《Concurrency in Go》阅读笔记 -- 第三章:Go语言并发组件
《Concurrency in Go》
本章节从goroutine入手,讲解go语言的各种并发原语。在讲解完goroutine之后,对于传统的内存同步访问的并发原语:sync包中的Mutex,RWMutex,Cond,Once,WaitGroup,Pool等进行了分析。在此之后着重讲了go语言的另一大特色:channel。在最后,讲解了如何结合channel的语法:select语句。
插一句题外话:这本书的中文版本的翻译就是一坨屎。
Chapter 3:Go’s Concurrency Building Blocks Go 语言并发组件
1. goroutine
goroutine是Golang中最基本的组织单位之一,每个go语言的程序都至少有一个goroutine:main goroutine,它在进程开始时自动创建并且启动。
1.1 什么是goroutine?
简单的说:goroutine是一个并发的函数,可以和别的代码块同时运行(不一定是并行的)。
至于如何使用go关键字来简单的创建一个goroutine,就不多讲了,看到这个博客的人估计没那么傻。
golang中的goroutine是这个世界上独一无二的东西。它不是OS线程,也不是绿色线程(由语言运行时管理的线程)。有些中文的翻译为轻量线程,但是事实上goroutine is a coroutine,也就是说goroutine是一个协程。协程是一种非抢占式的特殊线程(进程和线程是抢占式的)。协程不能被中断,但是协程尤多个允许暂停和重新进入的点。
1.2 goroutine的独到之处(和普通协程的区别)
goroutine的独到之处在于它们与golang的运行环境的深度集成。(原文是:What makes goroutines unique to Go are their deep integration with Go’s runtime. 这里的所谓golang的运行环境其实是特指的golang的runtime | 在中文翻译中为:它们与Go语言运行时的深度集成,这根本就不通顺嘛!)
goroutine定义了自己的暂停的方法和再切入的点。Go语言的runtime会观察goroutine的运行时的行为,并且在阻塞的时候自动挂起它们,然后在不被阻塞的时候再恢复。 在golang的runtime和goroutine的逻辑之间有一种优雅的伙伴一样的关系。
1.3 goroutine怎么实现并发
协程(coroutine)和goroutine都是隐式并发结构,这说明并发并不是协程的属性:必须同时托管多个协程,并且给每个协程一个执行的机会。
Golang的主机托管机制是一个M:N调度器,主要机制就是将M个由程序管理的线程映射到N个OS线程。而M:N调度器可以单独写一个博客了,这里就不再细说。
Golang遵循一个称为fork-join的并发模型。
- fork是指在程序运行中的任意一点,它可以将执行的子分支和父节点同时运行。
- join这个词是指的是在将来的某个时候,这个并发的执行分支将会合并在一起。
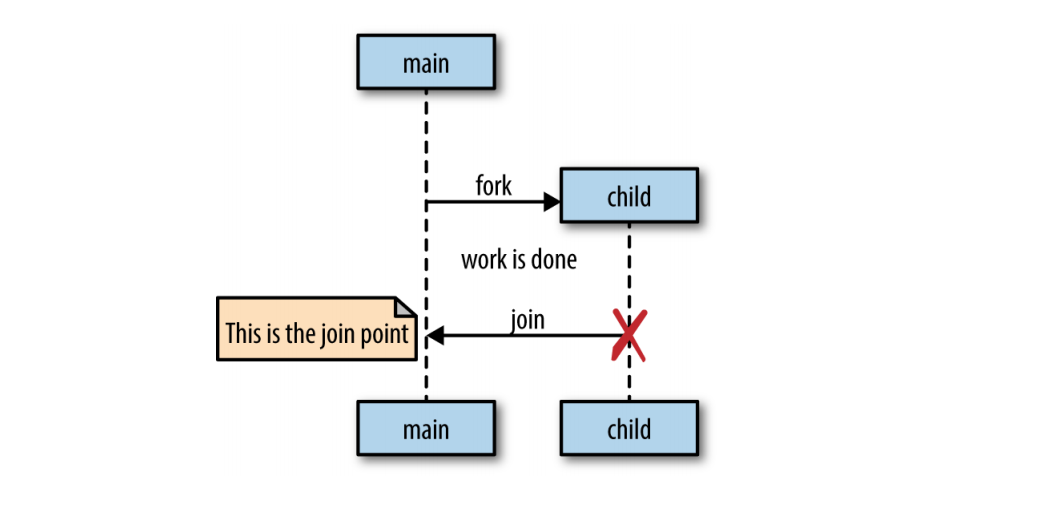
在fork-join模型中,掌握join的点是至关重要的,因为join点是保证程序的正确性和消除竞争条件的关键。而控制join点的关键技术是WaitGroup。
1.4 goroutine中闭包运行的情况
我们在快速创建goroutine的时候往往会选择使用匿名函数来创建,这就牵扯到了闭包中变量的引用问题:闭包可以从创建它们的作用域中获取变量,那么当这个闭包运行的时候,调用这些变量的方式是副本还是引用呢?
