【机器学习】创建自己的电影推荐系统
作者 | SO_HAM
编译 | Flin
来源 | analyticsvidhya
介绍
“每次我去看电影,不管电影是关于什么的,都很神奇。“——史蒂芬·斯皮尔伯格
每个人都喜欢电影,不分年龄、性别、种族、肤色或地理位置。通过这种神奇的媒介,我们在某种程度上彼此联系在一起。然而,最有趣的是,我们的选择和组合在电影偏好方面是多么独特。
有些人喜欢特定类型的电影,比如惊悚片、爱情片或科幻片,而另一些人则喜欢主演和导演。当我们考虑到所有这些因素时,要概括一部电影并说每个人都会喜欢它是非常困难的。但尽管如此,我们仍然可以看到相似的电影受到社会特定人群的喜爱。
这就是我们作为数据科学家的作用,从观众的所有行为模式中提取核心信息,也从电影本身中提取信息。所以,废话不多说,让我们直接进入推荐系统的基础。
什么是推荐系统?
简单地说,推荐系统是一个过滤程序,其主要目标是预测用户对特定领域的项目或项目的“评级”或“偏好”。在我们的例子中,这个特定于领域的项目是一部电影,因此,我们推荐系统的主要重点是在给定用户的一些数据的情况下,过滤和预测哪些是用户更喜欢的电影。
有哪些不同的过滤策略?
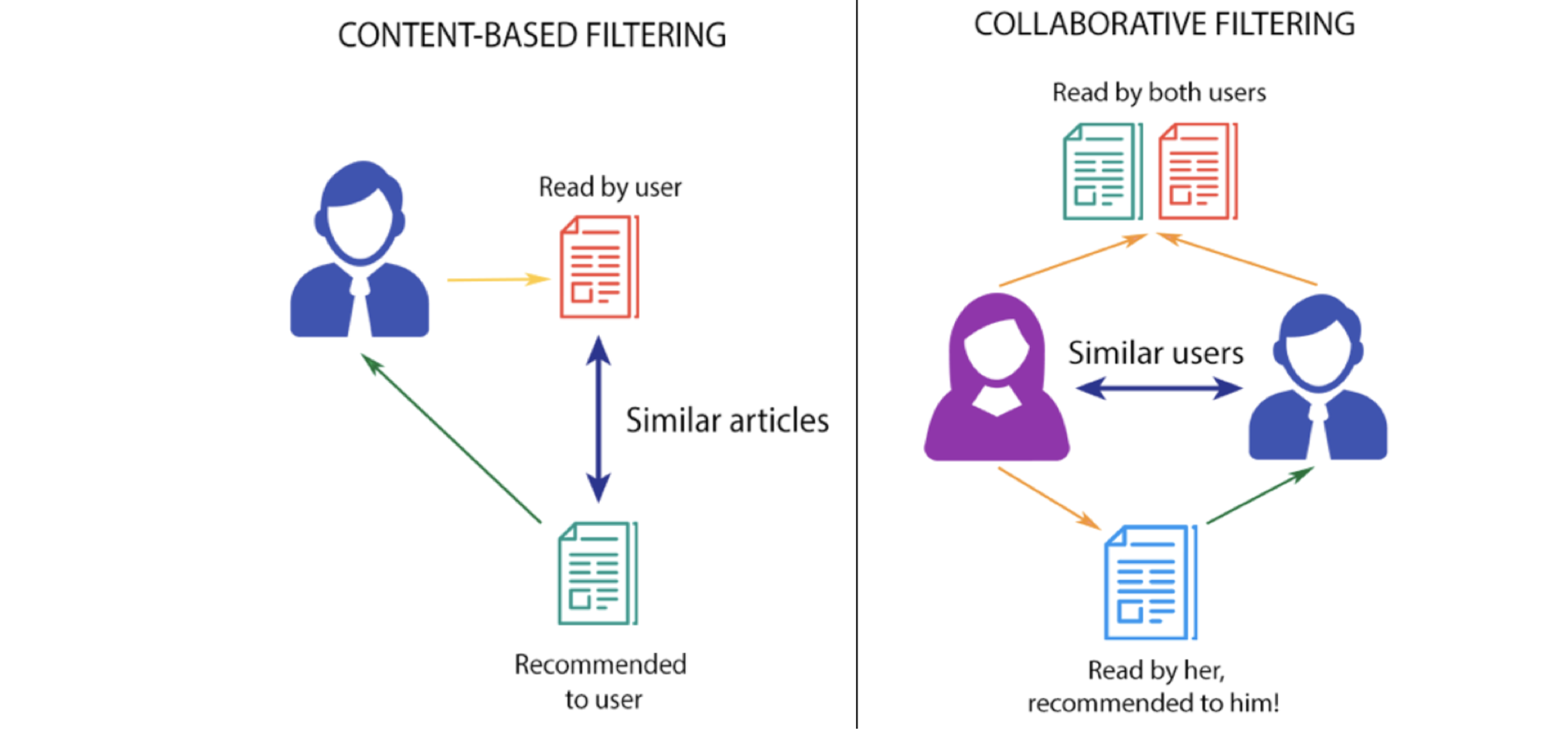
基于内容的过滤
此过滤策略基于提供的关于项目的数据。该算法会推荐与用户过去喜欢的产品相似的产品。这种相似度(通常是余弦相似度)是根据我们拥有的关于商品的数据以及用户过去的偏好计算出来的。
例如,如果用户喜欢《The Prestige》这样的电影,那么我们就可以向他推荐克里斯蒂安·贝尔(Christian Bale)的电影、惊悚片(Thriller)或者克里斯托弗·诺兰(Christopher Nolan)导演的电影。
这里发生了什么?用户的推荐系统检查过去的喜好,找到这部电影《The Prestige》,然后试图找到类似的电影,使用数据库中的信息,如主演、导演、相关体裁的电影,制作公司等,基于这些信息找到类似于《The Prestige》的电影。
缺点
用户很少能接触到不同类型的产品
由于用户不尝试不同类型的产品,业务无法扩展。
协同过滤
该过滤策略基于用户行为的组合,并将其与数据库中其他用户的行为进行比较和对比。所有用户的历史在该算法中扮演着重要的角色。基于内容的过滤和协同过滤的主要区别在于,协同过滤是所有用户与项目的交互影响推荐算法,而基于内容的过滤只考虑相关用户的数据。
协同过滤有多种实现方式,但需要把握的主要概念是,在协同过滤中,多个用户的数据会影响推荐的结果。而且建模并不仅仅依赖于一个用户的数据。
协同过滤算法有两种:
基于用户的协同过滤
这里的基本理念是找到与用户“A”有相似偏好模式的用户,然后推荐那些“A”还没有遇到过的相似用户喜欢的商品。这是通过建立一个矩阵来实现的,矩阵中列出了每个用户根据其手头的任务对其进行评级/查看/喜欢/点击的项目,然后计算用户之间的相似度得分,最后推荐相关用户不知道但与他/她相似的用户喜欢的项目。
例如,如果用户A喜欢“Batman Begins”、“Justice League”和“the Avengers”,而用户B喜欢“Batman Begins”、“Justice League”和“Thor”,那么他们的兴趣是相似的,因为我们知道这些电影都属于超级英雄类型。因此,用户a很有可能会喜欢《雷神》,用户B很有可能会喜欢《复仇者联盟》。
缺点
人是浮躁的,他们的喜好是不断变化的,因为这个算法是基于用户相似度的,它可能会挑选出两个用户之间最初的相似模式,一段时间后,可能会有完全不同的偏好。
用户比项目多很多,因此维护这么大的矩阵变得非常困难,因此需要定期重新计算。
该算法非常容易受到先令攻击,其中包含带有偏见的偏好模式的虚假用户档案被用来操纵关键决策。
基于项目协同过滤
这种情况下的概念是找到相似的电影,而不是相似的用户,然后推荐与“A”过去喜欢的电影相似的电影。这是通过找到被同一用户评价/观看/点赞/点击的每一对物品,然后在所有同时评价/观看/点赞/点击的用户中测量那些被评价/观看/点赞/点击的物品的相似性,最后根据相似性分数推荐它们。
