 3D Face Reconstruction and Dense Alignment with Position Map Regression Network》论文学习笔记
<Joint 3D Face Reconstruction and Dense Alignment with Position Map Regression Network>–<基于 ...
- 动态环境下的SLAM:DynaSLAM 论文学习笔记
动态环境下的SLAM:DynaSLAM 论文学习笔记 这篇文章 论文摘要 系统流程 相关环节的实现方法 神经网络检测图中动态物体(Mask R-CNN) Low-Cost Tracking 使用多视图 ...
- 软考网络工程师学习笔记3-广域通信网
软考网络工程师学习笔记3-广域通信网 1.广域网概念和分类 广域网是指长距离跨地区的各种局域网.计算机.终端互联在一起,组成一个资源共享的通信网络. 传统的广域网有: (1)公共交换电话网PSTN ( ...
- 【论文学习笔记-2】高分辨率3D深度重建
[论文学习笔记-2] 高分辨率3D深度重建 背景介绍 模型 目标 Related Works 背景介绍 应用场景广泛:桥,电缆etc 高分辨率图像的特点:像素多,potential disparity ...
- 论文学习笔记: Learning Multi-Scale Photo Exposure Correction(含pytorch代码复现)
论文学习笔记: Learning Multi-Scale Photo Exposure Correction--含pytorch代码复现 本章工作: 论文摘要 训练数据集 网络设计原理 补充知识:拉普 ...
最新文章
- PHP设置禁止目录索引,/var/www/html目录索引禁止
- 【经典算法】快速排序
- 智源研究院发布“知识疫图-全球新冠疫情智能驾驶舱”,一键预测、跟踪和决策辅助...
- Linux 下杀毒软件 CPU 占用率为何持续升高?
- MYSQL常用命令(转载)
- 001/Docker入门(Mooc)
- adadelta算法_对C++用户比较友好的机器学习算法库
- set和multiset集合容器
- mybaties总结+hibernate总结
- [css] 当使用@font-face的时候,为什么src中要加入local呢?
- Vertex and Fragment Shader
- [毕业生的商业软件开发之路]系列文章目录规划
- Atitit mysql 数据类型 5.7.9 目录 1.1. 数值类型 1 2. 字符串 2 3. 时间日期 2 4. 地理位置 2 5. 几何数据的存储,生成,分析,优化。 空间数据类型(存储)
- MaterialDesignInXAML WPF入门教程 目录
- 51单片机usb烧录电路_STC51单片机ISP自动下载电路设计
- Win10快捷键大全
- There appears to be trouble with your network connection
- OneNET麒麟座应用开发之七:控制采样电机
- python爬取微信好友信息_python itchat 爬取微信好友信息
- apk私钥_Android应用apk的程序签名详解