举个例子:
var wg sync.WaitGroup
salutation := "hello"
wg.Add(1)
go func() {defer wg.Done()salution = "welcome"
}()
wg.Wait()
fmt.Println("Out:", salutation)
我的得到的输出是:
Out: welcome
事实证明,goroutine在它们所创建的相同地址空间内执行。
从另一个角度再进行一个实验:
var wg sync.WaitGroup
for _, salutation := range []string{"hello", "greetings", "good day"} {wg.Add(1)go func() {defer wg.Done()fmt.Println(salutation)}()
}
wg.Wait()
这个程序我们期望得到的结果是:
hello
greetings
good day
以上的所有可能的排列组合,因为我们都知道并发所带来的竞争条件产生的影响,但是输出却让我们大吃一惊:
good day
good day
good day
当大家看到输出的时候应该已经明白了究竟是怎么回事:在输出之前,salutation就已经完成了迭代。
但是值得注意的一点是,既然迭代已经结束,为什么还能使用salutation的引用呢?这个就和golang的GC有关,golang的GC会小心的把salutation的引用从内存转移到堆,以便能够继续使用。
所以正确的程序应该这样编写:
var wg sync.WaitGroup
for _, salutation := range []string{"hello", "greetings", "good day"} {wg.Add(1)go func(salutation string) {defer wg.Done()fmt.Println(salutation)}(saluation)
}
wg.Wait()
也就是传入数据的副本。
由于所有的goroutine都在相同的地址空间中运行,而且只有简单的宿主函数,所有使用goroutine编写并发的任务是非常的自然的,golang的编译器很好的处理了内存中的变量,这样goroutine就不会意外的访问被释放的内存,这使得开发人员可以专注于它们的问题是如何被解决的,而不需要去消耗更多精力来管理内存。
但是golang带来的这些好处也付出了一些代价,由于多个goroutine运行在同一个地址空间,所以我们仍然需要担心同步问题。解决问题的方法:sync包和channel我们会在后面的小节进行讨论。
1.5 goroutine有多么的轻量级
以下是摘自Go Programming Language FAQ中的一段话。

这段话很夸张的说出:在同一个地址空间中创建成千上万的goroutine是可行的。
这是吹牛逼吧!怎么可能!
但是goroutine就是这么轻量,一个goroutine只有几千个字节,这完全是ok的。
但是当进程多了起来,一个问题将明显的影响着程序的性能:上下文之间的切换。当进程之间来回不断的切换的时候,保存现场和恢复现场的工作显得格外耗时,那么goroutine这么多,在它们之间的切换应该也相当耗时吧?
但是并不!goroutine之间的切换速度是OS线程切换速度的8%!
太轻了,实在是太轻了。goroutine的使用代价如此的小让我们能够放手的去用goroutine解决并发问题。
2. Package sync
sync包包含了对于低级别内存访问同步最有用的并发原语。很简单,很基础。
2.1 WaitGroup
当你不关心并发操作的结果,或者你又其他的方法能够收集它们的结果的时候。WaitGroup是等待一组并发操作完成的好办法。
你可以将WaitGroup视为一个并发安全的计数器。
func (wg *WaitGroup) Add(delta int)
// Add 方法增加计数器的增量。
func (wg *WaitGroup) Done()
// 调用Done方法来对计数器进行递减。
func (wg *WaitGroup) Wait()
// Wait方法会阻塞,直至计数器为0.