例如,我们选取两部电影“A”和“B”,并根据这两部电影的相似度,由所有给这两部电影都评级过的用户检查它们的评级,根据给这两部电影都评级过的用户的评级相似度,我们会发现相似的电影。所以,如果大多数普通用户对“A”和“B”的评价都是相似的,那么“A”和“B”很有可能是相似的,因此如果有人观看并喜欢“A”,那么他们就应该被推荐“B”,反之亦然。
优于基于用户的协同过滤
不像人们的喜好千变万化,电影不会改变。
矩阵的项通常比人少很多,因此更容易维护和计算矩阵。
先令攻击更加困难,因为电影不能伪造。
让我们开始编写我们自己的电影推荐系统
在这个实现中,当用户搜索一部电影时,我们将使用我们的电影推荐系统推荐排名前10的类似电影。我们将使用基于项目的协同过滤算法。本演示中使用的数据集是movielens-small数据集。
movielens-small数据集:https://www.kaggle.com/shubhammehta21/movie-lens-small-latest-dataset
启动并运行数据
首先,我们需要导入我们将在电影推荐系统中使用的库。另外,我们将通过添加CSV文件的路径来导入数据集。
import pandas as pd
import numpy as np
from scipy.sparse import csr_matrix
from sklearn.neighbors import NearestNeighbors
import matplotlib.pyplot as plt
import seaborn as sns
movies = pd.read_csv("../input/movie-lens-small-latest-dataset/movies.csv")
ratings = pd.read_csv("../input/movie-lens-small-latest-dataset/ratings.csv")现在我们已经添加了数据,让我们看看这些文件,使用dataframe.head()命令打印数据集的前5行。
让我们来看看电影数据集:
movies.head()![]()
电影数据集有:
movieId——推荐完成后,我们会得到一个包含所有相似movieId的列表,并从这个数据集获得每个电影的标题。
genres,体裁——这个过滤方法不需要。
ratings.head ()![]()
评级数据集具有:
userId——对每个用户都是唯一的。
movieId——使用这个特性,我们从电影数据集获取电影的标题。
rating——每个用户给所有电影的评级,使用这个我们将预测前10个类似的电影。
在这里,我们可以看到userId 1观看了movieId 1和3,并将它们都评为4.0,但根本没有给movieId 2打分。这个解释很难从这个数据帧中提取出来。
因此,为了使事情更容易理解和使用,我们将创建一个新的数据帧,其中每个列将表示每个惟一的用户id,每个行表示每个惟一的movieId。
final_dataset = ratings.pivot(index='movieId',columns='userId',values='rating')
final_dataset.head()![]()
现在,更容易理解的是,userId 1对movieId 1和3进行了评级,但根本没有对movieId 3、4、5进行评级(因此它们被表示为NaN),因此它们的评级数据是缺失的。
让我们解决这个问题,并将NaN归为0,以使算法更容易理解,同时也使数据看起来更令人舒服。
final_dataset.fillna(0,inplace=True)
final_dataset.head()![]()
去除数据中的噪音
在现实世界中,评分非常少,数据点大多来自非常受欢迎的电影和高参与度的用户。我们不希望电影被一小部分用户评分,因为它不够可信。同样,只给少数几部电影打分的用户也不应该被考虑在内。
因此,考虑到所有这些因素和一些反复试验,我们将通过为最终数据集添加一些过滤器来减少噪声。
至少有10个用户对一部电影进行了投票。
为了使一个用户有资格,至少50部电影应该由用户投票。
让我们直观地看到这些过滤器的外观
汇总投票的用户数量和被投票的电影数量。
no_user_voted = ratings.groupby('movieId')['rating'].agg('count')
no_movies_voted = ratings.groupby('userId')['rating'].agg('count')让我们直观地看到以阈值10投票的用户数量。
f,ax = plt.subplots(1,1,figsize=(16,4))
# ratings['rating'].plot(kind='hist')
plt.scatter(no_user_voted.index,no_user_voted,color='mediumseagreen')
plt.axhline(y=10,color='r')
plt.xlabel('MovieId')
plt.ylabel('No. of users voted')
plt.show()![]()
根据阈值设置进行必要的修改。
final_dataset = final_dataset.loc[no_user_voted[no_user_voted > 10].index,:]让我们以50的阈值来可视化每个用户的投票数量。
f,ax = plt.subplots(1,1,figsize=(16,4))
plt.scatter(no_movies_voted.index,no_movies_voted,color='mediumseagreen')
plt.axhline(y=50,color='r')
plt.xlabel('UserId')
plt.ylabel('No. of votes by user')
plt.show()![]()
根据阈值设置进行必要的修改。
final_dataset=final_dataset.loc[:,no_movies_voted[no_movies_voted > 50].index]
final_dataset![]()
消除稀疏
我们的final_dataset的维数是2121 * 378,其中大多数值是稀疏的。我们只使用了一个小的数据集,但是对于电影镜头的原始大数据集,有超过100000个特征,我们的系统可能会在将这些特征输入到模型时耗尽计算资源。为了减少稀疏性,我们使用scipy库中的csr_matrix函数。
我将举个例子来说明它是如何工作的:
sample = np.array([[0,0,3,0,0],[4,0,0,0,2],[0,0,0,0,1]])
sparsity = 1.0 - ( np.count_nonzero(sample) / float(sample.size) )
print(sparsity)![]()
sample = np.array([[0,0,3,0,0],[4,0,0,0,2],[0,0,0,0,1]])
sparsity = 1.0 - ( np.count_nonzero(sample) / float(sample.size) )
print(sparsity)![]()
正如你所看到的,csr_sample中没有稀疏值,值被分配为行和列索引。对于第0行和第2列,值是3。
应用csr_matrix函数到数据集:
csr_data = csr_matrix(final_dataset.values)
final_dataset.reset_index(inplace=True)制作电影推荐系统模型
我们将使用KNN算法计算与余弦距离度量的相似度,这是非常快的,比皮尔逊系数更好。