使用WaitGroup的时候需要注意的是:Add方法的调用应该是在跟踪的goroutine之外调用的。如以下程序为例:
// 正确的示例
var wg sync.WaitGroup
for i:=0; i<10; i++ {wg.Add(1)go func() {// wg.Add(1) 如果在这里调用wg.Add()会让程序直接结束。因为竞争条件。defer wg.Done()fmt.Println("Hello")}
}
wg.Wait()
2.2 Mutex & RWMutex
锁,这一节讲的就是锁。不管是在数据库中还是在一些传统的并发处理中,锁往往都是我们最常见的方式或者方法。而在sync包中有Mutex和RWMutex两种锁,分别是互斥锁和读写锁。
2.2.0 Locker
sync包中有一个锁接口,具体定义如下。
type Locker interface {Lock()Unlock()
}
2.2.1 Mutex 互斥锁
互斥是保护程序中临界区的一种方式,临界区是程序中需要独占访问共享资源的区域。Mutex提供了一种安全的方式来表示对这些共享资源的独占访问。
为了使用一个资源,
channel通过通信的方式来共享内存,而Mutex通过开发人员的约定来同步访问共享内存。
在使用的时候,往往会将共享资源和互斥锁绑定在一起:
type NewResource struct {Resource []interface{}Lock *sync.Mutex
}
使用时通过使用sync.Mutex.Lock()方法和sync.Mutex.Unlock()方法来声明对于资源的独占开始和结束。
最好使用 defer关键字来结束独占,否则可能因为panic引发死锁
在此之前我们介绍了原子操作的概念,也就是一个操作的原子性。事实上我们在对于一个资源的独占期间我们绝对不想要被打断,也就是说在对于资源的操作的上下文下,我们对于资源独占期间的操作整体是具有原子性的,而又结合我们之前接触过的所谓饥饿的概念,我们知道,我们的临界区应该尽可能的小,也就是我们独占的时间应该尽可能的小。因此一个良好的Mutex的使用应该像下面这样:
go func(resource) {init() // 和资源无关的操作resource.Lock.Lock()defer resource.Lock.Unlock()resource.Operation() // 对于资源的操作
}(resource_1)
2.2.2 RWMutex 读写互斥锁
读写锁在概念上和和互斥锁是一样的,但是读写锁让你对于内存有了更多的控制,也就是你可以单独请求一个锁用于读处理,这个情况下你将被授予访问权限。
2.3 cond 条件变量
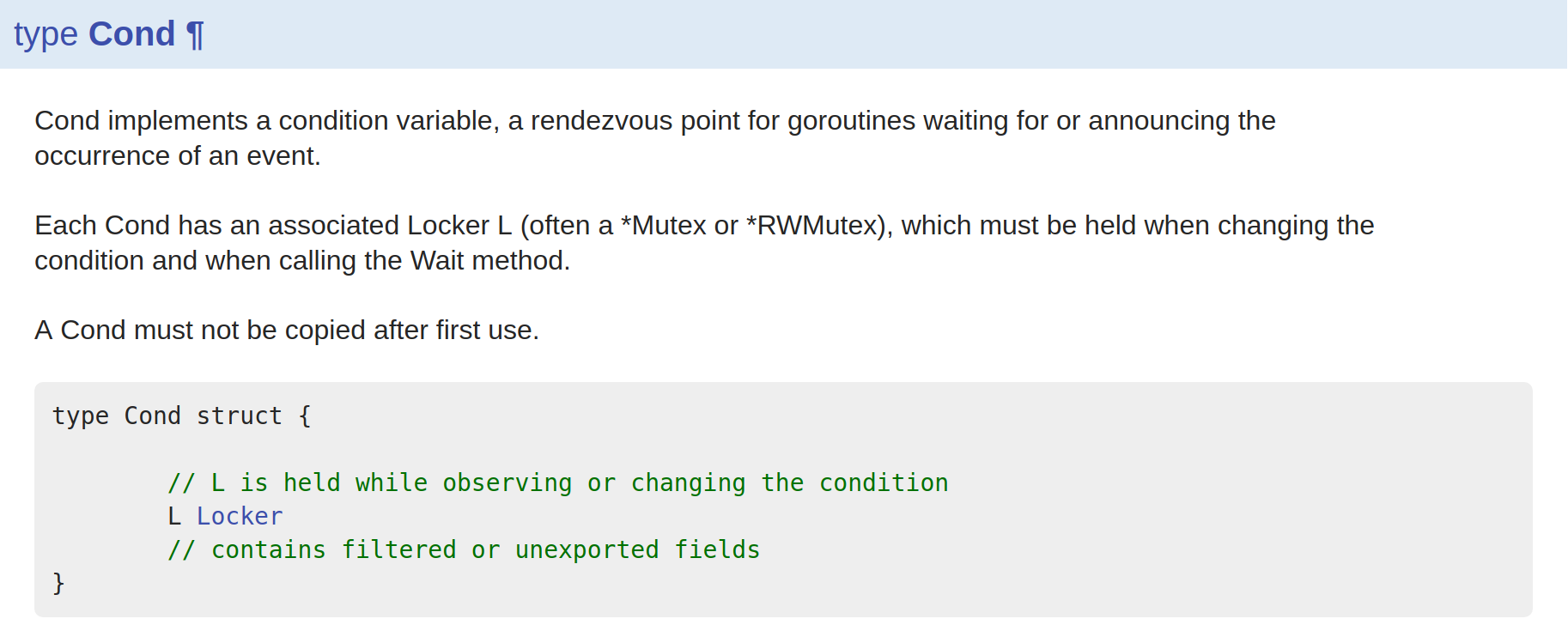
Cond实现了一个条件变量,是一些正在等待或者声明一个事件的goroutine的集合点。
每一个Cond都有一个相关联的锁,必须在条件改变和调用wait()时进行状态的改变。
在上述的定义中,有一个重要的概念:事件。这里的事件(Event)是指两个或者两个已上的goroutine之间的任意信号,除去这个事件已经发生之外,没有任何的信息能够被我们利用。
先看一下在不使用cond的时候我们应该怎样检查这个事件是否完成。
for conditionTrue() == false {}
then()
使用一个死循环来检查!这太聪明了!但是这样会消耗你所有的CPU时钟周期!
因此我们可以定时来检查一下?
for !conditionTrue() {time.Sleep(1*time.Millisecond)
}
then()
这显然比死循环好多了,但是也是相当低效的行为,而且对于休眠的时间长度也要有所掌控:太长,会人为的降低性能;太短,会不必要地消耗大量的CPU时间。而cond就是为了解决这种问题而生的。
让我们使用cond来改写之前的例子:
cond := sync.NewCond(&sync.Mutex{}) // new一个新的cond
cond.L.Lock() // 锁定条件,因为在执行cond.Wait()的时候会自动调用Unlock()
for !conditionTrue() {cond.Wait() // 开始等待,在另一个goroutine中发送信号来终止等待
}
c.L.Unlock() // 解锁这个条件,而Wait()方法在退出的时候会自动调用Lock()
Wait()方法不只是阻塞了goroutine,还挂起了当前的goroutine,允许其他goroutine在OS线程上运行。
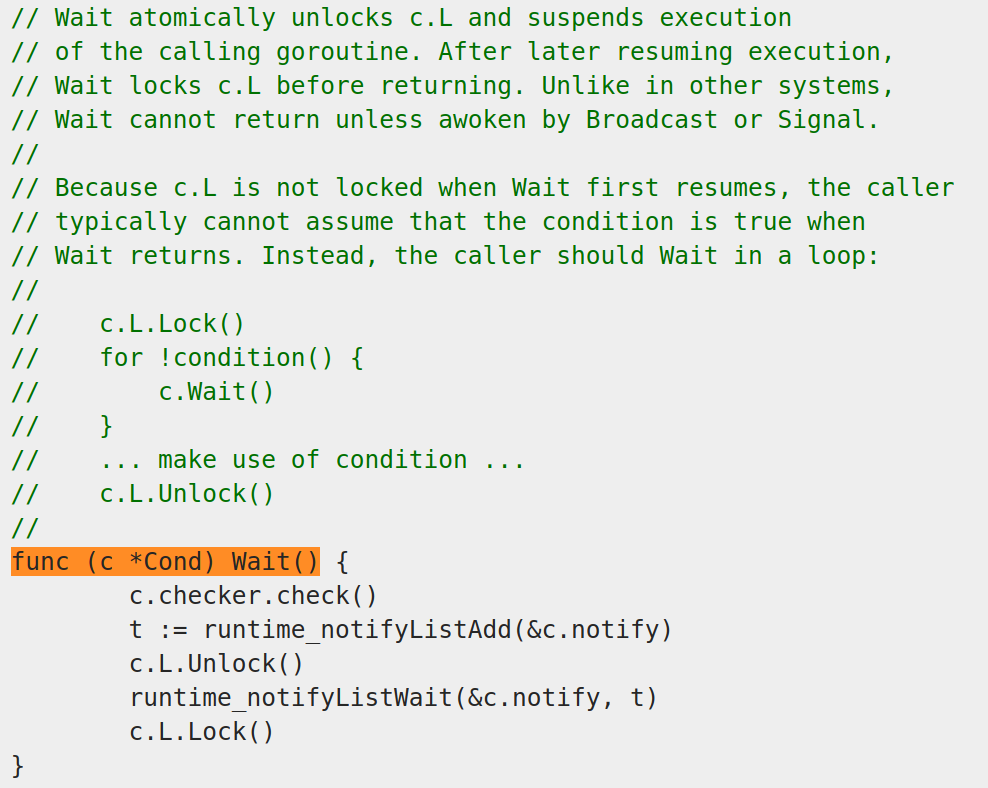
这里介绍了为什么使用循环来判定,而并非只使用if语句:因为当Wait()第一次返回的时候我们不能认为条件成立了,因此需要循环等待。但是这显然要比之前的两种方法高效多了。
其他的能够很好的体现的cond的例子,比如分配房间的例子在书中都有讲解,也挺好理解的,这里就不赘述了。
2.3.1 发送信号的方式:Signal和Broadcast
golang的runtime会内部维护一个FIFO的goroutine队列,等待接收信号。Signal会发现等待时间最长的goroutine并且通知它,而Broadcast会向所有等待的goroutine发送信号。
这里的Broadcast提供了一种同时和多个goroutine通信的方式,当然,我们也可以通过channel对信号进行简单的复制,但是使用Broadcast是更加自然且高效的行为。
2.4 once
once,顾名思义就是只执行一次。就很简单。就很简单。
function := func() {fmt.Println("Only do it once.")
}
var once sync.Once
var wg sync.WaitGroup
wg.Add(100)
for i:=0; i<100; i++ {defer wg.Done()once.Do(function)
}
wg.Wait()