knn = NearestNeighbors(metric='cosine', algorithm='brute', n_neighbors=20, n_jobs=-1)
knn.fit(csr_data)推荐函数的制作
工作原理很简单。我们首先检查输入的电影名是否在数据库中,如果在数据库中,我们使用推荐系统查找相似的电影,并根据它们的相似距离对它们进行排序,然后只输出与输入电影之间的距离最高的10部电影
def get_movie_recommendation(movie_name):n_movies_to_reccomend = 10movie_list = movies[movies['title'].str.contains(movie_name)] if len(movie_list): movie_idx= movie_list.iloc[0]['movieId']movie_idx = final_dataset[final_dataset['movieId'] == movie_idx].index[0]distances , indices = knn.kneighbors(csr_data[movie_idx],n_neighbors=n_movies_to_reccomend+1) rec_movie_indices = sorted(list(zip(indices.squeeze().tolist(),distances.squeeze().tolist())),key=lambda x: x[1])[:0:-1]recommend_frame = []for val in rec_movie_indices:movie_idx = final_dataset.iloc[val[0]]['movieId']idx = movies[movies['movieId'] == movie_idx].indexrecommend_frame.append({'Title':movies.iloc[idx]['title'].values[0],'Distance':val[1]})df = pd.DataFrame(recommend_frame,index=range(1,n_movies_to_reccomend+1))return dfelse:return "No movies found. Please check your input"最后,我们来推荐一些电影吧!
get_movie_recommendation('Iron Man')我个人认为结果相当不错。所有在顶端的电影都是超级英雄或动画电影,就像输入电影“钢铁侠”一样,是孩子们的理想选择。
![]()
让我们再试一个:
get_movie_recommendation('Memento')![]()
排名前十的电影都是严肃的、用心的电影,就像《记忆碎片》本身一样,所以我认为这个结果也是好的。
我们的模型运行得很好——一个基于用户行为的电影推荐系统。因此,我们在此总结我们的协同过滤。你可以在这里得到完整的实现代码。
https://github.com/So-ham/Movie-Recommendation-System
原文链接:https://www.analyticsvidhya.com/blog/2020/create-your-own-movie-movie-recommendation-system/
往期精彩回顾适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑温州大学《机器学习课程》视频
本站qq群851320808,加入微信群请扫码:【机器学习】创建自己的电影推荐系统相关推荐
- 第四范式程晓澄:机器学习如何优化推荐系统
本文经AI新媒体量子位(公众号ID:qbitai )授权转载,转载请联系出处 本文长度为9532字,建议阅读10分钟 本文为你介绍推荐系统的诞生土壤和早起演进.推荐系统当下的基本架构以及如何搭建一个推 ...