直觉告诉我们这句话Only do it once.只会输出一次。事实上确实如此。
这里需要注意的一点是:once只记录自己一共执行了多少个函数,而并非多少个不同的函数。
2.5 Pool 池
Pool是Pool设计模式的并发安全实现。Pool设计模式是一种可以创建和提供可供使用的固定数量的实例或者Pool实例的方法。通常用于约束创建昂贵的场景(比如数据库的连接操作)。对于sync.Pool,这种数据类型可以被多个goroutine安全的使用。
Pool的主要的几个方法是:
- 使用
Get方法来获取一个池中的实例给调用者。如果池中没有则会new一个新的实例出来。 - 在使用完毕之后,会调用
Put方法把实例还给池。
2.5.1 为什么使用Pool?
为什么要使用Pool而不是直接创建一个新的实例呢?这是因为golang有GC,因此实例化的对象会被自动清理。
另一个原因是,可以使用Pool来尽可能快的将预先分配的对象缓存加载启动。在处理代价昂贵的事务的时候这种模式可以极大的提高性能。
当并发进程需要一个对象,并且处理它的过程会是相当的快速的过程,或者这些对象的构造过程会对内存产生负面的影响,这个时候你最好使用Pool设计模式。
使用Pool时最好注意的几个点:
- 当实例化
sync.Pool时,使用new方法创建一个成员变量,在调用时会是线程安全的。 - 当你收到一个来自
Get方法的实例的时候,不需要对接受的对象的状态进行任何的假设判定,因为一定合法的。 - 当你使用完成了一个从Pool中取出来的实例的时候,请一定使用
Put方法把它放回去,负责你就没有办法复用这个实例了,通常情况之下会使用defer关键字来调用方法。
3. channel 信道
正如之前介绍过的CSP中的channel一样,你最好使用golang中的channel来进行goroutine之间的通信。而并非是用于同步内存访问。
channel是一个用于传递信息的管道。信息从一头进,从一头出。
3.1 创建和使用channel
创建一个channel非常的简单,只是需要指定一下数据的类型
var dataStream chan interface{} // 声明
dataStream = make(chan interface{}) // 实例化
一个普通的channel是双向的,也就是既可以输入数据,也可以读出数据。但是事实上,你也可以使用单向的channel,也就是定义一个channel,只用于发送或者接受数据。
var readStream <-chan interface{} // 一个只用于读取的channel
var inputStream chan<- interface{} // 一个只用于输入的channel
golang在必要的时候会将双向的channel隐式地转换为单向的channel。
一个简单的小例子:
stringStream := make(chan string)
go func() {stringStream <-"Hello, channels!"
}()
fmt.Println(<-stringStream)
这一段程序中,按照我们之前的理解:竞争条件在这里依然存在,也就是在程序退出之前很可能都不会执行goroutine中的内容。但是事实上channel消除了竞争条件。
这是因为channel的输入和读出在一定条件下都会让goroutine阻塞:当channel是空,但是你想要读取数据。或者channel满了你却想输入数据的时候。
能够阻塞,当然也能导致DeadLock,因此在使用的时候一定要注意。
关闭一个channel:
close(stringStream)
读出数据的时候可以读出两个值:
data, ok := <-stringStream
// 第一个值是数据值,或者被关闭的通道产生的数据的默认值
// 第二个值是状态值,判断信道的状态是开放还是关闭,开放是true,关闭是false
正因为channel的可以关闭并且有返回值的特性,我们可以使用for-range,并且在channel关闭的时候自动中断循环。
for data := range stringStream {}
3.2 带缓冲的信道 buffered channel
所谓buffered channel就是一个有缓冲容量的信道,我们在之前看到的channel其实就是缓冲容量为0的信道。我们在声明一个新的信道的时候就可以指定缓冲容量。
dataStream := make(chan interface{}, 4)
带缓冲的channel是一个内存中的FIFO队列,用于并发进程之间的通信。
两个比较生动形象的图:
3.3 channel上的操作和相应的结果
| 操作 | Channel的状态 | 结果 |
|---|---|---|
| Read | nil | 阻塞 |
| 打开且非空 | 输出值 | |
| 打开但是空 | 阻塞 | |
| 关闭 | <默认值>,false | |
| 只写 | 编译错误 | |
| Write | nil | 阻塞 |
| 打开且满 | 阻塞 | |
| 打开且不满 | 写入值 | |
| 关闭 | panic | |
| 只读 | 编译错误 | |
| close | nil | panic |
| 打开且非空 | 关闭channel;读取成功,直到信道内值耗尽,然后读取产生值的默认值 | |
| 打开但是空 | 关闭channel;读到生产者的默认值 | |
| 关闭的 | panic | |
| 只读 | 编译错误 |
3.4 使用channel的基本素养
所谓基本素养,其实就是规范使用channel的方法,从而规避死锁和panic的风险。
一个拥有channel的goroutine应该有以下操作:
- 实例化channel
- 执行写操作,或者将channel的所有权传递给其他goroutine
- 关闭channel
- 将1-3项封装好,并且通过一个只读channel将其暴露出来
4. select语句
channel是goroutine之间的粘合剂,而select语句则是channel之间的粘合剂。
如何使用select语句呢?下面是一个简单的示例:
var chan1, chan2 <-chan interface{}
var chan3 chan<- interface{}
select {case <-chan1:// ...
case <-chan2:// ...
case c3<- struct{}{}:// ...
}
和switch语句是很像,但是select语句中的case语句没有测试顺序,即使没有满足任何条件,执行也不会失败。而且一个很大的特性是:golang运行时会将一组case语句中执行伪随机选择。
使用伪随机选择的原因是,golang无法解析select语句的意图,也就是说,它不能推断出问题空间,或者说为什么将一组channel组合在一个select语句中。在这种情况下,最好的选择就是平均情况下运行良好。
4.1 为select语句设置超时时间
var channel <-chan int
select {case <-channel:
case <-time.After(1*time.Second):// ...超时操作
}
4.2 select语句中的default
在select中也存在default语句,执行的条件是全部的channel都是阻塞的。
var channel <-chan int
select {case <-channel:
default:// ...几乎是瞬间执行
}
4.3 使用for-select结构在等待同时工作
for {select {case channel:// ...default:}// ...工作语句
}
4.4 永远阻塞的语句也永远最简单
select{}
这个语句将永远阻塞
《Concurrency in Go》阅读笔记 -- 第三章:Go语言并发组件相关推荐
- 深入理解 C 指针阅读笔记 -- 第三章
Chapter3.h #ifndef __CHAPTER_3_ #define __CHAPTER_3_/*<深入理解C指针>学习笔记 -- 第三章*//*它们都保存在栈中的什么位置?*/ ...