- Azure机器学习——创建Azure机器学习服务
创建Azure机器学习服务 一.Azure订阅 二.创建Azure机器学习服务(工作区) 在Azure portal界面创建Azure机器学习工作区 使用Python SDK创建Azure机器学习工作 ...
- 【推荐书籍】《机器学习范式在推荐系统中的应用Machine Learning Paradigms- Applications in Recommender Systems》
前几天吐槽了一本口水太多的推荐系统书籍<Practical Recommender Systems实用推荐系统>,最近读到了这本<机器学习范式在推荐系统中的应用>(英文名< ...
- 基于大规模机器学习模型的推荐系统
推荐系统的本质是什么? 比如说我们看到手机淘宝首页,往下一拉,就能看到各种各样推荐的商品:比如说百度,它会给我们推荐广告,在某种程度上他的工作方式也很像推荐系统:再比如说今日头条,今日头条从数十万的新 ...
- apache mahout_使用Apache Mahout创建在线推荐系统
apache mahout 最近, 我们一直在为Yap.TV实施推荐系统:您可以在安装应用程序并转到" Just for you"标签后才能看到它的运行情况. 我们以Apache ...
- 使用Apache Mahout创建在线推荐系统
最近, 我们一直在为Yap.TV实施推荐系统:在安装应用程序并转到" Just for you"选项卡后,您可以看到它的运行情况. 我们以Apache Mahout为基础进行建议. ...
- 入门机器学习(十九)--推荐系统(Recommender Systems)
推荐系统(Recommender System) 1. 问题规划(Problem Formulation) 2. 基于内容的推荐系统(Content Based Recommendations) 3. ...
- 基于sklearn的机器学习 - 创建分类器
创建分类器 简介 分类器是指利用数据的特性将其分成若干类型的过程.监督学习分类器就是利用代表及的训练数据建立 一个模型,然后对未知数据进行分类 建立简单的分类器 代码参考learn1 建立逻辑回归分类 ...
- 1. 大数据 机器学习 深度学习 推荐系统 学习路线
文章目录 思维导图下载 大数据基础 linux NGINX负载均衡 Zookeeper hadoop生态 hadoop hive hbase 大数据数据仓库 数据仓库基础 日志收集系统(Flume) ...
最新文章
- 用VS(c#)创建、调试windows service以及部署卸载
- AtCoder Regular Contest 092 Two Sequences AtCoder - 3943 (二进制+二分)
- 高端计算机教室,又一所高端学校来了,能住校师资力量强大
- 【转】日服巫术online过驱动保护分析(纯工具)(工具+自写驱动)
- 完善Library的管理方式
- React Native之提示Unable to load script from assets ‘index.android.bundle
- [Java基础]List集合
- (第一章)数据库的类型
- Python3.x中的三目运算实现方法
- 《Spring Security3》第四章第一部分翻译下(自定义的UserDetailsServic
- [汇编学习笔记][第十六章直接定址表]
- CF618F Double Knapsack 构造、抽屉原理
- 使用traceview进行Android性能测试(转)
- 通讯(transport)
- .net GridView绑定数据、编辑、更新、删除(弹出确认对话框)、取消、根据条件隐藏或显示按钮操作
- cad导出pdf_办公神器(四)完全免费cad批量打印软件,支持导出pdf
- typora主题配置:公众号一键排版
- 使用 wpa_supplicant 连接 WiFi
- 属性值第二个字符是大写引发的血案Warning:(X,X) java: Unmapped target property: “vCpu“.
- 教你如何关闭Surface Go的触摸键盘?