- 《机器学习》阅读笔记 第三章
Contents 1. 不同学科中的线性模型[^1] 2. 线性模型:回归任务 2.1 估计方法 2.2 正则化 2.3 广义线性模型 3. 线性模型:分类任务 3.1 对数几率回归 线性判别分析(L ...
- Web前端开发笔记——第三章 CSS语言 第四节 CSS列表、表格样式
目录 一.CSS列表样式 (一)设计列表项前标志类型 (二)设计列表项前标志位置 (三)设计列表项图片 (四)设计整体列表属性 二.CSS表格样式 (一)设计表格大小 (二)设计表格边框 (三)奇偶选 ...
- Web前端开发笔记——第三章 CSS语言 第八节 CSS3文本文字设置
目录 前言 一.文本阴影 二.强制换行 三.字体设置 结语 前言 本节中的仅支持CSS3中的新语法,比如文字的阴影.长文本的换行等等. 一.文本阴影 通过定义text-shadow来对文本进行阴影设置 ...
- Web前端开发笔记——第三章 CSS语言 第七节 圆角边框、阴影
目录 前言 一.圆角边框 (一)border-×-×-radius (二)border-radius 二.阴影 (一)基本阴影设置 (二)内部阴影设置 结语 前言 本节介绍仅在CSS3中的新内容,例如 ...
- Web前端开发笔记——第三章 CSS语言 第六节 CSS定位
目录 一.定义 二.文档流定位 (一)block类型元素 (二)inline类型元素 (三)inline-block类型元素 三.浮动定位 (一)左浮动和右浮动 (二)清除浮动 四.层定位 (一)st ...
- Web前端开发笔记——第三章 CSS语言 第五节 盒子模型
目录 一.CSS布局与定位 二.盒子模型 三.盒子模型的组成 四.设置边框的属性 五.设置外.内边距的属性 六.overflow 属性 结语 一.CSS布局与定位 在CSS中对一个网页进行布局与定位, ...
- Web前端开发笔记——第三章 CSS语言 第二节 CSS选择器
目录 前言 一.CSS选择器 (一)标签选择器 (二)id选择器 (三)类别选择器 二.针对标签的选择器嵌套 三.集体声明和全局声明 (一)集体声明 (二)全局声明 结语 前言 CSS代码由选择器和一 ...
- Web前端开发笔记——第三章 CSS语言 第一节 CSS的基本概念和样式表
目录 一.CSS和HTML 二.CSS的基本语法格式 三.CSS样式设置 (一)行内样式 (二)内嵌样式 (三)引用外部CSS文件 四.多重样式优先级 结语 一.CSS和HTML CSS,又称为层叠样 ...
最新文章
- 树莓派4装Ubuntu
- AI芯片大战已然打响,国内外巨头抢占万亿智能家居市场
- 黑马lavarel教程---9、缓存操作
- 你不知道的Javascript之原型
- mysql proxy性能差_mysql性能的检查和优化方法
- 如何在程序中生成崩溃转储dump文件以及如何分析dump
- go语言函数的常用用法
- 微软在线测试之lucky string,有关斐波那契的题目都在此了
- WPF编程基础入门 ——— 第三章 布局(四)布局面板StackPanel
- 10.原码、反码、补码
- mysql插入记录时违反唯一索引的处理
- git pull 报错 Your local changes would be overwritten by merge. Commit, stash or revert them to procee
- 接口要怎么测试?接口自动化可以怎么做?
- spring cloud、gradle、父子项目、微服务框架搭建---搭建Eureka注册中心(一)
- 华为荣耀3x G750-T01 Root操作
- Java中有些好的特性(一):静态导入
- B端运营是在做什么 toB
- RT-Thread 移植是stm32F429 pwm例程
- python 全栈开发之路
- 2012年03月31日